基于LSTM的邊境頻譜占用度預(yù)測
2022-08-03 08:59:56蘆偉東羅士偉劉依卓
數(shù)字通信世界 2022年7期
關(guān)鍵詞:模型
蘆偉東,羅士偉,劉依卓
(國家無線電監(jiān)測中心哈爾濱監(jiān)測站,黑龍江 哈爾濱 150010)
0 引言
頻譜占用度是用來描述無線電頻譜資源利用率的重要指標(biāo),其也可以反映一個(gè)地區(qū)的頻譜利用率變化趨勢,邊境地區(qū)的無線電監(jiān)測的重要任務(wù)之一就是獲取準(zhǔn)確的頻譜占用度,為上級無線電主管部門制定頻率使用規(guī)劃和國際臺站申報(bào)計(jì)劃提供重要依據(jù)。傳統(tǒng)的分析方法不能通過頻譜占用度的歷史數(shù)據(jù)來預(yù)測頻譜未來一段時(shí)間的頻譜占用情況,難以滿足無線電管理需求。本文提出一種邊境頻譜占用度預(yù)測方法,通過實(shí)驗(yàn)優(yōu)化預(yù)測模型參數(shù)設(shè)置,使其能夠達(dá)到預(yù)測未來一段時(shí)間內(nèi)頻譜占用度的目標(biāo)。
1 時(shí)間序列
在不同時(shí)間對相同對象的持續(xù)觀察而得到的序列稱為時(shí)間序列[1]。通過對歷史數(shù)據(jù)進(jìn)行相關(guān)性分析,達(dá)到預(yù)測未來時(shí)間序列的目標(biāo)。頻譜占用度是通過不同時(shí)間段觀測頻譜占用情況而得到的數(shù)據(jù),因此其自然構(gòu)成了時(shí)間序列。頻譜占用度時(shí)間序列的平穩(wěn)性取決于具體數(shù)據(jù)的變化趨勢。
2 長短期記憶神經(jīng)網(wǎng)絡(luò)模型
長短期記憶(Long Short Term Memory,LSTM)神經(jīng)網(wǎng)絡(luò)通過門限機(jī)制留下輸入數(shù)據(jù)的有用信息[2],并控制其積累速度,相對于普通循環(huán)神經(jīng)網(wǎng)絡(luò),LSTM神經(jīng)網(wǎng)絡(luò)的隱藏層中除狀態(tài)h外,還引入了狀態(tài)c用于非線性信息的傳遞(如圖1所示),即

式中,U為網(wǎng)絡(luò)參數(shù);tanh(·)為激活函數(shù)。
隨著時(shí)間t的增加,ct的累積量將會變得越來越大,如圖2所示,這時(shí)LSTM的門限機(jī)制會主動(dòng)遺忘部分累積信息,避免出現(xiàn)信息量過大的問題。
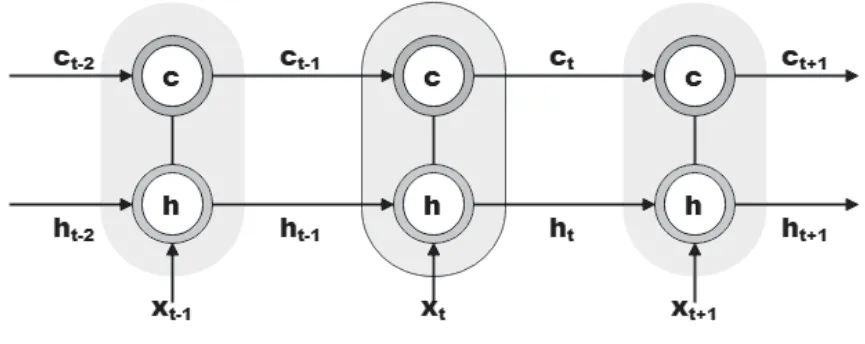
圖2 增加新狀態(tài)后的循環(huán)神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)
在t時(shí)刻有三個(gè)輸入量:xt,ct-1和ht-1,有兩個(gè)輸出量:ct和ht。LSMT的門限機(jī)制由輸入門、遺忘門和輸出門實(shí)現(xiàn)。
(1)輸入門的主要目的是通過下式確定輸入xt中部分信息留在ct中。
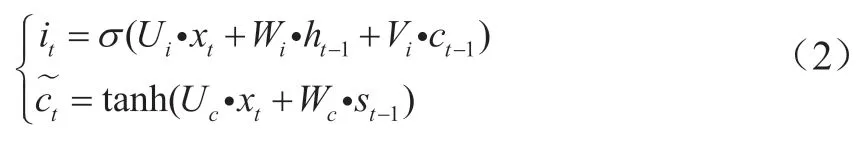
式中,i表示輸入;為激活函數(shù);U,V,W為網(wǎng)絡(luò)權(quán)重參數(shù);it為t時(shí)刻的輸入數(shù)據(jù),通過輸入門,將輸入中對應(yīng)的保留下來,即對應(yīng)向量中對應(yīng)元素的乘積。
(2)遺忘門的目的是確定t時(shí)刻輸入中的ct-1有多少成分保留在ct中,實(shí)現(xiàn)公式為
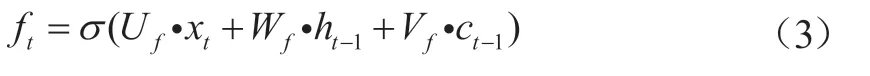
式中,f表示遺忘,此公式確定了遺忘門的門限,與輸入門的門限一樣,即通過遺忘門之后,將輸入中的保留下來。
(3)輸出門的目的是利用控制單元ct確定輸出ot中有多少成分輸出到隱含層ht中。
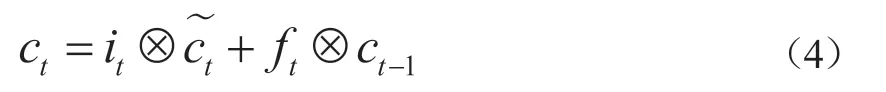
式(4)由兩部分組成,一部分為輸入門中存儲的信息,另一部分為遺忘門中的存儲的信息。下面給出留在ht中的信息實(shí)現(xiàn)公式:
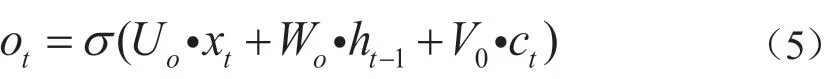
式中,輸出層狀態(tài)ot經(jīng)過輸出門,留在隱藏層中的信息實(shí)現(xiàn)公式為

綜上所述,隨著時(shí)間的變化,整個(gè)網(wǎng)絡(luò)的結(jié)構(gòu)設(shè)計(jì)流圖如圖2所示,目前LSTM神經(jīng)網(wǎng)絡(luò)已被成功應(yīng)用于數(shù)字識別、語音識別、圖像識別等領(lǐng)域。
3 基于LSTM的頻譜占用度預(yù)測模型
建立基于LSTM的頻譜占用度預(yù)測模型主要有5個(gè)步驟(如圖3所示):首先導(dǎo)入時(shí)序數(shù)據(jù),通過設(shè)定隱藏層和輸出層數(shù)量及激活函數(shù)來定義模型;然后編譯模型,為了使用模型能夠有效的進(jìn)行數(shù)值計(jì)算,設(shè)定整個(gè)模型的損失函數(shù)和優(yōu)化函數(shù);最后對模型進(jìn)行訓(xùn)練和評估預(yù)測效果。

圖3 建立LSMT預(yù)測模型流程
4 實(shí)驗(yàn)仿真
模擬2010年1月至2021年12月期間某邊境監(jiān)測站某頻段的頻譜占用度數(shù)據(jù),根據(jù)從實(shí)際邊境頻譜監(jiān)測工作中獲取的頻譜占用度數(shù)據(jù)特征,隨機(jī)生成144個(gè)月的頻譜占用度數(shù)據(jù)樣本,即生成時(shí)間序列數(shù)據(jù)。下面將根據(jù)建立LSMT預(yù)測模型流程進(jìn)行實(shí)驗(yàn)仿真。
4.1 實(shí)驗(yàn)步驟
4.1.1 導(dǎo)入時(shí)序數(shù)據(jù)
導(dǎo)入時(shí)序數(shù)據(jù)集(如圖4所示),可以看到頻譜占用度逐年增高的趨勢。對數(shù)據(jù)集進(jìn)行預(yù)處理,將單列數(shù)據(jù)集轉(zhuǎn)化為兩列數(shù)據(jù)集,第一列包含當(dāng)月(t)頻譜占用度,第二列包含下個(gè)月(t+1)的頻譜占用度。
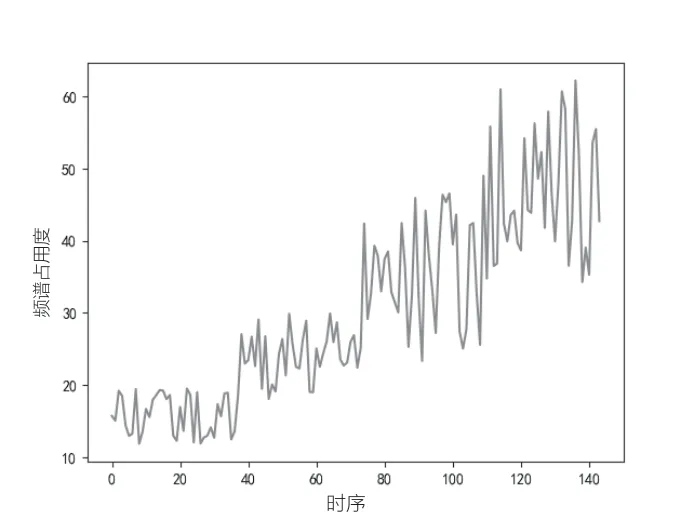
圖4 原時(shí)序數(shù)據(jù)集
4.1.2 定義模型
首先對數(shù)據(jù)集進(jìn)行歸一化處理,設(shè)定存儲單元和輸出層數(shù),選定sigmoid作為激活函數(shù),選取訓(xùn)練數(shù)據(jù)集,設(shè)定訓(xùn)練次數(shù)。
4.1.3 編譯模型
損失函數(shù)選取均方誤差,優(yōu)化函數(shù)選取自適應(yīng)矩估計(jì)。
4.1.4 訓(xùn)練和評估模型
用訓(xùn)練數(shù)據(jù)集對LSMT模型進(jìn)行訓(xùn)練,用均方根誤差(Root Mean Squared Error,RMSE)作為模型預(yù)測準(zhǔn)確度評價(jià)指標(biāo)。
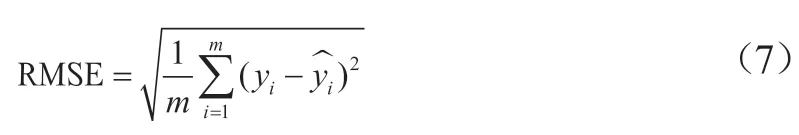
4.2 結(jié)果與分析
4.2.1 選取不同比例的訓(xùn)練數(shù)據(jù)
在144個(gè)數(shù)據(jù)樣本中,分別選取30%、60%和90%比例的數(shù)據(jù)作為訓(xùn)練數(shù)據(jù)集。用激活函數(shù)對數(shù)據(jù)進(jìn)行[0,1]區(qū)間的歸一化處理,設(shè)定隱藏層有4個(gè)存儲單元,訓(xùn)練次數(shù)為100,單個(gè)預(yù)測值輸出層,對比預(yù)測結(jié)果的評價(jià)指標(biāo)如表1所示。

表1 不同訓(xùn)練集比例的預(yù)測結(jié)果評價(jià)指標(biāo)
可以看出,當(dāng)選取訓(xùn)練數(shù)據(jù)集的比例由30%增加至60%,訓(xùn)練誤差增大,預(yù)測誤差減小;由60%增加至90%時(shí),訓(xùn)練和預(yù)測誤差都增大。這說明并非訓(xùn)練數(shù)據(jù)的比例越高越好,預(yù)測效果取決于樣本特征數(shù)量與網(wǎng)絡(luò)存儲能力的匹配程度。
選取60%的總樣本數(shù)據(jù)作為訓(xùn)練數(shù)據(jù)集,分別選取4,128,256個(gè)隱藏層存儲單元,其他實(shí)驗(yàn)條件不變,對比預(yù)測結(jié)果的評價(jià)指標(biāo)如表2所示。

表2 不同存儲單元個(gè)數(shù)的預(yù)測結(jié)果評價(jià)指標(biāo)
可以看出,在存儲單元個(gè)數(shù)從4個(gè)增加到128個(gè)時(shí),訓(xùn)練誤差略有增加,預(yù)測誤差降低,從128個(gè)增加到256個(gè)時(shí),預(yù)測誤差并沒有隨著存儲單元個(gè)數(shù)的增加而明顯降低,反而有所增加,這說明存儲單元個(gè)數(shù)達(dá)到128以后,LSTM網(wǎng)絡(luò)記憶了太多無效信息,因此無需再增加存儲單元的個(gè)數(shù)。
4.2.2 選取不同的訓(xùn)練次數(shù)
選取60%的數(shù)據(jù)樣本作為訓(xùn)練數(shù)據(jù),128個(gè)隱藏層存儲單元,分別采用50、100、300訓(xùn)練次數(shù),其他實(shí)驗(yàn)條件不變,對比預(yù)測結(jié)果如表3所示。

表3 不同訓(xùn)練次數(shù)的預(yù)測結(jié)果評價(jià)指標(biāo)
可以看出訓(xùn)練次數(shù)為100次時(shí),可以得到較低的預(yù)測誤差,說明網(wǎng)絡(luò)已經(jīng)比較穩(wěn)定,訓(xùn)練效果較好。
4.2.3 選取不同的窗口大小
對于時(shí)序預(yù)測問題,可以使用多個(gè)最近的時(shí)間項(xiàng)來進(jìn)行下一個(gè)時(shí)間項(xiàng)的預(yù)測,時(shí)間項(xiàng)的大小即為窗口大小。分別選取1個(gè)月和3個(gè)月的窗口大小對下一個(gè)月進(jìn)行預(yù)測,以總樣本60%的數(shù)據(jù)作為訓(xùn)練集,預(yù)測結(jié)果如表4所示。
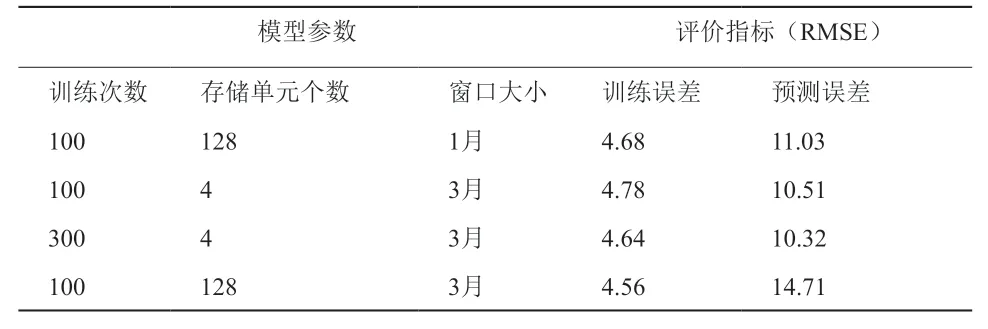
表4 不同訓(xùn)練次數(shù)的預(yù)測結(jié)果評價(jià)指標(biāo)
可以看出,當(dāng)窗口大小從1月增大為3月時(shí),訓(xùn)練次數(shù)和存儲單元的個(gè)數(shù)都會對預(yù)測誤差產(chǎn)生影響,這說明窗口的大小需要針對不同的問題進(jìn)行調(diào)整,不斷進(jìn)行調(diào)整參數(shù)的嘗試,才能得到較好的預(yù)測效果,如圖5所示。
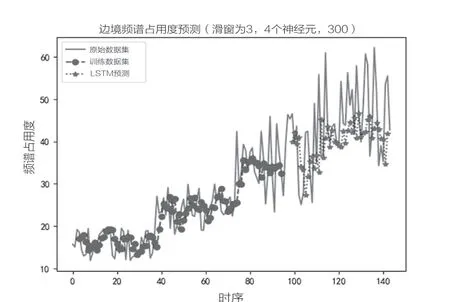
圖5 較好預(yù)測結(jié)果
4.2.4 分析
以上實(shí)驗(yàn)涵蓋了影響邊境頻譜占用度預(yù)測準(zhǔn)確度的主要因素,分別進(jìn)行了對比實(shí)驗(yàn),得到以下結(jié)論:對于此模擬邊境頻譜占用度數(shù)據(jù)集進(jìn)行基于LSMT的頻譜占用度預(yù)測,以總樣本數(shù)據(jù)的60%作為訓(xùn)練數(shù)據(jù)集,選取4個(gè)隱藏層存儲單元,網(wǎng)絡(luò)進(jìn)行300次訓(xùn)練,選取窗口大小為3個(gè)月,可以得到較為理想的預(yù)測結(jié)果。
5 結(jié)束語
對于邊境頻譜占用度的預(yù)測問題,本文提出了基于LSMT的邊境頻譜占用度預(yù)測方法,分析了影響預(yù)測誤差的主要因素,并得出結(jié)論,此預(yù)測方法在滿足一定的條件下,可以得到較為理想的頻譜占用度預(yù)測結(jié)果,為提升我國邊境地區(qū)頻譜競爭力和上級主管部門頻譜規(guī)劃的前瞻性提供了一種解決方案。■
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(bào)(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(bào)(2021年2期)2021-07-19 08:35:14
新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
