一種基于V-TGRU模型的資源調度算法
2022-07-25 13:52:06常曉潔張華
浙江大學學報(理學版) 2022年4期
常曉潔,張華
(浙江大學信息技術中心,浙江 杭州 310058)
云計算是一種基于可配置網絡、存儲、服務器、應用軟件等計算資源共享池進行計算并按需分配和付費的服務模型[1-4]。云計算環境下的資源分配和調度是云計算服務領域的核心問題。隨著云計算技術的不斷發展和應用需求的持續提高,云計算環境的復雜性日益加劇,機器選擇過程中基于任務應用行為[5]、故障表現[6]、能源效率[7]、親和性[8]等最優調度算法的影響因素研究正吸引越來越多學者的興趣。機器學習是依靠過去的經驗數據創建模型的能力[9-10],調度算法的優化需通過機器學習組件提高復雜決策的準確性和有效性[11]。文獻[12-13]提出了基于決策樹、支持向量機、神經網絡等經典模型的機器學習算法在云計算場景中的應用。文獻[14-15]討論了應用強化的機器學習算法進行權限管理和資源分配。文獻[16-20]分別介紹了針對單一資源變量,如CPU或資源請求輸入門控循環單元(gate recurrent unit,GRU)、長短期記憶(long short term memory,LSTM)網絡以及改進離散檢測GRU(IGRU-SD)算法進行資源預測。上述研究均基于單變量環境下的優化策略,在實際應用過程中則需考慮精度、訓練時間、參數量、特性數量和變量之間的關系等。
文獻[21]研究了虛擬化服務器集群中電源優化的動態配置方法;文獻[22]研究了基于信任驅動和服務質量需求的工作流聚類分析調度方法;文獻[23]研究了云計算環境下基于分簇的資源調度算法;文獻[24]研究了基于分布式深度學習的多個異構神經網絡調度模型。這些方法對云資源的充分調度具有一定借鑒意義,但在任務調度過程中,尚存在大量閑散的、未被利用的計算資源以及任務的反復調度所造成的資源浪費。
針對上述云計算環境下資源調度算法的問題,提出在私有云計算環境下基于機器學習變量傳輸控制GRU(V-TGRU)模型的資源預測算法。
1 資源預測模型
1.1 數據預處理

1.2 V-TGRU算法模型
GRU算法的記憶較循環神經網絡(recurrent neural network,RNN)算法更長,訓練速度較LSTM網絡算法更快,但仍存在需要預處理數據包和內存使用率高等問題。為此,引入變量門控遞歸單元,包括1個調整新輸入與前內存合并的重置器、1個控制前內存保存的更新門Z。
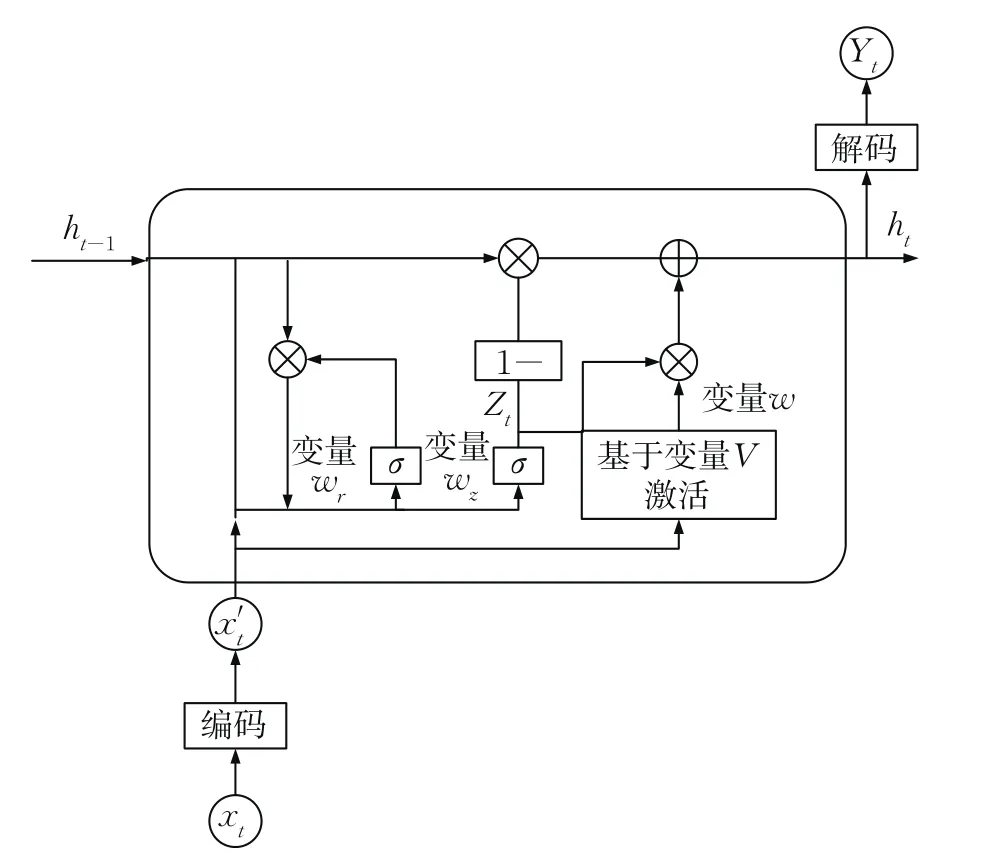
圖1 V-TGRU模型結構Fig.1 V-TGRU model structure
在V-TGRU模型框架中,提出了一種具有雙向結構和門控遞歸單元變量w的增強型V-TGRU網絡。首先,將雙向結構應用于捕獲輸出,從而提高GRU模型的表達能力。所采用的加權特征平均法簡單地導出了每個時間點帶中心雙加權方案的平均向量。其由兩部分組成:雙向GRU輸出和加權平均特征。變量w和變量激活指變量w中的權重和激活功能與GRU相同,但V-TGRU中的權重w和激活功能采用二值化表征。此外,V-TGRU用編碼器自動進行預處理。編碼器中輸入的為壓縮數據,通常比原始輸入數據更規整,從而降低內存占用率,解決GRU算法需要預處理數據包和內存使用率高的問題。
V-TGRU預測模型[25]的算法流程:
輸入:采集到的N個實例資源占用情況矢量包Xi={XID,Xlen,Xin,Xout,Xcpu,Xmem,Xnet,Xtk}。
輸出:測試數據集的評估結果。
步驟1創建編碼器模型。
(1)添加第一個編碼器層e1單元的tanh觸發;
(2)添加第二個編碼器層e2單元的tanh觸發。
步驟2創建V-TGRU模型。
(1)添加第一個V-TGRU層l1單元,退出dropout為d1且循環退出dropout為r1;
(2)添加第一個V-TGRU層l2單元,退出dropout為d2且循環退出dropout為r2。
步驟3訓練和驗證模型。
(1)當訓練模型驗證集上的誤差不滿足早停法條件時;
(2)當訓練數據集不為空時;
(3)將計算周期數據集作為模型輸入;
(4)計算H(p,q)分類交叉熵損失函數;
(5)用隨機梯度下降優化算法更新權重和偏差;
(6)用驗證集驗證輸出的訓練模型。
步驟4測試模型。
(1)用測試數據集測試已優化的超參數;
(2)返回測試數據集的評估結果。
編碼器編碼:X=[x1,x2,…,xp]T為編碼器的輸入數據矢量,為編碼器的輸出數據矢量。利用tanh激活功能,最終接收的節點值為
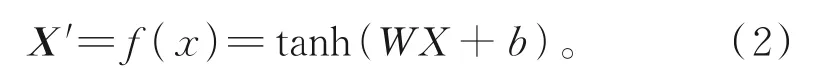
用編碼器對標準化后的矩陣X和Y編碼,得到歷史時段占用資源的時間序列矩陣和資源池的性能時間序列矩陣,其中p>q。
為提高訓練過程的穩定性和收斂速度,采用批量梯度下降法進行訓練,同時,采用誤差反向傳播法調整參數。對于GRU模型,有2種反向傳播方式:用最后一個時刻的值作為輸出和用各時刻的平均值作為輸出,參數更新式為
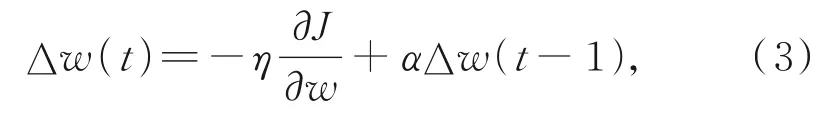
其中,Δw(t)為第t次迭代的加權更新,η為算法的學習率,0≤α<1為動量項,J為成本函數。
V-TGRU在最后一個時間點的隱藏輸出可代表任務資源的占用情況,但在V-TGRU中,序列中間區域的信息可能會丟失。考慮序列的起始和結束區域對后向GRU和前向GRU的輸出貢獻很大,因此,引入加權特征平均提供局部特征序列tk的另一種觀點。平均特征序列向量為

其中,wk表示迭代權值,k表示隨機時間步長索引。為突出中間局部特征的影響,迭代權值設計為
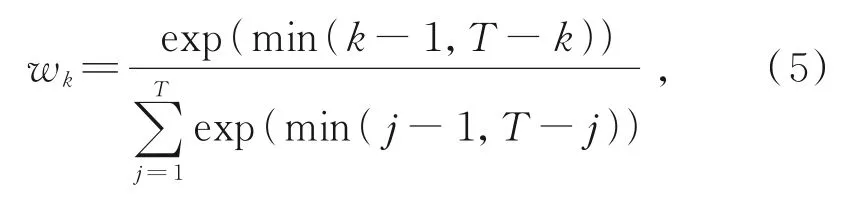
其中,j表示隨機時間步長參數量,T表示參數總量。
2 基于預測結果的調度模型
本文提出的基于預測結果的調度模型將在調度過程中結合多實例的現在及未來狀態值和資源池的現在及未來狀態值、實例調度的網絡傳輸時間以及CPU資源計算時間,以實例調度次數最少化、調度總時間最小以及資源預測調度最精確為調度標準。因此先對資源池和實例進行數據預處理,并將預處理數據輸入V-TGRU預測模型,得到預測結果;然后按照矢量參數優先級對實例進行排序,同時將預測后的資源池進行聚類分級,優先調度優先級更高的實例至更優的資源池聚類。調度算法流程如下:


算法(1)~(3),通過聚類方法對資源池進行預處理。(4)~(6),按照截止時間、現在和預測情況對實例進行排序,首先處理截止時間較近、資源情況緊缺的實例。(7)~(10),根據預測的實例運行情況和資源池占用情況,預判傳輸、調度及運行情況。(11)和(12),匯總預判情況,對實例運行情況進行排序,將最接近截止時間、最急需的實例優先調度到任務負載最少的資源池。
3 實驗結果分析
3.1 實驗環境
硬件環境:華為RH2288V3,CPU規格E5-2680V4×2,56核,內存 128 GB和384 GB,硬盤規格 800 G[ssd]×12和 6 T[sata,7200 r·min-1]×12,共100個虛擬節點,200個實例,通過觀察多個實例的24 h歷史數據,整理得到每個實例對應資源需求的時間曲線,描述每個實例每天每個采樣點所需的對應資源數量。每隔5 min采集一次,每天288個采集點,連續采集30 d。
3.2 結果分析
3.2.1 預測結果對比
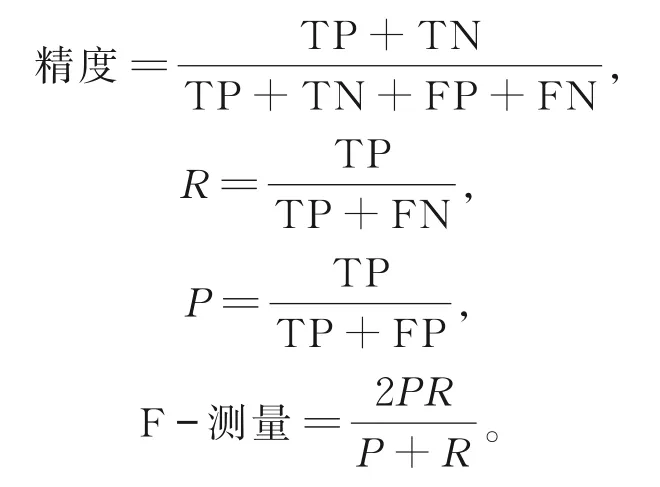
對采集到的數據進行訓練和建模,預測數據曲線的走勢,并根據預測結果進行資源調度,通過調度實例的精度和 F-測量[26],判斷 V-TGRU、GRU、LSTM及IGRU-SD模型預判的準確度。
表1中,“正”表示需要調度的實例;“負”表示不需要調度的實例,TP為實際需要調度,預測也需要調度的實例數;FN為實際需要調度而預測不需要調度的實例數;FP為實際不需要調度而預測需要調度的實例數;TN為實際不需要調度,預測也不需要調度的實例數。

表1 混淆矩陣Table 1 Confusion matrix
4個模型最優、平均及最差狀態對比見表2。由表2可知,基于變量門控編碼的雙向V-TGRU模型較另外3種資源預測模型更準確,也更穩定。
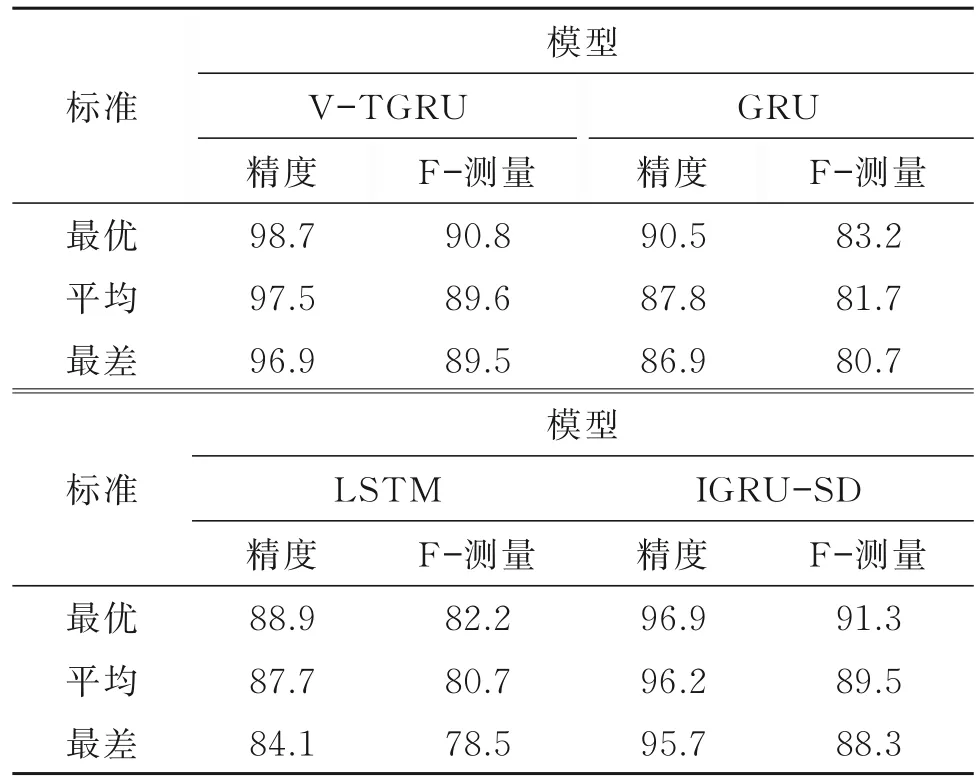
表2 精度與F-測量對比Table 2 Accuracy vs.F-measure
3.2.2 調度結果對比
V-TGRU與GRU、LSTM、IGRU-SD三種資源模型預測下的調度以及不進行預測的自適應調度算法(adaptive scheduling algorithm,ASQ)的對比見圖2~圖4。通過對比多任務下的調度執行時間、調度等待時間和調度次數,綜合評價調度算法的效率。
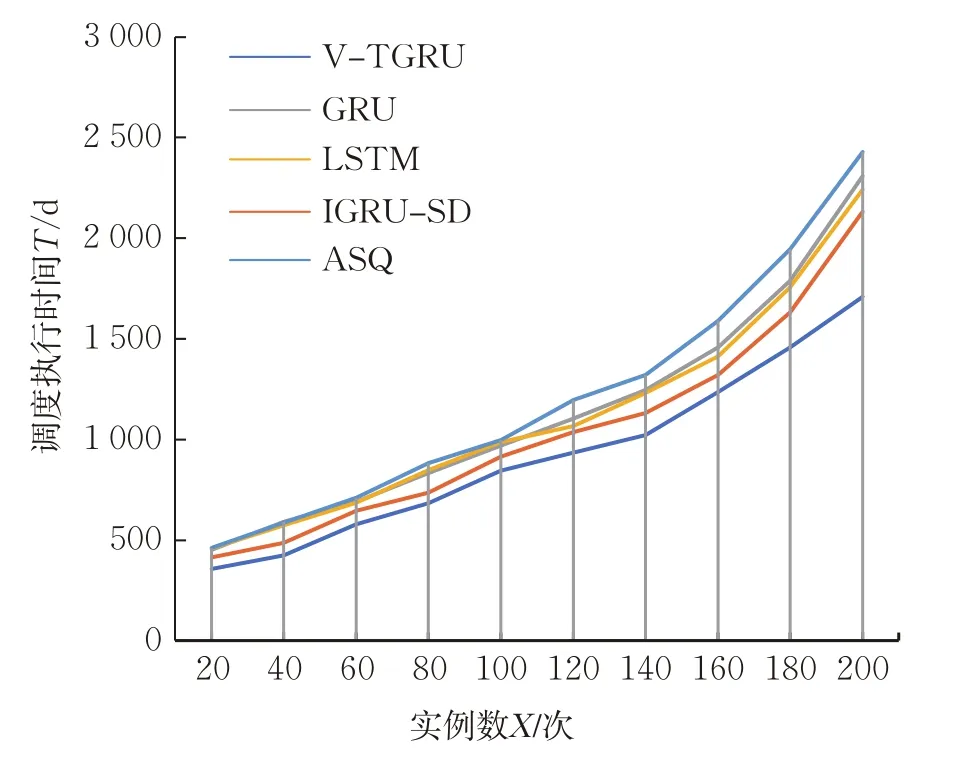
圖2 多任務實例調度執行時間Fig.2 Execution time of multi instance task scheduling
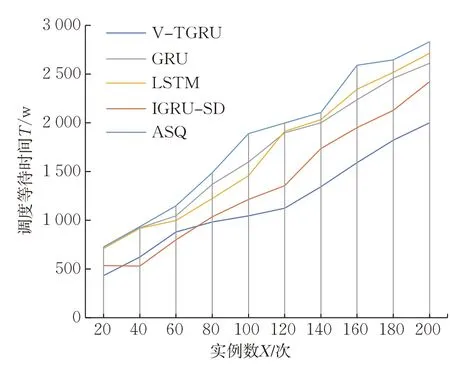
圖3 多任務實例調度等待時間Fig.3 Waiting time of multi instance task scheduling
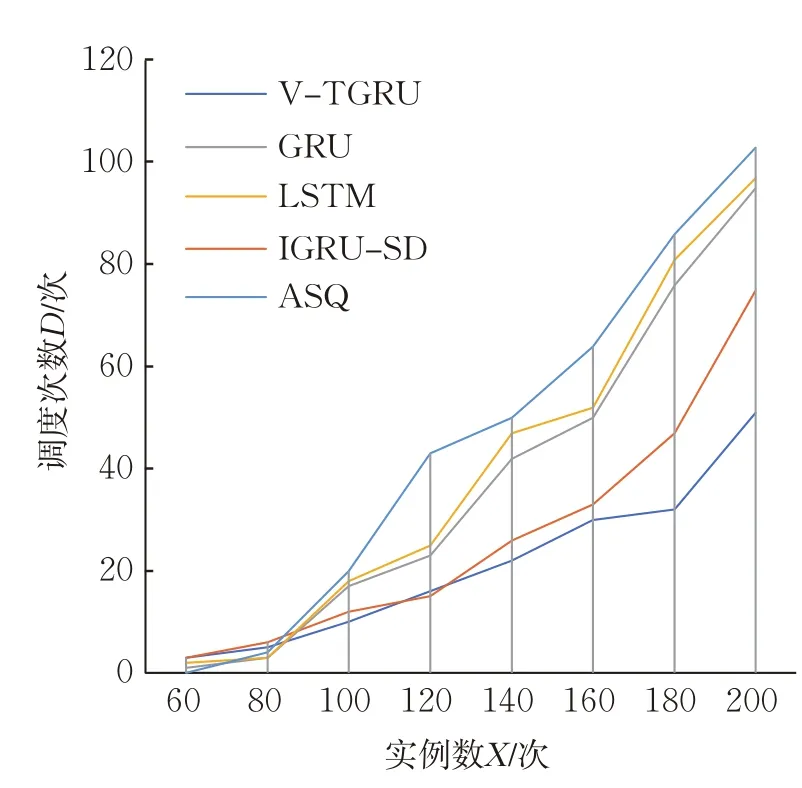
圖4 多任務實例調度次數Fig.4 Times of multi instance task scheduling
由圖2~圖4可知,隨著實例數的逐漸增多,4種預測調度算法和ASQ的調度執行時間呈增加趨勢,但每個任務的平均調度執行時間均呈不同程度的下降趨勢,這是因為當需要調度的實例數在一定范圍內增多時,并發處理能力令調度執行時間縮短。由于V-TGRU預測的準確率更高,使無用的調度大大減少,降低了調度過程中的資源浪費,同時由于更及時地調度了所在虛擬計算節點資源相對緊張的實例,提高了實例的穩定性和運行性能,保障了云平臺資源的利用率和可靠性。
4 結 語
經實驗測試,證明本文算法能更精確預測未來時效內實例占用資源的狀況、運行狀態以及資源池被占用情況,通過將更準確的預測結果和實時采集到的狀態數據相結合進行綜合分析調度,能更有效地完成實例對資源的預判選擇,減少調度時間,避免實例的反復調度,節省因云資源的強制占用和反復調度消耗的資源及帶寬,保證實例更穩定運行,提升用戶滿意度。下一步工作重點將積累并整合大量運維數據,研究更加高效的調度策略,進一步降低資源浪費,提升調度性能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
江蘇安全生產(2023年1期)2023-02-08 05:58:38
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
數學物理學報(2020年2期)2020-06-02 11:29:24
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
資源再生(2017年3期)2017-06-01 12:20:59
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
