基于Deeplab v3+的高分辨率遙感影像地物分類研究
2022-07-04 01:54:54陸妍如毛輝輝宋現鋒
地理空間信息 2022年6期
陸妍如,毛輝輝,賀 琰,宋現鋒,2*
(1. 中國科學院大學資源與環境學院,北京 100049;2. 中國科學院地理科學與資源研究所,北京 100101)
傳統的面向對象方法和機器學習方法在高分辨率遙感影像信息提取方面發揮了重要作用[1-9]。近年來,卷積神經網絡(CNN)發展迅速[10-19]。當前這些方法均在一定程度上提升了圖像分類精度,但是仍然存在著一些不足之處。Deeplab v3+[20]是Deeplab系列的最新改進模型版本,具有多尺度捕捉對象信息、獲取目標清晰邊界的優點,是目前最新的語義分割網絡之一。為了實現自動化程度更高、結果更精確的高分辨率遙感影像特征信息提取,本文深入分析Deeplab v3+模型結構,基于GF-2 米級與無人機亞米級遙感影像與其他網絡模型開展地物分類對比實驗,探究了該模型在高分影像幾何結構特征提取方面的優勢和有效性。
1 Deeplab v3+網絡模型
1.1 模型結構
DeepLab v3+網絡由兩部分組成:編碼和解碼模塊,編碼模塊由改進的Xception 網絡[20]和ASPP[21]模塊組成。如圖1 所示,訓練樣本經由Xception 網絡提取特征,然后經ASPP 獲取多尺度信息并聚合全局特征,最后經1×1卷積輸出具有深層特征的特征圖。將該特征圖做雙線性上采樣,同時把對Xception 網絡對應的同分辨率淺層特征做1×1卷積。最后將淺層特征和深層特征做卷積融合連接,對該多尺度特征做雙線性上采樣并實現分類預測。
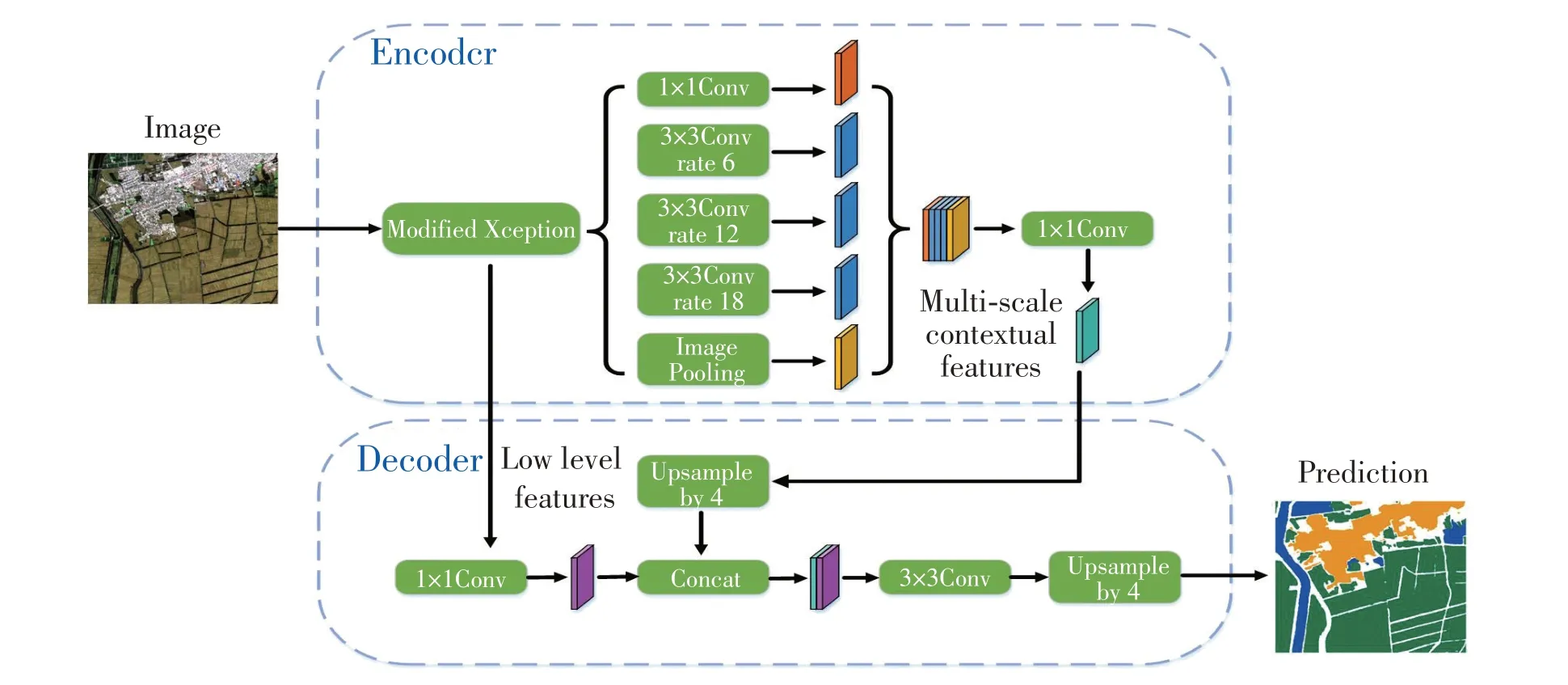
圖1 Deeplab v3+網絡結構
1.2 Xception改進模塊
如圖2所示,Xception網絡框架分為三部分:入口流、中間流和出口流。入口流用于對輸入圖像下采樣以減小空間尺寸,而中間流則用于連續學習關聯關系和優化特征,出口流對特征進行排序以獲得粗略的得分圖。結構圖中的紅色部分為改進部分:①中間流層數變多,深度可分離卷積層的線性堆疊由重復8 次改為16 次;②將原來簡單的池化層改成了stride 為2 的深度可分離卷積;③額外的RELU 層和歸一化操作添加在每個3×3 深度卷積之后。
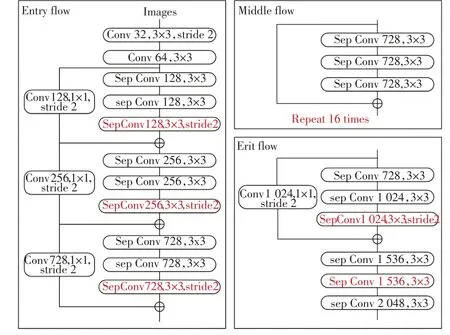
圖2 Xception改進網絡結構圖
1.3 ASPP和編解碼模塊
ASPP 模塊包含兩部分:一是使用多個不同大小的空洞卷積核并行地對輸入特征圖進行特征提取,獲取不同感受野大小的特征圖;二是將輸入特征圖做全局平均池化來取得圖像上下文信息,然后將這些不同尺度特征融合以獲取更精準的深層語義特征。
在編碼階段,網絡通過卷積等操作減小圖片尺寸并學習輸入圖像的特征圖;在解碼階段,通過卷積、上采樣等方法逐漸恢復目標細節和空間信息。編解碼器能夠極大提升神經網絡前向、后向傳播效率,減少內存資源的使用。
1.4 擴張卷積和深度可分離卷積
擴張卷積[22]是在標準卷積的核中注入空洞,使其不通過池化層也能有較大的感受野,在不降低分辨率的情況下聚合范圍更廣的特征信息。如圖3 所示,以3×3的卷積核為例說明感受野的增加情況。空洞率為2的3×3 卷積核的感受野已經增大為7×7。同理,空洞率為4的3×3卷積能達到15×15。
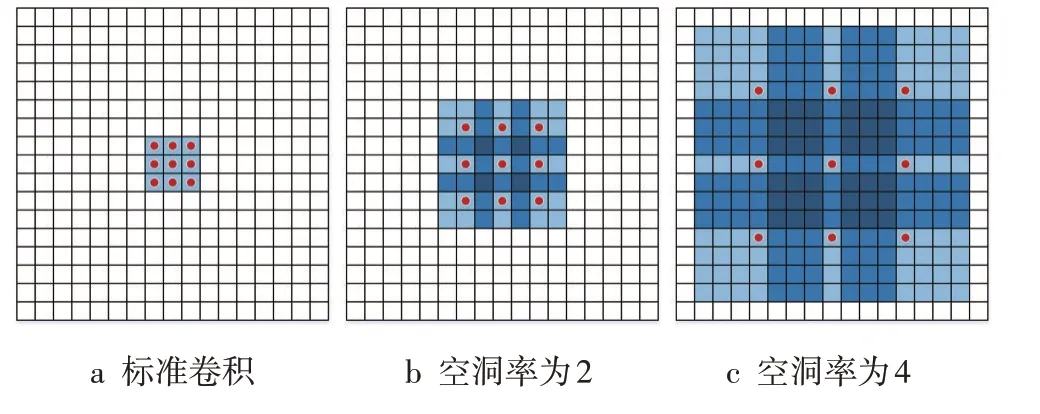
圖3 擴張卷積
深度可分離卷積[20]把標準卷積分解為深度卷積和逐點卷積(圖4),其中深度卷積獨立對每個輸入通道做空間卷積,逐點卷積用于結合深度卷積輸出。深度可分離卷積極大地抑制模型參數的增加。Deeplab v3+網絡將擴張分離卷積,應用于ASPP和解碼器模塊。
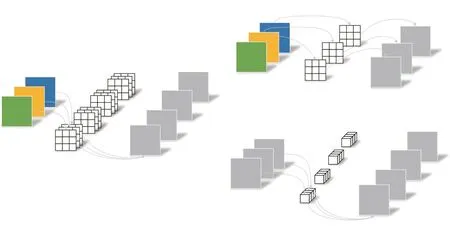
圖4 深度可分離卷積
2 實驗設計
本文利用高分辨率遙感影像為實驗數據集,開展Deeplab v3+和UNet、SegNet、FCN8s 的地物分類對比實驗,比較分類精度和分析地物識別存在差異的原因,探查Deeplab v3+模型在富含紋理特征的高空間分辨率遙感影像分類上的有效性與適用性。
2.1 數據集選擇
本文采用2 種遙感影像實驗數據集(圖5),GID數據集[23]空間分辨率為4 m,光譜為可見光波段(RGB)和近紅外波段(NIR),地物類型6 類(耕地、植被、建筑用地、道路、水系以及其他)。CCF數據集空間分辨率為0.3 m,光譜為可見光波段(RGB),地物類型5 類(植被、建筑、水體、道路以及其他用地)。
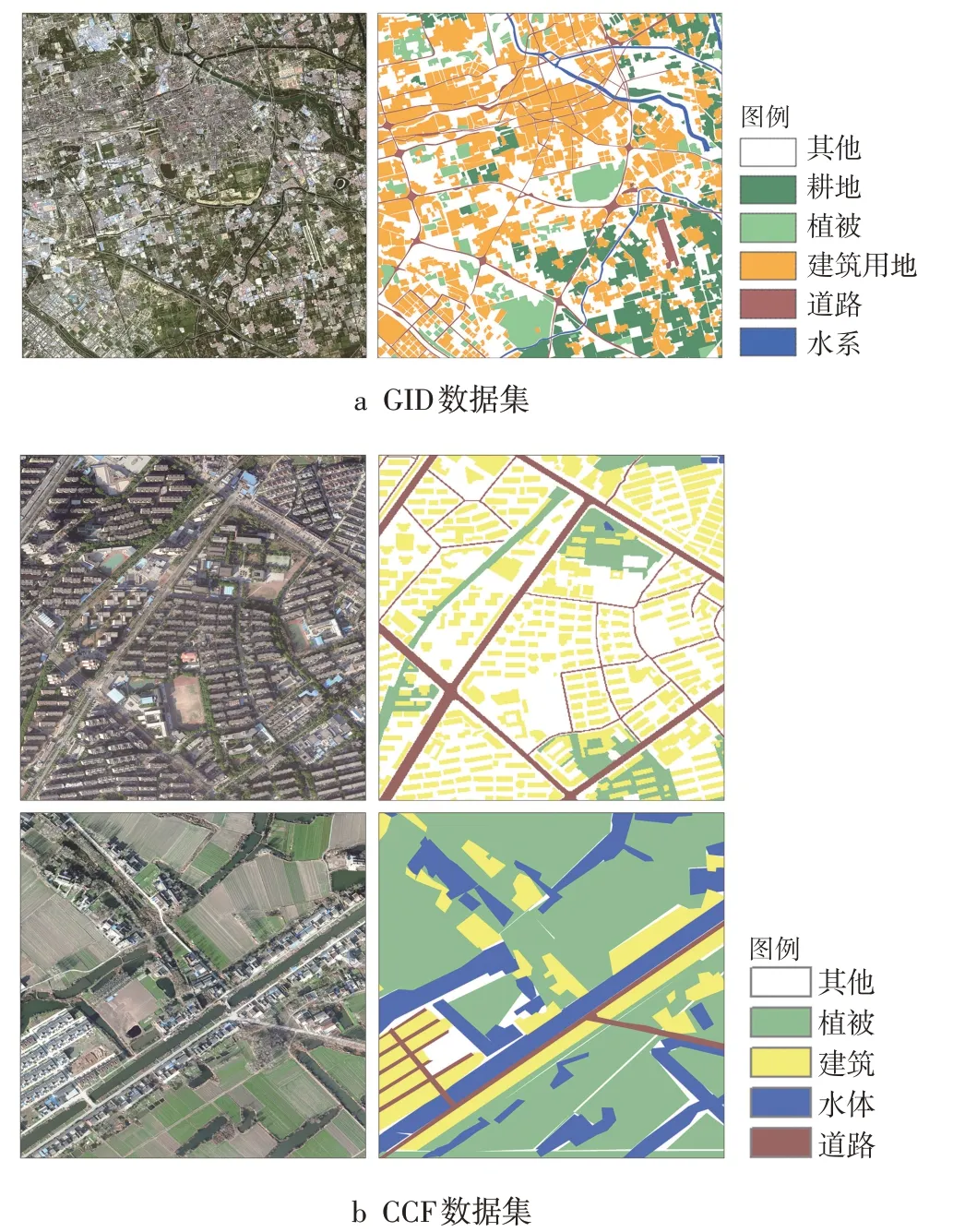
圖5 數據集示例
2.2 訓練樣本構建
兩組圖像覆蓋范圍都比較大,空間分辨率高,圖像尺寸大且不統一,直接輸入整幅圖像訓練模型會造成內存溢出。本文以128 像素為步長、以256×256 像素為裁剪尺寸,對影像進行從左到右、從上到下的滑動窗口裁剪以獲取訓練樣本切片數據。此外,原始數據存在類別分布不均衡問題(表1),本文去除0值像元占面積70%以上的訓練切片,以平衡正負樣本量。
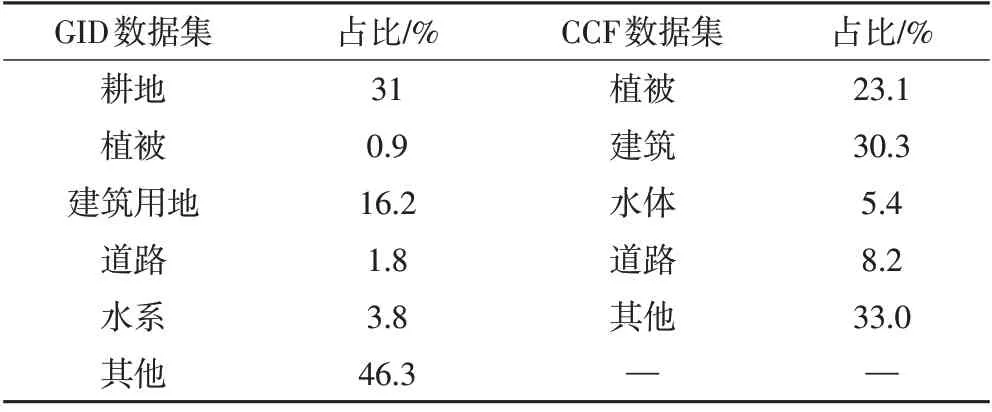
表1 兩個數據集地物分布占比
數據增強可以在數據集有限的情況下達到擴充訓練數據的效果,即數據增多使得模型過擬合概率降低,增強了模型泛化能力。本文采用旋轉、翻轉等方法,獲得GID有效樣本82 264個,訓練集和驗證集按4∶1比例進行劃分,CCF有效樣本54 304個,訓練集和驗證集按3∶1比例進行劃分。
2.3 分類精度評價
混淆矩陣是比較遙感影像分類結果與參考結果的常見統計方法,其分類精度評價指標包括總體精度(overall accuracy,OA)、精確度(Precision)、召回率(Recall)、F1值、交并比(IoU)和Kappa 系數。其中,總體精度表示正確分類的像素占總像素的比例;精確度表示在預測該類別像素中被預測正確的比例;召回率表示該類別在真實像素中被預測正確的比例;F1值為召回率和準確率的調和均值;交并比反映了實際類別樣本和預測類別樣本的交集和并集之比。
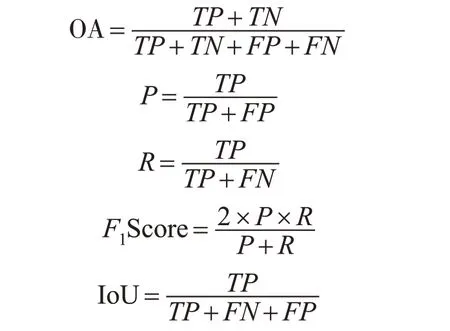
式中,TP是分類準確的正類;FP是被錯分為正類的負類;TN是分類準確的負類;FN是被錯分為負類的正類。
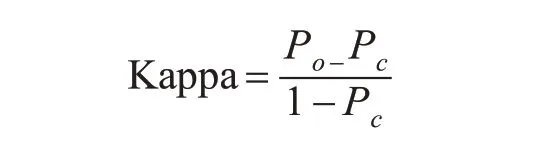
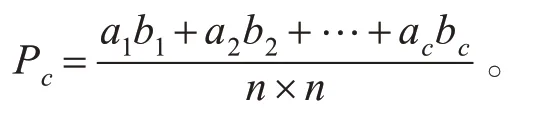
2.4 實驗平臺及參數設置
本文實驗以Pytorch 為開發框架,OS 為Ubuntu,CUDA版本為11.0,顯卡RTX2080TI GPU的顯存11 G*8,機器內存為48 G。GID 數據集分類模型的超參數:通道 個 數 為4,類 別 數 為6,batch size 為8,epoch 為20,優化算法Adam,基礎學習率0.000 3。CCF 數據集分類模型的超參數:通道個數為3,類別數為5,batch size 為8,epoch 為50,優化算法Adam,基礎學習率0.001。此外,訓練樣本類別不平衡造成的信息失衡會對網絡分類的性能產生較大影響。本文在訓練過程中采用了Lovasz-Softmax[24],它是一種基于IoU 的損失函數,可有效減弱上述影響。
3 結果分析
3.1 不同語義分割網絡對GF-2影像的地物分類結果比較
使用GID數據集對Deeplab v3+、UNet、SegNet和FCN8s網絡進行訓練并將分類結果與真值比較,得到各語義分割模型的分類結果精度指標(表2)。
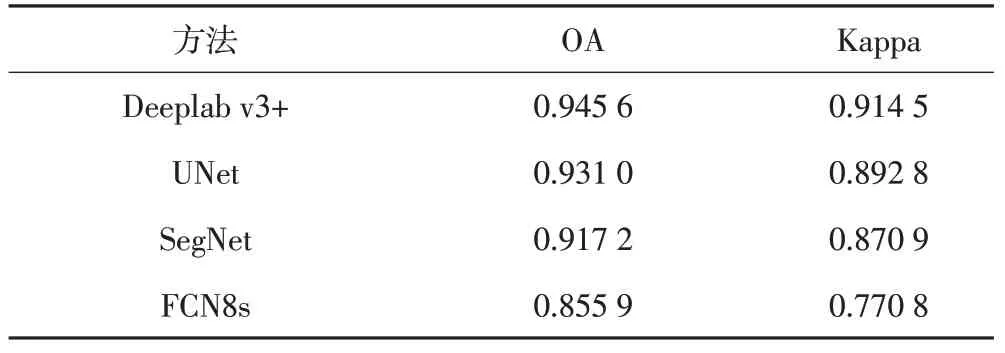
表2 語義分割網絡分割結果指標對比
在總體精度OA 指標上,Deeplab v3+表現最優,FCN8s 得分較低;在Kappa 系數方面,Deeplab v3+得分在0.9之上,相較UNet、SegNet FCN8s有明顯優勢。
圖6 分別給出了測試影像完整圖幅和其局部特征區域的分割結果,其中第一行圖像為不同語義分割模型的完整圖幅分類結果,可以看出4 個模型對大型水系均有較好的分割效果,但FCN8s模型對建筑用地的識別效果不佳;第二行影像側重于展示各模型對橋體的提取效果,其中僅Deeplab v3+能夠精準識別出細小狹長的橋體目標;第三行影像著重顯示各模型對建筑用地與道路的劃分效果,相較于其他三類模型,Deeplab v3+能夠提取清晰的路網及建筑用地輪廓線;第四行影像側重于比較各模型對湖泊的提取效果,其中Deeplab v3+表現最佳,能夠精確的檢測出湖泊邊界。從整體視覺上看,相比于Deeplab v3+的優異表現,UNet、SegNet、FCN8s的分割結果不夠理想,這是由于它們多次使用池化操作,損失了影像中的高頻成分,丟失了位置信息,造成地物分類精度較差,且分割邊界較粗糙。

圖6 地物分類結果對比
圖7 和表3 揭示了各模型對不同地物類型的識別能力。Deeplab v3+、UNet、SegNet都對水系有著較好的分割效果,F1值均大于0.9,這是由于水體在近紅外波段與其他地物的顯著差異性所致。對于道路等細小狹長線狀目標,所有模型識別效果都有所降低,其原因可能在于:①道路細長的空間形態特性,使得識別不全,導致召回率較低;②道路像元數目在訓練集占比很低(1.8%),稀疏樣本使得訓練不充分;盡管如此,Deeplab v3+提取的路網仍然最為清晰、完整;對于建筑用地、耕地等塊狀地物分類,Deeplab v3+的F1值分別為0.956和0.938,IoU為0.916和0.888,明顯優于其他模型。同其他3種模型相比,Deeplab v3+使用擴張卷積替代連續池化,在不降低特征空間分辨率的情況下增大感受野,使得輸出特征更加稠密,有效解決了高分影像地物的“同物異譜”問題。針對物體的多尺度問題,ASPP 模塊以不同采樣率的擴張卷積采樣,多比例捕捉圖像信息,提高了特征提取能力。編碼-解碼模塊則逐步重構空間信息精確捕捉了地塊邊緣。
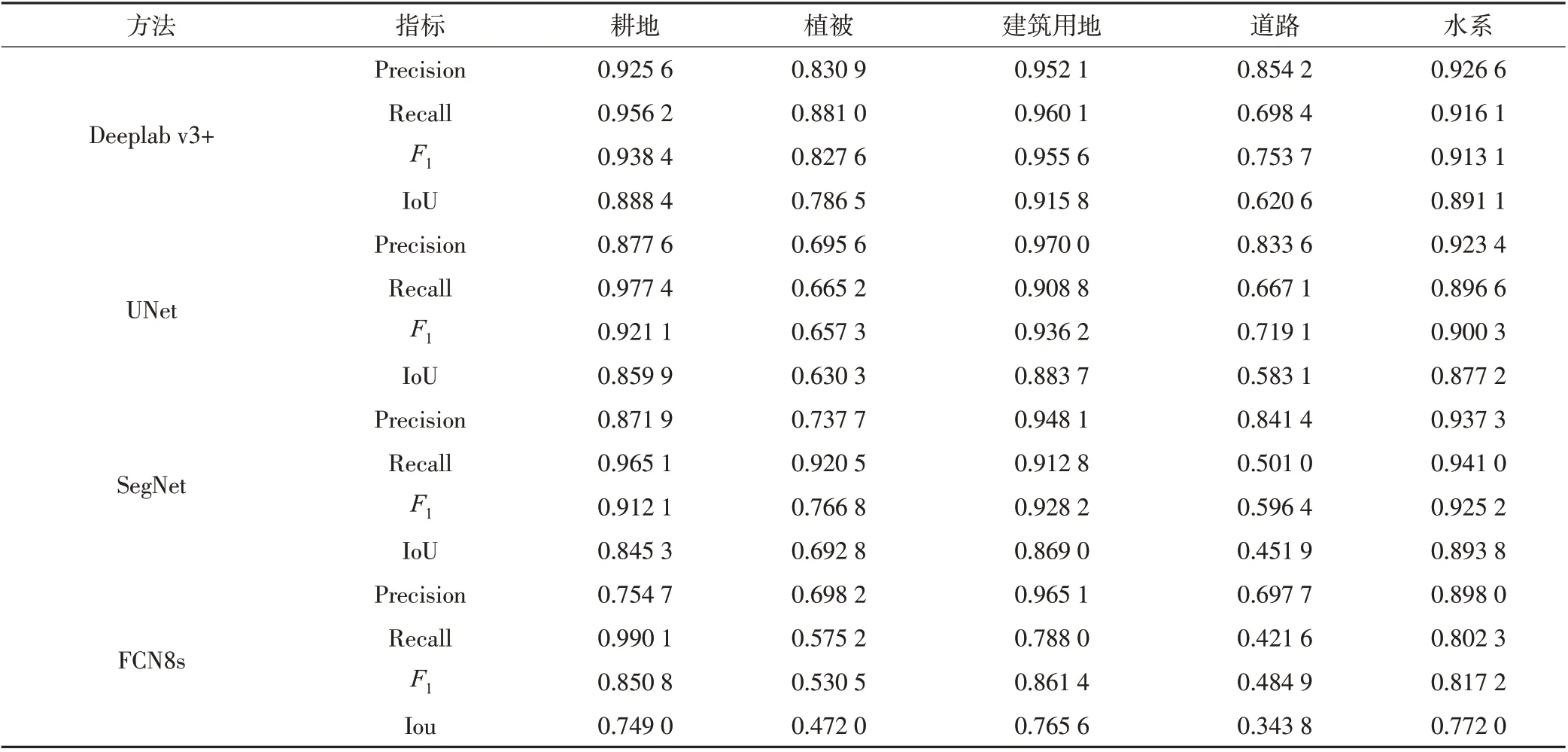
表3 各方法在不同地物類別上的分割效果
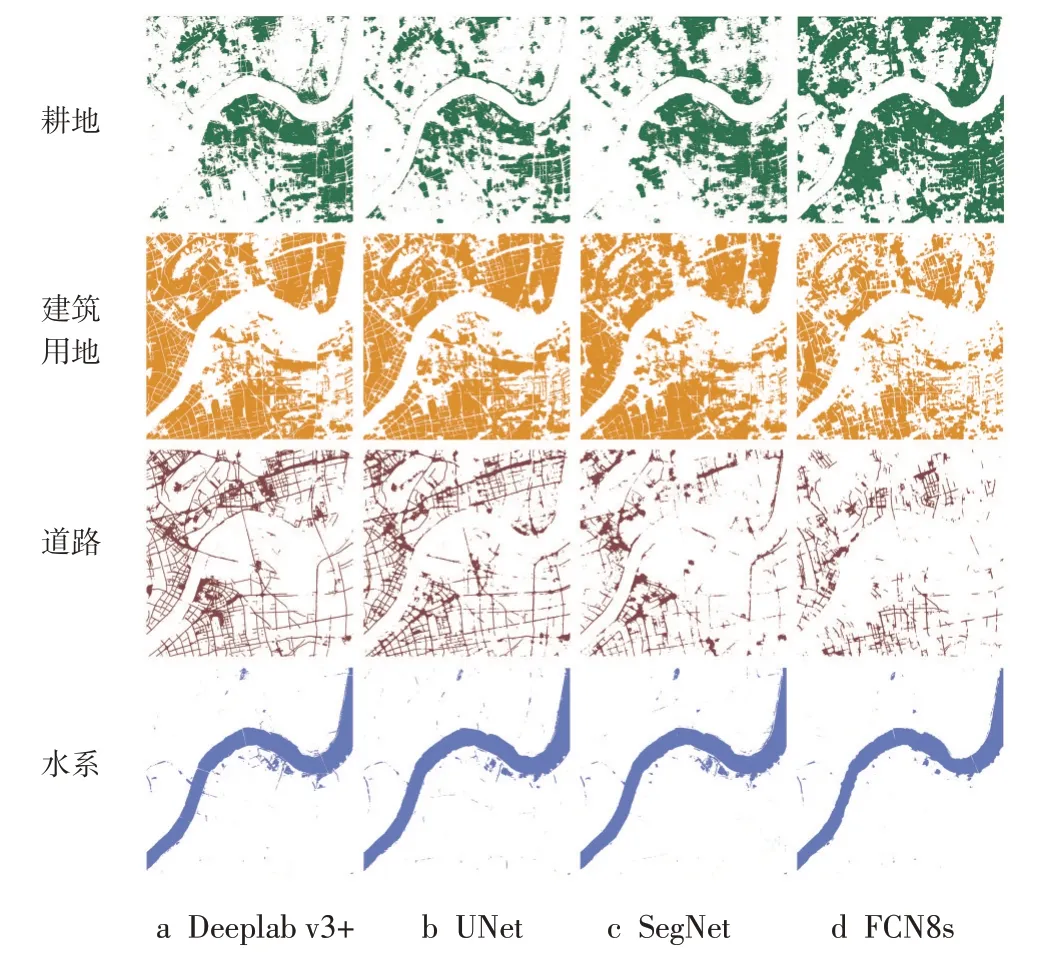
圖7 不同類別地物的分類結果對比
3.2 Deeplab v3+對亞米級航拍影像地物識別的有效性分析
使用CCF數據集訓練Deeplab v3+網絡并進行地物分類,對比分類結果與真值,其OA、Kappa系數分別為0.88、0.82。航拍影像紋理特征突出,同類地物內部的幾何結構增加了不同類別地物之間邊界的識別難度。由圖8 可以看出,Deeplab v3+分割結果和真實值比較接近,整體視覺上分割效果較好。具體而言,在建筑和道路主導的鄉鎮地區,模型對建筑邊界的響應表現優異,房屋陰影影響了小部分路段識別;而對于植被(耕地)主導的農村地區,模型同樣能對水體和耕地進行準確的提取,且分割邊界較為平滑。
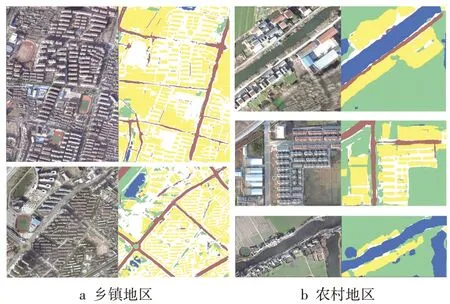
圖8 Deeplab v3+在CCF數據集上的分割結果
對比Deeplab v3+模型和文獻建議的分割模型[25],CCF 數據集分類的評價指標(圖9)表明Deeplab v3+在對水體、道路、植被和建筑這4 種地物類型的識別上表現優異,相對其他語義分割模型取得了較高的F1值和IoU 值。總體而言,Deeplab v3+模型能夠滿足亞米級航拍影像的特征信息提取和影像分割需求。
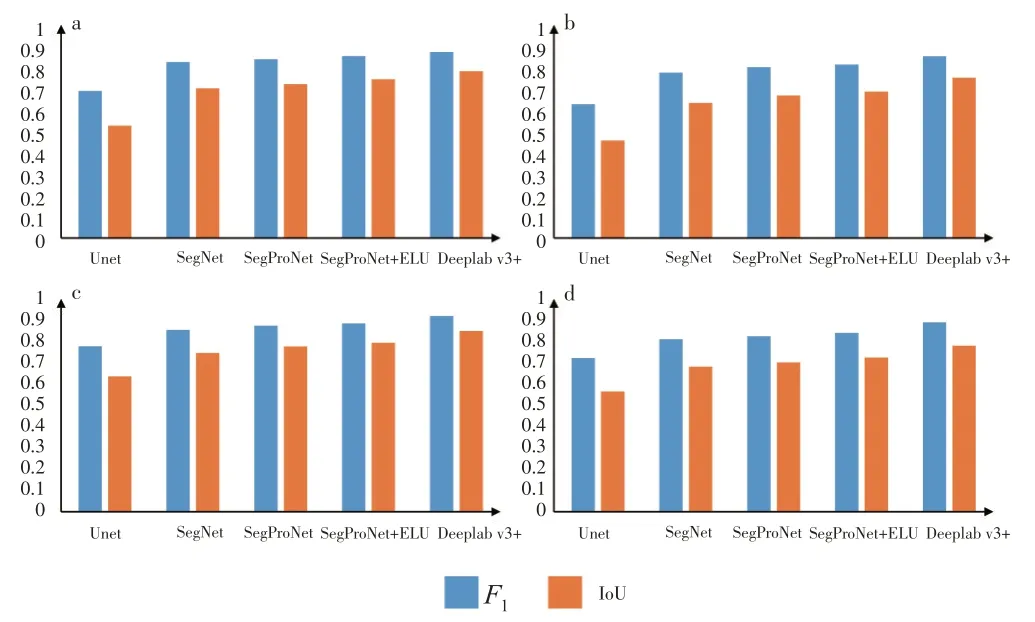
圖9 各模型在CCF數據集的地物分類精度評價指標
4 結 論
針對傳統神經網絡模型對高分辨率遙感影像分割精度不足的問題,實施了相應對措:①本文采用Deeplab v3+模型在GID 數據集上開展地物分類研究,其分類總體精度OA 和Kappa 系數分別為0.945 和0.915。與FCN、UNet、SegNet 模型的分類結果相比,Deeplab v3+能實現目標要素的完整提取,尤其是對線狀目標的識別,具有較為明顯的精度優勢。②針對亞米級無人機遙感影像,Deeplab v3+的分類總體精度OA和Kappa 系數分別為0.88、0.82,較之其他模型能實現對遙感影像中建筑物等人工地物更準確的提取,具有較高的可靠性。本文對高分辨率遙感影像要素提取具有一定參考價值,為深度學習在高分辨率遙感影像地物分類中的應用提供了參考方案。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
