基于深度學習OFDM信道補償技術硬件實現
2022-07-09 06:44:40劉仲謙薛乃陽
計算機測量與控制 2022年6期
劉仲謙,丁 丹,薛乃陽
(1.航天工程大學 研究生院,北京 101416; 2.航天工程大學 電子與光學工程系,北京 101416;3.中國人民解放軍63920部隊,北京 101416)
0 引言
近年來,無線通信系統的性能需求大大提高,給硬件實現帶來了巨大挑戰。傳統無線通信系統設計是基于模型驅動的理念,其中每個模塊的優化都是通過人們所掌握的知識信息即專家知識建立模型推導而來,這種優化模式在未來越來越復雜的信道環境條件下將變得越發難以實現。在這一背景下,這些年來快速發展的深度學習(DL,deep learning)技術為解決無線通信系統的算法難題帶來了新的思路,同時也為無線通信系統的硬件實現帶來了新的設計理念。深度學習技術可以直接從海量數據中學習到所需的隱藏規律,利用這些規律做出相應的預測或決策[1]。其數據驅動的特性正好可以解決傳統無線通信系統設計中因依賴專家知識推導優化算法而產生的問題。
目前有關深度學習的大量研究是基于計算機、工作站、服務器等大型平臺的運行仿真[2-3]。隨著深度學習技術研究的深入,部分高性能的神經網絡模型被應用在嵌入式硬件設備中,但在應用過程中理論上性能優異的網絡模型普遍存在著復雜度高以及計算量大的問題,以至于很多網絡模型應用到嵌入式設備上效果并不理想[4-5]。
針對嵌入式設備中網絡計算過程耗費大量時間和資源的問題目前已有的研究中通常集中于3個方面:1)采用諸如網絡裁剪[6-7]、低比特數據表示[8]、模型蒸餾[9]等方法來減少數據量或計算精度,此種方法雖然減少了計算量,但同時降低了網絡的性能,使計算的結果精度保持在實際系統可接受范圍內;2)在云和終端設備上分布式混合部署深度學習神經網絡[10],此方法可以有效解決復雜度高和計算量大的問題,但不適用一些延時要求較高或無網絡支持的場景;3)使用多種硬件平臺組成的異構計算平臺等來加速深度學習算法的計算過程[11-13],此種方法要求合理的計算資源分配,根據不同的網絡結構分配不同的硬件平臺完成實現,一旦達到較為理想的資源分配,此種方法可以有效解決神經網絡應用在嵌入式設備上效果不理想的問題。
基于以上分析可得目前已有的深度學習相關硬件實現大部分為系統復雜、體積大、成本高的系統,而基于深度學習無線通信傳輸系統的實現趨勢為小型化、系統簡單、成本低的集成終端設備。本文基于此趨勢研究了基于深度學習信道補償技術的OFDM信號傳輸系統的可集成小型化智能無線電設備實現,完成了OFDM信號收發處理、傳統信道估計與均衡算法、基于深度學習信道補償的板卡模級實現,推動深度學習在無線系統傳輸中的進一步實用化。本文選擇實現OFDM信號系統是由于其具有較高的頻譜利用率,能夠有效的抵抗多徑效應帶來的碼間干擾和子信道間干擾,且OFDM信號系統較容易實現,具有極大的實現價值。另外本文選用FPGA芯片與GPU集成的智能無線電設備作為實現平臺,可以有效分配不同硬件的計算資源給不同算法模塊以達到OFDM信號傳輸系統的快速有序實現。綜上所述本文以小型化智能無線電設備為平臺實現基于深度學習的OFDM信道補償技術,通過數據預處理減輕神經網絡工作量,完成神經網絡在嵌入式硬件設備中的高效實現,推動深度學習在無線系統傳輸中的進一步實用化。
1 系統整體方案及硬件選型
本文設計的OFDM信號傳輸系統旨在實現OFDM信號發送及接收前提下在接收端運用傳統信道估計均衡和深度學習信道補償技術結合的方法對接收信號完成進一步的信道補償從而降低收發兩端信號數據比對的誤碼率。其中硬件實現模塊包括OFDM信號的產生、傳輸、接收及后續的最小二乘(LS,least squares)估計算法、迫零(ZF,zero forcing)均衡算法、深度學習全連接神經網絡信道補償模塊。系統的設計如圖1所示。

圖1 系統設計框圖
本文將系統各個模塊設計在一個集成的智能無線電設備上,其中根據計算資源消耗水平的不同,系統前端OFDM信號收發過程及傳統信道估計均衡模塊所需資源分配較少,本文將其設計在FPGA Xilinx Artix-7 XC7A75T芯片上實現,該芯片在單個成本優化的FPGA中提供了高性能功耗比結構、收發器線速、DSP處理能力及AMS集成。深度學習信道補償技術模塊所需資源分配較多,本文將其設計在嵌入式平臺NVIDIA JETSON TX2多核處理器[14]上實現,該處理器體積小,功耗低,創建了實現高性能并行的計算環境。
2 系統設計
2.1 開發平臺簡介
根據上文描述硬件實現小型化、低功耗及資源合理分配的趨勢,本文根據FPGA芯片和GPU處理器的小體積、可集成性設計開發平臺。經過市場調研分析各種產品性能,最終發現AIR-T基本滿足本文硬件系統實現需求。硬件平臺使用unbuntu18.04 64位操作系統,ARMv8架構,內部構造包括AD9371收發器,FPGA Xilinx Artix-7 XC7A75T芯片和JETSON TX2多核處理器。FPGA Xilinx Artix-7系列芯片具有低功耗,高性能的特性,其中XC7A75T具有75 520個邏輯單元,3 780個存儲器,可提供具有100 MHz的傳輸帶寬,具有快速實時計算能力,符合本文OFDM信號傳輸系統模塊設計的實現需求。NVIDIA Jetson TX2 系列模組尺寸比信用卡還小,可為嵌入式 人工智能(AI,Artificial Intelligence) 計算設備提供出色的速度與能效。其配備NVIDIA Pascal架構,具有256個NVIDIA CUDA 核心,高達 8 GB 內存、59.7 GB/s 的顯存帶寬以及各種標準硬件接口,性能高達 Jetson Nano 的 2.5 倍,Jetson TX1的2倍,并且功耗低至 7.5 W。Jetson TX2 系列模組非常適用于實時處理需要解決帶寬和延遲問題的應用程序,在實時軟件無線電(SDR,software defined radio) 應用中,使用 NVIDIA Jetson TX2,比 Intel 7500U CPU 提高了 250%的帶寬處理,比 ARM Cortex-A57(4 核)提高了 1 350%的帶寬處理。除此之外,其GPU可用于高度并行處理。綜合來看,NVIDIA Jetson TX2在性能上最大程度匹配了本文設計的神經網絡信道補償技術模塊。
AIR-T是一款具有嵌入式高性能計算能力的小型化集成智能無線電設備,其通過集成FPGA、GPU、CPU三個數字處理器完成高性能計算、人工智能和深度學習。該系統可以用作深度學習算法的高度并行 SDR 處理和深度學習算法的推理引擎[15]。嵌入式 GPU 支持 SDR 應用程序實時處理大于 200 MHz 的帶寬。AIR-T開發套件支持Ubuntu16.4 系統,可以通過 SoapySDR 移植現有的 GNU Radio 應用程序,也可以使用自定義 GNU Radio 模塊部署神經網絡或高性能應用程序,同時,硬件支持使用 Python 或 C ++進行編程開發。從開發層面看大大提高了開發效率。總體來說,本文借助AIR-T智能無線電設備實現了一個高性能低功耗的基于深度學習信道補償技術的OFDM信號傳輸系統。
2.2 OFDM收發及預處理FPGA實現
2.2.1 OFDM信號收發模塊實現
本文實現的OFDM信號收發過程主要包括OFDM信號數據的產生模塊、傳輸模塊和接收模塊。其中信號數據的產生過程如圖2所示。

圖2 OFDM信號產生流圖
AIR-T支持RFNoC(RF network on chips)[16]對FPGA進行開發,可借助GNU Radio[17]創建流圖生成python腳本完成FPGA芯片上模塊的實現,也可使用python語言進行自定義模塊的開發,設備的初始化及模塊運行框架由RFNoC借助C++編譯完成,具體模塊參數設置可借助GNU Radio,也可以直接通過編寫代碼指令。
OFDM信號產生模塊的實現過程為首先從gunradio庫中導入需要調用模塊的指令庫如digital,blocks,gr,fft等。然后通過blocks庫函數的子函數random.randint產生16384個隨機0、1序列,需要注意的是此處生成的是Byte數據,經過stream函數指令將數據轉化為128位固定長度并添加長度標記,接著數據經過repack指令重新打包,每8bits一組轉換為2bits為后續QPSK映射做準備。QPSK的映射是借助digital庫函數指令對byte數據進行復數型數據映射,映射對應結果為0.707,-0.707,0.707j,-0.707j,將映射結果傳遞給虛擬接收器完成初始數據的生成。此前模塊之間的數據傳遞借助connect函數指令完成。RFNoC借助編譯配置可以直接將數據移入和移出FPGA,從而在應用程序中無縫使用基于主機和基于FPGA的處理,體現在開發方式上即為GNU Radio模塊之間的連線和代碼指令connect函數的使用,這也為下文實現信號傳輸模塊和傳統信道估計與均衡模塊提供了便利。
在已有初始數據條件下然后進行OFDM子載波分配,借用ofdm_carrier_allocator指令分配數據子載波及導頻子載波,導頻子載波間隔為1,數值為0.707,-0.707,0.707j,-0.707j的隨機排列,接著是調用fft函數對數據進行快速傅里葉逆變換(IFFT,inverse fast fourier transform)形成OFDM信號數據,此處FPGA中FFT的實現也是通過RFNoC編譯調用Xilinx CoreGen IP完成。最后使用ofdm_cyclic_prefixer函數指令給OFDM信號添加16位循環前綴(CP,cyclic prefix),將時域信號傳遞給虛擬接收器完成OFDM信號數據的生成。
信號的傳輸模塊是AWGN信道模塊的設計,此處主要借助blocks庫函數中有關數學運算的模塊和connect指令,首先依照信號功率求解公式借助庫函數中求和與除法模塊運算指令對時域數據進行處理。求解公式為:
(1)
xn為時域信號虛擬接收器中數據。S為信號功率模塊數據。
然后再借助指數、乘方及相加模塊指令完成噪聲方差模塊和信號疊加噪聲模塊的實現。噪聲方差公式為:
S2=S×10(-ebn0/10)
(2)
ebn0為可設置數據變量Eb/N0。S2為噪聲方差模塊數據。
信號疊加噪聲公式為:
(3)
Y為傳輸模塊虛擬接收器中數據,Sn為與已知產生信號長度相同的隨機序列。
OFDM信號的接收模塊為信號產生模塊的反向操作,接收模塊的實現過程是將OFDM信號傳輸模塊中的數據作為數據源,處理模塊包括去CP,FFT解調,其開發方式同樣采用直接編寫python代碼腳本的方式完成。
2.2.2 傳統信道估計與均衡算法模塊實現
本文借助FPGA芯片開發實現LS信道估計及ZF均衡模塊的方法與上文描述的模塊實現方法相同,需要注意的是connect指令連接的模塊位置。LS信道估計公式為:
(4)
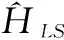
ZF均衡公式為:
(5)
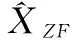
2.3 深度學習模塊GPU實現
2.3.1 網絡結構的選擇
根據上文描述傳統信道估計與均衡模塊有效減少了神經網絡層數和神經元個數,因此本文在設計神經網絡模塊時選擇層數較少的全連接神經網絡結構,有效控制了神經網絡模塊的計算次數。全連接神經網絡(FCNN,full connected neural network)[18]的網絡結構是從輸入層到隱含層,再到輸出層,層與層節點之間是全部連接的,但是隱含層之間的節點是無連接的。其中該神經網絡需要設計的參數包括神經網絡層數、神經元個數、激活函數、學習率、優化器、損失函數等。
本文實現的全連接神經網絡層數為2層,分別為輸入層與輸出層,中間無隱藏層,而神經元個數與每次運算處理數據的個數有關,本文一幀數據包括2個64位的OFDM符號,其實部加虛部的數據位數為256位,所以輸入層與輸出層的神經元個數都為256。
激活函數主要是為了給模型加入非線性因素,讓模型擁有更好的表達能力[19]。激活函數的選擇取決于數據的特性,本文設計的OFDM數據經過QPSK調制,具有雙極性,所以激活函數選擇雙切正切(Tanh)函數。
損失函數的本質是根據真實值和預測值的距離來改變模型的收斂方向。常用的損失函數有均方誤差(MSE, mean square error)和交叉熵[20]。優化器的選擇與模型優化方式有關,優化的實質是在損失函數和正則化函數確定的前提下,使權重更新達到最優。優化算法分為一階算法和二階算法,由于二階導計算成本高所以二階算法不常用,一階算法中最常用的是梯度下降法。學習率就是使梯度下降的步長,學習率也是每個優化器的重要參數。常用的優化器有小批量梯度下降優化算法(SGD)、引入一階動量的梯度下降算法(SGDM)、梯度平方根算法(RMSProp)、自適應動量估計算法(Adam)[21]。本文對于優化器和損失函數的選取則基于常規考慮采用RMSProp優化器和MSE損失函數,初始學習率設置為0.001且每訓練500輪數據將學習率設置為原來的1/5,在訓練過程中減小學習率不僅可以加快神經網絡的擬合速度,還可以提高網絡參數的擬合精度。
2.3.2 全連接神經網絡信道補償技術模塊實現
2.3.2.1 神經網絡參數設置及GPU配置
本文借助tensorflow[22]進行模塊開發和配置GPU實現模塊正常運行。首先是全連接神經網絡輸入層與輸出層的構建,網絡層參數的設置需要從tensorflow.contrib.layers庫函數中導入xavier_initializer,通過tf.Variable指令設置權重與偏置變量,變量的矩陣大小對應神經元個數即256。然后根據公式設置層中變量與輸入數據的運算關系:
y=x×w+b
(6)
x為輸入數據,w為權重,b為偏置,需要注意的是,在設置運算關系時還要借助tf.nn.tanh指令添加激活函數。
接下來需要根據MSE公式設置損失函數參數:
(7)
其中:yi表示實際值,ypre表示預測值。
然后通過tf.placeholder指令設置學習率參數并借助損失函數完成優化器參數設置。
網絡參數設置完成后需要將整個神經網絡的訓練和測試過程配置到GPU上。為了實現高效計算,本文借助tensorflow中config設置的allow_growth選項將網絡運算進程配置在所有GPU內存中以實現神經網絡模塊在JETSON TX2內 GPU上的配置運行。allow_growth選項可以根據運算需要自主分配GPU內存,運算開始時此選項會分配較小的內存,隨著網絡運算次數增加需要更多的GPU內存,此選項會擴展tensorflow進程所需的GPU內存區域。
2.3.2.2 神經網絡訓練與測試過程的GPU實現
完成GPU運行環境的配置后接下來是訓練數據與測試數據的選擇,這些FPGA模塊數據是借助PCle 2.0 X4通道傳輸給JETSON TX2平臺。具體數據的產生、網絡訓練及測試過程如圖3所示。

圖3 GPU實現神經網絡信道補償模塊流程圖
本文通過多次行2.2章節中的FPGA實現模塊得到大量神經網絡的訓練數據與測試數據存入JETSON TX2平臺中,訓練數據包括網絡訓練標簽和網絡輸入數據集,訓練標簽是指分配子載波模塊數據,其數據結構是信號實部與虛部的串聯,網絡輸入數據集是指ZF均衡模塊數據,數據結構與標簽數據相同。測試數據分為網絡輸入數據集和誤碼率比對數據,其產生流程、參數設置與訓練數據一致,同樣從對應FPGA模塊獲取,其中誤碼率比對數據對應訓練數據的訓練標簽。
本文在JETSON TX2平臺上存儲256×1 000 000組訓練數據,256×100 000組測試數據。訓練過程的實現為首先通過指令讀取訓練數據將網絡輸入集分配在網絡的輸入端,訓練標簽分配在網絡的輸出端,然后再借助tensorflow指令設置訓練輪數為5 000,學習率的設置如上文所訴,設置完成后通過指令運行神經網絡訓練擬合權重與偏置參數。以上為神經網絡信道補償模塊的訓練實現過程,即神經網絡在擬合參數時學習并補償了信道中未被LS信道估計和ZF均衡解決的未知誤差。當網絡訓練完成后通過tf.train.Saver()等相關指令將網絡參數保存在GPU中供測試使用,也可不保存參數直接測試網絡。測試過程的實現同樣先通過指令讀取測試數據,將測試網絡輸入集分配在網絡的輸入端,運行已訓練好的神經網絡信道補償模塊得到補償后的輸出端信號數據,將輸出端數據與誤碼率比對數據進行誤碼率分析顯示網絡信道補償模塊的實現效果。
3 實驗結果及分析
3.1 OFDM信號收發模塊的實現效果及分析
本文在FPGA芯片上實現OFDM信號收發模塊時使用的數據位數為16 384,信號帶寬為31.25 MHz。在其他模塊參數設置不變前提下改變AWGN傳輸信道模塊中Eb/N0參數,圖4~6分別為Eb/N0為5,15,25時OFDM接收信號的時域圖和頻域圖。

圖4 Eb/N0=5時OFDM接收信號時域圖與頻域圖

圖5 Eb/N0=15時OFDM接收信號時域圖與頻域圖

圖6 Eb/N0=25時OFDM接收信號時域圖與頻域圖
從圖6來看,OFDM接收信號模塊中輸出信號的時域頻域圖符合OFDM信號圖像特征,頻譜帶寬為31.25 M。其中不同Eb/N0參數值使得AWGN信道對接收信號時域部分的影響是不同的,在Eb/N0值較低時信號時域部分受噪聲影響較大,當Eb/N0值大于15時,噪聲影響明顯減輕,符合AWGN信道特性。綜上說明本文在FPGA芯片上有效實現了OFDM信號收發及傳輸模塊。
3.2 傳統信道估計均衡模塊實現結果及分析
針對在FPGA上實現傳統信道估計與均衡模塊的性能測試,本文以模塊輸出數據與OFDM信號產生模塊數據進行誤碼比對,得出如下誤碼率圖:
由圖7可知,當Eb/N0為10時,傳統信道估計與均衡模塊可實現10-2量級的誤碼率性能,當Eb/N0大于15時,此模塊可達到10-3量級的誤碼率數據均衡結果,而在實際系統中,此模塊性能無法達到OFDM信號精確傳輸的要求,需要對輸出信號進行后續信道補償。

圖7 不同Eb/N0下傳統信道估計與均衡模塊誤碼率圖
3.3 全連接神經網絡模塊實現結果及分析
本文通過記錄不同Eb/N0參數條件下網絡訓練過程中訓練輪數與損失函數值之間的關系來觀察網絡的計算復雜度和參數擬合速度,記錄結果如圖8~10所示。

圖8 Eb/N0=5時網絡訓練情況
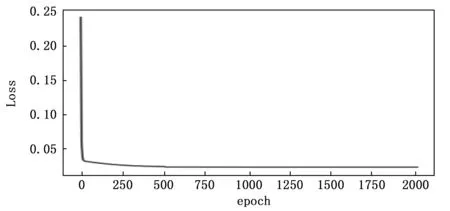
圖9 Eb/N0=15時網絡訓練情況

圖10 Eb/N0=15時網絡訓練情況
從圖8分析得知,在Eb/N0為5時,全連接神經網絡只需400~500輪的訓練就能達到參數擬合,在Eb/N0為15時,此網絡只需不到300輪就能接近擬合,當Eb/N0為25時,網絡只需不到50輪就能擬合參數,這說明此網絡復雜度低,計算量小,參數擬合速度快,在硬件實現方面具有結構優勢。
本文借助NVIDIA Jetson系列邊緣盒子配置性能查看工具jtop對神經網絡模塊訓練和測試過程中GPU的使用情況進行了記錄,記錄結果如下:
圖11神經網絡運行之前GPU資源使用情況,未運行網絡前GPU的使用效率在0~4%左右。

圖11 神經網絡未訓練時GPU使用效率圖
圖12為神經網絡訓練過程中GPU的使用效率情況,此過程中GPU的使用效率從6%提升到99%,說明網絡訓練過程占用了GPU全部計算資源。

圖12 神經網絡訓練過程中GPU使用效率圖
圖13為神經網絡測試過程中GPU使用效率情況,測試過程中GPU的使用效率在4%~76%之間,這說明測試過程并不需要占用GPU全部計算資源,同樣說明如果將訓練好的網絡保存在Jetson TX2平臺上,再次調用時不需要分配過多硬件資源。
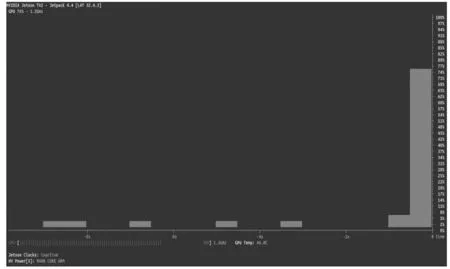
圖13 神經網絡測試過程中GPU使用效率圖
圖14是不同Eb/N0參數條件下傳統信道估計均衡模塊與全連接神經網絡信道補償模塊的性能對比圖。

圖14 不同Eb/N0情況下不同模塊誤碼率圖
從圖中分析得當Eb/N0為15時經過信道補償模塊后的數據誤碼率達到10-5量級,相比傳統信道估計均衡模塊具有明顯的性能優勢。從硬件實現方面分析,由上文可知,此網絡在GPU上實現時,具有網絡復雜度低,計算量小,參數擬合快的結構優勢。此模塊還可以通過提前訓練將擬合參數保存在Jetson TX2平臺上供實際系統直接使用,此過程不需要占用全部GPU計算資源。
4 結束語
隨著深度學習在嵌入式設備上實現的研究,簡單便攜的集成設備已成為基于深度學習無線通信傳輸系統的實現趨勢。結合傳統系統以模型驅動為設計理念和基于深度學習以數據驅動為設計基礎的OFDM信號傳輸系統實現具有一定的發展前景,根據不同系統模塊計算量大小借助集成設備分配不同硬件計算資源可以高效有序的實現高性能低功耗的基于深度學習信道補償技術的OFDM信號傳輸系統。
1)本系統借助python對AIR-T智能無線電設備進行頂層開發并在FPGA芯片上實現了OFDM信號產生模塊、信號傳輸模塊、信號接收模塊,下一步有望借助AD9371收發器實現芯片數據無線信道傳輸。
2)本系統基于傳統信道估計與均衡模塊所需少量運算資源的考慮在AIR-T的FPGA芯片上實現LS信道估計模塊、ZF均衡模塊,通過模塊數據的誤碼率性能分析,傳統信道估計與均衡模塊性能無法滿足實際傳輸系統需求,需要借助神經網絡信道補償模塊完成進一步的性能提升。
3)本系統基于深度學習模塊所需大量運算資源的考慮在AIR-T的GPU上實現了全連接神經網絡信道補償模塊,通過觀察分析得出此網絡復雜度低,計算量小,參數擬合速度快,這也說明LS信道估計與ZF均衡模塊有效降低了網絡訓練時的運算次數。從測試性能方面分析,經過全連接神經網絡信道補償模塊后的數據誤碼率比經過傳統信道估計均衡模塊后的誤碼率提高2個量級,具有明顯的性能優勢。另外測試過程并不需要占用GPU全部計算資源,這說明如果將訓練好的網絡保存在GPU所在平臺上,再次調用時并不需要分配過多硬件資源。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
鴨綠江(2021年35期)2021-04-19 12:24:18
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
電子制作(2018年11期)2018-08-04 03:25:42
