基于單哈希計數布隆的DDS自動發現算法
2022-07-21 04:11:44樊智勇劉哲旭李伯寧
計算機工程與設計 2022年7期
關鍵詞:信息
樊智勇,張 同,劉哲旭,李伯寧
(1.中國民航大學 工程訓練中心,天津 300300; 2.中國民航大學 電子信息與自動化學院,天津 300300)
0 引 言
數據分發服務DDS(data distribute service)[1,2]是由對象管理組織OMG(object management group)制定的以數據為中心的發布/訂閱通信模型規范,其采用簡單發現協議SDP(simple discovery protocol)來交換Publisher與Subscriber之間的實體數據[3]。在中小型分布式仿真系統得到良好應用,但當系統規模較大、數據交互較多時,SDP會造成網絡傳輸量高、內存消耗大等問題。針對這一問題,文獻[4]提出SDPBloom(Bloom filter simple discovery protocol)自動發現算法,通過將端點描述信息存儲到Bloom過濾器中發送給其他參與者,可以減少網絡傳輸量與內存消耗,但是該算法不支持元素刪除操作,且在運算過程中需要較多的哈希函數,時間消耗成本較大。文獻[5]提出一種單哈希閾值布隆過濾器DDS自動發現算法,通過調整閾值θ和判定閾值T進行端點信息的查詢匹配,降低了DDS在自動發現過程中的誤報以及網絡傳輸量。文獻[6]將可壓縮布隆過濾器應用到DDS自動發現算法中,在一定程度上降低了網絡傳輸量與內存消耗。文獻[7]提出一種基于分層布隆過濾器的DDS自動發現算法,通過改進原有的鏈式儲存結構以及增加節點刪除操作,有效降低內存消耗。
在以上研究基礎上,本文提出一種基于單哈希計數布隆過濾器的自動發現算法(simple discovery protocol_one hash counting Bloom filter,SDP_OHCBF),該算法通過使用計數布隆過濾器[8]來支持元素刪除操作,同時使用單個哈希和取模運算來代替標準布隆過濾器中的多個哈希函數,減少哈希運算成本,從而加快DDS的自動發現過程,實現對分布式仿真系統的實時性優化。
1 基于DDS的簡單發現協議
1.1 DDS
DDS中的域是指在邏輯上將應用系統進行隔離的通信網絡,其不受其它應用程序的影響,域參與者(domain participant)作為域中數據通信互動的進入點,主要包括發布者(publisher)、訂閱者(subscriber)和主題(topic),它們又包括數據寫入者(data writer)和數據讀取者(data reader)[9]。只有在同一個域中的參與者,且當數據的主題名稱、主題類型相同且QoS策略相互兼容時,數據寫入者與數據讀取者才可以相互通信,其中全局數據空間GDS主要負責完成發布者與訂閱者、主題與QoS策略的管理與匹配工作,即自動地將發布者發布的數據有效地傳送給感興趣的訂閱者[10,11],DDS的通信結構如圖1所示。

圖1 DDS的通信結構
1.2 簡單發現協議
DDS通過匹配主題信息以及QoS策略是否兼容,從而將發布者發布的信息發送到訂閱者,這一過程的實現需要復雜的內部數據結構、高效的發布/訂閱匹配技術以及自動發現算法做支撐,其中簡單發現協議是DDS的核心技術,其可以分為兩個階段:簡單參與者發現協議階段(simple participant discovery protocol,SPDP)和簡單端點發現協議階段(simple endpoint discovery protocol,SEDP)[12]。
簡單參與者發現階段:主要負責完成同一域中的本地參與者與遠程參與者的自動發現。本地域參與者通過DDS內置的數據寫入者將參與者數據包發送給其遠程域參與者,同時通過內置的數據讀取者接收其他遠程參與者的數據包,這個參與者數據包包含域參與者的唯一標識號GUID、地址、端口號以及QoS策略等信息,這些信息通過高效(best effort)組播方式進行傳輸。
簡單端點發現階段:在參與者相互發現的基礎上,主要負責交換本地參與者與遠程參與者的數據寫入者的發布端點描述信息與數據讀取者的訂閱端點描述信息,這些端點描述信息包括設置的標識號GUID、QoS策略等,經DDS全局數據空間進行匹配,若匹配成功,則通過可靠(reliable)傳輸方式進行端點之間的發布和訂閱,DDS的簡單發現協議過程如圖2所示。

圖2 SDP自動發現過程
在DDS簡單發現協議過程中,每個參與者都需要將自己所有的發布/訂閱端點信息發送給域中其他參與者,同時也要接收其他參與者發送的所有發布/訂閱端點信息,然而參與者只關心與自己主題相關以及QoS策略相互兼容的發布/訂閱端點信息,這就造成網絡傳輸量高、內存消耗大的問題,故本文提出一種基于單哈希計數布隆過濾器的DDS自動發現算法。
2 OHCBF的設計與理論分析
2.1 OHCBF的設計

OHCBF將散列映射過程分為兩個階段[15]:
哈希階段:通過使用單哈希函數h(x)將集合U中的元素xi映射成機器字W;
取模運算階段:通過取模運算 |T|(h(x) modmi) 將機器字W映射成向量組中的目標元素T,同時將該分區內相應位置的計數器加1。
OHCBF的結構如圖3所示,其中假設k=3,n=3,m1=5,m2=7,m3=11,即3個元素 (x1,x2,x3) 通過單個哈希函數h(x)映射和取模運算存儲到布隆過濾器OHCBF中。當存儲元素x1時,首先應用哈希函數h(x)將其映射成機器字,設h(x1)=1987, 然后對其進行取模運算,g1(x1)=h(x1)modm1=2,g2(x1)=h(x1)modm2=3,g3(x1)=h(x1)modm3=4, 則向量組中對應分區的第2位,第3位,第4位計數器加1,同理元素x2,x3的插入過程類似。

圖3 OHCBF結構
2.2 OHCBF的理論分析
2.2.1 OHCBF的計數器大小設定
OHCBF通過多占用存儲空間給Bloom過濾器增加了元素刪除操作,但為使占用空間最小,需要計算出OHCBF中的計數器大小[16]。設OHCBF中的計數器大小為j,則第i個計數器被映射j次的概率為P(c(i)=j), 其中
(1)
(2)

(3)
當j=16,即計數器為4位時,計數器會溢出,其概率為
(4)
這個概率值很小,所以當計數器位數為4時,對大多數程序來說足夠使用。
2.2.2 OHCBF的獨立性約束
在OHCBF中,k個哈希值全都來自于同一個哈希函數以及取模運算,大大減少了哈希計算時間,但為了使OHCBF和SDPBloom產生相同的誤報效果,保證哈希函數的原有性能,需要保證OHCBF中的單哈希函數在散列過程中生成的k個哈希值和在標準布隆過濾器中由k個哈希函數映射生成的k個哈希值具有相同的獨立性,即在OHCBF中,需要保證每個分區大小為互質,這樣才會產生獨立的取模結果,更確切地來說,讓gi(x)=h(x)modmi, 1≤i≤k, 如果 (mi,mj)=1, 1≤i 若每個分區大小不是相對素數,則在取模運算階段會產生一定的相關性。如在OHCBF中設其有兩個分區,其大小分別為m1=4,m2=6,則經過哈希映射和取模運算后,發現當g2(x)=0或2時,g1(x)=0, 當g2(x)=1或3時,g1(x)=1, 即g1(x) 與g2(x) 具有一定的關聯性,這將達不到獨立的取模效果。 2.2.3 OHCBF的誤報分析 在標準布隆過濾器中,通過使用k個哈希函數將集合U中的n個元素映射到m位數組中時,某一位數組仍為0的概率為[17] (5) (6) (7) (8) (9) 同理可得取模余數發生碰撞導致的誤報率為 (10) 通常情況下由于機器字的空間范圍要遠遠大于位向量,即2L?m, 所以只要機器字的存儲空間足夠大,則機器字發生碰撞的概率會很小,在實際操作過程中P(A)近似為零,因此,OHCBF的誤報率近似為 (11) 本文將OHCBF應用到DDS的自動發現過程中,以遠程參與者B向本地參與者A訂閱端點信息為例,具體說明DDS的自動發現過程,如圖4所示。 圖4 SDP_OHCBF的自動發現過程 在SDP_OHCBF的參與者發現階段,本地參與者A和遠程參與者B創建OHCBF向量;將端口變量數據的端點描述信息經過單個哈希函數和取模運算映射到k個不均勻分區的mi(1≤i≤k) 位OHCBF中,其中k個位置的位向量計數器加1,如果該位置被多次映射,則進行累加,將自己所包含的端點描述信息存儲到OHCBF向量中;本地參與者A的端點描述信息通過參與者數據包一起發送給遠程參與者B,用來宣布本身存在信息,同時接收遠程參與者B發送的包含端點描述信息的OHCBF向量,本文使用主題名稱作為參與者端點描述信息的唯一標識符,從而進行端點信息匹配;當遠程參與者B獲取到包含本地參與者A端點描述信息的OHCBF向量時,通過單個哈希函數和取模運算進行數據查詢,判斷k個位置的位向量是否為非0,若為非0,判斷該元素在本地參與者A中,則將OHCBF添加到本地信息庫中,進入到端點發現階段,否則忽略該信息;同理,當本地參與者A獲得遠程參與者B的信息時,執行相同步驟。至此,本地參與者A與遠程參與者B交換了彼此的端點描述信息并對其進行存儲,完成了參與者發現過程。 在端點發現階段,遠程參與者B通過對存儲的本地參與者A端點描述信息的OHCBF向量進行查詢,這一階段通過參與者創建的數據寫入者與數據讀取者分別進行匹配,遠程參與者B將獲得的本地參與者A發布的端點描述信息與自身需要訂閱的端點信息進行匹配,若匹配成功,則向本地參與者A發送訂閱請求;本地參與者A將被訂閱的包含主題以及QoS服務質量的端點具體信息發送到遠程參與者B進行再匹配;若匹配成功,則遠程參與者B的訂閱端點與本地參與者A的發布端點建立數據通信,若匹配不成功,則發生誤報,向遠程參與者B的訂閱端點發送“本地沒有相關端點信息”。通過此種方式改變了DDS參與者之間的對話方式,即不需將自己擁有的所有信息全部發送給其他參與者,只需告訴其他參與者自己擁有哪些信息即可。 將端點描述信息存儲在OHCBF向量中,設置主題名稱進行參與者之間的通信,假定域中參與者個數為P,其包含的端點總數為E,默認在每個參與者中擁有同樣多的端點數,即每個參與者均有E/P個端點,且不考慮心跳機制。定義ME(match endpoint)為Bloom過濾器中每個參與者匹配的端點數與端點總數的平均比率,MEBF為SDPBloom中匹配的端點總數,MEOHCBF為SDP_OHCBF中匹配的端點總數,MEBF和MEOHCBF決定了參與者在端點發現階段需要發送和接收的端點信息數。由于在SDP中每個參與者需要向其他參與者發送自己所有的發布/訂閱端點信息,所以其發送的消息數為E,而在SDPBloom與SDP_OHCBF中,每個參與者通過將端點描述信息存儲到BF和OHCBF向量中,可以篩選掉因主題不匹配的端點信息,所以E遠大于MEBF和MEOHCBF。 在不使用多播情況下,SDP、SDPBloom、SDP_OHCBF這3種算法中每一個參與者需要發送和接收的端點消息為 (12) (13) (14) 在SDP過程中,每一個參與者需要存儲域中其他參與者的所有端點信息,而在SDPBloom、SDP_OHCBF中,每一個參與者不僅需要保存本身自帶的端點信息和在參與者發現階段附帶的過濾器向量信息,還要存儲通過布隆過濾器向量匹配上的端點信息,所以在這3種自動發現算法中,每個參與者所占用的消耗內存為 MSDP=E (15) (16) (17) 由式(15)~式(17)可知,SDPBloom、SDP_OHCBF與SDP相比,通過使用布隆過濾器可以大大減少自動發現過程中的網絡傳輸量與內存消耗,同時SDPBloom和SDP_OHCBF的網絡傳輸量與消耗內存與端點匹配數相關。 基于RTI_DDS的分布式仿真平臺具有10個仿真節點,同時含有利用Matlab/Simulink、AMESim、Flightsim、C/C++等專業仿真軟件建立的仿真模型。在該平臺上將本文提出的改進算法SDP_OHCBF與SDP、SDPBloom算法在網絡傳輸量、內存消耗、誤報率以及查詢時間4個方面進行仿真實驗驗證。 在本實驗中,一個仿真模型作為一個參與者,一共有P個參與者,每個仿真模型有100個模型端口變量(端點),一共有100*P個端點。每個端點信息為6000字節,端點描述信息為4字節,在SDPBloom與SDP_OHCBF中,用來存儲端點描述信息的布隆過濾器位向量為64字節。 在端點發現階段,當端點匹配率為ME=0.1、ME=0.2、ME=0.5時,SDP、SDPBloom和SDP_OHCBF的網絡傳輸量隨參與者數量的變化情況如圖5所示。 圖5 網絡傳輸量 隨著參與者數量增加,端點數也增加,SDP、SDPBloom和SDP_OHCBF的內存消耗也隨著參與者數量增加而發生變化,圖6與圖7分別為匹配端點率為ME=0.1、ME=0.2的內存消耗變化情況。 圖6 ME=0.1的內存消耗 圖7 ME=0.2的內存消耗 從圖5~圖7可以看出: (1)SDP在整個自動發現過程中的網絡傳輸量較SDPBloom和SDP_OHCBF大,且發送的信息數不隨端點匹配率ME的變化而變化,所以SDP需要更大的消耗內存來存儲遠程端點信息;當端點匹配率越小,SDPBloom和SDP_OHCBF的優勢就越明顯; (2)無論端點匹配率ME如何變化,SDPBloom和SDP_OHCBF的內存消耗都近似相同且遠遠小于SDP,說明通過使用布隆過濾器可以大大減少端點存儲信息,減少不必要的內存消耗。 本實驗負責對SDPBloom與SDP_OHCBF的誤報率與查詢時間進行仿真驗證,與以上實驗條件相同,每個參與者都有100個端點描述信息映射到SDPBloom和SDP_OHCBF向量中,每個端點描述信息為4字節。令n=100,k=3,mt為SDPBloom的位向量長度,ms為SDP_OHCBF的位向量長度,其中SDP_OHCBF的哈希函數設置為MD2,SDPBloom的哈希函數設置為MD5、MD2和SHA-1,表1為SDPBloom和SDP_OHCBF的誤報率。 由表1可得,隨著布隆過濾器位向量m的變化,SDP_OHCBF的誤報率與SDPBloom的誤報率近似相等,且隨著m逐漸增大,SDPBloom與SDP_OHCBF的誤報率越來越小。 表1 SDPBloom和SDP_OHCBF的誤報率 當SDPBloom與SDP_OHCBF查詢100個成員元素,端點匹配率ME=0.5時,隨著布隆過濾器位向量m長度變化,其所需查詢時間如圖8所示。 圖8 隨m位向量變化所需查詢時間 當SDPBloom位向量長度m為1000,SDP_OHCBF位向量長度m為1009時,隨著100個元素中端點匹配率ME從0到1的變化,SDPBloom與SDP_OHCBF所需查詢時間對比如圖9所示。 圖9 隨端點匹配率ME變化所需查詢時間 由圖8、圖9可以看出,無論是隨著布隆過濾器的位向量大小變化還是查詢成員與非成員的比例變化,SDP_OHCBF與SDPBloom相比,都花費較少的哈希運算時間,因此SDP_OHCBF具有更好的實時性,這大大提高了DDS自動發布/訂閱的過程。 本文在對DDS的自動發現算法SDP以及常規改進算法SDPBloom的研究基礎上,提出一種DDS自動發現算法SDP_OHCBF,通過將標準布隆過濾器升級為計數布隆過濾器,使之無需重新構建布隆過濾器以支持元素刪除操作,同時使用單個哈希函數以及簡單取模運算代替標準布隆過濾器中的多個哈希運算。通過仿真實驗驗證,SDP_OHCBF與SDPBloom在網絡傳輸量、內存消耗以及誤報率基本保持一致的情況下,大大減少了哈希運算時間,提高了DDS自動發現過程的實時性。該算法在多電飛機分布式仿真系統中得到良好應用,加快了機電系統模型分布式仿真的數據交互過程,為接下來優化飛機機電系統分布式協同仿真提供了良好的實時性。但是該算法目前沒有將QoS考慮進去,無法預先在參與者發現階段完成對QoS的判斷,接下來將深入研究如何在SDP_OHCBF的基礎上加上對QoS的判斷,進一步提高其應用價值。
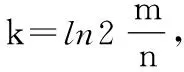

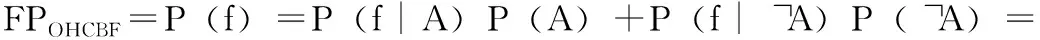


3 用于數據分發服務的SDP_OHCBF
3.1 基于SDP_OHCBF的自動發現過程

3.2 基于SDP_OHCBF的性能分析
4 實驗驗證與結果分析
4.1 網絡傳輸量與內存消耗



4.2 誤報率與查詢時間



5 結束語
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
大眾創業(2009年10期)2009-10-08 04:52:00
數字社區&智能家居(2009年7期)2009-09-29 08:16:48
數字社區&智能家居(2009年11期)2009-06-25 04:30:34
數字社區&智能家居(2009年3期)2009-04-21 03:09:04
數字社區&智能家居(2009年2期)2009-03-27 04:33:44
數字社區&智能家居(2009年12期)2009-02-03 07:50:48
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
