基于生成對抗網絡的混合類型數據生成方法
2022-07-12 14:03:28汪龍志董方敏
計算機應用與軟件 2022年6期
關鍵詞:模型
魏 寧 汪龍志 董方敏
(三峽大學計算機與信息學院 湖北 宜昌 443002)
0 引 言
在互聯網時代,隨著信息技術和人類生產生活交匯融合,大數據對經濟發展、社會治理、人民生活產生了重大影響,通過大數據分析可以對用戶群體的結構進行更合理的劃分,從而提供更加精確的服務。但與此同時,當大數據平臺將大量數據提供給外界進行數據分析時必然會增加用戶隱私信息泄露的風險,這種風險對于金融和醫療等領域都是備受關注的焦點。為了降低隱私信息泄露的負面影響,美國、歐盟、中國等國家或組織不斷通過完善隱私保護法規來對企業以及個人進行監管,以此來減少或者限制數據的共享和開放[1]。在這樣的背景下,大數據分析研究常常會遇到數據匱乏、訓練樣本過少等問題。為了解決該問題,目前的研究思路主要是從信息隱藏和數據生成兩個方面展開。從數據隱藏角度出發,如健康醫療組織(HCOs)通過泛化、抑制和隨機化來干擾潛在的可識別屬性然后再共享數據,以此來降低信息泄露的風險[2-3]。然而,不法分子依然可以通過剩余的屬性信息還原數據對應的個人標簽,從而恢復原始數據。而基于數據生成方法的研究,由于隨著各種深度學習模型的建立,越來越受到該領域學者的關注,其主要思想是通過對極為有限的真實數據進行學習來捕捉數據集的潛在分布結構,然后通過生成模型來生成與真實數據具有相似分布的合成數據,以此來解決數據匱乏的問題[4]。本文的工作也是基于該思路展開,通過深度生成模型中的生成對抗網絡來合成模擬真實的數據。
目前,深度生成模型被證實是一種高度靈活和可表達的無監督學習方法,能夠捕獲復雜高維數據的潛在結構。訓練好的深度生成模型可以有效模擬高維數據復雜分布,生成與原始數據相似的合成數據[5-6]。與之相關的一些研究主要包括基于先驗或后驗的變分自編碼器(Variational Autoencoder,VAE)[7],如變分有損自編碼器(Variational Lossy Autoencoder)[8]、具有重疊變換的離散變分自編碼器(DVAE++)[9]、形變化自編碼器(ShapeVAE)[10],以及生成對抗網絡(Generative Adversarial Networks,GANs)[11],如生成匹配網絡(MMD-GAN)[12]、增強生成模型(AdaGAN)[13]和Wasserstein GAN(WGANs)[14]。其中生成對抗網絡(GANs)近年在圖像生成方向取得了豐富的成果,在生成逼真圖像的性能上遠超其他方法[15]。GANs模型采用對抗博弈的思想,由生成器G和鑒別器D兩部分組成,生成器學習真實樣本的分布并生成相似的合成數據,鑒別器判別真實數據和合成數據,兩者互相進行對抗交替訓練。隨著生成對抗網絡領域的實踐應用與理論發展[16],越來越多的學者將關注點轉向對數據科學的研究。目前與GANs相關的研究大多針對連續數據集,但是數據科學應用通常還涉及離散變量。對于這些數據,GANs從離散分布層采樣是不可微分的,導致無法使用梯度反向傳播訓練模型,因此無法直接訓練出具有分類輸出的網絡。Jang等[17]提出Gumbel-Softmax方法來解決變分自編碼器(VAE)生成離散數據問題,與此同時Kingma等[18]也提出Concrete-Distribution方法來解決此問題。在基于VAE所提出的方法中,Kusner等[19]將這些方法應用到GANs模型來生成離散序列數據。針對同樣問題,seqGAN[20]基于強化學習的思想提出隨機策略方法以避免離散序列反向傳播問題。另一種避免離散數據反向傳播方法是Adversarially regularized autoencoders(ARAE)[21],將訓練用的離散詞項轉換為連續的潛在特征空間,并利用GANs生成潛在的特征分布。Edward Choi等[22]提出一個與ARAE類似的Medical Generative Adversarial Network模型(medGAN)來生成合成二進制或數值類型數據。此模型基于Vincent等[23]提出一種基于編碼器-解碼器的方法,預先訓練一個自編碼器,編碼器將樣本映射到低維連續空間,解碼器返回原始數據空間,然后利用GANs生成連續型數據的優勢生成數據的低維連續空間,接著通過解碼器解碼出低維連續空間對應的高維連續或離散空間,增強模型生成合成數據的準確度。對于標簽變量的生成,Ramiro等[24]在medGAN基礎上提出一種多標簽變量的生成對抗網絡(Multi-Categorical GAN),其思想是將多標簽變量編碼為多個獨熱編碼(One-Hot-Encodings)組合的二進制表示[25],并將Gumbel-Softmax這個針對變分自動編碼器(VAE)領域中的方法應用到模型當中,提高計算穩定性和收斂速度。基于現有的VAEs無法直接處理混合類型數據,Alfredo等[26]提出一個HI-VAE似然生成模型來擬合混合類型數據,并通過ELOB證據下界來優化生成模型和識別模型的參數,以此來生成混合類型數據。
現有基于GANs的模型缺少針對于混合類型數據生成方面的研究。本文提出一種混合類型數據生成模型mixGAN,該模型通過自編碼器將混合數據映射到低維連續空間,然后通過在低維空間中的生成器和原始空間的鑒別器進行聯合對抗學習獲得混合數據生成器,并構造出一個混合類型數據的損失重建函數。通過構造實驗,本文生成模型能夠捕獲復雜高維數據的潛在結構,有效地模仿來自大型高維混合數據集的分布,保持了數據集的完整性和相關性,生成與原始數據集更加接近的新數據集。
1 本文方法和模型
1.1 數據預定義背景
本文假設數據的每個記錄包含數值和標簽兩種類型,數據空間定義為S=(W×V),其中數值空間W=W1×…×WM(W∈RM),定義隨機向量x=(x1,x2,…,xM)∈W;標簽空間V=V1×…×VN,其中Vi為該屬性所具有的所有類別(比如男女、職業等),每個標簽的類別個數di=|Vi|,定義隨機向量v=(v1,v2,…,vN)∈V,對其中每個標簽向量vi經過One-Hot編碼后記為向量yi∈{0,1}di。于是空間S中的隨機變量s可以表示為s=(x,y)=(x1,x2,…,xM,y1,y2,…,yN),其中yi=(yi,1,yi,2,…,yi,di)。
1.2 本文模型
本文所提出的mixGAN首先預訓練一個并行輸出的自編碼器(Autoencoder),通過它完成混合數據空間到低維連續空間的映射。然后通過建立在低維連續空間的生成網絡G和建立在原始混合數據空間中的鑒別器D進行聯合對抗學習獲得最終需要的生成器G。本節將通過分別描述自編碼器網絡和生成對抗訓練網絡完成對mixGAN的各個模塊的介紹。
1.2.1前置自編碼器
本文針對自編碼器的解碼輸出層進行修改,將混合層的數據進行切割輸出,在其后放置N+1個并行的屬性輸出層,如圖1所示。并行輸出模型既保證了單屬性的獨立性也維持了屬性間的相互依賴關系。自編碼器的Encoder網絡將輸入的混合數據s=[x1,x2,…,xM;y1,y2,…,yN]映射到低維連續的編碼空間(Code Space),然后自編碼器的Decoder網絡將編碼空間數據投影回原始數據空間,完成數據重建。
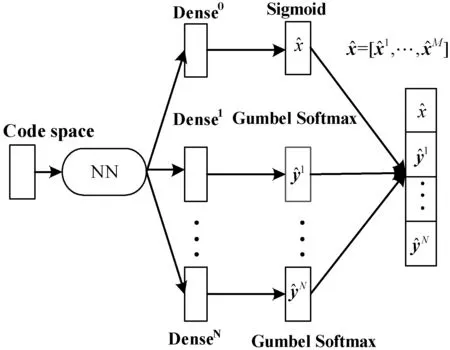
圖1 Autoencoder自編碼器
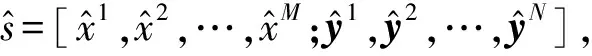
本文利用Gumbel-Softmax的采樣技巧來對離散分布進行采樣[17],解決離散數據反向傳播問題。具體方法是將隱變量建模為服從離散的多項分布,轉化過程滿足下式:
(1)
式中:j=1,2,…,N,k=1,2,…,dj,ai為全連接層Dense1,Dense2,…,DenseN的輸出,τ∈(0,∞)為大于零的超參數且控制著軟化程度:τ值越高生成的分布越平滑;τ值越低生成的分布越接近離散的One-Hot分布。訓練中過程中可以通過逐漸降低τ以逐步逼近真實的離散分布。
在模型訓練期間,對Decoder網絡的輸出與原始數據進行對比,重建損失函數為式(2)。式(2)中,對于數值類型變量采用均方誤差進行誤差計算,對于分類變量采用交叉熵進行誤差計算。數值類型數據在輸入模型之前進行歸一化處理,因此各個類型誤差量級相同且在0到1內,不會出現大的誤差量壓制小的誤差量。
(2)
式中:xm代表多數值向量x的第m個維度,yj,k代表多標簽向量yj的第k個維度,B為訓練批次的大小。
1.2.2生成對抗網絡模型(GANs)
生成對抗網絡由兩個網絡模塊組成,生成器網絡(Generator Network,G)和鑒別器網絡(Discriminator Network,D)[10]。生成器G(z;θg)學習訓練數據的分布,并將輸入的隨機先驗分布轉化為和訓練數據相似分布的生成樣本G(z)。鑒別器D(x;θd)是一個二分類器,用來判斷所輸入數據集是真實樣本還是生成的假樣本,即對于真實數據鑒別器將輸出較大的概率,而對于假數據將輸出較小的概率。在訓練過程中使G和D互相博弈對抗,直到G生成的數據可以“騙過”D,上述的博弈過程的優化目標可表示為:
Ex~Pz[log(1-D(G(z)))]
(3)
式中:Pdata代表真實樣本的分布,Pz代表服從N(0,1)的隨機先驗分布。在交替訓練G和D的過程中參數優化遵循如下迭代公式:
(4)
(5)
式中:B為每個訓練批次的大小,α為優化器的迭代步長。
1.2.3本文混合模型(mixGAN)
本文將自編碼器應用到GANs的數據生成中,利用自編碼器的解碼器將低維連續的編碼空間數據投影回原始空間。通過前置解碼器,提升了模型的離散特征學習能力,又解決了離散數據反向傳播問題。本文通過自編碼器學習混合數據的特征空間,利用自編碼器的解碼器Dec將生成器G生成的潛在連續特征空間解碼為原始混合數據空間,模型如圖2所示。
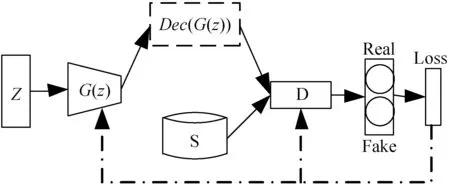
圖2 mixGAN模型視圖
如圖2所示,生成器G生成的數據在導入鑒別器之前先經過Dec(G(z))的解碼,可以看到鑒別器D對數據真實性的判別是在原始空間中進行的,本文模型訓練過程中生成器G和鑒別器D的損失函數構造如下:
(6)
(7)
在訓練mixGAN模型時,預先訓練好的解碼器會內置到模型中,優化生成器G參數的同時微調解碼器Dec可以看成是生成器G一個預訓練好的隱藏神經單元。
2 實驗與結果分析
基于目前最新的混合類型數據生成模型HI-VAE,本文以此為基準進行對比評估。HI-VAE在編碼和解碼時區分對待數據中不同屬性類型,為每一種類型設計對應的概率模型。依據每一種屬性所對應的概率模型,HI-VAE的編碼器對該屬性進行單獨處理,并把所有的屬性處理結果進行匯總而產生編碼。HI-VAE的解碼器則執行上述處理的反過程,即將編碼轉換為各個屬性值并拼接在一起。
2.1 數值實現的實驗
2.1.1數據集
本文實驗對LendingClub開源銀行數據集S={s1,s2,…,sk}進行訓練和評估,樣本總量為從中隨機抽取的10 000行數據記錄。每行數據si包含31個屬性特征,剔除其中7個固定不變屬性,并把相同類型屬性歸并到一起。si中代表分類類型的屬性用One-Hot進行編碼表示。數據集S進行預處理后si=[x1,x2,…,x15;y1,y2,…,y9],其中數值類型元素維度為15,Multi-One-Hot類型數據由9個One-Hot變量組成,每個標簽變量的類別個數(One-Hot的位數)為[2,2,2,12,2,7,29,4,3]。
2.1.2數據歸一化
原始混合數據集中,數值類型變量和標簽類型變量量級相差較大,如果直接以原始數據集進行訓練,量級大的類型就會在訓練過程中占據主導地位,量級小的類型的作用就會被削弱,模型可靠性低。針對此問題,在訓練之前對數值類型數據進行Min-Max標準化,使之與標簽類型(One-Hot)變量量級相同,保證每個特征對訓練結果的貢獻相同,提升模型的精度,同時加快收斂速度。
2.1.3模型結果及參數設置
本文實驗基于PyTorch 1.1環境完成。模型前向訓練的自編碼器基于Multilayer Perceptron(MLP)實現,Encoder和Decoder各自包含兩個隱藏層,采用tanh函數激活。Encoder輸出層輸出的潛在特征空間維度設置為72,Decoder輸出層采用Gumbel-Softma和Sigmoid激活。對于超參數τ,根據實驗經驗取0.666時可獲得較好效果。GANs的生成器G和鑒別器D也是基于MLP實現,層與層之間利用Batch Norm進行歸一化處理并進行殘差連接,生成器G的隱藏層采用Tanh函數激活,鑒別器D的隱藏層采用LeakyReLU函數激活。模型優化都采用Adam算法,學習率lr設置為0.002,weight_decay設置為0.001,前置自編碼器的訓練時間為52.30 s,mixGAN模型訓練時間為880.64 s。
2.2 結果評估
本文假設當所生成的數據和真實數據相似時應滿足如下兩個特點:① 在單個屬性上,所生成的數據分布應該和真實數據的分布盡可能相似;② 生成數據在各個屬性之間的依賴關系應該也和真實數據類似。基于以上假設,本文分別從屬性獨立分布和多屬性相關性兩方面來評估生成算法的優劣。
2.2.1屬性獨立分布評估
在對數據的屬性獨立分布進行評估時,本文按照數值類型屬性和標簽類型屬性分別進行處理。對于數值類型的屬性xi,首先將生成數據和真實數據在[0,1]區間內量化為10個等級,然后統計各自的直方圖,之后將生成數據直方圖和真實數據直方圖按照等級進行配對(Preal,Pfake),如果二者分布相似則配對后的值應該接近相等。類似地,對于標簽類型,分別統計生成數據和真實數據在屬性yi,j上取值為1的概率,然后兩兩配對。當生成數據與真實數據在某個屬性上分布相似時,則這些配對值應該近似相等。為評估這些配對值的相似性,圖3以Pfake作為x軸、Preal作為y軸將這些配對點繪制到圖中。圖3(a)是本文所提出的mixGAN生成的數據與真實數據按照單個屬性配對后繪制的點,圖3(b)是文獻[26]所提出的HI-VAE生成的數據與真實數據按照單個屬性配對后繪制的點,其中圓形點代表標簽類型,星形點代表數值類型。由之前的分析可知,點的分布越接近對角線則說明生成數據與真實數據在各個屬性上越相似。從圖3中的對比可以發現,在數值類型數據生成方面,本文所提出方法在屬性獨立分布方面明顯要優于HI-VAE。

(a) mixGAN
(b) HI-VAE圖3 生成數據與真實數據獨立屬性配對分布圖
2.2.2多屬性相關性評估

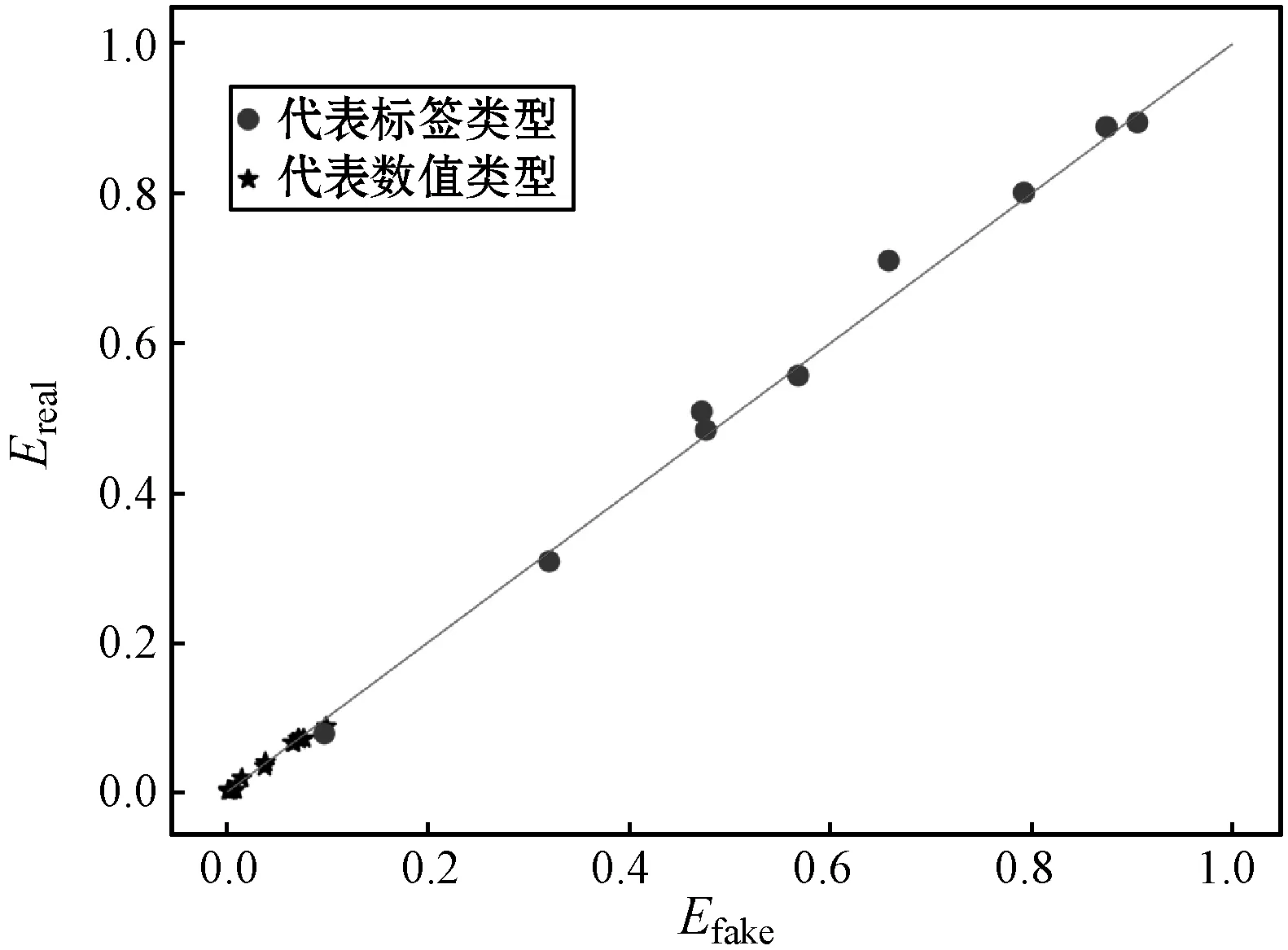
(a) mixGAN
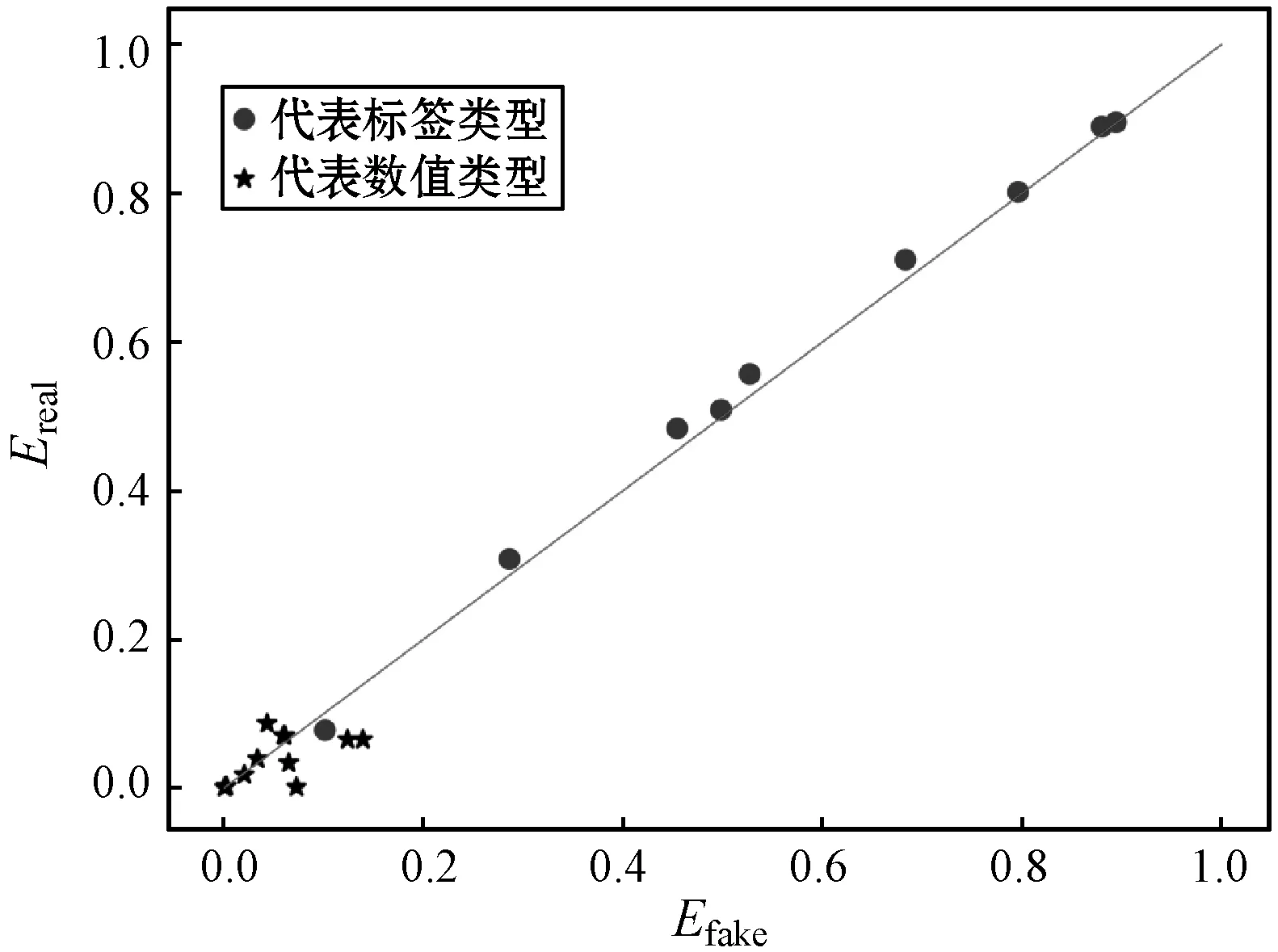
(b) HI-VAE圖4 生成數據與真實數據多屬性配對分布圖
3 結 語
本文所提出的混合數據生成模型mixGAN,特別適用于數據科學領域對混合類型數據的生成的需求。算法成功將改進的自編碼器應用到GANs模型中,提升了模型的離散特征學習能力。與現有的基于HI-VAE混合數據生成模型在屬性獨立分布和多屬性相關性方面進行對比,本文方法性能都具有較為明顯的優勢,生成的結果與原始數據集的分布更加接近。下一步的工作重點將著眼于缺失數據的補缺。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
