地鐵運營崗位應(yīng)急處置培訓(xùn)的語音識別研究
2022-07-13 01:04:46錢雪軍
網(wǎng)絡(luò)安全與數(shù)據(jù)管理 2022年6期
周 楊,錢雪軍
(同濟(jì)大學(xué) 電子與信息工程學(xué)院,上海 201804)
0 引言
地鐵行車事故和突發(fā)事件嚴(yán)重影響了地鐵的正常運營并威脅到了人民群眾的生命財產(chǎn)安全[1]。對于相應(yīng)的應(yīng)急預(yù)案而言,應(yīng)急預(yù)案演練的效果直接決定了應(yīng)急響應(yīng)的速度和應(yīng)急處置實施的有效性,其中應(yīng)急處置培訓(xùn)是應(yīng)急預(yù)案演練的重點。
目前的聯(lián)合培訓(xùn)系統(tǒng)需要所有培訓(xùn)崗位均為在崗狀態(tài),無法實現(xiàn)在聯(lián)合培訓(xùn)中的單崗位培訓(xùn)功能。因此在對各個崗位進(jìn)行應(yīng)急處置培訓(xùn)過程中需要模擬各個崗位之間的語音交互,實現(xiàn)單個崗位獨立培訓(xùn)時的智能互動,同時實現(xiàn)對培訓(xùn)過程的記錄與智能評價。語音識別是語音交互的基礎(chǔ)。目前,國內(nèi)外語音識別技術(shù)已經(jīng)趨于成熟,走向真正實用化[2],在日常對話等常見領(lǐng)域已達(dá)到實用要求,但是在地鐵等專業(yè)應(yīng)用領(lǐng)域的識別效果不佳[3]。
本文基于DFCNN-CTC 框架提出新的語音識別聲學(xué)模型結(jié)構(gòu),以實現(xiàn)對應(yīng)急處置培訓(xùn)術(shù)語的高精度識別。實驗表明,該語音識別模型可應(yīng)用于應(yīng)急處置培訓(xùn)系統(tǒng)中。
1 應(yīng)急處置培訓(xùn)術(shù)語
本研究使用上海軌道交通培訓(xùn)中心列車故障救援場景處置培訓(xùn)方案的培訓(xùn)術(shù)語,記錄列車故障救援場景下運營調(diào)度員、車站值班員以及列車司機的語音對話用語。對話內(nèi)容涵蓋了地鐵列車到達(dá)及出發(fā)的技術(shù)作業(yè)、線路封鎖、客運管理、技術(shù)設(shè)備的檢查排故、各部門協(xié)調(diào)等環(huán)節(jié)。
1.1 培訓(xùn)術(shù)語研究
如表1 所示,應(yīng)急處置培訓(xùn)用語有如下的特征:(1)培訓(xùn)用語中同時存在中文、英文、標(biāo)點符號和數(shù)字。將數(shù)字和英文字母用漢語文本表示,發(fā)音為普通話,并去除相關(guān)標(biāo)點符號。(2)車務(wù)人員對話用語按照標(biāo)準(zhǔn)多為長語句(30 至40 字),對過長的語句在不影響上下文的情況下進(jìn)行切分識別。(3)培訓(xùn)用語中含有鐵路專有名詞,例如:濟(jì)陽路、上南路、大渡河路、清客、入段線、聯(lián)控、對標(biāo)停車等。

表1 應(yīng)急處置培訓(xùn)通話文本(部分)
對比科大訊飛、百度、Siri、Cortana等國內(nèi)外公司所研發(fā)的語音識別軟件,在對鐵路車務(wù)專用術(shù)語的識別率中,Cortana 的綜合得分最高,科大訊飛的識別率最穩(wěn)定,但是準(zhǔn)確率僅為50%[4]。目前,這些識別軟件需要在聯(lián)網(wǎng)環(huán)境下才能使用,無法滿足在培訓(xùn)場景下離線局域網(wǎng)環(huán)境中使用的需求。本文針對上述問題收集專業(yè)術(shù)語語料,基于神經(jīng)網(wǎng)絡(luò)構(gòu)建和訓(xùn)練語音識別模型,提高對培訓(xùn)術(shù)語的識別率。
1.2 語料收集
為了提高模型的泛化能力,本文使用了三個公開的中文語音數(shù)據(jù)集以及一個自制的培訓(xùn)術(shù)語數(shù)據(jù)集。三個公開中文語音數(shù)據(jù)集分別是:清華大學(xué)語言與語音技術(shù)中心出版的THCHS-30,希爾貝殼公司開源的AI-SHELL-1 以及北京沖浪科技公司開源的ST-SMDS 中文語音數(shù)據(jù)集。語音的格式統(tǒng)一為采樣頻率16 kHz,16 bit 位深,單通道,總時長達(dá)到330 h,基本信息數(shù)據(jù)如表2 所示。對地鐵應(yīng)急處置培訓(xùn)用語進(jìn)行收集后,組織10 人進(jìn)行語料錄制,共錄制700 條語音,其中500 條作為訓(xùn)練集,200 條作為測試集。
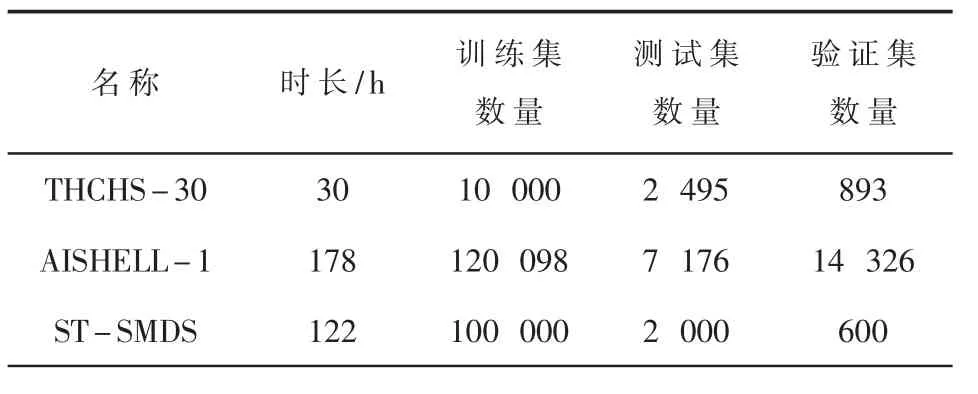
表2 中文語音數(shù)據(jù)集
2 語音識別系統(tǒng)結(jié)構(gòu)
首先,將音頻信號經(jīng)過預(yù)處理轉(zhuǎn)化為語譜圖進(jìn)行特征提取,使用聲調(diào)和韻母組成的1 427 種拼音作為聲學(xué)模型的建模單元,將聲調(diào)標(biāo)注為數(shù)字1~5,數(shù)字5 表示輕聲,例如“我”(wǒ)表示為wo3,對音頻信號所對應(yīng)的拼音序列進(jìn)行處理,生成拼音Index 序列。然后,將語譜圖和拼音Index 序列作為訓(xùn)練聲學(xué)模型的輸入數(shù)據(jù),經(jīng)過構(gòu)建的深層卷積神經(jīng)網(wǎng)絡(luò)提取語音特征,由全連接層進(jìn)一步提取信息,通過Softmax 層分類輸出概率矩陣。最后,由CTC 解碼算法使語音與標(biāo)簽序列對齊,將狀態(tài)概率解碼為標(biāo)簽序列輸出,采用Adam 優(yōu)化器進(jìn)行模型參數(shù)優(yōu)化,完成對聲學(xué)模型的訓(xùn)練。
使用統(tǒng)計學(xué)方法收集文本語料并構(gòu)建N-Gram語言模型,將聲學(xué)模型輸出的拼音序列通過語言模型計算輸出文本序列,實現(xiàn)拼音-漢字轉(zhuǎn)換,最后經(jīng)過模板匹配得出預(yù)測的漢字結(jié)果。語音識別結(jié)構(gòu)如圖1 所示。
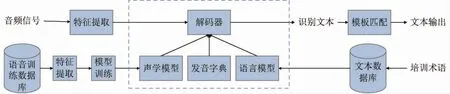
圖 1 語音識別系統(tǒng)結(jié)構(gòu)
2.1 特征提取
目前常用的聲學(xué)特征包括線性預(yù)測系數(shù)(LPC)、 濾 波 器 組 特 征(FBank)、 語 譜 圖 特 征 以及梅爾頻率倒譜系數(shù) (MFCC)。相較于MFCC,語譜圖不經(jīng)過人工設(shè)計的濾波器進(jìn)行特征提取,從而保留了更多信息。生成語譜圖的過程主要分為預(yù)加重、 分幀加窗、 快速傅里葉變換(FFT)和特征提取四個步驟。
采用一階高通濾波器,對語音信號的高頻部分進(jìn)行加重補償,使得頻譜分布變得更平緩,提高語音信號信噪比[5]。將長時語音劃分為幀信號,采用漢明窗降低旁瓣強度,對每一個語音幀進(jìn)一步提取特征。采用FFT 提取分幀加窗處理后語音信號的頻譜,將頻譜取模得到幅度譜,然后取對數(shù)得到對數(shù)幅度譜[6]。對得到的對數(shù)幅度譜進(jìn)行標(biāo)準(zhǔn)歸一化,使不同頻率之間的特征在數(shù)值上更有比較性,來提高分類器的準(zhǔn)確性。最終將處理后的對數(shù)幅度譜拼接成時間序列的形式,得到特征序列語譜圖。對訓(xùn)練集中一條語音數(shù)據(jù)進(jìn)行特征提取,得到的語譜圖特征如圖2 所示。
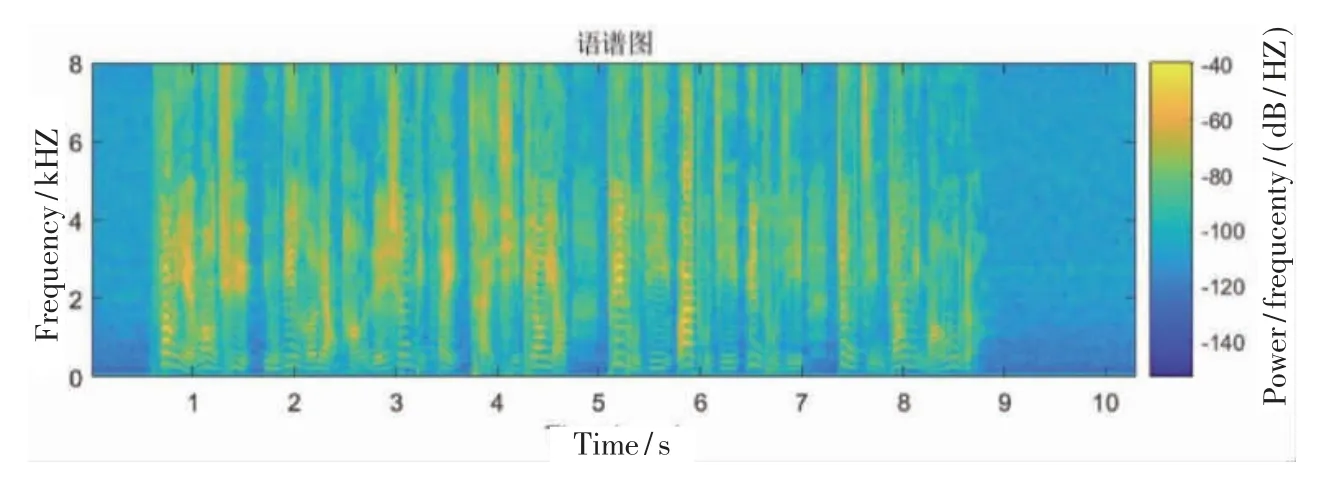
圖2 語譜圖特征
2.2 DFCNN-CTC 聲學(xué)模型
經(jīng)過對語音數(shù)據(jù)預(yù)處理和特征提取后,得到特征序列的橫軸為語音的幀數(shù),設(shè)置最大幀數(shù)限制為1 600 幀,約等于采樣16 s。特征序列的縱軸為每一幀的特征矩陣,為200 維。輸入特征序列進(jìn)入聲學(xué)模型,輸出為對應(yīng)1 427 個拼音和1 個空白單元的取值概率。
2.2.1 模型搭建
聲學(xué)模型使用DFCNN 架構(gòu),采用卷積神經(jīng)網(wǎng)絡(luò)對輸入的二維語譜圖提取特征參數(shù)。模型中間部分采用多層卷積單元結(jié)構(gòu),每一個單元結(jié)構(gòu)由卷積層、激活函數(shù)、批歸一化層、最大池化層交錯分布組成。聲學(xué)模型結(jié)構(gòu)圖如圖3 所示。
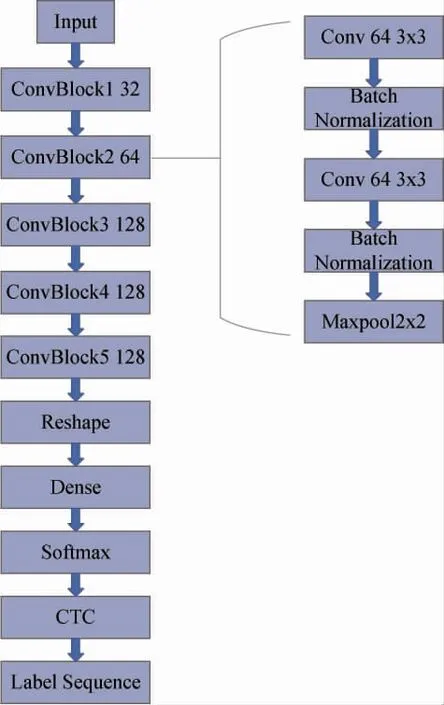
圖 3 聲學(xué)模型結(jié)構(gòu)圖
本文的聲學(xué)模型使用了5 個卷積層模塊,每一個卷積層模塊由2 層卷積層、2 層批歸一化層和1層最大池化層組成[7]。每個模塊中的卷積層分別設(shè)置有32、64、128、128、128 個卷積通道和大小為3×3 的卷積核。前3 個模塊的最大池化層窗口大小設(shè)置為2,后2 個模塊的最大池化層窗口大小設(shè)置為1,進(jìn)行下采樣。padding 均設(shè)置為same,激活函數(shù)選用ReLU。使用兩層全連接層,最后一層的建模單元個數(shù)為1 428,對應(yīng)1 427 個拼音并加上1個空白單元。經(jīng)過Softmax 輸出維度為200×1427的分類概率矩陣,使用CTC 損失函數(shù)對模型進(jìn)行訓(xùn)練。最后通過CTC 解碼算法輸出標(biāo)簽序列( 即拼音Index 序列),在發(fā)音字典中查找得出對應(yīng)的拼音序列。
1.3.1 農(nóng)村高齡空巢老人問題突出加大居家養(yǎng)老需求 隨著城鎮(zhèn)化進(jìn)程的推進(jìn),人口流動頻率不斷提高,導(dǎo)致了農(nóng)村地區(qū)的留守老人增多。據(jù)統(tǒng)計,2016年六合區(qū)祖孫二代留守老人5 216人,其中城鎮(zhèn)460人,農(nóng)村4 756人,農(nóng)村祖孫二代留守老人是城鎮(zhèn)的10倍之多。據(jù)六合區(qū)民政局有關(guān)調(diào)查顯示,“我國農(nóng)村空巢老人生活中存在困難的項目包括:去醫(yī)院看病占 34.3%、買菜占 12.5%、購買生活用品占 18.7%、洗衣服占 17.1%、打掃衛(wèi)生占 13.9%。”受制于種種現(xiàn)實因素,無人照料的農(nóng)村留守老人還要承擔(dān)繁重的田間勞動并養(yǎng)育子孫,形成了較大的養(yǎng)老服務(wù)需求,推動農(nóng)村居家養(yǎng)老服務(wù)的發(fā)展。
2.2.2 模型訓(xùn)練
使用公開中文語音數(shù)據(jù)集作為本模型的訓(xùn)練集,通過測試集和驗證集來調(diào)整學(xué)習(xí)率與驗證精度,并使用自制培訓(xùn)術(shù)語訓(xùn)練集對模型進(jìn)行微調(diào)。使用Adam 優(yōu)化器對模型進(jìn)行訓(xùn)練,bacth_size 為8,每一個epoch 訓(xùn)練量為5 000,進(jìn)行1 000 次迭代,初始的學(xué)習(xí)率為3×10-4,在300 次迭代后減少到1×10-4,在700 次迭代后減少到3×10-5。
2.3 DFCNN-CTC 聲學(xué)模型
語言模型在語音識別系統(tǒng)中的作用是將聲學(xué)模型輸出的拼音序列轉(zhuǎn)換成文字序列,得到具有漢語規(guī)律和符合人說話方式的語句。拼音與漢字具有一對多的關(guān)系,在發(fā)音字典的構(gòu)建過程中需要考慮多音字、諧音字以及生僻字等問題。
2.3.1 統(tǒng)計語言模型
本文使用N-Gram 統(tǒng)計語言模型,通過概率統(tǒng)計的方式來表示句子中每個詞語出現(xiàn)的可能。一個句子的概率由所有詞概率相乘得出,通過概率大小判斷句子是否合理。基于馬爾科夫假設(shè),一個詞出現(xiàn)的概率只依賴于前面出現(xiàn)的多個詞。本文采用二元模型對收集的培訓(xùn)語料進(jìn)行詞頻統(tǒng)計,由大數(shù)定律可知,詞頻約等于概率。
因為存在一音多字的情況,通過拼音序列找尋最匹配的語句的操作類似于搜尋最短路徑的行為。維特比算法是一種動態(tài)規(guī)劃求解概率最大路徑的算法,可以用來實現(xiàn)拼音序列轉(zhuǎn)換到文本的解碼[8]。求解最優(yōu)路徑時,對句子設(shè)置初始概率1.0,每一步取一個拼音,將其在發(fā)音字典中對應(yīng)的字接在已拼出的字序列后,將原序列概率與當(dāng)前字出現(xiàn)概率相乘得出拼湊后的概率,類似于路徑的延伸。如果路徑概率過低,低于設(shè)置的閾值,則將該路徑剔除。本文設(shè)置每一步的字閾值為0.001,在第n 步時,路徑閾值為0.001n。這樣可以剔除不常見的詞組合,大大降低計算量。最后對到達(dá)終點的所有路徑通過概率進(jìn)行排序,取概率最大路徑對應(yīng)的句子輸出。
2.3.2 術(shù)語匹配
最短編輯距離為字符串所經(jīng)過的最少增刪改操作數(shù),該距離越小,表示兩個字符串的相似度越高。本文將所收集的培訓(xùn)語料制作成術(shù)語匹配庫,將語言模型輸出的語句與庫中語句進(jìn)行匹配,找出最短編輯距離最小的語句,即為相似度最高的培訓(xùn)語句。
3 模型測試與分析
對語音識別模型的測試主要針對聲學(xué)模型進(jìn)行測試,測試可分為兩部分:一是采用公開中文數(shù)據(jù)集的測試集進(jìn)行,并與其他模型進(jìn)行對比;二是采用自制培訓(xùn)術(shù)語測試集進(jìn)行,對比使用自制數(shù)據(jù)集訓(xùn)練后模型的識別精度,取最好表現(xiàn)。測試結(jié)果如表3 所示。
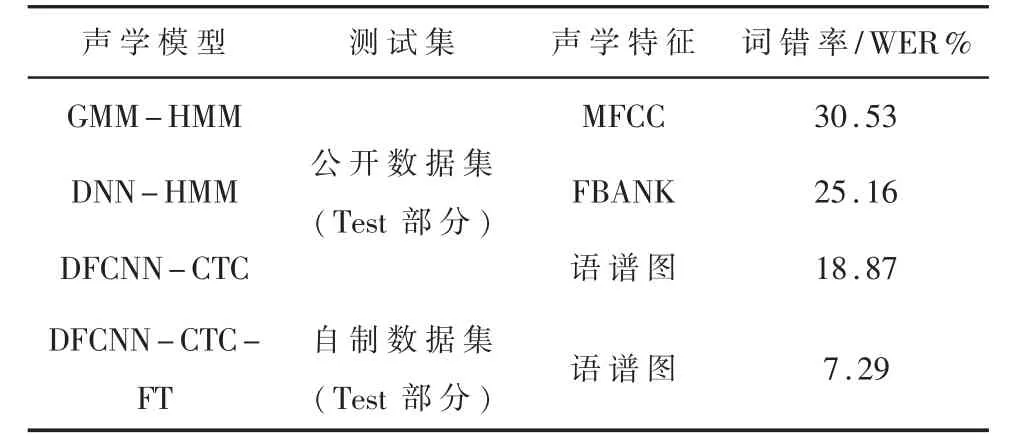
表3 聲學(xué)模型測試結(jié)果對比
由表3 可知,基于統(tǒng)計學(xué)原理的GMM-HMM 模型和DNN-HMM 模型詞錯率都較高,本文所提出的聲學(xué)模型利用提取的語譜圖特征進(jìn)行訓(xùn)練,在公開數(shù)據(jù)集上的詞錯率相較于前兩個分別降低了11.66%和6.29%。對模型進(jìn)行微調(diào) (Fine turning)后,測試集上的詞錯率下降了11.58%,明顯提高了對地鐵培訓(xùn)專業(yè)術(shù)語的識別率。
通過語言模型將聲學(xué)模型識別后得出的拼音序列轉(zhuǎn)化為文字序列,經(jīng)過模板匹配得出匹配度最高的培訓(xùn)語句。最終識別效果如表4 所示。
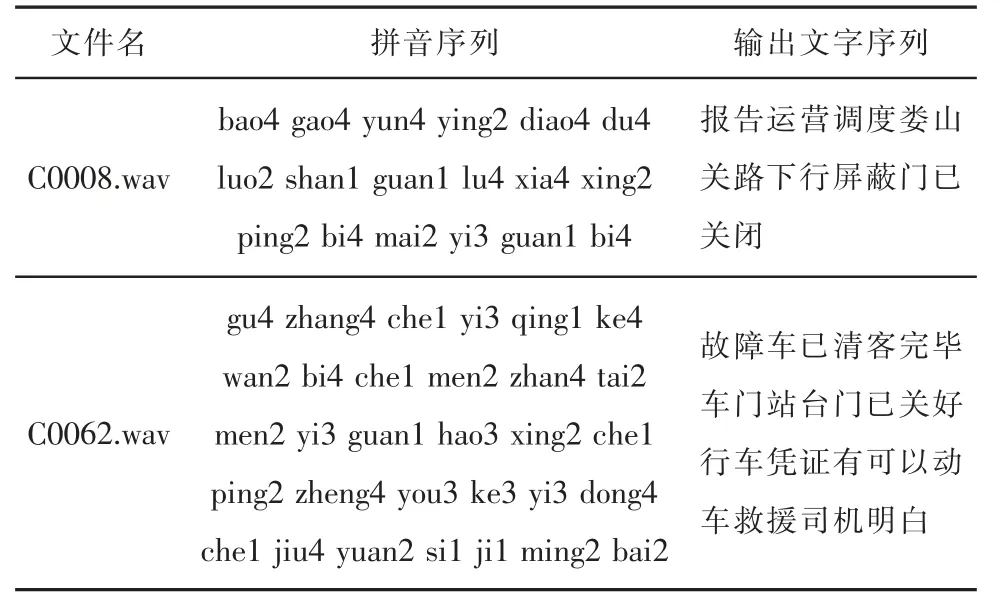
表4 語音識別效果
4 結(jié)論
本文提出的針對地鐵運營崗位應(yīng)急處置培訓(xùn)術(shù)語的語音識別方法,基于深度學(xué)習(xí)和DFCNN 神經(jīng)網(wǎng)絡(luò),實現(xiàn)了離線語音識別功能。其相較于傳統(tǒng)的語音識別方法和市面上的其他語音識別應(yīng)用,提高了對應(yīng)急處置培訓(xùn)術(shù)語的識別率。本語音識別方法可以用于實現(xiàn)培訓(xùn)系統(tǒng)智能評價功能和研究語音交互。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中小學(xué)教師培訓(xùn)(2022年10期)2022-10-15 02:16:04
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
辦公室業(yè)務(wù)(2020年18期)2020-09-29 12:15:58
家庭影院技術(shù)(2020年6期)2020-07-27 01:37:42
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
勞動保護(hù)(2019年7期)2019-08-27 00:41:26
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
體育師友(2011年5期)2011-03-20 15:29:53
