基于自適應指數蝙蝠和SAE的并行大數據分類①
2022-06-28 10:06:28錢真坤周思吉
西南師范大學學報(自然科學版) 2022年6期
錢真坤, 周思吉
1.四川文理學院 后勤服務處,四川 達州 635000; 2.四川文理學院 信息化建設與服務中心,四川 達州 635000
在信息技術高速發展的社會,數據正以前所未有的速度增長[1-2],大數據作為一種新的戰略資源正在推動創新,改變不同領域的研究以及人們的生活、思維方式[3-4].分布式計算是一種大數據策略,常用的大數據框架之一是Hadoop,在Hadoop分布式文件系統(Hadoop Distributed File System,HDFS)上實現MapReduce并行計算[5-6].Apache Spark是另外一個常用的并行計算框架,Spark基于MapReduce算法實現分布式計算,與Hadoop 框架的不同之處是: Job中間輸出和結果可以保存在內存中,因此不需要讀寫HDFS,Spark的核心依然是MapReduce.Spark對于數據挖掘與機器學習等需要迭代的算法更友好,適應性更強[7-8].MapReduce由兩個階段組成: Map和Reduce,Map階段處理輸入的數據拆分,生成不同的鍵值對,Reduce階段按鍵匯總在映射階段獲得的結果[9].
大數據分類研究已經應用到各個行業,如金融、醫療、工業等.文獻[10]針對大數據分類中的噪聲問題,提出兩種消除噪聲樣本的大數據預處理方法: 同質集合和異類集合過濾器,通過對大數據中噪聲的處理得到高質量和干凈的數據.文獻[11]提出一種Spark框架下K最鄰近(KNN)分類器的網絡大數據分類處理方法,該方法通過Map階段分區K近鄰操作,并通過Reduce階段確定最終K近鄰,同時對近鄰的標簽集合進行聚合,得出分類結果,但是該方法分類準確度較低.文獻[12]提出了物聯網大數據的隨機森林分類方法,并根據蜻蜓優化選取特征對電子醫療數據進行分類,但該方法僅考慮了目標和當前特征變量的數據.文獻[13]設計了一種線性支持向量機大數據分類方法,相較于傳統支持向量機,該方法在訓練速度和分類精度上具有明顯的優勢,但用于更大數據集時會影響性能.文獻[14]提出了蟻群優化-人工神經網絡聯合算法,該算法使用了深度人工神經網絡,并進行了蟻群優化,提升了分類準確度.文獻[15]使用蝙蝠算法優化人工神經網絡,提高了分類準確率.
本文在研究了大數據處理框架和現有大數據分類方法的基礎上,提出了基于自適應指數蝙蝠和堆疊自編碼器(Stacked AutoEncoder,SAE)的并行大數據分類方法,該方法根據大數據分類方法的MapReduce并行實現,設計了基于自適應指數蝙蝠算法.在Map階段進行特征選擇,在Reduce階段,使用AEB訓練的深度堆疊自動編碼器分類,得到分類結果.實驗結果表明,該方法能夠實現較高精度的大數據分類.
1 分布式處理框架
MapReduce是一個編程范例,用于在分布式環境中處理大數據集,MapReduce框架為大數據提供了一個可擴展的容錯環境.在MapReduce范例中,Map階段執行過濾和排序,Reduce階段執行分組和聚合操作.
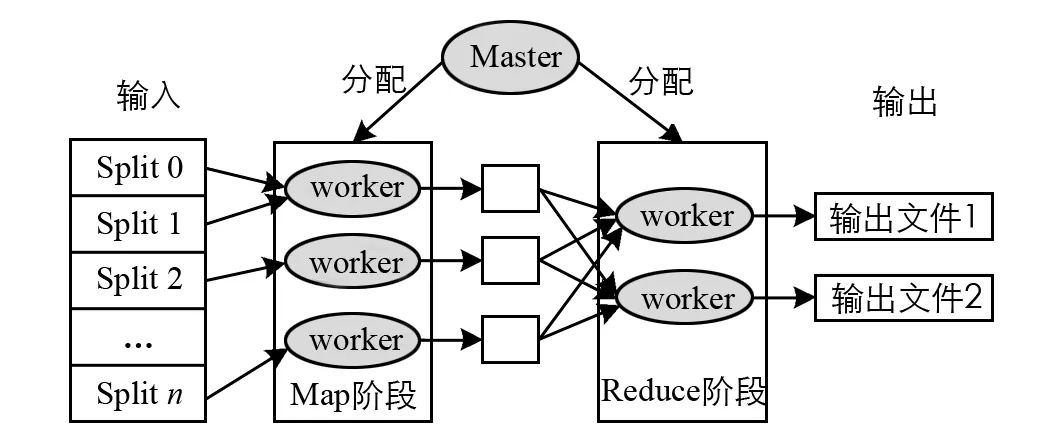
圖1 MapReduce框架
圖1給出了MapReduce框架流程.一個節點被選為負責分配工作的Master,其余的都是Worker,輸入數據分為多個Split,Master設備分配給Map Worker.每個Worker處理相應的輸入Split,生成<鍵/值>對并將其寫入中間文件(在磁盤或內存中).Master通知Reduce階段Worker關于中間文件的位置和讀取數據,根據Reduce階段處理它.最后,將數據寫入輸出文件.
MapReduce范例的主要貢獻是可擴展性,因為MapReduce允許在大量節點上進行高度并行化和分布式執行任務.在MapReduce范例中,Map或Reduce任務分成多個作業,這些作業被分配給網絡中的節點,通過將任何失敗節點的作業重新分配到另一個節點來實現可靠性.開源MapReduce在Hadoop分布式文件系統(HDFS)之上實現.
Hadoop MapReduce的主要優點之一是允許非專家用戶輕松地對大數據運行分析任務.Hadoop MapReduce使用戶可以完全控制輸入數據集的處理方式,用戶使用Java編寫查詢代碼,便于多數沒有數據庫背景,只需具備Java基礎知識的開發人員使用.
2 基于自適應指數蝙蝠和SAE的并行大數據分類
本文基于自適應指數蝙蝠和SAE的并行大數據分類方法,Map階段使用AEB算法從數據庫中選擇特征.然后,將選定的特征提供給Reduce進行大數據分類,Reduce階段使用深度堆疊自動編碼器進行大數據分類,該編碼器由AEB算法選擇特征訓練而成.圖2給出了基于AEB堆疊自動編碼器算法進行大數據分類的框圖.

圖2 自適應深度堆疊自動編碼器大數據分類
將輸入的大數據集合視為H,并將多個屬性表示為H=xnm,1≤m≤G,1≤n≤q.其中,xnm表示第m個數據的第n個屬性的大數據,所有數據均由G個數據點和q個屬性組成.
2.1 Map階段
特征提取是Map階段的重要功能,其中選擇相關特征通過減小維度來最大程度地提高分類精度.Map階段使用AEB算法選擇特征.

(1)

(2)
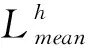
(3)
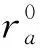
(4)
指數加權移動平均值(EWMA)是平均數據的過程,以獲得較少的權重隨時間而被刪除的數據,可表示為:
(5)
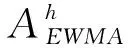
(6)
AEB算法是通過引入自適應速度的概念而得到的,蝙蝠個體繼承上一代的速度,并獲得最佳個體飛行,當算法進行到后期時,大多數蝙蝠個體都會陷入局部優化,而蝙蝠的速度無法使其逃脫局部優化,為了解決這個問題,本文提出了自適應蝙蝠速度算法. 該算法基于每個蝙蝠的適應度(距離越近適應的最佳距離值越高,距離越遠值越低),給其速度加上權重,如果個體比其他個體更接近最優解,則其適應價值更高,此時迅速放慢個體速度,使個體收斂到最優解,在這種情況下給出較小的權重值.相反,如果個體的適應價值非常低,則意味著個體距離最佳解決方案還很遠,需要給它更大的權重值.權重計算方法設計為:
(7)
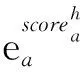
(8)
大數據被分為數據子集,表示為xnm={qe},1≤e≤F,數據子集的總數等于Map階段中的映射器數量,表示為D={D1,…,DF},其中F是從大數據開發的總子集數.Map的輸入由E個總屬性組成,表示為:
qe={Sj,q},1≤j≤M,1≤q≤E
(9)
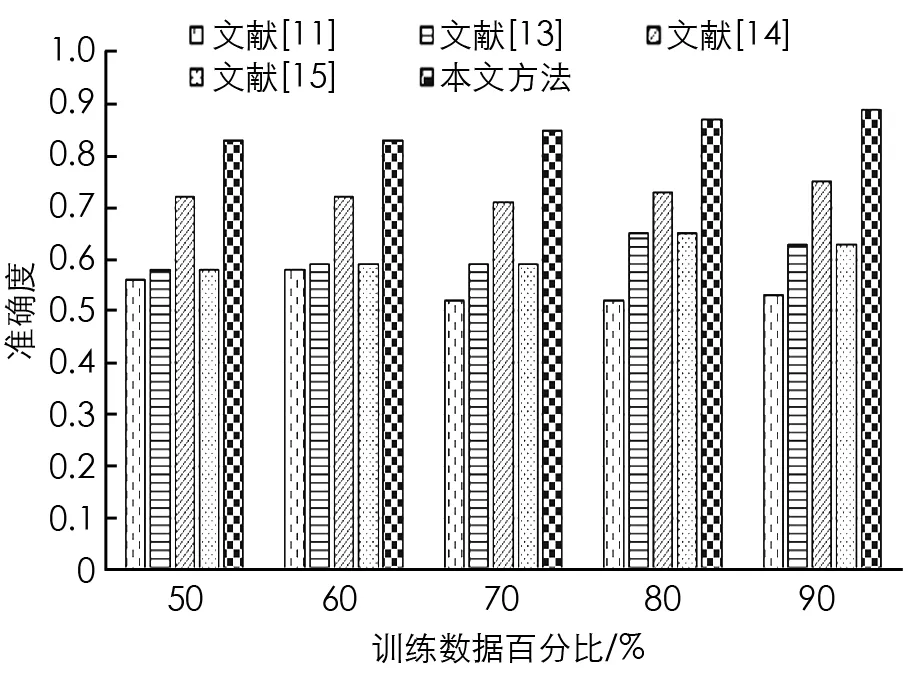
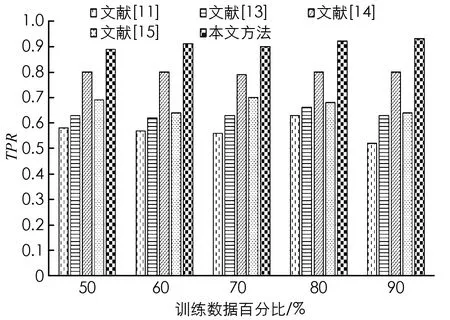
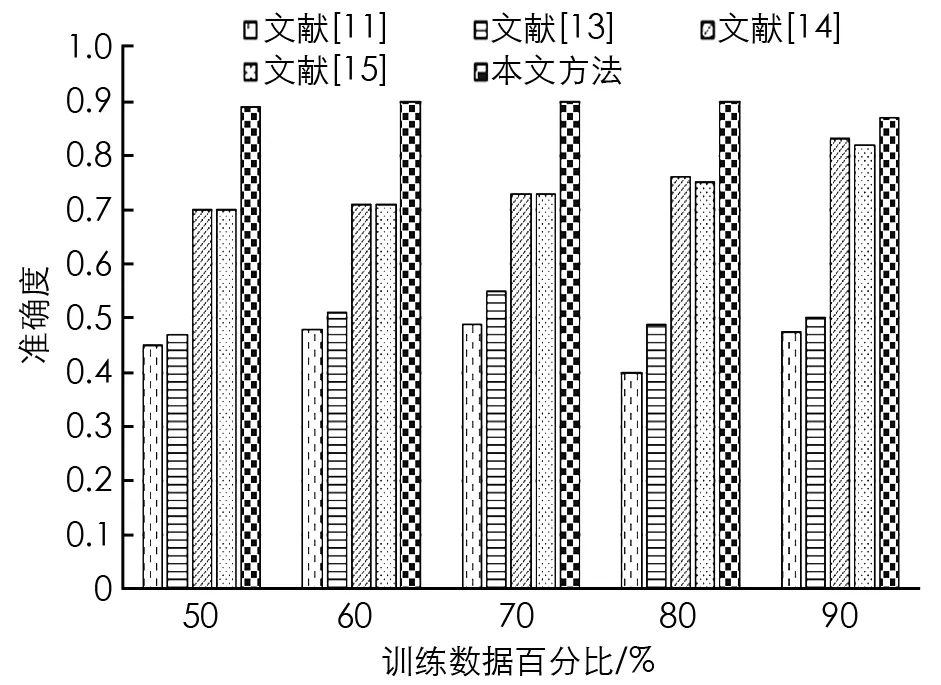
其中,M u={u1,u2,…,ub,…,ul} (10) 其中,選擇特征的總數表示為l.解向量是特征尺寸為[1×l]的向量. 在MapReduce處理框架中,首先對大數據集進行不同子集的劃分,每個子集對應不同的Split,然后在Map進行特征選擇,輸出鍵值對為<分類準確率,特征>,對所有分類準確率進行排序,選擇最大的分類準確率,其對應的特征即為最終特征,所有特征以集合形式輸入Reduce階段. 在Map階段將獲得的AEB算法用于從數據庫中選擇特征.并且在Reduce階段使用的深度堆疊自動編碼器由AEB訓練而成. 圖3 深度堆疊自動編碼器網絡體系結構 使用最常用的深度學習方法深度堆疊自動編碼器對Map中選定的特征進行分類,深度堆疊自動編碼器是一個對稱的神經網絡,用于無人監督方式學習數據集的特征,分為3層: 輸入層、隱藏層和輸出層.輸入層完全連接到隱藏層,隱藏層進一步連接到輸出層,如圖3所示. (11) (12) 其中,W1是編碼權向量,b1是編碼偏置向量,W2是解碼權向量,b2是解碼偏置向量.f(·)和g(·)表示非線性的輸入和輸出映射函數,采用Sigmoid函數可表示為f(x)=1/[1+exp(-x)].深度自動編碼器為了使隱藏層稀疏,使用稀疏約束最小化重構誤差,這種架構被稱為稀疏自編碼器. (13) (14) 多層自動編碼器是多個自動編碼器的串聯,是將連續層輸入與堆疊在該層上的自動編碼器輸出連接的過程.對于第p層,激活輸出為: (15) (16) 深層自動編碼器包含3個過程.①初始化成本函數局部最小值附近的各個自動編碼器參數.②學習到下一個自動編碼器隱藏層的輸入.③執行反向傳播進行微調,通過同時更改所有模型參數,可以改善整體分類性能. 將本文所提AEB堆疊自動編碼器的大數據分類方法進行實驗,并通過現有方法對本文方法進行比較分析,以證明本文方法的有效性.本文所有實驗在Windows 10操作系統的電腦中運行.MapReduce實驗環境由6臺集群結點組成,選取1臺作為主節點,另外5臺作為從節點,每個節點的配置如下: Intel Core i5-8GB,RAM為64 G,硬盤容量為1 T,軟件配置為CentOS 6.5,Hadoop版本為5.4.5,6個節點都連接在100 Mb的交換機上. 本文采用準確度(Accuracy)和真正例率(TPR)這兩個指標評估模型的性能,數學定義為: (18) (19) 當一個樣本為正類,且被預測為正類時,稱為真正類(TP); 假若負類被預測為正類,稱為假正類(FP); 假若是負類被預測成負類,稱為真負類(TN); 假若正類被預測為負類,稱為假負類(FN). 本文使用的兩個標準數據集分別是加州大學歐文分校(UCI)機器存儲庫中Cleveland數據集和Pima India數據集.對比算法有: 文獻[11]中的KNN大數據分類方法,文獻[13]中SVM分類方法,文獻[14]中蟻群優化-人工神經網絡聯合算法以及文獻[15]中蝙蝠算法+人工神經網絡.對比實驗通過改變組合數據集中訓練數據的百分比來對不同方法進行分析.經過多次實驗,本文對于自適應蝙蝠算法的參數設置為: 種群200,迭代次數70,初始發射速率0.95,響度衰減系數0.95,頻度增加系數0.5. 圖4和圖5給出了Cleveland數據集中不同訓練數據在百分比條件下準確度和TPR的對比結果. 圖4 Cleveland數據集的準確度對比結果 圖5 Cleveland數據集的TPR對比結果 從圖4和圖5中的對比數據可以看出,在Cleveland數據集上針對不同訓練數據百分比,本文所提算法的準確度都優于其他4種方法.在訓練數據百分比為90%時,本文所提算法具有最高的準確度,達到0.887 5,這是因為本文所提算法設計了自適應指數蝙蝠算法來選擇最優特征,增加了分類準確度,同時深度堆疊自動編碼器通過AEB訓練得到的分類結果更加準確.文獻[14]中蟻群優化-人工神經網絡聯合算法準確度次之,這是因為使用了深度人工神經網絡,并進行了蟻群優化,提升了分類準確度.文獻[15]中蝙蝠算法+人工神經網絡算法使用了蝙蝠算法優化人工神經網絡,但是由于蝙蝠算法的局限性,導致其分類準確度與SVM分類性能接近.在Cleveland數據集上,針對不同訓練數據百分比,本文所提算法的TPR都優于其他4種方法,在訓練數據百分比為90%時,本文所提算法具有最高的真正例率,達到0.928 9.這是因為本文AEB+堆疊自動編碼器對分類性能的提升. 圖6和圖7給出了Pima India數據集上不同訓練數據在百分比條件下準確度和TPR的對比結果. 圖6 Pima India數據集的準確度對比結果 圖7 Pima India數據集的TPR對比結果 圖8 Higgs大數據集的準確度對比結果 從圖6和圖7中數據可以看出,當訓練數據百分比達到80%時,Pima India數據集上本文所提算法的準確度最高; 當訓練數據百分比達到90%時,TPR最高.而且,在所有不同訓練數據百分比條件下,本文所提算法的性能都比其他算法高,說明了本文方法的有效性. 為了驗證本文方法在大數據集上的優越性能,在Higgs大數據集上給出性能對比結果.Higgs大數據集樣本數量為11 000 000,特征向量28,標簽數量42. 從圖8中可以看出,本文方法在Higgs大數據集上的準確度能夠達到0.83,比文獻[14]算法準確度提高了0.11.針對不同的大數據集,本文所提方法能夠以高精度實現大數據分類,且分類性能優于其他方法,說明了本文方法的普適性和優越性. 針對大數據分類性能低的問題,本文提出一種自適應指數蝙蝠和SAE的并行大數據分類方法,該方法在Map階段使用設計的自適應指數蝙蝠算法進行特征選擇; 在Reduce階段使用經過AEB算法訓練的深度堆疊自動編碼器進行分類,進一步提升了分類性能.使用不同的實驗數據集對本文所提方法進行實驗,不同百分比條件下的分類性能結果顯示,本文所提方法能夠以高精度實現大數據分類,且在準確度和TPR性能方面都優于現有其他方法,說明本文方法的有效性和優越性.未來的工作將通過擴展本文所提出的方法來處理安全約束.2.2 Reduce階段

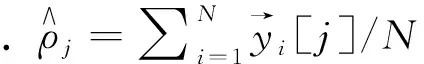
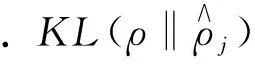
3 實驗分析


4 結論
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
