基于YOLOv4-GS檢測算法的服裝識別方法
2022-08-01 04:00:22田魏偉邱衛(wèi)根張立臣
現(xiàn)代計算機 2022年11期
田魏偉,邱衛(wèi)根,張立臣
(廣東工業(yè)大學(xué)計算機學(xué)院,廣州 510006)
0 引言
如今,隨著電子商務(wù)技術(shù)的迅速發(fā)展,我國服裝電商市場規(guī)模總體呈逐年井噴增長態(tài)勢。直播帶貨銷售讓用戶可以更為真切地感受到服裝的實際穿著效果,對服裝的效果有更深的了解。但服裝直播類型繁多,用戶難以高效準確地發(fā)現(xiàn)自己喜歡類型的服裝。如何快速、精準地對不同類型的服裝直播進行分類具有重要的研究意義。
近年來,服裝圖像分析在圖像處理和計算機視覺領(lǐng)域引起了巨大的關(guān)注。例如,2016 年公開的最大服裝數(shù)據(jù)集DeepFashion,擁有超過80 萬張圖片數(shù)據(jù),但該數(shù)據(jù)集的每張圖片包含一件服裝,因此在此類數(shù)據(jù)集上訓(xùn)練的模型無法在檢測圖像中檢測多個服裝目標。2019 年Ge 等提出了Deepfashion2 數(shù)據(jù)集,其中包含超過20 萬張服裝圖像,一共擁有13 種不同類型的服裝,每張圖片包含一個或多個服裝目標,彌補了DeepFashion 數(shù)據(jù)集的缺點。Ge等也嘗試使用基于Mask R-CNN 的改進模型對DeepFashion2 進行實驗,取得了良好的精度結(jié)果,mAP 值達到了66.7%。Mask R-CNN是類似于Faster R-CNN 系列的two-stage 算法,首先識別區(qū)域建議框,然后再對其進行分類識別,因此具有較高的準確性和定位能力,但該算法需要大量的參數(shù)量與浮點運算量。由于要將服裝檢測應(yīng)用到直播當中,就要將模型部署到手機等嵌入式設(shè)備當中,其巨量的參數(shù)與浮點運算,嚴重阻礙了這類模型在嵌入式設(shè)備上的部署,也極大地限制了這類模型在更廣泛領(lǐng)域中的應(yīng)用。因此,研究基于更輕量級的深度學(xué)習(xí)算法對于擴展檢測模型在服裝檢測領(lǐng)域的應(yīng)用具有至關(guān)重要的作用。
鑒于Two-stage 算法一直都存在效率方面的巨大劣勢,2016 年Iandola 等提出了輕量級神經(jīng)網(wǎng)絡(luò)SqueezeNet,通過減少參數(shù)量來進行模型壓縮,減少模型部署時的額外開銷。2017 年Howard 等在文獻中提出了MobilNets,利用逐點卷積構(gòu)造卷積層,實現(xiàn)了更好的性能。2020年Han 等提出了新的輕量級網(wǎng)絡(luò)GhostNet,其新穎的Ghost 模塊使用低廉的操作生成更多的特征圖,在效率和準確率方面都優(yōu)于現(xiàn)有的輕量級網(wǎng)絡(luò)。但是,由于這些輕量級網(wǎng)絡(luò)犧牲了檢測的準確度,不利于在實際生活中的應(yīng)用。后續(xù)出現(xiàn)了一些花費很小就可以提升網(wǎng)絡(luò)模型精度的方法,其中注意力機制就是相對高效的一種。注意力機制通過給予人類選擇性視覺注意,
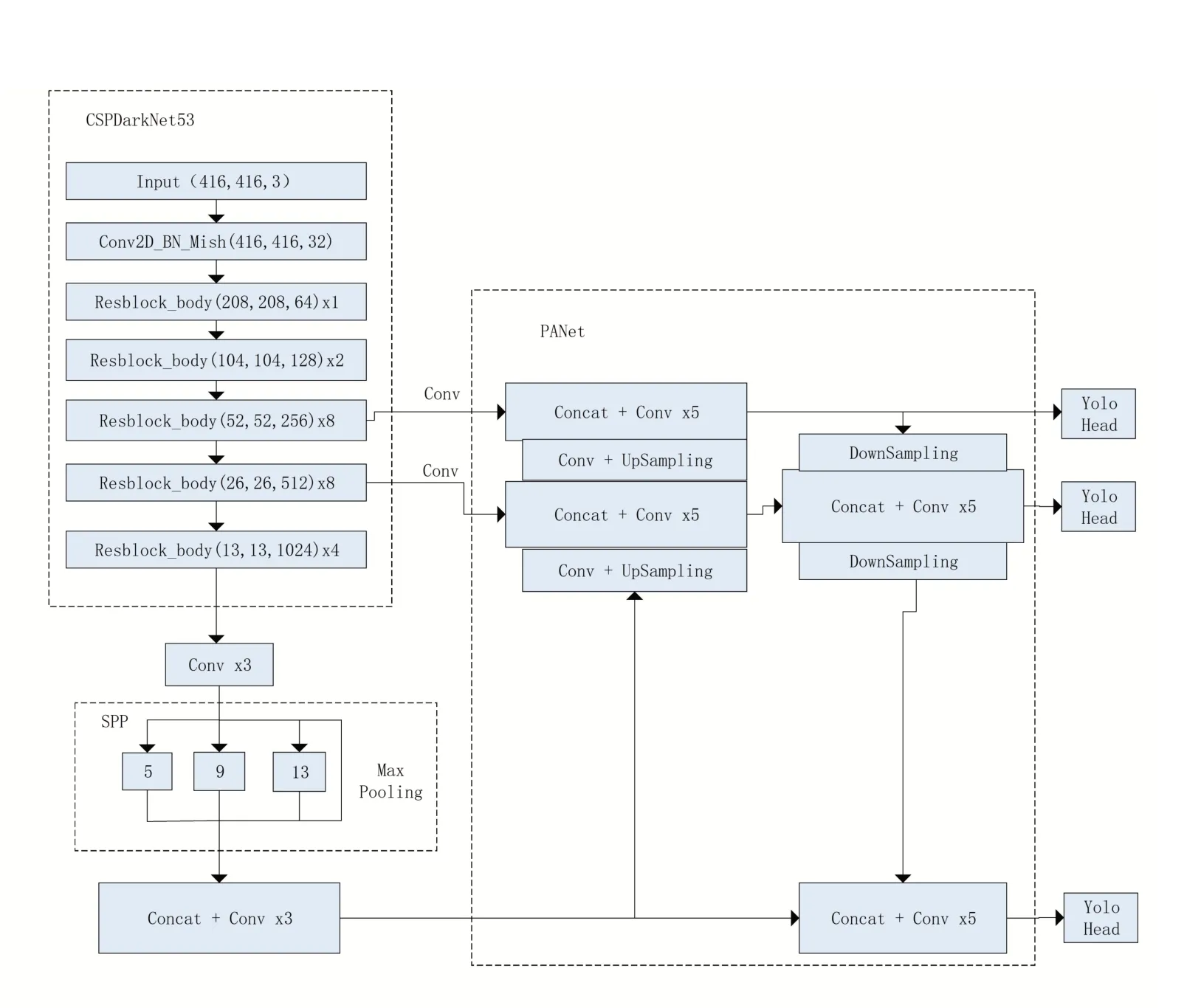
其 主 要 包 括 三 部 分:backbone 部 分、Neck 部分、head 部分。Backbone 部分使用CSP?DarkNet53 網(wǎng)絡(luò)提取目標特征,在不同圖像細粒度上聚合并形成圖像特征。該網(wǎng)絡(luò)由殘差結(jié)構(gòu)和與CSPNet連接的1×1 和3×3 卷積組成。其中殘差結(jié)構(gòu)可以有效降低復(fù)雜度并提升識別效果。同時,該網(wǎng)絡(luò)使用了Mish 激活函數(shù),其優(yōu)點是無邊界(正值可以達到任何高度),避免導(dǎo)致訓(xùn)練速度急劇下降的梯度飽和。Mish 函數(shù)是非單調(diào)函數(shù),保持有小的負值,從而穩(wěn)定網(wǎng)絡(luò)梯度流,它的光滑性使它具有較好的泛化能力和對結(jié)果的有效優(yōu)化能力;Neck 部分使用了PANet結(jié)構(gòu)和SPP 模塊。PANet 模型通過其金字塔結(jié)構(gòu),對從骨干網(wǎng)絡(luò)中提取的三個尺度特征圖進行增強,使模型性能獲得了極大的提升。SPP模塊可以極大地增加感受野,分離出顯著的上下文特征;head 部分延續(xù)了YOLOv3 的YOLO head 結(jié)構(gòu)設(shè)計,其利用前面部分提取的特征得到最終的預(yù)測結(jié)果,包括目標的類別、框位置信息和置信度。
1.2 YOLOv4-GS算法
為了進一步壓縮YOLOv4模型規(guī)模,使其輕量化的同時擁有高精度的性能,本文提出一種體積更小,計算量更少的YOLOv4-GS 目標檢測模型。
本文首先針對DeepFashion2 數(shù)據(jù)集進行Kmeans 聚類獲得對應(yīng)的anchors,再將Ghost 模塊和SimAM 注意力機制進行深度組合獲得GS 模塊,并重構(gòu)CSPDarkNet53 網(wǎng)絡(luò),獲得新的骨干網(wǎng)絡(luò)GS- CSPDarkNet53,最終通過迭代訓(xùn)練獲得高性能、高精度的YOLOv4-GS模型。
1.2.1 利用K-means聚類方法獲得數(shù)據(jù)集對應(yīng)的anchors
本模型中,錨框的引入將目標檢測的問題轉(zhuǎn)化為檢測固定格子內(nèi)是否存在目標以及預(yù)測框與真實框的偏差問題。所以,先驗框的設(shè)置對預(yù)測結(jié)果起著至關(guān)重要的作用。因此,本文算法使用K-means 聚類生成適應(yīng)的先驗框從而增加模型的檢測精度。
主要步驟為:
(1)隨機選取9 個樣本框分別作為9 個簇的聚類中心;
(2)計算相似性參數(shù),由聚類中心和標簽的交集(IOU)決定;
(3)根據(jù)參數(shù)的值將其他標簽劃分到對應(yīng)的簇中;
(4)一輪完成后將這9 個簇的均值作為新的聚類中心。
(5)重復(fù)步驟(2)到步驟(4),直到聚類中心不發(fā)生變化。最終獲得的先驗框符合大量服裝類型的尺寸,能有效提高模型的檢測精度。
本文算法一共輸出3 個特征層,所以生成9個anchor boxes,該算法所取的服裝數(shù)據(jù)集的寬度和高度相對應(yīng)的anchor box如表1所示。
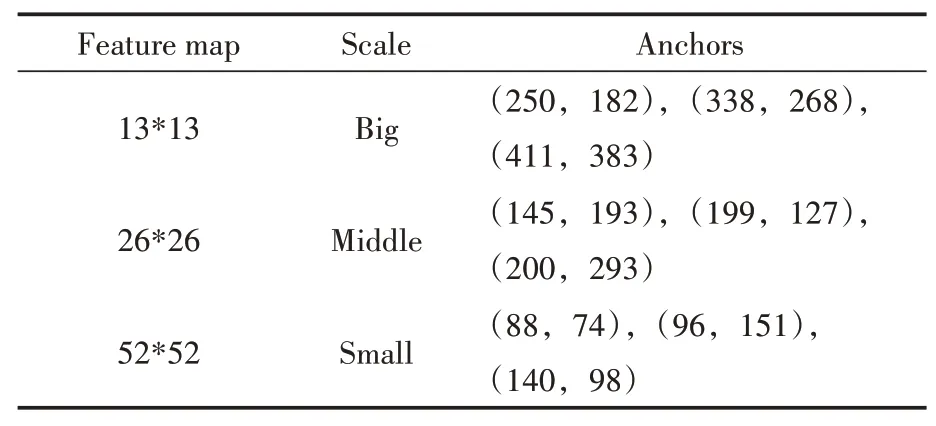
表1 服裝數(shù)據(jù)集對應(yīng)的anchors
1.2.2 GS模塊和GS-CSP模塊
在神經(jīng)網(wǎng)絡(luò)訓(xùn)練過程中,一般會生成大量的特征圖,雖然有利于模型全面理解輸入數(shù)據(jù),但其中必定存在一定數(shù)量的冗余。Han等研究表明,這些冗余特征圖可以利用低廉的線性操作映射部分特征圖得到。為減少其中大量的卷積運算,利用Ghost 模塊將普通的卷積層分成兩部分:一部分是正常的卷積操作,另一部分是對卷積操作獲得的特征圖做簡單的線性運算,以生成特征圖。這樣,降低了整個模型的參數(shù)量和計算量。Ghost卷積模塊如圖2所示。
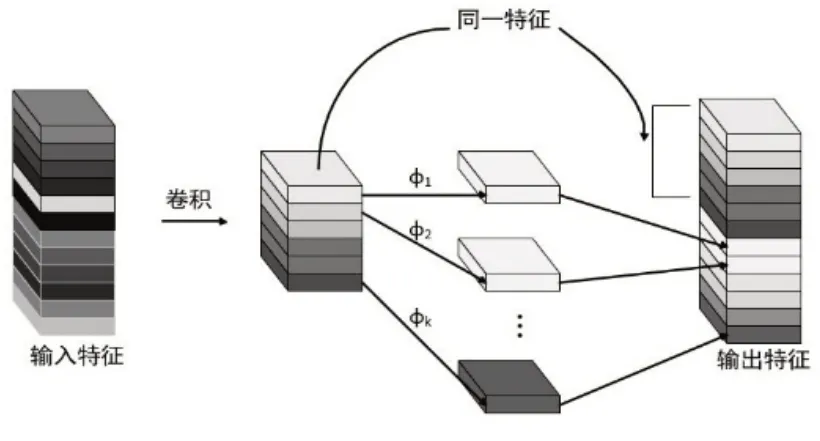
圖2 Ghost卷積模塊
但是由此生成的特征圖豐富度降低,識別精度受到影響,因此提出GS 模塊。與殘差模塊類似,GS 模塊的主干部分是由兩個Ghost 卷積塊和SimAM 注意力機制進行深度組合構(gòu)成。其中,利用殘差機制,有效地降低了卷積操作的復(fù)雜度。最后,將兩部分的結(jié)果通過特征相加操作構(gòu)成最后的GS模塊。GS模塊如圖3所示。圖3 中,SimAM 是無參數(shù)注意力機制,其在特征圖推導(dǎo)注意力權(quán)值時不需額外的參數(shù),確保了更輕量級和更高效。該注意力機制是通過度量神經(jīng)元之間的線性可分性來尋找重要的神經(jīng)元,將這些神經(jīng)元賦予更高的優(yōu)先級。定義每個神經(jīng)元的能量函數(shù)如式(1)所示。

圖3 GS模塊
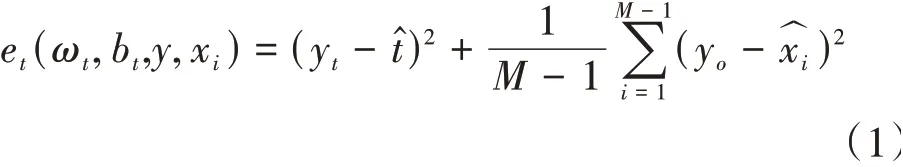
其中:
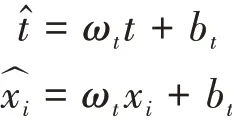
和x為通道中目標神經(jīng)元和其他神經(jīng)元,是空間維度的索引,=×是該通道上的神經(jīng)元數(shù)量,ω和b是權(quán)重和偏差。采用二值標簽,并添加正則項,最終的能量函數(shù)如式(2)所示。
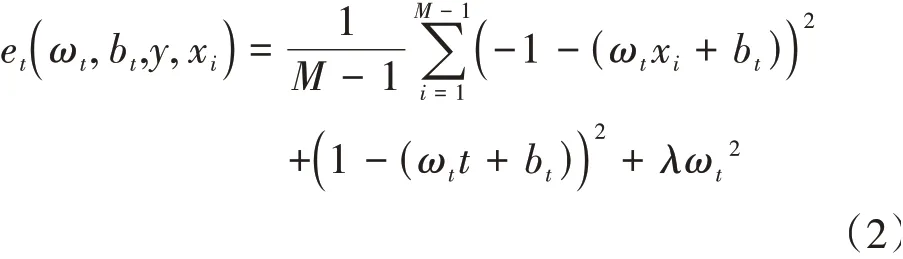
式(2)的解析解如式(3)和式(4)所示。
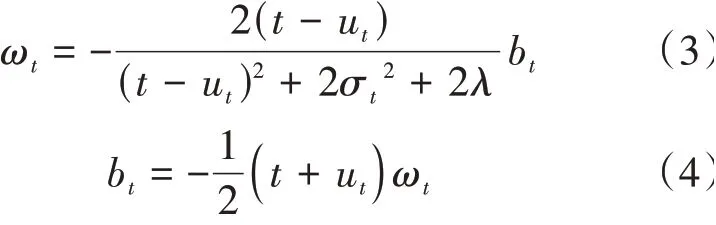
其中
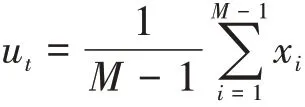
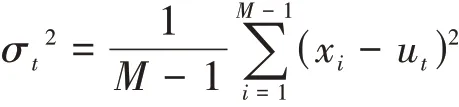
最小的能量計算方法如式(5)所示。
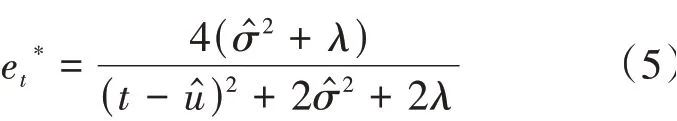
其中
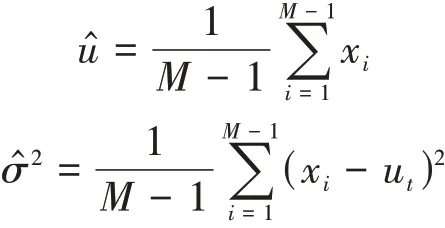
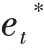
如圖4 所示,GS-CSP 模塊分為兩部分。主干部分是由兩個Ghost 模塊和GS 模塊進行串連,將結(jié)果連接到最后。另一部分經(jīng)過一個Ghost 卷積模塊后連接到最后。最后將兩部分的結(jié)果拼接起來,以有效地緩解梯度消失的問題,并獲取豐富的特征。
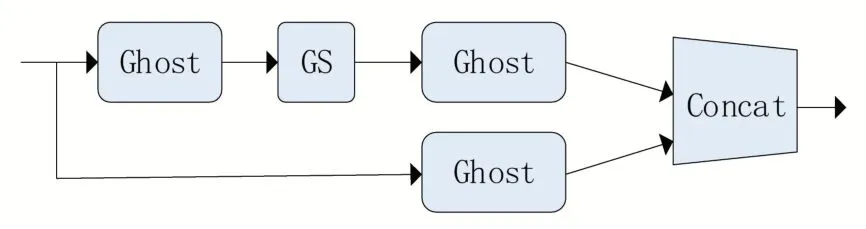
圖4 GS-CSP模塊
1.2.3 構(gòu)建YOLOv4-GS模型
YOLOv4-GS算法框架如圖5所示。
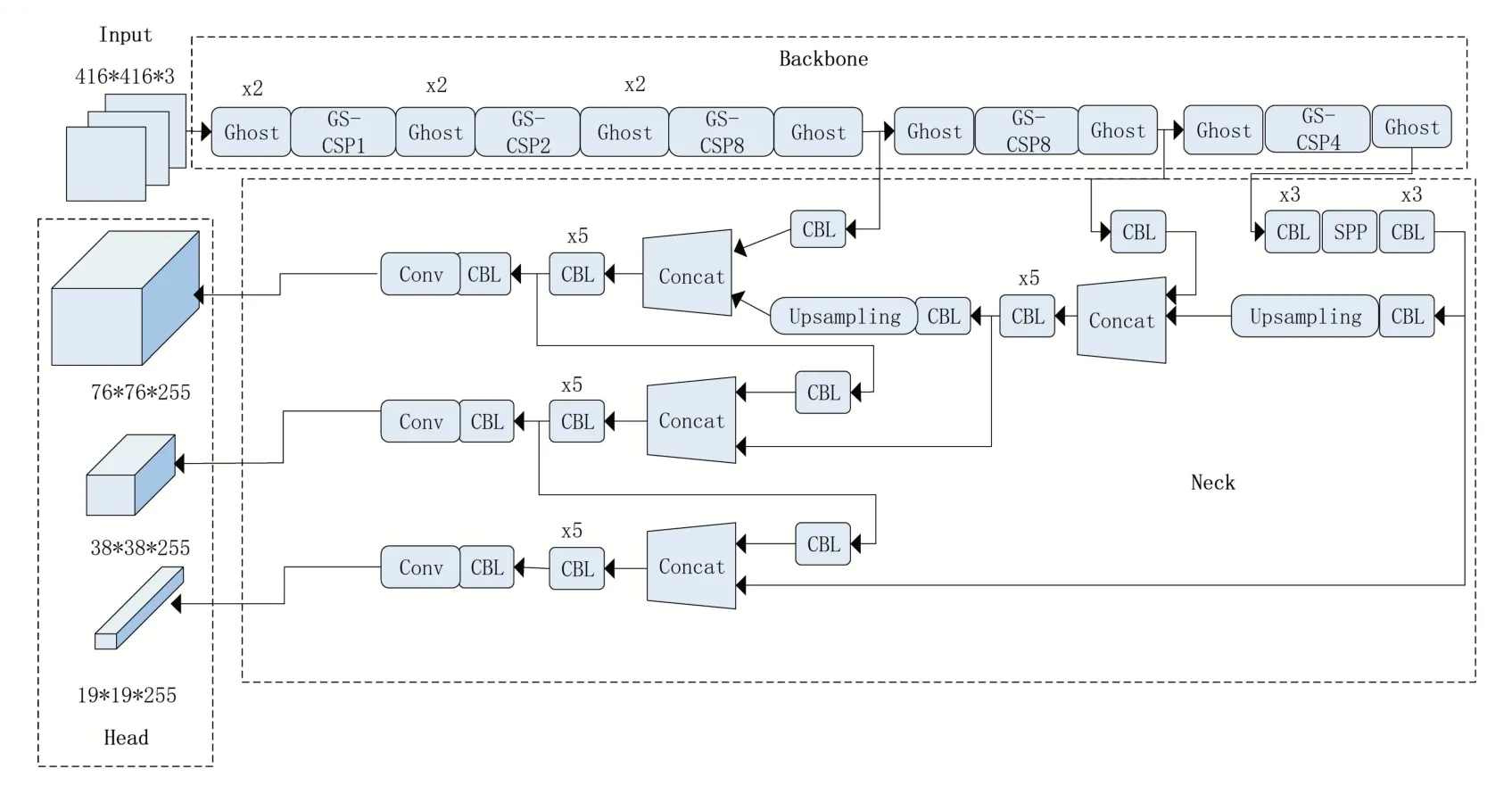
圖5 YOLOv4-GS算法框架
其中SPP 和CBL 結(jié)構(gòu)分別如圖6 和圖7所示。
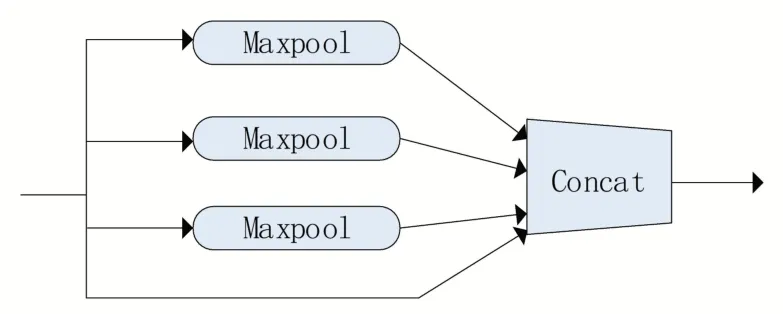
圖6 SPP結(jié)構(gòu)圖

圖7 CBL結(jié)構(gòu)圖
本文算法由三部分組成:1、backbone 是由GS 模塊重構(gòu)整個YOLOv4 骨干網(wǎng)絡(luò)構(gòu)成的GSCSPDarkNet53 網(wǎng)絡(luò),實現(xiàn)更輕量級、更高效的特征提取;2、Neck 部分使用SPP 結(jié)構(gòu)擴大感受野,其中分別利用四個不同尺度的最大池化核13×13、9×9、5×5、1×1 結(jié)構(gòu)進行池化處理,同時,還使用了PANet 特征金字塔結(jié)構(gòu),利用參數(shù)聚合來適用于不同level 的目標檢測;3、head部分使用三個不同尺寸的輸出頭,分別是76×76×255、38×38×255、19×19×255,對于大、中、小目標都有很強的魯棒性。
2 實驗與分析
2.1 實驗環(huán)境
本實驗利用Pytroch 深度學(xué)習(xí)框架實現(xiàn)YO?LOv4-GS 目標檢測算法。服務(wù)器硬件配置為Nvidia GTX1080ti 8g 顯存、內(nèi)存16 G、Intel(R)Core(R)i5-3230M 處理器。實驗的測試環(huán)境為Ubuntu16.04 操 作 系 統(tǒng)、Python3.6、Cuda10.0。基礎(chǔ)學(xué)習(xí)率設(shè)為0.001,調(diào)整方式為到達預(yù)定迭代次數(shù)后,將現(xiàn)有的學(xué)習(xí)率乘以0.1 后作為新的學(xué)習(xí)率,Batch_size 設(shè)為16,訓(xùn)練輪次設(shè)為50次。
2.2 實驗數(shù)據(jù)集
為了測試本文算法在不同服裝檢測場景下的效果,訓(xùn)練數(shù)據(jù)集必須是多樣的、豐富的,因此本實驗選擇在DeepFashion2 數(shù)據(jù)集上進行訓(xùn)練和測試。
DeepFashion2 是DeepFashion 的 改 進 版,具有大量的流行服裝數(shù)據(jù),為實驗提供了更好的數(shù)據(jù)基礎(chǔ)。DeepFashion2 包含13 個流行服裝類別,例如短袖、連衣裙和外套等類型,一共包括49 萬張圖片80 萬個服裝實例,訓(xùn)練出的模型具有很好的魯棒性,在不同場景下進行服裝檢測都可以起到很好的效果。
2.3 模型重構(gòu)及優(yōu)化實驗
在目標檢測中precision-recall 曲線是分別以精度和召回率為縱軸和橫軸的曲線,是該曲線下的面積,是所有類別的平均值,本實驗將作為模型評價指標進行對比。如表2所示,本文算法YOLOv4-GS在mAP這個評價指標上優(yōu)于DeepFashion2 論文中使用mask R-CNN模型得到的檢測結(jié)果,相比提升了1.1%。

表2 YOLOv4-GS在DeepFashion2上檢測結(jié)果對比
如表3所示,主要針對模型的骨干網(wǎng)絡(luò)計算量、骨干網(wǎng)絡(luò)參數(shù)量、模型大小和值進行了對比。引入了GS 模塊的YOLOv3 模型back?bone的計算量和參數(shù)量相比于原生YOLOv3模型幾乎都降低到了50%,模型體積下降了34.15%。在DeepFashion2 測試數(shù)據(jù)集下,值達到了61.5%,對比YOLOv3 模型,提升了1.4% 的。本文模型YOLOv4-GS 相比于傳統(tǒng)的YO?LOv4 模型,backbone 的計算力和參數(shù)量下降了50%左右,模型體積減少了33.12%,值達到了67.8%,相對原生YOLOv4 模型提高了

表3 改進YOLO模型對比
2.1%。
如表3數(shù)據(jù)所示,本文算法提出的GS模塊,引入到Y(jié)OLOv4 模型后,相對于傳統(tǒng)的YOLOv4模型參數(shù)量更少,計算力更低,擁有更小的模型大小和更高的精度,對于模型部署有一定的提升作用。由此證明,GS 模塊能有效使模型輕量化,模型的體積和運算量得到了有效的壓縮,并且模型的精度也得到了提升。YOLOv4-GS 模型的部分識別結(jié)果如圖8所示。

圖8 YOLOv4-GS模型部分識別結(jié)果
3 結(jié)語
針對現(xiàn)有模型無法滿足兼顧效率和檢測精度,不能適應(yīng)嵌入式環(huán)境的問題,本文提出更輕量高效的YOLOv4-GS 目標檢測算法。本文算法首先為了應(yīng)對不同的檢測任務(wù),對數(shù)據(jù)集使用K-means 聚類方法獲取對應(yīng)先驗框參數(shù)。然后深度融合Ghost模塊和SimAM注意力機制組成GS 模塊,并以之重構(gòu)整個YOLOv4 模型,獲得一個參數(shù)少、模型尺寸小、檢測效率高和精度高的目標檢測器YOLOv4-GS模型。
本文在DeepFashion2 數(shù)據(jù)集上的實驗結(jié)果表明,融合GS 模塊的YOLOv4-GS 模型取得了較好的效果。相對于DeepFashion2 模型Mask R-CNN,本文算法提升了1.1%的值。相對于原生YOLOv4 算法,本文模型大小減小了33.12%,指標提升了2.1%。實驗也表明,GS 模塊不僅對YOLOv4 起到了提高效率和精度的作用,在應(yīng)用到其他模型時也能很好地提升性能,例如,YOLOv3等類似的卷積神經(jīng)網(wǎng)絡(luò)模型,都可以參考本文方案進行改進。實驗證明了本文算法通過引入GS 輕量模塊縮小了深度學(xué)習(xí)模型的規(guī)模,對于深度學(xué)習(xí)模型在后續(xù)嵌入式設(shè)備上部署有較好的理論支撐。本實驗的更輕量更高效的模型,可以在服裝領(lǐng)域起到更好的適應(yīng)性,同時擴展了深度學(xué)習(xí)在服裝領(lǐng)域的應(yīng)用。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
