組合預測策略的動態多目標優化算法
2022-07-21 03:32:40唐曉樂王宏偉羅洪平
計算機工程與設計 2022年7期
唐曉樂,王宏偉+,夏 浩,羅洪平
(1.新疆大學 電氣工程學院,新疆 烏魯木齊 830047; 2.大連理工大學 控制科學與工程學院,遼寧 大連 116024)
0 引 言
現實生活中許多問題可抽象為動態多目標優化問題。近年來,動態多目標優化在工程應用[1,2]與科學研究[3,4]中得到了廣泛應用。在交通運輸領域,海上運輸中多個港口對不同產品的供需要求,不同港口開放的時間窗口都是動態變化的,考慮上述因素的情況下,如何合理規劃船舶路線與調度的同時減小碳排放與運輸成本就是一個動態多目標優化問題(dynamic multi-objective optimization problems,DMOPs);在節能環保方面,污水處理過程中的進水流量與污染物濃度總是隨時間動態變化的,如何在這一變化過程中優化污水處理廠的處理成本,提高污水質量指標也是一類DMOPs。動態問題的時變性為解決動態多目標優化問題帶來了很大的挑戰[5]。在過去5年里,許多新的策略被陸續提出,其中多以預測機制為主[6-9]。但這些方法大多只適用于線性的環境變化,并且算法在歷史信息較少的前期,若歷史信息不夠準確,則會影響后續預測的準確性。考慮到上述問題,本文提出一種基于新型組合預測策略的多目標優化算法(ADNSGA)。與現有算法相比,該算法主要有以下優勢:
(1)利用ARIMA(autoregressive integrated moving average)與SVR(support vector regression)組合預測模型對Pareto解集(pareto set,PS)質心進行預測,可以增強算法對復雜問題與非線性問題預測的準確性;
(2)歷史信息不足時,通過慣性預測方法在新環境下真實Pareto前沿(pareto front,PF)附近生成初始種群,保持多樣性的同時加快算法收斂,確保歷史最優解集的準確性;
(3)ARIMA-SVR與慣性預測方法的組合預測策略既增強了預測的準確性,又在多個方向上增加了預測的多個可能性,避免種群陷入局部最優。
本文選取FDA1、FDA4、FDA5[10]、dMOP1、dMOP2[11]、SW2[12]這6個動態測試函數,將本文提出的ADNSGA算法與DNSGA-II-A、DNSGA-II-B[13]、PMGA算法[14]和SGEA算法[15]進行對比研究,實驗結果表明,所提算法在多個測試問題中均表現出更好的收斂性、多樣性與分布性,在適應環境變化,處理線性及非線性問題方面具有一定的優勢。
1 問題描述
考慮如下動態多目標優化問題
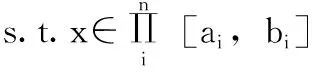
(1)

2 基于新型預測策略的動態多目標優化算法(ADNSGA)
在本節中提出了一種以NSGA-II為進化框架,用以解決DMOPs的新型進化算法,目的是利用歷史最優信息,通過組合預測策略在新環境下的真實PS附近生成初始種群。為了實現這一目的,首先對每個時刻的歷史信息進行有效篩選,利用聚類算法選出一定數量的代表個體。當檢測到環境發生變化時,通過這些代表個體在前兩個時刻的值預測產生初始種群。最后,當積累的質心時間序列足夠長時使用組合預測模型預測新的質心,并與慣性預測方法結合產生初始種群,這一初始種群的產生過程可以描述為下文中的算法2。
2.1 代表個體的選取
對環境變化后的目標函數進行預測的基礎是使用大量的歷史數據。在多目標優化問題中,目標函數所形成的點集較大,記錄PS的全部歷史信息需要大量的存儲空間,這將影響算法的性能。為了避免占用大量的存儲空間,可從PS中選擇幾個有代表性的點,但是所選擇的點需要能夠近似描述PS及PS的分布,而不是隨意選擇幾個點。綜上考慮本文采取聚類的方法,在每一次檢測到環境變化時,選取K-1個代表個體,與當前PS的質心點Ci(t) 組成代表個體集,以此來代替當前的PS流形。
首先選擇當前PS的質心點Ci(t) 以及在M個目標函數上的極值點組成初始代表個體集,然后通過計算PS中所有個體到每一個代表個體的距離,將PS劃分成若干簇。若選取代表性的個體不充分,則以半徑最大的聚類中,距離代表個體最遠的個體最為新的代表個體,重新計算該類下每個個體與代表個體的歐氏距離,相應的PS中的個體將被重新劃分到對應的類中。如此往復直到選出K個代表個體。
2.2 預測模型
2.2.1 ARIMA-SVR預測模型
ARIMA-SVR組合預測模型在處理線性問題與非線性問題方面均有著良好的表現。歷史最優信息先由ARIMA進行線性擬合,然后通過SVR模型預測殘差,彌補ARIMA在非線性性能方面的缺失,具體流程如圖1所示。該模型在一些工程應用領域中已驗證了其有效性。ARIMA與SVR的模型及定義請參見文獻[16,17]。

圖1 組合預測模型流程
2.2.2 慣性預測模型
在算法運行前期,因可用的歷史信息較少,無法建立復雜的時間序列預測模型,為了在環境變化后更快的跟蹤最優解集,采用慣性預測方法提高算法的適應性,使得歷史信息更加準確,為ARIMA-SVR模型的建立提供有效的歷史最優信息。慣性預測可表示如下
xi(t+1)=xi(t)+(xi(t)-xi(t-1))
(2)
其中,xi(t+1) 是新環境下的預測點,因為慣性預測并不準確,因此需要加入高斯變異的方式在減小預誤差的同時增加種群在新環境下的多樣性。鄰域中的點采用高斯變異的方式產生,產生方式如下
u(t+1)=gaussrand(xi(t+1),d)i=1,2,…,K
(3)
其中,gaussrand產生以預測點為均值,方差為d的高斯隨機數,d用來控制隨機數鄰域大小。
2.3 預測集的產生
通過歷史最優時間序列,利用ARIMA-SVR預測模型可以對新環境下的Pareto最優解集的質心進行預測,從而提高算法的適應性。然而在前期并沒有足夠多的變化來提供歷史數據,可用歷史數據較少。因此首先采用一種簡單的預測方法,稱為慣性預測,當累積到一定的歷史最優數據后,再加入質心預測策略,進一步提高算法的適應性。預測集的產生可以描述為算法1。
算法1:預測集的產生
步驟1 選取K個代表個體組成代表個體集CS(t);
步驟2 當t=1時,轉到步驟7;當1
步驟3 根據式(2)生成新環境下的K個預測個體Cset, 然后根據式(3)得到新環境下預測集u(t+1)。 轉到步驟6;

步驟5 其它K-1個預測個體根據式(2)生成,然后根據式(3)通過Cset得到新環境下預測集u(t+1)。 轉到步驟6;
步驟6 對預測集中個體ui(t+1) 進行如下調整
(4)
其中,ai,bi分別為搜索空間的上界與下界,i=1,2,…,n, 算法結束。

2.4 新型預測模型的動態多目標優化算法(ADNSGA)
本文將所提出的組合預測策略作為環境變化響應與DNSGA-II框架相結合,提出了基于新型預測策略的動態多目標優化算法ADNSGA,其算法框架可以描述如算法2所示。
算法2:ADNSGA
步驟2 環境變化檢測,若環境發生變化則Dynamic←Truth, 否則Dynamic←False;
步驟3 若Dynamic=Truth;
由算法1生成新環境下的預測集u(t+1) 并計算其F(x,t), 接著pop←u(t+1),t←t+1;
步驟4 若Dynamic←False;
(1)根據交叉概率Pc從種群pop(t) 中選出父代 (xi(t),xj(t)) 進行算數雜交,生成后代種群O1(t);
(2)按照變異概率Pm對種群pop(t) 進行變異操作,生成后代種群O2(t);
步驟5 對pop(t)∪O1(t)∪O2(t) 中的個體進行快速非支配排序,根據前沿等級與擁擠度距離選擇出N個個體,得到新的種群Q(t), 并令pop(t)←Q(t);
步驟6 若t>tmax, 則停止;否則轉步驟2。
ADNSGA從初始種群initialpop(N)開始,每次迭代前都會先進行環境變化檢測,一般可以通過對當前種群的部分個體進行重新評估[5],本文中采用當前種群5%的個體pl, 根據如下環境變化檢測算子進行檢測
(5)
其中,ω為當前代數。當μ(ω) 大于閾值μ*時,則判定此時環境發生了變化,采取相應的變化響應機制。
3 實驗分析
3.1 動態優化問題
本文將在6個測試問題上進行算法比較,其中包括Farina等所提出的經典測試問題FDA1,4,5[10],兩個dMOP問題[11],以及武燕等所提出的SW2測試問題[12]。其定義及其PS與PF見表1。
圖2(a)~圖2(f)分別為nT=10,n=20時F1~F6的真實帕累托前沿(pareto front,PF),其中F1與F4的PF不隨時間變化。圖3(a)~圖3(f)分別為參數設置nT=10,n=20時F1~F6的PS在低維空間中的投影,其中F2的PS不隨時間變化。這些問題中時間步t=τ/τT, 其中τ為當前種群迭代次數,τT為環境變化頻率,nT代表環境變化程度。

表1 動態多目標優化問題定義

圖2 F1~F6的真實PF

圖3 F1~F6的PS在低維空間中的投影
3.2 性能指標
本文采用改進的反向世代距離MIGD(modified inver-ted generational distance)[6,15]、改進的分布測度MHVD(modified hypervolume difference)、改進的超體積MSP(modified spacing)3個評價指標來評價算法的性能。MIGD、MHVD主要通過對真實PF的接近程度來衡量算法的收斂性與多樣性,MSP用于衡量算法的均勻分布性,3個評價指標的結合可以幫助更加全面了解每種算法。與MIGD一樣,MHVD、MSP分別為一段時間內HVD[6,15]與SP[6,15]的平均值。實驗中兩目標問題FDA1、dMOP1、dMOP2和SW2設置參考點數為1000個,三目標問題FDA4、FDA5參考點數為2500個。
3.3 對比算法及參數設置
為了驗證所提出算法的優越性,本文選擇了有代表性的4種動態多目標算法來進行對比研究。分別為:加入重新初始化種群方法的DNSGA-II-A、DNSGA-II-B[13],當檢測到環境變化時,前者隨機重新初始化部分個體,后者則是隨機對部分個體進行變異操作;PMGA[14]通過聚類選取PS質心,結合慣性預測的方法生成新環境下的初始種群。SGEA[15]通過線性時間序列模型,利用相鄰時刻的兩個PS中心點預測種群進化的步長;通過少量相鄰時刻的非支配解集中心點預測進化方向,指導生成預測種群。
5種算法中的參數設置如下:
(1)迭代進化:兩目標問題F1、F2、F3、F6中種群規模N=100,三目標問題F4、F5中N=200;交叉概率Pc=0.9,變異概率Pm=0.1,n=20為決策空間的維數,進化代數設定為gen=1600;
(2)預測部分:PMGA中質心選取個數與ADNSGA中代表個體數均為K=10,ARIMA模型階數為p=3,q=3,SVR模型選取徑向基函數(RBF)為核函數,歷史最優序列長度L=23,高斯隨機數的方差d=0.35;
(3)環境變化:設定環境變化程度nT=10,變化頻率τT=10,環境變化檢測閾值μ*=0.01,最大環境變化次數tmax=160; 從當前種群中隨機選擇5%的個體用以檢測環境變化,當t>tmax時算法終止。
3.4 實驗結果與分析
表2~表4分別為5種算法在環境變化設置為nT=10,τT=10時,求解F1~F6動態多目標測試問題所獲得的3種度量的平均值與標準差。從表2中可以看出。

表2 獨立運行20次的MSP度量統計結果
(1)就SP度量而言,在0≤t<20時,ADNSGA僅在F6上表現最佳,這說明單一的慣性預測策略無法保證算法在真實PF上分布的均勻性,應在運行前期結合一些策略來改善其分布性能;
(2)當20≤t≤160時,ADNSGA在F1、F3、F5、F6上表現優異,在F4上也優于除DNSGA-II-A外的其它3種算法,說明組合預測策略比起單一的預測策略能有效提升算法沿真實PF均勻分布的性能;
(3)整個運行過程中,ADNSGA在F6上始終優于其它對比算法,表明了其在處理非線性問題方面有更好的分布性。
從表3中可以得到以下信息:
(1)當0≤t<20時,ADNSGA在F2、F3、F6上有著更好的收斂性與多樣性,但在F4、F5兩個三目標問題上,DNSGA-II-A優于其它對比算法,說明重新初始化部分個體的動態響應策略在三目標問題上比單一的預測方法擁有更好的適應性;
(2)當20≤t≤160時,ADNSGA在所有6個動態測試問題上均優于其它對比算法,表明了組合預測策略的有效性。

表3 獨立運行20次的MHVD度量統計結果
從表4中可以看出:
(1)從數值上看,ADNSGA在大部分測試問題上都取得了不錯的結果。當0≤t<20時,ADNSGA算法在F1~F5的問題上,雖然不是表現最佳,但也始終處于第二的水平,優于其它3種算法,這表明慣性預測方法在算法運行初期是有效的,并且有著更好的普適性;
(2)當20≤t≤160時,ADNSGA算法在F1、F3~F6問題上均表現更好的性能,在F2問題上,DNSGA-II-B算法表現出了更好的收斂性與多樣性,原因在于F2問題中PS是固定不變的,采用預測的方式并不能很好指引新環境下的初始種群,因此PMGA、SGEA、ADNSGA均表現欠佳,而采取重新初始化或變異部分個體的方法,一旦找到F2的真實PS,就可以快速逼近新環境下的PS和PF。DNSGA-II-B在均值上略微優于DNSGA-II-A,說明采用變異的策略可以具有更好的多樣性;
(3)在F6測試問題上,ADNSGA始終優于其它對比算法,表現出更好的收斂性與多樣性。

表4 獨立運行20次的MIGD度量統計結果
為了進一步討論所提算法的性能,圖4(a)~圖4(f)繪制了ADNSGA及4種對比算法在F1~F6上,獨立運行20次的平均IGD度量與時間的關系圖。首先在0≤t<20時,ADNSGA在大部分問題上優于其它對比算法,當t≥23時,開始通過ARIMA-SVR模型對PS質心點進行預測,ADNSGA的IGD值在除F2之外的5個問題上均優于其它對比算法,且數值波動較小,而未采取預測策略的DNSGA-II-A、DNSGA-II-B則波動很大,這表明采用中心點預測的方法能夠有效的跟蹤環境變化。將PMGA、SGEA、ADNSGA這3種采取預測策略的算法進行對比,采取組合預測策略的ADNSGA始終優于PMGA與SGEA,在F6問題上優勢尤為顯著。

圖4 5種算法平均IGD值與時間的關系
圖5、圖6中(a)~(e)分別為5種算法在F6問題上,20次獨立運行中,當t=140,t=143,t=147時IGD最小的初始種群與最終種群。從圖5和圖6中同樣能清晰看到,ADNSGA相比于對比算法能更準確追蹤Pareto最優前沿。

圖5 5種算法IGD最小的初始種群

圖6 5種算法IGD最小的最終種群
通過對5種算法的MIGD、MSP和MHVD性能指標的統計分析可知,本文提出的ADNSGA算法所采取的組合預測策略更適用于PS變化及PS、PF同時變化的問題,在算法運行前期加入的慣性預測方法可以使算法在大部分測試問題中保持較好的收斂性與多樣性,具有很好的推廣性與普適性,但在分布性方面有所欠缺,積累到足夠的歷史信息后,組合預測模型使得算法在非線性問題上表現出良好的競爭優勢,同時提升算法對真實PF的均勻覆蓋性。
4 結束語
針對動態多目標優化問題,本文提出一種基于組合預測策略的動態多目標優化算法(ADNSGA),該算法在單一的慣性預測方法上增加了組合預測模型的質心預測,為預測最新的PS提供了更準確的指導依據。實驗結果表明,ADNSGA算法在多種動態問題上都有很好的環境適應能力。此外如何在算法前期提高在PF上的分布性是未來工作的一個可研究方向。另外如何根據環境變化程度[18]合理分配預測策略也是一個值得研究的課題。當前,動態多目標優化在控制問題、調度問題、機械設計問題、圖像分割問題,資源管理問題等現實生活和工業生產方面[5,16,17]應用廣泛。本文所提算法在為求解此類問題提供新思路的同時,豐富了動態多目標優化的應用前景。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中老年保健(2021年12期)2021-08-24 03:30:40
中國傳媒大學學報(自然科學版)(2021年1期)2021-06-09 08:43:00
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中國生殖健康(2020年6期)2020-02-01 06:28:50
新世紀智能(英語備考)(2019年12期)2020-01-13 06:07:18
中國生殖健康(2019年11期)2019-01-07 01:28:02
中國生殖健康(2018年6期)2018-11-06 07:09:28
光學精密工程(2016年6期)2016-11-07 09:07:19
