基于Stacking模型融合的胎兒健康狀態智能評估
2022-08-03 06:59:02郝婧宇陳奕吳水才
中國醫療設備 2022年7期
郝婧宇,陳奕,吳水才
1. 北京工業大學 環境與生命學部,北京 100124;2. 首都醫科大學附屬北京婦產醫院 婦產科,北京 100124
引言
電子胎心監護(Electronic Fetal Monitoring,EFM)是臨床上關注度最高的產檢監測指標之一,是通過超聲多普勒形成的脈沖向胎兒心臟傳輸信號,通過得到的胎心率(Fetal Heart Rate,FHR)變化來評估胎兒在子宮內的狀況[1]。臨床表明,FHR 曲線的變化有助于發現胎兒窘迫、宮內缺氧或酸中毒等異常病理狀態[2]。然而,由于FHR 信號的復雜性與多樣性,導致人工判讀結果存在一定偏差。利用智能分類算法可以輔助醫生診斷,對降低胎兒宮內缺氧、胎兒窘迫、新生兒窒息、缺血缺氧性腦病等不良妊娠結局具有重要意義。
近年來,國內外學者對胎兒心率參數定量研究,采用主成分分析、套索回歸等方法從原始特征集中選擇最優特征子集,隨后運用機器學習算法對胎兒健康狀態進行評估。2017 年,Georgoulas 等[3]運用曲線下面積對FHR 信號的54 個線性和非線性特征進行排序后,使用最小二乘支持向量機分類器來診斷胎兒類別。2018 年,Zhao 等[4]設計了統計檢驗、曲線下面積(Area Under Curve,AUC)和主成分分析等方法選擇出多模態信號特征,運用決策樹、支持向量機和自適應增強決策樹(Adaptive Boosting,Adaboost)執行分類,最終分類準確率(Accuracy,ACC)為92%。Li 等[5]從胎心圖中提取7 個特征參數,利用一維卷積神經網絡對FHR 信號進行分類,ACC 為93%。2020 年,葉明珠等[6]采用盲分割、插值法對信號預處理后,得到FHR信號的瞬時頻率特征圖,提取特征子集后運用支持向量機對FHR 分類,ACC 為97%。
在胎兒狀態的評估中,數據預處理至關重要,是獲取高準確性的第一步。其次,在特征選擇和模型構建時,一些機器學習模型的特征向量維數較低,并且過度依賴于時間特征。因此,本文將從數據處理、特征選擇和模型構建等3 方面做出研究。首先,運用極端梯度提升樹(Extreme Gradient Boosting,XGBoost)算法與HeatMap 對公開的胎心數據集進行分析,構建兩個新特征作為最終模型的輸入,提出一種兩層Stacking 模型融合的新方法用于胎兒健康狀態的分類,以輔助臨床醫師對宮內胎兒的健康狀態進行診斷。
1 數據和方法
1.1 實驗數據來源
本研究采用的數據集是波爾圖大學在UCI(Machine Learning Repository,https://archive.ics.uci.edu/ml/index.php)中公開的葡萄牙孕婦29~42 周的真實胎心數據集[7],該數據集是研究胎兒心電分類算法的常用數據庫之一,已被廣泛用于算法的驗證。
UCI 數據集中包含21 個臨床特征和2 個類別屬性,其臨床特征是通過SisPorto 2.0[8]分析程序從胎心監護圖中提取出來的,包含了致命心律的各種度量以及基于FIGO 指南的由產科專家分類的公共特征,包括臨床實踐中常見的形態學特征、時域特征、頻域特征等,23 個屬性的完整定義及說明如表1 所示。數據集共有2126 個樣本,其中“正常、可疑、異常”3 類的病例數分別有1655、295 和176 個,本文的任務是用前22 個變量作為自變量預測胎兒的狀態類別。

表1 數據集中23個屬性的完整定義及說明
1.2 實驗數據的臨床獲取
臨床表明,當缺氧、酸血癥和藥物誘導等現象發生時,會在時域和頻域內產生明顯的FHR 值變化[9]。臨床應用的胎心監護儀只顯示以每分鐘數表示的簡單的形態學參數,而不提供用于胎心率變異性(Fetal Heart Rate Variability,FHRV)分析的時頻域、非線性等其他參數,因此對胎心曲線的分析與解讀來說,最重要的是如何準確獲取上文所提數據集中包含的特征參數。
FHR 基線是指在沒有加減速和顯著變異的情況下,10 min 內胎心波動的平均值,一般可在胎心監護圖中直接獲得。FHR 加減速是指受到宮縮、胎動時,FHR 出現加快或減慢且與基線之差超過一定閾值,并持續十余秒的變化過程,可通過相位整序信號平均技術(Phase Rectified Signal Averaging,PRSA)計算加速(Acceleration Capacity,AC)與減速(Deceleration Capacity,DC)。
根據PRSA 計算AC 的公式如式(1)所示。
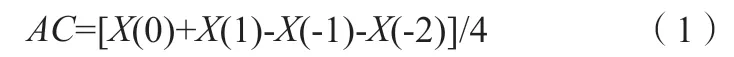
其中,X為心率加速點對應的心動周期的平均值,單位為ms,結果為負值。
根據PRSA 計算DC 的公式如(2)所示。
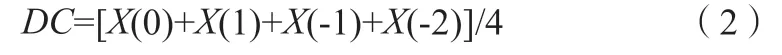
其中,X為心率減速點對應的心動周期的平均值,單位為ms,結果為正值[10-11]。
基線變異是指每分鐘FHR 自波峰到波谷的振幅改變,分為長變異(Long-Term Variation,LTV)與短變異(Short-Term Variation,STV)。這種變異估測的是兩次心臟收縮時間的間隔,在監護圖上無法直接辨認,需要計算才可獲得[11]。一些實用軟件,例如,Matlab 中的峰值檢測算法可以計算收縮峰值與持續時間,從而建立心率和心率變異信號之間的聯系。除此之外,可以對FHR 變化序列進行經驗模式分解,得到的若干個內蘊模式函數分量,然后進行希爾伯特-黃變換,得到希爾伯特譜及其邊界譜,最后計算FHR 的希爾伯特邊界譜在不同頻帶范圍內的功率,建立一個定量測量的方法[10]。從而獲得異常短期變異性的時間百分比(Abnormal Percentage of Time for Short-Term Variability,ASTV)、短期變異的平均值(Mean of Short-Term Variation,MSTV)、異常長期變異性的時間百分比(Abnormal Percentage of Time for Long-Term Variability,ALTV)、長期變異的平均值(Mean of Long-Term Variation,MLTV)等特征參數。
FHR 頻率直方圖的最小值(Min)、最大值(Max)、峰值(Nmax)、零點(Nzeros)、眾數(Mode)、均值(Mean)、中值(Median)、方差(Variance)等可通過連續小波變換(Continuous Wavelet Transform,CWT)在頻域和時域進行多分辨率分析。通常,小波被定義為母小波φ(t)和一組子小波φs(t),通過對φ(t)進行尺度變換得到φs(t),每個φs(t)的頻率含量與一定的頻帶相關聯,CWT 利用這一性質,將φs(t)與信號x(t)進行比較,FHR 信號中RR[n]的CWT 如式(3)所示。
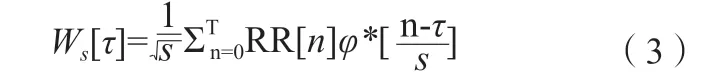
其中,φ*為小波的復共軛,計算某一尺度下每個時刻的功率如式(4)所示。
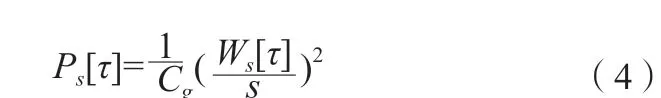
其中,Cg為可采性常數,通過計算Ps[τ]的平均值并對該頻段內的尺度積分,可以計算出某一頻段內的頻率,進 而 計 算 出Min、Max、Nmax、Nzeros、Mode、Mean、Median 等特征參數[12]。
1.3 類不平衡問題
類不平衡是指訓練分類器所使用的訓練集類別分布不均。在醫療領域中,數據集通常是不平衡的,多數類樣本數量與少數類樣本數量之比高達106[13],在臨床胎心監護案例中,異常類也極為稀少,若以不平衡數據建模,占據多數的正常類會被過度學習,使得分類算法傾向于忽略少數類樣本。例如,本文使用的數據集包含2126 個樣本,其中有471 個被評估為負類,正類和負類之比達9 ∶2,即任何分類算法的準確度均可達9/(9+2)×100%=82%,這是不合理的。面對不平衡的數據集,Jyothi 等[14]提出利用3 種不同的加權,同時利用合成少數類過采樣技術(Synthetic Minority Oversampling Technique,SMOTE)與決策樹相結合的方法解決類別不平衡的問題。張揚等[15]也采用SMOTE,利用線性插值,解決類不平衡的問題。
在本文中,采用SMOTE 與k-最近鄰相結合的方法對少數類樣本進行填充。該方法利用k-最近鄰的思想,在相距較近的兩個少數類樣本間插入新樣本,形成規模更大的訓練集。
采用SMOTE 技術后,數據集由2126 例變為3310 例,其中負類為1655 個,樣本數趨于平衡。其中原始數據集中的正常類、可疑類、異常類分別有1655、295 和176 個,受楊蔓麗等[7]研究的啟發,本文將數據集中的可疑類、異常類兩類數據進行合并,歸為“負類”,當某個樣本被判斷為“負類”時,需及時進行就醫,更加符合臨床實際意義。
1.4 特征工程
選擇合適的特征子集是機器學習算法中的關鍵步驟。在絕大多數分類問題中,某些特征往往包含重疊信息,相關性較高,甚至無法達到預期的信息量。因此,在應用分類算法之前,需進行特征選擇,減少一部分特征或構建一部分新的特征。選擇出最優特征子集作為分類器的數據輸入,不僅能提高計算效率,還能增強分類器的泛化能力[16-17]。
該數據集中包含23 維特征,其中“CLASS”標簽列不考慮在內,將該標簽列去除,最終用于特征選擇的特征列為22 維。本文采用XGBoost 算法來選擇最優特征子集,XGBoost 算法訓練速度極快,可以計算每個特征的重要性,在特征篩選、模型可解釋性等方面都有顯著的優勢。
XGBoost 算法選擇最優特征子集的原理如下:在單個決策樹中通過每個屬性分裂點改進性能度量的量來計算屬性重要性,由節點負責加權和記錄次數,一個屬性對分裂點改進性能度量越大,權值越大,屬性越重要[18]。最后將屬性在所有提升樹中的結果進行加權求和并平均,得到重要性得分。本實驗中,由XGBoost 算法計算得到的每個特征的重要性得分如圖1 所示。
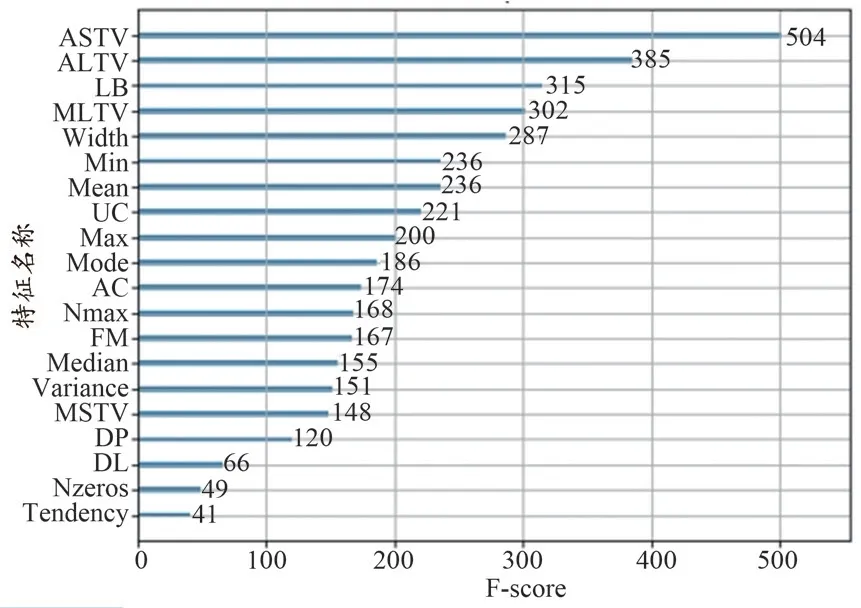
圖1 基于XGBoost算法的各個特征重要性得分
從特征重要性分析圖中可看出,ASTV 特征重要性最高,這與楊蔓麗等[7]的研究結果類似,考慮到短期變異的時間與短期變異的數值大小有相關性,因而將ASTV 與MSTV 這兩個特征相乘與相除得到兩個新特征,分別記為“ASTV_x_MSTV”與“ASTV_div_MSTV”。隨后運用HeatMap 對24 個特征進行相關性的分析,特征相關性高往往包含重疊信息,影響模型的解釋性和穩定性,因此我們需要刪除高度相關的特征。通過HeatMap 可以簡單地聚合大量數據,直觀地展現數據相關性程度或頻率高低,最終效果優于離散點的直接顯示,HeatMap 如圖2 所示,藍色代表相關性高,紅色則相反。
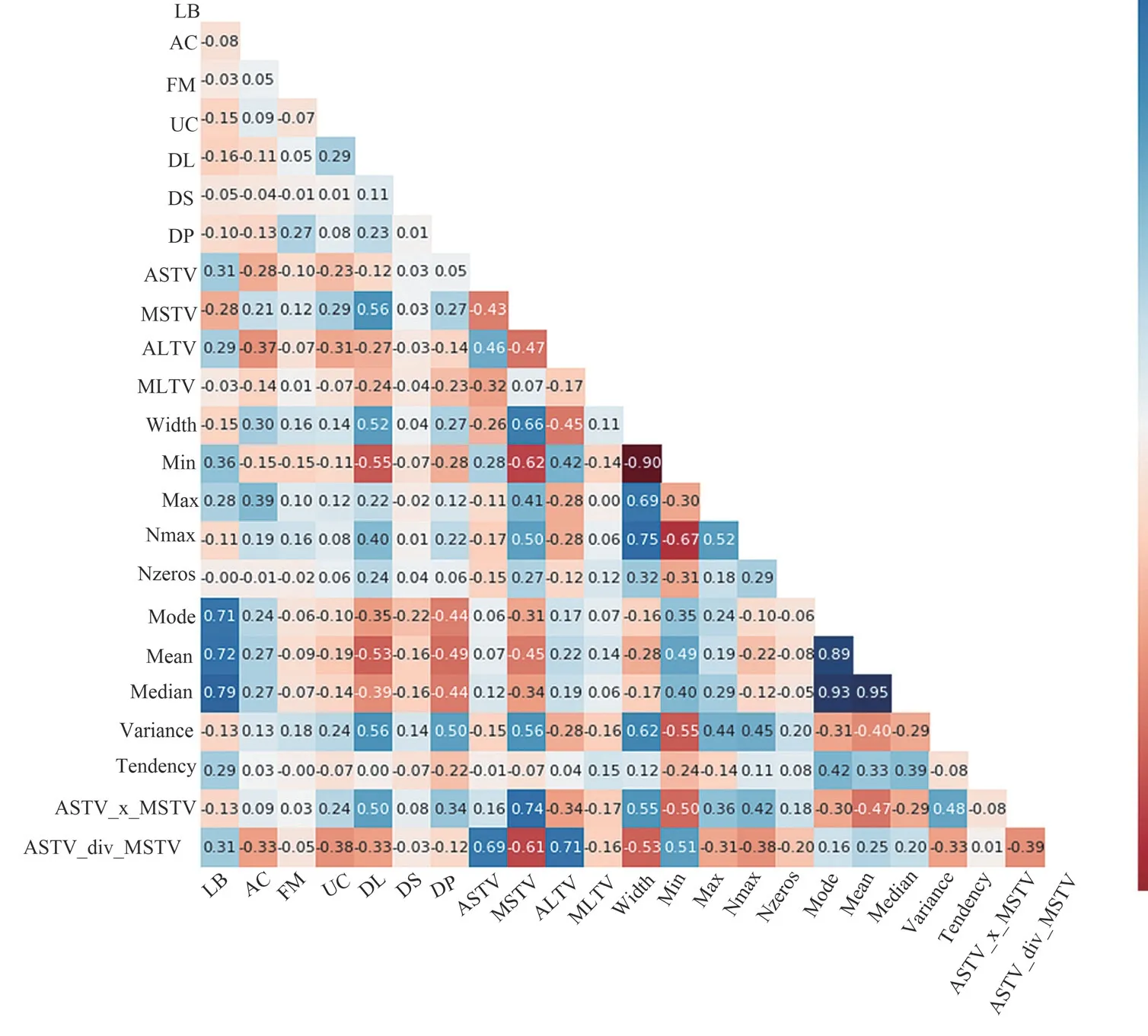
圖2 新特征子集的HeatMap圖
從HeatMap 圖 可 看 出,FHR 直方圖Mode、FHR 直方圖Median 與FHR 直方圖Mean 三者之間相關性極高,高達95%,則考慮在這三個特征中進行選擇,結合上文XGBoost 算法對特征重要性的排名,最終保留“Mean”特征集。通過特征工程這一步驟后,最終確定的特征子集共有22 維特征,包含構建的兩個新特征與剔除的兩個舊特征,特征選擇的效果在后文中得到評估。
1.5 模型構建
1.5.1 XGBoost分類器
XGBoost 分類器是數據挖掘和機器學習中最常用的算法之一,與傳統的梯度提升算法相比,XGBoost 集成算法更快,分類效果更準確,被認為是在分類和回歸上都擁有超高性能的先進評估器。
XGBoost 將回歸樹作為基分類器不斷生成新的回歸樹,每生成一棵樹即是在學習一個新的函數,去擬合上次預測的殘差,運用梯度下降的方法,將上一步生成的樹作為基礎,逐漸最小化目標函數。當預測樣本時,根據樣本特征,在每棵樹中尋找對應的葉子節點,每個葉子節點對應一個分數,最后只需將每棵樹對應的分數相加即得到該樣本的預測值[19]。
建樹過程如下:確定初始樹為f0(xi),那么建立第t棵樹時的預測模型如公式(6)所示。

其中,xi表示第i個樣本,fk表示第k棵樹,yi表示樣本xi的預測結果。
在建立模型過程中不斷優化目標損失函數,使其最小,見公式(7)。
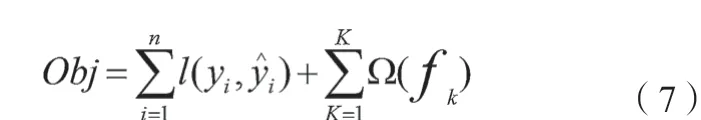
目標函數由兩部分構成,第一部分用來衡量預測分數和真實分數的差距,第二部分則是正則化項,正則化項表示每棵樹的復雜度[20]。XGBoost 通過將Objt使用二階泰勒公式展開得式(8)。
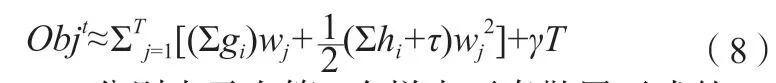
其中,gi、hi分別表示在第i 個樣本下泰勒展開式的一階導數、二階導數,通過公式(8)可得到關于wj的一元二次方程,因此能夠找到使Objt取值最小的wj。
通過以上步驟完成第t棵樹的建立[21]。
本研究基礎模型選擇樹形結構,模型調參采取GridSearch CV 方法,其中GridSearch 為網絡搜索,CV 為交叉驗證。網絡搜索為在指定的參數范圍內,依據其步長,不斷調整參數,從所有的參數中選擇出使測試集精度較高的參數,XGBoost 模型的幾個重要參數與解釋說明如表2 所示。
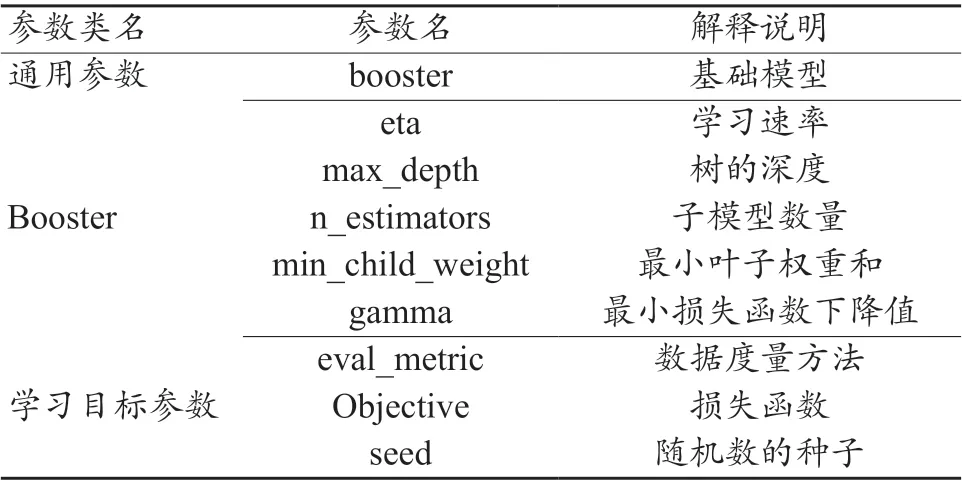
表2 XGBoost模型的幾個重要參數
1.5.2 Stacking模型融合
Stacking 是一種模型融合算法,又叫作模型堆疊,基本思路是先從初始的訓練集訓練出若干模型,然后將單模型的輸出結果作為樣本特征進行整合,并將原始樣本標記作為新數據樣本標記,生成新的訓練集[22]。再根據新訓練集訓練一個新的模型,最后用新的模型對樣本進行預測,其優點是降低單模型的泛化誤差。
本研究的設計步驟如下:
(1)首先將選擇的最優特征子集切分為5 份,每份包括662 例樣本數據。
(2)Stacking 的第一層模型可理解成一個超強的特征轉換層,第一層基模型選擇了5 個強模型,分別為:隨機森林(RandomForest,RF)、極端隨機樹(Extremely Randomized Trees,ET)、 梯 度 提 升 決 策 樹(Gradient Boosting Decision Tree,GBDT)、 自 適 應 增 強 決 策 樹(Adaptive Boosting,Adaboost)、XGBoost,這5 個樹模型均屬于強模型,均是在決策樹的基礎上進行優化與提升。將第一步切分好的5 部分數據分別作為這5 個模型的輸入進行訓練。
(3)第一層的5 個模型均運用六折交叉驗證的方法做訓練。六折交叉驗證的思想是:將數據劃分為6 部分,對其中的5 部分數據做訓練,每一份數據都會被作為一次驗證集,然后將得到的6 個結果取平均。通過第一層的訓練后,將5 個模型的5 個預測結果組成新的特征,作為第二層模型的輸入做訓練。第二層的基模型選用了一個簡單的Logistics 回歸分類器,可以避免過擬合現象的發生。具體的Stacking 模型融合步驟如圖3 所示。
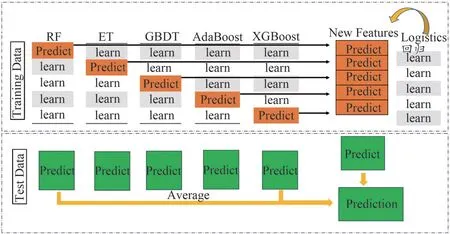
圖3 Stacking模型融合流程圖
2 實驗與分析
2.1 評估方法
采用混淆矩陣評估分類模型的性能。首先,對于測試數據的正負類別是已知的,要判斷的是通過模型預測出來的結果是否符合測試數據的真實結果。已知的測試數據分為正類和負類,預測出的結果分為陽性和陰性[23]。本文中,胎兒“正常”表示正類,胎兒“可疑”和“異常”表示負類,則真正類(True Positive,TP)為正常胎兒被正確分類為正常;假負類(False Negative,FN)為正常胎兒被錯誤分類為異常;假正類(False Positive,FP)為異常胎兒被錯誤分類為正常;真負類(True Negative,TN)為異常胎兒被正確分類為異常,TP、FP、FN、TN 分類矩陣如表3 所示。

表3 TP、FP、FN、TN分類方法
為能直觀反映分類性能,本文采用ACC、精確率(Precision)、召回率(Recall)以及F-score 值來衡量分類結果。ACC 是一個很好很直觀的評價指標,其計算公式如(9)所示。
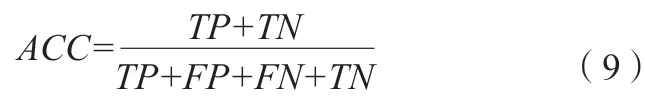
其 中,TP+TN表 示 分 類 正 確 的 樣 本 數,TP+FP+FN+TN表示所有的樣本數,ACC 為兩者的比值,ACC 越高,說明分類效果越好。
Precision 表示的是當前劃分為陽性的類別中,被分對的比例,其計算公式如(10)所示。

Recall 度量的是有多少個正例被分為正例,其計算公式如(11)所示。

F-score 值同時兼顧了分類模型的ACC 和Recall,它是分類模型ACC 和Recall 的一種加權平均,分數越高說明分類效果越好。
除此之外,本文還采用皮爾遜相關系數(Pearson Correlation Coefficient,PCCs)以及AUC 來衡量訓練模型的效果。PCCs 定義為兩個變量之間的協方差和標準差的商,它是一種統計指標,可以查看特征之間相關關系的密切程度。AUC 被定義為受試者特征曲線下與坐標軸圍成的面積,它的取值范圍通常為0.5~1,AUC 值越接近1 說明分類器的ACC 越高。
2.2 結果分析
本文的結果分析可分為兩部分。第一部分是運用XGBoost 算法與HeatMap 所選擇的最優特征子集的評估,運用這兩種方法確定出最終的22 個特征應用于模型的訓練。第二部分是模型分類結果的評估,將數據集劃分為訓練集和測試集,隨機選取1968 個數據作為訓練集,662 個數據作為測試集。
2.2.1 特征選擇
綜合XGBoost 算法和HeatMap 對特征的重要程度與相關性評估的結果,選出22 維特征作為最優特征子集進行模型的訓練。首先,通過XGBoost 算法進行模型訓練,運用GridSearch CV 方法選出XGBoost 算法的最優參數,最優參數如表4 所示。其中學習率為0.1,最大深度為9,模型數量為10。
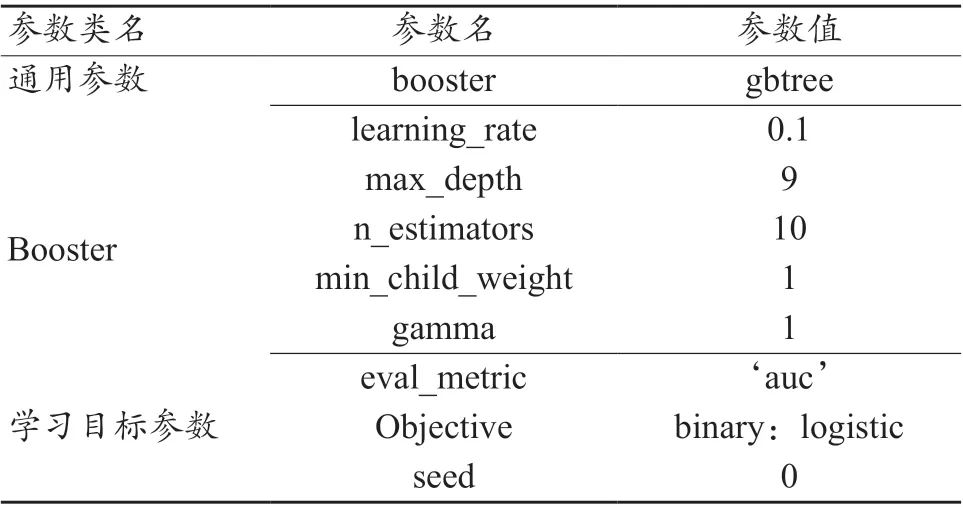
表4 XGBoost模型最優特征參數
隨后,運用PCCs 評估所得的預測結果與真實結果的差異性,結果表明,PCCs 由未選特征前的0.873 提高到0.885。
除此之外,運用ACC、Precision、Recall 以及F-score值所得評價結果如表5 所示。從表中可看出,運用最優特征子集所訓練的模型分類性能更好,ACC、Precision、Recall、F-score 值均有所提高。

表5 原特征與最優特征子集的結果比較
2.2.2分類結果
對原始特征集和最優特征子集使用Stacking 模型堆疊,在第一層基模型中,運用5 個強模型:RF、ET、GBDT、AdaBoost、XGBoost。每個模型運用六折交叉驗證進行訓練,將5 個模型的預測結果組成新的特征,作為第二層模型的特征輸入,第二層的基模型運用了簡單的Logistics 回歸模型。在第一層的模型訓練中,以AUC 為指標,對比了5 個基模型的得分情況,見表6。
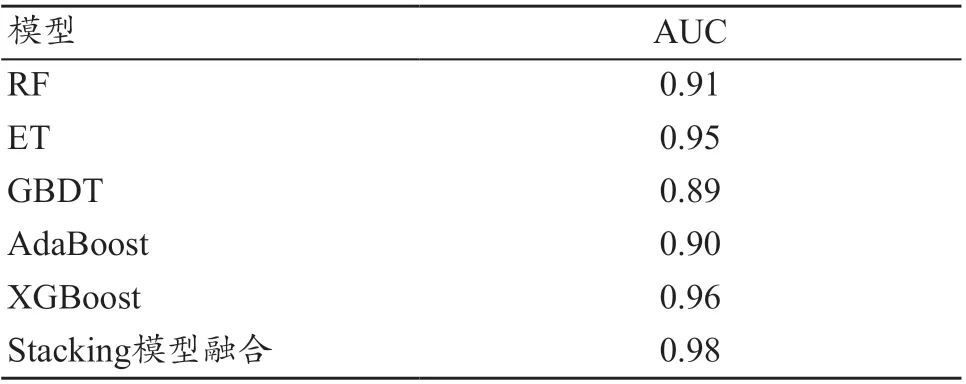
表6 五個基模型的AUC得分情況
從表6 中可看出,XGBoost 分類器相較于其他4 個機器學習單模型有較好的分類能力。采用ACC、Precision、Recall、F-score 值對第一層最強的基模型XGBoost、第二層Logistics 回歸模型以及第一層分別使用4 個和5 個基模型融合的分類結果進行比較,見表7。
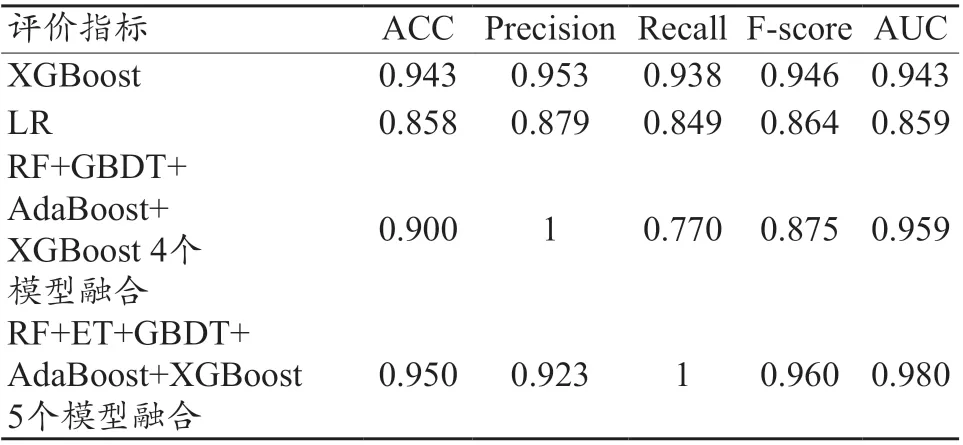
表7 ACC、Precision、Recall、F-score值評估結果
從表7 中可看出,RF+ET+GBDT+Adaboost+XGBoost 5 個模型融合的分類能力最優,ACC、Precision、Recall、F-score、AUC 分 別 達 到0.950、0.923、1、0.960、0.980,具有較好的分類性能。
除此之外,對第一層中最強的基模性XGBoost 與第二層基模性Logistics 回歸的性能采用混淆矩陣來評估,見圖4。結果顯示,在隨機選取的662 例測試集樣本中,運用XGBoost 模型,分類正確的有294 例(實際為正類,預測為正類)+330 例(實際為負類,預測為負類)=624 例,而運用Logistics 回歸模型分類結果不如XGBoost 模型,有269 例(實際為正類,預測為正類)+299 例(實際為負類,預測為負類)=568 例分類正確。
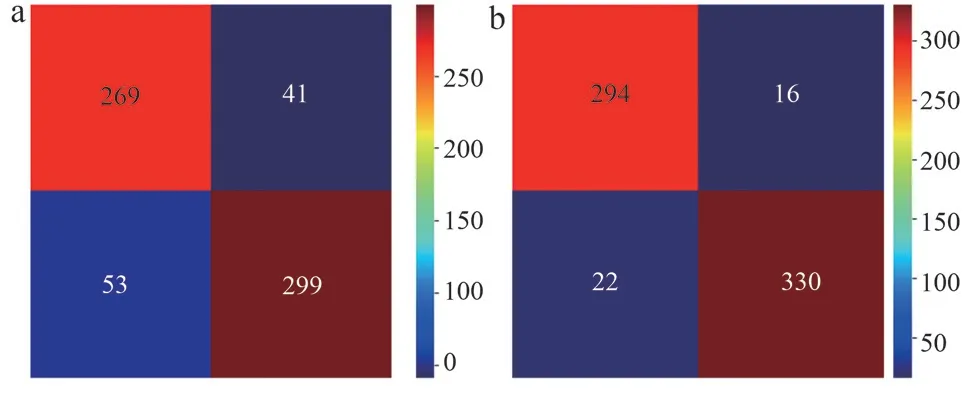
圖4 模型分類混淆矩陣
3 討論
本文提出一種基于公開數據集的胎兒宮內健康狀態智能評估新方法。針對正類和負類數據集不平衡問題,采用SMOTE 方法進行少數樣本集的填充。運用XGBoost 算法與HeatMap 對原始數據集分析,構建兩個新特征作為最佳特征子集用于模型的特征輸入,最后構建了一種兩層Stacking 模型融合的新方法用于胎兒分類。實驗結果表明,使用最佳特征子集的分類性能優于原始特征集,并且運用五層Stacking模型融合的方法達到性能最優,ACC 為0.950,Precision為0.923,Recall 為1,F-score 為0.960,AUC 為0.980。
此外,對比前人的研究工作,進一步證明了本文算法的性能。張揚等[15]對FHR 信號進行研究,提取出形態學、時域、頻域等多模態特征后,運用k-最近鄰遺傳算法選擇最優特征子集,最小二乘支持向量機法對其分類,ACC 為0.91,AUC 為0.92。Ocak[24]使用支持向量機和遺傳算法相結合的分類技術,使用回歸模型和粒子群優化方法來訓練,最后應用二叉決策樹進行數據分類,ACC 為91.6%,此方法中二叉樹算法很容易在訓練數據中生成復雜的樹結構,造成過擬合。本文中Stacking 模型融合第二層采用簡單的Logistics 回歸分類器,可以很好地避免過擬合問題,并且本文所提的算法準確度有所提升。
本文方法亦存在不足,今后在以下幾個方面還有待深入探究:
(1)臨床實踐的驗證。對于胎心信號圖的分析和解讀來說,最重要的是如何準確識別所有特征參數,因而,后期需在醫生的指導下,進行胎心信號的數據采集和參數提取,盡可能獲得本文所用數據集的所有參數,以便驗證本文所提出模型的性能。
(2) 提高算法精度。雖然該算法的ACC 有所提升,但對于要求更高的臨床診斷來說還有所欠缺。因此,后期將不斷改變算法結構,進一步提升分類性能。
(3)應用深度學習算法。應用深度學習算法對胎心監護圖研究,運用卷積降維,用低維的卷積核區代替高維的卷積核,并配置與優化網絡層數,減少運算量和參數量,設計出更加輕量級的網絡模型。
(4)構建完整的胎心監護輔助診斷系統。一個好的模型是輔助診斷的第一步,后續還需結合智能分類算法,將科研成果落地,將其部署到服務器軟件中,構建一個完整的胎心監護診斷系統。
4 結論
近年來,由于胎心監護圖中參數定義的不嚴謹性以及臨床醫師個體主觀認知的不同,對胎心圖像誤判導致剖宮產率不斷上升[25],利用智能分類算法可以輔助醫生對胎兒健康狀態做出診斷。本文提出的基于Stacking 模型融合的方法經過測試集的測試,最終的ACC 為0.950,AUC 為0.980,可作為醫護人員診斷胎兒健康狀態的參考依據。另外,XGBoost 等模型速度快、準確率高,可分布式部署,能集成到當前流行的Hadoop、Apache Storm 等數據處理框架之中,使得本方法可移植到服務器軟件平臺,實現診斷監護一體化。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
