基于專家系統(tǒng)的Web日志數(shù)據(jù)處理方法研究
2022-08-02 01:40:48李春生豆立憲張可佳鄒林浩
計算機技術與發(fā)展 2022年7期
李春生,豆立憲,張可佳,劉 濤,鄒林浩
(東北石油大學 計算機與信息技術學院,黑龍江 大慶 163318)
0 引 言
通過對企業(yè)員工的web日志的數(shù)據(jù)挖掘,能夠更加科學有效地監(jiān)督管理員工,數(shù)據(jù)挖掘的核心工作之一就是對原始數(shù)據(jù)的預處理,它影響到數(shù)據(jù)分析結果的準確度。但當前面向web日志的數(shù)據(jù)預處理方法沒有考慮到復雜web日志數(shù)據(jù)格式的問題,浪費了過多的人力與時間,缺乏智能性且不夠高效。通過專家系統(tǒng)自動對復雜web日志數(shù)據(jù)格式的判別,將對應的web日志格式進行數(shù)據(jù)清洗,完成數(shù)據(jù)預處理。能夠很大程度地節(jié)約時間與人力,相對于當下web日志數(shù)據(jù)的預處理方法更加智能高效。
由于專家系統(tǒng)其技術特點能應對復雜的日志格式,因此應用專家系統(tǒng)能很大程度地實現(xiàn)自動對復雜web日志數(shù)據(jù)格式的判別,彌補傳統(tǒng)方法的不足。
1 專家系統(tǒng)概述
專家系統(tǒng)定義:經(jīng)由推論引擎、知識庫及接口為基礎而組成的系統(tǒng)即是所熟知的專家系統(tǒng)。專家系統(tǒng)的職責就是對社會生活中的問題進行一定的判斷解釋及認知。只是在這個特別的領域中有著不同的對于認知定義的解釋。雖然當下還沒有明確的定義,但是只要當設計的系統(tǒng)在執(zhí)行的信度及效度、對專業(yè)知識的需求、復雜性等能夠與專家不相上下的時候,就可以把該系統(tǒng)稱為專家系統(tǒng)[1]。
1.1 基于框架的專家系統(tǒng)
由于基于規(guī)則的專家系統(tǒng)衍生出的一種推廣,即基于框架的專家系統(tǒng),本身具有一種區(qū)別于其余專家系統(tǒng)的編程風格。當初提出用框架來表示數(shù)據(jù)結構的人是Minsky。很多概念的槽、知識、名稱包含于框架之中,當符合這個概念的某些實例出現(xiàn)時,就可以把和這個實例相關的特定值輸入到當前框架中。編程語言中引入框架的概念后,就形成了面向對象的編程技術。所以目前可以得出一個結論:在某種程度上面向對象的編程技術等于基于框架的專家系統(tǒng)。但由于當下日志的總字段長短不一,屬性不同,所以基于框架的專家系統(tǒng)不適用于日志類型的判別。
1.2 基于案例的專家系統(tǒng)
采用以前存在的案例來推理解答目前問題的系統(tǒng),即基于案例推理的專家系統(tǒng)。求解的順序:第一步,得到問題,并開始對以往的案例進行匹配,直到找到跟目前問題最匹配的案例;第二步,基于第一步找到的當前問題最合理的匹配案例,就將之前案例所用的解決方案運用到現(xiàn)在,如果并沒有找到合適的匹配案例,將當前的作為新的案例并加入到案例庫。綜上所述,基于案例推理的專家系統(tǒng)能夠不斷地學習新的經(jīng)驗,并不斷進步。
當然,如何從過往的案例中找出最合理的案例并與當前的問題進行匹配是當前基于案例推理的專家系統(tǒng)比較大的一個難點。在案例尋找過程中,需要將一些過分相似的案例進行刪除,因為如圖案例庫太大,將會影響案例匹配的效率。目前來說一些主流的匹配算法有:徑向基函數(shù)網(wǎng)絡、k-近鄰法、最近鄰法。但基于案例的分析相對于基于規(guī)則的推理有一定的不準確性[2]。
1.3 基于規(guī)則的專家系統(tǒng)
由于該類系統(tǒng)是在專家系統(tǒng)中最早被研發(fā)出來的,同樣也是基本的結構被用來組成專家系統(tǒng)。由于使用的規(guī)則來源于產(chǎn)生式定義,所以,在一般的狀況下,在基于規(guī)則的專家系統(tǒng)中就會用“if……then……”的類型來解決問題。環(huán)境與行為的關系一般會被用一種心理學術語來進行描述,即產(chǎn)生式。而專家系統(tǒng)在最開始是從其中演變而來的。斯坦福大學設計的第一個專家系統(tǒng),它的主要功能是判定物質的結構。而且在產(chǎn)生式的系統(tǒng)當中,知識被分割成了兩個方面,靜態(tài)的系統(tǒng)是一方面,用事實來表示,例如事件與事物及其相互之間的聯(lián)系;推理的行為及其推理過程是另一方面,用產(chǎn)生式的規(guī)則來實現(xiàn)。因為該類系統(tǒng)的知識庫主要用來存儲規(guī)則,所以該類系統(tǒng)又被稱為基于規(guī)則專家系統(tǒng)[3]。
當前最常使用的方法是基于規(guī)則的專家系統(tǒng),其主要原因是擁有許多成功的案例和便捷輕快的開發(fā)工具。基于規(guī)則的專家系統(tǒng)不僅可以用各種各樣的規(guī)則來實現(xiàn)專家系統(tǒng),而且可以用來直接對人的心理過程進行模仿。基于規(guī)則的專家系統(tǒng)有兩種基本的推理:第一種是將已經(jīng)存在的知識作為專家系統(tǒng)推理開始點的正向推理;第二種是將假定的結果作為專家系統(tǒng)推理開始點的反向推理。且對于反向推理,如果找不到匹配的規(guī)則,改變假設,重新進行推理[4]。
知識與處理的相分離。基于規(guī)則的專家系統(tǒng)的結構為知識庫和推理引擎提供了有效的分離機制。因此,能夠使用同一個專家系統(tǒng)框架開發(fā)不同的應用,系統(tǒng)本身也容易擴展。在不干擾控制結構的同時通過添加一些規(guī)則,還能使系統(tǒng)更聰明。
大多數(shù)基于規(guī)則的專家系統(tǒng)都能表達和推理不完整、不確定的知識。因此可以采用基于規(guī)則的專家系統(tǒng)思路來構建專家系統(tǒng)。
2 web日志數(shù)據(jù)預處理流程
在數(shù)據(jù)分析的過程中,如果數(shù)據(jù)沒有進行過數(shù)據(jù)處理,原來的數(shù)據(jù)依然存在各種各樣的異常,且存在不一致、不完整等問題,即會導致數(shù)據(jù)分析的結果不夠準確。所以在數(shù)據(jù)分析之前,對原始數(shù)據(jù)進行數(shù)據(jù)預處理的步驟至關重要。
一條真實的NCSA(ECLF)日志記錄為“27.19.74.143 - - [30/May/2013:17:38:20 +0800] "GET /static/image/common/swfupload.swf?preventswfcach-ing=1369906718144 HTTP/1.1" 200 13333”,這類日志主要由以下幾個部分組成:
標識符(ident):目前幾乎多數(shù)的瀏覽器已經(jīng)取消了該功能,因為涉及到了用戶郵箱等隱私信息。
授權用戶(authuser):雖然目前多數(shù)的網(wǎng)站的該類日志項并不存在,但是該類字段對于那些需要身份驗證或者訪問時候個人密碼保護的信息項網(wǎng)站來說,不能為空。
日期時間(date):即[日期/月份/年份:小時:分鐘:秒鐘時區(qū)],占用的字符位數(shù)也基本固定,一般的格式形如[22/Feb/2010:09:51:46 +0800]。
請求(request):在網(wǎng)站上通過使用哪些方式獲取了哪些信息在日志數(shù)據(jù)格式中也扮演著重要的角色。
請求類型(method):目前來說,主流的請求類型主要有以下三種:POST/HEAD/GET。
請求資源(resource):可以是css、動畫、圖片等資源,也可以是某網(wǎng)頁的地址,即是請求資源的相應的UPL。
協(xié)議版本號(protocol):通常是HTTP/1.0或者HTTP/1.1,用于版本信息及顯示的協(xié)議。
狀態(tài)碼(status):用于響應瀏覽器的請求。
傳輸字節(jié)數(shù)(bytes):在一次請求過程中的資源數(shù)量。
訪問主機(remotehost):已經(jīng)解析的域名或者用于顯示主機的ip。
各類web日志數(shù)據(jù)的處理流程基本一致。處理流程主要分為:數(shù)據(jù)抽取、數(shù)據(jù)格式轉換、數(shù)據(jù)重復值處理[5]。
2.1 web日志數(shù)據(jù)抽取
web日志分析過程中,并不是每個字段都是日志分析中所需要的。比如,DNS的IP在每行數(shù)據(jù)中都是相同的,所以沒有必要分析;日志記錄中也記錄了兩次用戶請求的主機地址,實際分析中只需要一個即可;還有一些無關的符號(client、query、IN、+客戶端端口號等)[6]也都需要過濾。最終,在數(shù)據(jù)表中保存了所需要的有用字段。
2.2 web日志數(shù)據(jù)格式轉換
web日志數(shù)據(jù)格式的轉換主要針對的是日期字段。在這里,將字符型的日期格式04.Jan.2017轉換成了日期類型的數(shù)據(jù)格式2017—01—04[7]。
2.3 web日志數(shù)據(jù)重復值的處理
在海量的web日志數(shù)據(jù)行中,有大部分數(shù)據(jù)行是重復的,數(shù)據(jù)量很大,會對數(shù)據(jù)分析的準確性帶來一定的影響,因此有必要對重復的數(shù)據(jù)進行去重處理[8]。
3 基于專家系統(tǒng)的web日志數(shù)據(jù)預處理
3.1 數(shù)據(jù)來源
本次實驗的數(shù)據(jù)來源于某企業(yè)Apache服務器2013年的員工web日志數(shù)據(jù)。
3.2 專家系統(tǒng)設計
專家系統(tǒng)主要邏輯:
(1)獲取web日志數(shù)據(jù),將獲取web日志數(shù)據(jù)某一行的前三列轉換為已知事實。
(2)輸入目前已經(jīng)存在的事實—>進行推理。
(3)綜合數(shù)據(jù)庫db添加輸入的已知事實。
(4) 規(guī)則庫獲取,并在之后將存在對應關系的前提與結論分別各自存儲于兩個列表里[9]。
(5)前提與已知知識庫進行匹配:
如果有一個前提,所有這些在已知的事實中出現(xiàn),那么最少也能夠得出一個結論[10]。將結論添加到綜合數(shù)據(jù)庫中,并對推理過程進行標記。在推理列表之中存在的數(shù)字是前提和推理出來結論的下標[11]。用于展示。
如果這樣的前提并不存在,就無法推理出想要的中間結論,跳轉(7)。
(6)等循環(huán)完了,因為至少存在一個中間結論,所以直接輸出推理過程和(中間或者最終)結論[12]。
(7)提示什么也不能推出來,詢問是否進行補充,如果選擇“是”就回到主頁面,如果選擇“否”就關閉程序。
界面設置:
框:讀取并顯示web日志數(shù)據(jù)的框,輸入事實的框,顯示推理過程的框,顯示結論的框,自動顯示當前規(guī)則庫的框,用來添加規(guī)則庫的框。
按鈕:打開web日志數(shù)據(jù)的按鈕,點擊進行推理的按鈕,點擊添加規(guī)則庫并更新當前窗口的按鈕。
對話提示框:詢問是否進行補充的框。
主界面如圖1所示。

圖1 主界面
點擊文件,打開需要處理的web日志數(shù)據(jù),如圖2所示。

圖2 打開web數(shù)據(jù)
顯示讀取的web日志數(shù)據(jù),將獲取的web日志數(shù)據(jù)的第一行前三列,轉換為已知事實,并顯示于“獲取web日志”,推理輸出對應的日志格式,如圖3所示。

圖3 推理過程及結果顯示
3.3 web日志數(shù)據(jù)預處理
通過“2”得到輸入的web數(shù)據(jù)格式是NCSA(ECLF)[13],針對其特定的數(shù)據(jù)格式自動進行數(shù)據(jù)預處理,NCSA(ECLF)日志格式如下所示:
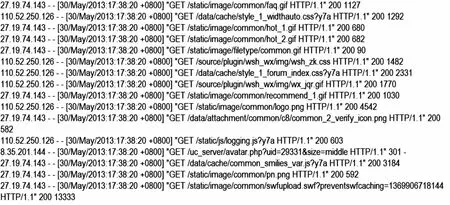
3.3.1 數(shù)據(jù)抽取
企業(yè)員工的web日志中時區(qū)、方法、協(xié)議、狀態(tài)碼等字段對于分析沒有作用。企業(yè)員工都在同一時區(qū),所以時區(qū)這一字段對于企業(yè)分析員工行為沒有意義,可以舍去;在企業(yè)分析員工web日志過程中,請求方法、協(xié)議、狀態(tài)碼等字段沒有實際應用價值,亦可以舍去。因此將這些無意義字段都刪除,只保留主機IP、請求時間、資源、發(fā)送字節(jié)量等字段[14]。

3.3.2 數(shù)據(jù)格式轉換
由于數(shù)據(jù)格式的轉換主要針對的是日期字段,因此需要將字符型的日期格式轉換成日期類型的數(shù)據(jù)格式。

3.3.3 重復字段刪除
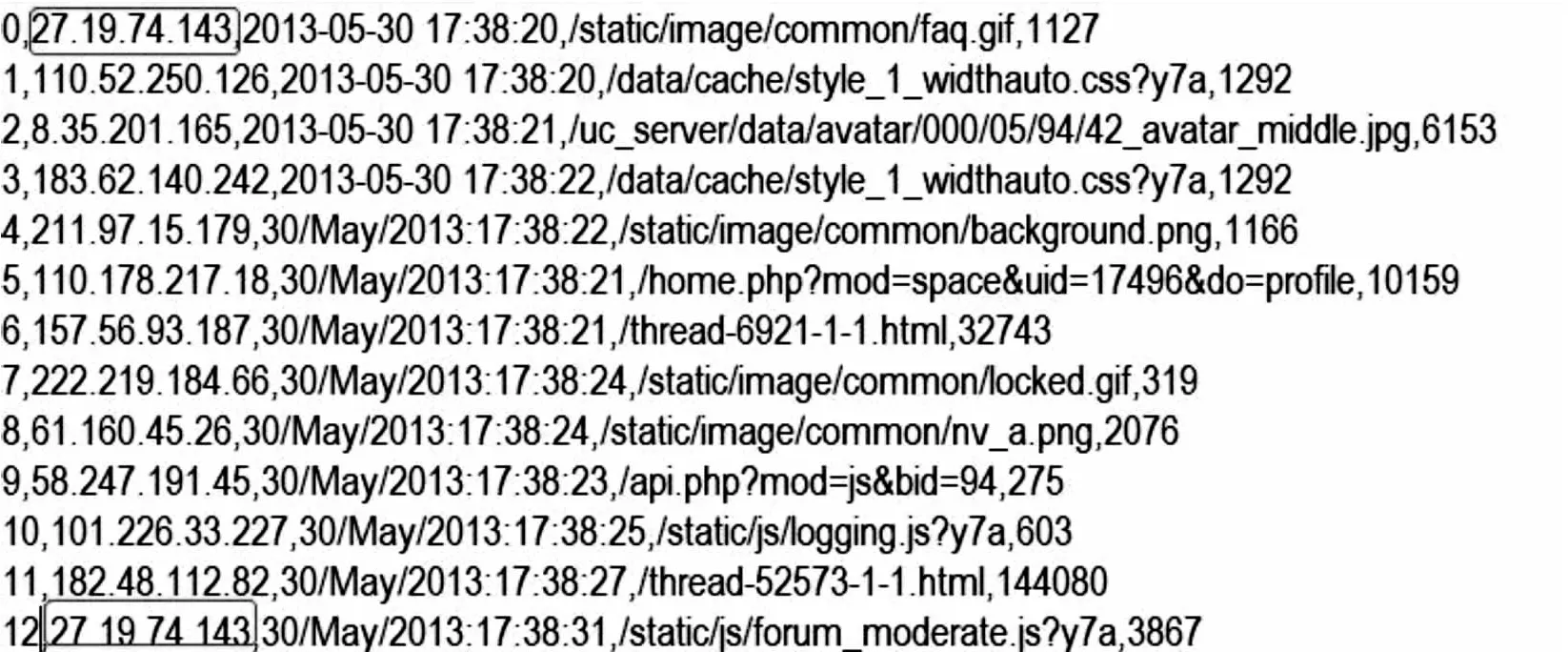
由于數(shù)據(jù)量龐大,因此以10秒鐘為間隔定義員工日志。在這里,刪除的對象針對的是同一ip,訪問時間相差大于10秒的數(shù)據(jù)行。將員工日志數(shù)據(jù)重新定義完成后,刪除其中的重復數(shù)據(jù)行。在一定程度上能提高之后數(shù)據(jù)分析的準確性[15]。
經(jīng)過處理完的ECLF web日志數(shù)據(jù)如下所示:
4 結束語
傳統(tǒng)的日志數(shù)據(jù)清洗方式難以應對目前如此復雜的日志格式。由于專家系統(tǒng)其技術特點能應對復雜的日志格式,所以通過結合專家系統(tǒng),推理出對應的web日志格式,從而自動進行日志數(shù)據(jù)清洗。該文通過對若干種日志數(shù)據(jù)格式建立規(guī)則庫,并對其進行知識推理,基于推理得到對應日志類型,自動進行數(shù)據(jù)預處理。證明了基于專家系統(tǒng)的web日志數(shù)據(jù)預處理的可行性,使得當前的日志數(shù)據(jù)處理更加高效且智能,有效提高了企業(yè)的工作效率,節(jié)約了時間成本,推動了企業(yè)快速發(fā)展。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數(shù)學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
少先隊活動(2021年2期)2021-03-29 05:40:48
中學生數(shù)理化(高中版.高二數(shù)學)(2019年6期)2019-06-24 03:37:50
幸福(2018年33期)2018-12-05 05:22:42
Coco薇(2017年11期)2018-01-03 20:59:57
中國公路(2017年7期)2017-07-24 13:56:38
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
中國科技信息(2016年14期)2016-07-31 21:16:32
中學生數(shù)理化(高中版.高二數(shù)學)(2016年4期)2016-03-01 03:46:18
