專利分類序列和文本語義表示視角下的技術(shù)融合預(yù)測研究
2022-07-02 07:18:40張金柱李溢峰
情報學(xué)報 2022年6期
張金柱,李溢峰
(南京理工大學(xué)經(jīng)濟(jì)管理學(xué)院信息管理系,南京 210094)
1 引 言
信息化、數(shù)字化、網(wǎng)絡(luò)化技術(shù)快速發(fā)展,科學(xué)技術(shù)變革速度不斷加快,市場需求日新月異,行業(yè)間的競爭已逐漸由資金、規(guī)模、勞動力等轉(zhuǎn)變?yōu)榧夹g(shù)間的競爭。為了提高行業(yè)競爭力,企業(yè)通過聯(lián)盟、合并、共同研發(fā)生產(chǎn)等活動實現(xiàn)了不同技術(shù)領(lǐng)域之間的相互滲透,推動了新技術(shù)的產(chǎn)生[1]。技術(shù)融合是新技術(shù)產(chǎn)生的重要來源,提前預(yù)測潛在的技術(shù)融合成為企業(yè)獲取競爭優(yōu)勢、提高競爭能力,甚至是顛覆現(xiàn)有市場的最有效和最重要的技術(shù)手段之一。技術(shù)融合一般是指兩種或多種技術(shù)通過互相借鑒、完全利用或重組的方式形成新技術(shù)的過程[2]。而技術(shù)融合預(yù)測則是通過歷史數(shù)據(jù)計算尚未發(fā)生融合的技術(shù)之間的相似性或相關(guān)性,并以此來表示未來發(fā)生技術(shù)融合的可能性。新的技術(shù)融合可能誘發(fā)新的技術(shù)機會產(chǎn)生,進(jìn)而引發(fā)技術(shù)變革或技術(shù)創(chuàng)新,為企業(yè)帶來新穎的產(chǎn)品和服務(wù)[3-6]。因此,技術(shù)融合預(yù)測不僅是技術(shù)機會的重要來源,也是技術(shù)創(chuàng)新的基礎(chǔ)和前提,為技術(shù)創(chuàng)新提供了契機和可能,被認(rèn)為是企業(yè)保持市場地位、持續(xù)發(fā)展、避免被其他企業(yè)顛覆的關(guān)鍵影響因素。
技術(shù)融合形成原因多樣且復(fù)雜,在定量分析中主要以專利分類號代表某一技術(shù)或功能,并以多個專利分類號在同一專利中出現(xiàn)作為技術(shù)融合的外在表現(xiàn),進(jìn)而研究特定形式下的技術(shù)融合預(yù)測。目前,技術(shù)融合預(yù)測的定量分析和研究主要從三個角度展開,包括基于專利引用的技術(shù)融合預(yù)測、基于專利分類號共現(xiàn)的技術(shù)融合預(yù)測以及基于專利文本的技術(shù)融合預(yù)測。基于專利引用的技術(shù)融合預(yù)測利用專利間的引用關(guān)系構(gòu)建專利引用網(wǎng)絡(luò),通過共被引、引用頻次等信息建立衡量技術(shù)融合的指標(biāo),評估不同技術(shù)領(lǐng)域在未來產(chǎn)生融合的可能性。然而,同族專利之間常常存在自引現(xiàn)象,使引用網(wǎng)絡(luò)變得復(fù)雜冗余;尤為重要的是,專利引用需要一定的時間積累,具有一定的時間滯后性,因此多是對已有技術(shù)融合的驗證,不利于技術(shù)融合預(yù)測。基于專利分類號共現(xiàn)的技術(shù)融合預(yù)測通過獲取每篇專利文獻(xiàn)下對應(yīng)的專利分類序列,依據(jù)分類號之間兩兩形成的共現(xiàn)關(guān)系構(gòu)建共現(xiàn)網(wǎng)絡(luò),之后利用節(jié)點中心度、中介中心度等網(wǎng)絡(luò)指標(biāo),或結(jié)合標(biāo)題、摘要等外部語義特征計算分類號之間的相似度來預(yù)測可能的技術(shù)融合。由于專利分類號共現(xiàn)網(wǎng)絡(luò)通過共現(xiàn)關(guān)系構(gòu)建,往往不能體現(xiàn)專利分類號在序列中的位置特征和上下文語義,由此得到的專利分類語義表示可能存在信息丟失的問題。基于專利文本的技術(shù)融合預(yù)測主要通過外部語義特征賦予專利分類號以文本信息,輔助專利分類共現(xiàn)網(wǎng)絡(luò)進(jìn)行技術(shù)融合發(fā)現(xiàn)時,現(xiàn)有研究一般平等對待序列中的每個專利分類號,進(jìn)而賦予同樣的文本信息[7],導(dǎo)致多個專利分類號之間文本信息冗余,形成的專利分類號文本表示相似度高,區(qū)分度較低,對于技術(shù)融合的作用難以體現(xiàn);尤為重要的是,專利分類號的網(wǎng)絡(luò)表示與文本表示在融合過程中,多采用直接拼接、點乘等方式進(jìn)行,而不同領(lǐng)域中,網(wǎng)絡(luò)和文本中的每一維特征的貢獻(xiàn)程度可能并不相同,需要針對不同領(lǐng)域數(shù)據(jù)進(jìn)行針對性學(xué)習(xí),自動調(diào)整特征的權(quán)重和貢獻(xiàn)。
為了解決上述問題,本文提出了一種基于專利分類序列和文本語義融合的技術(shù)融合預(yù)測方法。首先,直接對專利分類序列進(jìn)行語義表示,減少生成共現(xiàn)網(wǎng)絡(luò)時的信息丟失,研究基于專利分類序列語義表示的技術(shù)融合預(yù)測;其次,通過分析專利分類序列中不同位置專利分類號的重要性,設(shè)計專利分類文本分配方法,并結(jié)合文本表示學(xué)習(xí)方法,研究基于專利分類文本語義表示的技術(shù)融合預(yù)測;最后,設(shè)計特征融合方法,基于機器學(xué)習(xí)方法自動學(xué)習(xí)專利分類序列和專利文本兩種語義表示中每維語義特征的貢獻(xiàn)度和權(quán)重,研究基于序列結(jié)構(gòu)和文本語義融合下的技術(shù)融合預(yù)測。
2 相關(guān)研究
本節(jié)先介紹國內(nèi)外技術(shù)融合預(yù)測研究中的常用指標(biāo)和方法,發(fā)現(xiàn)共現(xiàn)網(wǎng)絡(luò)中專利分類語義表示能力需要加強、專利分類文本賦予方式需要改進(jìn)、不同來源的多維特征需要更有效融合是目前需要解決的重要問題;接著介紹表示學(xué)習(xí)的原理和常用方法,發(fā)現(xiàn)表示學(xué)習(xí)的理論和方法可以借鑒用于技術(shù)融合預(yù)測任務(wù)。
2.1 技術(shù)融合預(yù)測相關(guān)研究
研究技術(shù)融合預(yù)測首先必須明晰技術(shù)融合的基本概念、內(nèi)涵和特征,并在此基礎(chǔ)上利用多種相似性指標(biāo)計算技術(shù)特征間的相似性來判斷技術(shù)融合在未來發(fā)生的可能性。技術(shù)融合一開始是指生產(chǎn)過程中不同產(chǎn)業(yè)間的相互依賴關(guān)系,并在產(chǎn)品、服務(wù)、技術(shù)等多個方面體現(xiàn)。Roco 等[8]將技術(shù)融合定義為來自至少兩個不同領(lǐng)域的技術(shù)通過組合產(chǎn)生一個新的技術(shù)方案,從而為研發(fā)機構(gòu)的技術(shù)創(chuàng)新提供幫助。Lind[9]將技術(shù)融合定義為由兩個不同的工業(yè)部門共享知識和技術(shù)的過程。婁巖等[10]認(rèn)為技術(shù)融合包括專利分類號的跨領(lǐng)域和跨部融合。技術(shù)融合具有多種表現(xiàn)形式,研究者多從某一側(cè)面或角度開展研究[11];在定量分析中,技術(shù)融合通常體現(xiàn)在一個專利同時具有多個專利分類號或者專利分類號間發(fā)生了引用,而預(yù)測則主要通過設(shè)計指標(biāo)計算專利分類號間的相似性或相關(guān)性來實現(xiàn)[7,11-12]。由此形成了三類主要方法,分別為基于專利引用的技術(shù)融合預(yù)測、基于專利分類號共現(xiàn)的技術(shù)融合預(yù)測以及基于專利文本的技術(shù)融合預(yù)測。
2.1.1 基于專利引用的技術(shù)融合預(yù)測
基于專利引用的技術(shù)融合預(yù)測方法多從專利之間的相互引用來表示技術(shù)之間的相互引用,而新的引用預(yù)示著新的技術(shù)融合,并據(jù)此進(jìn)行預(yù)測。由于專利之間的引用錯綜復(fù)雜,處理難度較大,Batagelj[13]通過改進(jìn)主路徑算法處理百萬節(jié)點級別的大型網(wǎng)絡(luò),并將其應(yīng)用于專利引文網(wǎng)絡(luò),預(yù)測可能產(chǎn)生鏈接的專利,并抽取技術(shù)主題發(fā)現(xiàn)技術(shù)融合;Verspa‐gen[14]、Martinelli[15]使用該算法分析燃料電池和電信交換器行業(yè)的專利引文網(wǎng)絡(luò),得到清晰的技術(shù)發(fā)展交融軌跡,根據(jù)已有的軌跡發(fā)現(xiàn)未來可能產(chǎn)生的新軌跡,以此預(yù)測未來的技術(shù)融合方向。Kim 等[16]通過構(gòu)建不同年份的專利引用矩陣,通過利用神經(jīng)網(wǎng)絡(luò)技術(shù)預(yù)測新的引用來預(yù)測新技術(shù)的融合。Park等[17]以專利有向引用網(wǎng)絡(luò)表示專利的技術(shù)知識流走向,通過文獻(xiàn)計量、邊緣中心性等指標(biāo)來預(yù)測技術(shù)知識流的未來走向,并據(jù)此預(yù)測技術(shù)融合。
以專利引用為基礎(chǔ),一些學(xué)者據(jù)此得到專利分類號間的引用關(guān)系,并通過專利分類號引用來預(yù)測技術(shù)融合。翟東升等[2]將專利引文分析與國際專利分類號(international patent classification,IPC) 分析相結(jié)合,構(gòu)建IPC 引用網(wǎng)絡(luò)描述不同領(lǐng)域之間的知識流動,進(jìn)而通過鏈接預(yù)測的方式挖掘技術(shù)融合發(fā)展趨勢。Rodriguez 等[18]根據(jù)專利分類號之間的直接引用和間接引用構(gòu)建專利引用網(wǎng)絡(luò),通過計算專利間產(chǎn)生新鏈接的可能性來預(yù)測新的技術(shù)融合。No等[19]基于專利分類代碼之間的引用關(guān)系,以融合度指標(biāo)來確定技術(shù)融合的軌跡模式,通過可視化技術(shù)展現(xiàn)專利間的前向和后向引用關(guān)系,觀察軌跡的變化進(jìn)而預(yù)測可能的技術(shù)融合。Ko 等[20]使用專利分類號之間的引文分析構(gòu)建知識流矩陣,通過計算特定技術(shù)領(lǐng)域的技術(shù)融合評價指標(biāo),展現(xiàn)技術(shù)融合趨勢可視化地圖,根據(jù)融合趨勢預(yù)測整個行業(yè)技術(shù)融合的趨勢。Han 等[21]基于熵和引力的概念提出專利分類號引用網(wǎng)絡(luò)中的技術(shù)融合度指標(biāo),進(jìn)而發(fā)現(xiàn)與目標(biāo)領(lǐng)域相關(guān)聯(lián)的多個潛在技術(shù)領(lǐng)域,為后續(xù)的技術(shù)融合預(yù)測提供指導(dǎo)。Nesta 等[22]提出幸存者相關(guān)性測度(survivor measure of relatedness) 的專利分類分析方法,使用概率方法來測度技術(shù)領(lǐng)域融合。Pennings 等[23]將專利引文網(wǎng)絡(luò)中的專利節(jié)點替換為相應(yīng)的專利分類號,依據(jù)專利分類號間引用次數(shù)來識別技術(shù)融合,并根據(jù)引用頻次的變化預(yù)測未來的技術(shù)融合熱點。
基于專利引用形成的技術(shù)融合識別指標(biāo)和方法在多個領(lǐng)域中取得了較好的效果,但同族專利自引現(xiàn)象層出不窮,導(dǎo)致一些相互引用的專利之間技術(shù)內(nèi)容可能大體相似,導(dǎo)致引用網(wǎng)絡(luò)出現(xiàn)重復(fù)和冗余信息,影響預(yù)測結(jié)果的準(zhǔn)確性;與此同時,專利引用需要一定的時間累積,造成引用網(wǎng)絡(luò)的形成具有一定的時間滯后性,不利于技術(shù)融合的預(yù)測。
2.1.2 基于專利分類號共現(xiàn)的技術(shù)融合預(yù)測
基于專利分類號共現(xiàn)的技術(shù)融合預(yù)測方法多根據(jù)專利分類號之間的共現(xiàn)關(guān)系進(jìn)行判斷,這些共現(xiàn)關(guān)系在一定程度上代表了不同技術(shù)間的依賴關(guān)系,是定量測量技術(shù)融合的外在表現(xiàn),有助于預(yù)測技術(shù)融合。陳悅等[24]把兩個或多個IPC 的共現(xiàn)關(guān)系視為一種技術(shù)融合,并根據(jù)IPC 組合的共現(xiàn)頻次變化來預(yù)測該技術(shù)融合能否成為未來的研究熱點。Cavig‐gioli[25]認(rèn)為新IPC 共現(xiàn)關(guān)系的出現(xiàn)標(biāo)志著新技術(shù)融合的誕生,并將IPC 組合中不同IPC 之間的交叉引用次數(shù)作為技術(shù)融合預(yù)測指標(biāo)。Lee 等[26]根據(jù)四位IPC 號的共現(xiàn)關(guān)系,通過關(guān)聯(lián)規(guī)則研究了技術(shù)融合的模式,并根據(jù)節(jié)點之間的相似性預(yù)測了新的融合。李丫丫等[27]以全球生物芯片產(chǎn)業(yè)為例提出基于專利的技術(shù)融合分析方法框架,運用IPC 與35 個技術(shù)分類對照體系分析生物芯片領(lǐng)域產(chǎn)業(yè)技術(shù)融合的結(jié)構(gòu),建立技術(shù)融合矩陣并評估技術(shù)融合緊密程度,最后基于多樣性指數(shù)揭示產(chǎn)業(yè)技術(shù)融合動態(tài),通過判別發(fā)展趨勢預(yù)測未來的技術(shù)融合走向。吳曉燕等[28]基于專利分類號共現(xiàn)信息,利用文獻(xiàn)計量指標(biāo)(共現(xiàn)頻次、中介中心性和突發(fā)指數(shù))把握技術(shù)融合發(fā)展態(tài)勢,分析演化軌跡并預(yù)測未來的技術(shù)融合。王宏起等[29]構(gòu)建專利IPC 共現(xiàn)網(wǎng)絡(luò),根據(jù)產(chǎn)業(yè)技術(shù)融合態(tài)勢分析,綜合考慮多技術(shù)領(lǐng)域之間相互作用對技術(shù)融合的影響,設(shè)計基于鏈路預(yù)測的Katz指標(biāo)來預(yù)測技術(shù)融合方向。Feng 等[30]獲取電動汽車領(lǐng)域的專利文獻(xiàn),根據(jù)專利分類共現(xiàn)關(guān)系構(gòu)建技術(shù)共現(xiàn)網(wǎng)絡(luò)并根據(jù)節(jié)點間的多種維度預(yù)測新的技術(shù)融合。
目前,利用IPC 號的組合研究技術(shù)融合的學(xué)者大多從四位IPC 號的組合開展研究,而四位IPC 號包含的技術(shù)信息較為宏觀,往往更傾向于高層次的領(lǐng)域之間的技術(shù)融合,技術(shù)細(xì)節(jié)展示不足,尚需從更加細(xì)粒度的技術(shù)分類微觀角度出發(fā),挖掘關(guān)注技術(shù)細(xì)節(jié)的技術(shù)分類融合,補充和完善已有技術(shù)融合。此外,專利分類號共現(xiàn)網(wǎng)絡(luò)較難體現(xiàn)專利分類序列中專利分類號的位置和上下文語義信息,需要借鑒和改進(jìn)表示學(xué)習(xí)方法實現(xiàn)更為全面的語義表示。
2.1.3 基于專利文本的技術(shù)融合預(yù)測
為了豐富專利分類號的語義特征,一些學(xué)者通過引入文本信息來提高技術(shù)融合預(yù)測的效果和可解釋性。Preschitschek 等[31]借助專利分類號劃分多個技術(shù)領(lǐng)域,接著將專利分類號對應(yīng)的專利文本合并為一個文件作為技術(shù)領(lǐng)域的文本,之后通過計算一個技術(shù)領(lǐng)域中單個專利文件與另一個技術(shù)領(lǐng)域的整體文件之間的相似度,根據(jù)時間推移通過標(biāo)準(zhǔn)化統(tǒng)計技術(shù)預(yù)測技術(shù)領(lǐng)域是否產(chǎn)生技術(shù)融合。與此類似,Eilers 等[32]先劃分多個技術(shù)領(lǐng)域,接著根據(jù)技術(shù)領(lǐng)域中的所有專利文件提取技術(shù)詞作為該技術(shù)領(lǐng)域的代表技術(shù)詞,之后通過計算一個技術(shù)領(lǐng)域中的單個專利技術(shù)詞與另一個領(lǐng)域中的整體技術(shù)詞之間的語義相似度,根據(jù)時間推移監(jiān)測技術(shù)軌跡,為技術(shù)融合預(yù)測提供指導(dǎo)。
Kim 等[7]將文本信息作為一個特征融入技術(shù)融合預(yù)測中,對于同一篇專利文獻(xiàn)下的多個專利分類號,無差別地賦予每個專利分類號以文本信息。實際上,當(dāng)一篇專利文獻(xiàn)中包含多個專利分類號時,排序越靠前的專利分類號往往越重要,越能代表專利的核心技術(shù)[33-34]。當(dāng)平等對待同一篇專利文獻(xiàn)下的專利分類號時,即只要該專利包含該專利分類號就把該專利的文本分配給該專利分類號,容易造成分類號的文本信息出現(xiàn)大量重復(fù),難以區(qū)分不同專利分類號間的區(qū)別,導(dǎo)致對技術(shù)融合預(yù)測的貢獻(xiàn)降低。尤為重要的是,專利分類的網(wǎng)絡(luò)關(guān)系和文本特征均對技術(shù)融合產(chǎn)生作用,但每一維特征對技術(shù)融合預(yù)測的貢獻(xiàn)程度卻有區(qū)別,需要針對特定領(lǐng)域?qū)W習(xí)不同特征對技術(shù)融合預(yù)測的貢獻(xiàn),綜合利用網(wǎng)絡(luò)和文本特征,提高預(yù)測效果。
2.2 表示學(xué)習(xí)相關(guān)研究
表示學(xué)習(xí)通過多層神經(jīng)網(wǎng)絡(luò)將原始數(shù)據(jù)通過非線性模型轉(zhuǎn)變?yōu)楦邔哟蔚奶卣鞅硎荆瑢⒃瓉碛扇斯ぴO(shè)定的特征工程轉(zhuǎn)換為機器的自我學(xué)習(xí)過程,把研究對象的語義信息映射為低維度的、連續(xù)的語義向量,作為多種分類、聚類、推薦任務(wù)的輸入[35]。目前的表示學(xué)習(xí)方法根據(jù)研究對象不同主要分為三種:文本表示學(xué)習(xí)、網(wǎng)絡(luò)表示學(xué)習(xí)以及文本和網(wǎng)絡(luò)融合的表示學(xué)習(xí)[36]。
2.2.1 文本表示學(xué)習(xí)
文本表示是將文本中的信息轉(zhuǎn)換成計算機能夠處理的向量表示,傳統(tǒng)文本表示方法有向量空間模型、統(tǒng)計語言模型和主題模型等[37]。近年來隨著深度學(xué)習(xí)的興起,文本表示學(xué)習(xí)逐步成為深度學(xué)習(xí)的一個新興分支,由此形成了多種文本表示方法與模型。Mikolov 等[38]提出的word2vec 模型開啟了文本表示學(xué)習(xí)的熱潮,其基本思想是通過神經(jīng)網(wǎng)絡(luò)模型訓(xùn)練語料,結(jié)合每個詞語的上下文信息,將語料中每個詞映射成K 維實值向量,解決后續(xù)多種任務(wù)中的數(shù)據(jù)稀疏與維度災(zāi)難問題。
相比于詞向量,篇章級別向量表示的難點在于文章篇幅較長、語義過于復(fù)雜。Le 等[39]借鑒word2vec的基本思想,提出了一種無監(jiān)督的、將長文本轉(zhuǎn)化為固定長度向量的doc2vec 模型,在訓(xùn)練過程中將長文本作為一個特殊段落ID(identity document)引入語料中,同時結(jié)合了上下文、單詞順序和段落特征,在鏈路預(yù)測以及情感分類等方面表現(xiàn)出不錯的效果。Tang 等[40]使用CNN(convolutional neural net‐work)、LSTM(long short-term memory)建模句子,再使用Bi-RNN(bidirectional recurrent neural network)建模整個篇章,在文檔級情感分類任務(wù)上具有更好的效果。Yang 等[41]在Tang 等[40]提出的模型基礎(chǔ)上,在句子、文檔層面分別加入注意力機制,對文檔中的單詞、句子的重要性建模,進(jìn)行加權(quán)計算生成文檔向量。后續(xù)研究者們對關(guān)鍵詞、句子、上下文內(nèi)容等不同層次的文本表示學(xué)習(xí)方法進(jìn)行了改進(jìn),形成了key2vec[42]、senten2vec[43]、con-s2vec[44]等模型,針對不同特定領(lǐng)域數(shù)據(jù)類型形成了paper2vec[45]、query2vec[46]、hyperdoc2vec[47]等模型,提升了特定任務(wù)下的語義表示效果,并擴(kuò)展應(yīng)用在信息檢索、知識圖譜、自動問答和自然語言處理等領(lǐng)域。
2.2.2 網(wǎng)絡(luò)表示學(xué)習(xí)
網(wǎng)絡(luò)表示學(xué)習(xí)是復(fù)雜網(wǎng)絡(luò)與深度學(xué)習(xí)的交叉融合,可以將網(wǎng)絡(luò)節(jié)點轉(zhuǎn)化為低維稠密實數(shù)向量[48],為大規(guī)模復(fù)雜網(wǎng)絡(luò)的特征語義表示提供了解決方案。受word2vec 算法的啟發(fā),Perozzi 等[49]先通過隨機游走的方式生成有序的節(jié)點序列,隨后將網(wǎng)絡(luò)節(jié)點類比成詞,將word2vec 應(yīng)用在隨機游走序列上,學(xué)習(xí)節(jié)點表示。node2vec[50]與DeepWalk 類似,主要區(qū)別在于隨機游走算法的設(shè)計不同,使生成的節(jié)點序列存在差異。Tang 等[51]針對網(wǎng)絡(luò)結(jié)構(gòu)沒有一個明確的目標(biāo)函數(shù)的問題,提出了LINE(large-scale in‐formation network embedding)模型,該模型能夠處理任意類型的大規(guī)模網(wǎng)絡(luò),包括有向和無向,以及有權(quán)重和無權(quán)重;該算法保留了網(wǎng)絡(luò)中節(jié)點的一階相似性和二階相似性,可以同時利用連邊關(guān)系和共同鄰居來學(xué)習(xí)節(jié)點表示。SDNE(structural deep net‐work embedding)算法[52]利用深度神經(jīng)網(wǎng)絡(luò)采用半監(jiān)督的方式進(jìn)行網(wǎng)絡(luò)表示學(xué)習(xí),模型主要分為兩部分:一部分為無監(jiān)督深層自編碼器,用于獲取節(jié)點的二階相似度;另一部分用于有監(jiān)督地建模節(jié)點的一階相似度。Hamilton 等[53]提出一種適用于大規(guī)模網(wǎng)絡(luò)的歸納式學(xué)習(xí)方法GraphSAGE (graph sample and aggregate),該算法通過聚集采樣得到的鄰居節(jié)點表示來更新當(dāng)前節(jié)點的特征表示,而不是直接將每個節(jié)點單獨進(jìn)行訓(xùn)練。
早期的網(wǎng)絡(luò)表示學(xué)習(xí)主要針對節(jié)點和連邊類型單一的同構(gòu)網(wǎng)絡(luò),并不能真實反映現(xiàn)實世界中節(jié)點和連邊類型多樣的異構(gòu)信息網(wǎng)絡(luò),需要構(gòu)建更復(fù)雜的網(wǎng)絡(luò)表示學(xué)習(xí)方法捕獲更豐富的語義信息[54]。其中,Tang 等[55]認(rèn)為網(wǎng)絡(luò)中有多種類型的節(jié)點和邊,因此將LINE 擴(kuò)展到異構(gòu)網(wǎng)絡(luò)中,針對文本標(biāo)簽預(yù)測任務(wù)提出了半監(jiān)督的PTE(predictive text embed‐ding)模型;該模型將部分標(biāo)簽已知的文檔集合數(shù)據(jù)轉(zhuǎn)換為一個包含文檔、詞語和標(biāo)簽三類節(jié)點的異構(gòu)網(wǎng)絡(luò),然后學(xué)習(xí)不同類型節(jié)點的向量表示。Dong等[56]受同構(gòu)網(wǎng)絡(luò)中node2vec 算法的啟發(fā),提出了metapath2vec 算法,該方法通過在異構(gòu)信息網(wǎng)絡(luò)中進(jìn)行隨機游走來獲取節(jié)點的鄰居節(jié)點集合。Shi 等[57]提出 的HERec (heterogeneous network embedding for recommendation)模型基于元路徑從異質(zhì)信息網(wǎng)絡(luò)中抽取出同類節(jié)點序列,相當(dāng)于從異質(zhì)信息網(wǎng)絡(luò)中抽取出多個同質(zhì)信息網(wǎng)絡(luò),提高了推薦效果。
2.2.3 融合網(wǎng)絡(luò)結(jié)構(gòu)和文本內(nèi)容的表示學(xué)習(xí)
在文本表示學(xué)習(xí)與網(wǎng)絡(luò)表示學(xué)習(xí)的基礎(chǔ)上,近年來開始了將這兩者相融合的表示學(xué)習(xí)研究,即利用網(wǎng)絡(luò)的結(jié)構(gòu)信息以及節(jié)點的文本信息共同學(xué)習(xí)節(jié)點的低維向量表示。Yang 等[58]提出了TADW(textassociated DeepWalk) 模型,通過矩陣分解將網(wǎng)絡(luò)結(jié)構(gòu)特征和節(jié)點的文本特征進(jìn)行聯(lián)合訓(xùn)練,實現(xiàn)這兩種特征的融合。在TADW 模型的基礎(chǔ)上,Zhang等[59]從不同的網(wǎng)絡(luò)結(jié)構(gòu)與節(jié)點內(nèi)容相互作用的角度構(gòu)建了HSCA (homophily, structure and content aug‐mented)模型,認(rèn)為網(wǎng)絡(luò)信息有三個來源,分別是同質(zhì)、拓?fù)浣Y(jié)構(gòu)和節(jié)點內(nèi)容,并將三種信息源增加至一個目標(biāo)函數(shù)中,共同學(xué)習(xí)網(wǎng)絡(luò)表示。Sun 等[60]提出一種新的CENE(content-enhanced network em‐bedding)算法,將節(jié)點內(nèi)容視為一種特殊的節(jié)點來擴(kuò)展到網(wǎng)絡(luò)中,該算法使用邏輯回歸函數(shù)學(xué)習(xí)擴(kuò)展的網(wǎng)絡(luò),并通過負(fù)采樣的方法優(yōu)化目標(biāo)函數(shù),使得到的網(wǎng)絡(luò)表示不僅可以保留網(wǎng)絡(luò)結(jié)構(gòu)特征,還可以保留節(jié)點和內(nèi)容之間的語義信息。Li 等[61]提出了PPNE (post-processing network embedding) 模 型 來有效地融合不同類型的節(jié)點屬性信息,將表示向量的學(xué)習(xí)過程轉(zhuǎn)化為聯(lián)合優(yōu)化的問題,并通過使用有效的隨機梯度下降算法解決聯(lián)合優(yōu)化問題;在多個數(shù)據(jù)集上進(jìn)行的節(jié)點分類和鏈路預(yù)測任務(wù)證明了PPNE 的有效性。Ganguly 等[62]通過文本向量得到每個節(jié)點的N 個最近鄰居,并將其增加到網(wǎng)絡(luò)關(guān)系中,利用DeepWalk 算法的原理生成每個節(jié)點的向量表示,在節(jié)點分類和鏈路預(yù)測任務(wù)中證明了此方法的有效性。Pan 等[63]提出結(jié)合網(wǎng)絡(luò)結(jié)構(gòu)、節(jié)點內(nèi)容和節(jié)點標(biāo)簽的深度學(xué)習(xí)模型TriDNR (tri-party deep network representation),該模型通過隨機游走生成節(jié)點序列并學(xué)習(xí)節(jié)點語義表示來保留節(jié)點結(jié)構(gòu)信息,然后用另一個神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)節(jié)點上下文的相關(guān)性,同時,將節(jié)點標(biāo)簽作為輸入,直接在標(biāo)簽和上下文之間建模來學(xué)習(xí)標(biāo)簽向量和單詞向量。
3 模型構(gòu)建
首先基于專利文獻(xiàn)獲取專利分類序列,設(shè)計表示學(xué)習(xí)方法獲取專利分類在序列中的位置特征和上下文語義特征,形成專利分類序列語義表示,通過計算尚未產(chǎn)生融合的專利分類號間的相似度來預(yù)測技術(shù)融合;接著基于專利分類號在序列中的排序重要性形成專利文本內(nèi)容分配方法,利用文本表示學(xué)習(xí)方法實現(xiàn)專利分類文本語義表示,通過計算尚未產(chǎn)生融合的專利分類號間的相似度來預(yù)測技術(shù)融合;之后研究兩類特征的融合方法,利用機器學(xué)習(xí)方法自動學(xué)習(xí)每維特征的最優(yōu)權(quán)重,形成基于機器學(xué)習(xí)的特征融合模型,通過模型計算尚未產(chǎn)生融合的專利分類號間產(chǎn)生鏈接的概率來預(yù)測技術(shù)融合;最后基于鏈路預(yù)測的理論和方法設(shè)計技術(shù)融合預(yù)測評測指標(biāo)和方法,對不同方法進(jìn)行定量比較。
3.1 基于專利分類序列語義表示的技術(shù)融合預(yù)測
為了有效抓取專利分類號在序列中的位置信息和周圍上下文語義特征,不同于通過序列構(gòu)建共現(xiàn)網(wǎng)絡(luò)進(jìn)而基于網(wǎng)絡(luò)表示學(xué)習(xí)來實現(xiàn),本文直接對專利分類序列進(jìn)行建模獲得專利分類的語義表示,最大限度保留真實的位置信息和語義信息。借鑒word2vec 模型的思路,本文將專利分類號類比于“word”,將專利分類序列類比于“word”的序列,即句子,通過學(xué)習(xí)專利分類號在序列中的上下文語境,得到每個專利分類號的語義向量表示。按照訓(xùn)練方式不同,訓(xùn)練模型可分為CBOW(continuous bag-of-words) 與Skip-Gram 兩 種。 一 般 而 言,CBOW 模型在處理小型語料時有更好的效果,而Skip-Gram 模型更適合于大型語料[64-65]。根據(jù)本文數(shù)據(jù)規(guī)模,選取CBOW 模型進(jìn)行訓(xùn)練。在CBOW 模型中,利用專利分類號前后的各c 個專利分類號來預(yù)測當(dāng)前的專利分類號,據(jù)此形成專利分類序列表示學(xué)習(xí)模型,具體原理如圖1[38]所示。
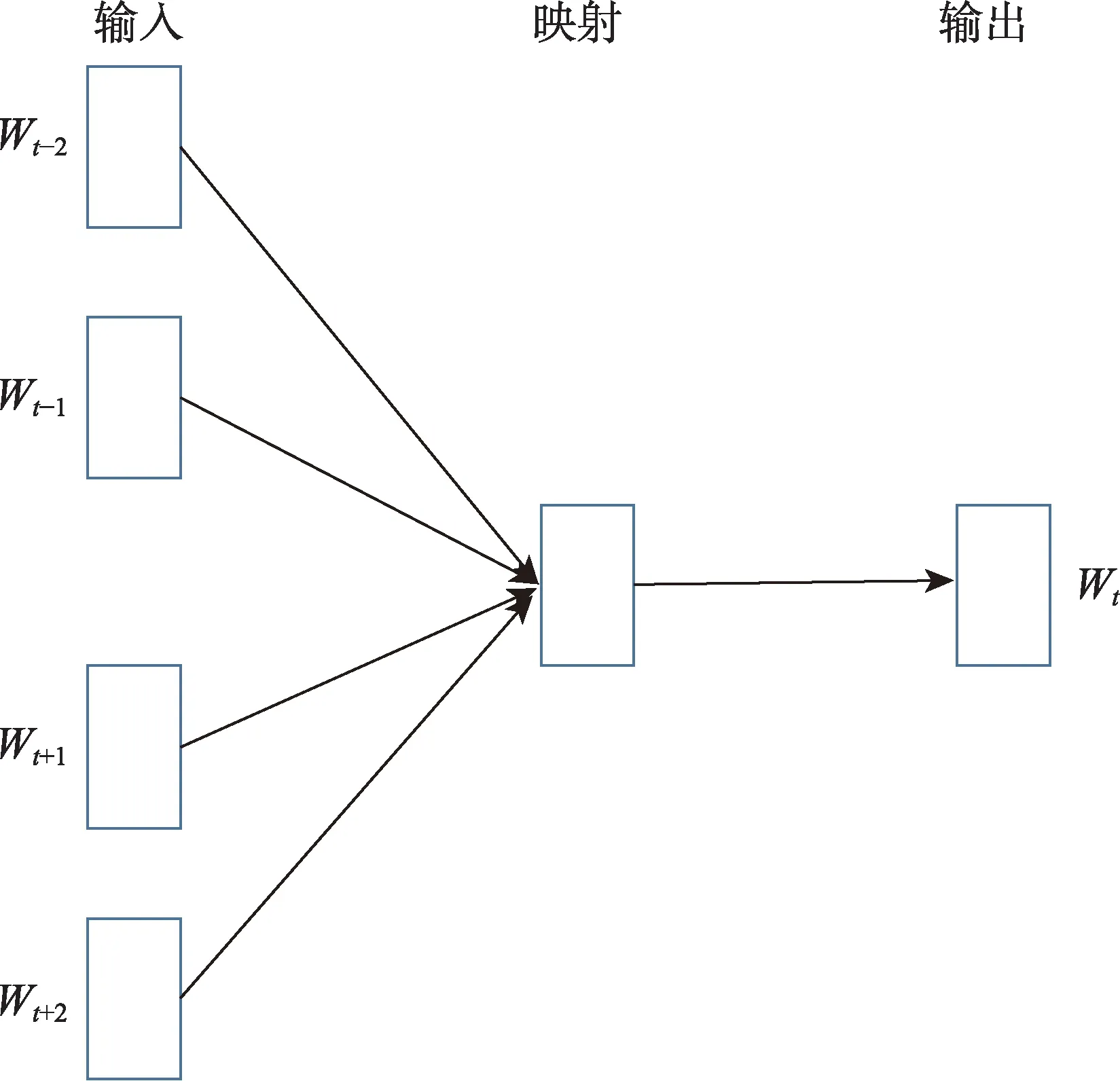
圖1 專利分類序列的表示學(xué)習(xí)模型[38]
專利分類序列的訓(xùn)練模型的優(yōu)化函數(shù)[38]為
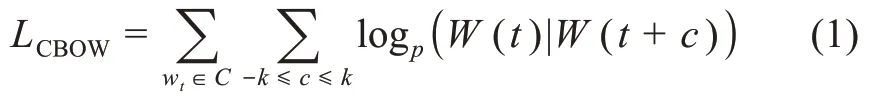
其中,Wt表示專利分類號序列中的任意一個專利分類號;Wt-2和Wt-1分別表示排序在Wt之前的兩個專利分類號;Wt+1和Wt+2分別表示排序在Wt之后的兩個專利分類號。這些共同構(gòu)成了當(dāng)前專利分類號的上下文語境信息。
利用專利分類序列表示學(xué)習(xí)模型可以將序列中的每個專利分類號映射到多維向量空間中,且每一維向量都表示一定的語義信息,從而實現(xiàn)基于序列結(jié)構(gòu)的專利分類語義表示。對于任意兩個專利分類號,其向量可以分別表示為xi=(x1,x2,x3,…,xn)和yi=(y1,y2,y3,…,yn)。在此基礎(chǔ)上通過余弦相似度、歐幾里得距離等多種指標(biāo)計算向量之間的語義相似性來表示尚未產(chǎn)生關(guān)聯(lián)的專利分類號之間的語義相似度,進(jìn)而根據(jù)相似度排序來預(yù)測是否產(chǎn)生技術(shù)融合。本文選取余弦相似度指標(biāo)進(jìn)行語義相似度計算,具體計算方法為
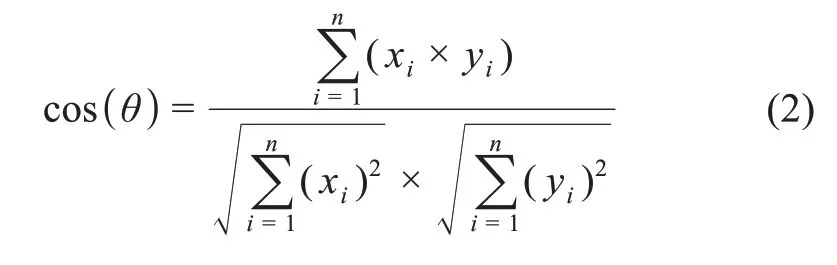
3.2 基于專利分類文本語義表示的技術(shù)融合預(yù)測
為了提高專利分類號區(qū)分度,考慮專利分類號在序列中的排序重要性信息,本文提出了兩種專利分類號文本分配方式。第一種方式是只對排序第一的專利分類號賦予對應(yīng)的專利文本(標(biāo)題和摘要)。第二種方式是在第一種方式的基礎(chǔ)上,繼續(xù)對處于其他排序位置的專利分類號賦予文本,主要包括以下步驟:首先對排序第一的專利分類號賦予文本;然后賦予排序第二的專利分類號以文本,若該專利分類號在前一步驟中已分配文本,則不進(jìn)行新的文本賦予,否則,把該專利文本賦予此專利分類號;依此類推,賦予其他所有專利分類號以文本。在分配文本過程中,如果某一專利分類號在多個專利分類序列中的同一排序位置多次出現(xiàn),只要其在之前步驟中未被分配文本,就將多個專利中的文本內(nèi)容都賦予給該專利分類號,如圖2 中排序第一的分類號1 和排序第二的分類號3。這樣可以保證在不同的處理順序下,專利分類號的文本內(nèi)容保持一致。
在圖2 中,以三個專利文獻(xiàn)及其對應(yīng)的專利文本和多個專利分類號為例進(jìn)行說明,如圖2a 所示。首先考慮所有專利中排序第一的分類號,如圖2b所示,由于“分類號1”在“專利1”中排序第一,因此將“專利文本1”分配給“分類號1”,同樣將“專利文本2”分配給“分類號2”,將“專利文本3”分配給“分類號1”。接著考慮排序第二的專利分類號,如圖2c 所示,由于“專利1”中的“分類號2”在上一步中已分配過文本,所以這一步中不將“專利文本1”分配給“分類號2”,而“專利2”中的“分類號3”在上一步中未分配文本,因此將“專利文本2”分配給“分類號3”,同樣地,將“專利文本3”分配給“分類號3”。依此類推,考慮排序第三的分類號,如圖2d 所示,由于“專利1”中的“分類號4”在之前步驟中未分配文本,所以將“專利文本1”分配給“分類號4”,而“專利2”和“專利3”中排序第三的專利分類號在之前的步驟中均已分配文本,所以這一步不再分配其文本。
我們在初中數(shù)學(xué)課堂教學(xué)中想要提高課堂質(zhì)效的最終目的是培養(yǎng)學(xué)生的學(xué)習(xí)能力,因此我們的課堂教學(xué)方式在創(chuàng)新的基礎(chǔ)之上還不能忽視對學(xué)生學(xué)習(xí)能力的培養(yǎng)。學(xué)生是數(shù)學(xué)課堂的主體,我們在課堂教學(xué)當(dāng)中可以適當(dāng)?shù)膶⑽枧_移交給學(xué)生,讓學(xué)生充分展示自己,這樣學(xué)生學(xué)習(xí)數(shù)學(xué)的興趣也會更濃厚。
在專利文本分配后,為了獲取每個專利分類號的文本語義表示,本文借鑒doc2vec 模型的思路,將專利分類號類比于模型中的文本ID,專利文本中的每個詞類比于“word”序列。每次訓(xùn)練時,模型選取專利文本中一定長度的句子,將句子中的每個詞以及專利文本對應(yīng)的專利分類號(文本ID)作為輸入一起訓(xùn)練。訓(xùn)練結(jié)束后,既可以得到每個詞的詞向量表征,又可以得到整個文本的向量表示,即專利分類號的語義表示。依據(jù)訓(xùn)練方式不同,可分為DM (distributed memory) 和DBOW (distributed bag of words)模型。DM 模型在處理小型語料時有更好的效果,而DBOW 模型更適合大型語料,根據(jù)本文數(shù)據(jù)規(guī)模,選擇DM 模型作為訓(xùn)練方式。專利分類文本語義表示模型的具體原理如圖3[39]所示,其中,ID 代表每個專利分類號,w1、w2、w3 代表專利分類號對應(yīng)的專利文本中的詞,w4 指一定長度句子中需要預(yù)測的詞。
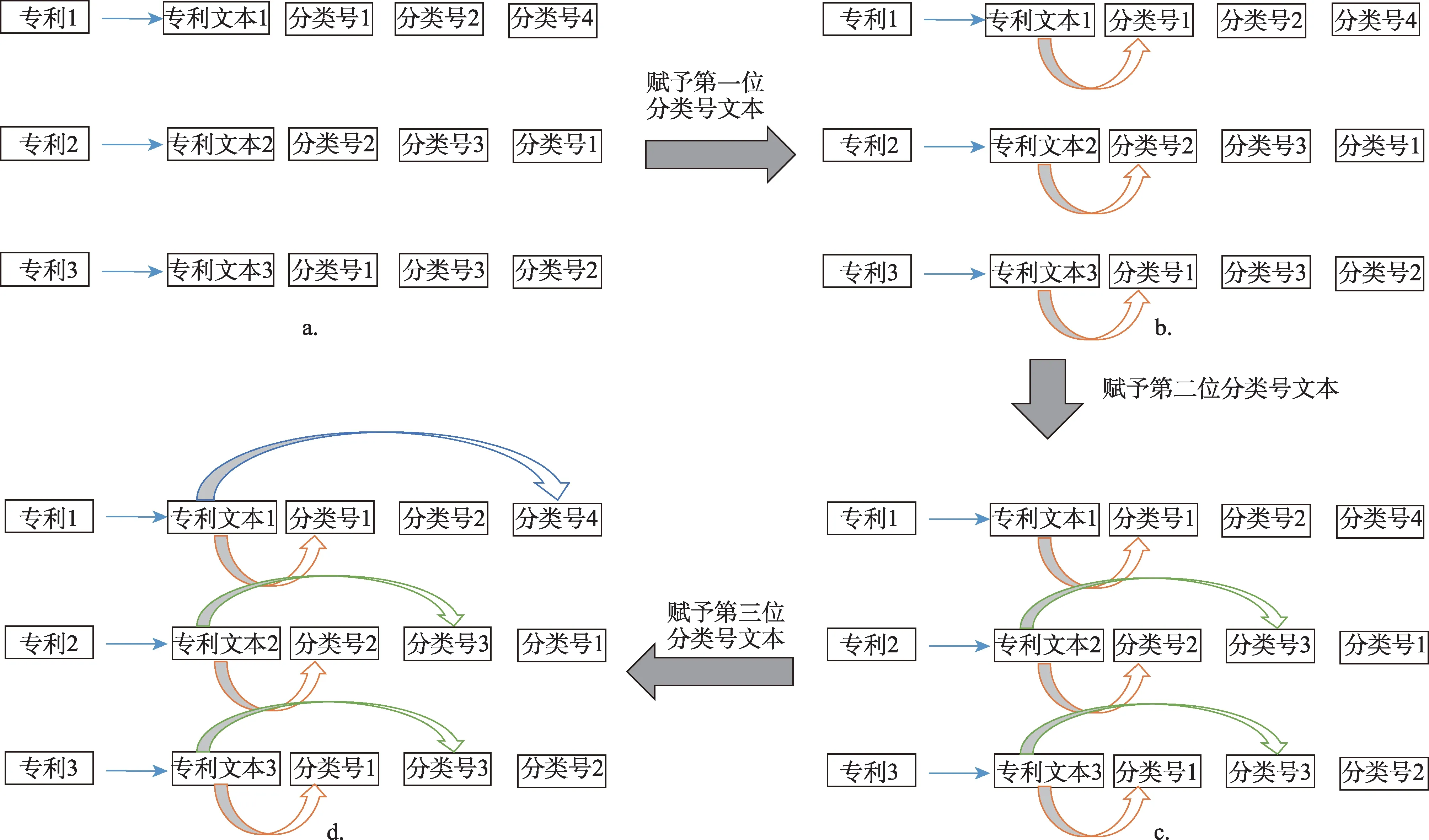
圖2 專利分類的文本分配方式示例
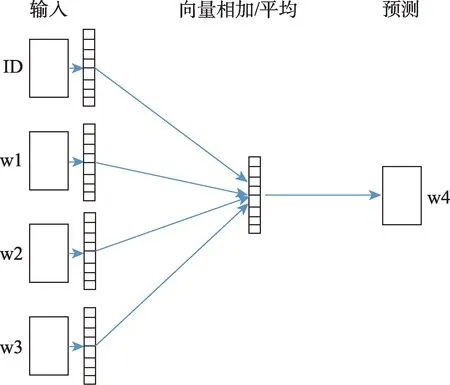
圖3 專利分類文本的語義表示模型[39]
利用專利分類文本語義表示模型可以在訓(xùn)練文本中每個詞的同時,實現(xiàn)整個文本的向量化表示,從而實現(xiàn)基于文本內(nèi)容的專利分類語義表示。在此基礎(chǔ)上,通過余弦相似度、歐幾里得距離等多種指標(biāo)計算向量之間的語義相似性來表示尚未產(chǎn)生關(guān)聯(lián)的專利分類號之間的語義相似度,進(jìn)而根據(jù)相似度來預(yù)測是否產(chǎn)生技術(shù)融合,本文選取余弦相似度指標(biāo)進(jìn)行語義相似度計算。
3.3 基于專利分類序列結(jié)構(gòu)和文本內(nèi)容語義融合的技術(shù)融合預(yù)測
序列信息與文本信息有著較大的區(qū)別,但兩者的每一維特征對技術(shù)融合預(yù)測都可能有貢獻(xiàn)。因此,本文通過機器學(xué)習(xí)模型來自動學(xué)習(xí)每一維特征的最優(yōu)權(quán)重,對多維度特征進(jìn)行有效融合,實現(xiàn)融合序列結(jié)構(gòu)和文本內(nèi)容的專利分類語義表示,進(jìn)而把技術(shù)融合預(yù)測轉(zhuǎn)化為尚未產(chǎn)生連接的專利分類號是否會產(chǎn)生鏈接的分類問題。SVM(support vector machine)作為常用的分類模型在多個領(lǐng)域具有優(yōu)異的表現(xiàn),因此本文選擇SVM 模型作為本文的機器學(xué)習(xí)分類模型。
基于SVM 的專利分類序列結(jié)構(gòu)和文本內(nèi)容語義融合的第一步在于確認(rèn)專利分類間是否產(chǎn)生技術(shù)融合,進(jìn)而分別得到訓(xùn)練集和測試集的正樣本和反樣本,進(jìn)行模型訓(xùn)練。為此,本文將處于同一序列中的專利分類號進(jìn)行兩兩組合,賦予正分類標(biāo)簽生成訓(xùn)練集正樣本,然后根據(jù)沒有產(chǎn)生鏈接的專利分類號對來生成相同數(shù)據(jù)量的訓(xùn)練集負(fù)樣本。同樣地,將上述方式應(yīng)用于測試集中,生成測試集正樣本和測試集負(fù)樣本。
該模型的第二個關(guān)鍵步驟是實現(xiàn)每個專利分類號組合對的向量表示。之前通過表示學(xué)習(xí)方法已經(jīng)得到了每個專利分類號單獨的向量表示,因此需要對單獨的專利分類號向量進(jìn)行合并,從而實現(xiàn)專利分類號對的語義表示。不同的合并方式對于最終結(jié)果可能有著不同的影響,本文設(shè)計了三種向量合并表示方法,分別為基于哈達(dá)瑪積的向量合并、基于平均向量法的向量合并和基于余弦相似度的向量合并。
(1)基于哈達(dá)瑪積的向量合并方式,即通過哈達(dá)瑪積的運算方式實現(xiàn)兩個專利分類號的語義向量合并,其基本思想是把兩個向量中每個維度的元素相乘得到一個新的向量。具體地,對于專利分類號組合中的兩個專利分類號,首先以拼接的方式連接每個專利分類號的序列向量X1=(x1,x2,x3,…,xn)和文本向量X2=(xn+1,xn+2,xn+3,…,x2n),得到拼接后的 分 類 號 向 量X =(x1,x2,x3,…,xn,xn+1,xn+2,xn+3,…,x2n);同樣地,另一個分類號的向量通過拼接表示為Y =(y1,y2,y3,…,yn,yn+1,yn+2,yn+3,…,y2n),接 著 通過哈達(dá)瑪積的向量合并方式得到專利分類號組合的向量Z,具體計算公式為
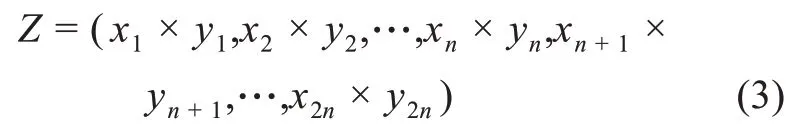
(2)基于平均向量法的向量合并方式,即通過加權(quán)平均的運算方式實現(xiàn)兩個專利分類號的語義向量合并,其基本思想是把兩個向量中每個維度的元素取均值得到一個新的向量。具體地,對于上述專利分類號組合中的兩個分類號向量X 和Y,通過公式
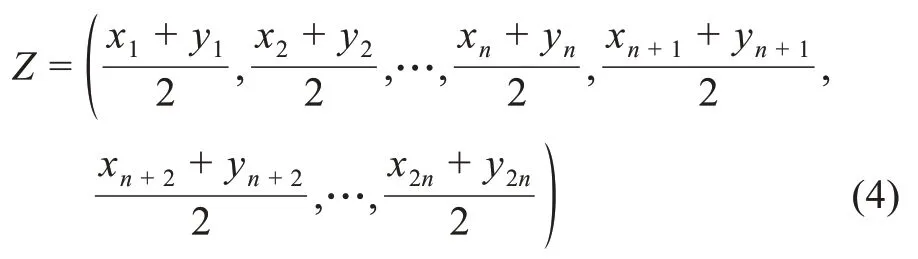
得到專利分類號組合的向量Z。
(3)基于余弦相似度的向量合并方式,其基本思想是把序列向量和文本向量作為一個整體進(jìn)行相似度計算來形成新的特征。一般而言,若兩個分類號的序列向量的相似度越高,該分類號組合產(chǎn)生技術(shù)融合的概率越大;同樣地,若兩個分類號的文本向量的相似度越高,該分類號組合產(chǎn)生技術(shù)融合概率越大。但是這兩種不同的相似度對于技術(shù)融合的貢獻(xiàn)度可能不同,如果把這兩種相似度作為新的特征并通過SVM 學(xué)習(xí)權(quán)重,有可能更好地實現(xiàn)技術(shù)融合預(yù)測。據(jù)此形成了基于余弦相似度的向量合并方式,在序列相似度計算中,兩個分類號的序列向量分別 為X1=(x1,x2,x3,…,xn)和Y1=(y1,y2,y3,…,yn),通過余弦相似度計算專利分類號的相似度值為z1,同理得到專利分類號的文本相似度值z2,以序列向量與文本向量的余弦相似度的值作為專利分類號組合的兩個特征,進(jìn)而得到專利分類號組合的向量Z =(z1,z2)。
對于以上三種合并方式得到的專利分類號組合向量,通過SVM 模型自動學(xué)習(xí)每維特征的最優(yōu)權(quán)重,形成基于SVM 的特征融合模型,通過模型計算專利分類號間產(chǎn)生鏈接的概率來預(yù)測技術(shù)融合。
3.4 基于鏈路預(yù)測的技術(shù)融合預(yù)測定量評估方法
本文將兩個專利分類號是否產(chǎn)生融合視為二分類問題。具體地,對于上文得到的訓(xùn)練集正樣本和測試集正樣本,認(rèn)為樣本中的每個專利分類號組合已產(chǎn)生技術(shù)融合;相反,對于訓(xùn)練集負(fù)樣本和測試集負(fù)樣本,樣本中的每個專利分類號組合均未產(chǎn)生技術(shù)融合。本文根據(jù)訓(xùn)練集中的正樣本與負(fù)樣本得到的模型計算專利分類號組合產(chǎn)生鏈接的概率,并與測試集中的實際結(jié)果進(jìn)行比較,利用AUC(area under curve)、MAP(macro average precision)以及準(zhǔn)確率對技術(shù)融合預(yù)測結(jié)果進(jìn)行定量評價。
AUC 從整體上衡量融合預(yù)測的準(zhǔn)確性,將正樣本中IPC 號之間的相似度得分與負(fù)樣本中IPC 號之間的相似度得分進(jìn)行比較。這個比較會獨立進(jìn)行n次。如果有n'次正樣本中IPC 號之間的相似度得分高于負(fù)樣本中IPC 號之間的相似度得分,并且有n″次它們之間的得分相同,那么AUC 的值可計算為
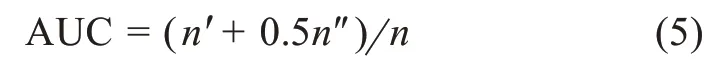
MAP 指宏平均準(zhǔn)確率,通過設(shè)定一組閾值,計算不同閾值下準(zhǔn)確率和召回率的變化,據(jù)此描繪準(zhǔn)確率和召回率曲線,計算曲線下的面積即為MAP值,用于評價預(yù)測算法的整體性能,具體計算公式為
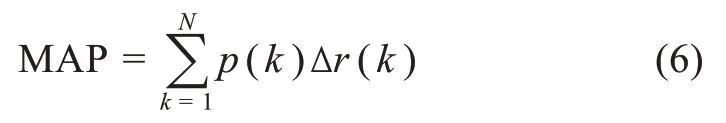
其中,k 代表正確識別出技術(shù)融合專利分類號組合數(shù);p(k)表示識別出k 個專利分類號組合時的準(zhǔn)確率;Δr(k) 表示隨著k 值的調(diào)整,召回率的變化情況。
準(zhǔn)確率指被分類器正確分類的樣本所占的百分比,反映分類器對各類樣本的正確識別情況[66-67]。一般通過Top-n 準(zhǔn)確率來計算,即可能性最大的前n個預(yù)測結(jié)果中,正確預(yù)測數(shù)所占的比值。首先把預(yù)測結(jié)果按照相似度或概率大小進(jìn)行降序排列,并取排序靠前的n 個專利分類號組合對;然后計算真正預(yù)測對的組合對數(shù)n'占總個數(shù)n 的比值,用來表示該種情況下的準(zhǔn)確率,即

最后通過改變n 的值,得到不同情況下準(zhǔn)確率變化情況,判斷模型的預(yù)測效果。
4 實證研究
無人機具有成本低、操作靈活、能夠避免出現(xiàn)人員傷亡等特點,備受軍事和民用領(lǐng)域的關(guān)注。2015 年國務(wù)院印發(fā)《中國制造2025》戰(zhàn)略文件,無人機產(chǎn)業(yè)被列入我國十大重點領(lǐng)域之中;無人機產(chǎn)業(yè)包括從人工智能到核心軟件和硬件工程的各種知識領(lǐng)域,是典型的多學(xué)科融合、跨領(lǐng)域集成的新興產(chǎn)業(yè)[68],技術(shù)融合已然成為無人機產(chǎn)業(yè)創(chuàng)新發(fā)展的主要來源之一。因此,本文以無人機領(lǐng)域?qū)@麛?shù)據(jù)為基礎(chǔ),對無人機的技術(shù)融合趨勢進(jìn)行預(yù)測,把握無人機產(chǎn)業(yè)未來的發(fā)展方向。
4.1 數(shù)據(jù)來源
本文選擇德溫特專利索引(Derwent Innovations Index,DII)數(shù)據(jù)庫作為數(shù)據(jù)來源,確定專利檢索表達(dá)式為TI=(((unmanned OR automatic OR autono‐mous OR remotely poloted OR nonhuman) AND (air‐craft OR“aerial vehicle”O(jiān)R airship* OR drone OR plane OR aerocraft* OR airplane OR aerobat* OR aero‐stat*)) OR“UAV”),時間區(qū)間為2011 年到2020 年,獲取專利的標(biāo)題、摘要和IPC 號等特征項。原始數(shù)據(jù)共計52602 條,經(jīng)過初步篩選,剔除無摘要數(shù)據(jù)557 條,最終有效數(shù)據(jù)52045 條。根據(jù)每年的專利數(shù)目對時間窗口進(jìn)行劃分得到訓(xùn)練集和測試集。其中,訓(xùn)練集來源于2011 年到2019 年的數(shù)據(jù),共計38362 條;測試集來源于2020 年的數(shù)據(jù),共計13683 條。
對無人機專利數(shù)據(jù)進(jìn)行整理和統(tǒng)計,如表1 所示,發(fā)現(xiàn)近十年以來無人機相關(guān)專利數(shù)量持續(xù)增長,尤其自2015 年以來,增長更為迅速。從產(chǎn)生了技術(shù)融合的專利數(shù)量來看,2015 年較2014 年幾乎翻了一倍,之后保持著高速增長的趨勢,到2020 年無人機領(lǐng)域技術(shù)融合專利數(shù)量達(dá)到了頂峰,共計10393 條。從產(chǎn)生融合的專利數(shù)量所占比例來看,早期融合比例緩慢波動,2015 年后融合比例逐步提高,其中,2011 年技術(shù)融合專利占比0.628,到2020 年達(dá)到了0.760。綜合分析可見,目前無人機領(lǐng)域需要多個技術(shù)共同協(xié)作完成,技術(shù)融合對無人機技術(shù)的發(fā)展起到了至關(guān)重要的作用。未來,無人機領(lǐng)域仍然是國家和企業(yè)的重點研究對象,對無人機的技術(shù)融合趨勢進(jìn)行預(yù)測,有利于企業(yè)及時把握無人機產(chǎn)業(yè)的技術(shù)研究方向,推進(jìn)無人機產(chǎn)業(yè)進(jìn)一步發(fā)展。
4.2 基于專利分類序列語義表示的技術(shù)融合預(yù)測結(jié)果
通過對專利分類序列表示學(xué)習(xí)模型的主要參數(shù)進(jìn)行不斷調(diào)整,選取預(yù)測效果最優(yōu)的參數(shù)組合,即dimension=128,window_size=2。為了驗證該方法的有效性,本文選取網(wǎng)絡(luò)表示學(xué)習(xí)中常用的代表性模型DeepWalk、LINE、node2vec、SDNE、HOPE(highorder proximity preserved embedding)進(jìn)行對比分析,由于這些模型的基本原理都是序列表示學(xué)習(xí),因此將這些網(wǎng)絡(luò)表示學(xué)習(xí)模型進(jìn)行相同的參數(shù)設(shè)置,并通過鏈路預(yù)測的方法定量評估模型效果。對應(yīng)的評測指標(biāo)AUC、MAP 值如表2 所示,準(zhǔn)確率評測如表3 所示。
從表2 可以看到,在同等條件下,專利分類序列表示實現(xiàn)的技術(shù)融合預(yù)測具有最好的效果,AUC和MAP 以及準(zhǔn)確率較其他方法均有所提高,說明該方法適用于技術(shù)融合預(yù)測。在綜合考慮AUC 和MAP 的情況下,DeepWalk 模型和HOPE 模型表現(xiàn)次優(yōu),專利分類序列表示學(xué)習(xí)方法的AUC 和MAP 較DeepWalk 分別提高了0.046 和0.081,較HOPE 提高了0.044 和0.121。此外,SDNE 和node2vec 表現(xiàn)較差,SDNE 的AUC 和MAP 僅達(dá)到了0.362 和0.397,本文方法的AUC 和MAP 較之分別提高了0.495 和0.480,較node2vec 模型分別提高了0.294 和0.303。表3 的準(zhǔn)確率對比結(jié)果與上述結(jié)果一致,專利分類序列表示方法的準(zhǔn)確率是所有模型中最高的,并且所有的Top-n 預(yù)測準(zhǔn)確率均為1.000,再次驗證了該方法的有效性。由此可見,專利分類序列中體現(xiàn)的真實位置信息對技術(shù)融合預(yù)測具有一定的補充和完善作用,相較于專利分類號共現(xiàn)提供了更多的語義信息,能夠?qū)崿F(xiàn)更有效的技術(shù)融合預(yù)測,驗證了該方法的有效性,可以擴(kuò)展應(yīng)用于專利分類號聚類等相關(guān)研究中。

表1 無人機領(lǐng)域發(fā)生技術(shù)融合的專利數(shù)量統(tǒng)計

表2 專利分類序列表示學(xué)習(xí)方法與其他網(wǎng)絡(luò)表示學(xué)習(xí)方法的AUC和MAP對比
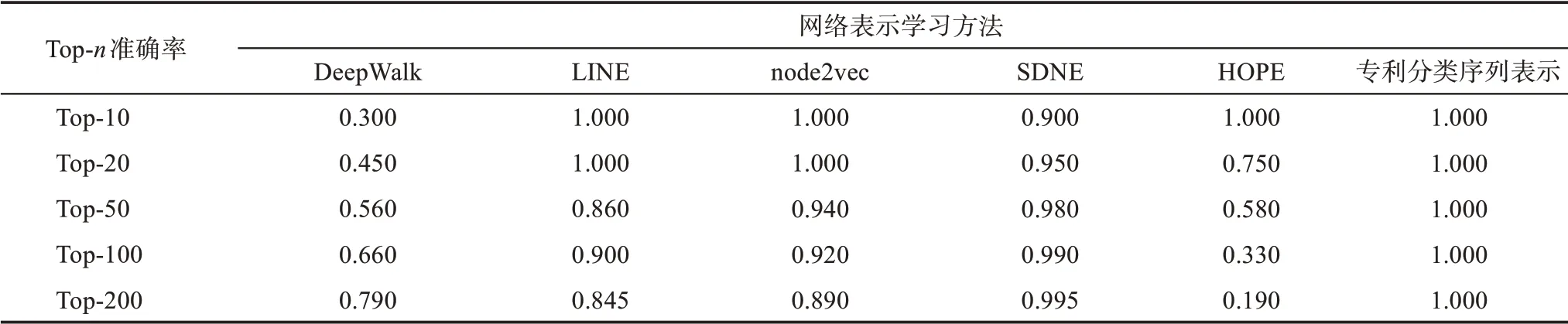
表3 專利分類序列表示學(xué)習(xí)方法與其他網(wǎng)絡(luò)表示學(xué)習(xí)方法的準(zhǔn)確率對比
4.3 基于專利分類文本語義表示的技術(shù)融合預(yù)測結(jié)果
根據(jù)專利分類號排序,依次賦予序列中的每一位IPC 號文本內(nèi)容,獲得文本的IPC 個數(shù)隨之不斷增加。當(dāng)賦予到前5 位IPC 時,獲得文本的IPC 個數(shù)達(dá)到9610 個,占IPC 總個數(shù)10520 的91.3%,幾乎覆蓋了全部的IPC 號。因此,對于排序第5 位之后的IPC 號,本文不再賦予文本。具體的IPC 文本分配統(tǒng)計信息如表4 所示。

表4 IPC文本分配統(tǒng)計
分配完文本后,通過專利分類文本語義表示模型實現(xiàn)IPC 號的文本語義表示,并通過余弦相似度計算IPC 號的語義相似度。為了對不同的專利分類文本賦予方式進(jìn)行比較,本文分別對每一種專利分類文本賦予方式進(jìn)行實驗和比較。通過對專利分類文本表示模型的主要參數(shù)進(jìn)行調(diào)優(yōu),得到最優(yōu)參數(shù)設(shè)置為dimension=128,window_size=15,并用鏈路預(yù)測的方法定量評估模型效果。同時,為了驗證方法有效性,與之前平均分配文本方式進(jìn)行對比實驗。具體實驗結(jié)果如表5 和表6 所示。
從表5 可以看到,在同等條件下,從賦予前1位IPC 文本到賦予前5 位IPC 文本,所有方式下的效果較平均分配的方式均有所提高。綜合考慮AUC、MAP 值的情況下,平均分配方式的AUC、MAP 值分別僅達(dá)到了0.563 和0.582,而本文最好的文本賦予方式的AUC、MAP 值分別達(dá)到了0.722 和0.726,較平均分配方式提高了0.159 和0.144;最差的文本賦予方式的AUC、MAP 值也分別達(dá)到了0.669 和0.642,較平均分配方式分別提高了0.106 和0.060。表6 的準(zhǔn)確率對比結(jié)果與上述結(jié)果一致,賦予前1 位IPC 文本的Top-n 預(yù)測準(zhǔn)確率均高于其他文本賦予方式,且最低的準(zhǔn)確率也達(dá)到了0.915,驗證了本文提出的專利文本賦予方式能有效地提高不同IPC 之間的區(qū)分度,進(jìn)而實現(xiàn)更準(zhǔn)確的技術(shù)融合預(yù)測。
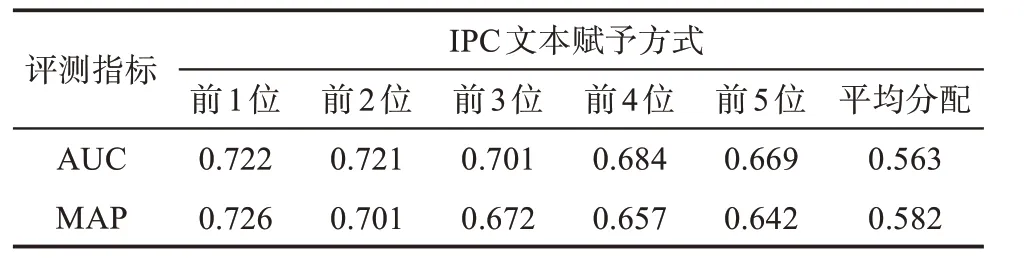
表5 不同IPC文本賦予方式下技術(shù)融合預(yù)測的AUC和MAP對比
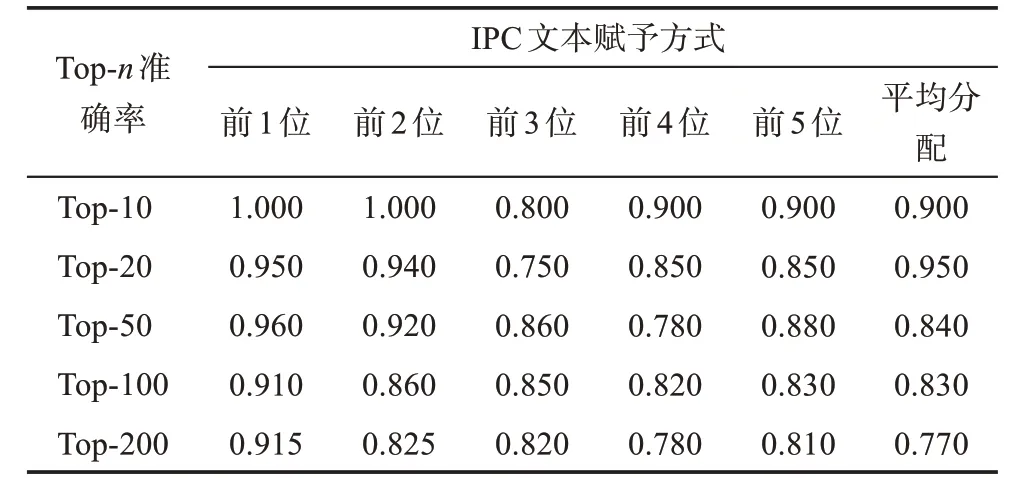
表6 不同IPC文本賦予方式下技術(shù)融合預(yù)測的準(zhǔn)確率對比
當(dāng)賦予的專利分類號數(shù)量逐漸增多時,技術(shù)融合預(yù)測效果卻逐漸下降。綜合考慮AUC、MAP 的情況下,賦予前1 位專利分類號文本的效果最好,AUC、MAP 值分別達(dá)到了0.722 和0.726,較賦予前5 位的方式分別提高了0.053 和0.084。說明在每篇專利文獻(xiàn)中,專利中包含的文本信息與排序靠前的專利分類號相關(guān)性更高,尤其是排序第一位的專利分類號。表6 的準(zhǔn)確率對比結(jié)果同樣證實了該結(jié)論,即隨著對更多排序位置的專利分類號賦予文本時,準(zhǔn)確率會呈現(xiàn)一定的下降趨勢。由此可見,僅賦予排序第一位的專利分類號文本,既能夠有效解決平均分配方式下分類號的文本信息冗余問題,又能夠?qū)@谋痉峙浣o最具代表性的專利分類號。因此,接下來本文將融合第一位IPC 號的文本語義表示與基于序列結(jié)構(gòu)的文本語義表示,進(jìn)而預(yù)測技術(shù)融合。
4.4 融合專利分類序列與文本語義表示的技術(shù)融合預(yù)測結(jié)果
本文將上文中表現(xiàn)最好的IPC 序列向量與僅賦予第一位IPC 號的文本向量應(yīng)用于SVM 模型,并以三種向量合并方式作為IPC 組合的語義表示,具體包括基于哈達(dá)瑪積的向量合并、基于平均融合的向量合并、基于余弦相似度的向量合并。其中,除了基于余弦相似度的合并方式特征維度為2,其余兩種方式均為256 維特征。
為了證明本文方法的有效性,將本文方法與兩種基準(zhǔn)模型進(jìn)行比較。基準(zhǔn)的融合方法包括向量拼接法和點乘相加法[69]。應(yīng)用這兩種基準(zhǔn)方法融合分類號序列表示和文本語義表示,與本文基于SVM的特征融合方式進(jìn)行對比,結(jié)果如表7 和表8 所示。
在表7 中,從融合方式來看,三種基于SVM 的特征融合模型效果均優(yōu)于兩種基準(zhǔn)模型。其中,拼接方式的效果最差,點乘方式相較于拼接方式效果有明顯提高,但仍低于本文提出的所有融合模型,說明本文的方式更適用于技術(shù)融合預(yù)測任務(wù)。在綜合考慮AUC 和MAP 的情況下,拼接方式的AUC、MAP 值分別為0.631 和0.621,點乘方式的AUC、MAP 值分別為0.827 和0.835,而本文方式中效果最好的為“SVM+哈達(dá)瑪積”融合模型,AUC、MAP值分別為0.913 和0.923,較拼接模型效果分別提高了0.282 和0.302,較點乘模型效果分別提高了0.086和0.088。本文方式中的“SVM+余弦相似度”,AUC、MAP 值分別為0.856 和0.875,雖然較其他兩種SVM 融合模型效果較差,但仍高于兩種基準(zhǔn)融合模型。表8 的準(zhǔn)確率對比結(jié)果與上述結(jié)果一致,“SVM+哈達(dá)瑪積”的準(zhǔn)確率仍然是所有模型中最高的,并且所有的Top-n 預(yù)測準(zhǔn)確率均為1.000,再次驗證了該方法的有效性。由此可見,拼接方式由于簡單地將序列特征與文本特征進(jìn)行連接,未能考慮序列特征和文本特征的權(quán)重,平等地看待每一維特征,導(dǎo)致預(yù)測的效果最差。點乘融合方式通過設(shè)置權(quán)重,不斷調(diào)整得到較優(yōu)結(jié)果,效果明顯優(yōu)于拼接方式,但點乘融合方式多通過人工設(shè)置權(quán)重,未必能夠得到最優(yōu)的結(jié)果。而本文的方法,即通過SVM 的特征融合模型能夠避免以上弊端,自動學(xué)習(xí)最優(yōu)權(quán)重,使技術(shù)融合預(yù)測任務(wù)效果最好。
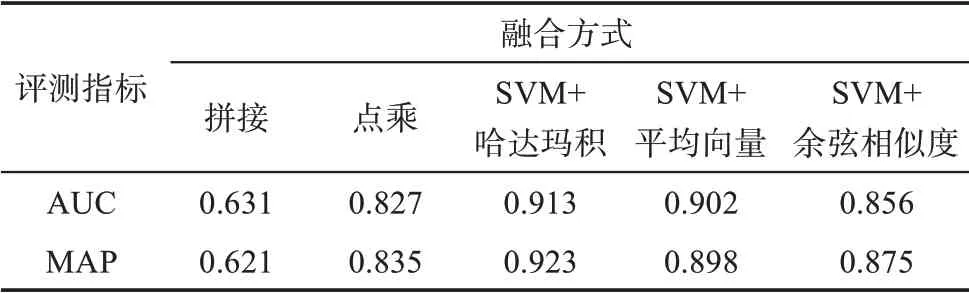
表7 不同融合方式下的AUC和MAP對比
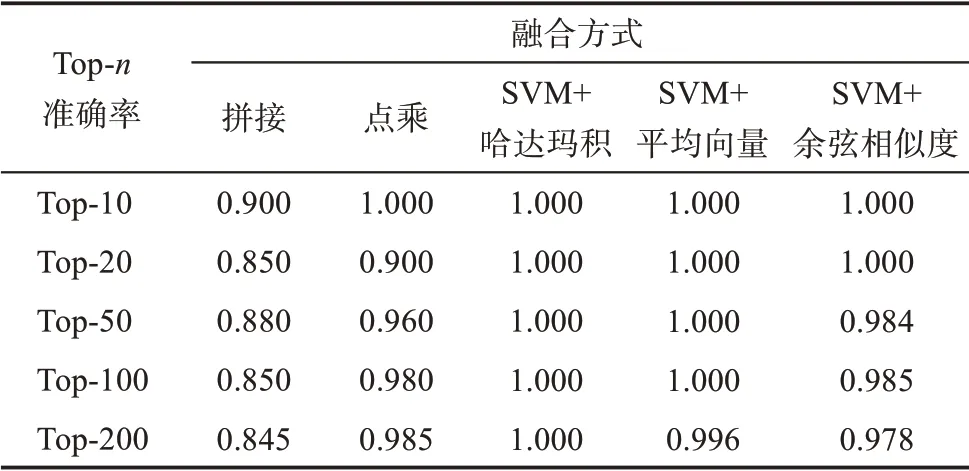
表8 不同融合方式下的準(zhǔn)確率對比
從不同的SVM 融合模型來看,通過哈達(dá)瑪積合并方式融合序列與文本特征,在三種模型中效果最優(yōu),“SVM+平均向量”模型效果次優(yōu),“SVM+余弦相似度”模型效果較差。從AUC 和MAP 的情況來看,“SVM+平均向量”模型的AUC、MAP 值分別為0.902 和0.898,“SVM+哈達(dá)瑪積”模型較之分別提高了0.011 和0.025;相較于“SVM+余弦相似度”模型,“SVM+哈達(dá)瑪積”模型分別提高了0.057 和0.048。表8 的準(zhǔn)確率對比結(jié)果同樣證實了該結(jié)論,其中“SVM+哈達(dá)瑪積”的準(zhǔn)確率穩(wěn)定保持為1.000,且SVM 相關(guān)的其他兩種方法同樣表現(xiàn)優(yōu)異,說明SVM 模型能高效學(xué)習(xí)不同特征的權(quán)重,進(jìn)而提高技術(shù)融合預(yù)測效果;也說明在不同的向量合并方式下,基于SVM 的哈達(dá)瑪積融合方式更適用于技術(shù)融合預(yù)測任務(wù)。值得一提的是,“SVM+余弦相似度”模型在效果上雖然不如其他兩種模型,但在實驗過程中該方式訓(xùn)練速度最快,因此該融合模型對于大規(guī)模數(shù)據(jù)有一定的應(yīng)用價值。
綜合以上分析發(fā)現(xiàn),“SVM+哈達(dá)瑪積”模型的表現(xiàn)最優(yōu),在效果和穩(wěn)定性上優(yōu)于網(wǎng)絡(luò)模型和文本模型。“SVM+哈達(dá)瑪積”模型的AUC 和MAP 值較專利分類序列表示學(xué)習(xí)模型分別提高了0.056 和0.046,較專利文本表示學(xué)習(xí)模型分別提高了0.191和0.197。此外,“SVM+哈達(dá)瑪積”模型的Top-n 準(zhǔn)確率均為1.000,與專利分類序列表示學(xué)習(xí)模型一致,大幅度優(yōu)于專利文本表示學(xué)習(xí)模型。當(dāng)擴(kuò)展實驗使n 增大到300 以上時,專利分類序列表示學(xué)習(xí)模型的準(zhǔn)確率開始下降,而“SVM+哈達(dá)瑪積”模型的準(zhǔn)確率仍能保持為1.000。這些都充分說明融合特征模型通過自動學(xué)習(xí)序列和文本特征的每一維權(quán)重,充分有效地利用了專利分類的多種上下文語義信息,從而得到了最好的效果。
4.5 技術(shù)融合預(yù)測示例
本文選取在所有評測指標(biāo)中表現(xiàn)最好的語義表示模型“SVM+哈達(dá)瑪積”模型來進(jìn)行示例展示和分析。與上文實驗一致,示例分析中歷史數(shù)據(jù)來源于無人機領(lǐng)域2011 年到2019 年的數(shù)據(jù),通過該數(shù)據(jù)集來計算之前未產(chǎn)生過關(guān)聯(lián)的IPC 對在未來發(fā)生融合的可能性,并在2020 年的測試集數(shù)據(jù)中進(jìn)行驗證。通過這些預(yù)測結(jié)果,能夠?qū)o人機的技術(shù)融合趨勢進(jìn)行預(yù)測,及時把握無人機領(lǐng)域未來的發(fā)展方向并提供決策支持建議。
在通過“SVM+哈達(dá)瑪積”模型計算IPC 組合產(chǎn)生鏈接的概率并進(jìn)行降序排列時,發(fā)現(xiàn)有較多組合鏈接概率均達(dá)到了0.9999999,且都在測試集中出現(xiàn),準(zhǔn)確率達(dá)到1.000。因此,本文根據(jù)專利數(shù)據(jù)中IPC 的已有順序,選取排序前10 位的IPC 組合對進(jìn)行具體分析,如表9 所示。
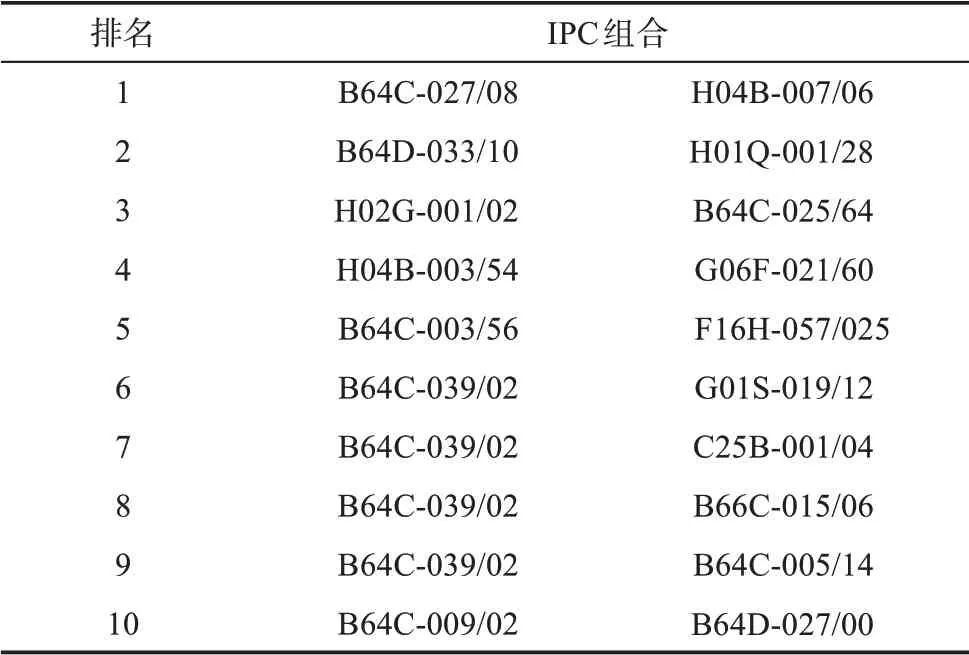
表9 “SVM+哈達(dá)瑪積”模型預(yù)測出的排序前10位的IPC組合對
如表9 所示,對于鏈接概率排序第一的IPC 組合,B64C-027/08 表示“飛行器有兩個或多個旋翼的”,H04B-007/06 表示“無線電傳輸系統(tǒng)”,該IPC組合在專利號為JP2020196355-A 的專利文獻(xiàn)中出現(xiàn)。從摘要中發(fā)現(xiàn),該文獻(xiàn)主要提及“將多個天線安裝在無人機的多個旋翼中,并通過地面站發(fā)射無線電信號對無人機進(jìn)行實時調(diào)整”,可以看出該專利將無人機的多旋翼技術(shù)與無線電傳輸技術(shù)進(jìn)行了有效的結(jié)合,實現(xiàn)了對多旋翼無人機的實時監(jiān)控。對于排序第二的IPC 組合,B64D-033/10 表示“飛機的散熱器配置”,H01Q-001/28 表示“適合于飛機、導(dǎo)彈、衛(wèi)星或氣球上或其內(nèi)使用的天線零部件”,該組合在專利號為WO2020251-216-A1 的專利文獻(xiàn)中出現(xiàn),該專利將兩個不同的技術(shù)模塊通過一定的方式進(jìn)行組合,推動了無人機技術(shù)的發(fā)展。此外,B64C-039/02 表示“特殊用途的飛行器”,該專利分類與G01S-019/12(“遠(yuǎn)程通信基站與接收器之間進(jìn)行交互或通信”)、C25B-001/04(“電解水法”)、B66C-015/06 (“警告裝置的布置或應(yīng)用”)、B64C-005/14 (“改變后掠角的”) 等IPC 發(fā)生了融合,說明B64C-039/02 具備較強的技術(shù)融合特性。通過示例可以看到,融合專利分類序列和文本的語義信息進(jìn)行技術(shù)融合預(yù)測具有較好的效果,可以提前預(yù)測可能的技術(shù)融合,為技術(shù)布局、技術(shù)研發(fā)提供借鑒和參考。
5 結(jié) 語
為了提升專利分類語義表示能力,提高技術(shù)融合預(yù)測效果,本文提出了基于專利分類序列和文本語義表示的技術(shù)融合預(yù)測方法。首先直接對專利分類序列進(jìn)行表示學(xué)習(xí),設(shè)計專利分類序列表示學(xué)習(xí)方法,得到每一個專利分類號的位置信息及上下文語義信息,相較于其他網(wǎng)絡(luò)表示學(xué)習(xí)模型,取得了最好的效果;為體現(xiàn)不同專利分類號在一篇專利文獻(xiàn)中的重要程度,本文逐步賦予每位專利分類號以文本信息,最大限度地提高不同專利分類號的區(qū)分度,實驗結(jié)果證明,本文方法優(yōu)于以往平均分配文本的方式,且發(fā)現(xiàn)賦予第一位專利分類號以文本時技術(shù)融合預(yù)測效果最好;為了有效融合序列向量與文本語義向量,充分利用每一維特征的貢獻(xiàn),本文設(shè)計了三種向量合并方式,利用SVM 模型自動學(xué)習(xí)權(quán)重實現(xiàn)技術(shù)融合預(yù)測,該融合方法在所有方法中表現(xiàn)最優(yōu),且其中最好的融合方式為“SVM+哈達(dá)瑪積”。
本文從專利分類序列和文本語義融合的視角對技術(shù)融合預(yù)測進(jìn)行了探索性研究,提出的方法較之前均有了較大提高,但未來仍需從多個方面展開深入研究。首先,本文只使用了專利的標(biāo)題、摘要來表示專利文本,實際上,專利聲明和專利全文中蘊含著更豐富的文本信息,可能有益于專利文本表示,未來需要進(jìn)行嘗試和對比。其次,在專利文本賦予方式的比較過程中發(fā)現(xiàn),僅對專利分類號序列中的第一位專利分類號賦予文本時技術(shù)融合預(yù)測效果最優(yōu),但是這種方式會導(dǎo)致部分專利分類號不存在對應(yīng)文本的情況,后續(xù)可以嘗試引入專利特征項中其他文本內(nèi)容或者外部信息來賦予每一位專利分類號以文本,更好地進(jìn)行專利分類文本賦予。最后,本文僅從專利分析視角研究了技術(shù)融合的某一特定類型,實際上,技術(shù)融合的表現(xiàn)形式多種多樣,尚需結(jié)合市場、產(chǎn)品、主題等進(jìn)行綜合評判,未來可以綜合利用專利數(shù)據(jù)、商標(biāo)數(shù)據(jù)、研究報告和市場信息綜合研究技術(shù)融合預(yù)測的指標(biāo)、方法和評測框架,實現(xiàn)更準(zhǔn)確的技術(shù)融合預(yù)測,提升決策支持效果。
猜你喜歡
今日農(nóng)業(yè)(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年1期)2021-03-19 08:28:38
現(xiàn)代出版(2020年3期)2020-06-20 07:10:34
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
大連民族大學(xué)學(xué)報(2015年2期)2015-02-27 08:28:11
