面向情緒識別中腦電特征分布不均勻的雙策略訓練方法
2022-07-20 08:18:10賈巧妹胡景釗鄭佳賓張麗麗趙晨宇吳東亞
西北大學學報(自然科學版) 2022年4期
賈巧妹,胡景釗,鄭佳賓,王 晨,張麗麗,趙晨宇,吳東亞,馮 筠, 2
(1.西北大學 信息科學與技術學院,陜西 西安 710127;2.新型網絡智能信息服務國家地方聯合工程研究中心,陜西 西安 710127)
情緒是人類生活中很重要的一部分,在人機交互領域,人們希望計算機有一定的能力去識別人類的情緒,理解并幫助他們[1]。近年來,研究人員在情緒識別技術上進行了廣泛的研究[2],目前的情緒識別主要是通過對語音[3]、面部表情[4]、生理信號[5]和姿態[6]等信息分析并識別主體的情感。但由于人們可能會掩飾自己的情緒,因此使用語音、面部表情和姿態對情感識別含有一定的主觀性。而生理信號可以客觀反應人的情緒,與眼電、心電等生理信號相比,腦電(electroencephalography,EEG)可以直接準確地反應人類的情緒[7]。因此,本文重點聚焦于使用腦電進行情緒識別。
傳統采用腦電進行情緒識別的方法主要是提取腦電的時間、頻率或時頻域特征,如微分熵(DE)特征、譜密度(PSD)和小波熵[8]等,然后使用機器學習模型進行情緒分類,如支持向量機(SVM)。近年來,隨著深度學習的發展,越來越多的研究人員將深度學習用于腦電情緒識別,以更好地挖掘腦電潛在的情緒特征[9]。尤其是卷積神經網絡(CNN)和長短期記憶網絡(LSTM)尤其被廣泛應用于腦電情緒識別[10]。使用端到端的深度神經網絡則可以對直接輸入的腦電數據進行情感識別,無需手動提取腦電的情感特征。一些研究者還將機器學習和深度學習結合起來用于腦電情緒識別,例如將深度神經網絡與bagging或boost算法結合起來以獲得更好的識別性能[11]。
傳統的機器學習方法依靠專家知識手動提取特征,而深度學習方法可以對直接輸入的腦電進行分析識別情緒,并且盡可能多地挖掘腦電中含有的情感信息[12]。雖然深度學習方法較傳統的機器學習方法有一定的識別性能,但使用腦電進行情緒識別的準確率仍然不高。為了提高基于腦電的情緒識別準確性,一些研究者采用了遷移學習的方法[13]。腦電的低信噪比(SNR)[14]、非平穩性以及受試者之間情緒表達方式的不同,都會導致從不同受試者甚至單個受試者采集腦電的特征存在差異。這些因素均會造成深度網絡提取的腦電樣本特征的非均勻分布,導致模型過擬合[15-16]。
本文針對以上問題提出了一種雙策略訓練方法來識別情緒。該方法通過在模型學習推理過程中動態地調整腦電特征的權重,提高腦電情緒識別模型的泛化能力。
1 相關工作
許多研究者已經使用腦電來識別情緒,目前在提取腦電的情緒特征和運用機器學習方法或深度學習方法對情感分類的研究取得了一定的進展。還有一些研究者使用原始腦電作為網絡的輸入進行情緒識別。
Wang等人提取了3種腦電特征,分別是功率譜、小波變換和非線性動力學分析(nonlinear dynamical analysis),然后通過線性動態系統(LDS)對特征進行平滑處理,去除與任務無關的噪聲,并使用支持向量機(SVM)進行分類[17]。Aggarwal等人提取了腦電的9個統計特征,如均值、方差等,用于情緒分類,并探討了XGBoost和LightGBM兩種提升方法對腦電情緒識別的影響[18]。Wang等人提出了一個三維卷積神經網絡EmotioNet,它使用原始腦電作為網絡的輸入,該網絡可以自動提取腦電的時空特征用于情緒識別[19]。Huang等人提出了一個集成卷積神經網絡(ECNN)用于提取腦電和周圍生理信號的有效特征,5種不同架構的CNN被用于腦電情感識別,最后,使用集成學習對多個網絡的預測進行投票得到最終結果,從而提高了模型的性能[20]。
在上述工作中,腦電情緒識別一般使用機器學習和深度學習方法。本文中使用雙策略方法訓練ScalingNet,以提高腦電情緒識別模型的泛化性能,ScalingNet是一種用于腦電情緒識別的端到端卷積神經網絡[21],雙策略訓練方法見圖1。實驗結果表明,與以往工作相比,本文方法在腦電情緒識別方面具有更好的性能。

圖1 雙策略訓練方法Fig.1 Bi-strategy training method
2 本文訓練方法
為了解決腦電樣本情緒特征分布不均勻而引起模型過擬合的問題,本文提出了一種將boost算法和梯度下降法相結合的雙策略訓練方法來訓練腦電情緒識別模型。
2.1 雙策略訓練方法
本文提出的雙策略訓練方法通過數據驅動的方法動態調整情緒腦電樣本特征分布,以提高腦電情緒識別模型的泛化性能。
如圖1所示,該方法的輸入是情緒腦電數據集。ScalingNet是一種端到端的腦電情緒識別神經網絡,作為該方法的分類器。首先,初始化輸入的情緒腦電數據集的樣本權重,并隨機初始化第1代分類器(1st ScalingNet)的網絡參數;其次,利用初始化后的加權腦電樣本訓練第1代分類器,基于梯度下降法迭代更新一趟網絡參數;然后,依據boost算法更新腦電樣本權重,并且訓練第2代分類器,其網絡參數繼承自上一代分類器訓練后得到的情緒識別模型。循環上述過程,迭代訓練多個分類器,直至觸發停機準則。
本文采用AdaBoost中SAMME的變體SAMME.R算法,SAMME.R算法使用概率預測真實值[22]。梯度下降法采用Adam(adaptive moment estimation)算法[23]。
以ScalingNet作為分類器,隨機初始化第1代分類器的網絡參數。假設輸入的情緒腦電數據集為X={x1,x2,…,xn},對應的情緒類別標簽為Y={y1,y2,…,yn},其中,n是情感腦電數據集的樣本數,xi是第i個樣本,是s×d維的向量,s是采樣點數,d是腦電通道數,并且yi是第i個樣本的標簽。假設輸入情緒腦電數據集的腦電樣本權重為{w1,w2,…,wn},其中,wi為第i個樣本的權重。初始化腦電樣本權重為wi=1/n。第j個分類器輸入的腦電樣本權重向量為Wj={wi},j=1,2,…,m,m是訓練的分類器數量。
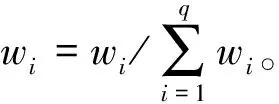
(1)
算法1雙策略訓練算法
輸入 情緒腦電數據集X,類別標簽Y,分類器ScalingNet
輸出 泛化性能最好的腦電情緒識別模型
1) 隨機初始化ScalingNet的網絡參數,令j=1,即第1代分類器。
2) isStop=False
3) while not isStop do
4) ifj=1 then
5) 初始化輸入腦電數據的樣本權重為W1={wi=1/n},其中,i=1,2,…,n,n是樣本數,并訓練第1代分類器,依據Adam算法迭代更新一趟網絡參數。
6) else
7) 第j代分類器的網絡參數繼承第j-1代分類器。訓練第j代分類器,依據Adam算法迭代更新一趟網絡參數。
8) 樣本權重公式(7)更新為Wj+1={wi}。
9) 保存第j代分類器,并且獲得泛化性能最好的分類器為第j代分類器。
10) 判斷是否滿足停機準則,滿足則isStop=True
11)j=j+1
基于計算出的加權損失L,采用Adam算法對分類器的網絡參數進行更新使損失最小化,
(2)
(3)
(4)
其中:mt是偏差一階矩估計;ut是偏差二次原始矩估計;β1和β2是時間步長t時的指數衰減率估計,
mt=β1mt-1+(1-β1)gt,
(5)
(6)
其中:gt是相對于θ的損失函數的梯度,即gt=θL(θt-1);L(θt-1)是損失函數;β1=0.9;β2=0.999。
然后,根據AdaBoost中的SAMME.R算法更新腦電樣本權重,訓練下一代分類器,
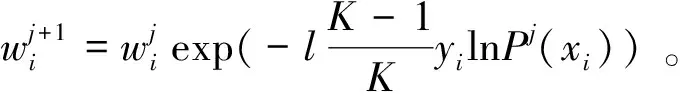
(7)
其中:wi是第i個樣本的權重;l為學習率;Pj(xi)是第i個樣本對應的第j個分類器的輸出預測概率。
輸入到第2代分類器(2nd ScalingNet)的腦電樣本權重可以從式(7)中獲得。第2代分類器繼承了第1代分類器的網絡參數,而不需要從頭開始訓練網絡。腦電樣本權重根據式(7)進行更新,以訓練第3代分類器(3rd ScalingNet)。綜上,依次迭代訓練多代分類器,具體過程如算法1所示。
2.2 加權情緒腦電樣本訓練ScalingNet
本文中使用的ScalingNet是一個用于腦電情緒識別的端到端的神經網絡架構。如圖2所示,ScalingNet有3個部分。第1部分是縮放層,通過多核卷積提取類頻譜特征圖,然后,將特征圖堆疊成三維張量;第2部分是進行特征圖變換的3層卷積層;第3部分是全局平均池化層和一個線性層,特征圖經過這部分進行情緒分類。
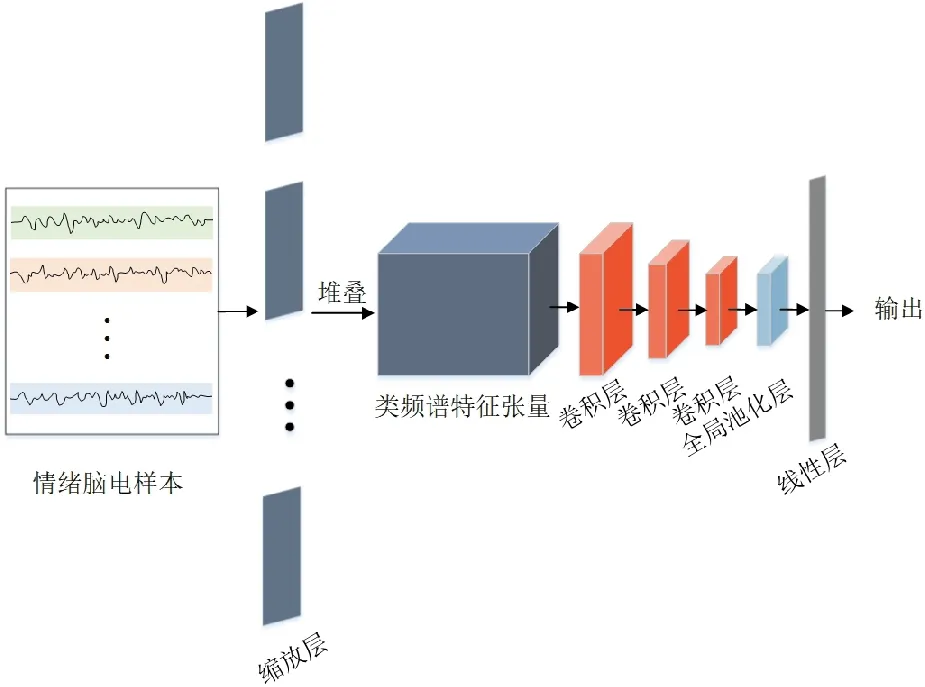
圖2 ScalingNet網絡架構Fig.2 ScalingNet architecture
Adam算法用來更新ScalingNet的網絡參數使損失函數最小化,交叉熵損失作為損失函數。本文在交叉熵損失中引入了腦電樣本權重,如式(7)所示。
3 實驗結果
3.1 DEAP數據集和預處理
本文使用DEAP數據集[24]驗證所提方法的有效性。DEAP數據集是一個包含腦電的多模態情感數據集,一共有32名受試者,每個受試者觀看40個視頻,每個視頻時長為1 min,當受試者觀看視頻時,采集他們32通道的腦電信號。每個樣本數據長為63 s,其中,前3 s為基線信號,是觀看視頻的前3 s。在觀看視頻后,受試者按照9分制對效價(valence)、喚醒(arousal)和優勢度(dominance)3個方面進行評分,通過這3個維度對人的情緒進行量化。
對腦電信號以128 Hz進行重采樣,將后60 s的腦電信號減去前3 s基線信號均值,做基線校正處理,減少基線漂移。根據效價、喚醒和優勢度3個維度的得分,以5作為閾值,小于5的為0類,大于或等于5的為1類,將任務抽象為3個二元分類問題。本文輸入數據集的大小為1 280×7 680×32(試次×采樣點數×通道數), 其中, 1 280為32×40(受試者數×視頻數),7 680為60×128(腦電數據時長×采樣率)。
3.2 實驗設置
實驗通過五折交叉驗證的方法評估本文所提方法在腦電情緒識別上的性能,五折的平均分類準確率作為最終的情緒識別結果。本文方法在腦電情緒識別模型訓練過程中設置的重要參數如表1所示。本文所提方法使用PyTorch框架實現,所有實驗都在Geforce RTX 2080 Ti上進行。

表1 本文所提方法的參數
3.3 結果和討論
將本文所提方法與已有研究的性能進行比較。同時,在基線模型ScalingNet上使用Focal Loss[25]進行比較實驗,并與本文方法進行對比,結果如表2所示。本文方法在效價、喚醒和優勢度上的準確率分別達到了71.25%、 71.48%和71.80%, 優于其他對比研究。 與Hu等人提出的基線模型ScalingNet[21]相比, 本文方法在效價、 喚醒和優勢度上的準確率分別提高了0.001 2,1.014 9和0.010 2。
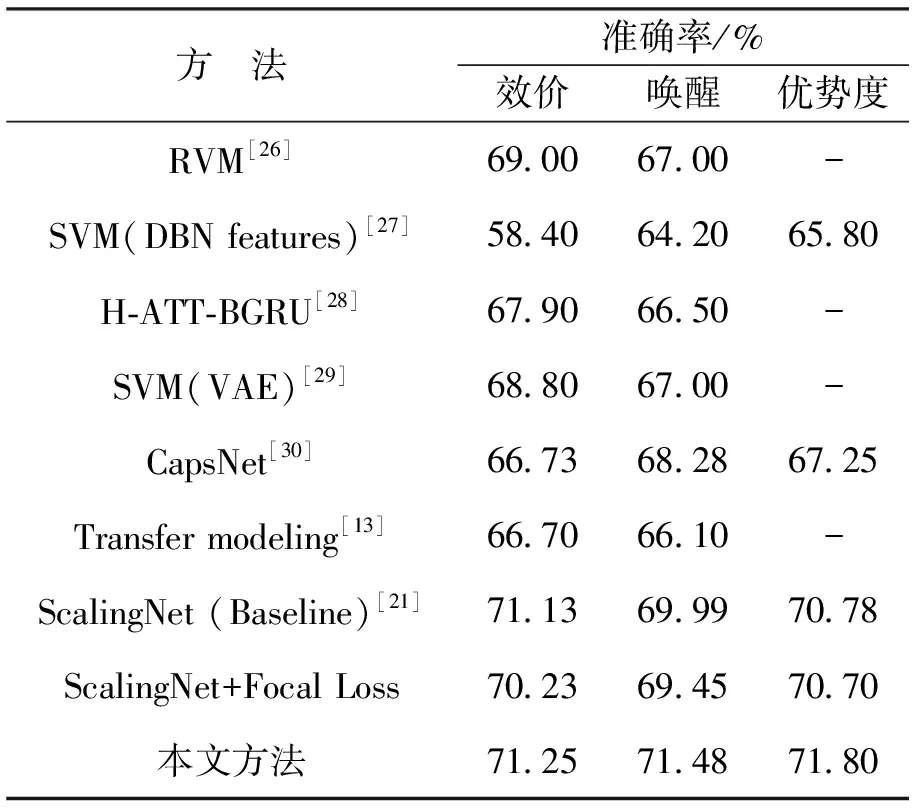
表2 本文方法的實驗結果與已有研究的比較
在進行腦電情緒識時, 大多數研究都沒有考慮到情緒腦電樣本特征非均勻分布所導致的腦電情緒識別模型泛化性能差的問題。 本文結合了兩種訓練策略, 交替更新腦電情緒識別模型, 以調整樣本特征分布, 進而提高模型的泛化性能。 本文方法通過先驗概率有效調整了腦電樣本特征的分布。
為進一步探討本文方法是否有效地調整了情緒腦電樣本特征的分布,使用t-SNE[31]可視化網絡最后一層的特征表示,如圖3所示為不同訓練階段即不同代分類器的可視化結果,網絡訓練過程中不斷調整樣本權重使其特征分布更均勻。圖4為不同方法在DEAP數據集上的可視化特征表示,可以觀察到,ScalingNet+Focal Loss并不能有效地調整情緒腦電樣本特征分布,因為ScalingNet+Focal Loss和基線模型ScalingNet腦電樣本特征都存在分布不均勻的問題。當情緒腦電樣本特征非均勻分布時,網絡訓練產生的情緒分類的決策邊界將很復雜,復雜的決策邊界可能會將訓練數據集中的類別完全分開,導致測試樣本容易被錯誤分類,并造成模型的過擬合。與基線模型和Scaling Net+Focal Loss相比,在可視化結果表面,本文方法有效地調整了腦電樣本特征的分布,使特征分布更加均勻。在這種情況下,生成的決策邊界更加平滑,模型的泛化性能將得到改善。

圖3 本文方法在不同訓練階段的可視化特征表示Fig.3 Visual feature representation of our method at different training stages
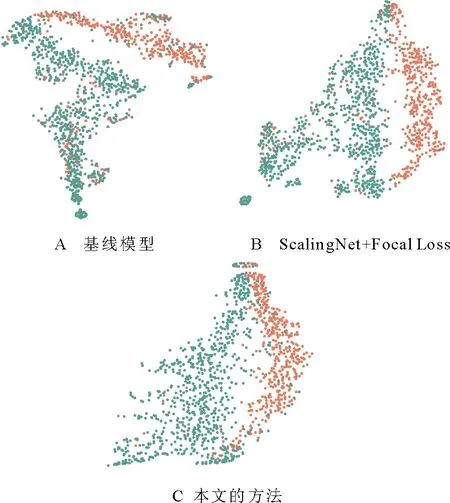
圖4 不同方法在DEAP數據集上的可視化特征表示Fig.4 Visualization of feature representation of different method on DEAP dataset
根據本文方法的特點,依據是否繼承上一代分類器的網絡參數,以及是否更新情緒腦電樣本權重進行情緒識別,進行了模型消融實驗,結果如表3所示。模型1即為本文所提出的方法,分別比較模型1和3、模型2和4,由實驗結果可以看出,更新樣本權重可以有效地提高腦電情緒識別模型的泛化性能。從模型1和2、模型3和4的對比結果可以看出繼承網絡參數的重要性。網絡參數的繼承有助于當前網絡在學習過程中獲得上一代網絡的情緒信息,有利于情緒識別。通過在學習推理過程中更新情緒腦電樣本權重,可以動態調整情緒腦電樣本特征分布,以提高腦電情緒識別模型的泛化性能。綜上所述,在模型消融實驗中,模型1具有最佳的泛化性能。
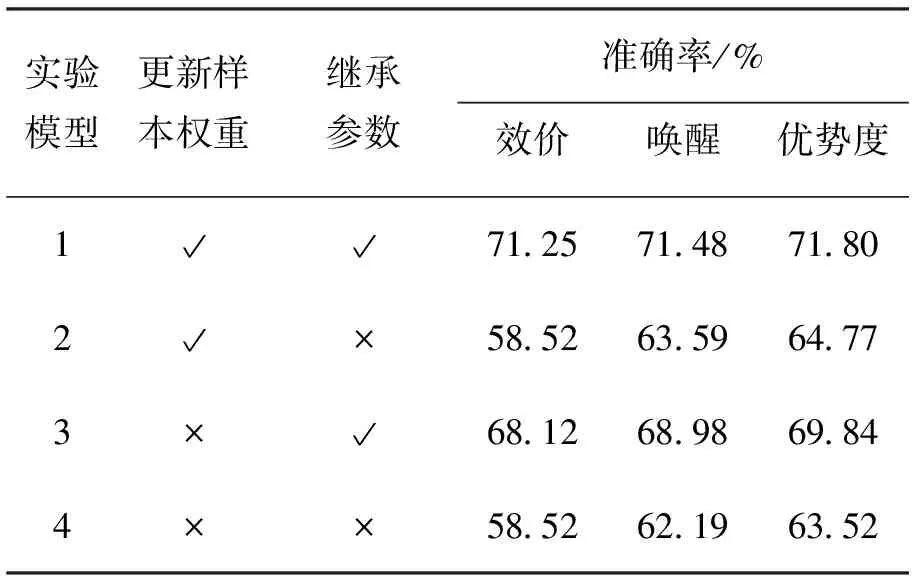
表3 模型消融實驗對比Tab.3 Model ablation experiments comparison
4 結語
本文提出了一種用于非均勻腦電情緒識別的雙策略訓練方法。 在模型的訓練過程中, 采用梯度下降法更新腦電情緒識別模型的網絡參數, 采用boost算法更新情緒腦電樣本的權重, 以調整腦電樣本特征的分布。 實驗表明, 與已有研究相比, 本文方法具有更好的情緒識別性能。 并且通過t-SNE可視化特征表示的結果表明,與基線模型ScalingNet+Focal Loss相比,本文方法有效地調整了情緒腦電樣本特征的分布。通過調整樣本特征分布,提取更魯棒的情緒腦電圖特征,提高了腦電情緒識別模型的泛化性能。為使用腦電進行情緒識別的實際應用提供了更大的可能性,今后將結合更多的訓練策略,進一步探索腦電情緒識別模型的訓練方法。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
風流一代·青春(2018年2期)2018-02-26 15:27:06
風流一代·青春(2017年6期)2018-02-14 19:28:55
風流一代·青春(2017年5期)2018-02-14 09:32:37
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
商業評論(2014年6期)2015-02-28 04:44:25
