基于卷積循環神經網絡的語音邏輯攻擊檢測
2022-07-23 12:17:28楊海濤王華朋楚憲騰牛瑾琳林暖輝張琨瑤
科學技術與工程 2022年18期
楊海濤, 王華朋*, 楚憲騰, 牛瑾琳, 林暖輝, 張琨瑤
(1.中國刑事警察學院公安信息技術與情報學院, 沈陽 110854;2.廣州市刑事科學技術研究所, 廣州 510030)
近年來電信網絡詐騙屢屢發生,不法分子利用偽造語音來掩飾自己的聲學特征以達到惡意欺騙的目的,對人民的生命財產安全構成嚴重威脅。快速、準確、有效地對偽造語音進行檢測可以有效保證錄音資料的真實性和完整性,保護公民合法權益,保障司法公正[1]。
偽造語音的方法通常包括合成、轉換、回放和模仿[2]。其中語音合成和語音轉換被稱為邏輯攻擊(logical access,LA)為本文的研究對象。語音邏輯訪問攻擊的檢測方法有很多,主要分為傳統機器學習的方法和基于深度學習的方法。在傳統機器學習檢測方法中GMM和i-vector較為常見,在2015—2019年自動說話人識別欺騙攻擊與防御對策挑戰賽(automatic speaker verification spoofing and countermeasures challenge, ASVspoof)上都取得不錯的成績,該項比賽是迄今為止規模最大,最全面的針對偽造語音的挑戰賽[3]。隨著深度學習(deep learning, DL)的發展出現了一批深度神經網絡模型,他們能夠很好地區分非線性復雜特征從而提高分類的準確度并被用于語音檢測領域[4]。Yu等[5]使用深度神經網絡DNN分類器及聲學動態特征在自動說話人識別系統對欺騙語音進行檢測取得了很好的結果。鑒于卷積神經網絡CNN在圖像處理中取得的成功,不少學者將其用于語音處理相關問題中[6]。Liang等[7]使用CNN網絡去解決失真小的偽造語音檢測問題,其結果區分準確度大于95%相比傳統方法提高了4.2%。在處理與時序相關的場景中循環神經網絡RNN有突出表現,本文研究中采用了長短時記憶網絡(long short term memory, LSTM)、門控循環神經單元(gated recurrent unit, GRU)、雙向長短時記憶循環網絡(bidirectional LSTM, Bi-LSTM) 3種變種RNN網絡用于語音邏輯攻擊檢測實驗,在其他學者的研究中Scardapane等[8]采用RNN網絡模型在ASVspoof2015數據集上提取常用聲學特征進行實驗,平均等錯誤率為2.91%。長短時記憶網絡則更加適合處理長時依賴問題[9],在ASVspoof2017挑戰賽中Li等[10]使用了基于注意力機制的LSTM結構并取得了良好的結果。有研究表明:融合模型是進一步提升系統性能的好方法。Chen等[11]使用基于ResNet的混合網絡模型進行語音回放檢測,其等錯誤率相對單層網絡結構減少了18%。Sainath等[12]2015年首次將CNN、LSTM、DNN三者結合成一個統一的體系結構CLDNN網絡,并將其用于自然語言處理來解決大詞匯量連續語音識別的問題。Emam等[13]則對CNN、LSTM、CLDNN三者進行了對比,結果表明CLDNN網絡表現最優。而后Bo等[14]將CLDNN網絡用于說話人識別,在2 000 h的含噪語音數據集上進行實驗其結果相對單層網絡提升了12.7%。Dinkel等[15]提出了一種基于CLDNN網絡端到端的偽造語音檢測在BTAS2016數據集上進行實驗表現優秀。
基于此,現從混合網絡模型,特征選擇出發,提出基于CNN-RNN-DNN的混合網絡,包括CNN-LSTM-DNN、CNN-GRU-DNN、CNN-BiLSTM-DNN三種混合網絡模型。模型中CNN部分可以進行下采樣充分提取語音信號的深度信息,RNN部分解決語音中的時序問題,DNN部分則實現分類功能。每種混合網絡模型包含20層網絡層,運用所提網絡對提取的6種聲學特征進行實驗,以期為語音邏輯攻擊檢測提供基礎。
1 提出的CNN-RNN-DNN混合網絡
基于CNN-RNN-DNN混合網絡檢測流程如圖1所示。分別提取語音信號特征后將提取到的語音特征數據劃分為訓練集、驗證集和測試集,模型訓練階段分別采用CNN-RNN-DNN網絡檢測系統中的CNN-LSTM-DNN、CNN-GRU-DNN、CNN-BiLSTM-DNN等混合網絡進行訓練,得到訓練好的模型后用測試集測試最后輸出結果進行系統性能評判。
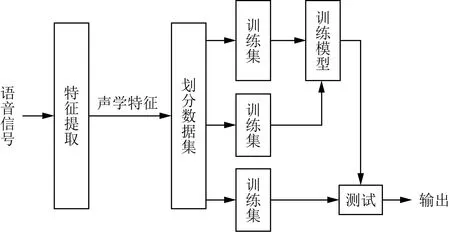
圖1 檢測系統流程Fig.1 Process of the detection system
1.1 聲學特征
在語音識別領域梅爾頻率倒譜系數MFCC被廣泛應用,語音信號經過預加重后分窗、加幀等處理再進行快速傅里葉變換,送入Mel濾波器進行濾波處理后取對數運算,再進行DCT操作最后輸出MFCC參數特征[16-17]。MFCC特征參數提取流程如圖2所示。
對輸入的語音信號s(n)依次進行預加重、分幀、加窗等處理,生成時域信號t(n),本文研究中預加重系數取值為0.95,分幀設置為25 ms(幀大小)和10 ms跨度(重疊15 ms),選擇窗的長度為25 ms的漢寧窗。

圖2 MFCC提取過程Fig.2 MFCC extraction process
(1)接著對語音時域信號t(n)通過快速傅里葉變換處理得到頻域信號P(k),其中N=256,FFT為快速傅里葉變換,ti為信號t(n)的第i幀。

(1)
(2)將頻域信號P(k)輸入Mel濾波器組進行濾波操作,Mel濾波器組是一組三角帶通濾波器,使用式(2)在Hertz(f)和Mel(m)之間轉換f為頻率:

(2)
(3)濾波操作后對信號進行取對數運算計算每個濾波器組輸出的對數能量S(m),Hm為經Mel濾波處理后的信號:

(3)
(4)使用離散余弦變換(DCT)將對數頻譜S(m)轉換為MFCC特征參數X(n)其表達式為

(4)
式(4)中:m為濾波器組;n為系數階數。


(5)
伽馬通頻率倒譜系數(gammatone frequency ceptral coefficient,GFCC)能夠精確模擬人耳的聽覺響應,且具有較強的噪 聲魯棒性,伽馬通濾波器是一組用來模擬耳蝸頻率分解特點的濾波器模型,可以用于音頻信號的分解[19]。GFCC特征參數的提取過程類似于MFCC,在處理過程中將伽馬通濾波器組代替Mel濾波器組,其時域表達式為
g(f,t)=tn-1e-2πSitcos(2πfi+?i)U(t),
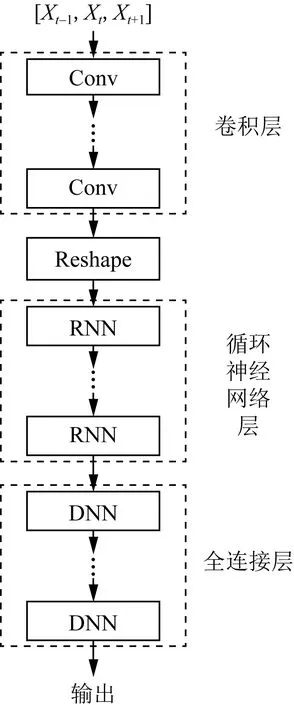
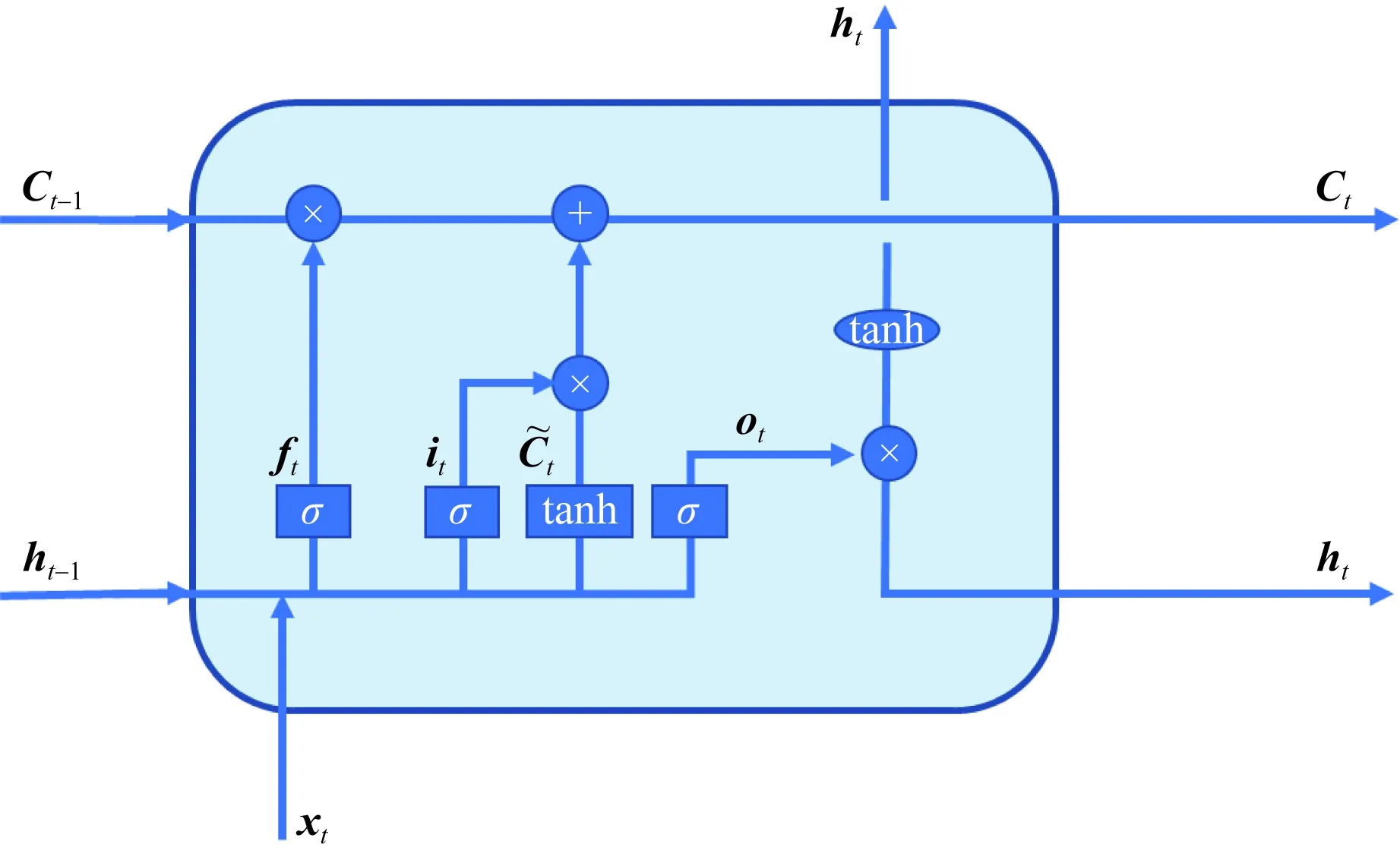
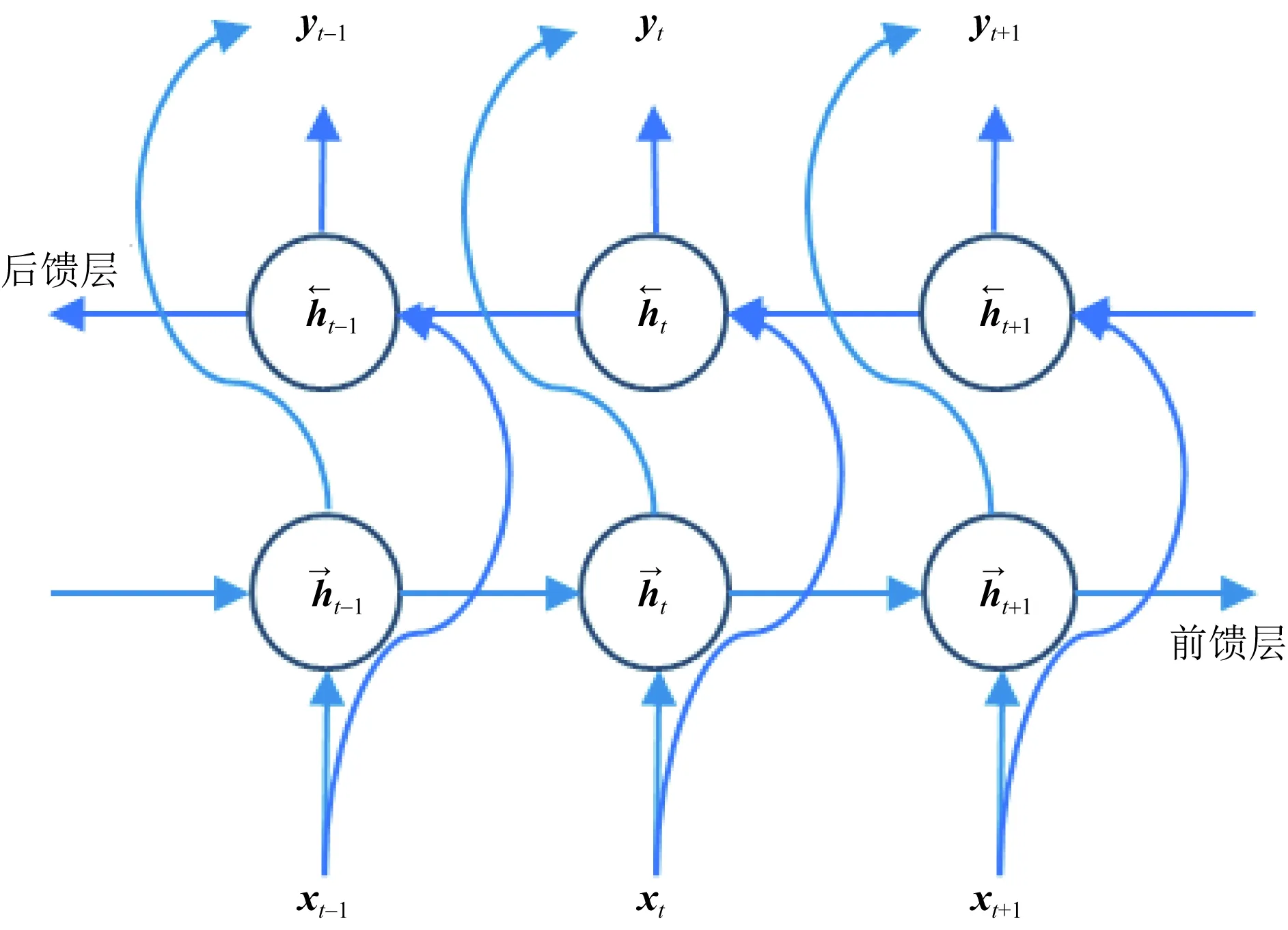
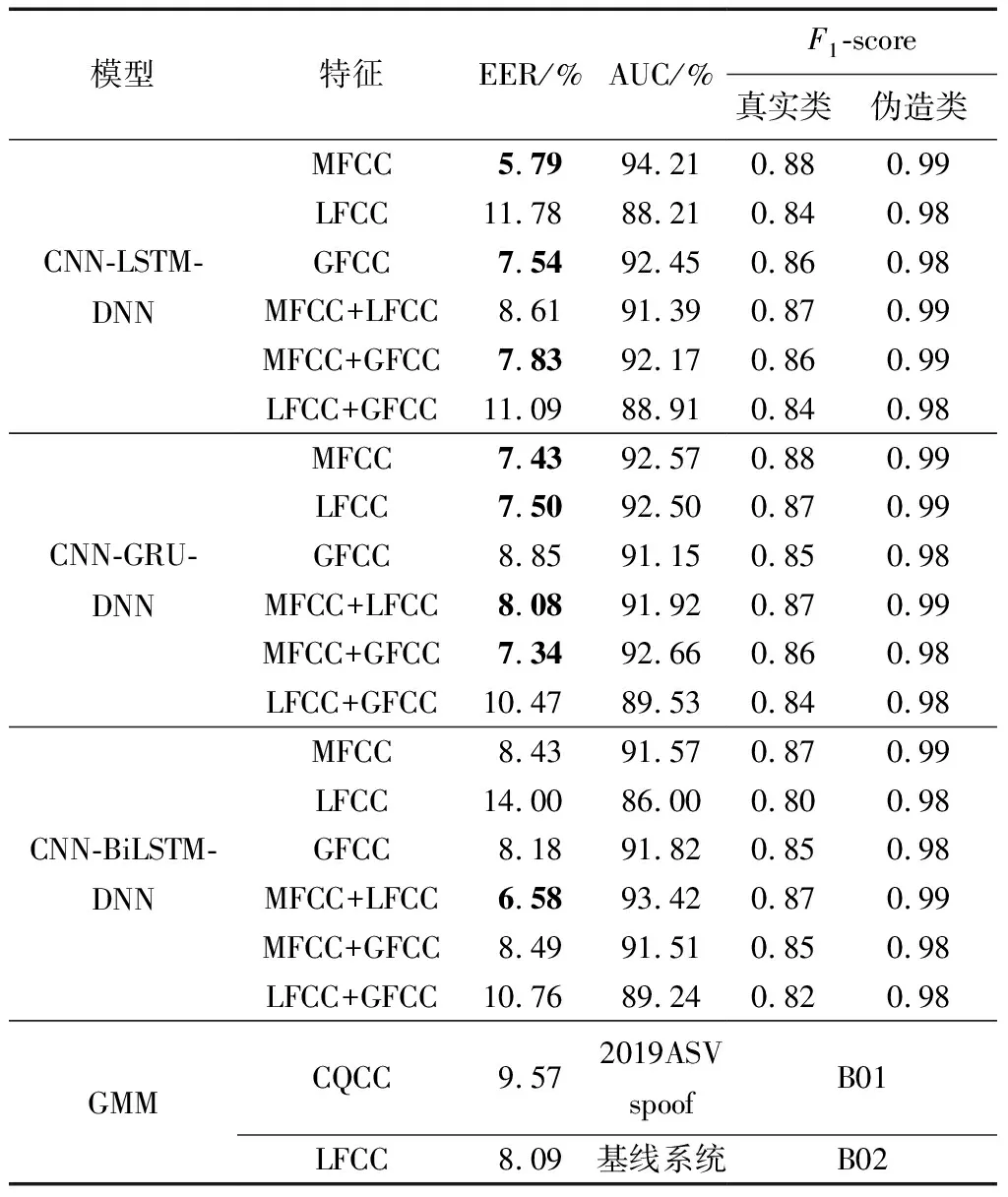
1≤i (6) 式(6)中:n為濾波器階數;Si為衰減因子;fi為中心頻率;?i為相位一般為0;U(t)為單位躍階函數;i為濾波器個數。 提取MFCC、LFCC、GFCC等單個特征及MFCC+LFCC、MFCC+GFCC、LFCC+GFCC等混合特征作為訓練神經網絡的語音特征。在單個特征提取過程中,特征維度設置為20維,選擇二維離散余弦變換,選擇窗的長度為25 ms的漢寧窗,每50幀語音為特征長度組成一個序列。混合特征提取分別設置單個特征維度為20維,選擇二維離散余弦變換,選擇窗的長度為25 ms的漢寧窗,單個特征長度為25幀,使用vstack函數將兩種單個特征組合在一起形成一個50幀語音為特征長度,維度為20的序列。 本文中提出的基于CNN-RNN-DNN網絡的混合網絡模型包括CNN-LSTM-DNN、CNN-GRU-DNN、CNN-BiLSTM-DNN,其結構如圖3所示。 圖3 混合網絡結構Fig.3 Fusion model structure 以MFCC特征為例,將提取到的MFCC特征X(n)中的隨機特征[Xt-1,Xt,Xt+1],其中每一個特征參數使用python中的reshape函數處理使其具有4個維度依次為:樣本個數、高度、寬度、通道數,然后輸入到卷積層,經過兩次卷積操作后輸入到池化層進行下采樣處理隨后設置Dropout隨機丟棄一部分神經節點防止過擬合,再進行卷積和Dropout操作,輸入到池化層最后經過歸一化層和Flatten層輸出給reshape通過調整網絡參數后輸出特征向量為yi然后輸入RNN網絡部分。RNN部分三種混合網絡分別為LSTM、GRU、Bi-LSTM網絡,一共設置兩層。數據通過RNN部分后經過Dropout和歸一化層最后輸出到Dense層進行二分類(真實類,偽造類)輸出。 1.3.1 卷積神經網絡(CNN) 標準的卷積神經網絡由卷積層、池化層、全連接層、激活函數構成,卷積層由多個卷積核組成,其目的是學習輸入數據的特征;池化層的目的是通過降低特征映射的分辨率來實現偏移不變性;全連接層則充當分類器的作用;激活函數通常包括sigmoid、tanh、ReLU[13,20-21]。圖4所示為本文設置的CNN網絡的結構。可由式(7)表示: (7) 式(7)中:N為卷積核個數。 CNN網絡模型在進行語音邏輯攻擊檢測時,輸入的語音特征xi為[Xt-1,Xt,Xt+1]經過卷積核kij的卷積操作后輸出的yi為[Yt-1,Yt,Yt+1],其中i為濾波器的編號,偏差為bi, *為卷積操作,f為激活函數本文使用ReLU。 Conv.卷積層;Maxpooling最大池化層;Dense全連接層 圖4 卷積神經網絡結構Fig.4 CNN network structure 1.3.2 長短時記憶神經網絡(LSTM) LSTM網絡結構由一系列的記憶單元所組成,圖5所示為LSTM的記憶單元結構,在時間步長t處,LSTM表示[9,22]為 ft=σ(Wf[ht-1,xt]+bf) (8) it=σ(Wi[ht-1,xt]+bc) (9) (10) (11) ot=σ(Wo[ht-1,xt]+bo) (12) ht=ot*tanh(Ct) (13) 圖5 LSTM記憶單元Fig.5 LSTM memory cell 在CNN-LSTM-DNN網絡模型中,語音特征經過卷積處理后輸出yi然后輸入到LSTM層進行前向計算,LSTM公式中的輸入特征xt=yi,過計算后將最后一個時刻的隱藏向量輸入到DNN網絡中進行分類處理,判斷真實類還是偽造類。 1.3.3 門控循環神經單元(GRU) GRU與LSTM的結構相似但是結構更簡單GRU通過直接在當前網絡的狀態ht和上一時刻網絡的狀態ht-1之間添加一個線性的依賴關系,來解決梯度消失和梯度爆炸的問題[23],GRU計算公式為 rt=σ(Wxrxt+Whrht-1+br) (14) zt=σ(Wxhxt+Whzht-1+bz) (15) (16) (17) 式中:rt、zt分別為重置門、更新門;Wxr、Wxh、Whr分別為輸入向量到重置門的權重、輸入向量到輸出向量的權重、輸出向量到重置門的權重;br、bz、bh分別為重置門、更新門輸出向量的偏置向量;⊙表示操作矩陣中對應的元素相乘。 在CNN-GRU-DNN網絡中,GRU網絡部分接收經過卷積處理過的特征yi作為輸入特征即xt=yi,GRU網絡進行前向傳播可由式(14)~式(15)表示,其中的rt通過計算能夠將新信息與前一時刻的記憶ht-1結合,zt與ht-1的矩陣相乘表示前一個記憶單元保留的最終記憶信息。輸入特征yi經過GRU網絡計算后得到最后一個時間步的特征向量,后輸入到DNN網絡層進行分類。 1.3.4 雙向長短時記憶循環網絡(Bi-LSTM) Bi-LSTM網絡由前饋LSTM和后饋LSTM組成,這種結構允許網絡在每個時間步長都有關于向前和向后的序列信息,能夠解決標準RNN網絡在處理時序過程中忽略上下文關系的問題[24-25]。Bi-LSTM網絡計算公式為 圖6 GRU記憶單元Fig.6 GRU memory cell (18) (19) (20) 圖7 BI-LSTM網絡結構Fig.7 BI-LSTM network structure 基于Ubuntu18.04.4LTS系統,使用Jupyter Notebook軟件運行環境,Python版本為3.6, tensorflow2.0深度學習框架,硬件配置采用Intel Xeon(R) Gold 6132 CPU處理器,NVIDIA Tesla P4顯卡。 針對語音邏輯訪問攻擊進行檢測,采用ASVspoof2019LA場景下的訓練集作為本次實驗的數據集,該數據集為英國愛丁堡大學、法國國家信息與自動化研究所、日本NEC等組織共同發起的ASVspoof挑戰賽官方用數據集,由20 名(8男12女)不同說話人組成,采樣率為16 kHz,共計23 580個音頻文件。該數據集是目前世界上偽造語音檢測的主要數據集,其語音偽造方法由4種語音合成算法和2種語音轉換算法生成,為目前主流的語音偽造方法,具有廣泛的代表性[3]。 提取語音特征后得到特征數據并將特征數據劃分為訓練集(60%)、驗證集(20%)和測試集(20%),表1給出本次實驗所劃分特征數據集詳細信息。 表1 劃分數據集詳細信息(特征個數)Table 1 Dataset used in the experiment(number of features) 使用基于CNN-RNN-DNN網絡的CNN-LSTM-DNN、CNN-GRU-DNN、CNN-BiLSTM三種混合網絡模型對提取到的MFCC、LFCC、GFCC、MFCC+LFCC、MFCC+GFCC、LFCC+GFCC進行實驗。由于單獨的神經網絡模型在處理語音信號問題上有所局限性,如CNN網絡能夠充分提取語音頻譜的偽影信息從而區分出偽造語音但是卻忽略了語音的時序性,RNN網絡則是處理時序關系常用的神經網絡,但是其提取頻譜信息能力較CNN差[12-13]。為了適應語音邏輯訪問攻擊檢測任務,更好地區分出偽造語音和真實語音,首先使用CNN網絡充當特征提取器,充分提取語音頻譜信息,再按幀輸入RNN網絡模型中來解決語音信號的時序問題,最后利用Dense網絡來進行真偽類別分類,設置的網絡參數結構如表2所示。 輸入的數據為(X,50,20,1),X為對應特征訓練集中特征數據的個數。網絡第1層設置32個輸出通道及3×3的卷積核,激活函數采用ReLU;第2層為具有64個隱藏節點的卷積層,卷積核大小為3×3,激活函數采用ReLU;第3層對經過兩次卷積處理的數據進行池化,此處采用最大池化,隨后第四層設置Dropout層隨機丟棄50%的神經節點防止過擬合;第5層設置隱藏節點為64的卷積層,卷積核為3×3,激活函數采用ReLU;第6層為Dropout;第7層為128個隱藏節點的卷積層,隨后經過最大池化,歸一化處理最后經過Flatten傳遞給變形層,數據經過變形處理后流入RNN部分,RNN部分分別采用LSTM、GRU、BiLSTM 3種網絡,共設置了兩層,隱藏節點分別為64和128,激活函數采用ReLU。隨后進行Dropout處理,丟棄50%神經節點后進行歸一化處理。Dense層設置為兩層,第1層隱藏節點為256,激活函數為ReLU,第2層激活函數為softmax,兩層Dense之間先后添加了Dropout和歸一化層。網絡的迭代周期設置為1000,batch-sizes設置為512即網絡一次訓練512個數據,優化器使用Adam,損失函數采用稀疏分類交叉熵。 表2 網絡參數結構Table 2 Network parameter structure 偽造語音檢驗中等錯誤率(equal error rate, EER)是常用的評價模型好壞的標準,在ASVspoof2015-2019挑戰賽中都被用作評判標準[3,26]。等錯誤率是指錯誤拒絕率和錯誤接受率相等時的數值,本文研究中使用Python中metrics函數計算等錯誤率。 AUC(area under the curve of ROC, AUC)是衡量二分類系統性能的標準,其數值越接近1,說明分類器性能越好[27]。本文研究中AUC數值計算采用Python中sklearn包的AUC函數計算。 F1分數(F1-score)是分類問題的一個衡量指標,它是精確率和召回率的調和平均數,最大為1,最小為0,F1-score越大說明模型質量越高[28]。本文研究中采用classification_report函數計算。 CNN-LSTM-DNN、CNN-GRU-DNN、CNN-BiLSTM-DNN 3種混合網絡模型對提取到的6種特征的實驗結果如表3所示。 AUC及F1-score指標均為衡量模型性能好壞的指標,兩種指標越接近1說明模型性能越好由兩種指標可以看出CNN-RNN-DNN模型系統具有良好的區分性能,AUC均在86%以上,對真實類語音區分準確度在80%以上,對偽造類語音區分度在98%以上,說明該系統可有效檢測邏輯攻擊偽造語音。其中CLDNN混合網絡與MFCC特征組合表現最好,AUC指標為94.21%,對真實類區分準確度為88%,對偽造類區分準確度為99%。 從等錯誤率指標分析,整體來看18種組合中EER指標共有13對組合超過B01基線系統,其中有8對超過B02基線系統(8.09%),如表3中加粗字體所示。其中表現最為突出的為CNN-LSTM-DNN混合網絡+MFCC特征,其等錯誤率為5.79%比B02基線系統低28.43%。 表3 邏輯訪問攻擊檢測實驗結果Table 3 Logical access attack detection experiment results 在模型選擇上總體來看表現最優的為CNN-GRU-DNN混合網絡,其對6種特征的平均等錯誤率為8.28%,平均AUC為91.72%。 在聲學特征的選取上,單個特征表現最突出的是MFCC特征其平均等錯誤率為7.22%,平均AUC為92.78%。混合特征中表現最突出為MFCC+LFCC,平均等錯誤率為7.76%,平均AUC為92.24%。 綜上所述,基于CNN-RNN-DNN網絡系統對邏輯攻擊檢測準確率高,穩定性好。其中CNN-LSTM-DNN混合網絡和MFCC組合取得最好的結果,在模型選取中CNN-GRU-DNN混合網絡平均測試結果表現最優。CNN-BiLSTM-DNN混合網絡對混合特征測試的結果最好。聲學特征的選取上單個特征中MFCC平均測試結果最好,混合特征中MFCC+LFCC平均測試結果最佳。 為驗證本文所提混合網絡模型的優點,增加了其與CNN、LSTM、GRU、Bi-LSTM等單獨神經網絡模型的對比實驗。對比實驗采用MFCC特征及MFCC+LFCC混合特征作為實驗用語音特征。對比實驗網絡參數按照CNN-RNN-DNN網絡中相應網絡設置,控制其他變量。表4給出了本次對比實驗的結果。 比較設置的CNN、LSTM、GRU、Bi-LSTM這幾種單獨神經網絡的實驗結果與本文所提方法的實驗結果,選取語音特征為MFCC時,對比模型中僅有CNN網絡超過本文所提方法的平均值。選取的語音特征為MFCC+LFCC時4種對比網絡均比本文所提方法要差。實驗結果表明,在邏輯訪問攻擊場景下,CNN-RNN-DNN網絡模型較其他模型有一定的性能提升。 表4 對比實驗結果Table 4 Comparative experiment results 提出了基于CNN-RNN-DNN網絡的3種混合網絡模型用于邏輯訪問攻擊語音檢測。這3種混合神經網絡模型能夠對提取到的特征有效分類,性能表現優秀。對提取到的6種聲學特征進行實驗結果表明18種組合中有13種超過B01基線系統,8種超過B02基線系統,其中CNN-LSTM-DNN和MFCC組合取得最好效果,在特征選擇上MFCC及MFCC+LFCC更為適合此混合網絡。通過對比實驗可知CNN-RNN-DNN網絡較其他模型表現更優,其原因在于混合網絡融合了單獨網絡的優點,CNN進行下采樣捕捉細節特征,RNN部分則解決語音長時依賴問題,結果證明CNN-RNN-DNN網絡系統能夠有效應用于語音邏輯攻擊檢測任務中,未來的工作將集中在模型的結構優化及深層特征的提取上,進一步提高準確率。1.2 神經網絡對語音特征的處理
1.3 相關網絡模型

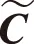



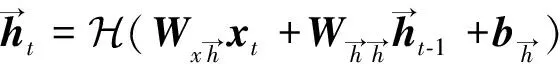

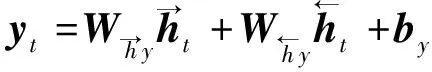

2 邏輯訪問攻擊檢測實驗
2.1 實驗環境
2.2 數據庫

2.3 實驗參數設置

3 實驗結果及分析
3.1 評價方法
3.2 實驗結果分析
3.3 不同模型比較分析

4 結論
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
