基于深度學習PyTorch 框架下YOLOv3 的交通信號燈檢測
2022-07-02 00:49:18李蔣
汽車電器 2022年6期
關鍵詞:檢測
李 蔣
(蘇州建設交通高等職業技術學校, 江蘇 蘇州 215100)
1 引言
2021年9月22日, 華為發布 《智能世界2030》 報告, 多維探索了未來10年的智能化發展趨勢。 報告中明確預測,到2030年全球電動汽車占所銷售汽車總量的比例將會達到50%, 中國自動駕駛新車滲透率將會達到20%, 整車算力超過5000TOPS, 智能汽車網聯化 (C-V2X) 滲透率預計會達到60%。 中國國家發展改革委員會等11個部委于2020年2月聯合印發了 《智能汽車創新發展戰略》, 提出到2025年實現有條件自動駕駛的智能汽車達到規模化生產, 實現高度自動駕駛的智能汽車在特定環境下市場化應用, 到2050年全面建成中國標準智能汽車體系。
在這樣的時代背景下, 中國自動駕駛汽車技術領域的研究開始快車模式。 在整個自動駕駛技術研究領域中, 復雜環境中目標物體的識別和判別一直以來都屬于一項高難度的挑戰, 也是亟需要解決的重點任務之一。 本文基于YOLO算法對實景圖像進行目標識別和檢測, 以期可以進一步在視頻流中進行交通標志、 行人、 汽車等物體的識別和檢測, 不僅是解決一個識別和檢測的問題, 更是提出一種解決問題的思路和方法。
2 目標檢測經典方法概述
目前, 在自動駕駛技術研究領域比較流行的目標檢測算法, 主要是CNN (卷積神經網絡)、 R-CNN、 faster RCNN、 SSD和YOLO等。 因為設計這些算法的初衷都是為了格物致知, 所以每種算法都有自己十分突出的優點, 但同時也都存在一些不可回避的缺點, 筆者簡單介紹幾種典型算法的優缺點。
2.1 CNN卷積神經網絡
CNN是從視覺皮層的生物學上獲得啟發, 首先將圖像作為輸入傳遞到網絡, 然后通過各種卷積層和池化層的處理, 最后以對象類別的形式獲得輸出。 對于每個輸入對象,會得到一個相應類別作為輸出, 因此可以使用這種技術來檢測圖像中的各種對象。 CNN網絡結構如圖1所示。
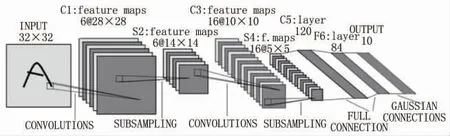
圖1 CNN網絡結構
使用這種方法會面臨的問題在于圖像中的對象可以具有不同的寬高比和空間位置。 例如, 在某些情況下, 對象可能覆蓋了大部分圖像, 而在其他情況下, 對象可能只覆蓋圖像的一小部分, 并且對象的形狀也可能不同。 為了精準判斷, 需要劃分大量的區域進行采集、 識別和判定, 這會生成大量的數據, 而且要達到準確判定目標需要花費大量的計算時間。
2.2 R-CNN
R-CNN算法不是在大量區域上工作, 而是在圖像中提出了一堆方框, 并檢查這些方框中是否包含任何對象。 RCNN使用選擇性搜索從圖像中提取這些框。 R-CNN網絡結構如圖2所示。
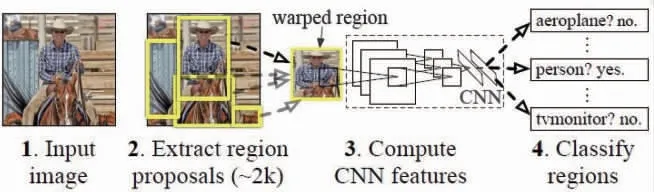
圖2 R-CNN網絡結構
R-CNN模型存在的主要問題是不能快速定位物體, 原因是模型算法對于單元格產生候選框過多, 且易重復, 而每一次選擇都需要代入卷積神經網絡模型加以識別, 得出物體的預測置信度和具體坐標位置, 這一步驟在單一圖片的處理上會消耗極多的時間。 這使得R-CNN在面對大量數據集時幾乎不可能被應用。
2.3 Faster R-CNN
Faster R-CNN使用 “區域提議網絡”, 即RPN。 RPN將圖像特征映射作為輸入, 并生成一組提議對象, 每個對象提議都以對象分數作為輸出。Faster R-CNN網絡結構如圖3所示。
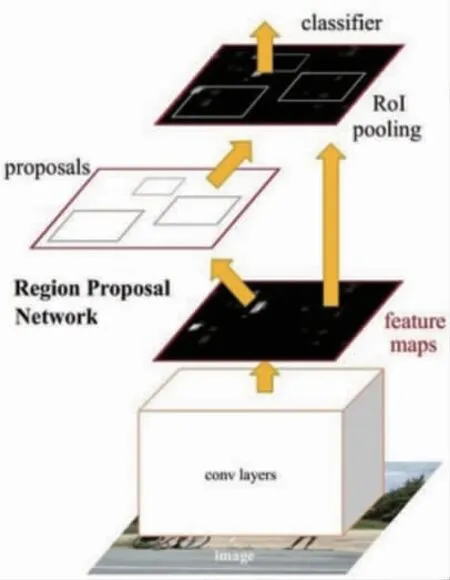
圖3 Faster R-CNN網絡結構
但是所有對象檢測算法都使用區域來識別對象, 且網絡不會一次查看完整圖像, 而是按順序關注圖像的某些部分, 這樣會帶來兩個復雜性的問題: ①該算法需要多次通過單個圖像來提取到所有對象; ②由于不是端到端的算法, 不同的系統一個接一個地工作, 整體系統的識別性能對于先前系統的表現效果有較大依賴, 對最終識別結果也有較大影響。
3 相關介紹
3.1 PyTorch
PyTorch 是一個開源的深度學習框架, 該框架由Facebook人工智能研究院的Torch7團隊開發, 它的底層基于Torch, 但實現與運用全部是由python來完成。 該框架主要用于人工智能領域的科學研究與應用開發。
PyTroch最主要的功能有兩個: 一是擁有GPU張量, 該張量可以通過GPU加速, 達到在短時間內處理大數據的要求; 二是支持動態神經網絡, 可逐層對神經網絡進行修改,并且神經網絡具備自動求導的功能。 深度學習框架PyTroch如圖4所示。

圖4 深度學習框架PyTroch
3.2 YOLO
YOLO (全稱為You Only Look Once, 譯為: 你只看一次), 是一個經典的one-stage的算法, 該算法與two-stage的算法相比, 減少或簡化了預選的步驟, 直接把檢測問題轉換為回歸問題, 只需要一個CNN網絡就可以了。 YOLO最為核心的優勢就是速度非常快, 非常適合做實時的檢測識別任務, 應用在自動駕駛技師領域, 尤其是現在基于攝像頭的視頻處理就需要很快的速度。 當然它同樣存在缺點, 因為少了預選的步驟, 在檢測識別的品質上通常不會有預期的那么好。 YOLOv3與其他目標檢測算法對比如圖5所示。
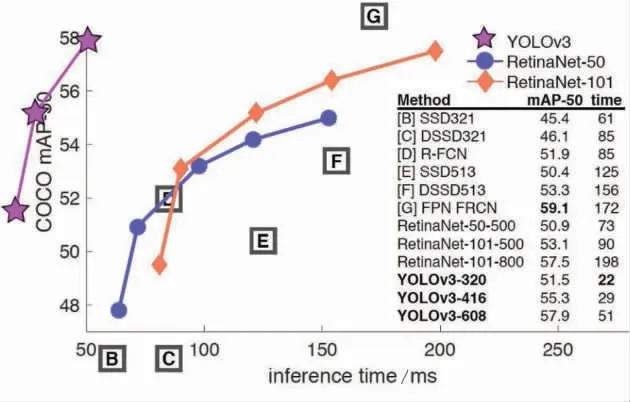
圖5 YOLOv3與其他目標檢測算法對比
YOLOv3在當年和其他算法相比, 無論是速度還是mAP(mean Average Precision, 綜合衡量檢測效果) 值都遠遠優于其他算法。 YOLO目前已經有5個版本, v3版本是其中最經典的一個版本, 應用率也較為廣泛。 因此, 本文主要應用YOLOv3版本進行目標檢測。
4 YOLOv3的版本改進及運作過程
4.1 v3版本改進
YOLOv3和之前的版本相比, 整體的網絡架構沒有改變, 但YOLOv3相較之前版本有很大的提升, 其中最大的改進有以下4點。
1) 改進網絡結構, YOLOv3僅使用卷積層, 使其成為一個全卷積網絡。 作者提出一個新的特征提取網絡——Darknet-53, 它包含53個卷積層, 每個后面都跟隨著batch normalization層和leaky ReLU層, 沒有池化層, 使用步幅為2的卷積層替代池化層進行特征圖的降采樣過程, 這樣可以有效阻止由于池化層導致的低層級特征的損失。 Darknet-53基本網絡結構如圖6所示。
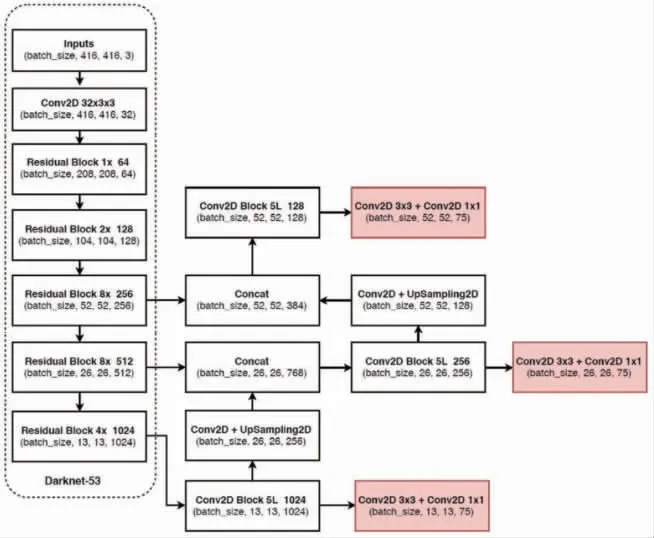
圖6 Darknet-53基本網絡結構
2) 特征做得更加的細致, 融入多尺度特征圖信息來預測不同規格的物體, 在多個尺度的融合特征圖上分別獨立做檢測。 由于YOLO是針對于目標識別速度的算法, 使其更加適合小目標檢測。
3) Anchor (先驗框) 更加豐富, 為了能夠全面檢測到不同大小的物體, 設計了3種scale, 每種3個規格, 一共9種, 其初始值依舊由K-means聚類算法產生。 YOLOv3先驗框種類如圖7所示。
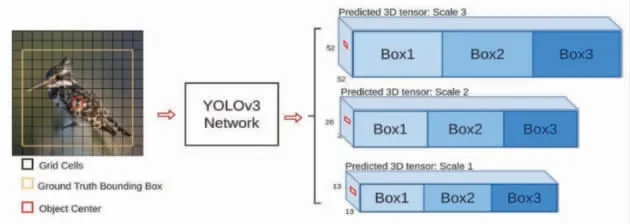
圖7 YOLOv3先驗框種類
4) YOLOv3一方面采用全卷積 (YOLOv2中采用池化層做特征圖的下采樣, v3中采用卷積層來實現), 另一方面引入殘差 (Residual) 結構, Res結構可以很好地控制梯度的傳播, 避免出現梯度消失或者爆炸等不利于訓練的情形。這使得訓練深層網絡難度大大減小, 因此才可以將網絡做到53層, 精度提升比較明顯。 此外, softmax (歸一化指數函數) 的改進, 可以預測多標簽任務。
4.2 YOLOv3運作過程
YOLOv3實現原理: 通過輸入416×416像素的圖片, 將圖片劃分成13×13、 26×26、 52×52大小的網格圖, 通過網絡去判斷我們需要識別的類別的中心點分別在哪一個網格的置信度比較大, 結合3種特征圖輸出的置信度, 只保留置信度最大的框, 最終通過自己認為設置的先驗框和真實類別的中心點反算出真實框的位置。
5 基于YOLOv3訓練自己的數據與任務
5.1 數據信息標注
首先安裝labelme工具, 對于自己的數據集進行打標簽工作。 如下:

安裝完成, 運行軟件, 把自己需要訓練的數據集打上標簽。 訓練的數據越多, 最終目標檢測的效果可能越好。雖然我們使用了遷移學習, 但一般也需要上千張圖片才可以達到一個比較理想的結果, 根據自己的需要調整標注訓練集。 數據集打標簽如圖8所示。
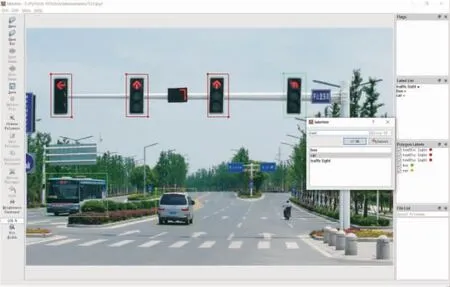
圖8 數據集打標簽
標注完成, 生成.json文件, 但是該文件還不可以直接使用, 需要轉換格式。
5.2 生成模型所需配置文件
利用Git工具編寫create_custom_model.sh 文檔。 因為本文研究的只是一個三分類任務, 所以參數定為3, 運行后會自動生成一個YOLOv3-custom.cfg配置文件。 修改.sh配置文檔如圖9所示。
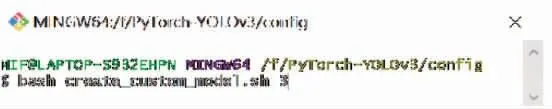
圖9 修改.sh配置文檔
5.3 json格式轉換成YOLOv3所需輸入
因為labelme中生成標簽的格式是X1、 X2、 Y1、 Y2實際坐標值, 而YOLOv3中需要的格式是中心點的X1、 Y1,以及W和H值, 并且數值為圖片中的相對位置 (取值范圍0-1)。 因此, 需要對標簽中的坐標值進行轉換。 利用相關代碼對坐標格式進行轉換, 轉換后形成YOLOv3所需的TXT文件。
5.4 完成輸入數據準備工作
首先, 我們還需要完善訓練過程中數據與標簽的路徑。轉換后的標簽文件文件名要和圖像的文件名完全一致, 文件分別放在不同的相應文件夾中。
接下來, 把.names文件中的類別改成自己需要做的類別名稱, 例如person、 car、 traffic light等。 然后, 修改train.txt和valid.txt中的文件對應的路徑。 最后, 修改custom.data文件中的配置。
5.5 運行參數配置修改
訓練代碼train.py需要設置運行參數如下:--model_def config/YOLOv3-custom.cfg--data_config config/custom.data--pretrained_weights weights/darknet53.conv.74 #如果需要在別人預訓練權重基礎上進行遷移學習, 則需要配置該項運行參數 (不進行遷移學習則需要上萬張圖片的數據量)。
5.6 訓練模型并測試效果
本文在實驗中利用自己標注的1000張數據集進行訓練,由于數據集只做了三分類, 標注工作量尚可。 訓練過程中采用了darknet53預訓練模型進行遷移學習, 減少由于數據量較少造成的訓練結果不理想。 利用訓練好的模型進行目標檢測, 通過對100張圖片進行測試, 發現無論mAP值還是檢測速度都比較滿意, 實際目標檢測結果如圖10所示。

圖10 實際目標檢測結果
6 總結
本文利用YOLOv3進行目標檢測與識別訓練, 主要針對交通信號燈進行試驗。 該算法也可運用在視頻流中的目標檢測, 并且取得了較高的檢測準確率和檢測速度, 基本滿足了圖片檢測和視頻檢測的預期需求。 同時, 該方法不局限于交通監控視頻中的車輛檢測, 也可以被應用于其他領域的目標檢測與識別, 具有很好的應用場景兼容性。
但是在研究過程中, 我們嘗試將該算法移植到ubantu系統上, 試圖利用嵌入式系統進行實時攝像頭的目標檢測時, 遇到了一些軟件配置上的問題未能突破。 此外, 該檢測識別方法在光照強度不足時, 例如雨天、 夜間無照明路段等惡劣條件下可能存在誤判的情況, 還需要進一步對算法進行優化。 同行研究試驗時可以選擇YOLO在2020年推出的v4和v5版本進行嘗試, 期盼更多研究成果大家共享。
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
