基于混合特征選擇算法的抑郁癥分類方法
2022-06-24 10:02:06沈瀟童王蘇弘陳芋圻
計算機應(yīng)用與軟件 2022年4期
王 玥 沈瀟童 王蘇弘 陳芋圻 鄒 凌*
1(常州大學(xué)信息科學(xué)與工程學(xué)院 江蘇 常州 213164) 2(常州市生物醫(yī)學(xué)信息技術(shù)重點實驗室 江蘇 常州 213164) 3(蘇州大學(xué)附屬第三醫(yī)院 江蘇 常州 213164)
0 引 言
抑郁癥是一種精神疾病,患者會表現(xiàn)出失去興趣、自卑感和注意力不集中等相關(guān)的精神癥狀,甚至?xí)霈F(xiàn)自殺傾向[1]。根據(jù)世界衛(wèi)生組織報告,預(yù)計在2030年,抑郁癥將成為世界疾病負(fù)擔(dān)的首位。目前,臨床對抑郁癥的診斷主要是通過臨床訪談和量表對癥狀進(jìn)行評估,如果根據(jù)大腦生理機制的情況監(jiān)測到抑郁癥的出現(xiàn),不僅能夠使治療更加有效,也更利于醫(yī)生改善患者的心理健康狀態(tài)[2]。而腦電(EEG)被公認(rèn)為是一種廉價、安全且無創(chuàng)性地評估腦功能的方法,更加適合于常規(guī)使用[3]。
此前,腦功能連接已被廣泛應(yīng)用于識別有無抑郁癥的差異,并根據(jù)這些差異進(jìn)行分類。Peng等[4]使用相位滯后指數(shù)研究抑郁癥患者的腦功能連接,并將上三角矩陣的連接值提取作為特征進(jìn)行分類。Zhong等[5]通過計算全腦功能連接,使用矩陣的連接值作為特征對抑郁癥和健康對照進(jìn)行分類,結(jié)果表明分類精度達(dá)到90%以上。Liu等[6]將腦功能計算后的連接值作為進(jìn)一步分析的特征并進(jìn)行分類。
由于特征維數(shù)較大,為提高學(xué)習(xí)算法效率,特征選擇顯得尤為重要。Sayed等[7]提出混沌烏鴉搜索算法(CCSA),并將其運用于優(yōu)化20個基準(zhǔn)數(shù)據(jù)集的特征選擇問題,結(jié)果表明該算法能夠找到最佳特征子集從而達(dá)到最大的分類性能。Majdi等[8]提出將鯨魚優(yōu)化算法(WOA)與模擬退火算法(SA)相結(jié)合,使用18個標(biāo)準(zhǔn)數(shù)據(jù)集對該方法進(jìn)行評估,發(fā)現(xiàn)其能使用更少的特征而獲得更高的準(zhǔn)確性。Shen等[9]為解決高維特征選擇問題,提出了競爭群優(yōu)化器算法(CSO),并與標(biāo)準(zhǔn)的蟻群算法(PSO)和最新PSO變體算法相比,其選擇的數(shù)量不僅最少,還能獲得更好的分類性能。本文選擇了二次規(guī)劃特征選擇(QPFS)和費舍爾分?jǐn)?shù),QPFS是依據(jù)互信息方法獲取同類之間的相關(guān)性,且對于大型數(shù)據(jù)集有著較高的效率,而費舍爾分?jǐn)?shù)排序是基于相似性方法,根據(jù)同一樣本中特征值相似,而不同樣本中的特征值不同來進(jìn)行排序。
機器學(xué)習(xí)在分類模型訓(xùn)練和建立中有著廣泛的應(yīng)用。Schnyer等[10]通過腦白質(zhì)MRI指標(biāo),使用機器學(xué)習(xí)中的SVM進(jìn)行分類預(yù)測,發(fā)現(xiàn)僅使用大腦右半球的分類精度更高。Sharma等[11]將所采集的腦電信號分解為七個小波子帶(WSB),六個詳細(xì)的WSB和一個近似WSB的L2范數(shù)的對數(shù)作為特征,通過最小二層支持向量機進(jìn)行分類,模型分類精度高達(dá)99.58%。Li等[12]采取了抑郁癥患者和健康人的任務(wù)態(tài)數(shù)據(jù),將功率譜密度、近似熵等18種腦電特征提取出來,利用差分進(jìn)化的全局優(yōu)化性能獲得最佳特征值,再使用K近鄰進(jìn)行分類,精度最高可達(dá)98.33%。
本文采用了EGI公司的64導(dǎo)腦電采集系統(tǒng),結(jié)合Net station軟件,實時采集了抑郁癥患者和健康人在面對flanker范式下的腦電信號,對其預(yù)處理分段,采用相位鎖定值構(gòu)建腦功能網(wǎng)絡(luò),求得連接矩陣,將兩組被試者具有顯著性差異的連接值作為分類特征進(jìn)行提取,然后使用二次規(guī)劃特征選擇方法(QPFS)和費舍爾分?jǐn)?shù)分別對特征進(jìn)行選擇排序,結(jié)合二者優(yōu)點,根據(jù)文獻(xiàn)[13]研究結(jié)果和排序結(jié)果,選擇排序后的前100個特征集,取二者交集和并集。進(jìn)一步使用遺傳算法(GA)選擇出最佳子集,因為GA是一種簡單的算法,且已自1970年以來被廣泛使用,被證明在減少特征維度和提高分類精度方面十分有用。最后采用支持向量機(SVM)、K近鄰(KNN)和邏輯回歸(LG)分類器,為了盡可能地利用數(shù)據(jù),分類器采用留一交叉驗證法,結(jié)果表明,采用混合算法的交集聯(lián)合遺傳算法,特征數(shù)目從1 317降維至12,且分類精度也達(dá)到最高值96.8%。
1 方 法
1.1 被 試
本次共16名健康青少年(對照組)與15名患有中度抑郁癥(抑郁組)的青少年參加實驗,其年齡范圍為(16.31±1.25),兩組之間的年齡無統(tǒng)計意義。所有被試者均無精神病史、吸毒史和酗酒等情況,且皆為右利手,其在常州市第一人民醫(yī)院經(jīng)過臨床確診,通過漢密爾頓抑郁量表檢測,結(jié)果顯示,抑郁組的分?jǐn)?shù)高于對照組。
該實驗已經(jīng)常州市第一人民醫(yī)院倫理委員會批準(zhǔn),所有受試者與其監(jiān)護(hù)人均簽署了知情同意書,自愿參加本實驗。
1.2 實驗范式
該實驗使用E-prime軟件進(jìn)行。首先,屏幕上將會出現(xiàn)形如“+”的注視點,持續(xù)時間為200~700 ms,隨即出現(xiàn)一幅由5個箭頭組成的圖形,目標(biāo)刺激為中間箭頭,如下所示,“<<<<<”(一致方向)、“>>>>>”(一致方向)、“<<><<”(不一致方向)、“>><>>”(不一致方向),該刺激持續(xù)時間為200 ms。最后,屏幕將會出現(xiàn)全黑圖片,被試者需要在1 700 ms內(nèi)根據(jù)目標(biāo)刺激與兩翼箭頭的方向按下按鈕,其中,目標(biāo)刺激與兩翼箭頭一致時按下“1”鍵,目標(biāo)刺激與兩翼箭頭不一致時按下“4”鍵。在正式實驗開始前,將會有一個訓(xùn)練部分,該部分有32試次。正式實驗階段有11部分,每部分同樣有32試次。一致和不一致圖片以偽隨機的方式呈現(xiàn),出現(xiàn)概率相同,具體如圖1所示。

圖1 flanker范式流程示意圖
1.3 數(shù)據(jù)采集及預(yù)處理
本次實驗使用軟件Net Station與EGI公司的64導(dǎo)聯(lián)腦電采集系統(tǒng)實時采集,電極位置分布符合10-10國際標(biāo)準(zhǔn),且以Cz為參考電極,采樣頻率為500 Hz,電極阻抗均設(shè)定在50 kΩ以下,進(jìn)行0.5~45 Hz的帶通濾波。
原始腦電信號的預(yù)處理使用EEGLAB(版本號:v14.1.2)工具箱[14],其經(jīng)過0.5~45 Hz高低通濾波,并針對所有導(dǎo)聯(lián)進(jìn)行獨立成分分析(ICA),用以消除眨眼、頭動等偽跡[15-16]。對于信號漂移的壞導(dǎo),使用相鄰導(dǎo)聯(lián)數(shù)據(jù)疊加平均替換,且參考點重新轉(zhuǎn)換為平均參考。基線重新校正為刺激前200 ms,并根據(jù)刺激前200 ms至刺激后800 ms對數(shù)據(jù)進(jìn)行分段。
1.4 腦功能連接
相位鎖定值是檢測兩個信號在具體頻率范圍內(nèi)與幅度無關(guān)的瞬時鎖相值,以此量化信號間的相互作用[17]。給定信號x,在進(jìn)行帶通濾波后,其相位瞬時相位可以通過計算希爾伯特變換獲得[18-19]:
(1)
式中:φ的取值范圍為-π到π。z(t)根據(jù)x(t)經(jīng)過下式計算得到:
z(t)=x(t)+i·HT{x(t)}=A(t)·ei·φ(t)
(2)
在t時刻的相位鎖定值定義如下:
(3)
式中:N代表的試次的數(shù)量;θ(t,n)代表兩個信號的瞬時相位差,即φ1(t,n)-φ2(t,n)。在此,PLV的取值介于0~1范圍內(nèi),當(dāng)兩信號在該試次的相位完美同步時,PLV的取值為1,反之,取值則為0。
根據(jù)式(3),本文研究了在五個頻段下被試者的腦功能連接,分別為delta(1~3 Hz)、theta(4~8 Hz)、alpha(8~13 Hz)、beta(13~30 Hz)和gamma(30~45 Hz)[20]。并使用t檢驗尋找對照組和抑郁組在面對兩種情況下腦功能連接的顯著差異,將差異顯著的連接值作為原始特征。
1.5 基于全局互信息的二次規(guī)劃特征選擇
特征選擇是一種必不可少的處理步驟,它能有效地消除機器學(xué)習(xí)樣本中不相關(guān)或者冗余的特征,進(jìn)而提高計算效率。本文特征選擇方法流程圖如圖2所示。

圖2 所提出的混合特征選擇算法流程
基于互信息的方法則在數(shù)據(jù)挖掘中的重要特征選擇有著重要地位。為了避免做出次優(yōu)選擇,可將基于互信息(MI)的特征選擇作為全局優(yōu)化問題,同時,考慮所有特征之間的相互作用來做出全局決策。假設(shè)有m個樣本n個特征,QPFS公式如下所示:
(4)

1.6 費舍爾分?jǐn)?shù)
在本研究中,除了基于二次規(guī)劃特征選擇將特征進(jìn)行排序,還選擇使用費舍爾分?jǐn)?shù)對特征進(jìn)行選擇。費舍爾分?jǐn)?shù)根據(jù)Fisher準(zhǔn)則對每個特征進(jìn)行評分,第j個特征的費舍爾分?jǐn)?shù)可通過以下公式計算得出:
(5)

1.7 混合特征算法
設(shè)原特征集為f={f1,f2,…,fn}m×n,代表著有m個樣本,n個特征。經(jīng)過QPFS按照權(quán)重進(jìn)行排序后,得到fQPFS={fQ1,fQ2,…,fQn},此外,根據(jù)費舍爾分?jǐn)?shù)進(jìn)行排序,得到ffisher={fF1,fF2,…,fFn},為了聯(lián)合兩種算法,盡可能的結(jié)合二者優(yōu)點,分別對fQPFS和ffisher特征集中,前100個特征取交集或并集:
f交集={fQ1,fQ2,…,fQ100}∩{fF1,fF2,…,fF100}
(6)
f并集={fQ1,fQ2,…,fQ100}∪{fF1,fF2,…,fF100}
(7)
1.8 遺傳算法
使用混合特征算法以后,再使用遺傳算法進(jìn)一步選擇合適的特征子集,如圖2所示。遺傳算法是基于達(dá)爾文的自然進(jìn)化和選擇過程的隨機過程搜索算法。通過模擬生物學(xué)中的繁殖、交叉和突變現(xiàn)象,在不斷的迭代中選擇出更好的個體[21]。首先,隨機初始化種群,即父本,計算適應(yīng)度函數(shù)以后,當(dāng)滿足目標(biāo)條件時,該算法結(jié)束,否則將會根據(jù)適應(yīng)度選擇父本,根據(jù)父本的染色體,進(jìn)行交叉產(chǎn)生新的子代,子代進(jìn)行變異,根據(jù)交叉和變異生成了新的種群,計算該種群的適應(yīng)度函數(shù),直至其滿足目標(biāo)條件。考慮到操作的快捷和計算效率,且由于特征值均在0~1之間,編碼采用二進(jìn)制編碼,設(shè)置特征值小于0.5為0,大于0.5為1。另外,考慮到分類性能,選取了較為廣泛使用的基于近鄰法分類的適應(yīng)度函數(shù),用以計算預(yù)期的適應(yīng)度,進(jìn)一步評估染色體的準(zhǔn)確性。
1.9 分 類
機器學(xué)習(xí)中包含著多種分類器,SVM、KNN和LG將會被使用來支持算法結(jié)果。為了分類精度更加可靠和最大化利用數(shù)據(jù),此次分類采用留一交叉驗證法,將平均后的分類精度(ACC)作為分類結(jié)果,其參數(shù)計算如下:
(8)
式中:TP代表正確將抑郁組識別為抑郁組的數(shù)量;TN表示正確地將對照組識別為對照組的數(shù)量;FP代表錯誤地將抑郁組識別為對照組的數(shù)量;FN表示錯誤地將對照組識別為抑郁組的情況。
2 實 驗
2.1 功能連接
根據(jù)PLV方法計算所得,抑郁組與對照組的在五個頻段下的功能連接矩陣圖(64×64,代表導(dǎo)聯(lián)×導(dǎo)聯(lián))如圖3所示。該連接矩陣的連接值介于0到1,連接值越大,代表兩信號間的同步性越強。從圖中可以看出,抑郁組的連接強度在五個頻段下都較低于對照組,然而對比在五個頻段下,抑郁組和對照組在面對兩種情況時,抑郁癥患者在對角線處的連接強度高于對照組,而除對角線以外,抑郁癥患者的連接強度低于對照組。
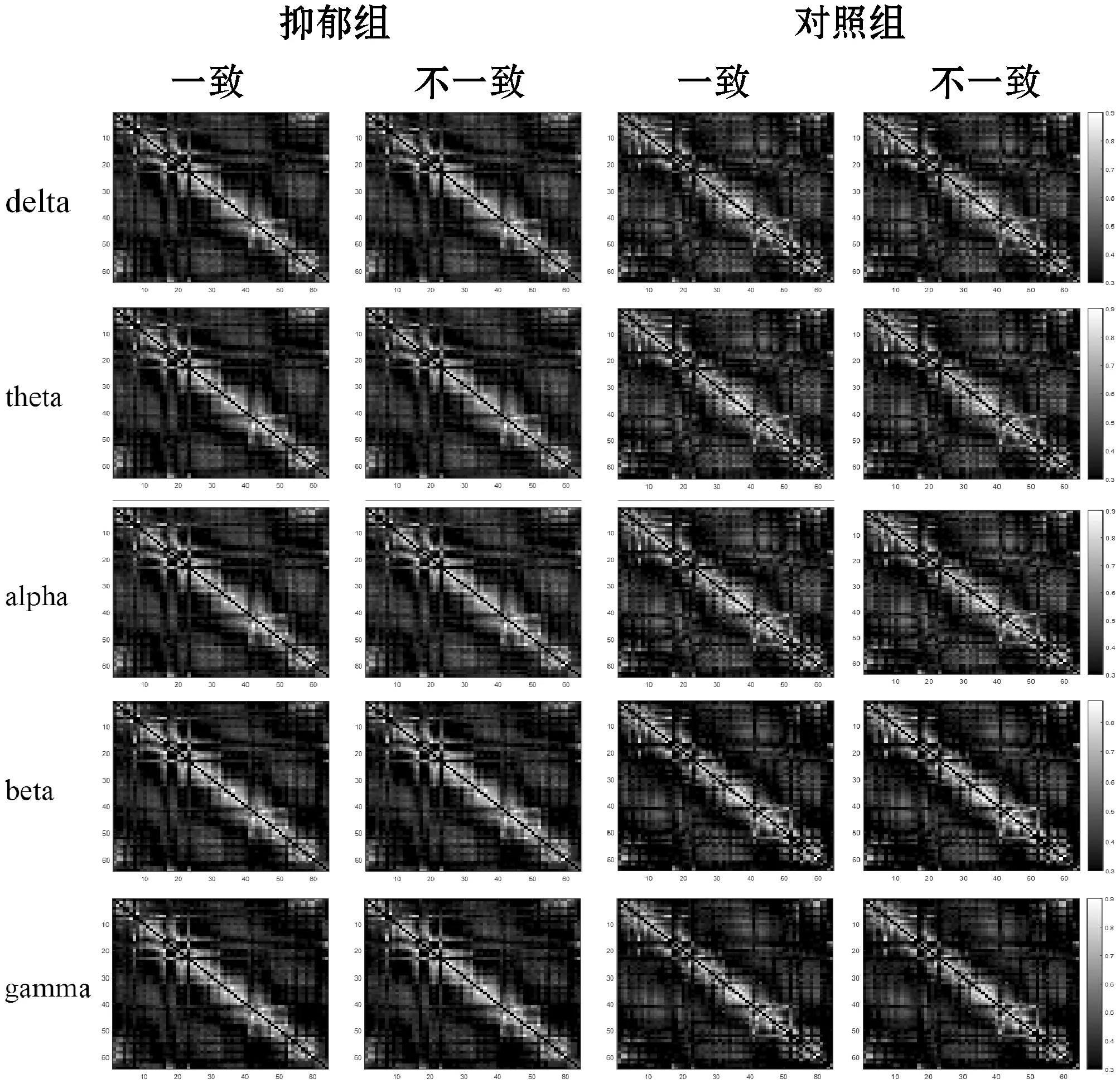
圖3 五個頻段下受試者的腦功能連接圖
為了尋找抑郁組與對照組在面對一致刺激和不一致刺激的顯著差異,將抑郁組與對照組進(jìn)行t檢驗,提取p<0.05的連接值,如圖4所示。通過抑郁組與對照組的連接強度差異來看,相對于面對箭頭一致的刺激,面對不一致刺激時,抑郁組與對照組的差異更為顯著,且在五個頻段下,均有較多差異顯著的連接值。

圖4 五個頻段下抑郁組與對照組的顯著差異圖
2.2 特征排序
在提取五個頻段和兩種情況下的連接強度的顯著性差異作為原始特征,特征數(shù)共1 317個,分別根據(jù)QPFS和費舍爾分?jǐn)?shù)進(jìn)行特征排序,QPFS排序后結(jié)果如圖5所示。前100個特征權(quán)重已達(dá)整體權(quán)重的99.99%,因此,分別取QPFS和費舍爾分?jǐn)?shù)排序后的前100個特征進(jìn)行交集和并集,生成新的特征集。

圖5 QPFS排序后的特征權(quán)重
2.3 分類結(jié)果
在分別對QPFS和費舍爾分?jǐn)?shù)排序過后的前100特征,分別對兩個新特征集進(jìn)行并集和交集,再使用GA算法,進(jìn)一步確定最優(yōu)的分類特征集。同時,為了顯示該操作的優(yōu)越性,分別在QPFS和費舍爾分?jǐn)?shù)排序后的前100特征進(jìn)行GA算法生成新子集,并采用SVM、KNN和LG進(jìn)行分類,其特征數(shù)和分類結(jié)果如表1所示。
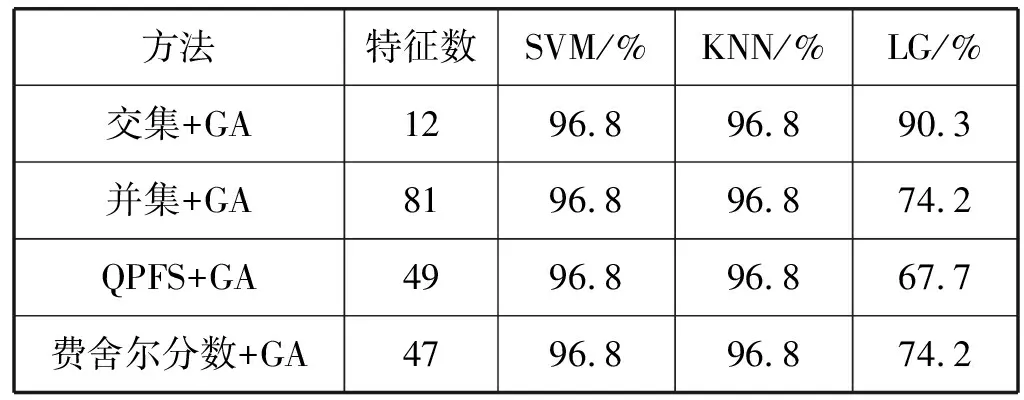
表1 不同算法下所使用的特征數(shù)和分類精度
當(dāng)采用SVM和KNN分類器時,其分類精度都能達(dá)到最高,但是,選擇QPFS和費舍爾分?jǐn)?shù)的交集結(jié)合GA,其特征數(shù)目最少,在僅有12個特征的情況下,精度都能達(dá)到96.8%。
為了進(jìn)一步突出所提算法的優(yōu)越性,將其與經(jīng)典的特征降維算法進(jìn)行比較分析,其中包括主成分分析(PCA)、線性判別式分析(LDA)、等距特征映射(ISOMAP)和局部線性嵌入(LLE)。其中,LDA、ISOMAP和LLE使用了drtoolbox工具箱,先對1 317個特征使用最大似然估計(EKM)做本質(zhì)維度估計,再調(diào)用不同函數(shù)進(jìn)行降維;而PCA降維采用MATLAB中的princomp函數(shù)直接對1317個特征降維。將所有降維后的特征值分別進(jìn)行分類,結(jié)果如表2所示。

表2 經(jīng)典算法下所使用的特征數(shù)和分類精度
與傳統(tǒng)經(jīng)典算法相比,多算法交集聯(lián)合GA所提取出的特征子集,不僅分類精度更高,特征數(shù)目也更少。
3 結(jié) 語
本研究采用了flanker任務(wù)態(tài)范式來研究抑郁組與對照組之間的差異,在分析面對一致性刺激和不一致刺激時的腦功能連接狀態(tài)時,運用了相位鎖定指數(shù)構(gòu)建腦功能連接網(wǎng)絡(luò)。研究發(fā)現(xiàn),在對角線區(qū)域,抑郁組的腦功能強度大于對照組,但是在其他區(qū)域,抑郁組的腦功能強度低于對照組。另外,在面對一致性刺激和不一致刺激時,將兩組差異顯著的連接值作為特征進(jìn)行分類,但是特征數(shù)量較大,如果直接進(jìn)行分類則計算耗時較長,效率較低。
本文著重于在保證分類精度的情況下,如何選出特征數(shù)目更少的分類特征子集。首先,使用基于互信息的QPFS對所有特征根據(jù)其權(quán)重進(jìn)行排序,取其前100個特征作為新特征集,另外,對原始特征集使用費舍爾分?jǐn)?shù)同樣進(jìn)行排序,也取前100個特征作為新特征集。QPFS能夠有效地根據(jù)互信息選擇出特征間相關(guān)性較大的特征,從而篩選出有效特征,而費舍爾分?jǐn)?shù)根據(jù)同類樣本間的相似度和不同樣本間的差異度選擇出分類特征。對于兩個特征集,分別取其并集和交集,取交集或并集的目的是為了滿足所選子集具有兩種算法的優(yōu)點。然后使用GA進(jìn)一步優(yōu)化特征子集,作為最終的分類特征集。最后在分類時,分別采用SVM、KNN和LG多種分類器,結(jié)果表明,多算法交集聯(lián)合GA在特征精度同樣的情況下,擁有更少的特征數(shù);與廣泛使用的傳統(tǒng)PCA、LDA、ISOPMAP和LLE相比,其不管在分類精度,還是特征數(shù)目方面,都顯示出了更優(yōu)越的性能。
本文方法偏重于特征選擇和降維,作為計算機輔助診斷技術(shù)來說是可行的,大大降低了臨床診斷時間。同時,對于高維特征選擇的問題,本文研究也提供了一定的思路,從1 317個高維特征數(shù)降到僅12個特征。
后續(xù)將進(jìn)一步劃分腦區(qū)作繼續(xù)研究,由腦功能連接矩陣圖可以看出,兩組都有較為明顯的腦區(qū),單獨從腦區(qū)進(jìn)行分析,提取特征參數(shù),將進(jìn)一步提高計算機輔助診斷的可行性。
猜你喜歡
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2022年11期)2022-02-14 07:14:12
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
科普童話·學(xué)霸日記(2020年1期)2020-05-08 16:45:11
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
小天使·一年級語數(shù)英綜合(2019年2期)2019-01-10 11:57:30
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
兒童繪本(2018年5期)2018-04-12 16:45:32
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
