融合標簽和組推薦技術的評分預測算法
2022-07-12 14:22:58吳曉鸰
計算機應用與軟件 2022年6期
詹 彬 吳曉鸰 凌 捷
(廣東工業大學計算機學院 廣東 廣州 510000)
0 引 言
推薦系統是繼信息分類、搜索引擎之后解決信息過載的一項重要技術。推薦系統根據用戶的歷史數據來幫助用戶從海量信息中篩選信息,減少所要處理的數據。用戶的歷史數據一般情況下有兩種:一種是顯式反饋的信息,比如用戶的評分數據、評價等級等;另一種是隱式反饋,如用戶的一些行為數據。目前推薦系統模型有很多,例如經典的協同過濾推薦模型[1]、基于知識或內容的推薦模型[2]、基于統計學的推薦模型、混合推薦模型、社會化推薦模型[3]和組推薦模型[4]等。
一些推薦算法[5-6]結合了用戶的評分信息和用戶之間的社交化信息來更為有效地為用戶解決推薦和緩解用戶信息過于稀疏的問題。現實中大多數情況下都是只擁有用戶的購買或評分信息,而實驗環境下才擁有用戶的社交網絡數據。通常大量的用戶社交網絡數據無法獲取到。在沒有用戶社交數據的情況下如何提高推薦系統的有效性以及準確率是推薦系統中的一個重要問題。
在推薦系統中已經有很多人提出解決此類問題的方法,比如圖論、降維等。在評分預測中,最為成功的還是奇異值分解,也就是矩陣分解技術。但是沒有結合用戶社交網絡信息的矩陣分解技術不能有效解決數據稀疏的問題。由于數據稀疏,預測結果的誤差到了一定程度就無法進一步縮小。本文提出融合標簽和組推薦的概率矩陣分解方法(CTPMF),在概率矩陣分解的基礎之上增加用戶對物品打的標簽數據再結合組推薦算法來進一步降低預測結果的誤差,從而提高算法的有效性。
1 相關工作
1.1 概率矩陣分解
矩陣分解作為推薦系統中特別常用的一種技術,在現代推薦系統領域比較有影響力,常用于評分預測(rating prediction)和Top-N推薦中,常見的場景如用戶的電影評分預測。
在矩陣分解的基礎上,研究者提出各種改進方法,有BiasSVD、SVD++、timeSVD、NMF[6]等。還有人提出在原來的基礎上增加用戶的社交關系數據來提高預測準確率和可解釋性,比如SoRec。本文提出的融合標簽和組推薦的概率矩陣分解方法(CTPMF)是在概率矩陣分解算法的基礎上[7]來改進的。PMF(Probabilistic Matrix Factorization)模型是假設用戶隱特征矩陣、項目隱特征矩陣、評分矩陣均服從正態分布,如式(1)-式(3)所示。將待求解的子矩陣作為參數(如式(4)所示),并用最大似然估計求出子矩陣,即最小化式(5)。概率矩陣分解模型如圖1所示。
(1)
(2)
(3)
(4)
(5)
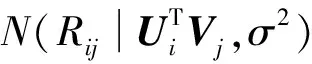
1.2 組推薦模型
在推薦系統領域,有越來越多的推薦服務涉及群體而不是個人。與個性化推薦系統不同,組推薦系統關注的是對某個群體的推薦。例如,電視節目的推薦FIT、TV4M,以及PolyLens和MusicFX音樂推薦等。組推薦技術關注整個用戶群體的綜合效果,本文方法(CTPMF)采用組推薦技術提取組成員的偏好來構造組偏好矩陣。計算用戶群體偏好常見的方法有如下幾種。
(1) 評分求和(Additive Utilitarian Strategy)。這個方法是將每一個用戶對當前項目的評分都累加,求出最后的和(如式(6)所示),從而產生一組對所有項目的評分列表。
(6)
式中:Hc表示c產品的綜合評分;Ruc表示成員u對c的評分。
(2) 評分相乘(Multiplicative Utilitarian Strategy):
(7)
1.3 基于標簽的推薦
目前的推薦系統主要是通過三種方式去聯系用戶的興趣和相對應的物品[8](如圖2所示),一種是給用戶推薦與用戶喜歡過的物品相似的物品,也就是基于物品的協同過濾算法;第二種是基于用戶的特征來對用戶推薦符合用戶特征的項目。最后一種是找到與用戶興趣最相似的用戶,并將其喜歡的物品推薦給當前用戶,也就是基于用戶的協同過濾算法。

圖2 推薦系統中聯系項目與用戶的幾種途徑
很多推薦系統算法也使用到了標簽[9],如基于social tag、social bookmarking等。這些都可以反映物品或者用戶之間的關系,還可以用于解決推薦系統當中的冷啟動問題[10]。根據給項目打標簽的人群,可大致將標簽分為兩種:一種是讓作者或者專家打標簽;另一種是讓用戶來打標簽,即UCG(User Generated Content)。很多網站都有UCG標簽系統,代表性的有Delicious、CiteULike、豆瓣等。
在推薦系統中,標簽的作用很大。30%的用戶認為標簽系統表達了用戶對物品的看法,23%的用戶認為可以幫助推薦系統找到用戶偏好,27%的用戶認為可以增加對當前項目的了解,14%的用戶認為可以輔助用戶更快地找到自己喜歡的項目。
2 融合標簽和用戶聚類的評分預測
2.1 方法介紹及變量聲明
本文方法(CTPMF)在基于傳統PMF的基礎之上,增加物品的標簽數據和通過組推薦技術得到的偏好信息來對原有的PMF模型進行約束。“用戶-標簽”矩陣-F為每個項目被打上各種標簽的次數。“用戶-標簽”矩陣一定程度上可反映用戶對物品的劃分。而“用戶-類別”矩陣則可以反映出用戶之間的關聯關系。
“用戶-類別”矩陣通過相似度計算獲得。首先通過用戶偏好計算用戶之間的相似度,然后使用用戶相似度對所有用戶進行聚類并計算出每個類簇的用戶的綜合評分,再計算用戶與每個類別的相似度得出“用戶-類別”相似度矩陣。
本文方法的計算過程如下:
(1) 根據用戶的評分來計算不同用戶之間的相似度,從而得到相似度矩陣。
(2) 根據用戶的相似度對用戶進行聚類(一個類別的用戶之間的相似度盡可能高,不同類別的用戶的相似度盡可能低)。
(3) 計算每個類別的用戶的偏好,得到“類別-項目”偏好矩陣。
(4) 計算出用戶與每個類別的相似度,得到“用戶-類別”相似度矩陣。
(5) 將“用戶-類別”相似度矩陣與“項目-標簽”矩陣添加到概率矩陣分解當中。
(6) 使用梯度下降尋找最優的預測參數。
變量說明如表1所示。

表1 變量說明
2.2 用戶類別矩陣
(1) 用戶相似度矩陣。在用戶的聚類過程中需要用到用戶之間的距離,可以使用用戶的相似度來度量。由于每一個用戶的評分習慣會不同,有的用戶習慣給高分,有的用戶則習慣給低分,比如用戶A習慣給的評分范圍是[3,5],而用戶B的習慣評分范圍是[1,3]。對于B用戶來說,3分已經算比較好的評價了,而從用戶A的角度來看,打3分基本算是很差的評價了。為了緩解這個問題帶來的影響,本文方法(CTPMF)使用余弦相似度來計算用戶之間的相似度(如式(8)所示)。
(8)
(2) 用戶聚類。計算出用戶之間的相似度之后,使用譜聚類算法對用戶進行聚類。譜聚類算法可以基于用戶的相似度來對所有的用戶進行聚類,使得相似度較高的用戶都被分到同一個類簇里面,相似度較低的用戶分配到不同的類簇。譜聚類算法在處理一些大小不一和形狀不一的數據時有較好的效果[11-13]。
定義G(V,E)表示用戶之間構成的無向圖(如圖3所示)。V表示點的集合,圖中的點表示每一個用戶。E表示邊的集合,邊則表示用戶之間有關聯,用戶之間的相似度作為邊的權值Wij,即WijSij。譜聚類是要將用戶之間組成的無向圖劃分為若干個無交集的子圖。同一個子圖里面的用戶相似度盡可能高,而不同子圖之間的用戶相似度盡可能低。一般情況下譜聚類劃分子圖時使用到的損失函數為被子圖截斷的邊(如連接U1、U5的邊和連接U3、U4的邊)的權重和(如式(9)所示),將這些邊的權重和最小化即可。
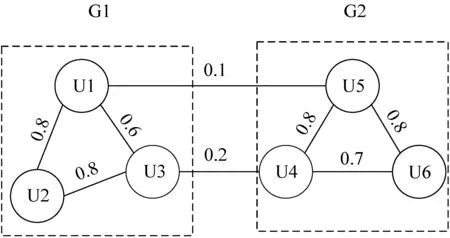
圖3 譜聚類
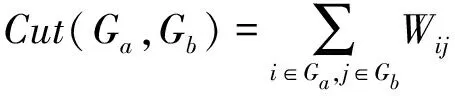
(9)
p=[p1,p2,…,pn]
(10)
(11)
式中:p用來表示劃分方案;根據pi的值來表示用戶i被劃分到哪一個類別。則損失函數可以寫成如式(12)所示。圖的劃分問題就轉化成pTLp的最小值問題。
(12)
計算過程如圖4所示。其中需要使用到無向圖的度矩陣D(度矩陣為對角矩陣,每個對角元素都表示所代表每個點(用戶)在無向圖中的度)、權值矩陣W(也就是用戶相似度矩陣)、拉普拉斯矩陣L。
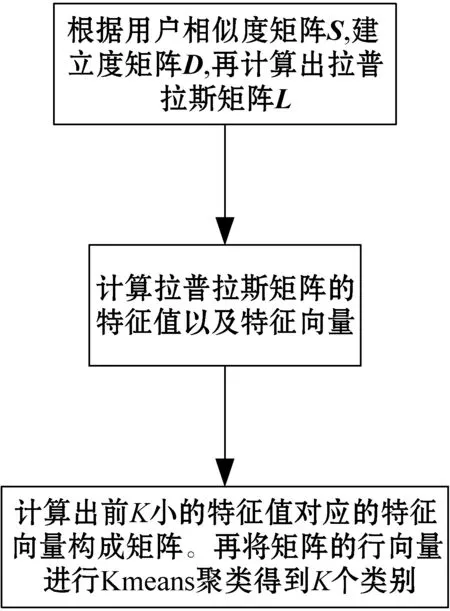
圖4 譜聚類流程
(3) 計算每個類別的用戶偏好。本文方法(CTPMF)用到用戶的群體偏好來對概率矩陣分解模型增加約束,所以首先需要獲取每個類別的用戶群體的偏好,用到的方法是評分求和法(Additive Utilitarian Strategy),即:
(13)
通過每個類別的用戶評分數據計算出類別的項目評分列表(如式(13)所示),由于得出的組偏好是當前類所有用戶的評分之和,所以在此之前需要將矩陣中用戶未評分的項目進行填充(如式(14)所示,Sil為上面所求的用戶相似度)。
(14)

(15)
組偏好的計算過程如圖5所示,其中U1、U2、U3為一個組的成員,首先根據用戶與類別中其他用戶的相似度填充每個用戶的評分,然后通過評分求和計算組偏好,得出最終的組偏好矩陣。

圖5 群偏好計算過程示例
(4) 生成用戶-類別矩陣。本文方法(CTPMF)將用戶-類別矩陣作為概率矩陣分解模型的一個約束添加到模型中。讓評分較少的用戶的評分偏向于用戶所在類簇的用戶偏好。這里需要通過用戶的偏好和每個類別的用戶的群體偏好來計算出用戶與每個用戶群體之間的相似度(計算相似度依然是使用式(8))。矩陣每一個值是對應類別和用戶的相似度。
2.3 加入用戶類別矩陣與物品標簽矩陣
PMF模型假設用戶、項目、用戶評分矩陣服從正態分布且相互獨立(如圖1和式(1)所示)。本文方法(CTPMF)在PMF基礎上加入項目標簽矩陣與“用戶-類別”相似度矩陣之后的模型如圖6所示。通過已有的評分矩陣R、C、F估算出所需要的U、V。最后只需最大化后驗概率來求得最優解,也就是最小化式(18)。使用梯度下降來最小化能量公式,需要先對各個方向求偏導,如式(19)-式(22)所示,再將對應值按負梯度改變。(這里使用了Logistic函數將數據映射到(0,1)的區間來計算梯度,如式(23)、式(24)所示)。
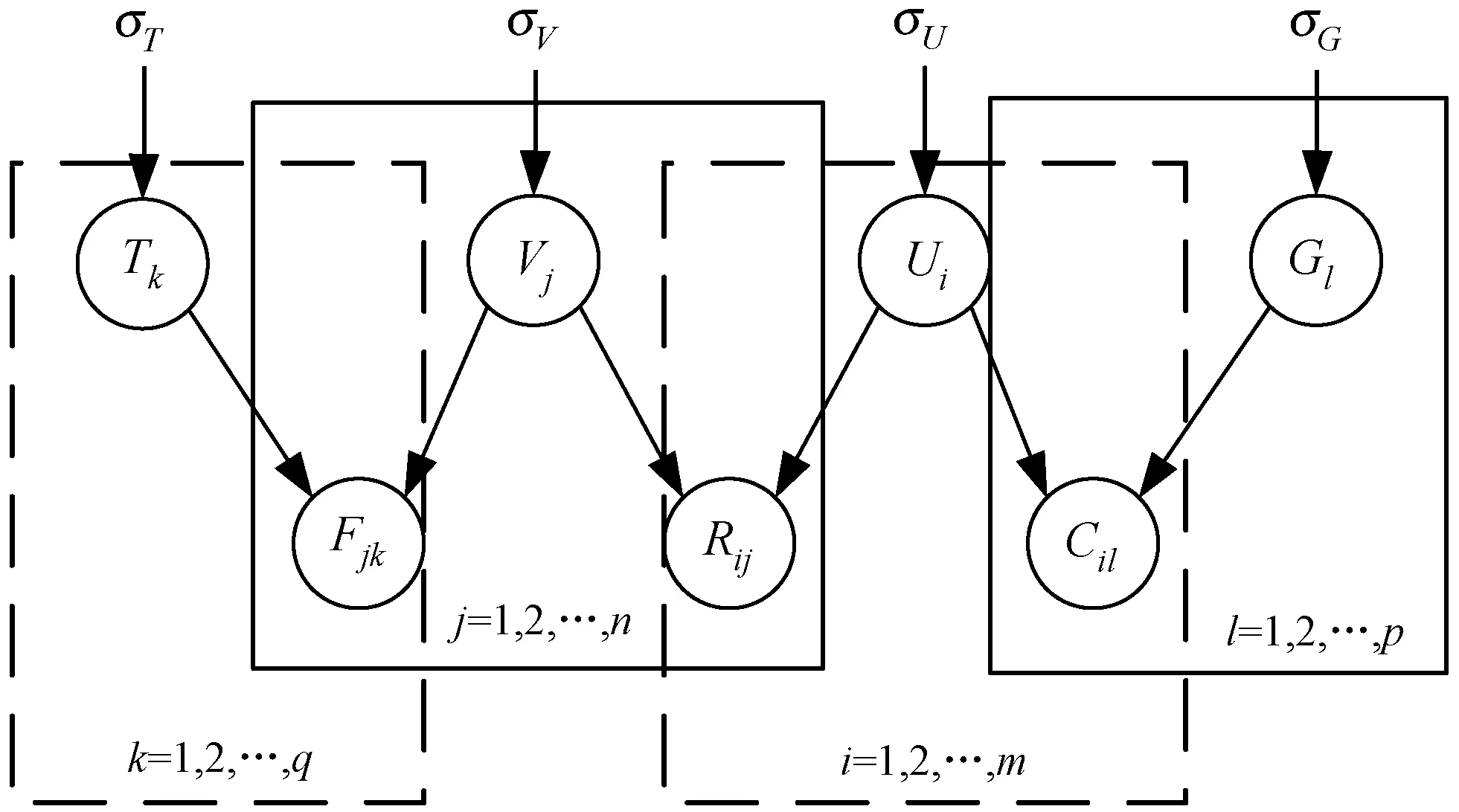
圖6 基于用戶聚類與物品標簽的概率矩陣分解模型

(16)
(17)
(18)
(19)
(20)
Fij)Vj+λTTk
(21)
Cli)Ui+λGGl
(22)
(23)
(24)
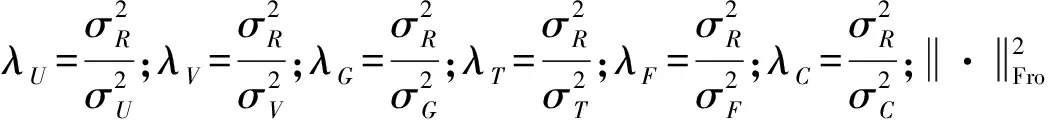
3 仿真實驗
3.1 仿真實驗數據
仿真實驗采用的數據是由明尼蘇達大學GroupLens實驗小組提供的MoiveLens數據集[14]。數據集由兩部分組成,分別包含100 835條用戶評分數據和3 662條用戶對電影打標簽的數據。其中用戶評分數據由評分用戶id、被評分電影id、評分、時間戳組成,打標簽數據由打標簽用戶id、電影id、標簽、時間戳組成。數據集中包含610個用戶、9 724部電影和1 589種標簽。數據集中的用戶評分為1分至5分,分數越高表示用戶的對電影的評級越高。
3.2 評價指標
本文選取了平均絕對誤差MAE(Mean Absolute Error)與均方根誤差RMSE(Root Mean Square Error)作為預測結果的評價指標。RMSE可以用來衡量觀測值同真值之間的偏差。MAE能更好地反映預測值誤差的實際情況。下面給出MAE與RMSE的公式定義:
(25)
(26)

3.3 實驗結果及分析
(1) 參數分析。這里將λu、λv、λg、λf、λc、λt設置為相同的值,測試參數對于預測誤差的影響。該實驗將參數分別設置為λ∈{0.1,0.3,0.8,2.0},比較使用這些參數分別在訓練集比例ratio∈{20%,50%,80%}的情況下的效果。具體如圖7-圖9所示。
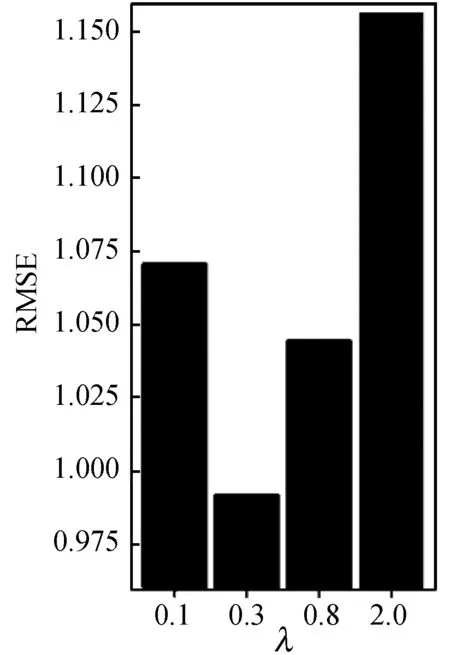
圖7 訓練集比例為20%下的參數比較結果
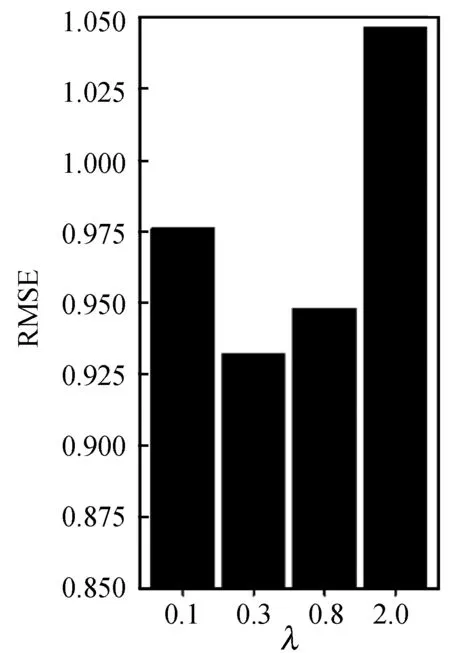
圖8 訓練集比例為50%下的參數比較結果

圖9 訓練集比例為80%下的參數比較結果
圖7-圖9展示了在不同比例的訓練集下,本文方法(CTPMF)對于不同λ值的結果對比。可以看出,在λ值為0.3時在20%、50%、80%的數據作為訓練集的情況下λ=0.3的結果優于λ=0.8與λ=0.1的結果,λ=0.8的結果優于λ=2.0的結果。
在基于矩陣分解的推薦算法中,潛在特征維度的大小對結果有一定的影響。潛在特征維度太小會導致潛在特征無法充分表示,而潛在特征維度過大則計算復雜度增大。本文分別在20%、50%、80%的數據作為訓練集時比較潛在特征維度分別取Dimension=5,10,15,20的情況下的結果,如圖10-圖12所示。
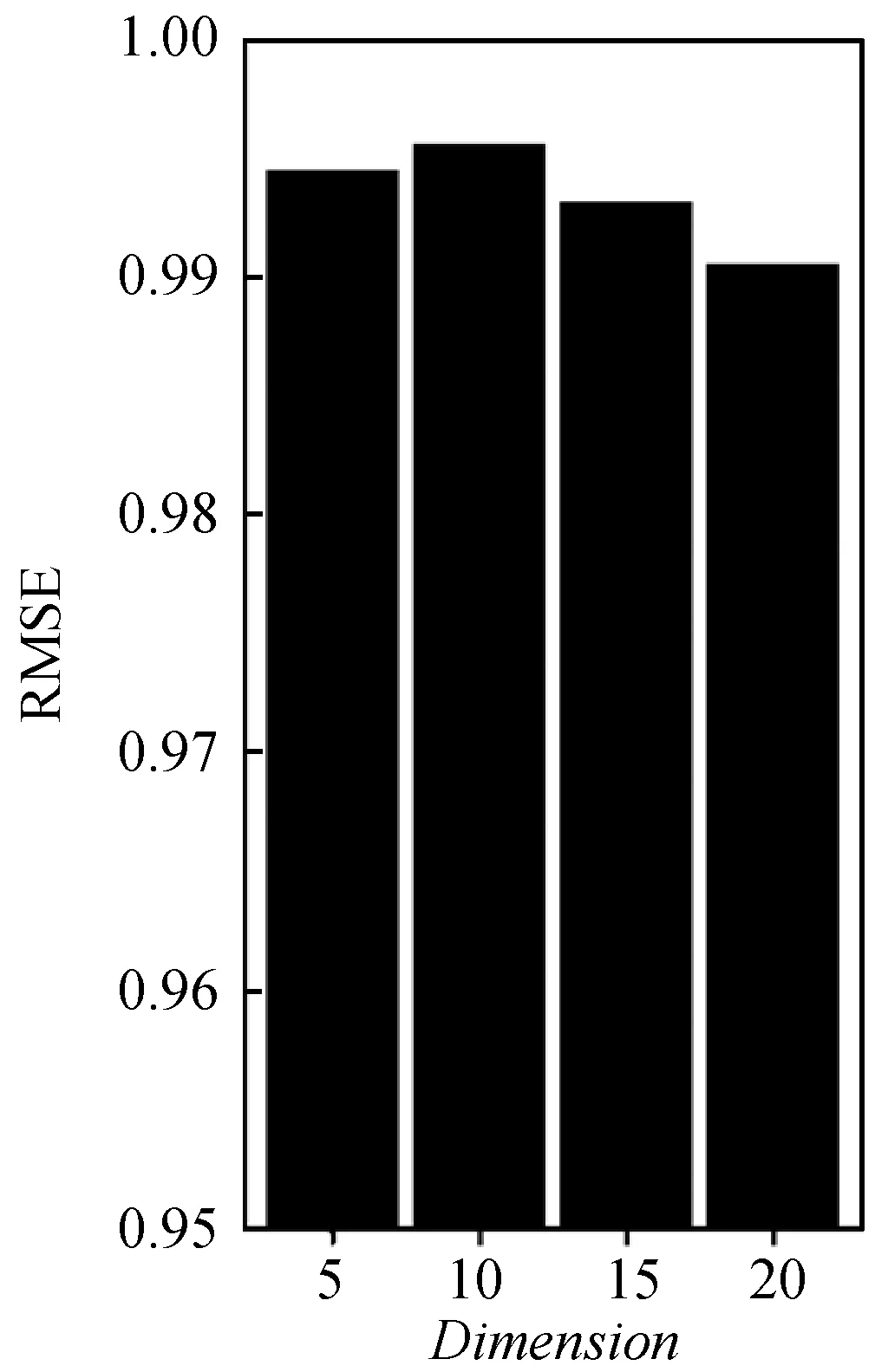
圖10 訓練集比例為20%下的特征維度比較結果

圖11 訓練集比例為50%下的特征維度比較結果

圖12 訓練集比例為80%下的特征維度比較結果
可以看出,在數據集的20%作為訓練集的時候潛在特征維度為15和20的情況下結果較好。在數據集的50%作為訓練集的時候潛在特征維度為5的情況下效果最好,其次是20,最后是10和15。在數據集的80%作為訓練集的時候,潛在特征維度為5的情況下效果最佳,然后依次是10、15、20。可以看出在這三種比例的訓練集中在潛在特征維度為5的情況下的效果較好。
本實驗共選取了4種方法與本文方法(CTPMF)進行對比,包括PMF、CPMF、NMF(Non-negative matrix factorization)、SVD[15]。實驗分別在潛在特征維度為5和10及訓練數據集比例為50%和80%的情況下對比CTPMF與其他算法的RMSE和MAE。
如表2和表3所示,CTPMF在原來的概率矩陣分解的基礎上增加了用戶聚類以及用戶的標簽數據。實驗結果表明,在50%和80%的數據作為訓練集的情況下CTPMF預測結果的RMSE、MAE優于其他推薦算法,而RMSE和MAE均隨訓練集比例的增加而減小,潛在特征維度為5時的實驗結果總體上優于潛在特征維度為10的實驗結果。

表2 特征維度為5的結果

表3 特征維度為10的結果
4 結 語
本文提出的融合標簽與組推薦技術的概率矩陣分解方法(CTPMF)通過用戶之間的評分相似度來對用戶進行聚類進而計算出用戶與每個組的相似度并增加物品的標簽數據進行概率矩陣分解,通過梯度下降逐漸降低誤差對個人評分進行預測。CTPMF改善了因數據稀疏導致的預測結果誤差無法進一步減小的問題,在不同比例的訓練數據集下的多個指標均優于實驗部分所提出的其他方法,進一步驗證了CTPMF的有效性。而在未來的研究工作當中仍需進行更深層次的探索,研究更優的推薦模型。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
核科學與工程(2015年4期)2015-09-26 11:59:03
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
