摩托車頭盔佩戴檢測算法研究綜述
2022-08-03 01:47:24張之云蘇山杰
汽車文摘 2022年8期
張之云 蘇山杰
(重慶交通大學機電與車輛工程學院,重慶 400074)
主題詞:摩托車頭盔 佩戴檢測 深度學習 目標檢測
NMS Non Maximum Suppression
KNN K-near Neighbor
SIFT Scale Invariant Feature Transform
LBP Local Binary Patterns
HOG Histogram of Oriented Gradient
HOI Human Object Interaction
CNN Convolutional Neural Network
SPP Spatial Pyramid Pooling
FCN Fully Convolutional Networks
SSD Single Shot Multi Box Detector
RSSD Rainbow-SSD
SVM Support Vector Machine
RPN Region Proposal Network
YOLO You Only Look Once
ROI Region of Interest
GPU Graphics Processing Unit
COCO Common Objects in Context
MAP Mean Average Precision
CSPNet Cross Stage Partial Networks
DIoU Distance Intersection over Union
CBAM Convolutional Block Attention Module
1 引言
一些欠發達地區,摩托車作為出行的主要工具,駕駛的安全問題越來越受到社會的關注。摩托車頭盔的佩戴對駕駛員的安全十分重要。據世界衛生組織(WHO)預測,2022 年中國的摩托車保有量達到7 925.1 萬輛,到2030 年摩托車保有量下降到7 500 萬輛。摩托車事故中,頭部受傷是導致死亡的主要原因。正確佩戴頭盔能降低42%的死亡率和69%的受傷率,摩托車頭盔能有效的保障駕駛者及乘客的安全。因此,在行駛過程中能及時有效的檢查駕駛人員的頭盔佩戴情況對減少交通傷亡事故非常重要。
最原始的頭盔佩戴檢測方法是交通部門派遣工作人員現場監督。這種檢測方法存在許多弊端,首先需要大量的資金和人力資源的投入,同時檢查效率變低、危險性大、容易造成道路擁堵的情況。
隨著計算機科學的迅速發展和智能交通的興起,對于一些特定場景下的目標可以采取自動檢測的方法,這些方法可以分為傳統的機器視覺檢測方法和基于深度學習的檢測算法兩種類型。本文先對摩托車頭盔檢測方法進行綜述,總結目前存在的問題,最后對摩托車頭盔佩戴檢測方法的未來發展進行展望。
2 傳統計算機視覺技術的摩托車頭盔檢測
計算機視覺技術使機器能夠通過相關設備和計算機來獲取圖片的信息,對人類視覺進行模擬,最終能夠對物體起到識別的作用。如圖1 所示,傳統的目標檢測方法主要分為感興趣區域的劃分、特征的提取和分類以及回歸4 個步驟。到目前為止,國內外許多研究者對摩托車頭盔的檢測做了大量的研究,以下是基于傳統計算機視覺的摩托車頭盔檢測的相關工作。

圖1 傳統目標檢測算法流程
使用頭盔檢測或搜索的方法來確定摩托車頭盔能有效提高檢測系統的效率和魯棒性。Chiu等提出了一種計算機視覺系統,用于檢測和分割被遮擋的摩托車。該方法使用視覺長度、視覺寬度和像素比來檢測被遮擋的摩托車,并將摩托車從中分割出來。再使用頭盔檢測或搜索的方法來確定頭盔是否存在,該方法克服了遮擋問題。Waranusast R 等提出了一種自動檢測摩托車駕駛員和安全頭盔的系統。該系統使用K-最鄰近(KNN)分類器,根據特征進行摩托車分類,然后對駕駛員的頭部進行計數和分割,該方法根據4 個部分的頭部特征對戴頭盔與不戴頭盔進行分類。R.Silva等,提出了一種基于局部二進制模式,采用定向直方圖和霍夫變換描述符的特征提取混合描述符。使用攝像機捕獲的交通圖像,從而對摩托車頭盔進行檢測。Chiverton等使用基于邊緣直方圖的特征來檢測摩托車駕駛員,這種方法的優點在于它不會受邊緣直方圖以及視頻中光照強度的影響。由于邊緣直方圖使用圓形霍夫變換來比較和分類頭盔,因此導致對頭盔的許多錯誤分類。Silva等提出了一種系統來處理卡爾曼濾波器跟蹤車輛的錯誤分類問題。卡爾曼跟蹤系統的一個顯著優點是能夠連續跟蹤物體,即使它們稍微被遮擋。但是當2 個或3 個以上的摩托車手出現在同一幀中時,卡爾曼濾波器會失敗,因為卡爾曼濾波器主要適用于線性狀態轉換。但是要跟蹤多個對象時需要非線性函數。Dahiya K 等提出了3 種特征表示方法:尺度不變特征變換(SIFT)、局部二值模式(LBP)和方向梯度直方圖(HOG)。分兩個不同的階段實現:首先利用背景減法和目標分割法從監控視頻中檢測駕駛員。然后利用視覺特征和分類器判斷駕駛員是否戴頭盔。第一階段檢測駕駛員,第二階段定位駕駛員的頭部并檢測頭盔。針對傳統的目標檢測方法中效率低以及時間成本大的問題,張乾雷等采用了一種基于并行點檢測和點匹配的單階段HOI Detection 方法。先采用新的全卷積方法對人與物體之間的相互作用直接進行檢測,通過網絡預測交互點人物交互進行分類和定位,與密集預測的交互向量配對,通過人類和物體檢測相關聯來獲取檢測結果。與傳統的兩階段算法相比,HOI算法的檢測精度與準確率都有了很大提高。
傳統機器學習,這類方法大多是依靠人為的設計來選取特征,需要實驗者具有扎實的專業知識和豐富的實驗經驗,特征設計的過程十分復雜,不但費時費力,而且不能獲取良好的特征、檢測速度慢、精度低也難以適應復雜的條件變化。經過不斷迭代研究,計算機視覺技術正從機器學習向深度學習神經網絡技術方向發展,它不僅速度快、精度高,在整體的檢測性能指標上都能有大的提升,這為目標識別技術領域未來發展提供了新動力。
3 基于深度學習的摩托車頭盔檢測算法
近幾年,深度學習目標檢測已經成為圖片及視頻識別和分類的主流方法,使用卷積神經網絡自動對圖像進行特征進行提取,從而對目標進行識別和定位。深度學習檢測算法可以從區域建議和回歸2個方面劃分為雙階段和單階段2 種不同的類型。表1 將雙階段與單階段的檢測算法在不同的功能上進行了對比。
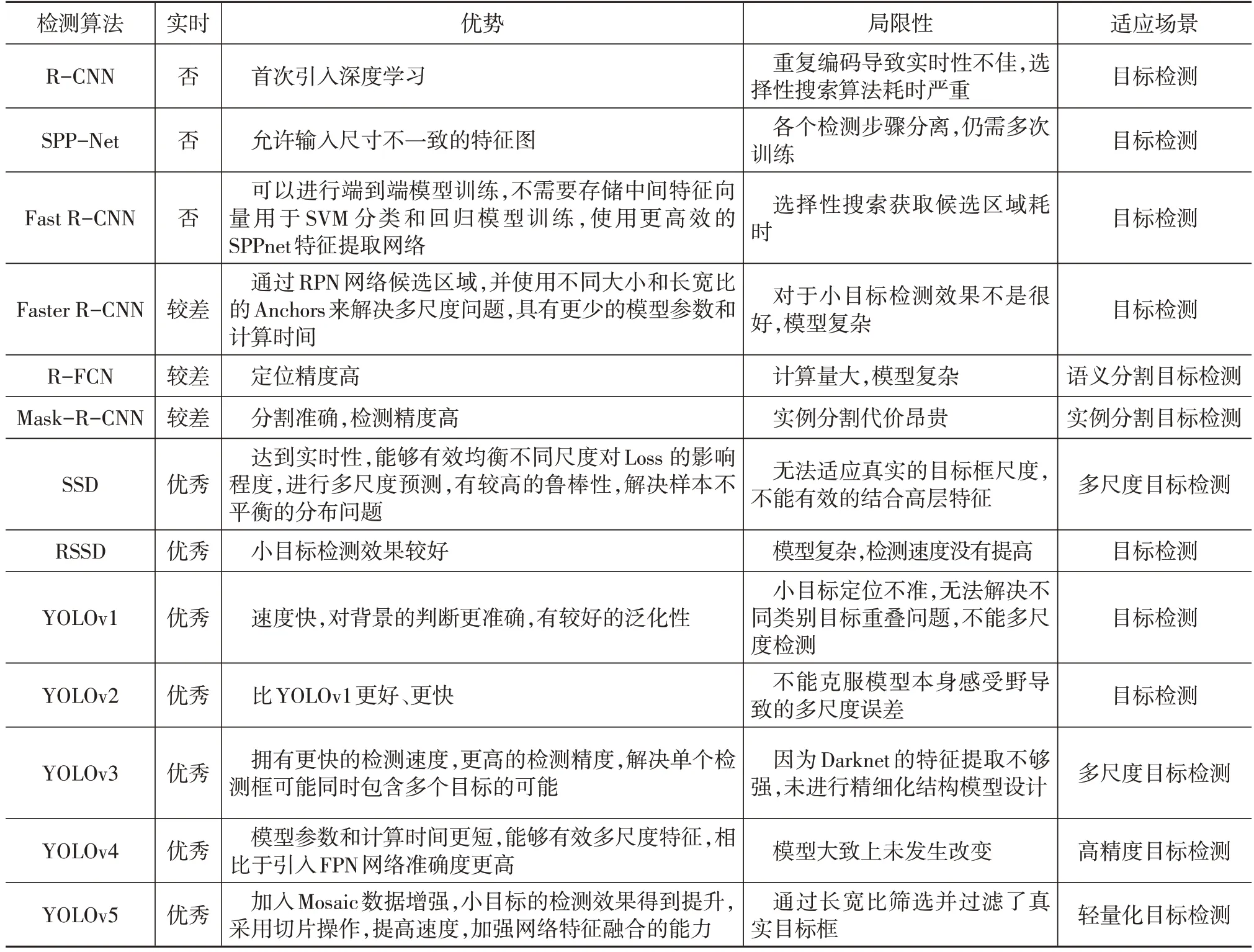
表1 雙階段與單階段檢測算法的性能對比
3.1 雙階段的摩托車頭盔檢測算法
雙階段的摩托車頭盔檢測算法主要以Faster RCNN 為主。該方法先利用算法來獲取候選區域,再通過卷積神經網絡對樣本進行分類。圖2 是Faster R-CNN 的整體結構,Faster R-CNN 首先使用一組基礎卷積層提取圖片的特征,該特征圖被共享用于后續的RPN 層和全連接層,RPN 網絡用于生成候選區域,該層通過Softmax 判斷Anchors 屬于前景還是背景,再利用邊界框回歸來修正Anchors 獲得精確的預測框。使用ROI pooling 層來綜合輸入特征圖和候選框的信息,提取候選特征圖,在后續的全連接層判定目標類別。
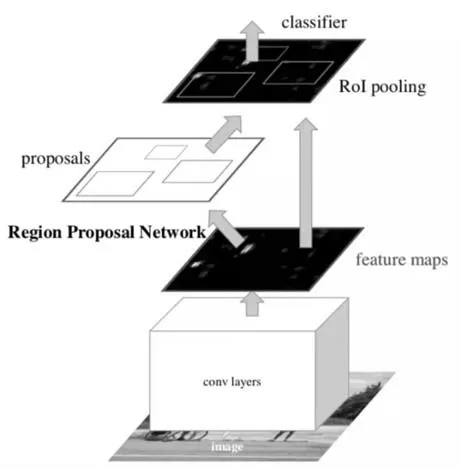
圖2 Faster R-CNN的整體結構[10]
Yogameena 等提出的系統基于Faster R-CNN 來檢測標記的前景目標中的摩托車,以確保摩托車駕駛員的存在。隨后,Faster R-CNN 也被用于檢測是否戴頭盔的摩托車駕駛員。由于目標檢測過程會受到分辨率、天氣條件和光照條件不同因素的影響,無法達到理想的檢測結果。Afzal A 等提出了一種監控視頻自動檢測摩托車駕駛員是否佩戴頭盔的方法。首先,應用候選區域網絡RPN對卷積得到的特征圖進行候選框選取,對頭盔進行檢測,最后再對檢測到的頭盔進行識別。試驗結果表明,實時監控視頻對摩托車頭盔的檢測準確率達到97.26%。
相比于傳統的檢測算法,深度學習的雙階段目標檢測算法降低了原來的計算量,加快了檢測速度。應用網絡自動提取候選區域的特征,解決了獲取特征信息不足的問題,提高了檢測精度。利用多類別分類器推斷類別概率,并使用邊界框回歸模型求出預測框的修正位置,使其更接近真實框,從而改善了算法的整體檢測性能。單階段網絡能夠達到實時的效果,更具備實用價值,因而大多數研究都是針對單階段算法。
3.2 單階段摩托車頭盔檢測算法
單階段算法一次性完成對物體的分類和定位,與雙階段檢測算法比,這種方式運算速度更快,能夠達到實時檢測的效果,其主要以YOLO、SSD 算法為代表。
Dasgupta 等提出了一個框架,用于檢測不戴頭盔的單人或多人騎摩托車騎行。在建議的方法中,在第一階段,使用YOLOv3 模型來檢測摩托車駕駛,在第二階段,提出了基于卷積神經網絡(CNN)的體系結構,該結構受到YOLO-Lite 網絡結構的啟發,減少了網絡結構層數,并且GPU 設備使用Batch Nor?malization 來檢測摩托車駕駛員的頭盔。Khan 等提出了一種計算機化的機器結構,以區分有或沒有頭盔的摩托車駕駛員與圖像,系統基于特征提取對象類。該系統使用YOLO-Darknet 深度學習框架,考慮到網絡的大小使用了YOLOv3-Tiny,通過以往在CO?CO 數據集上預訓練,然后在摩托車檢測數據集上進行微調來實現對摩托車駕駛員頭盔佩戴情況的檢測。針對現有的安全頭盔佩戴檢測正確率不高的問題,薛瑞晨等提出了一種改進的YOLOv3。將空間與通道的注意力模塊進行特征融合,并結合密集連接網絡來提高特征提取效果,并且引入了空間金字塔池化結構以增強特征,檢測精確度能達到93.29%。劉琛等對主流的單階檢測網絡SSD-Net引入類似視覺機制的模塊,對網絡特征圖在通道和空間上進行了權重的重新選擇,并增加了類似人類視覺偏心率機制的RFB 模塊。通過使用Mosaic 方法進行數據增強,并采用余弦衰減學習率來優化網絡。試驗結果表明改進后的網絡對摩托車頭盔佩戴的檢測結果比原始SSD-Net 提升了4%的mAP(Mean Average Precision),具有更好的應用效果,也被用于檢測摩托車駕駛員佩戴頭盔情況。王海寬等在Yo?lov3 網絡中加入跨階段局部網絡(CSPNet)來改進darknet53 的骨干網絡,降低了計算成本,其次通過空間金字塔池(SPP)結構,結合自上而下和自下而上的特征融合策略來改進多尺度預測網絡,達到特征增強和提升精度。Tan 等基于YOLOv5 增加檢測的尺度來獲取更小的目標,然后用DIoU-NMS 代替NMS,使其在抑制預測的邊界框時更加準確,該算法顯著提高了精度,可滿足實時檢測的需要。為了加強對施工人員的安全監督,提高檢查效率,Zhou 等對YOLOv4 算法的卷積神經網絡的損失函數進行替換,通過改變注意力機制來提高檢測網絡對于微小物體的敏感度,并且添加參數來解決類別不平衡的問題。試驗結果表明,改進的算法提高了網絡模型在檢測和識別安全頭盔佩戴的準確性。
采用候選框的雙階段檢測算法準確率較高,但是網絡的模型較大且結構復雜,運算量大,檢測的速度較慢。目前較為受歡迎的單階段算法具有較好的檢測性能,特別是對簡單目標來說,更能滿足實時性和準確性的要求。
4 摩托車頭盔檢測面臨的問題
4.1 復雜場景下的摩托車頭盔數據集的獲取問題
由于摩托車駕駛環境的多樣性、路況的復雜性,采集的圖片和視頻較為片面,現目前的數據集主要通過網絡進行收集或者針對特定情況下拍攝的圖片和視頻獲得,圖片單一、數量也比較少,導致對模型的訓練效果不是很好,從而影響模型的判斷力,降低了檢測精度。更全面的數據集應涵蓋真實環境下所出現的情況,能夠提高模型在不同情況下的魯棒性。趙睿等對馬賽克數據增強方式進行改進,增加了不同光照強度的小尺度樣本數據集,將圖片的拼接數量由原本的4張增加到了9張,增加小樣本的數量,剔除了多余的邊緣面積來加快模型的訓練速度。考慮多種不同環境條件會增加數據集的多樣性,對提高模型的魯棒性有很大的幫助。
4.2 遠距離、小目標和遮擋時摩托車頭盔識別問題
對于遠距離頭盔的檢測仍存在可用的特征少、定位精度不高、小目標易聚集問題,很難提高檢測精度,摩托車的頭盔檢測比施工現場復雜,遠處有更多的小目標。此外,在騎行過程中,目標的定位比較困難,駕駛員的頭腦更容易在圖像中聚集,從而引起車輛被遮蔽的問題,這給檢測任務帶來了更大的挑戰。
現在較先進的YOLO 算法已經能夠在速度和精度做到很好的平衡,針對遠處小目標和密集型目標的檢測準確率還是有很大的提升空間。近幾年也有許多研究者提出了相應的改進辦法,Wang等提出了一種改進的基于YOLOv5 的頭盔佩戴檢測方法YO?LOv5s-FCG,在YOLOv5 系列中YOLOv5s 體積最小的基礎上,對網絡進行改進,增加了淺層特征檢測層,將3 個尺度特征檢測改為4 個尺度的特征檢測,添加CBAM 注意力模塊,使用輕量級的Ghost Bottleneck 代替Bottleneck。該算法不僅保證了檢測率、體積、參數量,而且提高了檢測精度。對弱光、小目標的復雜道路環境具有良好的適應性。因此,針對非常普通的使用條件對算法進行改進,能夠明顯提高檢測模型的實用性。
5 總結與展望
本文分別對傳統的機器視覺與基于深度學習的摩托車頭盔佩戴檢測算法進行了綜述,早期實施的傳統方法在頭盔識別方面雖然能達到不錯的效果,但對于特征的選取主要依賴人為決定,而且需要較高的專業領域的知識和大量的人力和物力。另外,容易受天氣、光線和位置形態因素的干擾,算法相對復雜,而且性價比不高。而使用卷積神經網絡對圖片自動進行由淺到深的特征提取,使模型能夠學到數據中更高層次的信息,并且隨著數據集質量的越高,模型提取特征層次的能力就越強。基于深度學習的單階段算法比雙階段算法的模型更簡單,檢測速度也能滿足實時檢測的要求。但針對目前數據集的質量、應對復雜特征的識別能力還有待提高。
不同模型的訓練流程和策略都不同,當前的目標檢測模型具有更復雜的網絡結構和優化目標。未來,不同的優化方法應被更多地應用到各個算法當中。主要從數據、網絡結構優化、損失函數、訓練調參方面進行改進。主要的目的在于未來摩托車頭盔檢測網絡能達到高精度、高速度、較強的泛化能力。將改進后的模型能應用于計算量小的嵌入式設備中,比如交通部門的智能監控、摩托車安全啟動系統監測設備中。一方面,加強對摩托車戴頭盔佩戴情況實時監督,降低摩托車駕駛違規行為,從而提高行駛安全性并保障道路交通順暢。另一方面,隨著交通的智能化發展,將頭盔佩戴情況的實時檢測器與摩托車頭盔提醒系統結合起來,并使用后臺服務器進行記錄,搭載提醒式的摩托車可以減少非法行為的發生,對摩頭車智能駕駛的發展有一定研究意義。
猜你喜歡
汽車實用技術(2022年14期)2022-07-30 06:13:42
汽車實用技術(2022年4期)2022-03-07 06:07:20
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
公民與法治(2016年4期)2016-05-17 04:09:26
