基于代碼上下文相似度分析的代碼問題修復推薦方法
2022-07-12 14:03:28吳毅堅沈立煒趙文耘
計算機應用與軟件 2022年6期
劉 霜 吳毅堅 沈立煒 趙文耘
1(復旦大學軟件學院 上海 201203) 2(復旦大學計算機科學技術學院 上海 201203) 3(上海市數據科學重點實驗室 上海 201203)
0 引 言
軟件系統的開發過程中,不可避免會出現代碼問題。在成千上萬甚至百萬行代碼的大型項目中找到問題并修復是一件困難的事情,因此,研究人員多年來致力于代碼問題自動修復技術的研究。代碼問題自動修復是在沒有人工干預的情況下自動修復軟件問題。即對于不滿足正確約束的程序,生成滿足程序約束的補丁[1-2]。這種技術的基本目的是自動生成正確的補丁,消除軟件程序中錯誤的補丁程序[3-4]。工業界也很關注代碼問題自動修復技術,如Simfix、CBCD、PRECFIX[5]已步入應用。
本文介紹的推薦方法適用于代碼靜態分析檢測到的問題(Issue)。靜態分析檢測到的問題一般有三類,包括編程錯誤、違反標準的編碼、安全弱點,后面簡稱為代碼問題。代碼靜態分析是一種通過在運行程序之前檢查源代碼進行調試的方法,通過針對一組(或多組)編碼規則分析一組代碼來完成,相關工具包括FindBugs、SonarQube、Helix QAC、Klocwork等。
靜態分析尤其擅長發現編碼問題,例如緩沖區溢出、內存泄漏和空指針。當程序開發人員碰到緩沖區溢出問題時,由于提示信息往往僅包括問題類型和位置,可能無法馬上知道該如何修改。而同時,該類問題有很多歷史修復,它們對應的問題類型、出問題的代碼及問題的代碼上下文可能是類似的,于是這些歷史修復可作為推薦方案。然而如何進行方案推薦并不容易,首先,每種問題類型有著太多被正確修復過的源代碼文件,難以判定這些源代碼文件的歷史修復中哪個或哪些是我們需要的;再者,每種問題類型有著太多的歷史修復,修復方式也是多種多樣,難以從如此多的歷史修復中有效率地推薦出一個有效的方案;最后,面對一個曾經被正確修復過的源代碼文件,難以找到它針對該問題的修復方式。
針對這些問題,本文提出一種基于代碼上下文相似度分析的代碼問題修復推薦方法。該方法首先收集歷史版本中代碼問題的修復案例,建立問題修復資源庫,然后根據問題類型、問題代碼及上下文、修復代碼及上下文對修復案例進行聚類,對每種不同類型的問題建立修復模板,最后通過對有同類問題的目標代碼及其上下文進行相似性分析,從而推薦具體的修復方式。基于上述方法,設計并實現一個基于代碼上下文相似度分析的代碼問題修復推薦工具。
1 本文方法
1.1 研究動機
眾所周知,修復軟件項目中的各種問題是一件非常困難且大量耗費時間精力的事情。據統計,修復軟件問題的時間占軟件維護時間成本的35.6%[6],軟件成本的絕大多數被認為是軟件維護成本。開發人員花在修復問題上的時間占全部開發時間一半左右[7]。
靜態代碼分析是在軟件開發的早期,即運行程序之前(例如,在編碼和單元測試之間)進行的。靜態代碼分析可以盡早發現問題。靜態代碼分析可以通過創建自動反饋循環來支持DevOps。開發人員將及早知道他們的代碼中是否存在問題,此時解決這些問題將更加容易。靜態分析相比于動態分析更容易發現編碼錯誤,因為某些編碼錯誤可能不會在單元測試期間發生。因此,靜態代碼分析(特別是在需要遵守行業標準的情況下)有不少優勢。
目前學術界進行問題修復的前提基于兩個假設,測試用例的充分性假設(測試用例是否完全反映程序的正確性)和被修復代碼的高質量假設[26],因此通過測試不總是等于完成修復,存在精確性不夠高的問題。很多問題修復技術只針對某種類型的問題設計了修復算法。很多修復技術耗時長,計算資源消耗多。
針對自動修復技術存在的各種問題,以及需要人工確認的局限性,在工程上,我們可以采用修復方式推薦的策略來幫助程序開發人員更快更好地理解并修復代碼問題。因此本文提出基于代碼上下文相似度分析的代碼問題修復推薦方法,這是一種問題修復的通用技術,它無須基于兩個假設,生成的推薦方法能夠盡量避免引入其他的問題,且通過問題類型、問題代碼及上下文和修復代碼及上下文聚類方法提高了推薦效果及問題修復效率。
1.2 方法概述
基于代碼上下文相似度分析的代碼問題修復推薦方法過程,主要包括以下兩個步驟。
(1) 問題修復案例(case)的歸類和存儲。圖1展示了該步驟,首先通過靜態分析工具(如FindBugs)獲取問題版本的問題類型、問題代碼及上下文,通過diff分析獲取修復版本的修復代碼及上下文,這些信息作為一條修復案例。然后根據問題類型、問題代碼及上下文、修復代碼及上下文對修復案例進行聚類。最后,將修復案例抽象化,形成修復模板。將修復案例及模板存儲起來,作為問題修復資源庫。
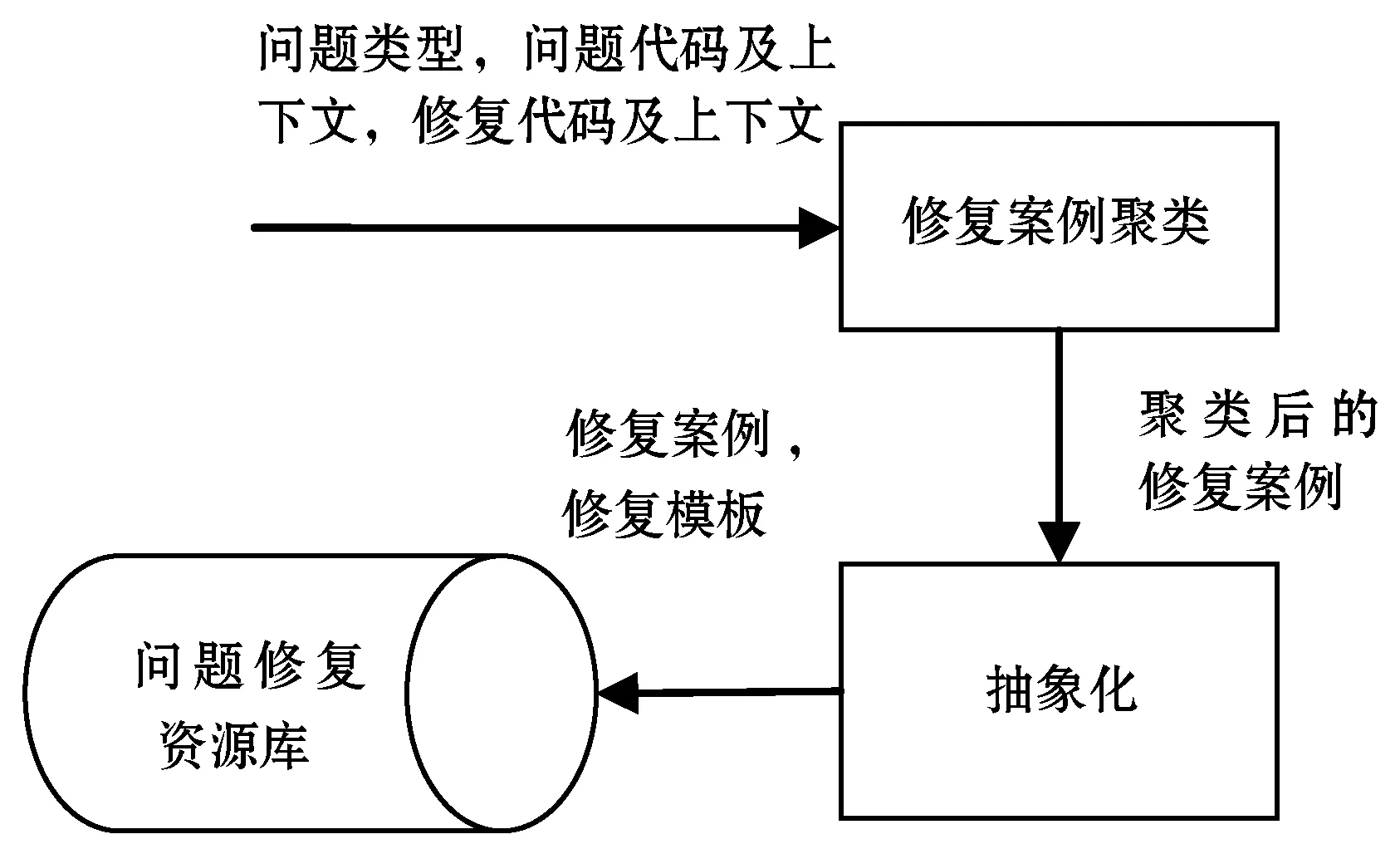
圖1 問題修復案例的歸類和存儲
(2) 代碼問題修復推薦。圖2展示了該步驟,以目標問題類型、問題代碼及其上下文代碼為輸入,結合問題修復資源庫中相應類型的問題代碼及其上下文的相似度匹配,進行問題修復案例推薦。本文提出基于代碼上下文相似度分析的代碼問題修復推薦方法,對輸入問題及其上下文代碼進行Token化后的文本相似度分析,找出相似度最高的幾種修復方式,為用戶進行問題修復推薦。
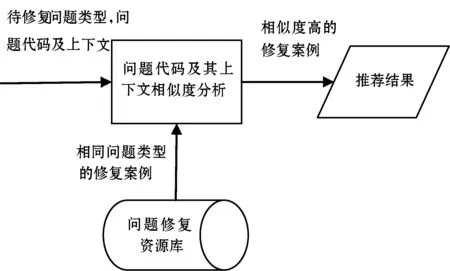
圖2 代碼問題修復推薦
1.3 代碼問題修復推薦方法的設計與實現
1.3.1問題修復案例的歸類和存儲
通過解析靜態分析工具(如FindBugs)的結果文件,得到問題版本的問題類型、問題代碼及上下文。通過diff分析得到解決版本的修復代碼及上下文。本文將每個歷史已解決問題的類型、問題代碼及上下文、修復代碼及上下文構造為一個修復案例,將它們保存在問題修復資源庫。
同種問題可能有多種不同的修復方式,但修復資源庫中針對同種問題的修復案例所采用的修復方式可能會存在較多重復,所以需要對同種問題類型中的修復案例根據修復方式進行聚類。具體對于某種問題的所有修復案例,其聚類方法是:首先,對于每個修復案例,將其問題代碼及上下文、修復代碼及上下文進行分詞,這里主要按空格和調用符進行劃分,接著采用詞袋模型將這些分詞構建為詞頻向量。最后對詞頻向量進行加權處理,以提升其中關鍵字的權重。最終每個修復案例被表示為一個加權的特征向量,其形式為:D=D(T1,W1;T2,W2;…;Tn,Wn),其中:T為分詞;W為權重;n為詞匯空間的大小,其由該問題所有修復案例的分詞種類數決定。最后使用凝聚層次聚類算法對這些特征向量進行聚類,聚為一類的案例本文認為有著相同的修復方式。
圖3展示了一個NP_NULL_ON_SOME_PATH問題類型的修復案例,其中:(a)展示的是問題修復前的代碼段,①②是問題代碼(FindBugs結果解析出的),其他的都是上下文代碼;(b)展示的是問題修復后的代碼段,①是修復代碼(問題代碼及上下文修復前后的diff),其他的都是上下文代碼。上下文代碼會用來計算代碼相似度,從而提高推薦效果。具有相似上下文的代碼問題會在推薦結果里排序更高。經過分詞,統計出每個詞語的出現次數,構建其詞頻向量為:
{if,4;_injectableValues,4;null,4;return,4;findInjectableValue,2;valueId,3;this,4;forProperty,3;beanInstance,2;throw,2;new,2;IllegalStateException,2;No,1;injectableValues,1;configured,1;can,1;not,1;inject,1;value,1;with,1;id,1;}


圖3 NP_NULL_ON_SOME_PATH修復案例- 修復前后代碼段
雖然詞袋模型沒有考慮詞在代碼中的順序,但其簡單高效,并且經過加權處理,在有限的修復案例中可以達到良好的效果。
使用上述修復案例聚類算法,發現每種代碼問題的修復方式一般分為一種或多種,例如NP_NULL_ON_SOME_PATH問題的修復方式一般有五種,且模式較為固定。
1) 對可能為空的變量進行null值判斷的操作加上else分支,可能出現異常的操作放在else分支中運行。
2) 先判斷變量是否為null值,如果為空直接拋異常。
3) 原問題代碼中沒有if-else語句的,在修復代碼中添加if-else,在if語句中對變量進行null值判斷,可能出現異常的語句在else分支中運行。
4) 先判斷變量是否為null值,如果為空直接進行return操作。
5) 在變量賦值的語句中,變賦值為null為賦值一個實例。
圖3(b)展示了NP_NULL_ON_SOME_PATH問題修復案例的修復后代碼段,該案例使用了第二種修復方式,即先判斷變量是否為null值,如果為空直接拋異常的方式進行修復。
修復案例聚類完成后,對其進行抽象化處理,形成修復模板。抽象處理過程為:將變量名按其出現的次序替換為MYM1、MYM2等;將基本數據類型分別初始化為其默認值;對于自定義的函數按其出現順序統一替換為f1、f2等;所有操作符、關鍵字保持不變;去掉注釋和多余的空行,統一縮進。本文認為每個修復案例抽象化后都是一個修復模板。一個修復模板包括問題類型、問題代碼及上下文(抽象化的)、修復代碼及上下文(抽象化的)。
1.3.2代碼問題修復推薦
本文提出的基于代碼上下文相似度分析的代碼問題修復推薦算法基于問題類型、問題代碼及其上下文的文本相似度(基于編輯距離),能夠為用戶推薦與其問題最為相似的修復方式。問題類型指根據代碼靜態分析結果得到代碼問題的類型。問題代碼指根據代碼靜態分析得到的具體問題代碼行。問題代碼上下文指根據代碼靜態分析得到的與具體問題行相關的上下文代碼,它是根據具體問題類型的具體特點得到的、與問題發生原因緊密聯系的代碼內容。以上所需可以通過代碼靜態分析的結果文件得到(例如通過分析FindBugs結果文件)。該算法將目標問題代碼及其上下文與資源庫中的相同問題類型的問題記錄的問題代碼及其上下文進行(基于有限自動機的Token化后的)文本相似度匹配,選擇相似度高的、歷史出現次數多的修復方式進行推薦。
2 實 驗
2.1 工具實現
基于本文方法,研發了基于代碼上下文相似度分析的代碼問題修復推薦工具。問題推薦工具可分析目標項目內的已修復問題的修復方式并對其進行聚類和建模,構建問題修復資源庫,然后根據目標問題代碼及其上下文匹配資源庫內的問題修復記錄,選擇相似度高的進行修復推薦。
2.2 實驗評價
實驗選取Github上的高星開源項目作為實驗對象,代碼問題修復資源庫則選擇本文資源庫進行實驗。本文根據實驗目的分別設置不同的實驗,分析了工具的聚類效果及推薦效果的有效性,并且對本文代碼問題修復推薦方法的局限性進行說明,最后將本文工具與“Nopol”進行對比。
2.2.1聚類效果的有效性評估
在基于代碼相似度分析的問題修復推薦方法中,使用問題代碼及其上下文聚類、問題修復方式聚類方法進行了優化,提高了推薦的效果。本實驗選取了Github上的高星開源項目的50條歷史修復案例,用聚類方法對其進行聚類操作,對其實驗結果進行評估,驗證其正確性、有效性。
這50條歷史修復案例分為七種問題類型,其中第一、第二、第五種問題類型只有一條修復案例,無須進行聚類,將其剔除。剩余47條歷史修復案例的聚類實驗結果如圖4所示。

圖4 聚類實驗結果
47條修復案例分為4種問題類型。圖4展示了每種問題類型的案例條數。只有同種問題類型的案例才能進行聚類。如問題類型三的20條修復案例,通過修復案例聚類將該20條修復案例聚為了4類,即該類型的代碼問題歷史上有4種修復方式。其余問題類型的聚類以此類推。
本文挑選了6位具有程序開發研究背景和經驗的碩士生,其中4位每人負責一種問題類型,對聚類結果的正確性進行人工驗證,其余2位對原始的47條修復案例分別進行人工分析歸類。針對聚類效果評估實驗,參與者得到的信息包括50條修復案例的問題類型、問題代碼及上下文代碼、提交日期、修復方式代碼及上下文等。他們可以訪問修復推薦系統,了解聚類方法的主要功能和流程,可以看到該方法的數據模型和源碼,也可以查看聚類方法的中間信息及結果信息。
實驗發現,驗證類型三、類型四、類型六的碩士生表示他們認為系統的聚類結果是正確的,即聚類方法對這三種問題類型的聚類類別個數以及每一類的修復案例劃分是正確的。驗證類型七的碩士研究生表示這7個修復案例應聚為4類而不是聚類所得的3類。即實驗結果中的問題類型七的三種修復方式中的第1類(圖4中標有星號的類別)應該聚為兩類。這兩類中的2種修復方式的代碼非常類似,但是他認為劃分為2種修復方式更為精確,其余兩類的聚類結果正確。其余2位實驗參與者中的第一位的人工聚類結果與工具的聚類結果是相同的,第二位參與者的人工聚類結果與工具的聚類結果稍有差異,差異也是問題類型七中的第一類(圖4中標有星號的類別)修復方式的劃分,他認為該類劃分為兩類更為合適,其余類別的劃分數量及每個類別中的修復案例與工具的聚類結果一致。
設置對比實驗以驗證問題聚類能有效提高對目標問題修復推薦的效果。本實驗挑選了2組具有程序開發經驗的碩士生,每組4人,2組參與者的程序開發能力相當。從平臺上隨機選擇8個未修復且有推薦結果的問題,分配給2組的參與者,每人2個問題。第一組參與者根據聚類后的推薦修復案例結果進行問題修復,第二組參與者根據不聚類的推薦修復案例結果進行問題修復,分別記錄每位參與者對每個問題進行出錯原因排查、選定修復案例、問題修復所用的時間。最終每個問題都在正常時間內被修復。實驗發現,第一組參與者的平均問題出錯原因排查時間為1 min,平均選定修復案例時間為1 min,平均問題修復使用時間為3.2 min。第二組參與者的平均問題出錯原因排查時間為2 min,平均選定修復案例時間為3.6 min,平均問題修復使用時間為7.8 min。從上述結果可知,問題聚類能有效提高對目標問題修復推薦的效果。
由實驗結果可知,本文的聚類結果基本正確,聚類方法較為合理,聚類效果較為有效。
2.2.2推薦方法的有效性評估
本實驗從Github上隨機選擇4個高質量項目中的23個待修復問題作為目標問題,使用自己的歷史修復記錄資源庫中的問題修復案例對工具進行有效性評估,工具中添加了來自Github的217個Java軟件項目,分析了這些項目近一年來的57 752個問題修復案例。選中的4個項目中有一個項目是平臺中的,隨機選擇該項目中的4個至今沒有被修復的問題作為目標問題。其余3個項目不曾添加到平臺中,從這3個項目中隨機選擇19個至今未修復的問題作為目標問題。本實驗認為對于一個待修復問題,推薦出的能夠幫助開發人員較快地理解并修復問題的修復案例叫作有參考價值的修復案例。
下面通過一個具體實例來說明怎樣叫做有參考價值的修復案例。
圖5展示了一個目標問題的代碼段,①為問題代碼行。實驗要求在不尋求其他任何幫助的情況下,僅依靠為它推薦出的代碼問題修復結果對問題進行修復。

圖5 目標問題代碼
本文工具為該目標問題推薦出兩條修復案例,其中第一條更為相似。圖6以及圖7展示了為該問題推薦的第一條修復案例。其中,圖6展示的是問題代碼段,①為問題代碼行,其余部分為上下文代碼行。我們把該問題代碼段與目標問題代碼段進行比較,可以看出,這兩段問題代碼發生錯誤的原因一致,且代碼非常相似,僅變量名不同,Token化后相似度很高,經過推薦算法的計算,此記錄作為目標問題的推薦結果很合適。圖7展示了推薦報告中的修復方式代碼段,①為修復代碼行,根據該推薦結果,無須尋求其他任何幫助,很容易對目標問題進行修復,具有很高的參考價值。

圖6 問題修復推薦報告-問題代碼段

圖7 問題修復推薦報告-修復方式代碼段
本實驗挑選了4位具有程序開發經驗的碩士生,讓他們分別對4個項目中的目標問題的推薦結果的有效性進行評估。實驗認為,如果在3小時內修復推薦系統能夠推薦出修復案例、參與者完成問題修復、修復后的程序能夠通過FindBugs檢測,就認為該目標問題被成功修復(其中參與者進行問題修復的過程不能超過15 min)。其中任何一項不能通過則認為目標問題沒有被成功修復。
本文認為精確率是所有被成功修復的目標問題數目除以所有成功生成推薦結果的目標問題數目。
表1展示了23個目標問題的推薦結果信息,參與者自己操作推薦系統獲取推薦結果,對于成功生成推薦結果的目標問題,參與者從所有的推薦修復案例中選出一個最具有參考價值的修復案例,根據該修復案例對目標問題進行修復,將修復后的程序進行靜態分析。最終經過實驗驗證,工具對23個目標問題中的20個成功生成了推薦修復案例,這20個修復案例與目標問題上下文匹配,是同種類型的問題。參與者對選定的最具有參考價值的20個修復案例進行評估,認為這20個選定的修復案例中17個是有效的、有參考價值的。即被成功修復的目標問題數目為17,所有成功生成推薦結果的目標問題數目為20,本文工具的精確率為85%。
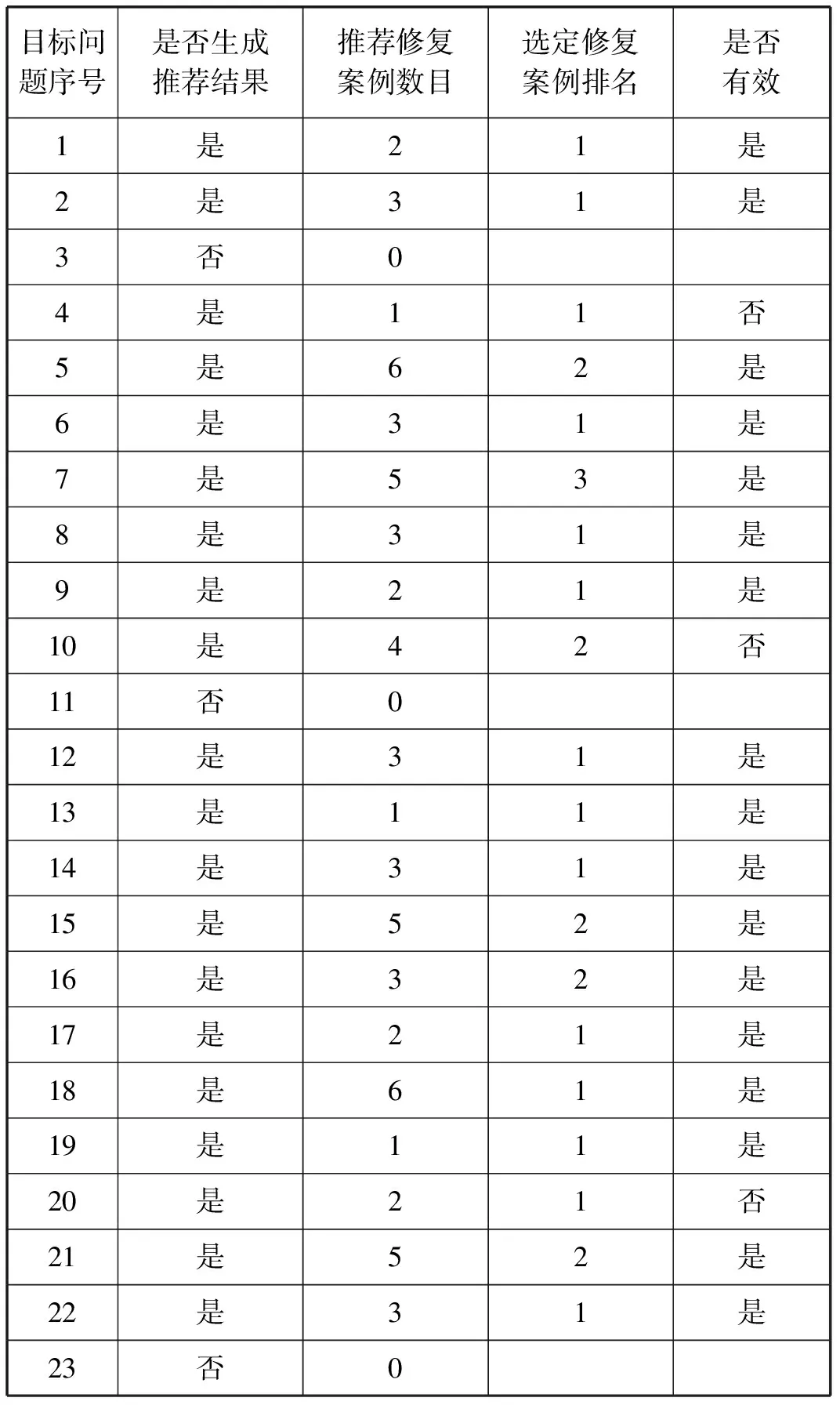
表1 目標問題推薦結果信息
設置對比實驗以驗證進行問題修復推薦是有效的,可以提升開發效率。本實驗挑選了2組具有程序開發經驗的碩士生,每組4人,2組參與者的程序開發能力相當。從平臺上隨機選擇8個未修復問題,分配給2組的參與者,每人2個問題。第一組參與者根據問題修復推薦系統的推薦結果進行問題修復,第二組參與者沒有推薦結果作為參考,分別記錄每位參與者對每個問題進行修復所用的時間。最終所有問題都被修復。實驗發現,第一組參與者的平均問題修復使用時間為3.7 min。第二組參與者的平均問題修復使用時間為16.2 min。從上述結果可知,問題修復推薦是有效的,可以提升開發效率。
上述兩個實驗說明本文問題推薦方法以及推薦工具在實際的應用中具有有效性。
然而,本文方法具有一定的局限性,由于本文方法是基于歷史修復的,因此修復推薦的結果的質量依賴于修復資源庫中所收集的項目的質量和數量。該方法僅針對靜態分析,只能修復代碼靜態分析檢測到的問題。由于該方法基于靜態檢測結果進行分析,因此FindBugs的誤報漏報可能會對后續分析產生影響。由于目前僅使用FindBugs作為代碼靜態分析工具,只分析了Java項目,本文中的問題修復推薦方法目前僅適用于Java語言。
2.2.3與Nopol的區別
Nopol[8]是一種基于語義的問題修復工具,由于它也是代碼問題修復方面的工具,可以對Java程序中的問題進行修復,且是近年來較新的工具,因此選擇該工具進行比較。我們從輸入輸出、問題類型、精確率、誤差幾方面將本文方法與其進行對比。
輸入輸出:Nopol的輸入是一個帶有問題的程序以及相應的測試集合,輸出是其生成的帶有條件表達式的補丁。測試集合包含可通過的測試用例以及至少一個失敗的測試用例。可通過的測試用例用以定義程序預期的行為;失敗的測試用例用以定義要修復的問題。而本文工具的輸入是一個有問題的程序,輸出是與該問題最為相似的幾條修復記錄,包括問題代碼及其上下文、修復方式代碼及其上下文、問題類型等。
問題類型:Nopol可以修復的問題類型是if條件語句錯誤及前置條件錯誤,即針對條件語句問題進行修復。本文工具的問題修復方法是通用的。
精確率:根據Xuan等[8]對Nopol的實驗可知,在得到的17個合成補丁中,有13個是正確的,而本文的實驗結果表明,在得到推薦結果的20個目標問題中,17個被正確修復。
誤差:在實踐中,僅僅通過測試集合的補丁不一定是正確的,因為測試用例不一定能夠正確地定義程序行為。因此,當測試集合的質量不足時,Nopol便無法保證能夠生成正確的補丁。而文本方法無需測試集合的支持,避免了該種情況的發生,且給出的已修復程序通過了FindBugs的靜態掃描,一定程度上避免了新問題的引入。
3 相關工作
代碼問題修復在產業界可以輔助開發人員修復代碼,提高代碼質量,在學術界更是實現軟件自動化的有效途徑。由于其極大的產業意義和學術意義備受關注,越來越多的研究人員致力于問題修復技術的研究。
Genprog是早期的能夠自動生成補丁的系統,該系統的研究人員提出,可在應用程序的其他位置找到補丁的代碼[9-10],除了發現可以重用的代碼存在于其他地方這一事實外,還發現了潛在的修復成分的上下文是有用的:通常,重用代碼部分的上下文類似于被修復的部分的代碼上下文[11-12]。生成候選補丁的一種方法是在原始程序上應用變異運算符。變異運算符潛在地通過它的抽象語法樹表示形式或更粗粒度的表示形式(例如語句級或塊級)操縱原始程序。較早的遺傳改良方法在語句級別運行,并執行簡單的刪除/替換操作,例如刪除現有語句或在同一源文件中用另一個語句替換現有語句[13-14]。最近的方法[15]在抽象語法樹級別使用了更細粒度的運算符來生成更多組候選補丁。機器學習技術可以提高自動問題修復系統的效率。SequenceR[16]對源代碼使用句到句學習,以生成單行補丁,它定義了一種神經網絡體系結構,可與源代碼很好地結合,并具有復制機制,該機制允許使用未包含在學習詞匯中的token生成補丁,這些token來自正在修復的Java類的代碼。
使用修復模板[17]是生成候選補丁的替代方法,用于修復特定類別的問題。也可以自動挖掘修復模板[18]用于生成補丁并對其進行驗證。Osman等[19]提出的修復模式(patterns)獲取方法是先自動地獲取修改模式,然后手動地修改這些模式。他們的人工分析階段對深入了解問題背后的原因至關重要。他們的更改粒度在單行代碼級別,無須任何抽象就可以捕獲所有更改。該研究包含的軟件項目有717個。
代碼問題修復技術有許多應用。在開發環境中,當開發人員遇到問題時,可以通過如單擊按鈕等操作來搜索補丁。當自動化到一定程度,IDE無須等待人工指示,主動在后臺搜索潛在問題的解決方案。在持續集成服務器中,如果在持續集成過程中構建失敗,則構建失敗后可以立即搜索補丁[20]。實驗表明,生成的補丁可以被開放源代碼的開發人員接受并合并到代碼庫中[21]。系統運行時,當發生運行故障,可以搜索二進制補丁并在線應用。這種修復系統的一個示例是ClearView[22],它使用x86二進制補丁對x86代碼進行修復。Itzal系統[20]與Clearview不同:修復搜索在運行時進行。而在生產中,所生產的補丁是源代碼級別的。BikiniProxy[23]系統可以在線修復瀏覽器中發生的JavaScript錯誤。阿里巴巴為了解決內部面臨的挑戰和難題,提出了PRECFIX[5]方法,主要分為三步,首先從代碼提交數據中提取“缺陷修復對”,然后將相似的“缺陷修復對”聚類,最后對聚類結果進行模板提取,這個缺陷檢測和補丁推薦技術可以用于代碼評審、全庫離線掃描等。
然而,目前提出的問題修復方法還是存在很多問題,如精確率低、只能修復特定問題類型、對測試用例完備性的要求非常高、修復的耗時長、消耗的計算資源較多等。本文基于所提方法研發的基于代碼相似度分析的代碼問題修復方式推薦工具,是針對任意問題類型的,它不需要輸入測試用例,聚類效果較好,推薦結果較為具有參考價值,能夠提高程序開發人員修復問題的效率。
4 結 語
本文提出一種基于代碼上下文相似度分析的代碼問題修復推薦方法。該方法首先收集歷史版本中代碼問題的修復案例,建立問題修復資源庫,然后根據問題類型、問題代碼及上下文、修復代碼及上下文對修復案例進行聚類,對每種不同類型的問題建立修復模板,最后通過對有同類問題的目標代碼及其上下文進行相似性分析,從而推薦具體的修復方式。基于以上所述方法,設計并實現一個基于代碼上下文相似度分析的代碼問題修復推薦工具,并基于Github上的真實項目設置多組實驗對聚類效果的有效性和推薦方法的有效性進行驗證。
然而,本文方法的問題推薦目前是基于代碼問題修復方式資源庫的,因此資源庫中修復案例的質量決定了修復推薦結果的質量。另外,該方法僅針對靜態分析,因此只能修復代碼靜態分析檢測到的問題,對于靜態分析結果中可能產生的誤報漏報需要進行進一步處理,因此在實際應用中代碼問題修復推薦的能力受此影響,對此,我們需要繼續進行研究。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
少先隊活動(2021年2期)2021-03-29 05:40:48
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中學生數理化(高中版.高二數學)(2019年6期)2019-06-24 03:37:50
電子制作(2018年18期)2018-11-14 01:48:24
中國公路(2017年7期)2017-07-24 13:56:38
山東工業技術(2016年15期)2016-12-01 05:31:22
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
