基于深度學習的車輛目標檢測算法綜述
2022-08-03 01:47:22蘇山杰陳俊豪張之云
汽車文摘 2022年8期
蘇山杰 陳俊豪 張之云
(重慶交通大學機電與車輛工程學院,重慶 400074)
主題詞:深度學習 車輛目標檢測 卷積神經網絡 輕量化網絡
CNN Convolutional Neural Network
GPU Graphic Processing Unit
CPU Central Processing Unit
LRN Local Response Nor
VGG Visual Geometry Group
BN Batch Normalization
SVM Support Vector Machine
SPP Spatial Pyramid Pooling
ROI Region of Interest
RPN Region Proposal Networks
R-FCN RPN-Fully Convolutional Networks
IOU Intersection over Union
SSD Single Shot MultiBox Detector
FPN Feature Pyramid Network
PAN Path Aggregation Network
SVD Singular Value Decomposition
ReLU Rectified Linear Unit
1 引言
目標檢測是計算機視覺技術、深度學習和圖像識別領域下的基礎研究方向,它是更為復雜的高層計算機視覺任務的技術前提,如在檢測任務后對圖像中物體行為進行預測;在物體識別后進行目標跟蹤等等。其中,車輛目標檢測任務作為計算機視覺和深度學習領域下的研究重點和熱門任務,它的目的是在圖像中定位出感興趣的目標,然后根據特征信息正確定義出定位目標的類別,再利用檢測的邊框圈出定位目標,從而完成檢測任務。在智能駕駛、行人檢測和建立智能化的交通系統中有著重要的研究意義與價值,也是未來建立智慧城市的前提任務。近年來,以物聯網技術、計算機視覺技術為代表的核心技術得到了蓬勃發展,基于深度學習的車輛目標檢測算法得到了許多研究學者的青睞。
本文針對車輛目標檢測任務,首先對深度學習車輛目標檢測進一步探討,提出檢測任務的重點、難點及發展現狀,以時間線對卷積神經網絡下車輛目標檢測算法進行概括,并對目前2 種主流的基于候選框和基于回歸的車輛目標檢測算法進行總結,最后對目前目標檢測算法的發展前景進行展望。
2 車輛目標檢測研究背景
2.1 車輛目標檢測任務重點
基于深度學習的車輛目標檢測算法任務是從一系列的圖像或者視頻中找出感興趣的物體,同時根據特征信息確定車輛的大小和位置。但是,在實際的場景中,始終會有許多干擾因素,例如光照,遮擋,不同的尺度形狀等情況,這會導致車輛目標檢測任務進行中出現漏檢和誤檢的問題,影響算法的精度。因此,如何能達到算法在精度上的要求是目標檢測中的一項重點難點項目;同時,針對車輛檢測在智能駕駛和違章檢測領域中的應用,算法能夠做到實時的檢測也是目前研究重點。大量的研究人員在此兩項任務上做了一系列卓越的貢獻,尤其是深度學習算法的蓬勃發展,為車輛檢測任務帶來了更好的研究前景。
2.2 車輛目標檢測任務難點
當前,車輛目標檢測任務所面臨的巨大挑戰仍然是檢測算法的實時性,精度上與檢測需求之間的矛盾,如何更好的平衡它們一直是基于深度學習的目標檢測算法的重要研究方向。而目前對以上2項指標的研究也在逐漸進行,但仍存在5項研究難點:
(1)無人駕駛車輛在行駛過程中會遇到不同的環境狀況,因此所采集到的圖像往往會受到不同光照條件,天氣不斷變化,以及出現目標物被大面積遮擋的情況影響,這會導致目標檢測任務出現提取特征不足,漏檢物體的情況,進一步加大檢測難度。
(2)目前存在的數據集對象類別與現實世界中獲取的圖像中的部分類別存在一定的差距,這會導致在訓練過程中,所標注的物體被識別為其它對象,或者識別為背景,這會大大降低檢測結果的精度。
(3)在特定數據集訓練后,更換新的數據集會出現較低的檢測精度,因為檢測算法的泛化能力不夠好。
(4)目前采集的圖像數量呈指數級增長,而處理設備的計算能力及儲存能力可能無法做到更好的實時檢測。
(5)未來的研究難點更注重分割圖像中感興趣物體的類別,甚至可以做到根據圖像預測物體的行為及會出現的對象。
2.3 車輛目標檢測發展現狀
傳統的車輛目標檢測中,也有許多代表性的檢測算法,占主要地位的就是基于人工特征提取的檢測方法。這類方法一般都是用作特定的目標檢測任務,在整個環節中,人工特征提取階段對人的主觀意識有較高的要求,扮演著重要的角色,對整個算法的性能有直接的影響。傳統的車輛目標檢測算法的缺點主要是數據量小,人工提取效果不好,可移植性較差,時間復雜度高,窗口贅余,面對環境多變性的魯棒性差,只有在特定的環境下才有良好的性能,故并不適合在檢測實時性要求較高和環境多變的場景中應用,在現實中也得不到大規模的應用。隨著計算機視覺技術的快速發展,基于深度學習的車輛目標檢測算法也逐漸成為主流算法,與傳統的經典算法不同,此類算法克服傳統算法的大部分缺點,同時在計算機GPU 和儲存能力都大幅度提高的信息技術下,深度學習的運算速度比過去提高了2~24 倍,從而得到了越來越多的國內外學者認可。2012 年,基于卷積神經網絡的分類網絡被提出后,許多學者已經開始將深度卷積神經網絡應用于目標檢測任務,并提出了許多優秀的算法。目前,基于深度學習的目標檢測算法在學術領域的主要關注點就是模型的精度和速度的實時性,從而產生了2 個不同發展方向:2 階段目標檢測算法和1 階段目標檢測算法,分別強調檢測精度和檢測速度。
3 基于深度學習的車輛目標檢測算法研究現狀
提出性能較好的深度學習下目標檢測算法是近些年來計算機視覺技術領域的重要研究目標,特別是基于卷積神經網絡的深度學習算法被國內外學者普通接受的環境下,對算法的創新使檢測精度和實時性達到了一個新的高度。
3.1 卷積神經網絡下車輛目標檢測算法
卷積神經網絡(Convolutional Neural Networks,CNN)經歷了幾十年的發展歷程,現在已經在許多領域中得到應用,并進一步提高了許多任務的效率,目前對圖像中目標進行分類、檢測及語義分割的計算機視覺任務也逐漸成為一種高效率的檢測方法,卷積神經網絡在目標檢測研究中的重要里程碑如圖1 所示。卷積神經網絡是由3部分組成,包括進行卷積操作的卷積層、采樣的池化層和對向量進行處理的全連接層,這些模塊最后堆疊形成一個深層架構,卷積神經網絡在發展歷史中演化出3個有借鑒意義的理念和方法:
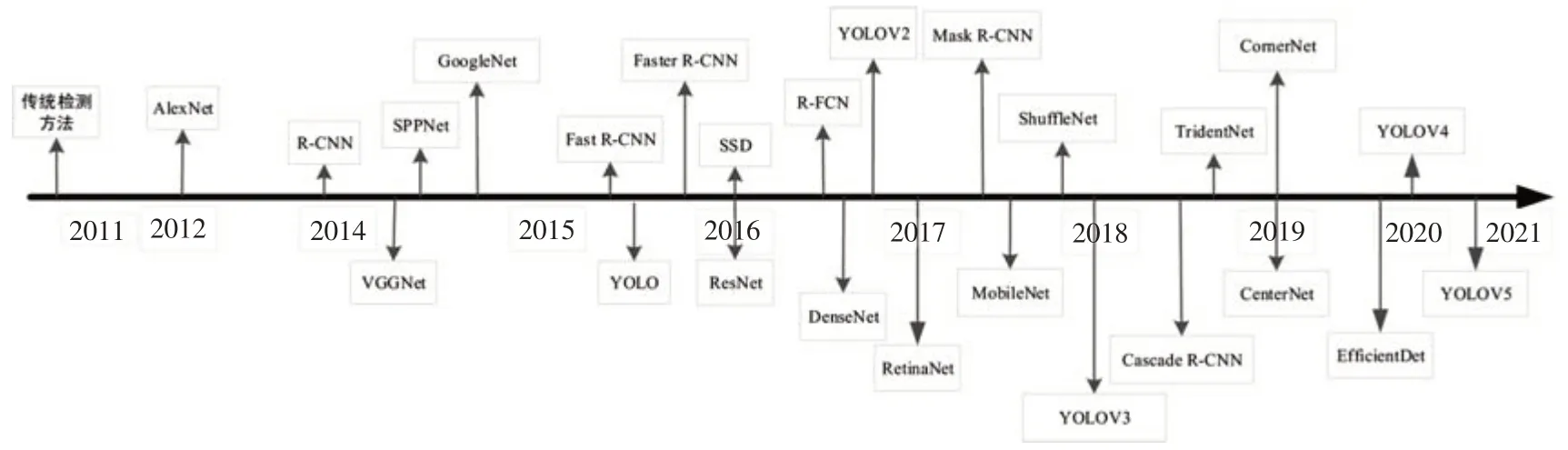
圖1 經典神經網絡算法發展歷程
(1)權值共享的理念;
(2)局部連接(稀疏連接)方法;
(3)平移不變性和等變性。
隨著算法的發展,卷積神經網絡也出現許多性能較好的算法,每一種網絡結構都有其獨特的結構和創新點,并對前人的工作做了對比分析,本節對這些結構進行總結和分析。
3.1.1 AlexNet
由LeCun 等提出的LeNet-5 卷積神經網絡最初是應用在數字識別問題上,該網絡模型的出現奠定了現代神經網絡的發展基調,為后續新的網絡模型的提出產生了深遠的影響。2012年,針對前期各種卷積神經網絡結構的不足,Krizhevsky等人通過大量的訓練集訓練網絡,最終提出了一種全新的AlexNet 網絡結構,在舉辦的ImageNet 大規模視覺識別挑戰賽(ILS?VRC)中,網絡具有最優的性能,在檢測精度和檢測速度都大幅度提升,該網絡結構瞬間推動了神經網絡的應用熱潮,而深度卷積神經網絡在計算機視覺領域的大規模應用,進一步推動了其主導地位的建立。AlexNet 的網絡結構共有8 層,包括5 個卷積層和3 個全連接層,這樣網絡結構在增加深度和廣度的同時,使其網絡參數增加到了6 000 萬個,網絡結構通過兩塊GPU 運算,大大減少了CPU 訓練的時間成本。AlexNet 有以下貢獻:在ReLU 函數提出后,對其使用并沒有發揚光大,作者經過大量數據分析發現ReLU函數解決了傳統的Sigmoid函數在網絡層數較深時會出現梯度彌散的問題。對比分析后,將ReLU 作為激活函數來提高網絡性能;使用數據增強減少過擬合問題;由于參數量過大的問題,使用Dropout函數去隨機選擇一些神經元失去活性,在對試驗的精度沒有影響的同時,也避免了模型過擬合問題,之后的網絡結構中該層成為全連接層之后的標配層;作者提出局部響應歸一化(Local Response Nor,LRN)層是對模型泛化能力的進一步保障。
3.1.2 VGGNet
VGGNet是由牛津大學VGG(Visual Geometry Group)團隊和Google Deep Mind 公司在針對AlexNet網絡層數深度問題進行研究而提出來的,并取得了ImageNet 競賽中定位檢測的第一名和分類任務的第二名的好成績,同時證明了算法的網絡深度對目標檢測性能有較大的影響。然而這種增加網絡深度的改進方法并不是沒有限制的,作者通過設定VGGNet 網絡結構為11、13、16、19 層,驗證了在恰當的網絡深度的基礎上繼續添加網絡的層數會出現訓練差增大,而出現的網絡退化的問題,故目前最佳的網絡深度為16層和19 層,VGG16 的網絡結構如圖2 所示。VGGNet網絡結構有以下特點:結構簡潔,并在卷積層中采用多個小卷積核去替代較大的卷積核,這一方面減少了模型的參數,增大了網絡感受野,另一方面進行了更多的非線性映射操作,增加網絡層數加深時的擬合和表達能力,且模型采用了更小的2×2 池化核,并在測試階段把3 個全連接替換為3 個卷積,該網絡的突出貢獻在于證明了使用小卷積核,能夠增加網絡的深度從而更好的提取特征。
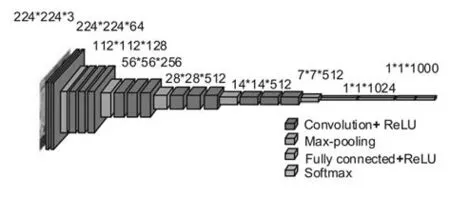
圖2 VGG16框架網絡結構[8]
3.1.3 GoogleNet
GoogleNet 是Szegedy 等在2014 年提出的,網絡最主要的就是Inceptionv1模塊層,并在之后改進過程中出現包括Inceptionv2,Inceptionv3和Inceptionv4的3個版本,這些模塊主要是由1×1,3×3,5×5的卷積核模塊組成,目的是通過優化網絡結構從而降低網絡的復雜程度,減少了模型的參數量。由于該網絡結構擁有較好的性能,在2014 年的ILSVRC 圖像分類競賽中,獲得了第一名的佳績,為后續網絡結構的改進提供了新的思路。
3.1.4 ResNet
網絡層數到了一定的深度,會不可避免的出現許多問題,如參數量增多,訓練結果不理想等,學者對問題更深一步探討,主要原因是網絡層數深度的增加,數據集不充分,便會引起梯度彌散或梯度爆炸的問題。以上問題的是由何凱明團隊提出的ResNet 網絡改善的,主要工作是在主干卷積環節添加Residual結構模塊,這種模塊利用跳連的結構將輸入的特征和經過卷積操作后的輸出特征相加,共同成為輸出層的一部分,模塊結構如圖3 所示。該網絡在增加了網絡深度的同時,對輸入數據進行訓練時也不會影響誤差,取得了較好的效果,該網絡設計特點是在非線性層后,激活函數前采用批標準化(Batch Normalization,BN)層加快網絡的訓練速度和收斂時的穩定性,用平均池化層代替全連接層。在同年的ILSVRC 和COCO的競賽中,各個方面的性能實現了驚人的突破,幾乎以碾壓性的優勢分別取得了分類、定位、檢測和分割任務的第一名,該網絡的提出進一步奠定了深度卷積神經網絡在計算機視覺技術的主導地位,對后續網絡的提出與改進有著較好的借鑒意義。
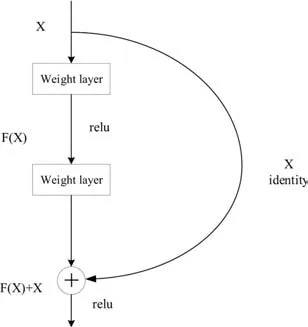
圖3 Residual模塊結構
3.1.5 DenseNet
2016年,Huang等為緩解梯度損失,加強網絡中特征的傳遞,提出了轟動一時的DenseNet 網絡結構,主要構建模塊是稠密層和過渡層,稠密塊主要是稠密連接的Highway 模塊,過渡層為相鄰2 個稠密塊的中間部分,這樣的連接方式大幅度減少了模型的參數,有效地對特征進行復用,甚至解決了在小樣本上的過擬合問題。
3.1.6 MobileNet
2017年,隨著計算機視覺技術和GPU的快速發展,神經網絡模型的輕量化逐漸成為國內外學者爭先研究的方向,常見的設計方法有2種:設計輕量化的網絡模型和對訓練好的復雜網絡進行壓縮處理。Google團隊經過大量的研究,提出了一種當時最輕量化的網絡模型:MobileNet,并且具有高效的性能。作者的初衷是為了減小參數量提升運算速度,使算法更適用小型設備,作者并沒有采用傳統的卷積網絡,而用深度可分離卷積網絡替代全部的卷積網絡,進一步提出了Width Multiplier和Resolution Multiplier兩個超參數,2個參數都可以進行調節,調節的結果會對不同的檢測任務實現更好的檢測性能,經歷了多年的發展出現了許多的輕量化網絡版本,如MobileNetV2、MobileNetV3。
3.1.7 ShuffleNet
輕量化神經網絡熱潮進一步得到推動,曠視科技提出了一種新的更加高效的移動端卷積神經網絡,命名為ShuffleNet,主要有2個創新的應用:
(1)將逐點組卷積應用到網絡結構中,去降低逐點卷積使用中的計算復雜度,同時可以消除多個卷積堆疊后產生的負面影響;
(2)采用通道混洗的操作,可以大大改善在跨特征通道中的信息流動。
2 種創新點的提出,使得該算法在ImageNet 競賽和COCO 競賽中取得了優秀的成績,表現出了移動端先進網絡的優越性能。
在計算機視覺技術的更新迭代中,卷積神經網絡也得到快速發展。每一種卷積神經網絡框架都有獨特的優勢,目前模型結構正在逐漸優化,向更深的網絡結構、更輕量化的結構發展,模型性能也在逐漸提升。卷積神經網絡由于存在優異的性能,在目標檢測算法中具有更深層次的提升,使得目前許多領域在相關的研究中都采用了目標檢測算法,并取得了較好的成績。
3.2 基于候選區域的車輛目標檢測算法
基于候選框的車輛檢測方法通過2 個步驟實現,這類檢測算法的優勢是可以充分提取圖像的細節特征,故該算法有更好的檢測精度,但由于算法分為2個步驟,從而導致模型的運行速度較慢。
3.2.1 R-CNN
2014 年,Girshick 等對神經網絡算法進行不斷優化,進一步提出了R-CNN模型,是第一個將深度學習應用到目標檢測的算法,該算法總共4 個部分獲得檢測結果,首先通過網絡獲取檢測的圖像;其次對輸入的圖像采用選擇性搜素(Selective Search)算法,提出大約2 000 個區域候選框,并把不同大小的候選框縮放到相同大小;然后使用AlexNet 獲得候選區域的特征;最后利用多個SVM分類器和回歸器得到目標的類別和位置信息,結構如圖4 所示。雖然該類算法的檢測精度很高,但是還是有缺陷:
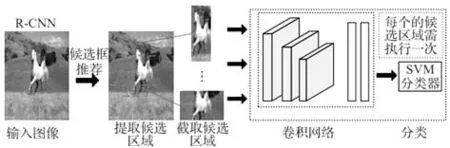
圖4 R-CNN框架網絡結構[16]
(1)網絡的各個階段都需要單獨訓練,這大大增加了算法的時間成本。
(2)卷積神經網絡需要對所有的候選框進行特征的提取,且大量的重復區域會產生大量的運算,增加計算復雜度。
(3)該算法需要對輸入圖像進行縮放操作,會導致一定的細節信息丟失。
3.2.2 SPP-Net
2015 年,為了解決R-CNN 缺陷的部分問題,He等提出了一種新奇的卷積操作模型,該網絡模型對輸入的圖像可以一次性進行卷積操作,沒有多余的步驟,這樣的操作大大減少了運算時間,且作者提出了一種新的池化策略,該策略主要思想是在網絡模型的最后一個卷積層后、全連接層前添加金字塔空間池化結構(Spatial Pyramid Pooling,SPP),這樣可以提取固定尺寸的特征向量,避免了在候選區域批量歸一化的操作。該算法的檢測速度相較于R-CNN快了24~102倍,但是該算法還是有缺陷:
(1)訓練方式分階段,每部分網絡都需要訓練,這樣的方式導致需要儲存大量特征,需要更多的空間成本。
(2)網絡在池化層的加入后只更新了后面的全連接層,忽略前面層數對網絡模型的影響,這會導致檢測精度變差。
3.2.3 Fast R-CNN
2015 年Girshick 等提出了Fast R-CNN 算法,該算法融合了SPPNet的思想,將網絡的SPP層設計成為單獨的一層,即ROI Pooling 層,進一步解決了權值更新的問題。另外該算法引入SVD,將全連接層的輸出分解,得到Softmax 函數分類得分和矩形窗口(Bound?ing Box)回歸,將分類和回歸問題進行合并處理,SVD的引入在不降低檢測精度的同時,大大提升了了檢測速度。其中使用Softmax 函數代替SVM,將卷積神經網絡提取的特征都儲存在顯存中,減少了磁盤空間的占用,提升訓練性能,加快訓練速度。但是該算法還是存在一定的缺陷:
(1)依然使用Selective Search方法選取候選區域,這一步驟不可避免會包含大量計算。
(2)目前算法無論在檢測精度和速度都有大幅度的提升,但是目前大多數領域在實時檢測的需求要求更高,故針對實時性較高的目標檢測問題,仍不能使用。
3.2.4 Faster R-CNN
對以上網絡存在的不足,微軟團隊的Ren 等經過大量的改進試驗,2015年正式提出了Faster R-CNN算法,算法主要是使用區域生成網絡(Region Proposal Networks,RPN)網絡替代Selective Search算法,成為了第一個真正意義上的端到端的網絡,訓練流程如5 所示。該算法的提出,大幅度提升了目標檢測速度,但是該算法也存在一定的瑕疵:
(1)沿用ROI Pooling 層,網絡特征失去平移不變性,導致最后目標檢測中定位的準確性降低。
(2)Faster R-CNN 在特征圖上使用錨點框去對應原圖,而錨點框在網絡上會經過多次下采樣操作,這樣會導致對應的原圖是一塊較大的區域,然后對小目標的檢測變得不理想。
(3)存在重復運算。
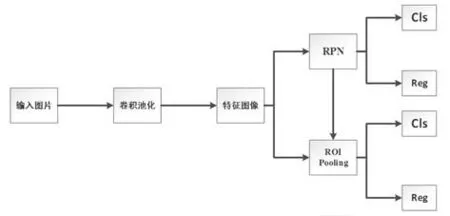
圖5 Faster R-CNN訓練流程[19]
3.2.5 R-FCN
針對Faster R-CNN 存在的問題,Dai 等對網絡進行一定的改進,提出了R-FCN。該算法主要是使用ResNet主干網絡替換VGG網絡,提升了網絡的特征提取能力和分類的效果,同時提出了一種特定的卷積層,生成包含目標空間位置信息的位置敏感分布圖(Position-sensitive score maps),解決了物體分類中平移不變性而物體檢測要求有平移變化的矛盾。
3.2.6 Mask R-CNN
2017 年Facebook 的He 等在前人對Faster RCNN 的研究基礎上,提出了Mask R-CNN 算法,網絡框架如圖6 所示,該算法主要應用于實例分割任務。算法主要提出了ROI Align 來代替ROI Pooling,從而實現更加精確的實例分割,然后提出增加一個Mask分支來預測每一個ROI上的分割掩碼,這樣的操作使分類分支、邊框回歸分支和Mask分支并行運行,在提高分割精度的同時,減少了運行時間,使得模型運行速度更快。該算法雖然運行速度較快,但不能滿足實時檢測的需求,且目前實例分割主要面臨大量標注代價的問題。
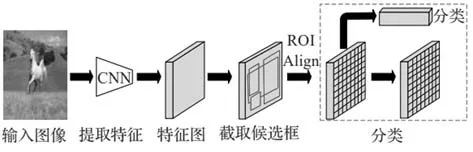
圖6 Mask R-CNN框架網絡結構[16]
3.2.7 Cascade R-CNN
之前大多數網絡結構都使用IOU 閾值來判斷正負樣本,在訓練過程中,采用較低的IOU閾值訓練目標檢測器(Object detector),通常會出現噪聲干擾;在逐漸提高閾值后,發現性能會有所下降。針對這一問題,2018 年Cai 等提出了一種級聯結構的目標檢測器Cascade R-CNN,該算法主要貢獻是能夠在低IOU值獲得更多“高IOU”樣本,且每一個階段的Object de?tector 都不會出現過擬合的情況,因為都有足夠滿足閾值的條件樣本。
3.2.8 TridentNet
在檢測任務中,存在目標尺度多樣化的問題,為了解決這個問題出現了許多經典的算法,如一階段的SSD 算法,或者依賴于圖像金字塔與特征金字塔FPN。2019 年,Li 等提出了一種利用空洞卷積構建的網絡TridentNet,且使用并行多分支學習輸入圖像的不同尺度目標的特征。這種算法與SSD算法相比,對于小目標檢測有更優越的性能。
目前,基于候選框的目標檢測算法仍然在不斷發展,雖然檢測精度在不斷提升,總體而言該類算法還是存在檢測速度不能達到實時檢測的需求。整個發展歷史過程中,新的網絡都是針對當前網絡的缺點,進而提出改進的方法,把前者的不足進一步完善,但網絡模型檢測速度提升并不夠,這也是該階段算法需要重點關注的問題。在未來發展過程中,該類算法應借鑒基于回歸的目標檢測算法去提高檢測速度,盡可能降低算法訓練時間,減少模型參數數量來滿足實時檢測的需求。表1總結了基于候選區域的車輛目標檢測算法的優缺點和適用場景。
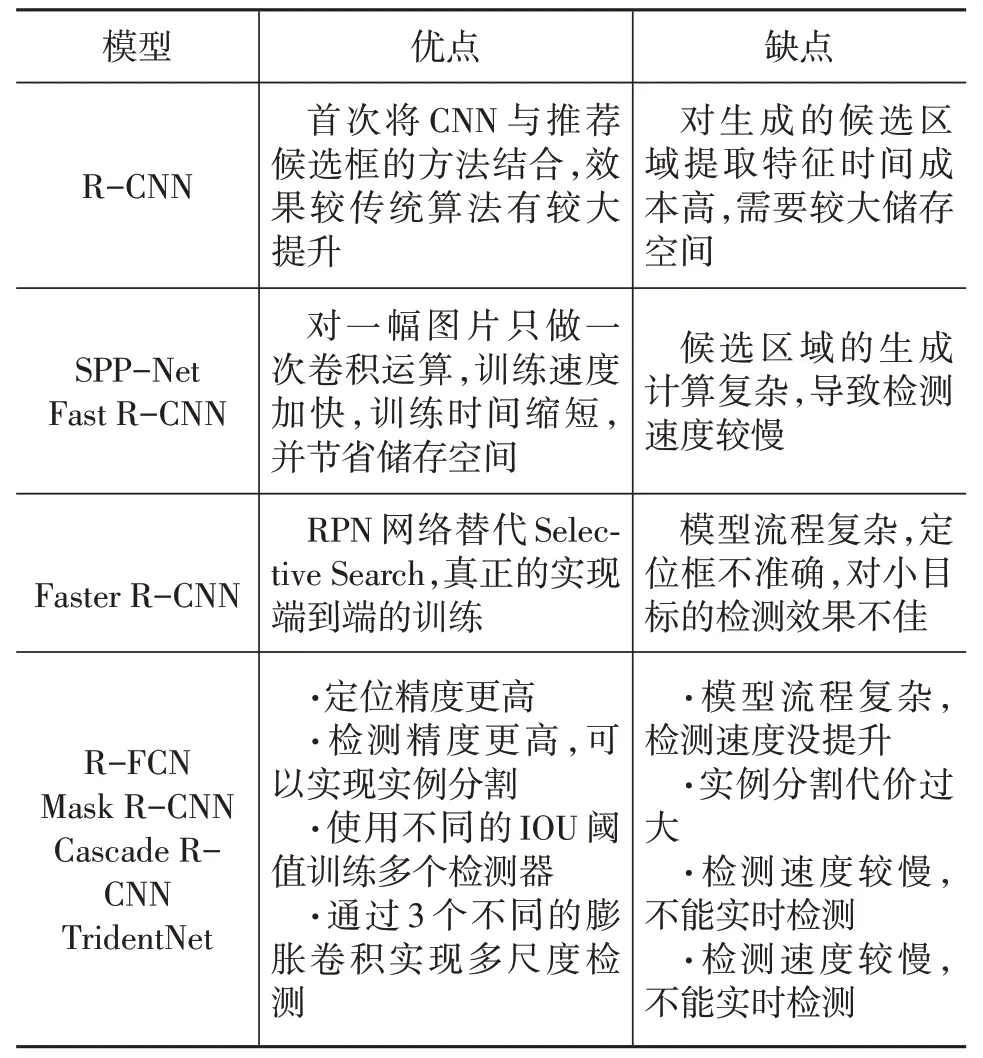
表1 基于候選區域的車輛目標檢測算法優缺點
3.3 基于回歸的車輛目標檢測算法
基于回歸的車輛目標檢測算法是針對圖像的分類和定位轉換回歸問題,可以經過一次運算從圖像中得到邊界框和類別概率的預測,該類算法主要優勢是模型的構建更為簡單,且檢測實時性更能滿足需求,但在檢測精度的方面還存在提升空間。
3.3.1 YOLO系列
目前基于候選區域的目標檢測算法普遍存在實時性檢測差的問題,2016 年,針對這個問題,Redmon等提出了YOLOv1 算法,主要的操作是將圖片劃分為S×S個網格,每一個網格檢測中心落在當前網絡的目標,預測出2 個尺度的Bounding Box 和類別信息,一次性預測出圖像區域包含的所有目標的Bound?ing Box、目標的置信度以及類別概率,得到最終的檢測結果,YOLO 的框架算法結構如圖7 所示。該算法的檢測速度非常快,達到了45 幀/s,但網絡會產生更多的定位誤差,在每一次特征提取后,使得網絡最終的檢測精度下降,且網格劃分的操作是很粗糙的,每個網格只預測2個Bounding Box,且類別相同,因此對小物體的檢測效果較差,對多物體環境下漏檢也很明顯。
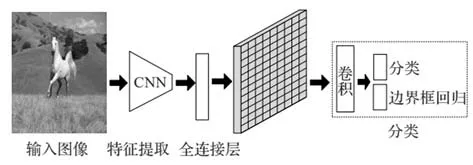
圖7 YOLO框架算法結構[16]
針對YOLOv1的問題,Redmon經過一段時間的嘗試,最終提出了檢測速度更快,精度更高的v2版本,主要創新是訓練了一個Darknet-19 的網絡作為主干網絡,用于更好的提取特征,并減少模型的計算量,同時網絡舍棄Dropout 操作,在每一個卷積層后添加BN層,加入新的K-Means 維度聚類方式,并進行多尺度訓練。文獻[26]還提出了YOLO9000,該算法應用WordTree 層次分類,能檢測多達9 000 多類物體的檢測。
2018 年,Redmon 等在YOLOv2 的基礎上,提出了更優秀的V3版本,使用更深層次的Darknet-53殘差網絡,并結合特征金字塔網絡進行多尺度的融合策略,使得算法能夠在3個不同的尺度上進行檢測,同時對于小目標的檢測效果有更好的檢測效果。
2020 年,Bochkovskiy 等融合各種調優技巧,使得模型實現了當時最優的試驗結果,并命名為YO?LOv4。模型主要選用感受野更大,參數更多的CSP?Darknet53 作為主干網絡,同時模型采用Mish 激活函數,Dropblock 模塊也加入到主干網絡中,起到了更好的檢測效果;并加入了SPP 模塊及FPN+PAN 結構讓網絡進行特征融合。YOLOv4較為突出的優點就是能夠使用單GPU進行模型的訓練,并不需要昂貴的訓練設備。
同年也出現了YOLOv5 版本,總共有4 個模型YOLOv5s、YOLOv5m、YOLOv5l 及YOLOv5x,YOLOv5s是4 個版本中深度最小、特征圖寬度最小的網絡,其它3個模型就是在此基礎上不斷加深網絡、加寬寬度后形成的模型。YOLOv5 主要創新是在輸入端應用自適應錨框計算,在Backbone 加入了一種Focus 結構,在預測端提出了一種訓練GIOU_Loss 函數。總體來說改進的網絡模型YOLOv5 在檢測精度和速度上都有一定的提升,對后續算法的改進有著較好的借鑒意義。
3.3.2 SSD
針對YOLO 算法容易造成漏檢和對尺度變化較大物體的泛化能力較差的問題,2016 年Liu 等提出了SSD算法,該算法主要目的是有效地進行小目標和多尺度的檢測,采用6 個不同尺度的FeatureMap 進行檢測任務;同時結合Faster-RCNN 中的Anchor,提出了Default boxes 的生成,這些改進點都提高了算法的運行速度和檢測精度,網絡也得到了廣泛的應用,雖然主要是針對小目標的檢測,但淺層特征的特征圖包含的語義信息較少,使得算法對小目標的檢測仍達不到Faster R-CNN的精度。
3.3.3 RetinaNet
基于回歸的目標檢測算法的運行速度雖然很快,但是檢測精度始終沒有基于候選區域的目標檢測算法高,針對這一問題,研究者發現主要原因是因為正負樣本不平衡造成的。2017 年,Lin 等設計了一個簡單密集型網絡(RetinaNet),RetinaNet訓練在保證速度的同時達到了精度最優。作者提出了使用Focal Loss解決負樣本過多的問題,并使用RetinaNet網絡證明Focal Loss 的有效性,同時試驗證明了檢測速度能夠與單階段的檢測算法媲美,且檢測精度超越了當時的最先進的兩階段的檢測算法。
3.3.4 CornerNet
在單階段的檢測算法中,很多都是基于Anchor,但是這種方法也有許多缺點,大量的Anchor會產生很多超參數,如Anchor 的比例、數目、大小,同時也會帶來正負樣本不平衡的問題。針對以上不足,2018 年Law 等提出了CornerNet 算法,該算法沒有沿用An?chor的方式,而是將目標檢測的問題以另一種方式進行檢測。對關鍵點檢測,主要操作是通過檢測目標框上的左上角和右下角2 個關鍵點得到預測框,進而得到檢測結果,也為目標檢測算法提供了一種新思路,且試驗結果表明在精度上有一定的提升,但是該算法對于2個關鍵點的檢測還是比較慢的,這一定程度上影響了檢測速度。
3.3.5 CenterNet
針對CornerNet 在關鍵點檢測過程較慢的不足,2019 年由Duan 等進一步做了大量的研究,提出了CenterNet 算法。該算法的主要目的是將目標檢測問題轉換為對一個中心點的檢測,且無需后處理過程,CenterNet直接回歸目標框尺寸,最后基于目標框尺寸和目標框的中心點位置就能得到預測框。算法的改進能夠提高檢測速度,且目前由于Anchor-free的大量應用,提高了研究人員將該算法擴展到其它目標檢測任務類型的信心。
3.3.6 EfficientDet
目前各個領域都有使用目標檢測技術,工業界更是把檢測精度和檢測速度作為最重要的指標,但提出的所有算法不能同時顧及這2 項指標,一項指標的提升會犧牲另一項指標,針對目前基于回歸的目標檢測算法速度較快,但檢測精度相對較低的問題,Tan等提出了一種能夠把檢測速度和檢測精度同時做到最優的算法EfficientDet,該算法網絡結構如圖8 所示。該算法主要將EfficientNet作為主干網絡,提出了一種簡單高效的加權特征金字塔網絡BiFPN,同時提出了復合系數來改變網絡的分辨率、深度和寬度。目前該網絡在COCO 數據集上試驗結果達到了51.0%的檢測精度,且檢測速度非常快,在嵌入式設備及移動端都能大規模的應用,也能為后續算法的提出與改進起到啟發式的作用。
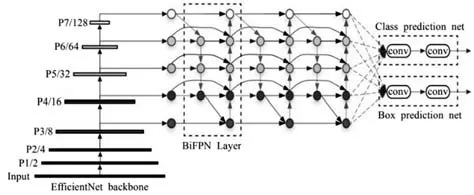
圖8 EfficientDet框架算法結構[36]
基于回歸的車輛目標檢測算法的優缺點如表2所示。
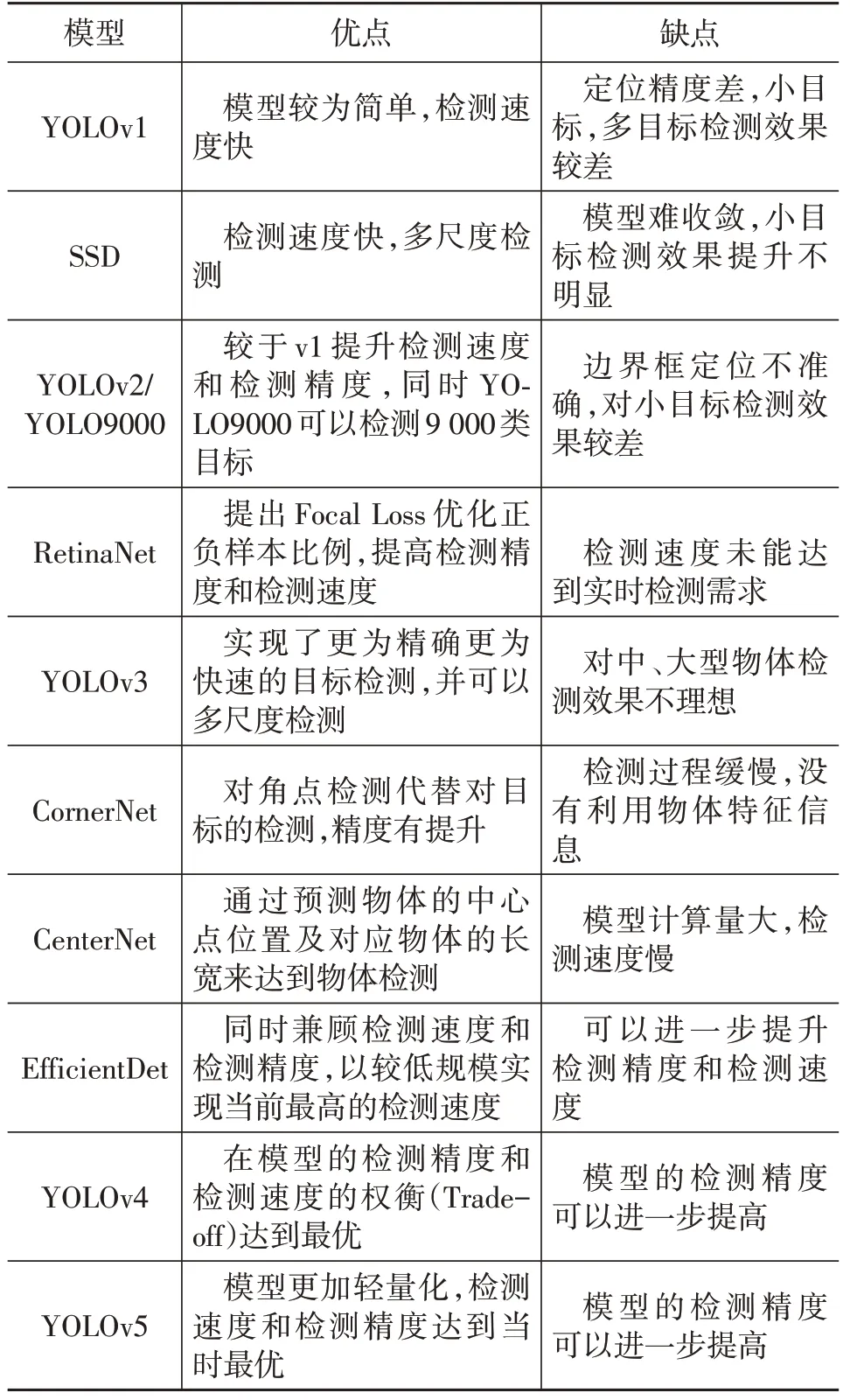
表2 基于回歸的車輛目標檢測優缺點[41]
近3 年來,2 種主流算法的檢測精度和檢測速度都在不斷提高,除此之外更多優秀的算法也在不斷提出。對YOLO 系列算法改進后,在模型參數數量減少的同時,改善了對不同尺度目標檢測的效果,對SSD系列算法進行改進后,小目標多尺度檢測精度得到提高,也應用于復雜場景下的車輛目標檢測;Effi?cientDet 網絡算法用更少的參數量實現更高精度,模型更加精簡;基于關鍵點的檢測算法用全新的方式提高了算法的檢測性能,有望成為下一階段的研究重點。硬件設備的不斷完善,給目標檢測算法領域帶來了不少的機遇和挑戰,車輛目標檢測算法性能的不斷提高給智能駕駛和智慧交通系統帶來了前所未有的新發展。
4 總結與展望
本文針對車輛目標檢測任務,首先對深度學習的車輛目標檢測進一步探討,提出檢測任務的重點、難點和發展現狀,以時間線對卷積神經網絡下車輛目標檢測算法進行概括,并對目前2種主流的基于候選框和基于回歸的車輛目標檢測算法進行總結。總體來說,基于候選區域的車輛目標檢測算法檢測精度較高,由于候選區域的生成花費大量的時間成本,使得檢測速度較慢,檢測實時性尚不能滿足要求。而基于回歸的車輛目標檢測算法雖然精度上普遍不如前者,但在檢測速度上具有很大的優勢,隨著深度學習技術快速發展,檢測精度也有大幅度的提升。目前基于深度學習的車輛目標檢測算法處于一個快速發展的階段,算法的創新和計算機視覺技術的發展提升了算法檢測性能,輕量化的算法模型在嵌入式設備中得到了普遍使用,使得車輛目標檢測任務效率進一步提高。目前基于深度學習的車輛目標檢測算法仍有許多改進的空間,歸納如下:
(1)數據集場景和質量問題。數據集在獲取中仍不完善,缺乏復雜場景下的車輛目標檢測數據集,這導致算法在特定場景的檢測魯棒性較差;數據集的質量不夠高,這將會導致算法檢測精度下降,且構建數據集對人力需求較大。
(2)其它形式上的目標檢測問題。目前車輛目標檢測都是以圖片形式進行檢測,而3D檢測、視頻流檢測的算法性能還有待提高。
(3)復雜場景下的多目標,小目標檢測問題。目前車輛目標檢測算法在復雜場景下的單目標檢測效果較好,在對多目標檢測時,會出現漏檢、誤檢的問題,造成精度降低;而在尺度異常和群體小目標中的檢測效果更差。
在未來自動駕駛和智能交通系統中,對于精確性和實時性的要求會更高,車輛目標檢測的重要研究方向將會圍繞以上3點進行不斷優化,滿足更高需求。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
