裝備系統剩余使用壽命預測技術研究進展
2022-06-30 06:57:20郭忠義李永華李關輝彭志勇于振中
南京航空航天大學學報 2022年3期
郭忠義,李永華,,李關輝,彭志勇,張 寧,于振中
(1.合肥工業大學計算機與信息學院,合肥 230009;2.哈工大機器人(合肥)國際創新研究院,合肥 230601;3.天津津航技術物理研究所,天津 300192;4.北京機電工程研究所,北京 100074)
21 世紀作為技術創新的時代,國內和國際社會發展日新月異,科技信息量呈現指數式的高速增長。工業設備系統也日趨復雜多樣化,航空航天、整車制造、武器裝備、智能家電以及工業設計等各個領域的工程體系日趨精密、變得更加復雜和智能[1-3]。隨之而來的便是故障風險的增加。設備突然宕機將造成巨大危害,各種因設備故障引發的事故也見諸報端,引發人們對財產以及生命安全威脅的擔憂。因此,剩余使用壽命(Remaining useful life,RUL)預測成為設備系統健康管理領域研究的重點和熱點。
早期工業設備的維護方式是故障之后維修,能夠很快找到對應的故障,并實現完美的修復,但是會浪費大量的生產時間;隨后,提出預防性維護。預防性維護從系統維護發展到基于狀態的維護(Condition-based maintenance,CBM)[4]。在系統維護中,使用由部件構造者提供的與壽命相關的度量或可靠性信息來安排干預。在CBM 中,評估組件的狀況,即其退化水平,并跟蹤其演變,直到其越過某個閾值后及時進行維護,實現更加優化的維護方法。如今,預測性維護的提出對設備狀態管理進一步細化,實現精確的故障預測,實現智能化的同時,進一步降低維護的成本。工業智能化不但能夠提供安全高效的管理系統,而且能夠實現成本的精確控制,減少不必要的消耗。精準的RUL 預測便是實現智能化的重中之重。
RUL 預測的實現方法在不同的文獻中使用了不同的分類標準[5-7]。結合當前流行的分類方式,將預測模型分為兩類:基于物理模型[8-23]和基于數據驅動模型。
物理模型是通過工業系統零部件的退化現象的數學或物理模型來構建的,能夠用專業的模型對退化進行表征,從而能夠將現有的觀測數據代入模型求得RUL。例如,滾動軸承的L-P 公式[8]、Ioannides-Harris 模型[9]、裂紋擴展方程[10]和Forman 裂紋擴展規律[11],電池的指數模型[12],使用粒子濾波作為參數估計器[13],以及其他物理模型[14-23]。隨著時代發展,工業系統日趨復雜化、集成化,基于物理模型的RUL 預測的相關研究呈現下降趨勢。
數據驅動模型的建立依靠于先前觀察到的數據來預測系統的未來狀態,或通過匹配歷史上類似的模式來推斷RUL。數據驅動模型需要大量的數據進行訓練,無需事先對系統的物理行為有專業認識,就能夠很好地建模高度非線性、復雜和多維的系統。但是運行到故障的數據很難獲得,因為獲取系統故障數據可能是一個漫長而昂貴的過程。因此,通常使用公共數據庫來驗證所提出的模型,如FEMTO-ST研究所提供的PRONOSTIA-FEMTO軸承數據集[24],NASA 提供的電池數據集[25]和渦扇發動機退化仿真數據集[26]。支持向量機(Support vector machine,SVM)在RUL 預測領域有著廣泛應用[27-42]。從單SVM 方法發展到與其他方法相結合,在對PRONOSTIA-FEMTO 軸承數據集的RUL 預測中將預測誤差E由2%降至0.6%;結合神經網絡的SVM 方法使均方根誤差(Root mean square error,RMSE)降低了10%以上。維納過程(Wiener process,WP)多用于構建可解釋性的退化模型,在RUL 預測中準確率表現并不優異[43-53]。高斯過程回歸(Gaussian process regression,GPR)利用高斯過程對函數從輸入空間到目標空間的非線性映射進行建模,在RUL 預測中得到應用[54-62],對于電池數據集的RUL 預測中RMSE 隨著GPR算法的開發有較大幅度的下降。另外神經網絡也被引入到GPR 中以提高回歸性能[63]。相似性方法是通過匹配退化軌跡實現RUL 預測[64-73],最早以PHM’08 競賽冠軍的姿態出現。隨著此方法的改進將對渦扇發動機退化仿真數據集的RUL 預測中懲罰分數(Score)降低了72%以上,當前的研究也開始與神經網絡進行結合,并將Score 由千位數量級降低至百位數量級。神經網絡方法被廣泛應用于RUL 預測[74-106]。在不考慮時間記憶性的情況下,從簡單的人工神經網絡(Artificial neural network,ANN)到卷積神經網絡(Convolutional neural network,CNN),再到深度卷積神經網絡(Deep convolutional network,DCNN),逐步降低了對渦扇發動機退化仿真數據集RUL 預測的RMSE 和Score,其中Score 都能保持在百位數量級。在后來的研究中時間記憶性也被引入,循環神經網絡(Recurrent neural network,RNN)能夠將預測準確性再提升,長短時記憶網絡(Long short-term memory,LSTM)被用來解決RNN 存在的長期依賴問題,能夠在RNN 的基礎上將預測誤差進一步降低。基于神經網絡的RUL 預測優于其他方法的RUL預測,對抗學習與遷移學習[107-122]通過與神經網絡結合,能夠將RUL 預測結果進一步提升。神經網絡在近些年來成為重點研究的對象,對抗學習與遷移學習也是神經網絡相關研究的強大助推力量。
因此有必要對工業系統中的現有RUL 預測工作進行回顧,以此來掌握未來工業系統RUL預測的發展。本文介紹并總結了各種RUL 預測方法、相應的主要假設和應用領域,并著重于基于數據驅動的RUL 預測。接下來,指出并討論當前和未來的挑戰性問題,以期有助于未來的研究工作。
1 技術基本原理
1.1 RUL 預測
RUL 定義為從當前時間到有效壽命結束的長度[123]。RUL 預測就是通過設備的歷史狀態變化及其他條件信息來判斷設備從當前時刻運行到失效的剩余時間。其中歷史狀態變化及其他條件信息多是對設備運行時的監控數據,包含但不限于監控數據的變化以及環境信息等,其基礎定義公式如下[124]
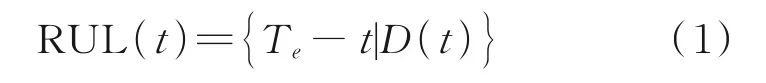
式中:RUL(t)為設備在時刻t的剩余使用壽命,Te為設備的失效時間,D(t)為當前時刻所擁有的所有狀態信息。
1.2 RUL 預測方案
RUL 預測整體方案如圖1 所示,需要完成從數據采集、數據處理、特征提取、模型構建、RUL 輸出以及提供運維方案一系列工作。
數據是RUL 預測的基礎,其中監控數據能夠對設備的健康狀態進行度量。監控數據的采集一般由傳感器、數據傳輸設備和數據存儲設備組成。采用多種傳感器捕捉不同類型的監測數據,能夠反映設備的健康狀態變化。獲取的數據通過數據傳輸設備傳輸到電腦或其他設備,并將其存儲。隨著傳感器和通信技術的迅速發展,越來越多的先進數據采集設備被設計并應用到現代工業系統中。
有些數據可以直接作為設備性能或健康狀態的表征。有些數據則不具有直接表征的能力,但是可以通過對數據進行更深層次的挖掘來對設備健康狀況進行解讀,實現間接表征。由此看來利用直接數據來進行RUL 預測是最好的選擇,但是直接數據的獲取具有很大的難度,有些數據通常是不可獲取的或者需要付出高昂代價。直接數據難以獲取,間接數據的獲取更加方便。一般無需停機收集,且使用特定的傳感器便可得以實現。間接數據雖然不能直接表征設備性能和健康狀態,但是可以通過數據處理將其映射到相應的健康指標上來描述設備的性能。特征提取方法包括但不限于傅里葉變換、均值方差提取、小波變換和主成分分析(Principal component analysis,PCA)法等。
數據處理包含數據去噪、數據標準化/歸一化、特征選擇和特征提取等。數據去噪是由于原始數據被污染,會存在噪聲,但是噪聲不能反映設備的真實狀態,會影響預測的結果。因此需要將原始數據中的噪聲去除,以減少甚至消除噪聲的不當干擾。
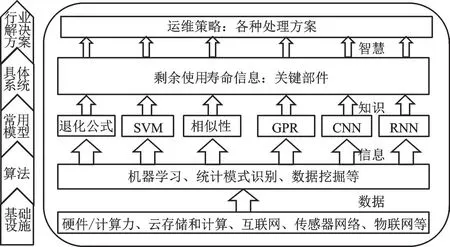
圖1 RUL 預測整體方案Fig.1 RUL prediction scheme
數據標準化/歸一化是由于采集到的原始數據會有多維變量,多維變量可能就會由于量綱的不一致導致數據的大小和方差有很大不同,因此需要消除數據中不同量綱尺度對設備健康狀態估計的影響。一般會采用標準化和歸一化的處理方法來消除量綱的影響。
特征選擇主要針對包含多維變量的原始數據。多維變量中不相關或者冗余的變量可能會導致模型過擬合或者低靈敏度,因此變量選擇是十分必要的。特征提取是為了消除數據中不同變量間具有明顯或隱藏的相關性,將其變成線性不相關的新向量,新向量將具有更多的有效信息以及代表性。特征選擇能夠保持數據的原始特征,最終得到的降維數據其實是原數據集的一個子集;而特征提取會通過數據轉換或數據映射得到一個新的特征空間,盡管新的特征空間是在原特征基礎上得來的,但是新數據集與原始數據集之間的關聯無法直接體現。
模型構建是考慮對應已有的數據,是采用物理模型還是數據驅動模型,或者是混合式的模型。針對不同的研究對象,需要分析不同模型的優缺點,再根據目標指導選擇最合適的模型。對于單一設備的RUL 預測可以選擇簡單明了的物理模型,能夠實現低成本且高效率的預測;而對于復雜的集成系統,構建物理模型是十分困難的,而數據驅動的方法能夠取得更佳的效果。
RUL 輸出以及運維方案是RUL 預測最后的步驟,將預測結果以需要的方式展現。運維方案是基于預測結果給予適當的處理方案,將預測結果變得更加立體化,展現出基于RUL 預測的智能一體化終端平臺。
1.3 評價標準
RUL 預測結果一般可以由預測值和實際值進行直接差值對比,但是由于預測對象以及壽命計量單位的不同,會出現較大的差值。因此,對一些常用的評價標準進行簡單介紹。常用的評價標準包括預測差值、RMSE、預測誤差E、相對精度(Relative accuracy,RA)和懲罰分數(Score)等。
預測差值是真實RUL 值與預測RUL 值的差值,直觀反映了預測的好壞。
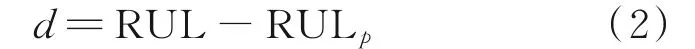
均方根誤差是預測值與真實值偏差的平方和觀測次數n比值的平方根,能夠很好地反映出預測的精密度。
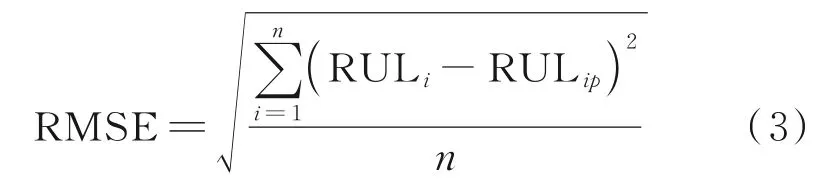
預測誤差是預測值與真實值的差值除以真實值,反映了預測值與真實值的偏離程度。
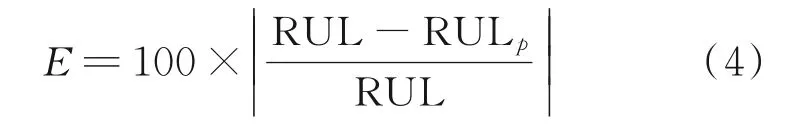
相對精度是相對于預測誤差的另一種表現預測值與真實值的偏離程度的評價指標。
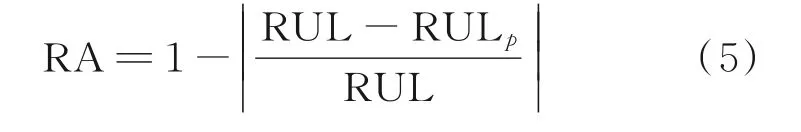
懲罰分數為航空發動機數據專用評價指標[26],是預測值和真實值之間的偏差帶來的懲罰分數
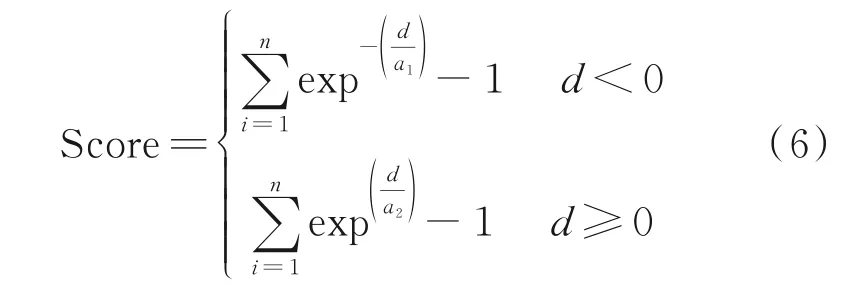
式中:RUL 為真實的RUL 值,RULp為預測的RUL值,a1=13,a2=10。
2 研究進展
基于物理模型的RUL 預測方法能夠在擁有少量數據樣本的情況下實現工業設備系統RUL 的預測,其不需要考慮大規模大數量的采集數據,甚至無需數據分析就可以得到設備的故障或失效情況。在物理模型中,相應的專家知識是必不可少的,這里涉及到的模型構建將會花費大量的時間精力,模型一旦建立完成就具有了專用性,無法很好地適配到其他類似的系統中去,甚至在環境變化過大的情況下也不能很好地工作。故其在專業性上能夠表現出可靠的預測效果,但是不具有遷移性,無法為其他類似或相近的工業系統服務。基于數據驅動模型的RUL 預測模型則完全不需要考慮系統的專業知識,能夠對數據運用不同的數據分析方法進行分析和數據信息的深度挖掘,獲取特征信息,再根據特征信息建立模型。基于數據驅動的RUL 預測模型的準確性依賴于數據的質量,只有足夠且具有完整特征信息的數據才能實現模型的準確預測。數據的大量運用使其能夠完成很復雜的物理模型無法完成的系統建模,但這既是其優點也是其缺點。設備運行的完整和準確的數據往往是不易獲取的,其中完整的壽命周期數據更是難以獲得,同時數據的采集也會受到噪聲以及其他的干擾。本文將對近些年關于RUL 預測的研究進行歸納,重點將介紹數據驅動模型的RUL 預測,其中基于神經網絡的RUL 預測研究由于其強大的特征提取能力以及計算機算力的大幅提升而出現了爆發式的增長。
2.1 物理模型
物理模型的正確建立是實現準確RUL 預測的基礎,它涉及系統失效機制的專業知識,以建立系統退化過程的數學模型來估計RUL。模型參數的識別通常需要專門設計的實驗和大量的經驗數據。Lundberg 和Palmgren 在1949 年對滾動軸承疲勞失效進行研究[8],通過修正威布爾失效統計理論,分析了軸承疲勞失效的特征,并對應力材料體積的影響進行了評估,建立了各變量與承載力關系的L-P 理論公式。將滾動軸承的失效模型具現化,使得其壽命有了直觀的描述
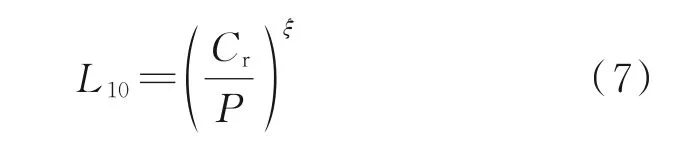
式中:L10為工作時間,Cr為額定動載荷,P為當量動載荷,ξ為軸承參數。
隨著時代的發展,人們意識到L-P 理論存在一定的局限性。1985 年,Ioannides 和Harris 在引進了材料疲勞極限應力和考慮應力體積內各點應力及其深度的情況下,構建了滾動軸承及其他易疲勞機械元件疲勞壽命預測的一種新的數學模型[9],加入載荷、材料和操作條件等參數,能夠對軸承的疲勞壽命描述得更加精準。
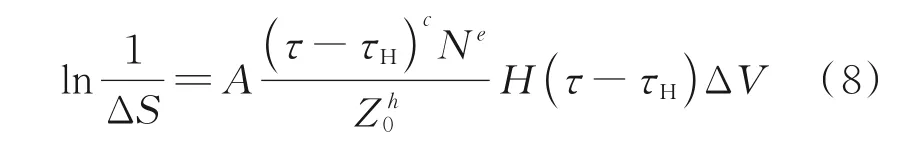
式中:S為存活率,τH為材料的疲勞極限應力,τ為產生疲勞裂紋的誘發應力,V為承受應力的體積,Z為應力所在的深度,H為海維賽階躍函數,N為應力循環的次數,A為常數。
另一種軸承壽命預測模型是基于斷裂力學,假定疲勞壽命取決于裂紋發展至斷裂的過程。文獻[10]基于混合模態Dugdale 模型、累積塑性位移準則和循環積分概念,建立了混合模態加載和小尺度屈服條件下的四次方應力強度因子裂紋擴展方程和二次方循環積分方程,使得各種加載條件下都能得到合理的大小。基于機器故障組合的物理模型的濾波器建立了基于線彈性斷裂力學的Forman 裂紋擴展規律的壽命模型[11],將應用范圍推廣到機器系統,實現了發生災難性故障前的剩余循環次數的預測。為了預測缺口鎳基單晶高溫合金的同相熱機械疲勞(In-phase thermomechanical fatigue,IP TMF)壽命,基于連續損傷力學,建立了考慮疲勞損傷和蠕變損傷的鎳基單晶高溫合金光滑試樣的IP TMF 壽命預測模型[14],再使用實驗數據識別材料常數,最后通過在光滑試件上進行帶停留時間的IP TMF 應力控制試驗,驗證了壽命模型的準確性。胡殿印等[15]建立了GH2036 合金的裂紋閉合模型,依據此模型研究GH2036 高溫合金平板的低循環疲勞裂紋擴展壽命,取得了有效的RUL 預測。基于廣義熱力學框架的非線性連續介質損傷力學模型[12],在考慮不同載荷水平以及加載順序的復雜條件下對某淬硬回火鋼的疲勞實驗數據建立模型,展現出對疲勞壽命的良好預測。隨著新能源的大力發展,電池的壽命預測也有不少模型被建立起來。構建一個模型來反映電池健康狀態(State of health,SOH)與其內外特性之間的聯系,然后根據模型對SOH 或RUL 進行預測。文獻[16]研究發現鋰離子電池的面積比阻抗增加和功率衰減的速率遵循了基于時間功率和阿倫尼烏斯動力學的簡單定律,以此根據功率衰減的電化學機理,建立了電池退化與溫度和使用時間之間的聯系。粒子濾波器(Particle filtering,PF)被用來估計和預測模型結構可用的時間序列數據[13],構建指數模型和改進指數模型,分別使用不同的狀態方程來跟蹤電池容量退化,對鋰電池RUL 預測展現出了較強的優越性。考慮到PF 存在樣本退化和貧瘠的問題,引入啟發式卡爾曼算法(Heuristic Kalman algorithm,HKA),構建出HKA-PF 算法,在3 種不同情況下都能更準確地估計出RUL[17]。將PF 和無跡卡爾曼濾波(Unscented Kalman filter,UKF)融合構建了無跡粒子濾波(Untracked particle filter,UPF)[18],首先利用電池容量數據對電池退化趨勢進行建模,再利用UPF 實現對鋰離子電池RUL 的預測,相較于PF 算法降低了預測誤差。在此基礎上,進一步提出改進UPF 算法(Improve untracked particle filter,IUPF)[19],結合馬爾可夫鏈蒙特卡羅算法解決了混合動力汽車中鋰電池的退化現象,有效地實現鋰電池RUL 的預測。另外通過對原始數據使用凸優化降噪處理,提升數據的可靠性,再求取鋰電池退化機理模型的參數,構建了準確的表達式,進一步提高了對鋰電池RUL 預測的準確率[20]。
電化學阻抗譜(Electrochemical impedance spectroscopy,EIS)被提出用作監測鋰電池健康狀況的指標[21],為了實時監測電池的健康狀態,采用在線的EIS 估計方法非常有益。提出了一種基于可在線實現的分數階等效電路模型的鋰電池EIS估計方法,對電池的RUL 進行了較好的預測。文獻[22]使用可循環鋰的摩爾數和歐姆電阻作為SOH 指標的參數,開發了一種基于增強單粒子模型(Enhanced single particle model,eSPM)參數估計的RUL 預測算法。從實驗數據中估計這些參數,并表明它們與從實驗老化研究中測量的電池SOH 有關。最后利用估計的eSPM 參數導出的復合SOH 度量設計了基于PF 的RUL 預測器,該預測器可以利用SOH 度量的演化來預測RUL。文獻[23]基于Dempster-Shafer 理論和貝葉斯蒙特卡羅方法建立了一個由兩個指數函數組成的電池容量衰減模型,該模型在建模精度和復雜性之間有很好的平衡,能夠準確捕捉電池容量衰減趨勢的非線性。
以上基于物理模型的RUL 預測方法可以在相對穩定的外部條件下較好地提高預測的準確性。物理模型具有專用性,無法推廣到其他設備中,而且其準確性很容易受到外界環境影響。隨著工業設備系統高度集成化的發展,單個模型的建立已經不能滿足整個工業設備系統壽命預測的需求。然而多模型的組合是困難的,無法通過簡單疊加得到,需要基于設備的整體組合以及全面的專業知識去實現模型的建立,因此依靠物理模型來預測工業設備系統的RUL 十分困難。越來越多學者的研究集中于數據驅動模型的RUL 預測。
2.2 數據驅動模型
數據驅動模型的RUL 預測方法很多都是著眼于退化模型的構建,其基本原理如圖2所示。使用離線數據庫構建退化模型,再通過實時數據獲取當前研究對象的退化模型,進行壽命預測。數據驅動模型可以總體概括為機器學習的方法,機器學習不需要專業的先驗知識便能夠從大量的數據中自主學習其中的規律,構建出高度非線性的復雜系統。機器學習能夠適配工業設備系統的復雜性,使得其被廣泛應用于RUL 預測中。數據驅動方法可以分為統計學習與機器學習兩類。統計學習主要包括支持向量機、維納過程和基于高斯過程回歸等方法;機器學習方法包括相似性方法和神經網絡模型等。

圖2 基于退化模型的RUL 預測基本框架Fig.2 RUL prediction framework based on degradation model
2.2.1 支持向量機
支持向量機首先由Cortes 和Vapnik 提出[125],用于數據分析和模式識別。優點是靈活,當提供足夠的數據時,可以模擬任意復雜的系統[126]。它通過搜索以最大間隔分隔感興趣類別的超平面來執行分類。在SVM 中,核函數經常被用于通過將低維空間中的非線性問題轉化為高維特征空間中的線性問題來促進非線性問題的解決。通常,預測基于在輸入空間上定義的一些函數,而學習是推斷該函數參數的過程。SVM 基于式(9)進行預測[127]
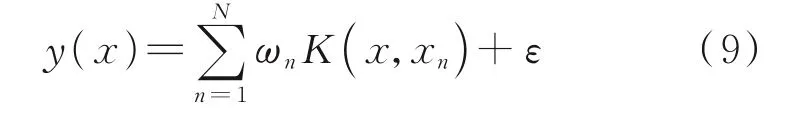
式中:ωn為連接特征空間到輸出的模型權值,K( ·)為核函數,ε為獨立噪聲項。
該方法具有出色的小樣本處理能力和避開維數災難的能力,能夠將高維空間中的非線性關系映射為線性關系。因此,許多學者嘗試將該方法用于其他問題的解決。基于SVM 及其擴展的RUL 預測被應用到軸承、鋰電池、航空發動機和機械部件等方面。文獻[27]采用PCA 對滾動軸承運行故障試驗的振動信號特征進行選擇,并將粒子群算法應用于SVM 的參數優化,建立了基于SVM 回歸的RUL 預測模型。如圖3(a)所示,該模型主要有3個步驟,即敏感特征的選擇、構建SVM 預測模型的輸入輸出和SVM 參數的優化。模型建立完成后將振動信號的特征作為輸入,然后輸出與軸承壽命相關的標量,相比于式(7)具有更高的預測精度。將機器退化過程中的離散健康狀態概率與SVM 分類器結合,應用到健康狀態估計中,能夠有效地表征軸承故障的動態隨機退化并有助于軸承RUL 的長期預測[28]。以上研究都是圍繞單變量,考慮到僅關注單變量時間序列預后,不能很好地預測RUL,研究人員構建了基于相關特征和多變量SVM 的預測模型[29]。多變量SVM 考慮了變量間的影響,能夠挖掘出小樣本更多的潛在信息,并根據個體差異無效的相對均方根對軸承壽命階段進行劃分,對軸承RUL 實現有效的預測。不同于著眼于變量的多少,考慮到單個預測方式的不足,提出了一種結合Hilbert-Huang 變 換(Hilbert-Huang transform,HHT)、SVM 和支持向量回歸(Support vector regression,SVR)的滾珠軸承監測新方法[30],該方法利用HHT 從平穩/非平穩振動信號中提取新的健康指標,然后通過SVM 的監督分類技術給出故障診斷,最后通過基于SVR 的時間序列預測獲得RUL 的估計。三者的有效結合,提高了軸承退化檢測、診斷和預測性能。另一種改進的灰色預測模型結合SVM 的灰色SVM 模型的RUL 預測方法也被提出[31],首先利用三角函數對原始數據序列進行平滑處理,然后利用SVM 和遺傳算法建立最優預測模型,最后,通過回歸生成操作恢復數據,得到電池壽命RUL 預測值。
2015 年以來,隨著新能源汽車產業的蓬勃發展,SVM 的分類屬性與回歸屬性結合被用來實現鋰離子電池RUL 的實時預測[32]。首先由鋰離子電池循環數據中提取關鍵特征,然后利用SVM 建立了基于關鍵特征的RUL 分類模型和回歸模型,在電池接近壽命終點時,使用支持向量回歸來預測準確的RUL。文獻[33]構建了基于多健康狀態評估的RUL 預測框架,該框架將軸承的整個壽命劃分為多個健康狀態,并分別建立局部回歸模型,進行RUL 預測。RUL 預測框架如圖3(b)所示,首先是數據采集,然后原始數據預處理,再使用SVM 進行軸承健康狀態評估,將軸承的整個壽命劃分為多個退化狀態,最后構建出局部RUL 預測模型。文獻[34]繼續了多方式結合的探索,提出將最小二乘支持向量機(Least squares support vector machines,LS-SVM)與貝葉斯推理相結合,設計了一種預測微波元件RUL 的方法。如圖3(c)所示,首先將訓練數據和設置算法參數作為LS-SVM 框架的輸入,然后對訓練數據使用LS-SVM 學習算法進行建模,得到構成退化曲線的多個一步預測;同時利用貝葉斯推理找出最優模型參數,得到LS-SVM 回歸模型的誤差線;最后在給定失效閾值的情況下,得到RUL 點估計和區間估計。同樣為了能實現點預測及一定置信水平的置信區間,于震梁等提出一種將SVM 和非線性卡爾曼濾波相結合的RUL 預測模型[35]。使用已有的具有全壽命周期的數據訓練SVM 回歸模型,引入非線性卡爾曼濾波構建出狀態方程,再將機械零部件的退化特征構造出時間更新方程,最后通過逐步迭代計算出各時刻RUL 估計值及一定置信水平的置信區間。文獻[36]提出了一種基于多傳感器數據信息冗余的故障診斷與預測監測方法用于液壓控制閥系統健康監測。如圖3(d)所示,該故障診斷與預測系統采用模塊化結構,包括一個故障檢測與診斷(Fault detection and diagnostics,FDD)單元、一個故障參數估計(Parameter estimation,PE)單元和一個RUL 單元。將特征選擇策略和SVM 技術結合在一起,以捕獲多傳感器數據信息中的冗余,并隔離FDD 單元中的故障。然后建立了3 種自適應神經模糊推理系統的分散網絡來估計故障參數,最后使用自適應貝葉斯算法構造RUL 單元。自回歸綜合移動平均(Autoregressive integrated moving average,ARIMA)與SVM 結合的混合ARIMA-SVM 模型也被應用于RUL 預測中[37],首先通過ARIMA 模型對輸入變量進行預測,然后將ARIMA 模型計算出的值作為輸入值輸入到使用線性核函數、多項式核函數、徑向基核函數和S 形核函數訓練得到的SVM 模型,最后得到RUL預測值。
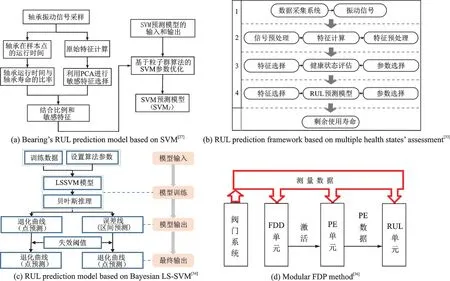
圖3 基于支持向量機的RUL 預測方法Fig.3 RUL prediction methods based on SVM
2020 年以后,學者們不再只關注已被運用到RUL 預測方法的研究,有些未曾被應用的方法也被遷移到RUL 預測中,并取得了較好的預測效果。鳥群算法被引入到LS-SVM 參數進行尋優中[38],并在跟隨者的位置更新中引入自適應學習因子,得到改進鳥群算法(Improved bird swarm algorithm,IBSA),然后結合LS-SVM 模型,建立了IBSA-LS-SVM 模型以解決鋰離子電池RUL 預測問題。區別于其他學者的參數優化選擇方式,粒子群算法(Particle swarm optimization,PSO)與LS-SVM 結合[39],其中LS-SVM 和核函數由PSO 進行優化選擇,然后使用LS-SVM 進行故障預測,當故障癥狀的特征幅值超過特定閾值時,將RUL 預測模塊激活,使用PSO-LS-SVM 進行RUL 預測。文獻[40]采用了與文獻[39]相同的PSO 算法,首先提取滾動軸承整個生命周期數據的特征值,利用單調性初步選擇性能退化參數。然后利用本征矩陣的聯合近似對角化(Joint approximative diagonalization of eigen-matrices,JADE)對提取的性能退化特征參數集進行降維,得到與設備性能退化一致的融合特征。最后構建基于PSO-SVM 的預測模型,預測性能退化趨勢。2021 年,有學者將神經網絡與SVM 結合,提出一種基于ANN 和SVM 的軸承RUL 預測方法[41]。考慮到神經網絡的合理運用能夠保證特征提取的準確性,使用ANN 模型將輸入的多維時域和頻域特征進行進一步的特征提取,然后將提取后的特征輸入到SVM 模型中進行RUL預測。采用特征遷移的策略也被使用[42],使用同型號軸承在不同工況下的輔助數據,計算深度特征和退化軌跡間的相似度,提取出與退化軌跡走勢相近的特征作為公共特征,實現退化信息的遷移。最后使用SVM 實現對軸承RUL 的預測。以上種種方法的結合及擴展使SVM 在RUL 預測的道路上有了更加廣闊的前景。
如表1 所示,展示了SVM 在軸承RUL 預測上的應用,使用SVM 的方法能夠在IEEE 2012 PHM數據集上分別取得RMSE 為34.5 和E為2%的結果。文獻[30]和[42]由于結合了其他方法,使得在RMSE 和E結果上表現更加優異。文獻[41]采用了不同于其他文獻的RUL 統計方式,將整個壽命周期計為1,故而取得了遠小于其他預測算法的RMSE。由于其他文獻中使用了不同的數據集,且未有統一的評價標準,在這里沒有進行相應的定量比較。
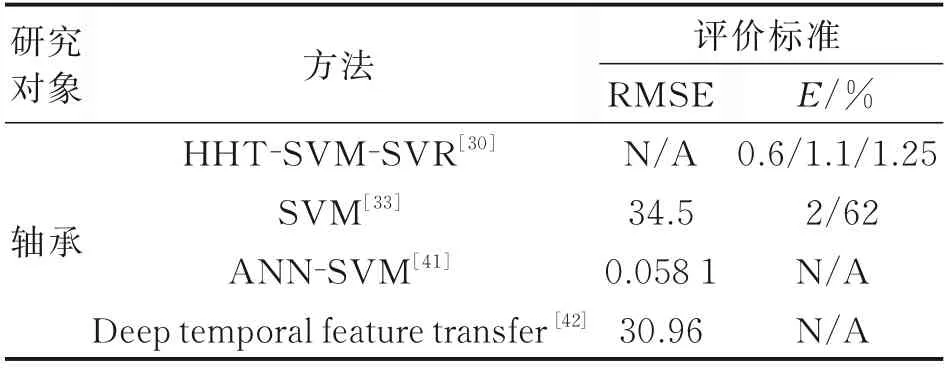
表1 基于SVM 方法的RUL 預測性能Table 1 Performances of RUL prediction based on SVM
2.2.2 維納過程
維納過程是布朗運動的數學模型。以X(t)表示運動中一微粒在時刻t在X軸的位置。X(t0)=x0,x0為微粒在時刻t0的位置,用p(x,t|x0)表示X(t0+t)=x的條件概率密度,則有
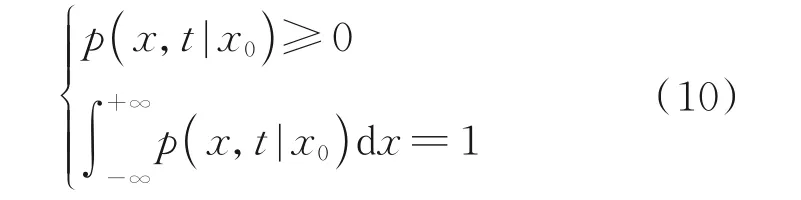
假定p(x,t|x0)與初始時刻t0無關,且當t趨于零時,有X(t0+t)的值無限趨近于初始時刻X(t0)的值,則有
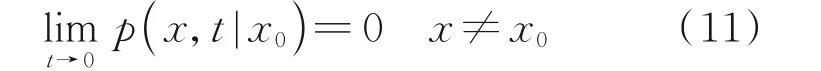
根據中心極限定理,微粒的位移服從正態分布,即
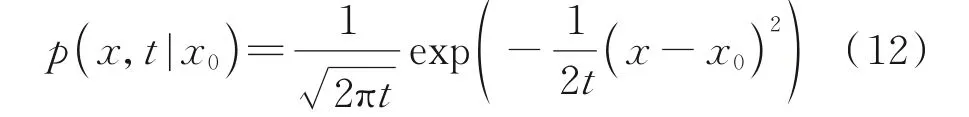
如果隨機變量X(t)滿足:(1)X(0)=0,且在t=0 連續;(2)具有獨立增量;(3)對?t>s≥0,有X(t)-X(s)~N(0,σ2(t-s)),σ>0;(4)對于任意兩個互不相交的區間[t1,t2]和[t3,t4],隨機變量X(t)的增量X(t2)-X(t1)和X(t4)-X(t3)相互獨立。則稱此隨機變量X(t)服從維納過程分布。維納過程有許多種的變形,例如線性帶漂移維納過程、非線性帶漂移的維納過程以及集合布朗運動等。
學者們假設設備隨時間的退化是一個維納過程,提出了一種新的隨機退化過程RUL 預測方法來更準確地預測退化早期階段的RUL[43]。該方法以核函數加權和為漂移增量的維納過程來建模退化過程,然后通過LSTM 預測未來退化增量,最后導出了一個數值近似的RUL 分布,并量化預測RUL。文獻[44]提出了一類具有自適應漂移的維納過程模型,該模型利用了布朗運動的自適應漂移和基于極大似然估計的模型估計方法,建立了鋰離子電池的RUL 預測模型,展現了良好的預測效果。有學者假設產品隨時間的退化是可以由Frank copula 函數來表征它們之間依賴性的維納過程,于是提出了一種基于二維退化數據的自適應RUL 估計方法[45],該方法使用具有測量誤差的二元維納過程模型用于建模退化測量,結合基于群體的退化信息和被監測產品的退化信息,采用馬爾可夫鏈蒙特卡羅(Markov chain Monte Carlo,MCMC)方法獲得參數值,對未知參數進行序列估計得到RUL。為了描述表現出非線性、時間不確定性、項目間可變性和時變退化的退化行為,另一種具有自適應漂移的基于廣義維納過程的退化模型被提出[46],首先利用期望最大化算法來在線估計所有其他模型參數,而不需要來自同一批次中相同系統的基于群體的退化數據;然后結合隱藏漂移的不確定性,導出RUL 分布的解析近似的封閉形式;最后對實際銑削數據實現了良好的RUL 預測。
測量誤差(Measurement error,ME)是測量數據的不確定性來源之一,對數據驅動壽命估計的性能影響很大。文獻[47]提出一種基于維納過程測量誤差(Wiener process measurement error,WPME)的鋰電池RUL 預測方法。該方法首先采用基于截斷正態分布的估計退化狀態建模方法,同時考慮測量不確定度和估計漂移參數分布,得到了精確的、封閉的RUL 分布;然后對基于總體的參數估計的最大似然估計方法進行改進,提高了RUL 預測效率。隨后又提出一種具有測量誤差的非線性維納退化過程閉合形式的近似解析RUL 分布[48],采用極大似然估計方法對模型中未知的固定參數進行估計,再利用貝葉斯方法更新隨機參數,最后仿真結果表明,在退化過程中考慮測量誤差可以顯著提高實時RUL 預測的精度。文獻[49]提出了一種基于序貫貝葉斯更新的維納過程模型用于RUL 預測,序貫方法采用上一次隨機漂移參數的貝葉斯估計作為下一次隨機漂移參數的先驗;首先構建基于隨機漂移效率的維納過程的線性退化趨勢模型;然后基于最大似然估計方法,確定初始模型參數;最后基于首次通過時間的概念,推導出了RUL 分布的解析表達式。文獻[50]證明了用最大似然估計方法估計維納過程的參數是有偏差的,于是構建了一種基于維納過程一致性檢驗的RUL 預測模型;該模型在小樣本的情況下,取得了高于經典的最大似然估計方法的估計精度。對于許多工業系統,由于外部操作條件和內部機制的變化,其退化軌跡往往呈現兩相模式,在實際應用中,每一相的退化過程都表現出非線性特征,用線性維納過程建立兩相模型往往是不夠的。Lin 等提出一種兩相退化產物的新RUL 預測方法[51],首先采用非線性維納過程的退化模型來描述兩階段退化軌跡,然后分別使用最大似然估計和貝葉斯方法求取模型的未知參數并更新參數,最后根據初始態躍遷到變化態的隨機性和不同單元退化的可變性,導出首次穿越時間概念下RUL 的近似解。在另一項研究中,基于電荷剖面信息間接提取出兩個健康指數,參考文獻[45]建立了二維維納過程模型來表征電池退化過程[52],利用最小二乘算法對參數進行估計后,得到了RUL 的概率密度函數,此外,維納過程結合其他方法的應用也越來越多。文獻[53]采用具有隨機漂移、擴散系數和測量誤差3 個狀態變量的維納過程來表征電池容量退化過程,并使用基于粒子濾波的狀態與靜態參數聯合估計方法,迭代更新后驗退化模型,同時估計單個電池的退化狀態。
基于維納過程的RUL 預測研究對象過于分散,且采用的判定標準不一致,故在此未列表展示近期研究成果的定量對比。基于維納過程的RUL預測會伴隨著大量的公式推導以及計算,雖然具有很好的可解釋性,但是其準確率表現并不優異,且隨著其他數據驅動方法的快速發展及高準確率的表現,基于維納過程的RUL 預測研究呈現了一種下降的趨勢。
2.2.3 高斯過程回歸
GPR 是由Williams 等在1995 年提出[128],其原理是用歷史樣本對預測模型進行訓練,然后用測試樣本作為模型輸入,得到具有概率顯著性的預測結果。GPR 適合處理復雜的回歸問題,如高維、小樣本和非線性等。與神經網絡和SVM 相比,該方法具有易于實現、超參數自適應獲取和概率輸出等優點。GPR 是一種貝葉斯回歸技術,其聯合分布是有限子集的多元正態分布。它由均值函數和協方差函數參數化。對于標量輸入和輸出,高斯過程定義為

式中:μ(t)為均值函數,k(t,t′)為協方差函數。為了回歸,假設先驗均值μ(t)=E(f(t))為零。協方差由所選核指定,核函數有常數、線性、母函數、徑向基函數和多核合成等多種選擇。常用的指數平方函數用來表示協方差。它是一個平穩核,定義為
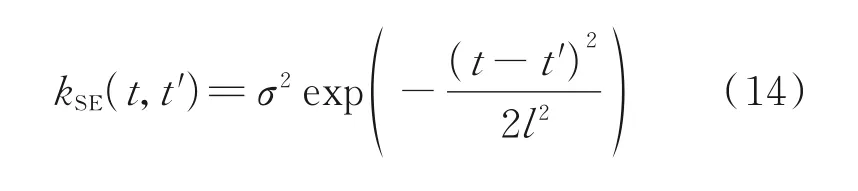
式中:σ為超參數方差,l為長度尺度。
在實際應用中,f(t)是難以獲取的,實際上都是含有噪聲的觀測數據y=f(t)+ε,ε~N(0,σ2n)是服從獨立同分布的高斯白噪聲,σn是噪聲的標準偏差。任意有限個觀測值可以形成一個高斯過程,即
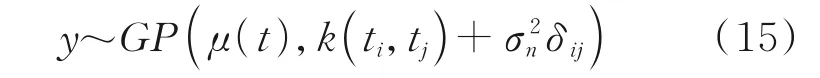
其中當且僅當i=j時δij=1,否則δij=0。
引入噪聲項后,根據高斯過程的定義,觀測值和新樣本點處的函數值是有限數量的隨機變量,服從聯合高斯分布
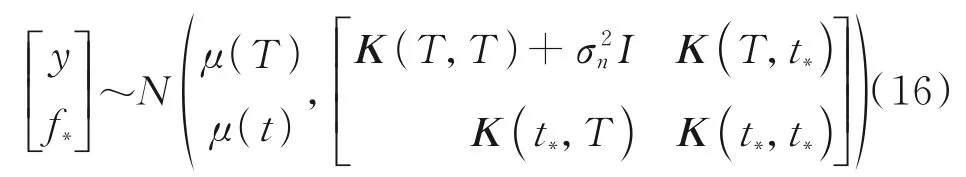
式中:I為單位矩陣,K(T,T)為訓練數據的協方差矩陣,K(t*,t*)為測試處的方差,K(T,t*)為N×1 協方差向量,且K(t*,T)=KT(T,t*)。
根據貝葉斯原理以及聯合正態分布的條件概率特性有
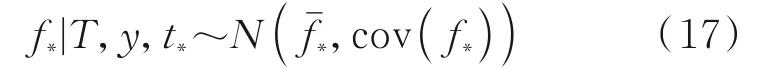
式中
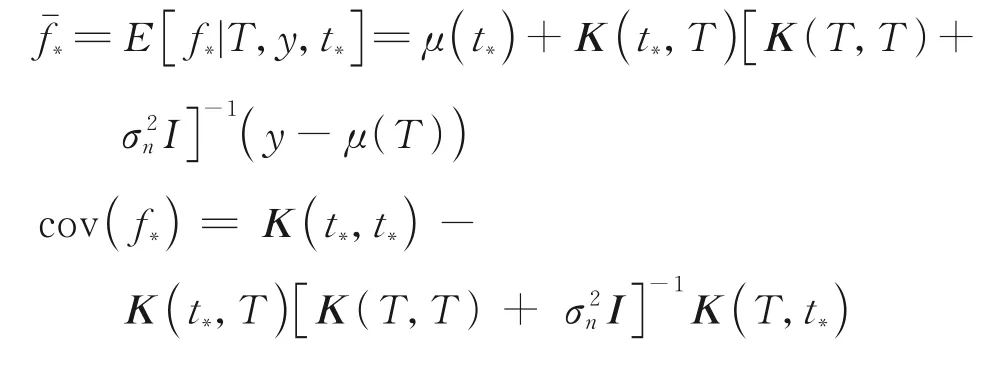
因此,f*的后驗分布可以用來對新樣本點進行預測。是高斯過程模型在新的樣本輸入t*的預測值,置信區間由cov(f*)描述。
使用GPR 構建的通用健康模型被用于預測在各種使用場景下的電池容量退化[54],在這里GPR 以多種方式利用先驗信息,多輸出GPR 有效利用不同單元數據之間的相關性,能夠實現對鋰電池的容量和周期數據短期和長期RUL 預測。多輸出GPR 也與代謝灰色模型結合[55],模擬電池復雜的退化行為;再利用PF 跟蹤電池容量退化進行健康狀態估計,并外推退化軌跡進行RUL 預測。為了實現多步預估,利用改進的GPR 方法結合高斯過程函數回歸(Gaussian process functional regression,GPFR)來捕捉健康狀態的實際趨勢,包括全局容量退化和局部再生[56],可以有效地應用于鋰電池的監測和預測。GPR 也適用于功率金 屬 氧 化 物 場 效 應 晶 體 管 器 件(Metal-oxide-semiconductor field-effect transistor,MOSFET)RUL 預測[57],該方法以MOSFET 導通電阻為研究對象,分別以GPR 算法探討數據驅動技術,以擴展卡爾曼濾波和粒子濾波探討基于模型的技術,兩種方法均能得到有效的RUL 預測結果。文獻[58]將部分增量容量和GPR 結合的混合方法用于電池的短期健康狀態估計和長期RUL 預測,利用混合方法的同時利用雙高斯過程回歸模型對電池健康狀態進行了預測,根據電池健康狀況值和以往輸出的結果,建立了電池長期剩余有用壽命自回歸模型。
深度高斯過程算法利用高斯過程對層間映射進行建模,再使用矩陣變量高斯分布對給定層間與節點間相關性進行建模[59],該算法利用局部充放電時間序列數據(電壓、溫度和電流)進行容量估計,并估計容量和運行時間之間的統計相關性,從而實現了RUL 預測。鋰電池由于自充電和容量再生,退化軌跡具有多模態特性,高斯過程混合(Gaussian processes mixture,GPM)的RUL 預測方法被用來描述這種多模態[60],通過對不同退化模型的不同軌跡段進行擬合,可以揭示軌跡段之間的微小差異,從而實現多模態處理;此外,GPM 可以生成預測置信區間,使得預測比傳統模型更加可靠。Kang 等提出一種基于模糊評價高斯過程回歸(FE-GPR)的RUL 預測方法[61],首先對觀測數據進行模糊評價預處理,然后利用重力搜索算法與歷史數據有效結合,優化分類節點,最后利用該方法強大的數據提取能力,實現準確的RUL 預測。將狀態空間模型和高斯過程相結合,Mohanty 等提出了一種適用于飛機變幅服役載荷的金屬合金疲勞裂紋擴展混合模型[62],將FASTRAN-11 模型中的裂紋閉合狀態變量公式與采用基于核的高斯過程回歸模型相結合,構建了等效于無限神經元的神經網絡模型的物,該模型能夠更好地預測疲勞裂紋長度和擴展速率。
如表2 所示,展示了高斯過程回歸在鋰電池[25]RUL 預測上的應用。改進的高斯過程回歸方法[56]將RUL 預測的RMSE 降低到2.69。雙高斯過程回歸模型[58]的使用將RMSE 進一步降低。具有多模態處理能力的高斯過程混合的方法[60]將RMSE 大幅度縮小。可以看出隨著模型的改善,預測結果變得更加準確。FE-GPR 方法也展現出了較高的準確率[61]。
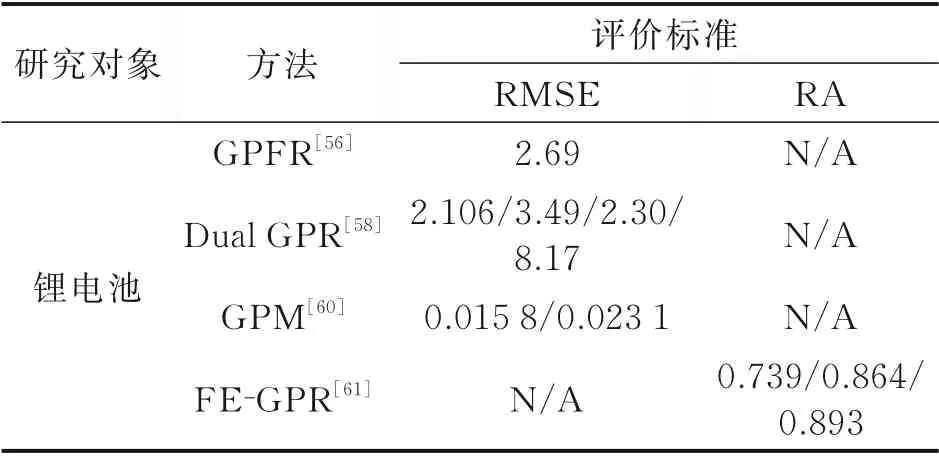
表2 基于GPR 的RUL 預測方法Table 2 RUL prediction method based on GPR
2.2.4 相似性方法
Wang 等在2008 年PHM 數據挑戰競賽中提出一種基于軌跡相似度(Trajectory similarity based prediction,TSBP)的RUL 預測方法[64]。使用大量的具有完整生命周期的傳感器數據構建出同一系統下不同航空發動機的退化模型庫,對于測試單元也構建出退化曲線,并將兩者進行匹配以獲取測試單元的RUL。如圖4(a)所示,TSBP 方法包括3 個基本步驟[65]:(1)退化軌跡抽象——從訓練實例的退化軌跡構建實例/局部模型;(2)相似度評價——根據退化軌跡評價一個測試實例與每個實例模型之間的相似度,將從每個實例模型中獲得一個RUL 估計;(3)模型聚合——將所有實例模型得到的RUL 估計進行聚合,得到最終的RUL 預測。從那時起,各種方法被開發來擴展軌跡相似度預測。隨后,一種廣義相似度預測方法被提出來[66],在衡量系統與其他參考系統的相似性時,賦予系統最近的時間比以前的時間更多的權重,體現出系統退化過程中后面數據的重要性。2014 年,在TSBP 中使用基于皮爾遜相關性的相似線性回歸和動態時間規整進行相似性預測方法被提出[67],使用該方法選擇出最符合測試數據的退化模型,然后量化RUL 預測中的不確定性,在相同的數據及評判標準下取得了優于TSBP 的結果,提高了相似度預測的性能。提高相似度度量準確度也是改進的方向,分段式相似性度量方法被提出[68],使用一個固定長度的窗口,切割對比的兩條曲線,形成兩個線段集合,再將兩個集合中的線段去做相似性對比,同時給予靠后位置的線段以更高的權重。該方法提高了相似性度量的準確性,在保持其他預測模塊不變的情況下提高了RUL 預測的準確度。
在探究提高相似性方法的路上,文獻[69]另辟蹊徑,從多參數方面入手,使用相關性Spearman 系數從設備退化數據中選取關鍵參數,同時由系數大小進行權重分配。如圖4(b)所示,不同于多參數共同構建一維退化曲線,每個關鍵參數都構建出對應的退化曲線,從而形成相應參數的退化模型庫,測試數據便得到多個關鍵參數預測而來的RUL值,再通過相應參數的權重,加權融合實現裝備系統的RUL 預測,關鍵參數的選取以及RUL 預測值的加權融合使得預測精度得到提升。類似方法也被應用于刀具的RUL 預測[70],充分利用歷史數據,對海量復雜的原始監測數據進行挖掘與融合,構建出刀具的健康指數(Health index,HI)曲線,不同于TSBP,同時考慮距離相似性和空間相似性,提高了相似性的準確度,取得了更加準確的預測結果。針對TSBP 只能提供RUL 的點估計,不能適用于某些特定預測的問題,尋求一種能夠提供RUL 預測置信區間的方法;Huang 等提出一種將自適應核密度估計技術與β準則相結合,擴展RUL 估計模塊的框架的改進方法[71];改進后的TSBP 方法不僅能夠提供準確、精確的RUL 點估計,而且能夠在一定的置信水平下量化RUL 預測的不確定性,在增強TSBP 方法的不確定性管理能力的同時拓寬了TSBP 方法的應用場景。文獻[72]從數據角度出發,考慮到之前提出的預測方法中對航空發動機原始數據的處理總是不太完美,由此將具有強大數據處理能力的神經網絡引入到數據處理中去,如圖4(c)所示,設計了一個神經網絡擬合模型,用來構建原始數據輸入和HI 輸出的映射,再通過相似性算法實現測試實例的RUL 預測,該方法克服了短時測試數據的缺陷,并提高了關于預測指標的預測性能。2021 年提出結合自編碼器神經網絡的基于多時間尺度健康指標相似性的預測方法(AE MTS-HI)[73],如圖4(d)所示,采用了類似于文獻[72]的方法,引入非監督式神經網絡的自編碼器構建原始數據輸入和HI 輸出的映射,在相似性算法的實現上增加了多時間尺度的思想,根據測試軌跡長度選取不同時間長度的部分軌跡,與退化模型庫中的退化軌跡進行相似性匹配,再以相似距離作為加權標準,求得不同時間長度軌跡對應的最優RUL 預測值,最后將所有時間長度下的RUL 預測值取平均,得到最終RUL 值。
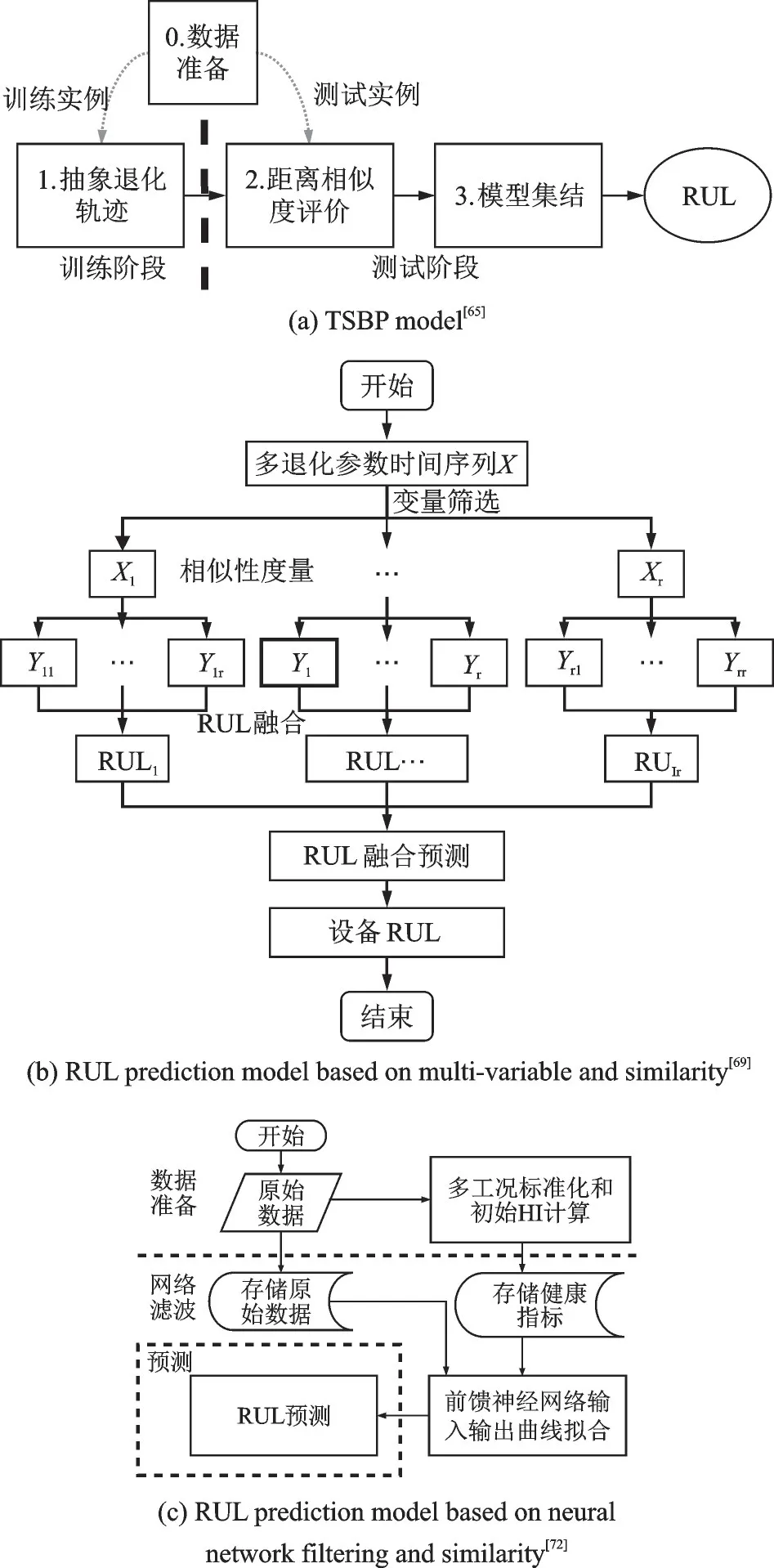

圖4 基于相似性的RUL 預測方法Fig.4 RUL prediction methods based on similarity
表3展示了相似性方法在航空發動機[26]RUL 預測的應用。TSBP 方法在2008 年PHM 數據挑戰競賽中以5 636.06的懲罰分數摘得桂冠[64],文獻[72]通過神經網絡濾波將懲罰分數進一步減小。增強的相似性方法大幅降低了懲罰分數,結合自編碼器神經網絡的基于多時間尺度健康指標相似性的預測方法將懲罰分數進一步縮小。隨著研究的深入,相似性方法與神經網絡結合將是未來發展的大方向。

表3 基于相似性的RUL 預測方法Table 3 RUL prediction method based on similarity
2.2.5 神經網絡方法
ANN 是由大量的處理單元(神經元)互相連接而形成的復雜網絡結構,是對人腦組織結構和運行機制的某種抽象、簡化和模擬,圖5(a)所示為簡單的神經網絡模型。ANN 可以實現仿真、二值圖像識別和預測等功能,是處理非線性系統的有力工具。神經網絡的短期趨勢預測和基于多項式擬合相融合的RUL 預測方法被應用于風電齒輪箱[74],其預測流程如圖5(b)所示,首先對采集到的振動數據進行頻譜分析,得到軸承故障,接著計算并選擇反映故障部件退化趨勢的特征指標作為預測對象,同時設置各特征指標的閾值,然后再使用神經網絡預測所選特征指標的短期趨勢并擬合表征特征指標長期趨勢的多項式曲線,通過觀察歷史和短期預測特征的形狀確定擬合曲線的類型,最后通過計算擬合曲線與預先設定的閾值的交點來估計RUL。文獻[75]應用ANN 和自適應神經模糊推理系統建立的預測水管魯棒性的計算模型來訓練和測試獲得的現場數據,能夠有效識別影響RUL預測的重要參數。隨著神經網絡的發展,深度神經網絡(Deep neural networks,DNN)也被應用到RUL 預測中,文獻[76]提出分層深度神經網絡的RUL 預測方法。該方法為每個健康階段構建RUL 模型,最后應用平滑算子得到更精確的RUL預測值。反向傳播(Back propagation,BP)神經網絡是一種通過迭代優化實現的有監督學習算法,用于解決分類或回歸問題,一種改進的BP 神經網絡被用來實現飛機發動機RUL 預測[77],該方法采取在損失函數中加入一個相鄰差分項的方法來適當增加正則化,這種相鄰差分BP 神經網絡設計能夠更好的學習退化過程中任意一點與對應RUL 之間的映射關系,有較好的預測精度。考慮到誤差對BP 神經網絡精度的影響,UKF 與BP 神經網絡被結合起來,首先利用UKF 算法獲得基于估計模型的預測,并建立原始誤差序列,然后誤差序列被BP神經網絡用來預測UKF 未來殘差,最后使用預測殘差修正UKF 的預測結果,實現鋰電池的RUL 預測[78]。文獻[79]使用自組織映射(Self-organizing map,SOM)獲取最小量化誤差指標,訓練聚焦于退化周期的BP 神經網絡,建立了一種實用的滾珠軸承RUL 預測模型,相比于式(7)具有更高的預測精度。文獻[80]構建了一個綜合評價函數來選擇優良的時域、頻域和時頻域退化特征,并使用SOM網絡將特征融合成一維HI 曲線,構建出表征風力發電機組健康狀態的HI 曲線。在此基礎上采用果蠅優化算法優化的改進PF 對小風力渦輪機變速箱的剩余使用壽命進行預測[81]。
CNN 是典型的深度學習模型,基本結構由輸入層、卷積層、池化層、全連接層和輸出層組成。考慮到CNN 強大的特征提取能力,基于雙CNN 模型結構的智能RUL 預測方法被提出[82]。如圖5(c)所示,具體預測過程包括兩個階段:首先利用第1個CNN 模型和提出的“3/5”原則識別出初始故障點;然后構建第2 個CNN 模型進行RUL 預測。為了反映RUL 估計與健康狀態檢測過程的相關性,卷積神經網絡與多任務學習(Multi task learning,MTL)方法結合[83],組織了一個共享網絡和兩個特定于任務的網絡。如圖5(d)所示,在MTL 模型中,利用卷積神經網絡層作為共享層的基本結構,從復雜信號中提取全局特征,原始傳感器數據直接輸入到基于CNN 的MTL 結構中,利用多變量1~D 濾波器進行特征提取,反映了多傳感器數據之間的時變關系。為了提高滾動軸承缺陷漸進狀態下RUL 的預測精度,提高對個體差異和振動特征波動的魯棒性,Kitai 等在2021 年提出了一種基于CNN 和層次貝葉斯回歸的RUL 預測框架[84],通過考慮RUL 的退化條件和個體差異,可以生成具有概率分布的單調RUL 預測曲線,提高RUL 預測精度。文獻[85]引入可以同時提取正向和反向特征的雙向長短期記憶網絡(Bi-directional long-short term memory,BiLSTM),提出了一種基于CNN 和BiLSTM 網絡的雙通道混合預測模型從原始傳感器數據中提取深層特征。這種混合模型將從第1通道和第2 通道提取的特征數據矩陣串聯起來,輸入到全連接層中,并采用丟失輸出(Dropout)技術來防止過擬合,然后利用包含神經元的回歸層對目標RUL 進行預測。隨著CNN 的發展,可轉移卷積神經網絡(Transferable convolutional neural network,TCNN)也被提出,并結合多核最大平均差異用于RUL 的預測[86]。該方案利用多層CNN 同時提取源域和目標域樣本的退化特征,利用多核最大平均差異測量提取兩個域之間的分布差異并與源域的預測誤差相結合形成優化目標,再采用Adam 優化器對TCNN 進行訓練,最后將測試數據輸入訓練好的TCNN,輸出RUL 預測值。一種基于多層自關注和時間卷積網絡的RUL 預測方法被提出用來改善CNN 網絡過深時容易出現梯度消失的問題[87]。該方法首先利用多層自關注對不同通道和不同時間步自適應分配權重,然后通過采用了擴張卷積和剩余連接的TCN 得到數據的特征,最后有效預測了渦扇發動機的RUL。
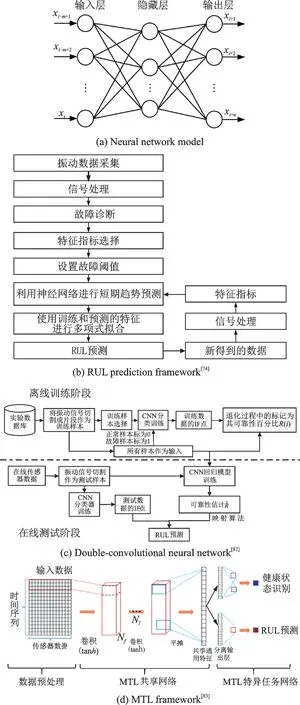
圖5 基于神經網絡的RUL 預測方法Fig.5 RUL prediction methods based on neural network
DCNN 也被用于RUL 預測,使用新的特征提取方法在時域和頻域上針對不同類型的數據在不同場景、不同預測模型相結合,得到適合于DCNN的特征,將所提取的特征輸入到DCNN 中進行軸承的RUL 預測[88]。同樣為了提高預測模型的自適應性,將自適應批量歸一化(Adaptive batch normalization,AdaBN)與DCNN 相結合,將滑動時間窗和改進的分段線性RUL 函數也引入其中,提出一種自適應性RUL 預測模型[89]。該AdaBN-DCNN模型不僅可以提高預測的準確性,而且可以適應不同神經網絡下的預測任務。Yang 等提出一種新型DCNN 使用多個卷積核組成的核模塊用于特征提取,降低了時間維度上的參數,并能夠利用任意時間間隔內連續時間樣本的數據進行RUL 預測[90]。該網絡所設計的新的預測內核模塊,可以自動選擇內核,進一步提高了網絡的特征提取能力。隨后采用貝葉斯優化方法自動選擇網絡結構和超參數改進AdaBN-DCNN 模型[91],能夠對不同數據域具有自適應能力,并且能夠在更短的時間內建立性能更好的RUL 預測模型。類似于文獻[83]的多任務學習,多尺度也被應用到深度卷積神經網絡中,提出了多尺度深度卷積神經網絡(Multi-scale deep convolutional neural network,MS-DCNN)[92],MS-DCNN有3 個多尺度塊,在每個塊上并行地進行3 種不同大小的卷積運算。通過提取不同尺度的特征,提高了網絡學習復雜特征的能力。Zhang 等提出了自適應時空圖卷積神經網絡[93],在空間領域以動態圖神經網絡來學習傳感器的空間關系;在時域中利用堆疊的擴展1D-CNN 來捕獲傳感器輸入信號的長距離依賴性。這兩個部件組合在一起實現了渦扇發動機數據的性能預測。隨后他們改變之前空間領域處理方式,提出ASTGNN-M 和ASTGNN-A 兩個空間圖卷積層,從時變信號中自適應學習空間結構,建立了高階時空特征學習的自適應時空超圖神經網絡模型[94],該模型能夠更有效地學習傳感器信號的圖和超圖結構,并在測試中取得優于自適應時空圖卷積神經網絡的性能。
RNN 具有記憶性,在對序列數據的非線性特征的學習方面具有很大的優勢,結構如圖6(a)所示,因此,RNN 在RUL 預測方面同樣體現出了巨大的潛力。Guo 等提出一種基于RNN 的軸承RUL 預測健康指標(Recurrent neural network based health indicator,RNN-HI)[95],首先將相關相似度特征與經典時頻特征相結合,形成原始特征集;然后利用單調性和相關性度量,選取最敏感的特征;最后將選擇的特征送入RNN 來構建RNN-HI,有利于承載RUL 預測。不同于前者使用RNN 來構建HI,一種新的循環卷積神經網絡(Recurrent convolutional neural network,RCNN)框架被提出[96],首先構造遞歸卷積層來建模不同退化狀態的時間依賴性,然后利用變分推理對RCNN 在RUL 預測中的不確定性進行量化。Dong 等提出將RNN 與LSTM 結合進行RUL 預測[97],首先利用LSTM 單元來捕獲和記憶傳感器信號的數據特征,再通過RNN 學習所有產品故障數據的特征,最后生成估計模型,映射RUL 的向量信息。回聲狀態網絡(Echo state network,ESN)是RNN 的一個分支,經典RNN 中的梯度消失問題在ESN 中可以得到避免,這使得ESN 適合處理長期依賴關系時間序列。不同于文獻[57],使用基于ESN 的預測方法來估計MOSFET 的RUL[98],該方法將導通電阻作為健康指標,通過輸入歷史運行到故障數據和粒子濾波方法來訓練基于ESN 的預測模型,實現實時RUL 預測。基于相似度的方法與ESN 相結合,也可以實現RUL 預測[99],首先,采用PCA 對數據進行預處理,得到退化軌跡,然后采用歐氏距離計算不同退化軌跡之間的相似度,最后使用相似度最高的軌跡在ESN 中進行訓練,有效地預測了航空發動機的退化軌跡。
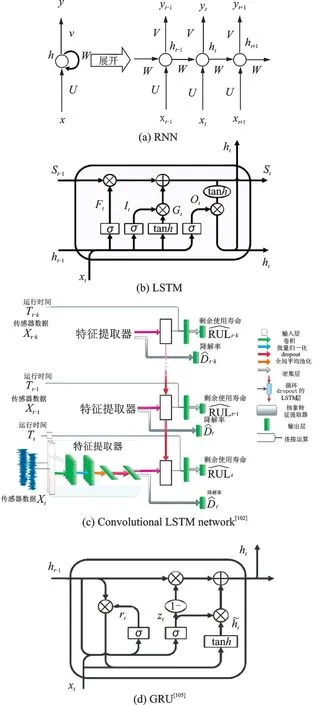
圖6 用于RUL 預測的網絡結構Fig.6 Network architectures for RUL prediction
LSTM 是為了解決一般的RNN 存在的長期依賴問題而專門設計出來的,如圖6(b)所示,由于它獨特的設計結構,使得LSTM 更適合處理和預測時間序列中間隔和延遲非常長的事件。文獻[100]提出了一種基于LSTM 的航空發動機故障診斷與RUL 預測,該方法能夠在復雜運行模式和混合退化情況下提供準確的RUL 預測和故障發生概率。另一種基于混合長-短序列的發動機RUL 預測模型針對長序列和短序列分別利用LSTM 和梯度推進回歸法實現[101],然后利用BP 神經網絡對長序列與短序列的RUL 結果進行分析,得到混合序列預測結果。考慮到CNN 的強大特征提取能力,構建了基于卷積和長期短期記憶循環單元的端到端深度魯棒估計框架[102]。如圖6(c)所示,該神經網絡首先利用卷積層直接從傳感器數據中提取局部特征,然后引入LSTM 層捕捉退化過程,最后利用LSTM 輸出和預測時間值估計RUL。同樣結合了LSTM 和CNN 的有向無環圖(Directed acyclic graph,DAG)網絡被用來預測RUL[103]。這種DAG 網絡有LSTM 和CNN 兩條路徑。這兩條路徑之間沒有相關性,考慮到兩條路徑的輸出會影響RUL 預測,采用了不同于文獻[101]最后添加的BP 神經網絡,構建的DAG 網絡是一個整體模型,可以根據預測誤差對網絡中的各個參數進行校正,對渦扇發動機展現了優秀的RUL 預測能力。全卷積層一維卷積神經網絡(1-FCLCNN)也與LSTM 相結合[104],對多場景、多時間點數據進行有效特征提取,以提高RUL 預測精度。使用LSTM 和1-FCLCNN 分別提取數據集的時空特征,然后將這兩種特征進行融合,作為下一個CNN 的輸入,從而獲得目標RUL。為了減少訓練時間,提高網絡性能,提出了一種簡化的改進于LSTM 結構網絡的門控循環單元(Gated recurrent unit,GRU),如圖6(d)所示,將LSTM中的門數從4 個減少至GRU 中的2 個,該網絡一經提出很快得到了大量的應用,由此提出一種基于門控循環單元的循環神經網絡預測非線性退化過程的RUL[105]。使用一種能通用的兩步法預測非線性退化過程的RUL 方法來解決退化建模中的非線性問題,首先使用核主成分分析進行非線性特征提取,通過減小維數,有效地避免模型參數過多而引起的過擬合;最后,利用參數更少的LSTM 簡化網絡GRU,用于預測RUL。
也有其他新型神經網絡方法也被提出用來進行RUL 的預測,文獻[106]研究了退化過程如何受到單元特定操作條件的影響,提出了一種基于非線性自回歸神經網絡的預測建模方法,用于計算動態運行條件下退化系統的RUL。該方法包括兩個過程:(1)基于數百個相同單元的運行到失效時間序列傳感器數據集,建立離線訓練過程,對退化規律和失效區域進行建模;(2)構建在線預測流程,對測試單元的RUL 進行預測。
表4 中研究對象為航空發動機[26]與軸承[24]。通過其與表1、3 的對比,可以看出神經網絡在RUL 預測上的巨大優勢。得益于神經網絡強大的特征提取能力和非線性模型構建能力,神經網絡的應用使得RMSE 有大幅度的降低。CNN 通過與其他方法的組合將RMSE 逐步降低,DCNN 在預測中展現了略優于CNN 的效果。各種方法的組合能夠合理運用各方法的優勢,并彌補其他方法的不足,使得RUL 預測更加傾向于多方法的組合運用,而不是單方法預測的小幅提升。因此RUL 預測的未來發展方向將更大可能向多方法的融合方向進行研究。
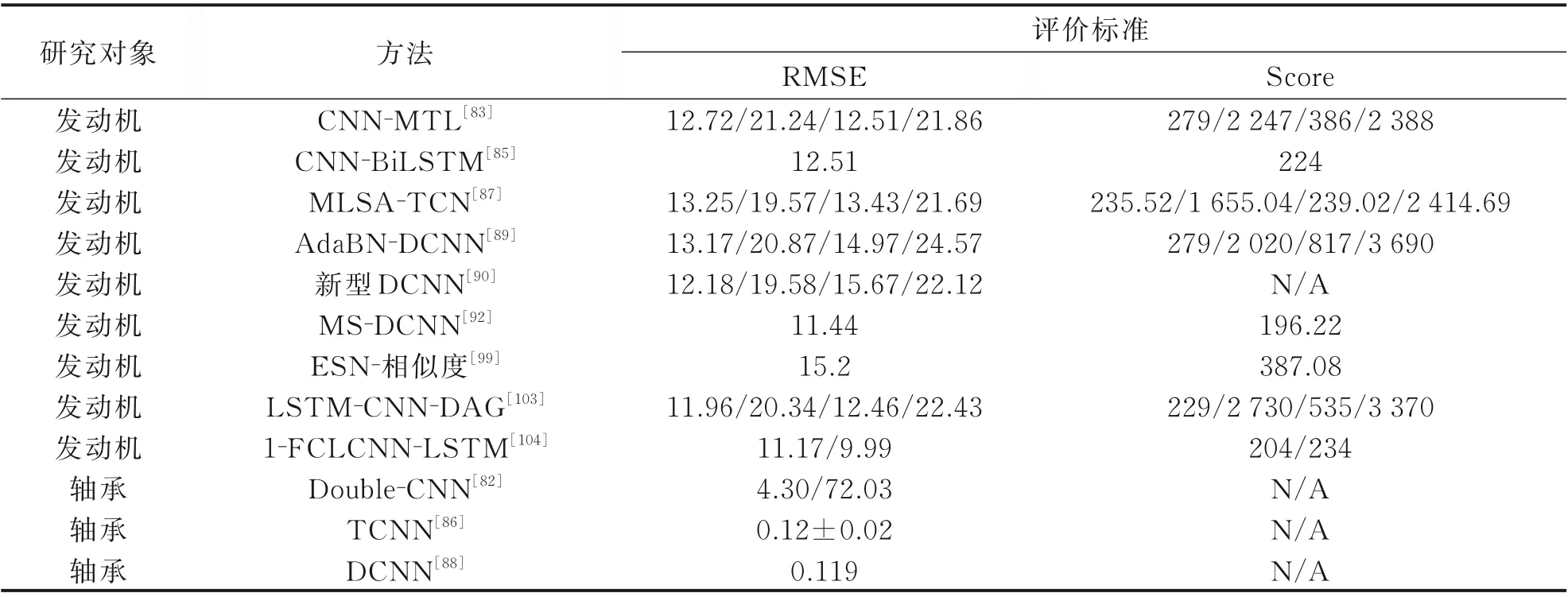
表4 基于神經網絡的RUL 預測Table 4 RUL prediction based on neural networks
2.2.6 對抗學習與遷移學習
生成對抗網絡(Generative adversarial network,GAN)是2014 年由Goodfellow 等[107]提出的一種網絡訓練框架,該框架僅有兩個組成部分:生成器和判別器。GAN 的核心思想來源于博弈論中的零和博弈,其中生成器通過學習訓練集數據的特征,在判別器的指導下,將隨機噪聲分布盡量擬合為訓練數據的真實分布,從而生成具有訓練集特征的相似數據。判別器用來判斷數據是真實的還是生成器生成的假數據,并反饋給生成器。兩個網絡互相反饋訓練,直到生成器生成的數據能夠通過判別器的真實性判斷。
GAN 多用于小樣本數據的增強,以改善數據不足的困境。文獻[108]為了解決行星齒輪箱故障診斷的故障樣本數量較少的問題,使用GAN 進行數據擴充,再使用堆疊去噪自編碼器方法實現故障診斷。基于信息最小二乘生成對抗網絡[109],同樣用于行星輪軸承數據的擴充,結合行動者-評論家算法實現滾動軸承剩余壽命預測。隨后又將門控循環單元神經網絡與條件生成對抗網絡相結合,構建C-DRGAN,再結合動作探索方法同樣實現滾動軸承剩余壽命預測[110],并將預測平均準確率由95.84%提升至96%以上。半監督生成對抗網絡回歸模型利用條件多任務目標函數從懸架歷史中捕獲有用的信息,將相似的故障與懸架歷史之間的統計信息進行最大程度的匹配[111],通過對抗性訓練,模型對噪聲和多模態數據的泛化效果顯著提高,由此提高了RUL 預測效果。對抗網絡也被應用到DNN 模型訓練中,文獻[112]中構建了包含一對與單調性相關的和一對與范圍相關的對抗神經網絡,在每對網絡在迭代中進行對抗比較,直到滿足模型要求。
GAN 在無監督學習和遷移學習方面有著優異的性能,它可以利用有限的標記數據和豐富的非標記數據提供更高的分類精度。文獻[113]在不平衡數據集上訓練不同架構的CNN 模型與GAN 在交互模式下工作,訓練多個CNN 的集合,然后對罕見類生成對抗樣本,進一步細化集合模型,實驗表明此方法能一定程度上提高某些類別的性能。一種新的基于GAN的主動半監督學習方法(Active semi-supervised learning with GANs,ASSL-GANs)[114],利用GAN進行主動半監督學習,在鑒別器、生成器和分類器之間進行對抗或合作學習,用來研究標記樣本和未標記樣本之間的潛在相關性,以充分獲得數據分布的洞察力。精準的分類和數據打標有助于RUL 預測準確性的提升。
遷移學習和GAN 都是為了應對發生失效的數據難以收集或數據不足的情況。不同于GAN去生成數據,遷移學習是利用目前已有預測模型遷移到相關研究中去提高RUL 預測性能。文獻[115]提出了一種基于雙向長短時記憶(Bidirectional long short term memory,BLSTM)遞歸神經網絡的遷移學習算法,該算法首先在不同但相關的數據集上訓練模型,然后RUL 預測模型從源域遷移到目標域,再由目標數據集進行微調,取得了更好的效果。文獻[116]使用自組織共識模型搜尋不同領域中的數據差異,并進行知識的遷移,取得不輸于傳統及其他方法的預測效果。稀疏自動編解碼器的編碼器部分也可以進行參數遷移[117],隨后固定編碼器部分參數,以目標域的數據更新解碼器部分參數的形式進行模型的遷移,實現了在刀具數據上的有效遷移。遷移成分分析法被用來提取不同軸承的公共特征[118],然后以物理特征遷移的方式將特征輸入到支持向量機,實現軸承RUL 預測。基于多層感知器(Multilayer perceptron,MLP)的遷移學習被用來解決分布差異問題,構建了RUL預測和域適應兩個模塊[119],RUL 預測模塊負責找出提取的特征與相應的RUL 之間的關系;域自適應模塊通過域分類器和域分布差異度量獲得域不變特征。實現了一種工況下有標記數據訓練的RUL 預測模型有效地預測另一種工況下無標記數據的RUL。在遷移學習的基礎上提出由條件識別模塊和域適應模塊組成的深度卷積遷移學習網絡[120],與非遷移學習方法相比,有著更高的軸承健康狀態識別精度。
對抗性訓練也是遷移學習常用的方法,通過建立源域與目標域之間的映射,將域分布差異調整到最小,便可將源域學習到的知識應用于目標域,實際上就是以博弈思想為核心的對抗式訓練來實現遷移學習。文獻[121]提出利用LSTM 進行預測的域適應方法,使用領域對抗神經網絡的方法,以適應剩余有效壽命估計的目標領域傳感器信息,該方法對于不同的運行條件和故障模式,能夠提供更可靠的RUL 預測。另有學者同樣使用LSTM 網絡作為時間特征提取器,并進行類似于對抗判別域自適應的對抗學習,以學習領域中的不變特征[122],該方法在重載貨車車輪的磨耗數據進行了有效的RUL 預測。
對抗學習與遷移學習是近年來興起的深度學習方法,有助于解決基于數據驅動模型的RUL 預測中最關鍵的數據問題,因此相關研究有著爆發性增長的趨勢。對抗網絡擴充數據后,相關研究對象的RUL 預測效果隨著數據量的增強都有一定的提升。遷移學習使得模型的建立變得簡單,能夠有效利用同類型數據,從而降低建模成本,提高數據有效利用率。對抗性訓練為遷移學習提供了優化的參數遷移方式,通過無監督學習便可實現參數有效遷移。
3 總結與展望
本文對基于物理模型和數據驅動模型的RUL預測方法的優缺點進行比較,如表5 所示。物理模型直接從基本原理和對物理機制的理解中導出。當對系統擁有可用且足夠完整的邏輯認知時,物理模型往往顯著優于其他類型的模型。但是許多實際系統和組件的基礎物理知識不確切或不可用,而且其中完整邏輯的獲取十分困難。一般情況下,導致失效的底層物理過程并沒有被完全理解,必須簡化假設以促進模型開發。在物理模型開發中做出的假設可能不完全適用于現實世界的系統,從而限制了失效模型的適用性。而且對于大型、復雜的系統來說,失效模型的物理特性通常是不可用的、不精確的或不及時的。另外,因為開發的模型很少能夠滿足所需的靈活性,以匹配新場景下進行預測的條件,所以應用領域受到很大限制。基于數據驅動模型的RUL 預測就不需要專業知識,可以通過對已有數據的深度挖掘來獲取其退化的特征,從而實現RUL 預測。

表5 各種RUL 預測方法優缺點對比Table 5 Comparison of advantages and disadvantages of various RUL prediction methods
支持向量機具有處理非線性映射問題的能力,在樣本數量較少的情況下也有優異的表現,這使得支持向量機在RUL 預測中得到了廣泛的應用。提高監測數據質量和從監測信息中提取有用特征是重要的研究方向。另外,如今主要研究對象僅包括軸承和電池,對支持向量機的應用進行更多的研究也是具有很大前景的。維納過程具有良好的數學性質和物理解釋能力,它可以很好地描述系統的非單調動態特性。未來需要在預測數據下進行更多的決策研究,增強模型參數的修正。高斯過程回歸是一種靈活的非參數貝葉斯模型,允許在函數上直接定義先驗概率分布,可以利用高斯過程對函數從輸入空間到目標空間的非線性映射進行建模,對高維、小樣本、非線性、復雜的分類和回歸問題具有良好的適用性。對核函數的研究是一直以來研究的重點,未來的研究應該考慮結合其他方法來擴展其在不同領域的應用。相似性方法主要是基于退化模型的建立來實現基于實例的預測。需要退化模型的有效構建和完整生命周期數據的獲取。可以考慮引入數據擴充算法,實現在原始有限數據基礎上的擴充。
神經網絡方法具有強大的特征提取和非線性映射構建能力,成為當今理論科研和應用研究的熱點。但是神經網絡存在建模訓練成本高昂、模型復雜以及可解釋性不強等缺點,導致它的使用受到諸多限制,但是強大的預測能力和提升的算力注定其將是未來RUL 預測研究的重點。結合對抗學習和遷移學習能夠解決神經網絡中存在的數據不足和模型建立困難的問題。神經網絡訓練需要大量經驗數據的問題可以通過數據擴充的方式來解決,對于傳感器數據一般可以采用復制、插值、加噪聲和使用生成對抗網絡生產數據等方法。另外對于小樣本場景,可以考慮在神經網絡中加入注意力機制以增加有效特征的權重。對于降低建模訓練成本方面,可以使用輕型神經網絡減少網絡的參數量級。神經網絡同樣存在泛化性不強的問題,對于不同的預測對象往往需要重新訓練模型,因此自適應方法也是學者研究的方向。深度神經網絡通常過于復雜,一個神經網絡往往涉及巨量計算,學者們很難對其內在工作機理進行解釋,這也正是神經網絡的痛點。未來學者應該考慮原理性解釋與神經網絡的結合,有著合理性解釋的RUL 預測才是最合理的。
本文總結了近年來對RUL 預測的方法,對基于物理模型和基于數據驅動模型的RUL 預測方法進行綜述,并分析其優缺點。最后根據當前RUL預測研究的熱點,對未來研究方向提出了發展性建議。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
