多主體機器人路徑規劃方法研究
2022-06-28 17:46:24祝晨旭仲志丹張浩博喬棟豪
制造業自動化 2022年6期
祝晨旭,仲志丹,張浩博,喬棟豪
(河南科技大學 機電工程學院,洛陽 471003)
0 引言
機器人路徑規劃是指在機器人工作環境中,為指定目標的移動機器人規劃出無碰撞、高效率的最佳路徑。隨著移動機器人的廣泛應用,導航場景由最簡單的預設軌道的導航[1,2],擴展到躲避靜態障礙、動態障礙和動態靜態障礙混合的復雜場景。得益于傳感器技術的提升,移動機器人獲取環境信息的能力增強,移動機器人的路徑規劃方法也演變成了更加強大的基于學習的算法[3~5]。
常見的移動機器人有各個品牌的掃地機器人,它們的路徑規劃分為兩個部分,全局路徑規劃和局部路徑規劃。掃地機器人的全局路徑規劃屬于遍歷式的路徑規劃,這取決于它們的工作性質。全局路徑規劃通過雷達掃描環境完成地圖創建,基于地圖信息完成清掃路徑的規劃;局部路徑規劃適用于處理突發情況,躲避地圖信息上未顯示的特殊障礙,例如人。一旦出現突發情況,要結合全局規劃重置全局路線繞過特殊障礙。在掃地機器人的工作環境中,對出現特殊障礙的問題處理的時效性要求不高。
相對于掃地機器人,在多主體環境中運動的移動機器人需要的不僅是將其他主體視為動態障礙,還要對其他主體的移動趨勢進行判斷,以此來做為決定自身下一步運動規劃的重要條件。在較為簡單的情況下,其他主體的移動趨勢為靜止或者勻速運動,易于觀測與判斷,Chen Y F[6]提出短時間內將其他主體看作明確的勻速運動模型來簡化方法設計。但是在多數情況下,即便了解其他主體的目的地,在轉向角度等內部因素未知,尤其是其他主體為人的情況下,其他主體的移動趨勢就變得難以捉摸,這是常規的運動規劃處理不好的。為了應對這樣的工作環境,Long P[7]等不再試圖明確其他主體的動作,而是使用深度強化學習直接對移動機器人與環境的交互建模完成路徑規劃。
多主體機器人運動規劃還需要解決另一個關鍵問題:環境中其他主體的數量是變化著的,深度強化學習網絡需要固定維度的輸入,Cho K[8,9]等定義網絡所能觀測到的主體的最大數量,使用LSTM(long-short term memory)神經元,接收不同長度的輸入信息,輸出固定維度的向量,輸入信息在輸出中所占比重與時序相關,距離主體機器人越近,信息所占比重越大。這使得規劃方法能夠基于任意數量的其他主體做出決策。
1 基于深度強化學習的避障
延續之前方法[10]的常規設定,使用st表示主體機器人的狀態,ut表示它的動作,用表示其他主體的狀態。狀態由可觀測和不可觀測兩部分組成,可觀測部分s0包含主體的位置p,速度v,和半徑r,s0=[px,py,vx,vy,r],不可觀測部分sh包含目標位置,優先速度vp和方向角ψ:sh=[pgx,pgy,vpx,vpy,ψ],動作ut由速度和方向角組成,ut=[vt,ψt]。深度強化學習的策略π:該策略在避免與其他主體發生碰撞的同時,最小化到達目標的時間Etg。
其中,式(2)代表碰撞約束,在所有時間內主體與任意其他主體距離不得超過其半徑和;式(3)為目標約束,式(4)為主體的運動方程。對于式(1)中的期望值,不需要去考慮明確的數學模型,通過強化學習方法,發生碰撞時給予主體懲罰,順利到達目標點給予主體獎勵,由獎勵方程Rcol(Sjn,u)決定:
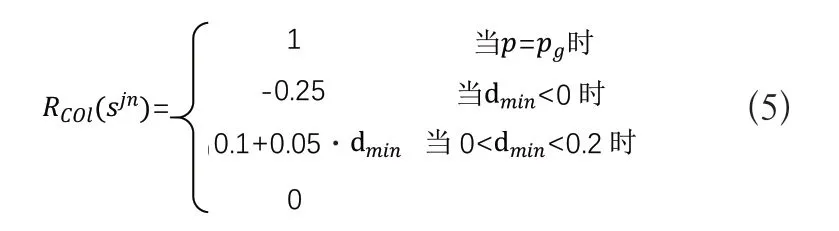
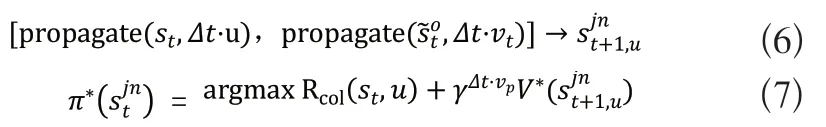
在式(7)中γ表示獎勵因子,V*(Sjnt+1,u)表示通過選擇動作u達到最大化的價值。
2 學習策略
2.1 演員-評論家(Actor-Critic)
深度強化學習方法對于動作的選擇有兩種方式,基于概率(Policy-based)和基于值(Value-based),其中基于概率的方式中,動作集中的每個動作都可能作為下一個動作,只是選擇概率不同;基于值的方式中,算法為每個動作評分,選擇評分最高的動作作為下一個動作。演員-評論家算法是這兩種方法的結合:Actor基于概率選擇下一步的動作,環境將對動作的獎勵反饋給Critic,Critic根據環境反饋的獎勵指導Actor修改選擇動作的概率。圖1的框架顯示了Actor網絡、Critic網絡之間的關系。
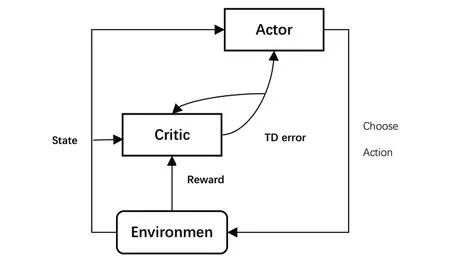
圖1 AC網絡結構圖
2.2 NoisyNet-GA3C避障方法
A3C方法是基于AC方法的一種優化訓練方法,對學習主體多線程訓練以加快主體的訓練速度。A3C結構如圖2所示。在A3C方法中,主體與環境交互的許多線程是并行模擬的,學習方法的訓練結果基于全部經歷的融合。這個算法在許多電子游戲的表現中優于人類。Babaeizadeh M[12]對其實現進行了修改,以有效地使用GPU來最大化每秒處理的訓練經驗的數量,在許多情況下,GA3C方法的學習速度比A3C方法快一個數量級。
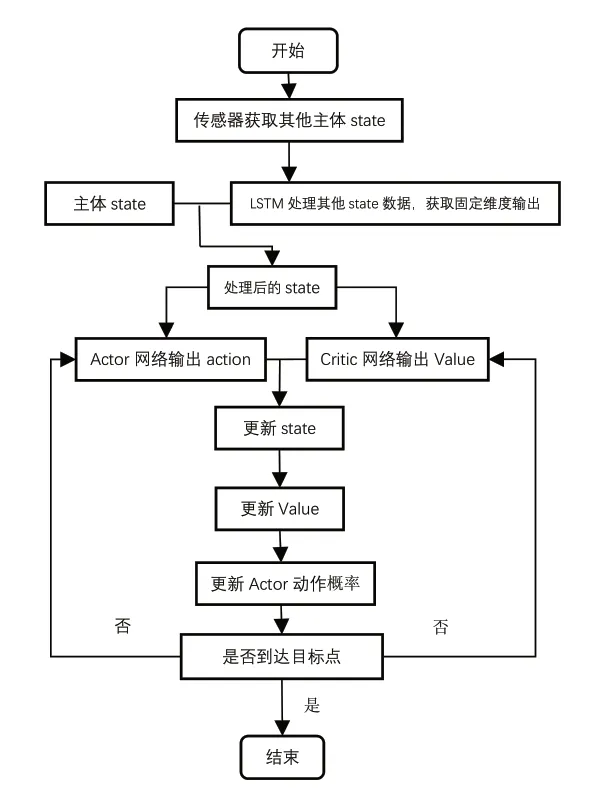
圖2 Noisy Net-A3C方法流程圖
一般地,將NoisyNet以y=fθ(x)表示,x表示輸入,y表示輸出,θ表示噪聲參數,其中θ定義為:


NoisyNet-GA3C方法在Critic網絡的全連接層中添加了一層噪聲網絡以增加模型的探索能力。NoisyNet-GA3C方法總體流程圖如圖2所示。
3 實驗驗證
3.1 網絡訓練
針對現存方法在數據維度較低時尋路時間長,碰撞率高的問題,設置訓練場景時,場景中的最多共存機器人數量n<5。Actor網絡為基于概率的學習網絡。設置主體轉向角度的間隔為30°,每一步的動作有十一個方向可以選擇,每次訓練中的動作選擇概率由Critic網絡的Value更新。Critic網絡為基于值的學習網絡,通過環境反饋的獎勵更新Value。在訓練網絡時,Critic網絡選擇的學習率為,Actor網絡選擇的學習率為,這是因為Critic網絡對Actor網絡起指導作用,Critic網絡要更加快速的學習。網絡訓練的tensorflow版本為tensorflow1.4.0-GPU,使用Adam優化器。
將主體每回合接收的最大獎勵設置為1,最終獲得的平均獎勵為0.96,意味著最終收斂之后還是會發生碰撞,這在預料之內,在大量的訓練中,選擇出非最優動作是難以避免的。如表1中所示,相對于之前的方法平均獎勵為0.92,改進后的方法平均獎勵取得了可觀的進步。
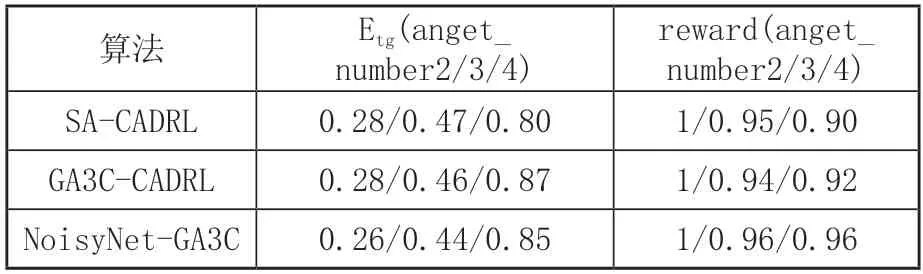
表1 三種規劃方法平均獎勵對比
3.2 實驗仿真
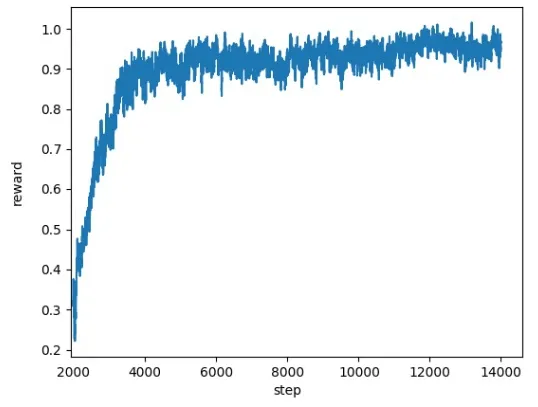
圖3 訓練中主體得到的獎勵
ROS(Robot Operating System)是一款機器人仿真開源平臺,使用ROS平臺仿真主要應用到了它獨特的通訊機制——話題的發布和訂閱,可以通過修改話題內容和訂閱者對機器人模型進行修改和。Gazebo是ROS平臺中的機器人仿真工具,在Gazebo中設置一個turtlebot3_waffle機器人作為實驗主體,三個turtlebot3_burger機器人作為其他主體。獲取Gazebo發布的機器人state作為NoisyNet-GA3C的輸入,算法輸出的action發布到action話題,實驗主體訂閱action話題,即可在仿真環境中做出相應的動作。
在gazebo中,場景里設置一定數目的移動機器人后,算法所需state值,即移動機器人的在仿真世界的坐標、速度,可以由軟件自行生成(圖4(a)),獲取到數據后按照算法所需state格式打包發送至對應的pose話題,NoisyNetA3C算法獲取主體state和LSTM算法處理過的其他主體state之后,輸出action至cmd_vel話題,主體訂閱該話題接收action信息完成響應。使用gazebo仿真的話題節點圖如圖5所示。在仿真環境中,主體能夠快速響應,避開其他主體到達給定目標。
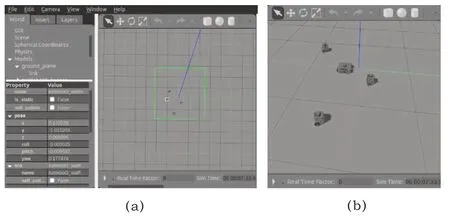
圖4 gazebo中仿真
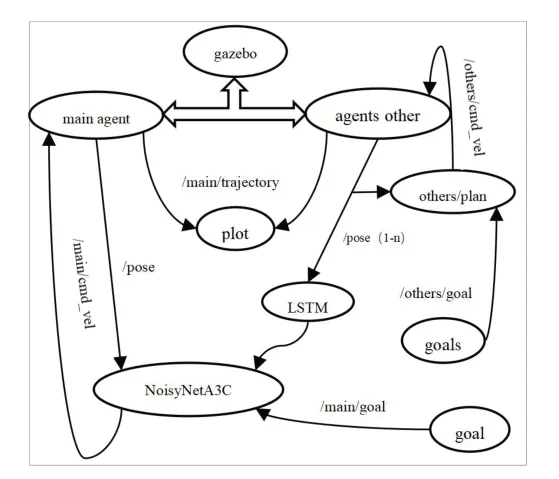
圖5 gazebo仿真節點圖
4 結語
本文對現存的基于強化學習的多主體路徑規劃方法進行了改進,引入NoisyNet方法,使用LSTM網絡處理不同維度的數據,在輸入網絡前得到相同維度的輸入。通過在網絡的全連接層添加噪聲網絡,增強模型的探索能力,提升了現存深度強化學習算法在輸入數據維度較低時規避障礙的能力。隨著強化學習方法的不斷發展,將有更加優秀的強化學習方法提出和改進,多主體機器人規劃會在避障速度和時效性上獲得更進一步的發展。
猜你喜歡
北京航空航天大學學報(2022年6期)2022-07-02 01:59:12
南大法學(2021年3期)2021-08-13 09:22:32
領導決策信息(2018年50期)2018-02-22 06:17:16
商周刊(2017年5期)2017-08-22 03:35:26
制造技術與機床(2017年3期)2017-06-23 08:11:21
中國衛生(2016年2期)2016-11-12 13:22:16
自然與文化遺產研究(2016年2期)2016-05-17 05:53:59
中國工程咨詢(2016年4期)2016-02-14 07:28:28
山西大同大學學報(社會科學版)(2015年6期)2015-01-22 07:22:22
中國海洋大學學報(自然科學版)(2014年8期)2014-02-28 12:21:31
