基于改進FaceNet的飛行器結構裂紋識別方法
2022-08-01 07:29:56呂帥帥楊宇王彬文殷晨飛
航空學報 2022年6期
呂帥帥,楊宇,王彬文,殷晨飛
中國飛機強度研究所,西安 710065
金屬裂紋是航空結構的一種常見損傷形式。在航空結構疲勞試驗中及時發現并跟蹤損傷擴展過程,能夠暴露航空結構設計的薄弱環節,支撐結構強度和完整性評估,同時也為航空結構維修大綱和維修手冊編寫提供必要的技術數據。目前發現裂紋主要依靠人工目視檢查,以及定期的無損檢測(如渦流、超聲等)。但是飛機結構內部空間狹小、大量傳感器線纜干擾,使得無損檢測人工操作極為不方便。另外,裂紋通常只在結構加載至高載狀態時才目視可見,而此時出于安全考慮,檢測人員是無法抵近檢查的。因此,傳統的人工無損檢測存在較大的損傷漏檢可能性。
隨著計算機視覺和機器人技術的發展和應用,機器視覺為飛機疲勞試驗中的裂紋自動化檢測提供了一條新的解決途徑。通過工業攝像頭和高精度運動系統(如機械臂、爬行機器人)定位檢測位置并獲取高清圖像,再應用目標檢測算法進行裂紋自動識別,可以大幅度降低人工在成本、實時性和危險性等方面的不利影響。
目前研究者主要采用單幀目標檢測算法進行裂紋識別,即在單張圖像內搜索裂紋。Ren等提出的Faster R-CNN算法和Redmon等提出的YOLO算法是典型的單幀目標識別架構,其差異體現在對檢測準確率和計算速度的不同側重。Deng、Du、Wang和楊晶晶等分別使用Faster R-CNN、YOLO等進行了混凝土結構和金屬結構的裂紋檢測,且獲得較高的檢測準確率。但是需要注意的是,被識別的裂紋主要是張開位移較大的混凝土裂紋和長度較長的金屬裂紋。全尺寸疲勞試驗中的裂紋長度、張開位移均較小,且金屬結構表面的紋理、劃痕、打磨痕跡等與這些微小裂紋的相似度極高,形成強烈的干擾。因此,單幀目標檢測算法并不適合于飛機全尺寸疲勞試驗中微小裂紋的識別。
另一種潛在的方法是采用基于兩幀圖像對比的相關性識別算法進行微小裂紋檢測。該類算法是以兩張圖像間特征的相關性為依據,判別兩者是否包含同一個檢測目標,分為特征提取和相關性計算兩個步驟。常用的特征提取方法包括多通道方向梯度直方圖、顏色命名算法、多特征集成尺度自適應算法和深度學習算法等,相關性計算則以基于傅里葉變換和核函數的計算方法為主。該類方法目前通常應用于目標跟蹤,即跟蹤已知對象的運動軌跡。但是這類算法無法直接應用于飛機全尺寸疲勞試驗,因為微小裂紋的尺寸相對于檢測區域存在2個數量級的差別,很難對圖像特征產生顯著影響。此外,常用的特征提取方法對圖像亮度、清晰度敏感,而全機疲勞試驗由于結構的不規則振動,無法保證圖像質量的一致性。
因此,本文提出了面向飛機全尺寸疲勞試驗的微小裂紋識別方法,其創新點體現為:① 針對劃痕、污損等廣泛存在的干擾因素,采用特征對比策略識別裂紋;② 針對微小裂紋與被檢測區域尺寸存在2個數量級差別這一矛盾,提出基于關鍵部位狀態對比的識別方法,首先根據疲勞裂紋萌生機理,設定重點檢測區域,然后將檢測區域劃分為4個部位,使得微小裂紋與檢測部位的幾何尺寸處于相同數量級;③ 為降低疲勞試驗中結構振動導致的清晰度、亮度變化等問題對裂紋識別準確率的影響,選取人臉識別模型FaceNet作為基礎架構,再根據裂紋數據集的結構特點,對FaceNet模型進行相應改進。
1 面向全尺寸疲勞試驗的裂紋檢測方法
1.1 檢測策略
本文應用特征對比的方法進行目標檢測。圖像間的特征能夠進行有效對比的前提是檢測目標與被拍攝區域不能存在跨數量級的尺寸差別。而在全尺寸結構試驗中,雖然飛機結構龐大,但是裂紋均是在結構細節處萌生,例如緊固件孔和非連續結構等應力集中區域。因此,本文采用基于關鍵部位狀態對比的策略進行裂紋識別。
例如根據結構受力分析可知,圖1中可能出現裂紋的關鍵部位為緊固件1~6的孔邊。為提高微小裂紋的檢出概率和裂紋在檢測圖像中的比例,本文將每個關鍵部位的周邊區域分為4個部分,每一部分作為一個檢測部位(如緊固件 1 所示)。通過對比每個檢測部位的實時采集圖像和無裂紋模板來發現裂紋。

圖1 全尺寸疲勞試驗中關鍵區域的檢測圖像示例Fig.1 Sample images of key areas in a full-scale fatigue test
1.2 基于改進FaceNet的裂紋檢測模型
FaceNet是一種基于深度學習的人臉識別模型,本文選擇FaceNet作為裂紋識別模型的基礎架構,因為該模型的核心是三元組損失。三元組損失的優勢在于細節識別,善于處理非同類、極相似樣本的分類問題,可支撐深度學習網絡提取僅對裂紋敏感的圖像特征,降低圖像質量變化對檢測結果的影響。
1.2.1 FaceNet模型
FaceNet實現人臉識別的基本原理為:利用深度學習網絡將輸入的人臉圖像映射至一個128維的歐氏特征空間,并計算不同圖像在新空間內的特征距離,特征距離小于類別判定閾值的兩張人臉圖像可被判定為同一個人。
FaceNet的基本結構如圖2所示,其中深度學習網絡采用已有的成熟網絡。該模型能夠實現高準確率人臉識別的根本原因在于提出了三元組損失的概念,并應用三元組損失對深度學習網絡進行訓練。
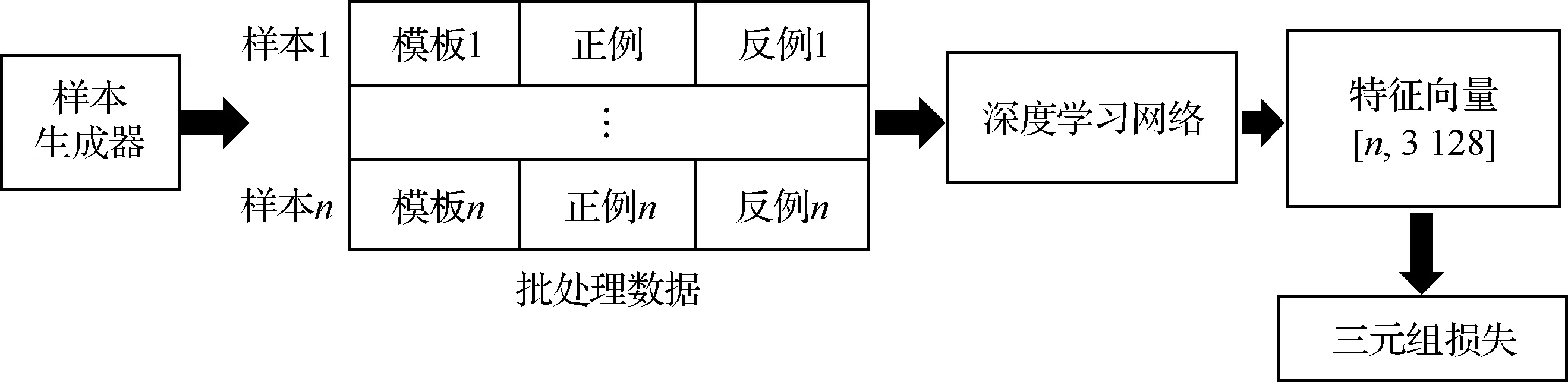
圖2 FaceNet模型的基本架構Fig.2 Basic architecture of FaceNet
人臉識別問題中的“三元組”指的是由模板-正例-反例三張圖片組成的一個數據樣本,其中模板和正例為同一個人在不同狀態下(如正臉、側臉)的兩張圖像、反例則為任意其他人的一張圖像。在訓練過程中,模型每次處理個樣本(記為一個批處理數據),每個樣本通過深度學習網絡提取特征,得到3個128維的特征向量。然后網絡根據特征向量計算批處理數據的三元組損失。三元組損失具體可表示為
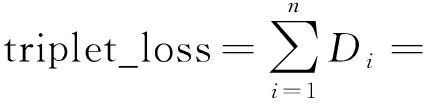
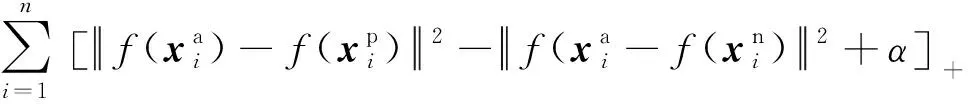
(1)
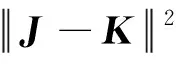
由式(1)可知,三元組損失的本質是在新的特征空間內,盡量減小模板和正例圖像間的特征距離,同時盡量增大模板和反例圖像的特征距離,并要求前者的距離值至少比后者的距離值小。也就是說,FaceNet通過三元組損失使深度學習網絡對比學習同一個人在不同狀態下(如正臉、側臉、不同表情)的共性特征和不同人間的差異特征,這使FaceNet提取的特征向量不易受人臉圖像狀態的影響,而對人臉的固有屬性更加敏感。
1.2.2 裂紋識別與人臉識別的差異分析
在復雜的全尺寸疲勞試驗環境中,針對同一檢測部位在不同時刻拍攝的圖像在亮度、清晰度和拍攝角度等方面均可能存在差異。深度學習模型必須能夠準確區分裂紋的產生和圖像質量的變化,即要求模型提取的特征不易受圖像質量影響,而對裂紋十分敏感。這與FaceNet模型中三元組損失的設計目標是一致的。因此本文選擇FaceNet作為裂紋識別的基礎架構。但是,裂紋識別與人臉識別問題有兩方面的差別:數據結構差異及由此引起的特征分布差異。
1) 數據結構的差異
在人臉識別問題中,若待識別數據包含個人,則每個人可看作一個類別,模型處理的是一個分類問題;而在裂紋識別問題中,無論訓練數據來自于多少個檢測部位,其均為一個二分類問題(有、無裂紋)。針對該問題,需對原FaceNet中的三元組樣本生成規則進行改進。
原FaceNet模型的樣本生成規則如圖3所示:① 從待分類的個人中隨機選擇兩個和,在的圖像中隨機抽取兩張作為模板和正例,在的圖像中隨機抽取一張作為反例,構成一個三元組樣本;② 重復步驟①至樣本數量達到設定要求;③ 計算所有樣本的正、反例距離差(見式(1)),并將大于0的所有樣本作為最終樣本。
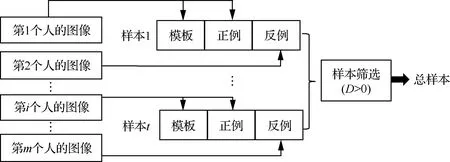
圖3 FaceNet的樣本生成規則Fig.3 FaceNet sample generation rules
改進FaceNet裂紋樣本的生成規則如圖4所示:① 針對第一個檢測部位,在所有無裂紋圖像中隨機抽取2張分別作為模板和正例,并在所有有裂紋圖像中隨機抽取一張作為反例,組成一個樣本;② 重復步驟①,直至檢測部位1的樣本數量達到設定要求;③ 計算檢測部位1中所有樣本的正、反例距離差(見式(1)),并將大于0的所有樣本作為位置1的最終樣本;④ 針對其余位置,仿照第一個檢測部位,重復以上操作,獲取每個部位的最終樣本;⑤ 所有部位的最終樣本組成總樣本,再分割成批處理數據進入深度學習模型參與訓練。
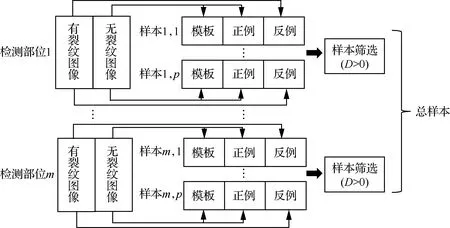
圖4 改進FaceNet的樣本生成規則Fig.4 Sample generation rules of improved FaceNet
2) 由數據結構差異引起的特征分布差異
對比兩種樣本生成規則可知:① 原FaceNet模型是對所有數據進行分類,改進后的模型是在每個檢測部位內部進行分類;② 原FaceNet模型是對每個類別進行聚類,而改進后的模型只對每個檢測部位的無裂紋圖像進行聚類。樣本生成規則的更改直接影響了模型提取特征的分布規律。圖5為原FaceNet模型在人臉分類數據集上提取特征的分布示例,其中數字表示第個人的人臉圖像,表示第個人圖像的類內距離,,表示第、兩個人的類間距離;圖6所示為改進FaceNet在裂紋數據集上提取的數據特征的分布示例,其中-crack、-uncrack分別表示裂紋數據樣本中第個部位的有、無裂紋圖像,1表示第個部位有、無裂紋圖像的類間距離,2表示第個部位無裂紋圖像的類內距離。需要指出的是,圖5和圖6中顯示的是原128維特征經過主成分分析降至2維后的分布狀態,降維會導致部分數據特征的改變,只能定性表示原特征的分布規律。
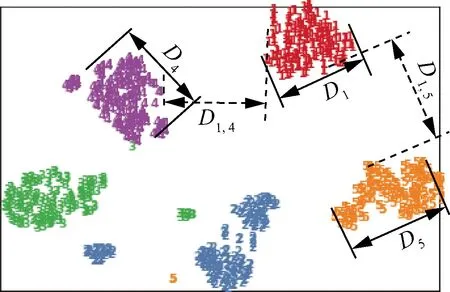
圖5 FaceNet提取特征的分布示例Fig.5 Distribution example of FaceNet extracted features
對比圖5和圖6可知,裂紋特征分布的規律性明顯低于人臉特征。其中最明顯的就是圖5中的類內距離整體小于類間距離,例如、、小于、。基于這一規律,原FaceNet模型的類別判定閾值計算可以轉化為一個簡單的線性問題;而在圖6中,數據特征的分布是高度非線性的,類別判定閾值的求取不再是一個線性問題,下面從兩個層面對該問題進行分析。
首先,各檢測部位有、無裂紋的判定閾值是不一致的,例如圖6中檢測部位1的判定閾值∈(,),部位3的判定閾值∈(,),而小于,也就是說無法通過線性計算的方法在各檢測部位間確定一個統一的判定閾值;其次,即使在一個檢測部位內部,判定閾值也無法直接求取。例如針對檢測部位2,小于,也就是說在新的樣本生成規則下,三元組損失只能保證每一張無裂紋圖像到任意一張有裂紋圖像的距離都大于該無裂紋圖像到其他任意無裂紋圖像的距離(例如>),卻無法保證1大于2,這是裂紋特征與原FaceNet模型提取特征的最大區別,該區別增加了特征分類問題的非線性度。
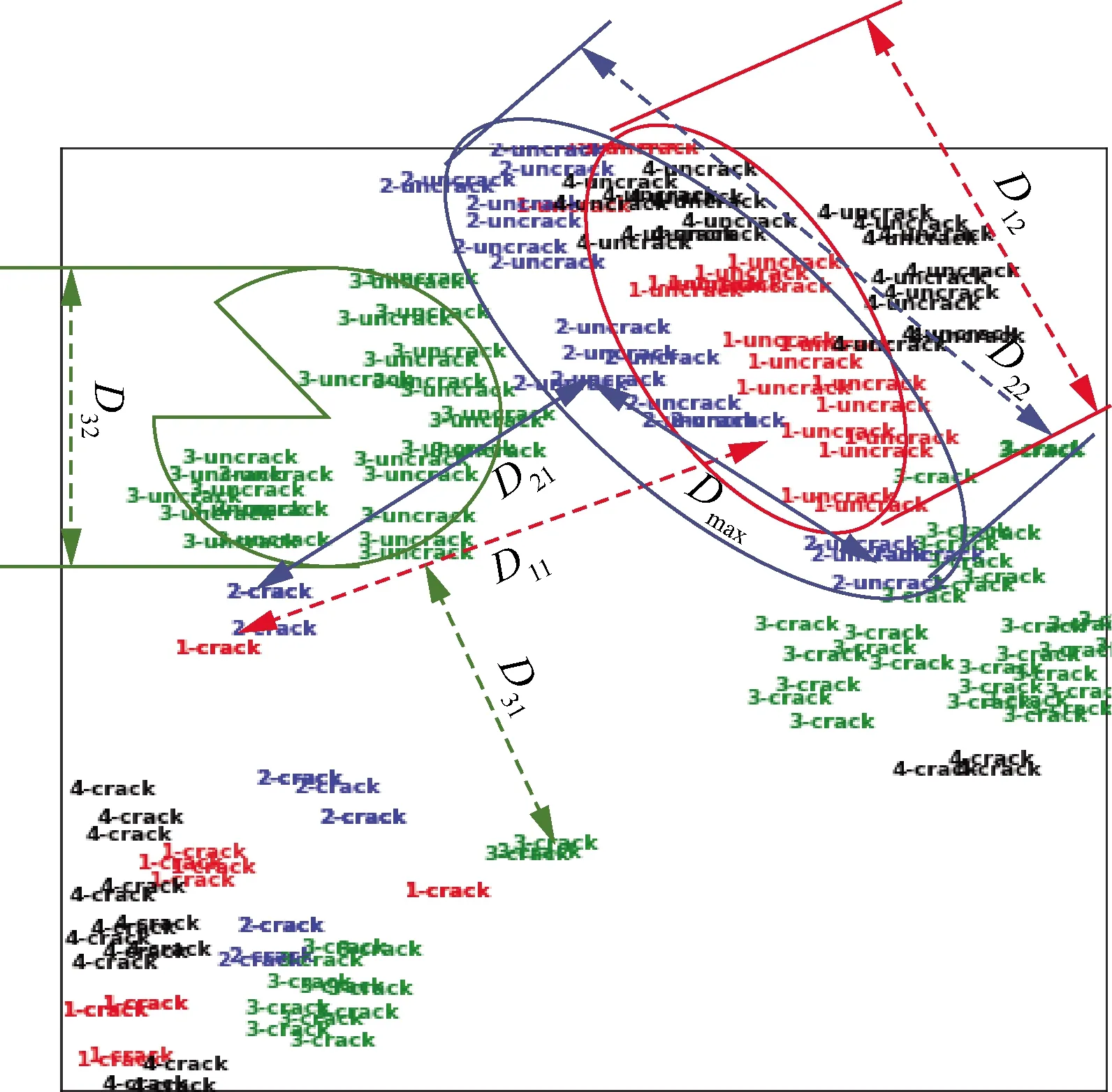
圖6 原FaceNet模型提取的裂紋特征的分布規律示意圖Fig.6 Schematic diagram of distribution of crack characteristics extracted from original FaceNet model
1.2.3 對現有FaceNet模型的改進
通過以上分析可知,更改樣本生成規則后,原FaceNet模型的架構和三元組損失已無法滿足裂紋識別任務的要求。因此,本文在原FaceNet模型后增加一個全連接層(2個神經元)直接進行樣本分類,同時在原損失函數中加入分類層的交叉熵損失,以在參數優化過程中統籌考慮特征分布和分類準確率。改進后的模型架構如圖7所示,原FaceNet模型輸出的3個128維特征向量先通過特征拼接形成兩個256維的拼接向量,再輸入全連接層進行分類。特征拼接的具體方法如圖8所示。
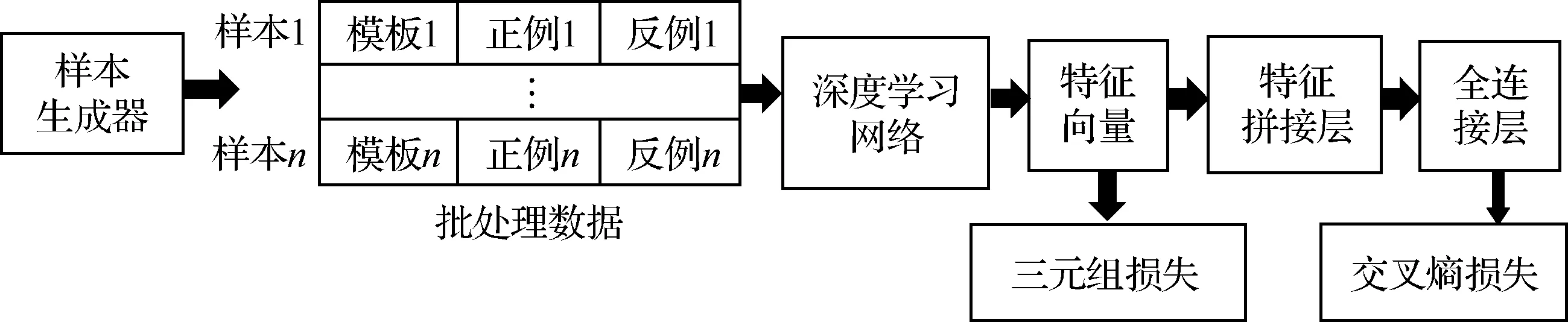
圖7 基于改進FaceNet的裂紋識別模型架構Fig.7 Framework of crack identification model based on improved FaceNet
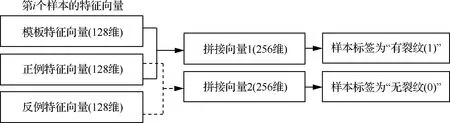
圖8 改進FaceNet中的特征拼接方法Fig.8 Feature mosaic method in improved FaceNet
改進FaceNet模型的損失函數具體可表示為
Loss=triplet_loss+cross_entropy_loss=
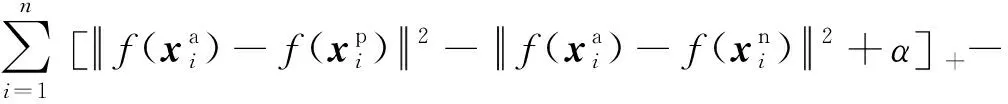
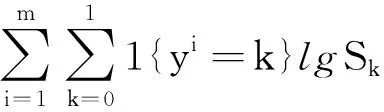
(2)
式中:cross_entropy_loss為交叉熵損失;為批處理數據中的分類樣本個數,=2;表示第個樣本標簽的真值;1{=}表示樣本標簽真值為時,系數為1,其他情況系數為0;為分類層第個神經元的輸出值。
2 試驗設計與結果分析
2.1 試驗設計
為豐富樣本類型,本文使用的數據集由兩類構成,第1類是全尺寸疲勞試驗的實時檢測圖像(如圖9(a)所示),這類數據的圖像像素為2 000萬,視場為200 mm×300 mm,物方分辨率為0.055 mm。裂紋為通過圖像處理手段制造的模擬裂紋。該類圖像共包括200個檢測部位,每個部位有24張圖像,所有圖像均由機械臂采集系統在艙內巡檢時自動拍攝,拍攝間隔時間為1 d,因此該類圖像代表了全尺寸疲勞試驗中待檢測圖像的質量水平。針對每個檢測位置,從24張圖像中隨機選擇10張添加模擬裂紋。
第2類樣本是金屬元件疲勞試驗中的裂紋圖像(如圖9(b)所示), 這類數據的圖像像素為200萬, 視場為33 mm×50 mm,物方分辨率為0.026 mm, 與全尺寸疲勞試驗圖像為同一量級。

圖9 疲勞試驗中的數據獲取方法Fig.9 Data acquisition method in fatigue test
通過15個試驗件的疲勞試驗共獲取80個檢測部位,每個檢測部位包含25張無裂紋圖像和12張真實裂紋圖像,每張圖像的拍攝間隔時間為2 s。由于元件疲勞試驗中的試驗件始終處于振動狀態,所以各圖像間會存在一定的光線和清晰度差異。
在280個檢測位置中隨機選擇210個作為訓練集、70個作為測試集。使用本文提出的改進FaceNet模型進行訓練,深度學習網絡的基礎模型選擇Inception V3,邊界距離設置為0.05,優化器為Adam,設置一個批處理數據包含40個三元組樣本,每200個批次為一個循環。經過2 100個循環后模型收斂,第2 100個循環的平均三元組損失為0,平均交叉熵損失為0.005。
圖10所示為改進FaceNet模型在部分訓練集上提取的128維特征的分布狀態(通過主成分分析法降維至2維)。對比圖6可知,圖10中每個檢測位置的類間距離(有裂紋圖像到無裂紋圖像的最小距離)均大于類內距離(無裂紋圖像間的最大距離),特征分布的規律性明顯增強。
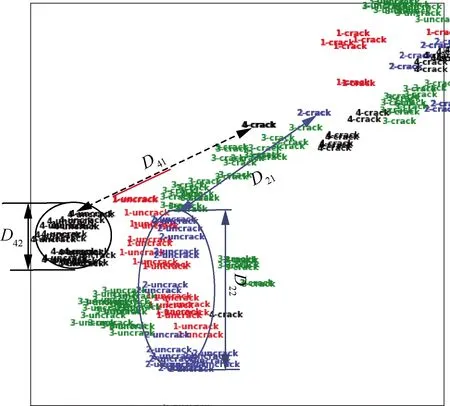
圖10 改進FaceNet提取裂紋特征的分布規律示意圖Fig.10 Schematic diagram of distribution law of crack feature extracted by improved FaceNet
2.2 結果分析
針對測試集中的每個檢測部位,隨機抽取5個無裂紋待檢測樣本和5個有裂紋待檢測樣本,其中無裂紋樣本由兩張無裂紋圖像組成,有裂紋樣本由一張無裂紋、一張有裂紋圖像組成,70個檢測位置共獲得700個檢測樣本。樣本中待檢測裂紋的長度從0.2~8 mm不等。使用訓練好的改進FaceNet模型對700個待檢測樣本進行測試,測試結果中350個無裂紋樣本均判定正確,350個有裂紋樣本中有13個被判定為無裂紋,測試樣本的整體檢測準確率為98.1%,有裂紋樣本的誤判率為3.7%。對誤判樣本進行分析發現,13個樣本來自4個檢測部位,裂紋長度均小于0.6 mm 且處于裂尖(如圖11所示)。該現象說明大尺寸裂紋更容易被檢出,而小尺寸裂紋由于寬度小,檢出難度較大,這與人工目視檢查的經驗相同。要提高小尺寸裂紋的檢出概率,可結合試驗場景,通過減小視場、增大物方分辨率等手段來實現。

圖11 誤判樣本示例Fig.11 Example of misjudged samples
需要指出的是,在無裂紋樣本的部分圖像中,劃痕的形態與裂紋相似度較高,當使用FasterR-CNN對這些圖像進行檢測時,劃痕會被誤判為裂紋。但使用本文模型進行檢測時,即使待檢測圖像與模板的清晰度和亮度分布存在一定差異,也均能判斷正確,其對比如圖12所示。說明針對疲勞試驗中的裂紋識別問題,相較于單幀目標檢測算法,該模型優勢明顯。
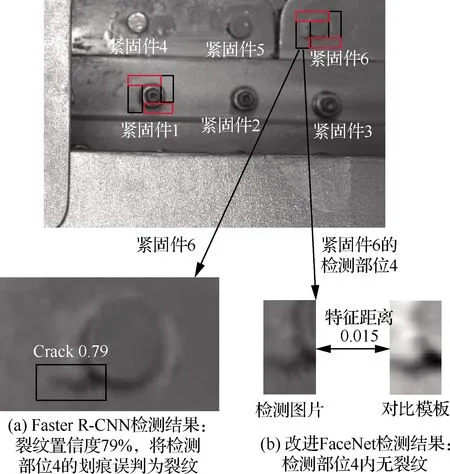
圖12 Faster R-CNN和改進FaceNet檢測結果對比Fig.12 Comparison of Fasters R-CNN and improved FaceNet detection results
此外,本文使用相同的數據集對原FaceNet模型進行了訓練,并分別使用線性計算閾值和單獨訓練一個兩層分類神經網絡的方法完成對訓練集的分類,最后使用以上兩個完整的模型對700個測試樣本進行檢測,其與改進FaceNet模型的性能對比如表1所示。
由表1可知,改進FaceNet模型的檢測準確率明顯高于原有模型的79.8%和91.7%,但由于進行了向量拼接,模型的復雜度提升,其在測試狀態下的浮點運算數(FLOPs)明顯增大,造成每秒可檢測圖片數量減少,該問題可通過提高硬件水平得到改善。
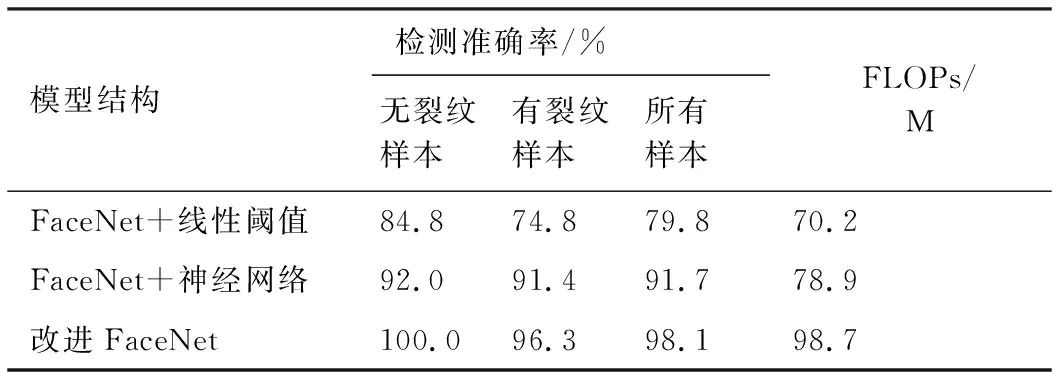
表1 改進FaceNet模型與原FaceNet模型的 檢測結果對比Table 1 Comparison of detection results between proposed model and FaceNet
3 結 論
1) 本文提出了基于關鍵部位狀態對比的裂紋識別策略,設計了基于改進FaceNet的裂紋檢測模型,從而形成了一種基于機器視覺的面向飛機全尺寸疲勞試驗的裂紋識別方法。
2) 本文提出的方法解決了由全尺寸結構與微小裂紋跨數量級的尺寸差異導致的裂紋難以被檢測的問題,能夠有效排除被檢測結構表面廣泛存在的劃痕、污損等因素的干擾,實現了高準確率的裂紋識別。
3) 本方法裂紋識別準確率高的原因為:特征對比機制可有效避免劃痕等干擾因素的影響;三元組損失支撐模型對比學習裂紋特征和圖像質量差異;面向實際問題的模型架構和損失函數改進。
4) 本文提出的方法需結合工程經驗才能縮小裂紋檢測范圍,為實現緊固件孔、非連續結構等應力集中區域的自動檢測和定位,進一步的改進方向是進行單幀目標檢測算法和特征對比算法的融合模型設計。
猜你喜歡
艦船科學技術(2022年13期)2022-08-11 09:29:16
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
World Journal of Diabetes(2019年7期)2019-07-23 11:52:08
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
建筑材料學報(2014年3期)2014-03-11 17:08:02
