基于ResNet的音頻場景聲替換造假的檢測算法
2022-07-05 08:28:58董明宇嚴迪群
計算機應用 2022年6期
董明宇,嚴迪群
基于ResNet的音頻場景聲替換造假的檢測算法
董明宇1,嚴迪群1,2*
(1.寧波大學 信息科學與工程學院,浙江 寧波 315211; 2.東南數字經濟發展研究院,浙江 衢州 324000)(*通信作者電子郵箱yandiqun@nbu.edu.cn)
針對造假成本低、不易察覺的音頻場景聲替換的造假樣本檢測問題,提出了基于ResNet的造假樣本檢測算法。該算法首先提取音頻的常數Q頻譜系數(CQCC)特征,之后由殘差網絡(ResNet)結構學習輸入的特征,結合網絡的多層的殘差塊以及特征歸一化,最后輸出分類結果。在TIMIT和Voicebank數據庫上,所提算法的檢測準確率最高可達100%,錯誤接收率最低僅為1.37%。在現實場景下檢測由多種不同錄音設備錄制的帶有設備本底噪聲以及原始場景聲音頻,該算法的檢測準確率最高可達99.27%。實驗結果表明,在合適的模型下利用音頻的CQCC特征來檢測音頻的場景替換痕跡是有效的。
音頻造假;音頻場景聲替換;殘差網絡;常數Q頻譜系數
0 引言
隨著人們生活水平的提高,信息已經成為人們日常生活中的接觸媒體,用來與外界進行溝通,了解外界的發展情況。然而信息的不對稱性可能會導致信息造假的現象,而這種造假技術所產生的信息很有可能是人們利用自身條件無法辨別的,其中造假新聞的出現會嚴重誤導沒有相關辨別能力或者技術的人[1]。例如現在電影中的計算機動畫(Computer Graphics, CG)技術,它將合成技術應用到特效電影中,幾乎到了人眼無法分辨的程度。這樣的技術雖然能帶來視覺上的享受,但也會帶來一定的危害,如果不法分子利用這種技術對人們日常接觸的信息進行修改將會造成非常惡劣的影響;而且利用現在的技術進行造假并不是非常困難,造假的產物也真假難辨。
隨著深度學習技術的日益進步與普及,普通用戶利用這項技術對多媒體媒介(圖像、視頻、音頻)進行造假的能力有了明顯的提升。在音頻領域,一些工具能讓造假音頻從人類的聽覺角度上達到難以辨認的地步。造假技術具有非常多樣的變化,其中音頻的降噪工具的應用使得場景聲替換的音頻能夠更加真實。如造假者把一段只含有說話人說話的音頻與一段只含有場景聲的音頻合成在一起,將會生成一種極具欺騙性的音頻,且從聽覺上很難區分真假。通常可以利用這種方式隱藏說話人的真實位置信息,但也有不法分子將說話人的某段音頻與某些違法場所的錄制音頻進行合成,制造說話人有違法行為的假象,并對說話人進行敲詐勒索。從法證的角度上講,音頻證據需要有完整性和真實性的保障,因此辨別音頻是否有經過場景聲替換的痕跡是很有必要的。
在音頻領域,已經有研究對音頻的變調不變速造假樣本[2]、音頻重捕獲樣本[3]等進行檢測,但據作者了解,目前對音頻的場景聲替換的研究還較少。
大部分音頻檢測算法的第一步往往是提取音頻的某些特征,如利用梅爾倒譜系數(Mel-Frequency Cepstral Coefficients, MFCC)特征來進行說話人驗證[4]。常數Q頻譜系數(Constant Q Cepstral Coefficient, CQCC)作為音頻的一類特征值,其特點是時間分辨率可變,優點是能夠很好地描述音頻波形走勢上的信息,在計算常數Q變換(Constant-Q Transform, CQT)時能夠將時域信息轉換到頻域,有更小的帶寬,使得低頻部分信息能夠更詳細地被突出。基于CQT的倒譜分析已經被Lidy等[5]用于音頻場景聲的識別,并取得了一定的成功。發展到現在,如今的算法對CQT的頻率尺度進行了線性化,從而保持了離散余弦變換(Discrete Cosine Transform, DCT)基的正交性。
在圖像領域,殘差網絡(Residual Network, ResNet)在分類上的表現很出色[6-7];在音頻領域,也有研究在頻域上使用ResNet對載體進行隱寫分析[8],針對聲音場景分類的任務在使用ResNet時也取得了不錯的效果[9]。在ASVspoof 2019的比賽上,ResNet的網絡結構的優勢也得到了驗證,取得了很好的比賽成績。因此本文也考慮使用一個二分類的ResNet對從音頻中提取到的CQCC特征值進行分析,以判斷音頻是否進行過場景替換操作。本文的主要工作如下:利用深度學習方法對場景聲替換造假音頻進行檢測,并結合多種深度學習框架和機器學習模型與音頻的特征探究了能最大區分場景聲替換音頻的方法。
1 場景替換的造假音頻
對于音頻場景聲替換的應用背景首先需要確定的是正負樣本的定義以及數據庫。本文定義正樣本即原始樣本未經過任何操作的且由錄音設備進行錄制的樣本,負樣本為將錄制好的場景聲音頻疊加到原始音頻后得到的樣本。實驗數據庫來自于開放且知名度非常高的TIMIT[10]以及Voicebank[11]數據庫。原始的純凈樣本是未經過處理的原始音頻,原始音頻并不含有任何帶有場景的聲音。其中TIMIT是由德州儀器、麻省理工學院和SRI International合作構建的聲學-音素連續語音語料庫。TIMIT數據庫的語音采樣頻率為16 kHz,位深度為16 bit。該數據庫包含來自美國不同地區的630個人的聲音,其中70%的說話人是男性,大多數說話者是成年白人。參與者每人說出10個不同句子,最后總共獲得6 300個樣本,所有的句子都在音素級別上進行了人工標注。在Voicebank數據庫中選擇了30個說話人,每個音頻都是16 kHz的采樣頻率。
實驗選用的場景聲的音頻也是同樣來自于知名的開放數據庫Demand[12]。該數據庫包含多種不同場景下錄制的場景聲,每一段是長達5 min的音頻,有咖啡廳、車站、廚房等不同的場景,所有的音頻都為單通道且采樣頻率為16 kHz。
由上述定義,正樣本為原始未修改過的音頻,而負樣本則是將Demand數據庫進行裁剪疊加到原始音頻上得到的一段帶有場景聲的語音音頻。從主觀角度來評價制作的負樣本,負樣本完全可以以假亂真、混淆視聽。
對正樣本與負樣本進行時域及頻域上的分析。首先獲取正負樣本的語譜圖,并將其數據取對數來放大它們的時域以及頻域分布,如圖1所示:圖(a)、(c)為原始音頻,圖(b)、(d)為場景替換音頻;為了放大真假樣本音頻的區別部分,圖(a)、(b)為取了對數處理的語譜圖,圖(c)、(d)是正常語譜圖。
在圖1(a)中可以明顯看到,高亮的部分基本集中在中低頻說話人講話的部分。而經過場景聲音頻的疊加后,會將原先高亮的部分分布模糊化,在低頻部分還多了一些新的信息。從圖1(d)可以看到,被掩蓋之后依舊會表現出跟原始分布略有差異的表現形式,只是有些地方會被“修改”得表現不出原始音頻的特性,大部分疊加到原始音頻上的部分集中在低頻部分,某些中高頻部分也會發生一些突變,只是數量比較少。因此,從語譜圖上分析來看,可以使用一些能夠表現人類說話相關的特征值來描述音頻,例如MFCC、CQCC等,這些音頻的特征可以將低頻中的信息放大,進而將兩者區別開來。
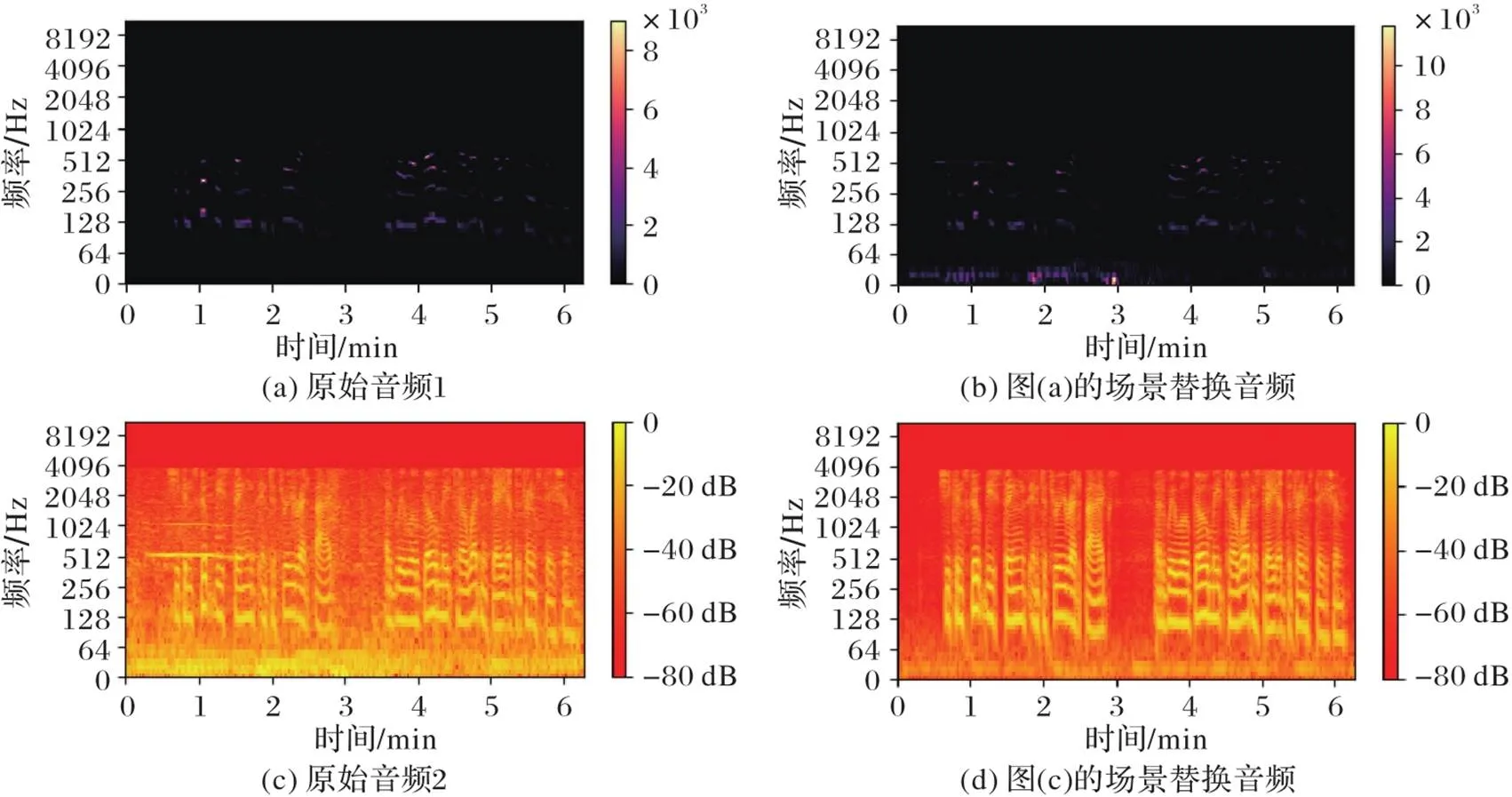
圖1 正負樣本的語譜圖
2 區分場景聲替換音頻的算法
2.1 提取聲學特征
在ASVspoof 2015數據庫的實驗結果表明,CQCC在音頻取證領域具有實用性,它的性能比之前的最佳結果高出72%。在此之后,CQCC在說話人驗證等方面也表現出了很強的競爭力[13],它作為音頻的一類特征值在很多的場景下都發揮了作用。



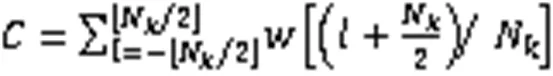
得到CQT之后的處理相對簡單,主要是利用一些樸素的數據處理方式將音頻的特征凸顯出來。最后經過DCT得到CQCC最終表達式為:

提取CQCC特征值的流程如圖2所示。
圖2 CQCC特征提取流程
Fig.2 Flowchart of CQCC feature extraction
將音頻進行快速傅里葉變換(Fast Fourier Transform,FFT)之后,如圖3所示:圖(a)展示的是原始音頻的頻率分布,音頻的信息基本上分布在中低頻的部分;經過場景替換之后,在中低頻有明顯的差異,如圖(b)。根據CQCC特征的設計,在低頻段會使用帶寬窄的濾波器進行計算,所以經過CQT之后中低音頻信息可以將這部分的信息差異放大,從而將正常樣本與場景替換的造假樣本(負樣本)區分開來。
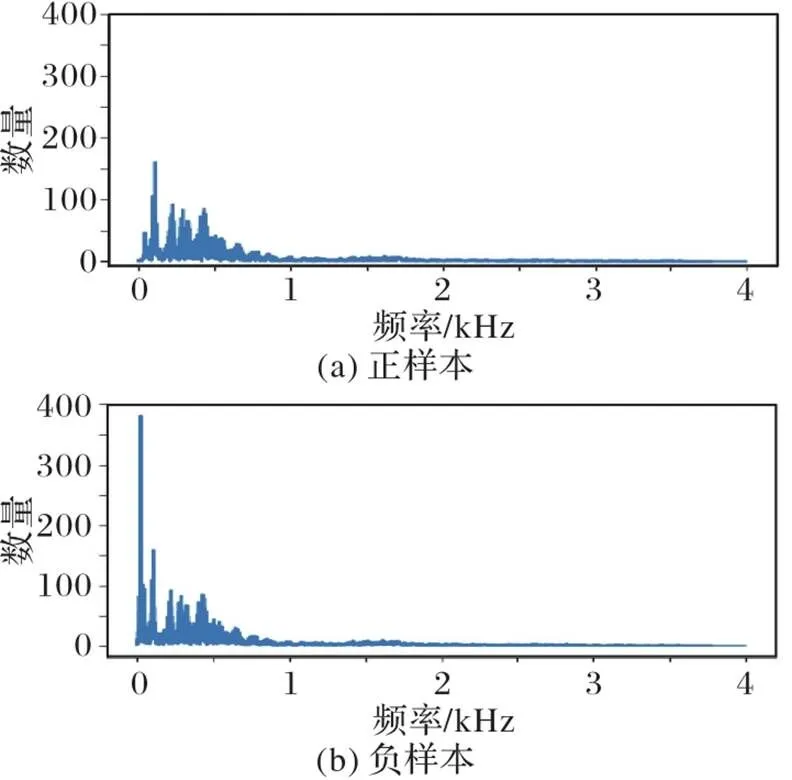
圖3 正負樣本頻率分布
2.2 音頻區分算法
本文采用的網絡模型是在ASVspoof 2019上性能表現優良的殘差網絡模型[14],結構如圖4所示。該網絡結構中采用了多個殘差塊(圖4中虛線框所示),每個殘差塊都由兩個卷積以及卷積對應的歸一化和激活函數構成,最后使用交叉熵作為損失函數。雖然在視覺層面上網絡的層數非常深,但是歸功于跳躍連接的使用,不會讓梯度隨著網絡深度的遞增而消失[15]。同時根據原始殘差網絡的設計理念,特征圖隨著網絡深度的增加,會放大所需的“信息”部分。由于送入到網絡結構中的是CQCC特征值,是類似于圖片的一組單通道的數值矩陣,所以在應用殘差網絡時可以讓決策邊界快速收斂,即使收斂到極限時也不至于退化嚴重。
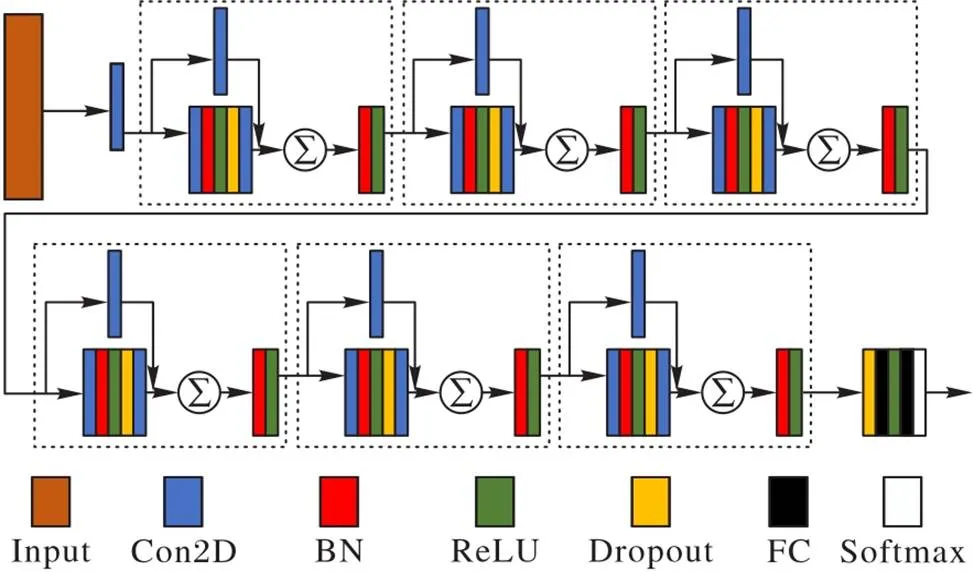
圖4 ResNet的結構示意圖
在訓練過程中,特征值經過每一個殘差塊之后,都會將特征的大小進行一定程度上的壓縮。特征進行第一次卷積之后,都會把每一組的數據進行橫向的歸一化,保證數據在均值為0、方差為1的范圍內。接下來把歸一化之后的矩陣經過激活函數中的線性整流函數(Rectified Linear Unit,ReLU)。在第二次卷積之后會加上第一次卷積之后的第二路卷積后的值,這么做是為了防止發生梯度消失,疊加之后繼續歸一化和激活。以上是每一個殘差塊的工作,網絡中具有多個殘差塊,并且前后直接緊密相連。特征值經過若干個殘差塊的提取之后,需要將其展平到一維并連接到緊密層,即全連接層。為了防止過擬合現象發生,會在兩個全連接層之間加上一個Dropout層,其中Dropout層也會在之前的殘差塊中有應用,隨機斷開一定數量的連接來防止過多連接所導致的過擬合。最后將一維的特征數據經過LogSoftmax層,產生是否為場景替換音頻的概率。以上就是一個完整的訓練過程。
為了探究不同的模型對實驗結果的影響,實驗中使用在分類模型中性能優良的VGG網絡[16]以及機器學習中的支持向量機(Support Vector Machine, SVM)模型來對比在不同特征值選擇條件下的結果。
3 實驗與結果分析
3.1 實驗設置
實驗中使用的音頻來自多個數據庫,其中正樣本來自TIMIT和Voicebank數據庫,噪聲樣本來自Demand數據庫,均是開源且具有一定代表性的語料數據庫。來自Demand數據庫的噪聲樣本包含多種不同場景下的聲音,如廚房、車站、咖啡廳等。
實驗中將所有音頻樣本均統一重采樣到8 kHz,重采樣后的音頻表現都大致相似而且可以減少運算量。將每段音頻統一剪切至時長2 000 ms,即16 000個采樣點。正樣本與負樣本的數量一致,但正、負樣本出現的音頻中的純凈音頻都不同。負樣本的制作是將場景音頻疊加至純凈音頻上生成帶有場景聲的音頻,在控制好兩者疊加音頻音量的條件下,負樣本可以達到以假亂真的效果。

ResNet中一共有6個殘差塊,每個殘差塊前后直接緊密相連,在特征輸入到殘差塊之前會經過一次3×3卷積。在送入到網絡模型中的數據中,每25個音頻為1個Batch,初始化學習率為0.000 1。
根據筆者調研了解,目前還少有人進行場景聲替換音頻的檢測,為了客觀地分析實驗結果,實驗中選用了兩個指標來衡量檢測的結果:檢測準確率(Accuracy)用來展示檢測算法的效率;錯誤接受率(False Acceptance Rate, FAR)則用來展示檢測過程中錯漏過負類的占比。FAR的計算公式如下所示:

3.2 結果與分析
從兩個不同實驗場景呈現實驗結果:第一個實驗中的負樣本是將場景聲音頻直接疊加在純凈的原始音頻上;而第二個實驗是在真實物理世界場景中的,大部分原始音頻本身就含有場景聲音頻,而負樣本則需要在原始音頻處理之后再進行場景聲音頻的疊加。
3.2.1 數據庫場景下的實驗
人耳感受到的聲音高低與其頻率不呈線性關系,人耳對低頻信號比高頻信號更加敏感[13],因此根據人耳的特性模擬出的MFCC特征會適用于該場景。與CQCC一致的是映射到頻域階段的濾波器都是低頻窄、高頻寬的設置,由于使用濾波器的不同,兩者中低頻的信息量也不同。
圖5是在VGG以及ResNet下,用CQCC作為特征值輸入時訓練過程中的損失的表現。可以清晰地看到,在訓練過程中損失保持下降趨勢,足以說明使用殘差的結構會使得整個網絡保持收斂狀態,讓決策邊界不斷收縮,從而使往后訓練時更新的步伐會很小,并且整個網絡也沒有表現出退化的趨勢。在收斂性上VGG以及ResNet都表現出持續收斂,ResNet某個時刻的損失值會突然增大,但是在后期會慢慢修復這個突然的變化。

圖5 兩種網絡的收斂性分析
表1是在不同的判別模型下CQCC和MFCC特征在不同數據庫訓練的準確率與FAR。SVM的準確率在大部分的數據庫上都很高,但是在跨數據庫間的表現上會差一些。VGG網絡依舊存在數據庫之間的準確率偏低、同時FAR也比較高的問題。ResNet的表現比SVM和VGG好很多,準確率較高而且很均衡,不會出現像SVM和VGG模型中某些樣本無法判別的情況。在兩個特征值中,CQCC作為特征表現得比MFCC好一些。從上述結果可以看出,用CQCC作為特征值,結合ResNet來區分樣本是否經過場景聲的替換是有效的。

表1 不同條件下不同模型的準確率和錯誤接受率
3.2.2 現實場景下的實驗
現實場景錄制的音頻不如數據庫音頻純凈,為了增加數據真實性的驗證,用不同的手機設備進行錄制,并且每段錄音都含有原始的場景聲音的音頻,場景有辦公室、操場、醫院、食堂等,使用錄制設備有Letv、OPPO和iPhone手機。在實驗中將錄制好的原始音頻作為正樣本。為了更加貼近現實中替換場景聲的操作,將原始音頻利用去噪軟件進行降噪后疊加上錄制好的場景聲音頻,實現場景替換。
表2是用三個不同設備錄制的音頻的檢測準確率結果,使用的模型是由TIMIT和Voicebank兩個數據庫進行訓練的ResNet。由表2可以看出,CQCC作為特征值的檢測效果會比MFCC好很多(表2中加粗數據)。由于錄制設備的不同,原始音頻可能含有的場景聲有設備的本底噪聲以及原始的場景聲,或者有些音頻在經過設備的錄制之后會經過設備自帶的壓縮過程,所以檢測的結果會略有些差異,但是整體檢測率依舊不夠高。
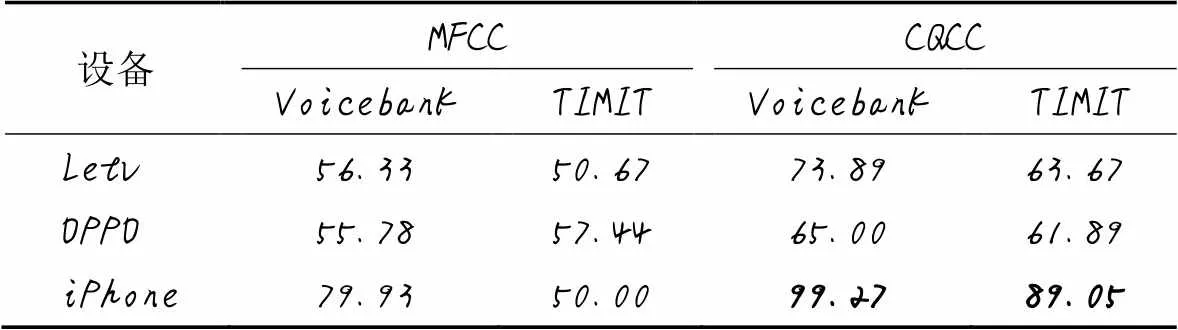
表2 不同設備錄制音頻的準確率 單位: %
4 結語
本文提出了對音頻場景聲替換的造假樣本的檢測方法,目前相關方面的工作還不多。實驗的基本思想是通過對正負樣本的頻譜分析,提取音頻樣本的CQCC特征值,利用ResNet對特征值進行判斷分類。雖然在公認的數據庫上的檢測準確率可以達到一個很高的水準,但依舊存在一些問題,例如在檢測真實場景下不同設備錄制的音頻時,模型對這些樣本有不同的效果,針對有些設備錄制并造假的音頻檢測率非常低。所以我們今后的工作是提出更加魯棒的跨設備的檢測方法,讓現實場景下場景替換的造假樣本能以一個高準確率被檢測出來。
[1] WESTERLUND M. The emergence of deepfake technology: a review[J]. Technology Innovation Management Review, 2019, 9(11): 39-52.
[2] WU H J, WANG Y, HUANG J W. Identification of electronic disguised voices[J]. IEEE Transactions on Information Forensics and Security, 2014, 9(3): 489-500.
[3] LIN X D, LIU J X, KANG X G. Audio recapture detection with convolutional neural networks[J]. IEEE Transactions on Multimedia, 2016, 18(8): 1480-1487.
[4] AL-ALI A K H, DEAN D, SENADJI B, et al. Enhanced forensic speaker verification using a combination of DWT and MFCC feature warping in the presence of noise and reverberation conditions[J]. IEEE Access, 2017, 5: 15400-15413.
[5] LIDY T, SCHINDLER A. CQT-based convolutional neural networks for audio scene classification[C/OL]// Proceedings of the 2016 Workshop on Detection and Classification of Acoustic Scenes and Events. [2021-04-21].https://dcase.community/documents/workshop2016/proceedings/Lidy-DCASE2016workshop.pdf.
[6] WU Z F, SHEN C H, VAN DEN HENGEL A. Wider or deeper: revisiting the ResNet model for visual recognition[J]. Pattern Recognition, 2019, 90: 119-133.
[7] HE K M, ZHANG X Y, REN S Q, et al. Identity mappings in deep residual networks[C]// Proceedings of the 2016 European Conference on Computer Vision, LNIP 9908. Cham: Springer, 2016: 630-645.
[8] REN Y Z, LIU D K, XIONG Q C, et al. Spec-ResNet: a general audio steganalysis scheme based on deep residual network of spectrogram[EB/OL]. (2019-02-26)[2021-04-21].https://arxiv.org/pdf/1901.06838.pdf.
[9] LIU M L, WANG W C, LI Y X. The system for acoustic scene classification using ResNet[R/OL]. [2021-04-21].https://dcase.community/documents/challenge2019/technical_reports/DCASE2019_SCUT_19.pdf.
[10] GAROFOLO J S, LAMEL L F, FISHER W M, et al. DARPA TIMIT: acoustic-phonetic continous speech corpus CD-ROM: NIST speech disc 1-1.1: NISTIR 4930[R]. Gaithersburg, MD: National Institute of Standards and Technology, 1993.
[11] VEAUX C, YAMAGISHI J, KING S. The voice bank corpus: Design, collection and data analysis of a large regional accent speech database[C]// Proceedings of the 2013 International Conference Oriental COCOSDA Held Jointly with 2013 Conference on Asian Spoken Language Research and Evaluation. Piscataway: IEEE, 2013: 1-4.
[12] THIEMANN J, ITO N, VINCENT E. The Diverse Environments Multi-channel Acoustic Noise Database (DEMAND): a database of multichannel environmental noise recordings[J]. Proceedings of Meetings on Acoustics, 2013,19(1): No.035081.
[13] TODISCO M, DELGADO H, EVANS N. Constant Q cepstral coefficients: a spoofing countermeasure for automatic speaker verification[J]. Computer Speech and Language, 2017, 45: 516-535.
[14] ALZANTOT M, WANG Z Q, SRIVASTAVA M B. Deep residual neural networks for audio spoofing detection[C]// Proceedings of the Interspeech 2019. [S.l.]: International Speech Communication Association, 2019: 1078-1082.
[15] 楊磊,趙紅東. 基于輕量級深度神經網絡的環境聲音識別[J]. 計算機應用, 2020, 40(11):3172-3177.(YANG L, ZHAO H D. Environment sound recognition based on lightweight deep neural network[J]. Journal of Computer Applications, 2020, 40(11): 3172-3177.)
[16] MATEEN M, WEN J H, NASRULLAH, et al. Fundus image classification using VGG-19 architecture with PCA and SVD[J]. Symmetry, 2019, 11(1): No.1.
Detection algorithm of audio scene sound replacement falsification based on ResNet
DONG Mingyu1, YAN Diqun1,2*
(1,,315211,;2,324000,)
A ResNet-based faked sample detection algorithm was proposed for the detection of faked samples in audio scenes with low faking cost and undetectable sound replacement. The Constant Q Cepstral Coefficient (CQCC) features of the audio were extracted firstly, then the input features were learnt by the Residual Network (ResNet) structure, by combining the multi-layer residual blocks of the network and feature normalization, the classification results were output finally. On TIMIT and Voicebank databases, the highest detection accuracy of the proposed algorithm can reach 100%, and the lowest false acceptance rate of the algorithm can reach 1.37%. In realistic scenes, the highest detection accuracy of this algorithm is up to 99.27% when detecting the audios recorded by three different recording devices with the background noise of the device and the audio of the original scene. Experimental results show that it is effective to use the CQCC features of audio to detect the scene replacement trace of audio.
audio falsification; audio scene sound replacement; Residual Network (ResNet); Constant Q Cepstral Coefficient (CQCC)
This work is partially supported by National Natural Science Foundation of China (U1736215, 61901237), Zhejiang Provincial Natural Science Foundation (LY20F020010, LY17F020010), Ningbo Natural Science Foundation (202003N4089).
DONG Mingyu, born in 1997, M. S. candidate. His research interests include machine learning, multimedia forensics, adversarial example.
YAN Diqun, born in 1979, Ph. D., associate professor. His research interests include machine learning, information security, information hiding.
TP391.4
A
1001-9081(2022)06-1724-05
10.11772/j.issn.1001-9081.2021061432
2021?08?10;
2021?11?10;
2021?11?17。
國家自然科學基金資助項目(U1736215, 61901237);浙江省自然科學基金資助項目(LY20F020010, LY17F020010);寧波市自然科學基金資助項目(202003N4089)。
董明宇(1997—),男,浙江寧海人,碩士研究生,CCF會員,主要研究方向:機器學習、多媒體取證、對抗樣本;嚴迪群(1979—),男,浙江余姚人,副教授,博士,CCF會員,主要研究方向:機器學習、信息安全、信息隱藏。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
財經(2017年2期)2017-03-10 14:35:35
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
財經(2016年15期)2016-06-03 07:38:02
海峽科技與產業(2016年3期)2016-05-17 04:32:12
