交通場景下基于深度強化學(xué)習(xí)的感知型路徑分配算法
2022-07-13 01:04:38曹歡
網(wǎng)絡(luò)安全與數(shù)據(jù)管理 2022年6期
曹 歡
(中國科學(xué)技術(shù)大學(xué) 信息科學(xué)技術(shù)學(xué)院,安徽 合肥230026)
0 引言
目前我國交通環(huán)境日益復(fù)雜,現(xiàn)有交通體系的服務(wù)能力難以滿足城市居民的出行期望,城市面臨日益嚴(yán)峻的交通管理挑戰(zhàn)。研究者們希望借助交通數(shù)字孿生技術(shù),通過數(shù)據(jù)驅(qū)動、精準(zhǔn)建模,實現(xiàn)交通的模擬、預(yù)測診斷和優(yōu)化[1]。然而在交通仿真模擬層次,現(xiàn)有的路徑分配模塊不能反映出現(xiàn)實交通的多變狀況。在人-車-路的核心體系中,天氣氣候、交通管制、突發(fā)事故等影響因子將時刻影響駕駛員的判斷以及路網(wǎng)的狀態(tài)[2]。
在當(dāng)前的交通數(shù)字孿生系統(tǒng)中,現(xiàn)有的路徑分配方法主要分為兩類,第一類為用于實現(xiàn)靜態(tài)全局路徑最優(yōu)的傳統(tǒng)算法,如經(jīng)典的蟻群算法、Floyd 算法、A-Star、粒子群算法、Dijkstra 及其改進算法等,本質(zhì)為基于圖論中重要的最短路徑問題所提出的各種方案,也即在一個加權(quán)有向圖中,按一定要求尋找一條權(quán)重總和最短的路徑[3]。如Xu[4]等基于二叉樹結(jié)構(gòu),通過雙向搜索方法加快搜索效率,作為A-Star 改進算法;Lee[5]等基于遺傳算法實現(xiàn)蟻群算法中的參數(shù)調(diào)節(jié)優(yōu)化。在路網(wǎng)信息發(fā)生變化時,該類算法難以做出及時反饋。如果需要滿足動態(tài)路徑規(guī)劃的需求,則需要施加額外的更新優(yōu)化和重規(guī)劃機制。第二類指的是通過機器學(xué)習(xí)、時空神經(jīng)網(wǎng)絡(luò)、強化學(xué)習(xí)等技術(shù)來實現(xiàn)路徑分配。這一類更加強調(diào)數(shù)據(jù)的搜集、分析和處理,通過提取海量歷史數(shù)據(jù)的價值信息,為解決路徑規(guī)劃問題提供了一個新的思路[6]。
本文的中心工作是研究了一種基于傳統(tǒng)路徑算法與深度強化學(xué)習(xí)的感知型路徑分配算法,首先通過改進版Dijkstra 算法為所有車輛分配初始路徑,路網(wǎng)中的車輛在不斷感知當(dāng)前位置、行駛軌跡以及目標(biāo)路網(wǎng)中各路段的車流等信息后,通過DDQN(Double DQN)將自動選擇是否重新進行全局的路徑規(guī)劃,實現(xiàn)路徑更新。與現(xiàn)有的經(jīng)典路徑規(guī)劃方法相比,本文提出的規(guī)劃方案填補了傳統(tǒng)模型在路況變化下的泛化性、拓展性不足,優(yōu)化了深度學(xué)習(xí)型方法的資源損耗,同時基于強化學(xué)習(xí)模型在長期收益方面的優(yōu)越性,本文模型更加滿足路徑分配模型對當(dāng)今城市路網(wǎng)交通出行的各種需求。
1 理論基礎(chǔ)
1.1 動態(tài)交通路網(wǎng)下的路徑分配問題
交通路網(wǎng)可以看作一個有著時序變化的有向圖網(wǎng)絡(luò),將其作為一段時間內(nèi)的狀態(tài)集合,即為:

其中,T 指的是時間周期,在規(guī)定的T 內(nèi),可以將動態(tài)交通路網(wǎng)拆成靜態(tài)的網(wǎng)絡(luò)即G。網(wǎng)絡(luò)G 由路段集合以及路網(wǎng)節(jié)點集合構(gòu)成:

其中,vi∈V 指的是路網(wǎng)節(jié)點,i 為節(jié)點編號,ej∈E指的是有向邊路,j 為邊路編號。可以看到,不同的時間周期T 下,路網(wǎng)也會動態(tài)變化得到隨時間更新的網(wǎng)絡(luò)G1,G2,…,Gi,表征不同T 下的路網(wǎng)狀態(tài)。同時,路徑L 正是由路網(wǎng)節(jié)點中的多個節(jié)點組成的聯(lián)通路徑構(gòu)成的,而重要的兩個節(jié)點——起終點(Origin-Destination,OD)同樣來源于集合V。因此,L 可視為(v0,v1,v2,…,vd)這一相鄰節(jié)點集[7]。
為衡量路徑選擇的優(yōu)劣,可通過定義道路代價函數(shù)的具體表達(dá)式來實現(xiàn),假設(shè)(va,vb)是取自路徑L 中的任一鄰接節(jié)點集,則該集對應(yīng)的代價函數(shù)為:
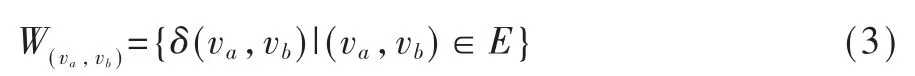
不同于常見的距離度量如歐式距離、馬氏距離,上式中的δ 是與時間相關(guān)的時序函數(shù)即δt,因此路徑L 經(jīng)過相鄰節(jié)點集(v0,v1,v2,…,vd)的總代價為:
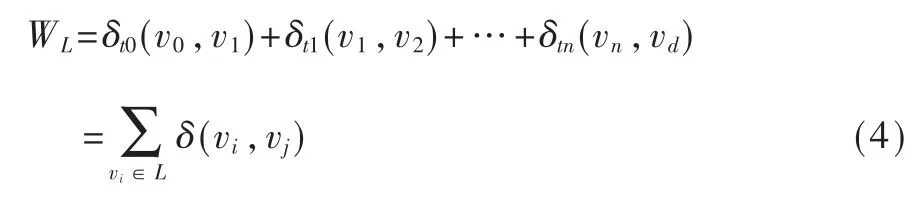
上式中的n 為時間步,因此動態(tài)路徑分配的問題可以理解為在路徑連續(xù)鄰接邊的集合上的代碼函數(shù)min(WL1,WL2,…,WLn),優(yōu)化目標(biāo)為總代價最小。進一步沿著時間步展開,即基于時間t 的OD 路徑分配優(yōu)化問題如下:
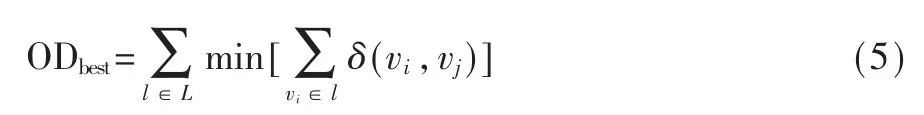
上式指明行駛個體在每一個特定周期T 中,都將以最小化代價函數(shù)的策略原則移動。其中的[·]表示T 時刻內(nèi)的出行路線,l 指的是路徑中的各相鄰路段[3]。
1.2 強化學(xué)習(xí)在動態(tài)路徑分配中的應(yīng)用
為提升動態(tài)路徑分配的拓展性和真實性,目前的一些動態(tài)模型大多以路網(wǎng)中的重要交叉口為決策點,不斷更新全局路徑分配結(jié)果,同時與車輛行駛線路進行比較,判定是否需要路徑更新。亦或是通過對路段設(shè)置閾值參數(shù)比如擁堵系數(shù)、排隊時長等,如果感知到車輛即將面臨嚴(yán)重?fù)矶拢到y(tǒng)將更新路線。以上的解決方案具備一定的感知性和動態(tài)拓展能力,但有著難以忽略的缺陷。前者由于大量冗余的復(fù)雜運算造成資源損耗,后者往往只依據(jù)相鄰路段的擁堵狀況來決策,未能考量到路網(wǎng)中路徑分配是一個需要最大化長期收益的問題[8]。
車輛在前進過程中,到達(dá)靠近路口前的一段區(qū)域時,就需要重新進行線路規(guī)劃,然后決定行駛方向。當(dāng)前時刻的車輛狀態(tài)以及選擇的工作決策會影響下一時刻行駛車輛的狀態(tài),故上述問題是一種較為典型的馬爾可夫決策過程(MDP),具備引入強化學(xué)習(xí)的潛在優(yōu)勢[9]:一方面可以提升全局路徑分配的長期收益,另一方面可以高效地開展分析和決策,實現(xiàn)動態(tài)路線更新。
考慮到本次任務(wù)較為離散的動作空間以及動態(tài)路網(wǎng)環(huán)境下狀態(tài)空間的連續(xù)性,本文最終采用了DQN 的優(yōu)化模型DDQN,后文會詳細(xì)介紹。
2 基于深度強化學(xué)習(xí)的路徑分配模型建模
2.1 模塊設(shè)計
圖1 展示的是整體的模塊設(shè)計,主要分為兩個階段:階段一是通過改進版Dijkstra 實現(xiàn)初始路徑分配決策,階段二則是在階段一的基礎(chǔ)上實現(xiàn)強化學(xué)習(xí)訓(xùn)練,完成決策更新。具體如下:
(1)路網(wǎng)靜態(tài)信息獲取模塊需要獲取相應(yīng)路網(wǎng)結(jié)構(gòu)信息、路網(wǎng)中路段信息以及連接關(guān)系等。
(2)路網(wǎng)動態(tài)信息獲取模塊需要獲取建模區(qū)域內(nèi)各路段的車流數(shù)據(jù),包括平均車流密度等。
(3)行駛車輛信息集成模塊的任務(wù)是確定車輛行駛中的具體信息,包括起終點路段ID、當(dāng)前路段ID 以及鄰接路段ID。
(4)State Space(狀態(tài)空間)模塊整合路網(wǎng)信息和車輛自身行駛信息,并對其進行數(shù)值化轉(zhuǎn)化,將編碼后的向量作為車輛狀態(tài)。
(5)Action Space(動作空間)模塊負(fù)責(zé)明確Agent(智能體,在本任務(wù)中指的是路網(wǎng)中的車輛)和環(huán)境交互過程中所有潛在行為的Action 集合。同時,在這一部分需要制定馬爾可夫決策過程中Agent 選用不同Action 的策略規(guī)則,較為常見的包括Q 值最大化策略以及貪心策略(ζ-greedy 或UCB)等。
(6)Reward 反饋模塊則主要定義了強化學(xué)習(xí)問題中的學(xué)習(xí)目標(biāo),在每個時間步,環(huán)境向Agent 發(fā)送一個稱為Reward 的反饋,進而實現(xiàn)訓(xùn)練。Agent 的唯一目標(biāo)是最大化其長期收到的總收益。
(7)Agent 設(shè)計/動態(tài)路徑分配模塊便是具體的學(xué)習(xí)、訓(xùn)練、預(yù)測部分。
2.2 算法設(shè)計
2.2.1 Dijkstra 算法及改進
區(qū)別于僅使用深度學(xué)習(xí)等技術(shù)的復(fù)雜動態(tài)分配算法,本文算法以Dijkstra 改良算法為基礎(chǔ)進行強化學(xué)習(xí)決策前的初始化路徑分配工作。
Dijkstra 算法基于貪心的思想,以當(dāng)前點為圓心不斷向四周擴展進行路徑搜索,搜索尋優(yōu)過程沒有考量目標(biāo)點的位置以及方向,因此在這一尋優(yōu)過程中所有點被搜索的概率一致。而交通路網(wǎng)中,往往會有起終點過遠(yuǎn)、可選點眾多這一問題,因此,將Dijkstra 直接用于動態(tài)交通條件下的路徑分配問題時,會出現(xiàn)效率低下、資源損耗嚴(yán)重的挑戰(zhàn)。這種計算延遲也同樣不符合實時性的要求。
因此本文希望提升Dijkstra 算法在路徑分配方面的運算效率,減少計算時長。Dijkstra 算法時間復(fù)雜度是O(n2),以城市交通路網(wǎng)為例,將其視為若干帶權(quán)有向圖,其中大多數(shù)城市交叉口數(shù)目遠(yuǎn)大于1 000,在此數(shù)量級上,資源損耗時長將呈現(xiàn)指數(shù)增長,產(chǎn)生大量冗余運算。
在此本文設(shè)定優(yōu)先目標(biāo)區(qū)域,在優(yōu)先區(qū)域內(nèi)路徑尋優(yōu),假設(shè)起終點a,b 坐標(biāo)依次為(x0,y0),(x1,y1),以a,b 為圓心繪制圓形區(qū)域,再對上述兩圓形區(qū)域分別做外切線,形成優(yōu)先搜索區(qū)域矩形,如圖2 所示。如未能搜索到最優(yōu)結(jié)果,將在此基礎(chǔ)上拓展圓形區(qū)域半徑,在新的優(yōu)先區(qū)域上實現(xiàn)搜索。

圖1 基于深度強化學(xué)習(xí)的路徑分配模塊設(shè)計
2.2.2 狀態(tài)空間
在基于DDQN 的模型中,智能體進行判斷的主要依據(jù)為車輛自身信息和感知區(qū)域內(nèi)路網(wǎng)中各路段的車輛密度數(shù)據(jù),在對單個路段進行編號后,需要通過信息整合實現(xiàn)狀態(tài)描述。本文最終選取一維向量進行狀態(tài)s 的表達(dá),這種表示方式有利于提升模型訓(xùn)練效率和表示的準(zhǔn)確性。
Agent 在t 時刻的狀態(tài)定義為:

其中cart表示前面提到的車輛當(dāng)前時刻t 的自身信息變量,包括出發(fā)點、當(dāng)前點、當(dāng)前路線預(yù)計的下一到達(dá)點以及目標(biāo)點對應(yīng)的路段ID,即:
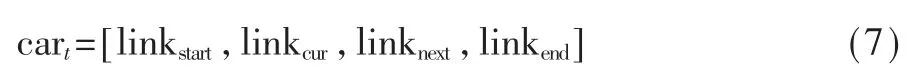
同時,roadt指的是路網(wǎng)中各路段的交通流密度數(shù)據(jù)變量,表達(dá)式如下:

其中n 為路段總數(shù)目,ρi表示第i 條路段對應(yīng)的平均車流密度。在上述基礎(chǔ)上繼續(xù)開展動作空間設(shè)計。
2.2.3 動作空間
鑒于本文中的DDQN 模型是在改良版本的Dijkstra上進行路徑優(yōu)化,即車輛依據(jù)當(dāng)前狀態(tài)判定是否需要更新路徑分配結(jié)果,因此這里的動作空間得以極大簡化,可以定義為:A=[a0,a1]。a0表示無需進行路徑更新,當(dāng)前路線即為最優(yōu);a1表示當(dāng)前路線需要優(yōu)化,需重新調(diào)用路徑分配模型實現(xiàn)更新。
值得強調(diào)的是,為了防止系統(tǒng)回溯這一冗余操作,減少歷史選擇路線對現(xiàn)有模型的噪聲干擾,必須記錄歷史途徑信息,防止Agent 趨于過度判斷。同時考慮到強化學(xué)習(xí)的Exploration & Exploitation(探索與利用機制),模型選用的動作選擇策略如下:
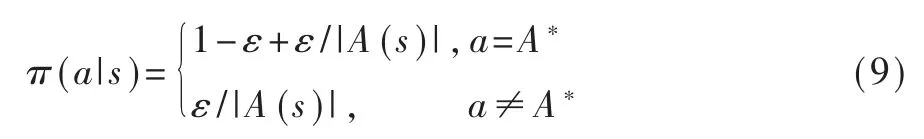
該策略既能以較大概率選擇Q 值大的動作,也保留了較小概率的探索能力。
2.2.4 獎勵函數(shù)
強化學(xué)習(xí)的標(biāo)準(zhǔn)交互過程如下:每個時刻,智能體根據(jù)其策略(Policy),在當(dāng)前所處狀態(tài)(State)選擇一個動作(Action),環(huán)境(Environment)對這些動作做出響應(yīng),轉(zhuǎn)移到新狀態(tài),同時產(chǎn)生一個獎勵信號(Reward),這通常是一個數(shù)值,獎勵的折扣累加和稱為收益/回報(Return),這是智能體在動作選擇過程中想要最大化的目標(biāo)[10]。
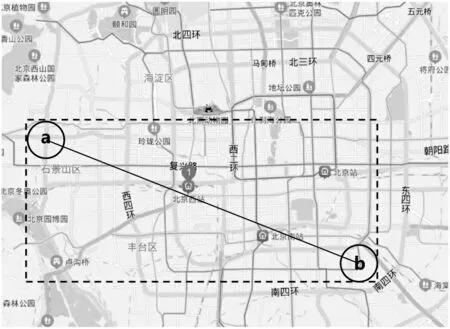
圖2 優(yōu)先搜索區(qū)域示意圖
本模型的優(yōu)化目標(biāo)著眼于最小化車輛到達(dá)目標(biāo)點的行駛總時長。Agent 采取動作后,狀態(tài)開始轉(zhuǎn)移,即在當(dāng)前決策點/區(qū)域進行路徑重分配判斷后,將花費一定時間到達(dá)下一個決策點/區(qū)域,因此Agent的行駛總時長可以視為每相鄰決策點的時間間隔總和,再加上額外的路口等待時長、擁堵排隊時長等。因此定義獎勵函數(shù)為:

其中ti為從第i-1 個決策點到達(dá)第i 個決策點的時間間隔,tdelay為對應(yīng)時期的各種等待時長,琢為自定義等待權(quán)重系數(shù),可根據(jù)實際需要調(diào)節(jié)。該獎勵函數(shù)能夠保證模型會趨于行駛時間短的鄰接路線,獲得短期激勵。通過取相反數(shù)也能夠綜合考量等待時長對決策的影響,符合長期收益原則。
2.2.5 DDQN 訓(xùn)練模型
DDQN 是Double DQN 的縮寫,是在DQN 的基礎(chǔ)上改進而來的。DDQN 的模型結(jié)構(gòu)基本與DQN 的模型結(jié)構(gòu)一樣,唯一不同的就是它們的目標(biāo)函數(shù):
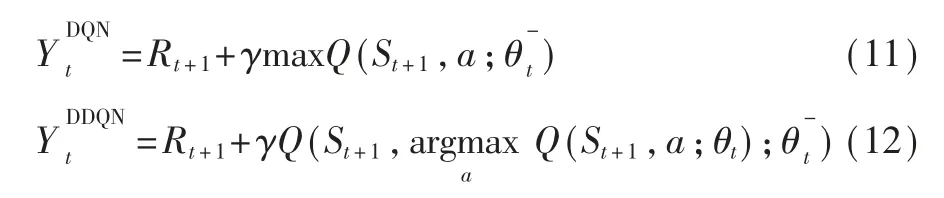
DDQN 與DQN 結(jié)構(gòu)類似,其模型結(jié)構(gòu)如圖3 所示。DDQN 包含兩個結(jié)構(gòu)完全相同但是參數(shù)存在差異的網(wǎng)絡(luò),預(yù)測Q 估計的主網(wǎng)絡(luò)MainNet 使用的是最新的參數(shù),而預(yù)測Q 現(xiàn)實的目標(biāo)網(wǎng)絡(luò)TargetNet 使用的是較早前的參數(shù)。主網(wǎng)絡(luò)MainNet 的輸出Q(s,a;茲i)用來評估當(dāng)前狀態(tài)-動作對的值函數(shù)。目標(biāo)網(wǎng)絡(luò)TargetNet 的輸出Q(s,a;)可以用來求解目標(biāo)Q值。當(dāng)智能體對環(huán)境采取動作a 時就可以根據(jù)上述式 (12) 計算出Q 值并根據(jù)損失函數(shù)更新主網(wǎng)絡(luò)MainNet 的參數(shù),每經(jīng)過一定次數(shù)的迭代,將主網(wǎng)絡(luò)MainNet 的參數(shù)復(fù)制給目標(biāo)網(wǎng)絡(luò)TargetNet。這樣就完成了一次學(xué)習(xí)過程[9]。
基于模型狀態(tài)空間設(shè)計,本文通過一維多元向量描述智能體狀態(tài),同時采用了多層感知機(Multilayer Perceptron,MLP)作為Q_value 網(wǎng)絡(luò),MLP 中隱藏層數(shù)目為3,每一層包含2×(N+3)個神經(jīng)元。最終的訓(xùn)練模型包括輸入層、3 層全連接隱藏層以及輸出層等結(jié)構(gòu)。基于圖3 所示神經(jīng)網(wǎng)絡(luò)模型結(jié)構(gòu)進行訓(xùn)練,Loss 函數(shù)見式(12),模型可輸出兩個Q 值。當(dāng)前值網(wǎng)絡(luò)用于更新現(xiàn)有參數(shù),再經(jīng)過時間間隔N 后將參數(shù)復(fù)制給目標(biāo)值網(wǎng)絡(luò)進行參數(shù)更新。
3 實驗結(jié)果及分析
3.1 仿真場景
從開源網(wǎng)站Open Street Map 官網(wǎng)下載北京市部分路網(wǎng),包括13 020 個路段以及9 873 個節(jié)點。在ArcGIS 軟件中對獲取的osm 地圖文件進行讀取修改,鑒于直接下載的路網(wǎng)文件存在大量低質(zhì)量路段,因此將其編碼成可讀取的矢量地圖文件(.shp),然后進行數(shù)據(jù)清洗和分析,最終的路網(wǎng)呈現(xiàn)效果如圖4 所示。同時,為進一步進行實驗,提取了所在區(qū)域的所有路段編號ID、長度位置信息以及對應(yīng)拓?fù)潢P(guān)系等。此外另采集了一天內(nèi)該區(qū)域近3 000 輛浮動車的行駛數(shù)據(jù)。實驗環(huán)境為Intel?I7-8750H CPU@2.20 GHz,64 GB 內(nèi)存,Windows10 64 位操作系統(tǒng)。

圖4 北京市路網(wǎng)文件
3.2 實驗方案
將本文提出的路徑動態(tài)分配方法分別與Dijkstra、A*、動態(tài)A*算法進行實驗對比。其中DDQN的訓(xùn)練參數(shù)如表1 所示。
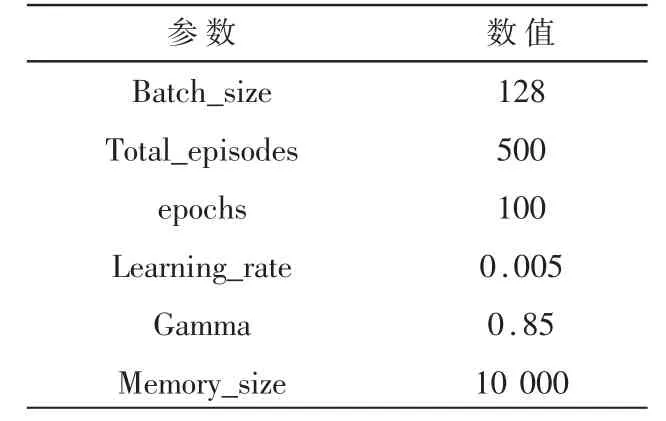
表1 DDQN 訓(xùn)練參數(shù)
為了捕捉路網(wǎng)動態(tài)信息對路徑規(guī)劃造成的影響,本文針對北京市路網(wǎng)開展兩個時間點下的對比試驗,選取的時間點依次為8:00 以及13:00。實驗首先確定待觀察的OD 點對,接著針對OD 點對分別在兩個時間點上開展路徑請求,各模型平均訪問遍歷節(jié)點數(shù)目如表2 所示。

表2 OD 點對訪問節(jié)點數(shù)
從表2 可以看出,在算法搜索效率上,傳統(tǒng)Dijkstra 算法效率最低,依據(jù)貪心策略展開搜索的Dijkstra 由于其復(fù)雜度為o(n2),導(dǎo)致需要遍歷的節(jié)點數(shù)最多,達(dá)到4 728 和4 435。A*以及動態(tài)A*算法相較于傳統(tǒng)的Dijkstra 遍歷節(jié)點數(shù)目分別下降32%以及61% ,這是基于這兩個算法啟發(fā)式的搜索策略[12]。本文模型的遍歷訪問節(jié)點數(shù)分別為1 430和1 230,相較最差的Dijkstra 分別有70%和72%的明顯提升,均為最優(yōu),符合實驗預(yù)期。另外由于8:00處于上班高峰期,因此擁堵現(xiàn)象會加重,模型感知到的信息更加復(fù)雜,會趨于做出更多嘗試性的路徑分配。
為進一步驗證模型中深度強化學(xué)習(xí)在路徑分配性能上的作用,實驗綜合納入行駛時間、行駛距離以及延遲等待時間(車速小于1 m/s 的時長)作為具體的指標(biāo)因子[13]。在這里本文額外加入了依據(jù)分層理論的CH 路徑算法,指標(biāo)記錄如表3 所示。
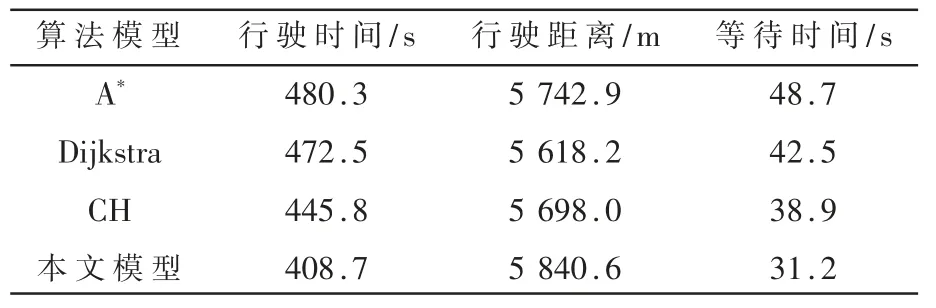
表3 性能對比表
從表3 可知,本文提出的結(jié)合深度強化學(xué)習(xí)和傳統(tǒng)靜態(tài)路徑分配算法的優(yōu)化模型在行駛耗費時間以及等待延誤時間上表現(xiàn)突出,其中行駛時間相較A*縮短14.91%,等待時間更是較于A*大幅減少35.93%。值得注意的是,在行駛距離這一指標(biāo)上,本文模型表現(xiàn)略差于其他對比模型,這是由于在強化學(xué)習(xí)的獎勵設(shè)計階段,延誤等待時間權(quán)重較高的影響,這也從另外一方面驗證了本文模型出色的動態(tài)路徑分配性能和深度強化學(xué)習(xí)在長期收益方面的優(yōu)越性[14]。
4 結(jié)論
針對復(fù)雜多變的動態(tài)交通路網(wǎng),本文提出了一種結(jié)合傳統(tǒng)路徑算法與深度強化學(xué)習(xí)的感知型路徑分配算法,模型依據(jù)改進的靜態(tài)路徑分配算法生成路徑分配的初始化結(jié)果,之后Agent 感知路網(wǎng)變化,包括當(dāng)前位置、行駛軌跡以及目標(biāo)路網(wǎng)中各路段的車流等信息后,通過DDQN 網(wǎng)絡(luò)模型進行動作選擇,完成狀態(tài)轉(zhuǎn)移,實現(xiàn)路徑分配再更新。
經(jīng)過大量仿真實驗表明,相較于經(jīng)典的路徑分配模型,本文模型無論是在搜索尋優(yōu)效率上,還是在最終的性能指標(biāo)(行駛時間以及等待時間)上都表現(xiàn)出色,這一方面是由于對動態(tài)信息的搜集和感知學(xué)習(xí),另一方面是基于深度強化學(xué)習(xí)獨有的提升系統(tǒng)長期收益能力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
鐵道通信信號(2020年9期)2020-02-06 09:15:22
數(shù)學(xué)大王·趣味邏輯(2019年5期)2019-06-13 20:27:43
小學(xué)科學(xué)(學(xué)生版)(2019年5期)2019-05-21 01:00:18
經(jīng)濟技術(shù)協(xié)作信息(2018年30期)2018-11-22 06:20:24
中華手工(2017年2期)2017-06-06 23:00:31
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
中外會展(2014年4期)2014-11-27 07:46:46
