年齡跨度感知的多任務親屬關系驗證
2022-07-12 14:03:42秦曉倩劉大琨
計算機應用與軟件 2022年6期
秦曉倩 劉大琨
1(淮陰師范學院城市與環境學院 江蘇 淮安 223300) 2(鹽城工學院機械工程學院 江蘇 鹽城 224051)
0 引 言
親屬關系驗證的目標是通過學習得到一個分類模型,以判斷給定的人臉圖像是否具有父子(FS)、父女(FD)、母子(MS)和母女(MD)等直接血親關系。分類模型所獲知的對象間的關系信息可被應用于人臉識別、社會媒體分析、人臉標注和圖像追蹤等[1]。已有的親屬關系驗證方法可大致分為基于特征的和基于相似性學習的。Fang等[2]率先提出利用一些包括器官顏色、人臉的結構和紋理信息等特征來刻畫親屬關系人臉圖像。此后,研究者提出了其他多種不同的特征[3-7]以及屬性[8]。還有一些工作提出融合多種特征[9-12]來刻畫親屬關系人臉圖像。基于相似性學習的方法學習一個特征轉換空間,以達到更好地刻畫親屬關系樣本間相似性的目的。其中,文獻[13-16]使用遷移學習來減少年老父母與子女間的臉部外觀差異。度量學習方法是該類別中另一有效的驗證方法,其主要目標是學習某個相似性度量,以使得親屬關系樣本間相似性大于非親屬關系樣本。已有的度量學習方法又可以進一步根據所要學習的特征轉換矩陣的個數,繼續劃分為僅學習一個轉換矩陣的單度量學習[9,17]和學習多個轉換矩陣的多度量學習[10-11,18-23]兩種類型。Zhao等[24]和Liang等[25]則結合了度量學習與核方法,學習一個非線性的特征轉換矩陣。近期,深度學習亦被引入到親屬關系驗證任務中[18,26],但卻無法避免親屬關系人臉圖像的數據量較少這一問題。Yan等[27]則使用基于人臉圖像的親屬關系驗證工作中主流的幾種度量學習方法來對視頻中的親屬關系進行判斷,但仍只是簡單地將視頻中所有幀的均值作為某主體對象的最終的特征表示,從本質上來看,仍然是基于圖像的。
盡管已經有許多用于親屬關系驗證的度量學習方法,但已有方法中的大多數都是直接在每種親屬關系訓練樣本上統一學習,而鮮有討論年齡跨度對學習模型的影響。但是,隨著人的年齡增長,人臉外觀會在形狀和紋理上發生顯著變化,這都將增加親屬關系驗證的難度。另外,Xia等[13]的實驗結果也表明,主體對象的年齡跨度越大,外觀相似性越低,如圖1所示,圖1(a)是孩子和其父/母在年輕時的人臉圖像對,圖1(b)是該孩子和其父/母在年老時的人臉圖像對,觀察發現,圖1(a)中對象間的相似程度更高。對分類模型來講,這些具有不同相似程度的樣本對模型的影響程度截然不同。

圖1 不同年齡跨度的親屬關系圖像對
本文提出一種年齡跨度感知的多任務學習方法,通過在具有不同年齡跨度的親屬關系樣本間共享判別信息的方法,達到利用更多判別信息的目的。所提出的方法在學習時區別對待由年齡跨度不同所引起的在相似程度上存在差異的樣本對,而不是簡單地統一學習,解決了年齡跨度對親屬關系驗證的影響問題。
本文的主要工作如下:
(1) 在多任務學習框架下,將具有不同年齡跨度的親屬關系驗證問題分別看作一個學習任務,聯合學習兩類特征轉換矩陣,其中一類由所有學習任務共享,另一類則由每個學習任務獨享,以利用具有不同相似程度的樣本所蘊含的判別信息。
(2) 為了充分利用父母-孩子對象在不同人臉局部區域中所表現的遺傳相似性,借助金字塔多層結構進行親屬關系人臉圖像特征的表示學習。
(3) 在親屬關系人臉數據庫KinFaceW和UBKinFace上與現有的度量學習方法進行對比實驗,驗證了本文方法的有效性,并獲得了較高的驗證性能。
1 年齡跨度感知的多任務親屬關系驗證
本文提出的年齡跨度感知的多任務親屬關系驗證方法整體框架如圖2所示,首先將訓練樣本劃分為具有不同年齡跨度的樣本簇,再借助金字塔多層(Pyramid Multi-Level, PML)結構進行人臉圖像特征的表示學習,然后在多任務學習框架下學習特征轉換矩陣,最后使用SVM進行親屬關系人臉圖像的驗證。
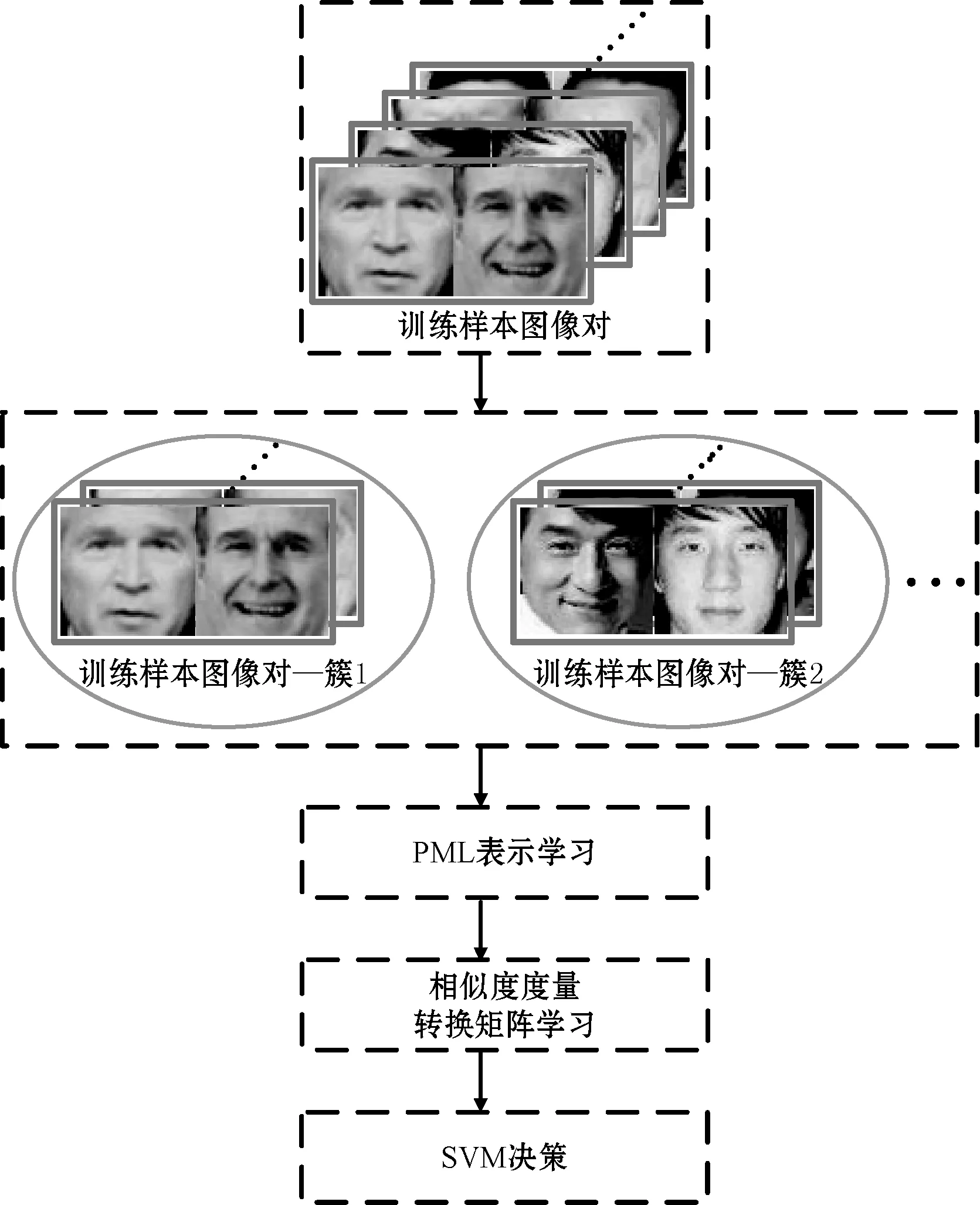
圖2 年齡跨度感知的多任務學習 親屬關系驗證算法框架
1.1 基于金字塔多層結構的人臉特征表示學習
在日常生活中,我們經常會聽到類似“小明的鼻子那兒和他媽媽真像”這樣的語句,因此,我們猜想,親屬關系對象間的遺傳相似性往往隱藏在臉部局部區域。基于此,我們借助金字塔多層結構,將父母-孩子人臉圖像分別劃分為不同尺度的多個局部塊,如圖3所示,我們在L=4個尺度上分別對人臉圖像進行劃分,其中,在第l個尺度上,人臉被劃分為l2個局部人臉塊,從每個局部塊上,抽取維度為m的特征向量,再將所有特征向量按序置于二維矩陣的列上,最終,得到兩個大小為m×B的矩陣Xp和Xc,其中B為所有尺度上的全部局部塊的個數,即B=L(L+1)(2L+1)/6。

圖3 基于金字塔多層結構的人臉劃分(Xpc)

(1)

1.2 年齡跨度感知的多任務學習方法


(2)

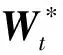
(3)
式中:轉換矩陣W0用于刻畫具有某種親屬關系樣本所共享的遺傳特性;Wt則被每個任務獨享,用于刻畫具有某種年齡跨度的親屬關系樣本的遺傳特性。
為了學習這兩種轉換矩陣,我們構建下面的優化問題:
(4)
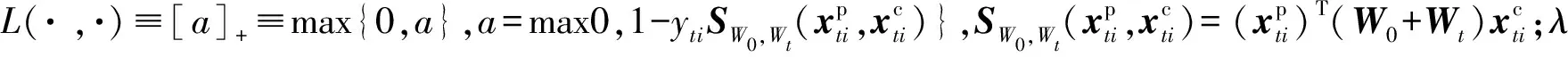
目標函數G(W0,Wt,λ,η)關于W0和{Wt}是凸的,為了獲得W0和{Wt},使用隨機梯度下降法求解式(4)。具體地,W0和{Wt}的梯度使用式(5)計算:
W0=W0L(·,·)+ηW0
Wt=WtL(·,·)+λWt
(5)
(6)
式中:μ是一個范圍在0到1之間的參數。
我們采取交替迭代優化的策略進行學習。具體地,首先固定W0,優化{Wt},再固定{Wt},優化W0。該過程一直重復直至到達預設的某種收斂條件,如迭代次數或相鄰兩輪經驗損失函數的差值變化小于某誤差等。
算法的具體過程整理如下:
算法1年齡跨度感知的多任務學習方法(AS-MTL)
參數:λ,η,迭代次數Nu,誤差τ。
輸出: 轉換矩陣W0和{Wt}。
Step1 初始化
1 隨機T+1個d×d的矩陣作為W0和{Wt}的初始值;
2 計算損失函數的值L0(·,·);
Step2 優化
Forr=1,2,…,Nu
固定W0,使用式(5)-式(6)更新{Wt};
固定{Wt},使用式(5)-式(6)更新W0;
計算Lr(·,·);
若r>2且Lr-Lr-1∨τ,轉到Step3;
Step3 輸出
輸出轉換矩陣W0和{Wt}
1.3 SVM決策
當從訓練樣本中學習獲得轉換矩陣W0和{Wt}后,意味著已經探尋到了所有親屬關系樣本所共有的投影轉換判別空間,以及具有不同年齡跨度的樣本簇各自獨享的判別空間。接下來,借助SVM訓練一個分類器做最后的決策。
具體做法如下:
首先,對每個訓練樣本簇中的每對訓練樣本圖像數據,根據其所對應的學習任務t,借助雙線性函數計算每幅圖像對主體間的相似度,即:
SW0,Wt(xp,xc)=(xp)T(W0+Wt)xc
(7)
接著,基于所有圖像對的相似度及其標號,訓練一個線性SVM分類器。
當有待驗證圖像對出現時,首先將待驗證圖像對劃分到某個對應的樣本簇t,再根據該樣本簇對應的轉換矩陣Wt和共有轉換矩陣W0,借助式(7)計算該圖像對的相似度,最后使用訓練好的SVM分類器進行預測。
2 實驗和結果分析
2.1 KinFaceW數據庫上的實驗
2.1.1數據庫和實驗設置
KinFaceW-I[9]和KinFaceW-II[9]是目前流行的親屬關系人臉圖像數據庫。這兩個數據庫最大的不同是前者中的每對人臉圖像來自于不同照片,而后者中的每對人臉則來自同一幅照片。考慮到我們的目標,即討論年齡跨度差異在親屬關系驗證問題中的影響,而KinFaceW-II中的父母—孩子年齡跨度情況較為單一,因此,我們在KinFaceW-I上驗證本文算法的性能。圖4展示了KinFaceW-I數據庫中的四對圖像,其中每列的兩幅人臉圖像依次具有父子、父女、母子和母女關系。

圖4 KinFaceW-I數據庫圖像對樣本
KinFaceW-I[9]共包含156對父子、134對父女、116對母子和127對母女關系人臉圖像。但KinFaceW-I并未給出每幅人臉圖像上的主體對象的年齡信息,導致我們無法直接在其上驗證本文算法。為此,我們采取人工標注的方法,將該數據庫中的所有人臉對按照年齡跨度小于20歲和大于20歲這兩種情形進行歸類處理,這直接使得式(4)中的參數T=2。當然,也可以使用年齡分類器對人臉圖像進行自動年齡標注,但這里為了使得圖像樣本對的年齡跨度更為精準,使用了人工標注的方法。實驗遵循文獻[9]中的評估協議。
對本文方法中的參數,即λ、η、Nu和τ,使用4折交叉驗證方法設置它們的值,具體地,對λ,其候選值的值域為{0.001,0.01},對η,則根據λ的值確定其值的變化范圍,分別是{1×10-4:10:1×103}或{1×10-3:10:1×104}。分別設置Nu=200,τ=0.1。
2.1.2結果和分析
1) 基準實驗。首先,我們設計了基準方法Base_1以討論在學習過程中考慮年齡跨度影響的有效性。具體地,將式(4)中的T設置為1。其次,為了討論特征選擇方法的有效性,我們執行了本文方法的無特征選擇版本Base_2。
對這兩組基準實驗,我們為每幅人臉圖像抽取和數據庫發布者[9]所使用的相同的兩種特征:(1) SIFT:從相互之間有8個像素重疊的大小為16×16的塊中抽取SIFT特征。接著,將這些特征拼接為一個維度為6 272的特征向量。(2) LBP:將圖像分為4×4個相互之間無重疊像素的塊,每個塊的大小為16×16。接著,從每個塊中抽取256維的LBP特征,并拼接為4 096維特征向量。使用PCA將提取的兩種特征向量分別降到100維以去除噪聲。
表1是實驗結果。通過觀察,得到以下結論:

表1 基準方法和本文方法在KinFaceW-I
(1) 由于考慮了年齡跨度的影響,Base_2在所有親屬關系上可以獲得比Base_1更高的性能,且平均來看,兩種特征可分別獲得12.0百分點和12.5百分點的提高,說明在學習時考慮不同年齡跨度的影響是十分有效的。
(2) 所提的AS-MTL可以在Base_2的基礎上進一步提升性能,說明特征選擇的有效性。實驗中每種親屬關系上選擇出的人臉區域如圖5所示,其中被黑色塊覆蓋的部分是未被選擇的局部區域。觀察發現,所選的人臉塊大多位于人臉上的關鍵器官區域,這與我們日常生活中的經驗相一致。另外,我們也發現,在不同種類的親屬關系人臉圖像數據上選出的局部區域有所不同,這也暗示了性別對親屬關系驗證的影響。

圖5 KinFaceW-I數據庫親屬關系圖像選出的人臉區域
(3) SIFT特征在所使用的兩種特征中可以獲得更好的性能,在后面,我們將使用該特征與其他算法進行比較。
為了進一步展示本文方法的有效性,我們將KinFaceW-I數據庫中500對隨機的親屬關系對和非親屬關系對在Base_1和Base_2方法下的相似度分布進行了可視化處理,結果如圖6所示,其中:圖6(a)是Base_1方法所獲得的相似度分布;圖6(b)是Base_2方法的相似度分布。通過觀察可以發現,親屬關系對和非親屬關系對的相似度分布在Base_1方法所獲轉換空間中存在較為嚴重的重疊現象,而它們在Base_2方法所獲得的轉換空間中則變得更可分,再一次說明本文方法的有效性。
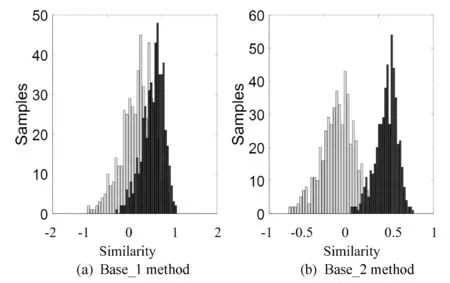
圖6 KinFaceW-I數據庫中500對親屬關系對和 500對非親屬關系對的相似度分布
2) 與其他度量學習方法的對比。由于本文方法需要學習特征轉換矩陣,這與已有的度量學習方法NRML[9]和NRCML[17]的學習目標一致,為此,我們還將本文方法與這兩個度量學習方法進行了比較。其中,NRML方法在學習時利用不同非親屬關系樣本對度量學習的不同影響,提出尋求一個特征轉換矩陣,以使得所有親屬關系樣本對的距離盡可能小而所有非親屬關系樣本對之間的距離盡可能大。而NRCML則在NRML的基礎上引入了相關性度量。
由于兩個對比方法僅在前述人臉特征上進行了特征轉換矩陣的學習,而沒有進行特征學習,因此,我們還將本文方法的無特征選擇版本Base_2與對比方法進行了比較。除此之外,我們還將本文方法與兩個多視圖度量學習方法S3L[22]和MHDL3-V[19]進行了比較。這兩種方法旨在利用多種特征相互間能提供互補性判別信息的能力來學習多個特征轉換矩陣。其中:S3L[22]使用了SIFT、HOG和LBP特征;而MHDL3-V[19]則使用了FV、Color和LPQ三種特征。所有對比方法的性能均來自對應文獻。表2比較了Base_2、AS-MTL和四個對比度量學習方法在KinFaceW-I上的結果。我們有以下幾點觀察:(1) 與單度量學習方法NRML[9]和NRCML[17]相比,由于NRCML[17]方法是NRML[9]方法的改進,因此可以獲得較高的平均性能。相較于NRCML[17]方法,Base_2在KinFaceW-I上平均獲得9.3百分點的提高,再一次說明在學習時考慮年齡跨度影響的有效性,而所提AS-MTL則可進一步平均獲得4.0百分點的提高,說明本文方法的有效性。(2) 與多度量學習方法S3L[22]和MHDL3-V[19]相比,由于S3L[22]和MHDL3-V[19]使用了多種特征,因此可以獲得比僅使用一個特征的NRML[9]和NRCML[17]方法更高的性能。而MHDL3-V[19]方法除了利用多種特征的互補性外,還學習了對稱和非對稱的多種度量,因此可以獲得最高的驗證性能。所提的AS-MTL方法也僅使用了一種特征,但在經過特征選擇后可以獲得與MHDL3-V[19]方法相當的平均驗證性能,說明本文方法的有效性。
3)與其他多任務學習方法的對比。由于本文方法構建在多任務學習框架下,因此,我們還將本文方法與No-group MTL[28]和GO-MTL[29]這兩個子空間正則化多任務學習方法進行了比較。其中:No-group MTL方法假設所有的學習任務是相關的,并通過對學習參數施加Lq,1正則化范數的方法來約束學習任務處于某個低維子空間;而GO-MTL方法則假設每個學習任務的參數向量是一些潛在的基任務的線性組合。
圖7比較了Base_1、Base_2、AS-MTL和兩個對比多任務學習方法在KinFaceW-I上的平均驗證精度。觀察發現,所有多任務學習方法都可以獲得比Base_1方法更高的性能,說明在進行親屬關系驗證時,考慮年齡跨度影響,并同時學習具有不同年齡跨度的樣本間的參數,可以有效提高泛化性能。
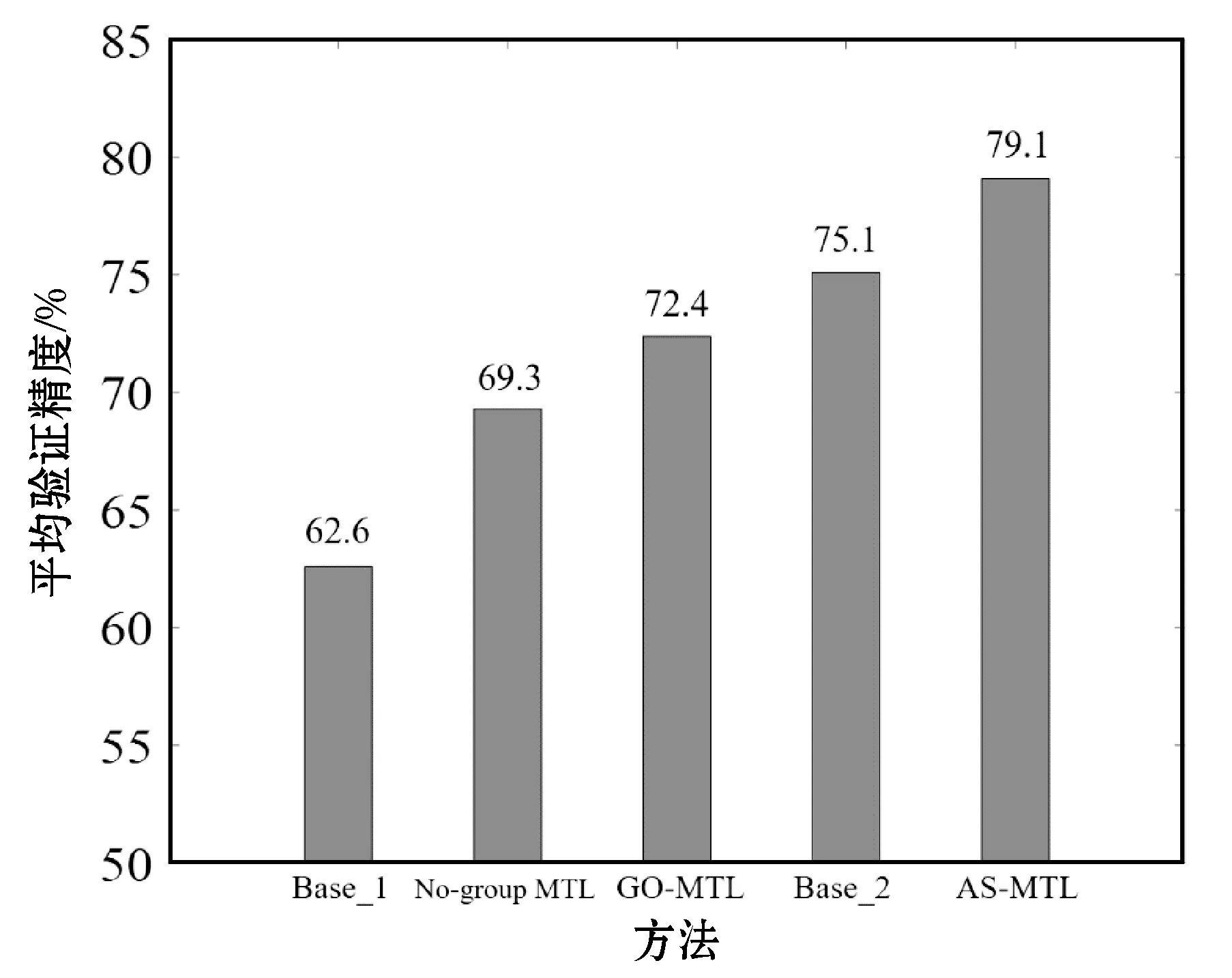
圖7 不同方法在KinFaceW-I庫上的平均驗證精度比較
其中,GO-MTL通過引入重疊組結構,在No-group MTL的基礎上獲得了3.1百分點的提高,說明具有不同年齡跨度的樣本簇相互間具有一定的結構。而Base_2方法則可在其基礎上進一步提高2.7百分點。原因是,相較于GO-MTL方法所假設的學習任務間存在的重疊組結構,Base_2方法僅通過在任務間共享一個共有轉換矩陣的形式在學習任務間共享判別信息,是一種相對松弛的學習方法,因此有機會獲得更高的驗證性能。
4) 參數的影響。我們還討論了參數u=λ/η的大小對算法性能的影響,具體地,通過固定參數λ的值,變化參數η大小的方式進行查看。另外需要說明的是,為了更純粹地討論年齡跨度對驗證結果的影響,需要將特征選擇過程剝離,因此,我們在本文方法的無特征選擇版本Base_2上進行具體的分析。圖8展示了在u取不同值時,Base_2方法的平均驗證性能。觀察發現,當u較大時,算法性能相對較低,表明具有不同年齡跨度的親屬關系樣本不能被無差別地統一處理。
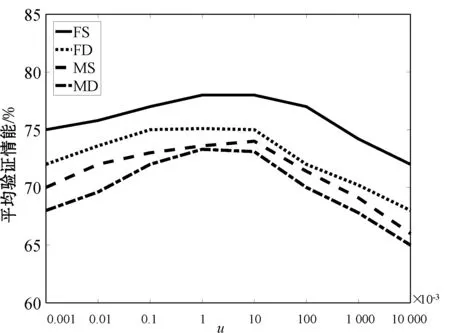
圖8 參數u=λ/η對驗證性能的影響
2.2 UBKinFace數據庫上的實驗
2.2.1數據庫和實驗設置
UBKinFace數據庫[13]包含200組親屬關系人臉圖像,每組人臉圖像由年老父母圖像、年輕父母圖像和孩子圖像組成,圖9展示了數據庫中的四組人臉圖像,其中每列的三幅人臉圖像依次是年老父母、年輕父母和孩子的圖像。

圖9 UBKinFace數據庫圖像組樣本
已有的親屬關系驗證算法都遵循文獻[13]中的協議,即構建兩個子集:“孩子—年輕父母”和“孩子—年老父母”,并分別在這兩個子集上驗證算法的性能。而我們的目標,是要討論年齡跨度差異在親屬關系驗證問題中的影響,因此,我們在遵循文獻[13]中的5折交叉驗證協議的基礎上,采取將這兩個子集合并且按照兩種不同年齡跨度情形進行歸類處理的策略來驗證本文算法的性能。
對本文方法中的參數,即λ、η、Nu和τ,采用與前述KinFaceW親屬關系人臉數據庫上相同的策略來設置它們的值。
2.2.2結果和分析
1) 基準實驗。我們執行了本文方法AS-MTL及其無特征選擇版本Base_2,在實驗中,我們為每幅人臉圖像抽取與KinFaceW數據庫所使用的相同的SIFT特征,表3是實驗結果。通過觀察,可以發現,所提的AS-MTL可以在Base_2的基礎上提升2.5百分點的驗證性能,說明方法的有效性。

表3 基準方法和本文方法在UBKinFace
2) 與其他最好學習方法的對比。我們將本文方法和包括基于遷移學習的文獻[13]的方法、基于單度量學習的NRML[9]、非線性多度量學習的NMML[21]和基于深度神經網絡的KML[26]等在內的四個方法在UBKinFace數據庫上進行了比較。但由于已有的方法都是分別在子集1“孩子—年輕父母”和子集2“孩子—年老父母”上驗證算法的性能,因此我們取這些對比算法在兩個子集上的驗證精度的均值作對比。
表4是實驗結果,其中所有對比算法的最后一列的精度值是其在兩個子集上精度的均值。我們有以下幾點觀察:(1) 與單度量學習方法NRML[9]和多度量學習方法NMML[21]相比,本文方法的無特征選擇版本Base_2可以獲得與NMML[21]相當的驗證精度,說明在進行親屬關系驗證時考慮年齡跨度影響是十分有效的,而AS-MTL可以獲得比其高2.7百分點的平均驗證精度,說明所提特征選擇策略的有效性。(2) 與基于深度神經網絡的KML[26]相比,所提AS-MTL可以獲得0.9百分點的平均驗證精度的提高,再次說明本文方法的有效性。同時也說明,在樣本數量較少的親屬關系數據上直接使用深度學習未必是最好的選擇。

表4 不同方法在UBKinFace庫上的驗證精度比較(%)
3 結 語
為了討論親屬關系驗證問題中具有不同年齡跨度的樣本對相似性學習具有不同影響的問題,提出一種年齡跨度感知的多任務學習方法。實驗表明,由于在多任務學習框架下同時學習具有不同年齡跨度的親屬關系樣本所蘊含的共有的、獨有的空間結構信息,因此,可以利用更多的判別信息,進而獲得較高的驗證性能。探討年齡跨度對親屬關系驗證的影響是利用人臉圖像進行親屬關系驗證的第一次嘗試,在今后的工作中,我們將考慮用自動化的方式獲取年齡跨度,再在此基礎上,構建一個年齡分類和親屬關系驗證的統一學習模型。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
兒童故事畫報(2019年5期)2019-05-26 14:26:14
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
