基于優化非線性自回歸神經網絡模型的水質預測
2022-06-25 01:24:32唐亦舜劉振鴻
東華大學學報(自然科學版) 2022年3期
唐亦舜, 徐 慶, 劉振鴻, 高 品
(1.東華大學 環境科學與工程學院, 上海 201620; 2.上海市環境監測中心, 上海 200235)
因化學品泄露等原因引發的水質污染事件頻發[1-3],造成嚴重的環境污染和社會影響。水質預測已成為環境監測領域的關注焦點,對地表水環境進行有效管理是至關重要的[4]。河流水質預測是區域水環境管理的基礎[5],通過對一定區域的河流水質參數變化情況進行實時監測,結合當地水質狀況、生態環境狀況、污染物遷移特性和經濟發展等實際情況預測未來水質變化趨勢[6]。盡管如此,水質預測研究仍處于發展階段[7],如何有效利用現有龐大的在線監測數據提高水質預測精度,是構建水質預測模型亟需解決的關鍵問題。
隨著人工智能技術的迅速發展,人工神經網絡(artificial neural network, ANN)因其優異的非線性關系處理能力、較高的預測準確度和較強的復雜水質適應性等,成為國內外水質預測模型的熱點研究方法[8-9]。其中,非線性自回歸(nonlinear auto-regressive, NAR)神經網絡具有反饋與記憶功能,以自身為回歸變量,每一時刻的輸出都是當下時刻之前系統內隨機變量的線性組合,具有動態性與綜合性特征[10-11],在時間序列動態建模預測方面具有明顯優勢。雖然NAR神經網絡已被廣泛應用于交通運輸[12-13]、空氣質量[14]、社會經濟[15-16]等領域,但在水質預測方面的應用研究還較少。本文以上海市某支流具有代表性的監測斷面為研究對象,通過試驗法優化確定輸入數據段和模型參數,采用不同指標對模型預測性能和預測效果進行對比評價以改進NAR神經網絡模型,并將改進的NAR神經網絡模型用于預測pH、溶解氧(dissolved oxygen, DO)質量濃度和濁度等水質指標,以期為水質的預測預警提供技術支撐。
1 研究方法
1.1 NAR神經網絡
NAR神經網絡屬于處理時間序列的動態神經網絡模型,其每一個時刻的輸出都是先前全部輸入的綜合描述,可通過輸入/輸出關系進行不斷調整,具有反饋記憶功能和動態綜合性特征。NAR神經網絡模型一般由輸入層、帶有延遲的隱含層和輸出層構成,如圖1所示,輸入層時間序列y(t)進入帶有延遲的隱含層,隱含層為一層或多層的神經元,經訓練、傳遞和學習后,最終到達輸出層,并傳遞模型結果[10]。
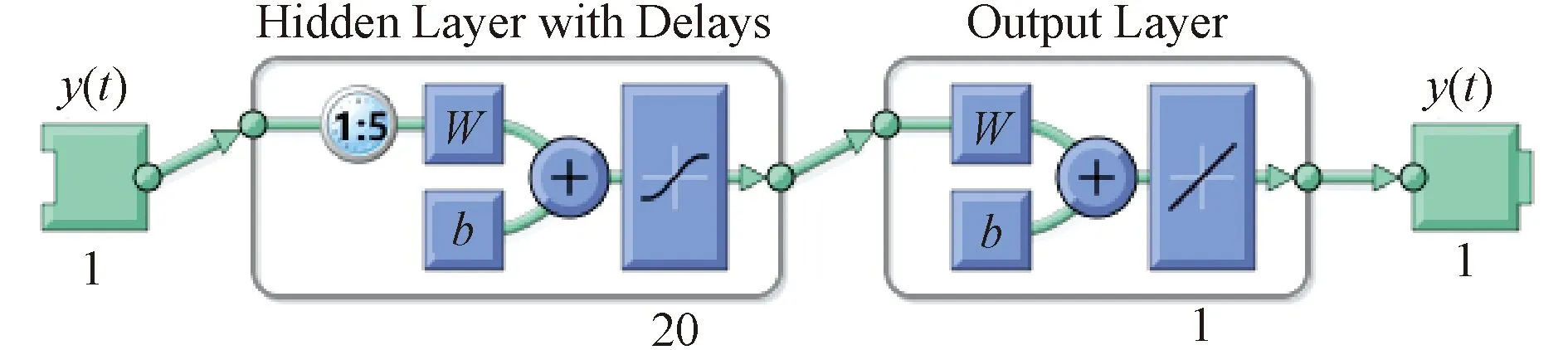
注:1∶5表示延遲階數為5;20為隱含層神經元數; W為權值;b為閾值。圖1 NAR神經網絡結構Fig.1 Structure of NAR neural network
對于時間序列{y(t)},t=1,2,3,…,n,NAR神經網絡模型表達式如式(1)所示。
y(t)=f(y(t-1),y(t-2),y(t-3),…,
y(t-n))+ε(t)
(1)
式中:n為輸入延遲階數;f(·)為傳遞函數,神經網絡訓練的目的是通過優化網絡權值和神經元偏置進行函數估計;ε(t)為y(t)的擾動項,屬隨機白噪聲,但其與前一時刻時間序列y(t-1)無關[17-18]。
1.2 數據來源與預處理
1.2.1 數據來源
本文研究數據源于上海市某支流具有代表性的監測斷面的水質監測結果,選取2019年1月1日—12月1日的水質監測數據,水質指標包括pH、DO質量濃度和濁度。由于原始數據監測頻率存在差異,本文統一以4 h間隔對原始數據進行篩選,每天共6組數據。
1.2.2 缺失數據填補
針對前后時間間隔較小的缺失數據,考慮到DO質量濃度具有周期性變化特點,選用前1 d同一時刻與其前后時間點的3組數據平均值進行填補,即若缺失數據為第i點,其替代值可通過式(2)獲得。此外,針對時間間隔較大的缺失數據,則采用天氣狀況相似的臨近日期的同一時刻數據進行補全。
(2)
1.2.3 異常數據剔除
通常異常數據主要由過失誤差所導致。過失誤差是指由非隨機事件如工藝泄漏、測量儀表失靈、設備故障等引發的測量數據嚴重失真導致數據真實值與實測值之間出現的顯著差異。一般根據拉依達準則剔除異常數據。


圖2 剔除異常數據前后的pH和濁度Fig.2 pH and turbidity before and after abnormal data removal
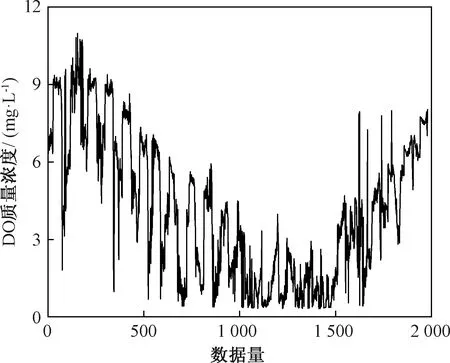
圖3 DO質量濃度變化趨勢Fig.3 Variation trend of DO mass concentration
1.2.4 數據歸一化處理
將有量綱表達式轉化為無量綱表達式,通常需對輸入數據作歸一化處理。本文采用最大最小值法進行數據歸一化,將原始數據線性化轉換到[0,1],歸一化方法如式(3)所示。
(3)

1.3 神經網絡設計
采用試驗法確定NAR神經網絡模型的延遲階數和隱含層神經元數,輸入樣本數據對模型進行訓練并進行誤差計算和模型檢驗,通過調整網絡結構獲得最佳預測模型。
1.3.1 試驗法
試驗法即根據經驗對某一輸入參數設置不同值進行多次模擬預測,通過比較分析預測結果選擇最優結果對應的輸入值作為該參數的初始輸入值。
1.3.2 模型評價指標
采用相關系數r、納什效率系數(Nash-Sutcliffe efficiency coefficient, NSE)、均方根誤差(root mean squared error, RMSE)和平均絕對百分比誤差(mean absolute percentage error, MAPE)評價模型預測性能。
r用于評價變量之間的相關程度,對于兩組變量X和Y,其定義式如式(4)所示。
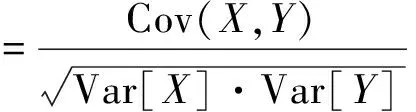
(4)
式中:Cov(X,Y)為X與Y的協方差;Var[X]和Var[Y]分別為X和Y的方差;|r|≤1,|r|越大,X和Y之間相關性越強。
NSE用于評價模型預測效果,表達式如式(5)[19]所示。
(5)

RMSE用于衡量模型預測值與實測值之間的偏差,表達式如式(6)所示。
(6)
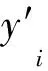
MAPE是平均絕對偏差(mean absolute deviation, MAD)的變形,其消除了原始數據絕對大小對MAD的影響,是衡量模型預測準確性的統計指標,計算公式如式(7)所示。
(7)
式中:EMAPE∈[0,+∞),EMAPE>100%表明預測模型為劣質模型。若存在真實值為0的數據,則該式不再適用,因此在計算EMAPE時需先對原始數據進行反歸一化處理。
1.3.3 檢驗方法
采用Ljung-Box Q-test(LBQ)法檢驗某一時段內時間序列預測值是否為隨機獨立值,若預測值不是彼此獨立的,則多個預測值之間存在關聯性,這將使得整體時間序列具有自相關性。通常這種自相關性會降低基于時間序列模型的預測準確度,并導致模型對數據的錯誤解釋,故采用LBQ法評估NAR神經網絡模型的擬合結果,以確保預測殘差彼此獨立[10]。LBQ檢驗的統計結果計算方法如式(8)所示。
(8)

1.3.4 輸入數據段選取
神經網絡輸入時間序列的波動程度、時間跨度、完整性等對其輸出的影響非常大,訓練數據不足造成機器學習不充分導致欠擬合,但過量的樣本輸入則會使模型陷入過分學習,在影響學習效率的同時還會導致過擬合,降低模型預測精度。本文以2019年11月30日監測數據為樣本終點,分別以11月16日、11月1日、10月16日、10月1日、9月16日和9月1日的監測數據為樣本起點,對應的樣本量分別為90、180、270、360、450和540,以不同數據段預測12月1日的相應指標值,以各評價指標與檢驗結果為依據對比模型整體性能和預測精度,進而確定輸入數據段。為方便計算,對12月1日的預測值進行反歸一化處理。
設置訓練集、驗證集和測試集的比例為70%、15%和15%,延遲階數為2,隱含層神經元數為10,訓練次數為10,優化選取數據段。圖4 和表1為pH、DO質量濃度和濁度的預測結果,采用LBQ法進行統計檢驗,可得邏輯值h、概率值p、檢驗統計量s和臨界值c,其中:h=0表示拒絕原假設,即殘差序列無自相關性,h=1表示存在自相關性;p越小、s越大,表明自相關性越強。檢驗結果見表2。

圖4 不同輸入數據量下pH、DO質量濃度和濁度的ERMSE和EMAPEFig.4 ERMSE and EMAPE for pH, DO mass concentration and turbidity with different input data volumes
由圖4、表1和表2可知,選取2019年11月1日—11月30日時間序列共180個數據點進行模型訓練時,模型對pH、DO質量濃度和濁度的預測效果最好,預測RMSE值分別為0.054、0.424 mg/L和20.960 NTU,MAPE值分別為0.58%、4.83%和20.33%。LBQ檢驗結果表明,在最佳數據段下只有濁度預測殘差仍具有自相關性,可通過調整模型參數對模型進行優化,進一步提高預測精度。

表1 不同輸入數據量下pH、DO質量濃度和濁度的r和ENSETable 1 Results of r and ENSE for pH, DO mass concentration and turbidity with different input data volumes
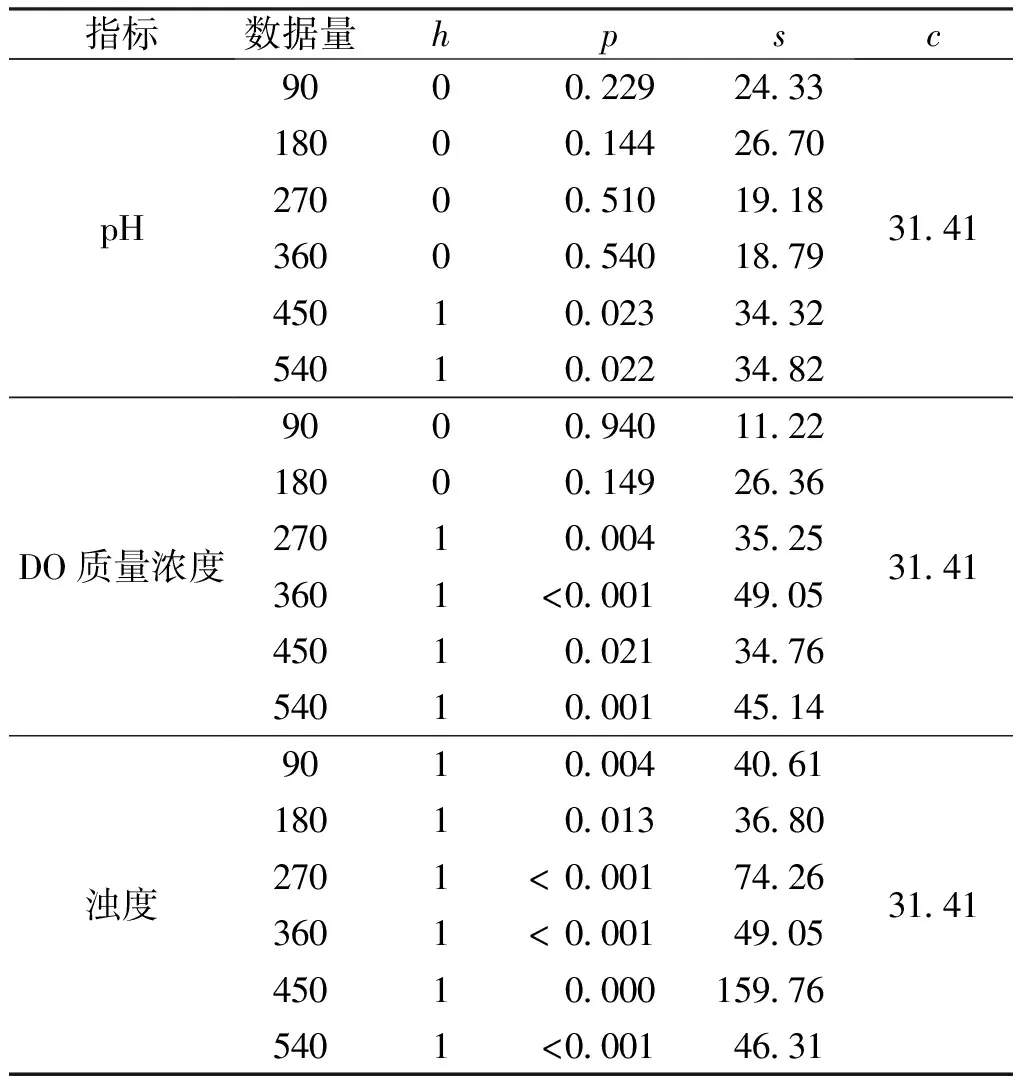
表2 不同輸入數據量下pH、DO質量濃度和濁度預測值的LBQ檢驗結果
1.3.5 模型參數確定
NAR神經網絡延遲階數和隱含層神經元數的選取尚無成熟的理論依據,通常只能根據經驗或試驗來確定[20-21]。
(1)延遲階數。選定輸入時間序列為2019年11月1日—11月30日的監測數據,保持訓練集、驗證集和測試集不變,隱含層神經元數為10,訓練次數為10,調整延遲階數,對比分析不同延遲階數下pH、DO質量濃度和濁度預測性能及檢驗結果,如圖5、表3~6所示。
從圖5、表3和表4可以看出,由于原始數據的差異,pH、DO質量濃度和濁度預測模型的最佳延遲階數分別為2、3和9,在最佳延遲階數下,預測模型對pH、DO質量濃度和濁度的預測精度均得到提高,其中濁度的預測RMSE值從20.960 NTU降至17.940 NTU。由表5可知,pH和DO質量濃度預測結果均通過LBQ檢驗,而濁度預測模型較調整延遲階數前可消除預測殘差時間序列的顯著自相關性(見表6),使得預測結果從不可接受變為可接受。

表3 不同延遲階數下pH和DO質量濃度的r和ENSETable 3 Results of r and ENSE for pH and DO mass concentration with different delay orders

表4 不同延遲階數下濁度的r和ENSETable 4 Results of r and ENSE for turbidity with different delay orders
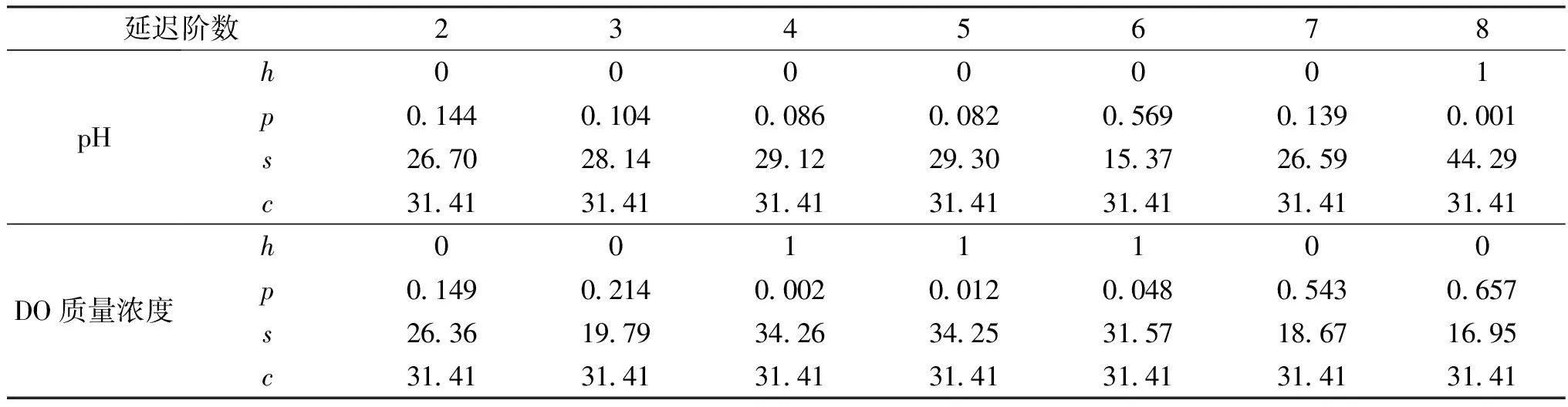
表5 不同延遲階數下pH和DO質量濃度預測值的LBQ檢驗結果Table 5 LBQ test results of pH and DO mass concentration with different delay orders

表6 不同延遲階數下濁度預測值的LBQ檢驗結果Table 6 LBQ test results of turbidity with different delay orders
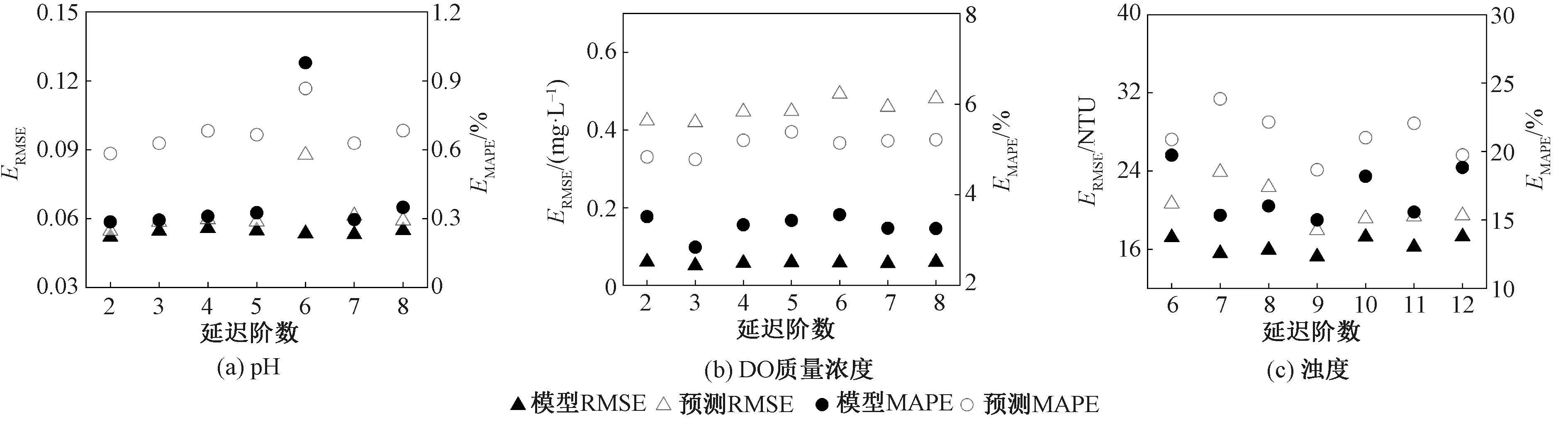
圖5 不同延遲階數下pH、DO質量濃度和濁度的ERMSE和EMAPEFig.5 ERMSE and EMAPE for pH, DO mass concentration and turbidity with different delay orders
(2)隱含層神經元數。采用相同訓練數據集,選取pH、DO質量濃度和濁度預測模型的延遲階數分別為2、3和9,通過調整隱含層神經元數,重復上述預測步驟,對比分析pH、DO質量濃度和濁度預測性能及檢驗結果,確定最佳隱含層神經元數,如圖6和表7所示。
從圖6和表7可以看出,pH、DO質量濃度和濁度的預測RMSE和MAPE值均先減小后增大,而r和NSE值則相反,在模型隱含層神經元數為10時,預測RMSE、MAPE、r和NSE值幾乎均達到極值,且預測殘差也均通過LBQ檢驗(見表8),隱含層神經元數過低,易出現擬合不足和容錯性差等問題,但數量過多同樣會造成過擬合現象,并顯著增加模型迭代次數和訓練時間。
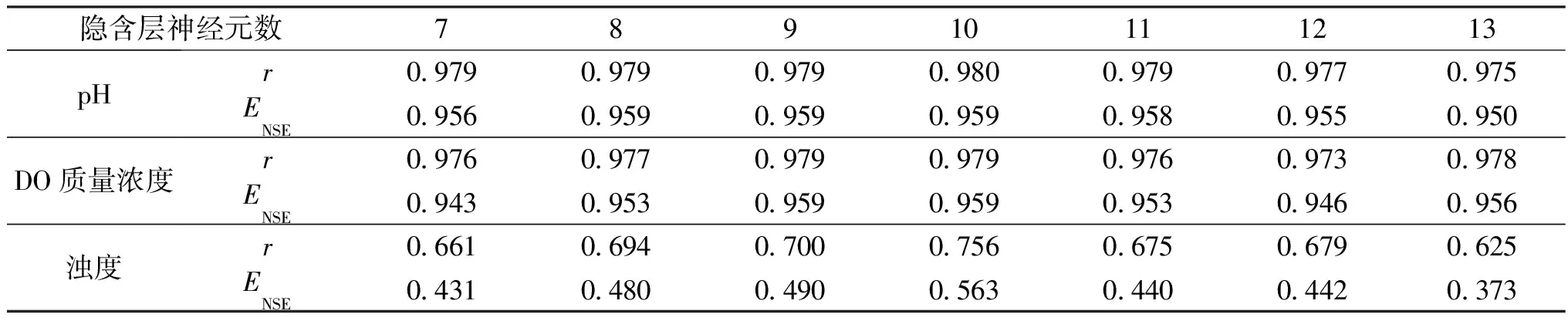
表7 不同隱含層神經元數下pH、DO質量濃度和濁度的r和ENSETable 7 Results of r and ENSE for pH, DO mass concentration and turbidity with different numbers of hidden layer neuron

表8 不同隱含層神經元數下pH、DO質量濃度和濁度預測值的LBQ檢驗結果Table 8 LBQ test results of pH, DO mass concentration and turbidity with different numbers of hidden layer neuron

圖6 不同隱含層神經元數下pH、DO質量濃度和濁度的ERMSE和EMAPEFig.6 ERMSE and EMAPE for pH, DO mass concentration and turbidity with different numbers of hidden layer neuron
2 模型預測結果分析
2.1 模型構建
基于上述優化結果,確定pH、DO質量濃度和濁度預測模型結構參數如下:各指標預測模型輸入樣本時間序列均為2019年11月1日—11月30日,訓練集、測試集和驗證集分別占70%、15%和15%,pH、DO質量濃度和濁度預測模型的延遲階數分別為2、3和9,隱含層神經元數均為10。采用Levenberg-Marquardt(L-M)算法訓練網絡模型,訓練函數為trainlm,傳遞函數為tansig,權值自適應學習函數為learngd。
2.2 預測結果與誤差分析
為評價模型預測效果和實際應用效果,以目標監測斷面2019年11月2日—12月1日監測數據為訓練樣本,預測12月2日pH、DO質量濃度和濁度。由于輸入權值和閾值會影響神經網絡性能,因此各模型在表4模型結構參數下訓練20次,預測結果如圖7所示,同時對比分析6個預測點的RMSE與MAPE值(見表9)。
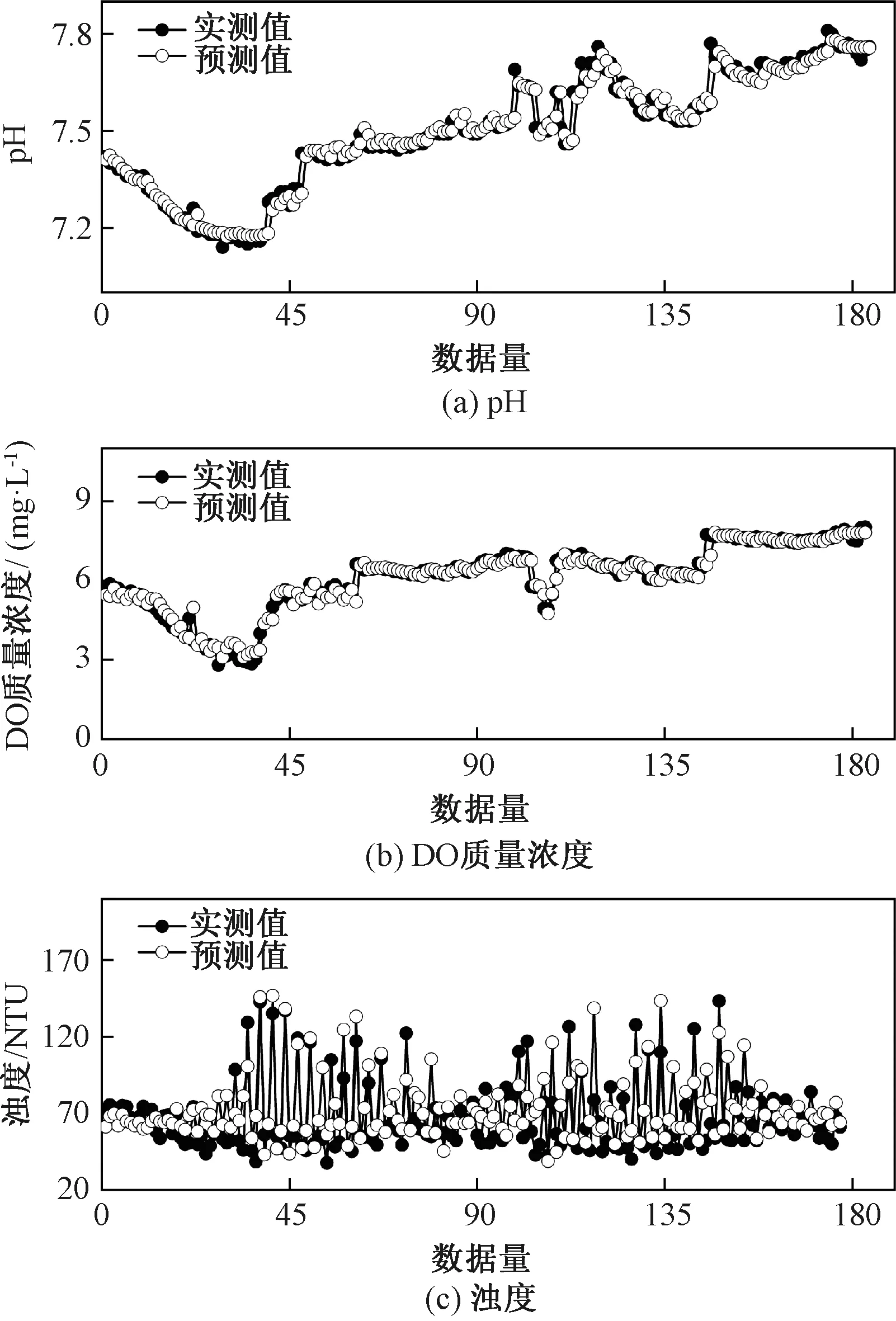
圖7 預測模型對pH、DO質量濃度和濁度的預測效果Fig.7 Model prediction performance of pH, DO mass concentration and turbidity
由圖7和表9可以看出,基于L-M算法建立的NAR神經網絡模型對目標斷面pH、DO質量濃度和濁度的預測值與實測值的變化趨勢基本一致。結合RMSE值和MAPE值可知:輸入數據段經優化選取和結構參數調整后,NAR神經網絡模型的預測精度和自相關檢驗通過率均得到顯著改善;各時間序列預測結果出現的差異主要是由原始時間序列波動和量級的影響所致。由實測結果可知,目標斷面pH值在7.13~7.82波動,而DO質量濃度雖出現驟變情況,但驟變前后兩個點的值很接近。相比之下,濁度易受往來船只和天氣等因素的影響,即使剔除了異常數據,其數據波動(40~150 NTU)仍較大。由此可見,數據波動可能是造成pH、DO質量濃度和濁度預測結果具有差異性的主要原因。
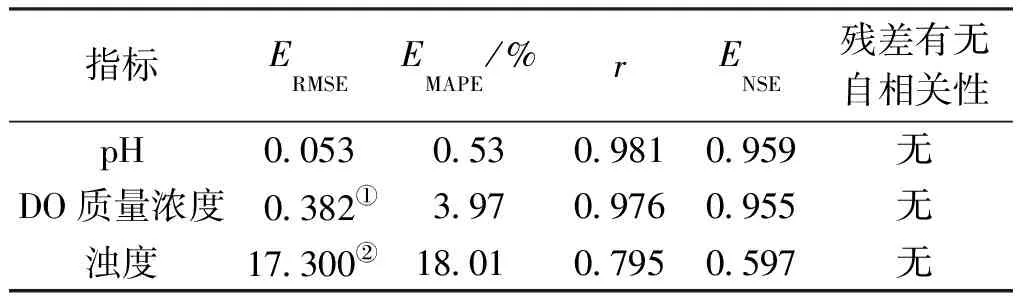
表9 預測效果評價Table 9 Evaluation of the prediction effect
3 結 論
(1)通過調整輸入數據量、延遲階數和隱含層神經元數優化NAR神經網絡模型,當輸入數據量為180,模型參數延遲階數分別為2、3和9,隱含層神經元數為10時,模型對pH、DO質量濃度和濁度的預測效果最好。
(2)在最優參數設置條件下,NAR神經網絡模型對pH、DO質量濃度和濁度的預測均方根誤差分別為0.053、0.382 mg/L和17.300 NTU,平均絕對百分比誤差分別為0.53%、3.97%和18.01%,模型對pH和DO質量濃度的預測精度優于濁度。
(3)針對地表水環境系統復雜且完全非線性的特點,NAR神經網絡模型具有很強的非線性映射能力和靈活的網絡結構,預測精度較高,在水質預測預警和評價方面具有較好的應用價值。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
環境(2023年5期)2023-06-30 01:20:01
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
中學生數理化·中考版(2020年10期)2020-11-27 01:59:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中國生殖健康(2019年2期)2019-08-23 08:12:08
當代水產(2019年1期)2019-05-16 02:42:04
光學精密工程(2016年6期)2016-11-07 09:07:19
汽車觀察(2016年3期)2016-02-28 13:16:26
