關于人工智能方法用于鉆井機械鉆速預測的探討
2022-07-06 06:30:06石祥超王宇鳴劉越豪陳雁
石油鉆采工藝 2022年1期
石祥超 王宇鳴 劉越豪 陳雁
1. 油氣藏地質及開發工程國家重點實驗室·西南石油大學;2. 西南石油大學計算機科學學院
油氣公司在科研、生產、管理、經營活動中積累了海量的結構化及非結構化數據,其數據總量仍在不斷持續攀升,充分挖掘這些數據的價值是非常重要和十分迫切的,尤其是在低油價時期。據統計,非常規油氣鉆井作業產生的數據非常龐大,每英尺鉆井產生的數據量就能達到1MB,每打一口井產生的數據量能達到1~15 TB,如何挖掘和利用鉆完井大數據蘊含的價值,為鉆完井提供優質方案,將是未來很長一段時間面臨的科學技術問題。
隨著鉆井數據信息采集技術的迅速發展,鉆井過程中產生的數據體量龐大,機器學習能夠精準地對海量鉆井數據進行分析,從中發現一定的規律,為高效率鉆井提供結構化的信息和指導,目前許多新的機器學習方法都被應用于鉆頭優選、鉆頭性能評價、機械鉆速的預測與優化、鉆井過程中的事故預測與解決方法、鉆井液的優選、綜合系統的構建等方面。準確預測并優化機械鉆速是縮短鉆井周期、節省鉆井成本的良好方法,將人工智能方法與鉆井結合是目前的研究趨勢[1]。筆者總結分析了人工智能方法預測機械鉆速的研究進展,指出了目前研究存在的一些問題,主要針對相關性分析、數據選取及對訓練和預測結果的影響開展了研究。
1 智能方法預測鉆速技術發展
鉆井機械鉆速(ROP)預測是進行鉆井優化、鉆井投資測算等工作的重要技術內容,目前建立的傳統機械鉆速方程有幾十種之多[2],但影響機械鉆速的因素繁多,關系復雜,目前為止尚未建立令人信服、普遍適用的數學模型,而隨著帶有數據驅動特性的人工智能方法在工程領域的應用越來越廣泛,使用人工智能算法預測機械鉆速受到研究學者的廣泛關注。Moran等[3]指出基于推測或假設出的機械鉆速在未知區域估計鉆井時間的傳統方法可以被人工神經網絡所取代;Soares等[4]揭示了傳統機械鉆速模型的局限性,包括Bourgoyne的機械鉆速模型[5];Jahanbakhshi等[6]將影響機械鉆速的不同鉆井參數放入人工神經網絡進行訓練,得出預測結果最高的參數組合;Hegde等[7]使用了多種人工智能算法對機械鉆速進行預測,表示人工智能算法的靈活性可以適用于常規井與非常規井的機械鉆速預測。近年來眾多專家學者基于人工智能算法預測機械鉆速的研究見表1。
人工智能方法提供了預測機械鉆速的新思路,但影響機械鉆速的因素繁多,有些因素(如巖石強度、鉆頭磨損)不是很好獲得,這些因素是否要作為輸入參數放入模型,在已有文章中選取的輸入參數是否忽略了某些重要變量也不得而知。為優化機械鉆速,提高鉆井效率,Graham等[22]分析了鉆井效率與機械鉆速的關系,表示機械鉆速不等同于鉆井效率,而應被視為影響鉆井效率的幾個因素之一;Hedge等[23]從單一的機械鉆速優化模型,轉為多目標的模型,將機械鉆速、機械比能、扭矩3種因素交互評估,從而獲得最佳的鉆井方案。
以上調研文獻中,大多數訓練模型所用數據是基于單井或井段數據,人工智能模型很好地預測了機械鉆速,且對數據采取K折交叉驗證[15,19, 21]找到模型泛化能力最優的超參數組合,或是用其他方法直接優化超參數[8-9,14, 17]以提高預測精度。但若僅使用單井或少量數據訓練模型,會使模型輸入數據不具備代表性,因此模型無法向其他井或者整個區塊進行推廣,在預測其他井鉆速時還需重新訓練模型,不符合工程需要。
2 人工智能方法進行鉆速預測的探討
2.1 相關性分析
由表1可以看到,使用人工智能方法預測機械鉆速選擇的輸入參數各不相同。研究表明[12,20]可以應用相關性分析找到對機械鉆速影響最大的幾個參數,并使用這些參數進行機械鉆速的預測與優化。但在實際工程中所獲得的鉆井日志,可能并不會含有某些關鍵因素(如鉆頭磨損),在對這些鉆井參數進行相關性分析過程中,可能會由于數據問題將一些相關性低的重要因素忽略掉。李謙等[24]分析了基于人工智能方法的鉆速預測模型數據有效性下限,表明在引入足夠的參數后,無論引入參數的相關性高低,都可取得較高的預測精度。筆者將原始鉆井數據進行了相關性分析,發現有些相關性分析可能得出錯誤的結論。圖1將某井的輸入參數與機械鉆速進行相關性分析,發現鉆壓、轉速與鉆速不是想象中的正相關。這是因為隨著鉆井深度的增加,井下的情況越來越復雜,雖然增加了鉆壓,但機械鉆速仍然可能降低。圖2選取了圖1中某井二開井段數據做了相關性分析,可以看到全井的相關性分析與某井段的相關性分析結果差距較大。故使用相關性分析去尋找輸入參數或是刪除某些分析出來的相關性低的因素尚需討論。
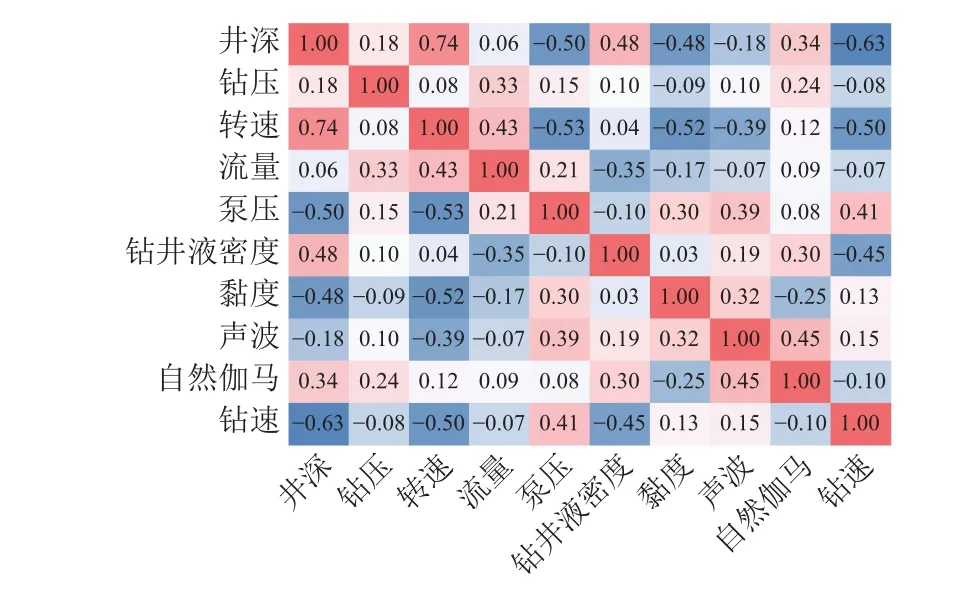
圖2 某井二開井段機械鉆速影響因素相關性分析Fig. 2 Correlation analysis of factors affecting penetration rate in the second section of a well
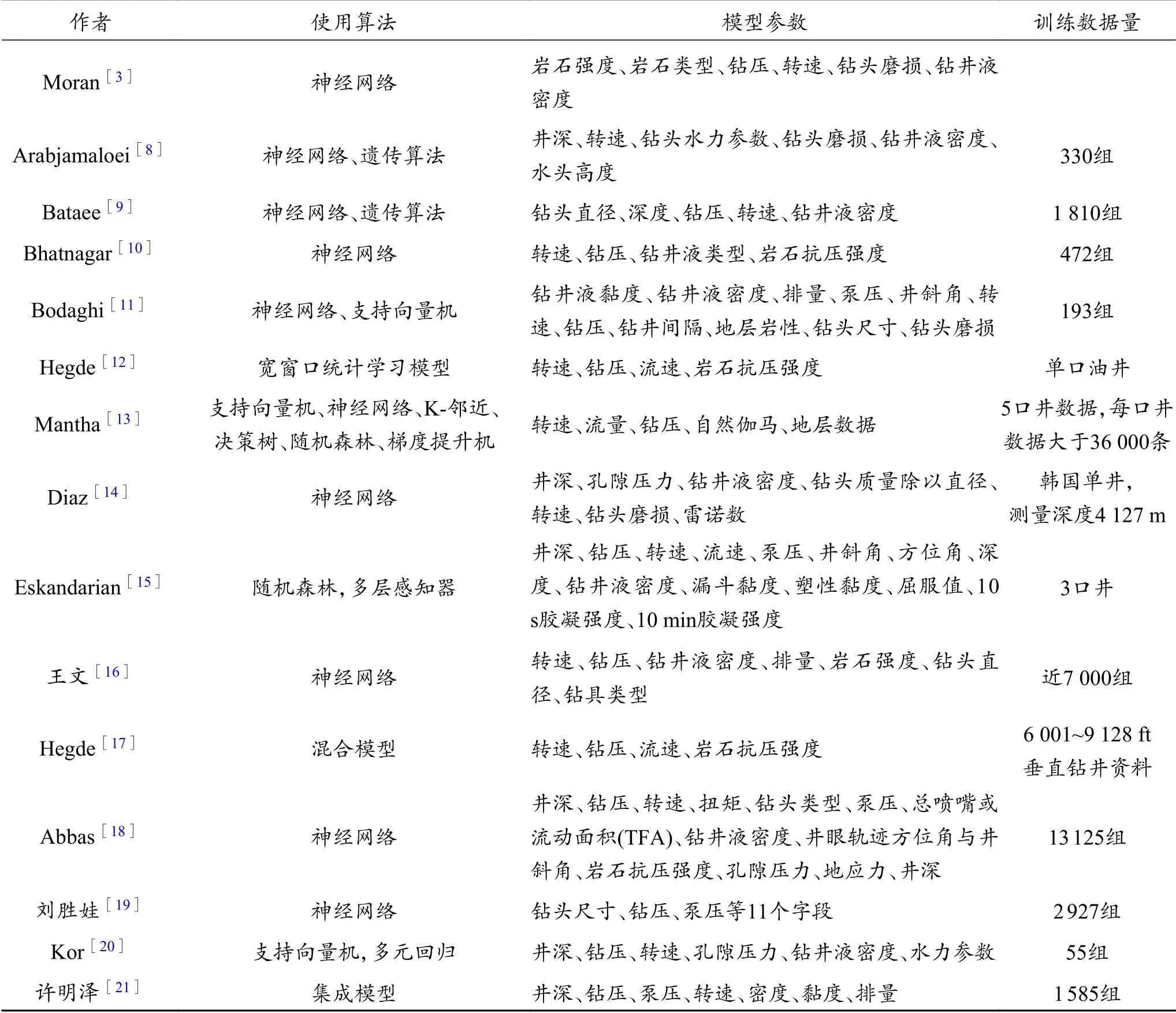
表1 近年人工智能預測機械鉆速方法匯總Table 1 Summary of methos predicting penetration rate with artificial intelligence in recent years
2.2 訓練數據選取
鉆井會產生大量井數據,但在使用人工智能方法進行鉆速預測與鉆井優化時,許多調研的文獻中僅僅只用一口井或是某一段鉆井數據進行嘗試。訓練數據量的多少會影響人工智能方法預測的精度,從而影響對人工智能模型的選擇。Korhan等[20]研究表明在訓練數據有限的情況下,支持向量機可以更準確地預測機械鉆速;Yavari等[25]研究表明在數據量較大時,自適應神經模糊推理系統更適合預測機械鉆速。人工智能模型預測的準確度基于輸入數據,將超出輸入數據范圍外的數據輸入模型訓練將會得到不確定的結果,使用單井數據或是某井段數據進行模型訓練和訓練是否具有良好的泛化能力值得討論。
為了使預測模型具有泛化能力,Hedge等[26]將數據集按巖性拆分,基于不同巖性分別建立人工智能模型。該模型可以更加準確地預測對應巖性地層的機械鉆速。筆者將區塊數據與單井數據分別使用人工智能模型進行訓練,擴大了輸入數據的范圍,使得模型在該地層更具泛用性。
筆者收集了四川盆地某開發區塊的鉆井數據,使用隨機森林(RF)[27]、支持向量機(SVR)[28]、人工神經網絡(ANN)[29]以及梯度提升樹(GBDT)[30]等4種算法,分別對該開發區塊的單井與區塊的機械鉆速進行預測,并且在已有鉆井參數(鉆壓、轉速、泵壓、鉆井液密度、黏度、排量)的基礎上,引入地層參數(井深、巖性、聲波時差、自然伽馬)和鉆頭參數(鉆頭型號、開次)作為輸入參數,對其中非結構化參數(鉆頭型號、巖性)進行編碼,并與其他參數一樣進行歸一化處理。在下文所有機械鉆速預測模型中,數據集將按照訓練集80%、驗證集20%的方式送入模型訓練,并且采用可決系數R2作為模型精度的評價指標[19]。
2.2.1 單井數據訓練和預測結果
4種人工智能算法對某單井數據進行機械鉆速預測結果如圖3所示,可以看出,隨機森林與梯度提升樹可決系數可以達到0.92,支持向量機和人工神經網絡的可決系數分別為0.88,0.90。
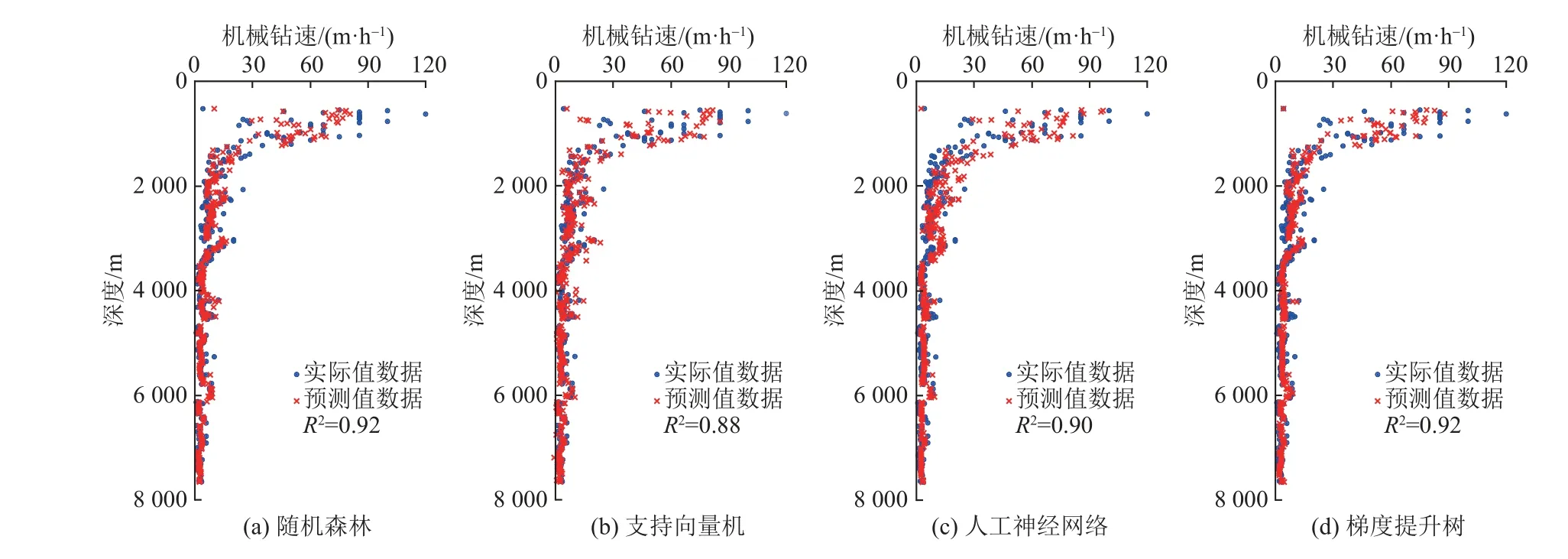
圖3 4種人工智能方法對某單井數據驗證集的預測結果Fig. 3 Prediction results of the four artificial intelligence methods on single-well data validation set
2.2.2 區塊多井數據訓練和預測結果
使用4種人工智能算法對某區塊進行機械鉆速預測,區塊數據包括在此區塊的5口井,數據量為15317組。機械鉆速預測結果如圖4所示,可以看出,隨機森林可決系數可以達到0.88,支持向量機、人工神經網絡和梯度提升樹的可決系數分別為0.86、0.74、0.85。結果表明,人工智能方法可以對單井或是區塊的機械鉆速進行良好的預測,且隨機森林方法對于機械鉆速的預測更為優秀。
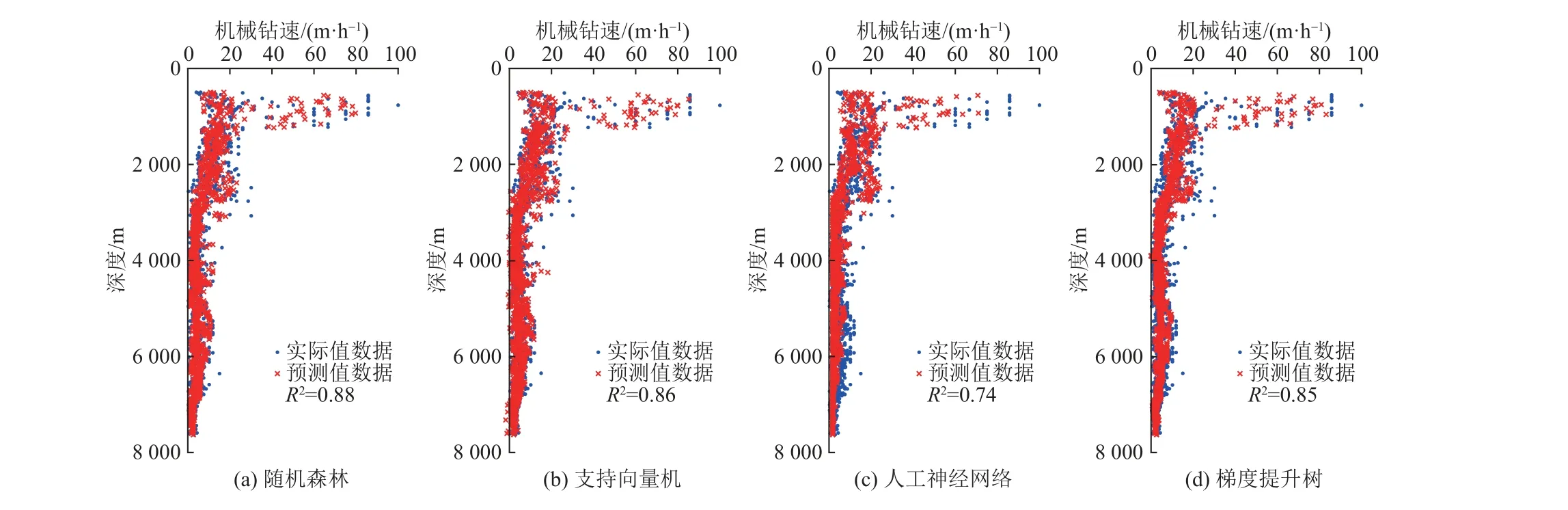
圖4 4種人工智能方法對區塊數據驗證集的預測結果Fig. 4 Prediction results of the four artificial intelligence methods on the block data validation set
2.2.3 單井模型與區塊模型泛化能力對比
將訓練好的單井與區塊的隨機森林模型分別保存,將新井數據輸入后,對比二者模型的泛化能力。圖5為使用單井數據訓練出的隨機森林模型預測該區塊其他單井的結果,可決系數分別為0.16、0.13、0.13;圖6為使用區塊數據訓練出的隨機森林模型預測該區塊其他單井的結果,可決系數分別為0.91、0.76、0.91。結果顯示區塊數據訓練后的模型在此區塊對新井數據具有更好的泛化能力。
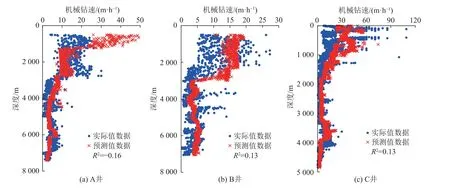
圖5 單井數據訓練的隨機森林模型對該區塊其他井的預測結果Fig. 5 Prediction results of other wells in this block by the random forest model trained with single-well data
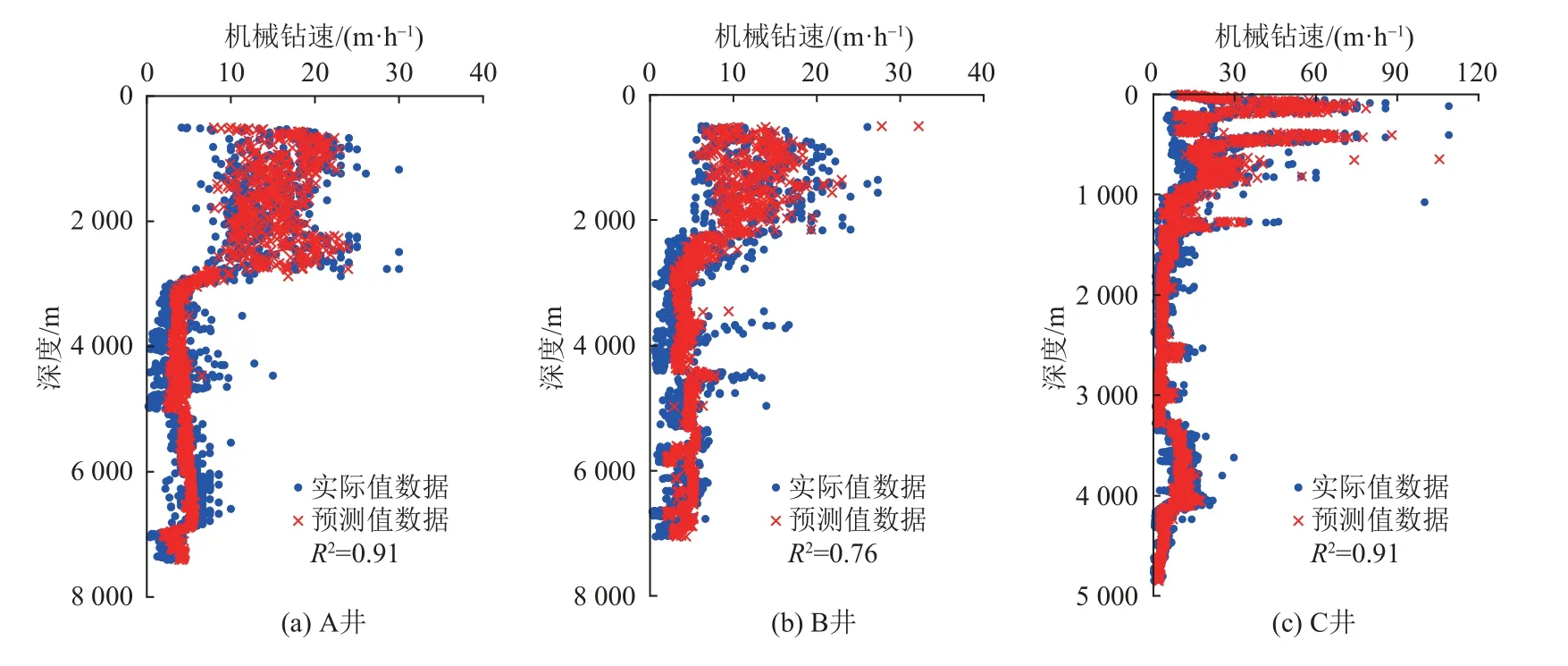
圖6 區塊數據訓練的隨機森林模型對該區塊其他井的預測結果Fig. 6 Prediction results of other wells in the block by the random forest model trained with block data
3 結論
(1)人工智能方法在各個學科應用廣泛,國內外使用人工智能方法預測機械鉆速已取得良好的成效,但由于訓練出的人工智能模型泛化能力低,該方法還未在工程上得到廣泛應用。
(2)采用相關性分析方法分別對整個單井數據與該井二開數據進行相關性分析,發現參數之間的相關性在一口井內都有較大差異。故使用相關性分析去尋找輸入參數或是刪除某些相關性低的輸入參數尚需討論。
(3)將新井數據作為驗證集,測試單井與區塊數據訓練后的隨機森林模型泛化能力,得到區塊數據訓練的模型在此區塊的泛用性遠好于單井數據所訓練的模型。這表明使用區塊數據訓練的模型具有較高的泛化能力,認為該模型能夠推廣至整個區塊,有利于指導該區塊的鉆井工程技術優化。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
西安航空學院學報(2022年2期)2022-07-04 07:45:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商界(2019年12期)2019-01-03 06:59:05
IT經理世界(2018年20期)2018-10-24 02:38:24
小康(2017年16期)2017-06-07 09:00:59
光學精密工程(2016年6期)2016-11-07 09:07:19
南風窗(2016年19期)2016-09-21 16:51:29
南風窗(2016年19期)2016-09-21 04:56:22
