基于語義融合的域內相似性分組行人重識別
2022-08-04 02:14:38寇旗旗黃績程德強李云龍張劍英
通信學報 2022年7期
寇旗旗,黃績,程德強,李云龍,張劍英
(1.中國礦業大學計算機科學與技術學院,江蘇 徐州 221116;2.中國礦業大學信息與控制工程學院,江蘇 徐州 221116)
0 引言
行人重識別[1-2]任務的目標是在同一區域內的多個攝像機視角中識別并匹配具有相同身份的人,它在智能監控系統中發揮著重要作用。該任務可以分為有監督和無監督2 種情況,近年來,有監督重識別任務所取得的優異成果給學術界留下了深刻印象,但由于訓練數據集包含標簽,不僅標注成本巨大,而且在實際測試時不具備實時獲取目標域標簽的能力,導致監督行人重識別難以滿足實際應用的需求[3]。此時,無監督訓練的優勢便體現出來,利用有標簽的源域數據集訓練出具有較強泛化性的網絡,應用于無行人標簽的目標域,這類網絡稱為無監督跨域行人重識別網絡。
在網絡跨域訓練過程中,為了解決標簽問題,通常采用聚類的方式為行人分配偽標簽,節省了人工標注的成本。深度卷積神經網絡通過堆疊卷積層和池化層來學習判別特征,由于輸入行人圖片情況各異,如行人身體錯位和區域比例不一致等,導致識別的準確率受影響。其中,身體錯位一般有2 種情況:1) 人在行走時被相機抓拍導致姿態不同;2) 由于檢測不完善,導致同一行人在不同圖像中的身體部位出現區域比例不一致問題。在網絡對特征向量進行聚類時,上述問題產生的噪聲會直接影響聚類結果的準確性。
此外,在域自適應過程中不同數據域相機風格或背景風格等存在差異性,這種差異性對網絡的泛化能力是一種巨大的考驗。為了縮小這種差異,目前有2 種主流方法:1) 通過增強數據集或網絡重新生成數據集的方式,加大訓練樣本的數量來提高網絡識別性能[4-5];2) 基于生成對抗網絡(GAN,generative adversarial network)將圖像外觀從源域轉換到目標域,從而增加2 個域的相關性[6-7]。上述針對數據集操作的方法均是對源域和目標域之間相關性的考慮,目標域內訓練樣本中存在的相似性并未被進一步挖掘,且在網絡學習過程中增加了額外計算成本。
針對圖像身體錯位等因素導致聚類結果不準確的問題,本文提出一種簡潔高效的基于語義融合的域內相似性分組網絡。本文的主要貢獻如下。
1) 本文網絡在Baseline 網絡的基礎上創新性地添加了兩層語義融合層,實現對網絡中間特征圖的細化處理,增強卷積神經網絡提取特征的辨識度,其中,本文提出的語義融合層包含空間語義融合(SSF,spatial semantic fusion)和通道語義融合(CSF,channel semantic fusion)2 個模塊。
2) 在不增加額外計算成本的前提下,本文利用域內行人的細粒度相似性特征,將網絡的輸出特征圖水平分割為兩部分,通過聚類的方法根據全局和局部各自的域內相似性對行人進行分類,使同一行人被分配多個偽標簽,構成新的數據集。被分配相同偽標簽的不同行人圖片具有許多相似性,通過新的數據集對預訓練模型進行微調來迭代挖掘更精確的行人分類信息。
3) 與近年會議中提出的算法相比較,本文算法在DukeMTMC-ReID、Market1501和MSMT17這3 個公共數據集上的跨域識別率得到顯著提升,算法的直接效果通過熱圖以及檢索排序等方式進行展示。
1 相關工作
1.1 跨域行人重識別
最近,眾多學者密切關注跨域行人重識別算法,利用在源域中訓練的重識別模型以提高對未標記目標域行人的識別性能,跨域行人重識別也稱作無監督域自適應行人重識別,它解決了不同域間差異性的挑戰。但是,由于源域訓練的模型對目標域中特征變化很敏感,在使用預訓練模型適應目標域時必須考慮到圖像的變化,當前無監督域自適應行人重識別的解決方案可以分為三類:圖像風格遷移、中間特征對齊和基于聚類的方法[8]。
在圖像風格遷移方法中使用基于生成對抗網絡[9]是當下流行的方法。ECN(exemplar-cameraneighborhood)[10]利用遷移學習并使用示例記憶最小化目標不變性來學習不變特征;多視圖生成網絡CR-GAN(context rendering GAN)[6]著眼于背景風格,通過掩蓋目標域圖像中的行人以保留背景雜波,疊加源域中行人和目標域背景作為輸入圖像來訓練模型。但是,GAN的訓練過程復雜,而且會引入額外的計算成本,因此不適用于實際場景。
中間特征對齊方法旨在減少域間特征和圖像級別的差距,假設源域數據集和目標域數據集共享一個共同的中間特征空間,該共同中間特征可以用于跨域推斷人員身份。D-MMD 損失(dissimilaritybased maximum mean discrepancy loss)[11]通過使用小批量來關閉成對距離,實現特征對齊;基于補丁的無監督學習(PAUL,patch-based unsupervised learning)[12]框架假設如果兩幅圖像相似,那么圖像間存在相似的局部補丁;PAUL[12]并不學習圖像全局級別特征,而是為行人識別提供局部細節級別特征。
基于聚類的方法通常根據聚類結果生成硬偽標簽或軟偽標簽,然后根據帶有偽標簽的圖像訓練模型和交替迭代這2 個步驟使模型達到最優。深度軟多標簽參考學習模型MAR[13]根據特征相似性和分類概率之間的差異挖掘潛在的成對關系,然后使用對比損失加強挖掘的成對關系;UDAP(unsupervised domain adaptive person re-identification)[4]計算重排序的距離后對目標圖像進行聚類,然后根據聚類結果生成偽標簽;SAL(self-supervised agent learning)[14]算法通過利用一組代理作為橋梁來減少源域和目標域之間的差異。
上述3 種域自適應行人重識別方法在訓練時通過縮小源域和目標域之間的差距從而提高模型的泛化能力,然而忽略了目標域內同一行人自身存在一定的相似性。利用這一特性,本文對目標域行人特征進行上下分塊,聚焦于行人圖像上下部分的非顯著性特征,用聚類的方法將兩部分特征進行聚類,為行人共分配3 種偽標簽。
1.2 建模尺度變化
針對公共數據集內存在的圖像尺寸和人物比例不一致的問題,近年已有研究增強對尺寸和比例變化的特征表示能力。傳統方法一般采用尺寸不變的特征變換,如 SIFT(scale invariant feature transform)[15]和ORB(oriented FAST and rotated BRIEF)[16];對于卷積神經網絡,通過圖像對稱、尺度變換和旋轉等操作對數據進行轉換。然而,此類方法采用固定尺寸的卷積核進行操作,導致其對于未知的轉換任務存在局限性。此外,一些其他方法自適應地從數據域中學習空間轉換:STN(spatial transformer network)[17]通過全局參數變換來扭曲特征圖;DCN(deformable convolutional network)[18]用偏移量增加了卷積中的采樣位置,并通過端到端的反向傳播來學習偏移量。
上述方法均通過對網絡進行大數據量的訓練來得到圖像變換參數,這對于數據量有限的行人識別任務來說并不合適。本文提出的空間語義融合模塊計算空間語義相似度,對相同身體部位信息進行聚集,無須進行參數訓練。而且,在語義融合層中的通道語義融合模塊通過建模計算通道之間存在的相關性,顯著增強了特征的表示能力。
2 基本原理
參照現有的大多數跨域識別網絡在源域數據集上對模型進行預訓練的方式,本文利用在ImageNet[19]上預訓 練好的 ResNet50[20]作 為Baseline 網絡。如圖1 所示,在Baseline 網絡layer2和layer3后分別添加語義融合層(虛線框內2 個深灰色層)作為主干網,為中間特征圖融合更多語義信息。將原網絡最后的全連接(FC,fully connected)層替換為兩層維度分別為2 048和源域身份數的全連接層。將網絡輸出的特征圖F水平切分為上下兩塊Fup和Fdn,由此可以獲取更多的細粒度特征。分別對特征圖F、Fup和Fdn進行全局平均池化(GAP,global average pooling)操作得到特征向量。然后將不同行人圖像的特征向量分組并分配偽標簽。通過最小化每組偽標簽的三元組損失Ltri來迭代更新模型。
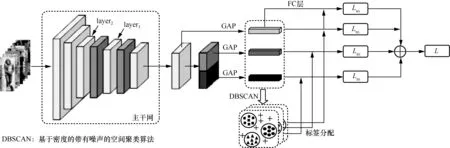
圖1 整體網絡結構
2.1 語義融合層
語義融合層依次對空間和通道信息進行融合。空間語義融合模塊根據輸入行人圖像的姿態和尺度自適應地確定感受野。給定來自卷積神經網絡的中間特征圖,利用相似特征和相鄰特征之間的高相關性特點,自適應地定位各種姿勢和不同比例的身體部位,以此來更新特征圖。將更新后的特征圖經過批量歸一化(CBN,batch normalization)層與原特征圖構成殘差結構,再將結果進行通道語義融合。通道語義融合模塊是通道之間的相關語義融合,實現小規模視覺線索的保留。圖2 為語義融合層的網絡結構,殘差結構可以使融合層保持良好的性能。
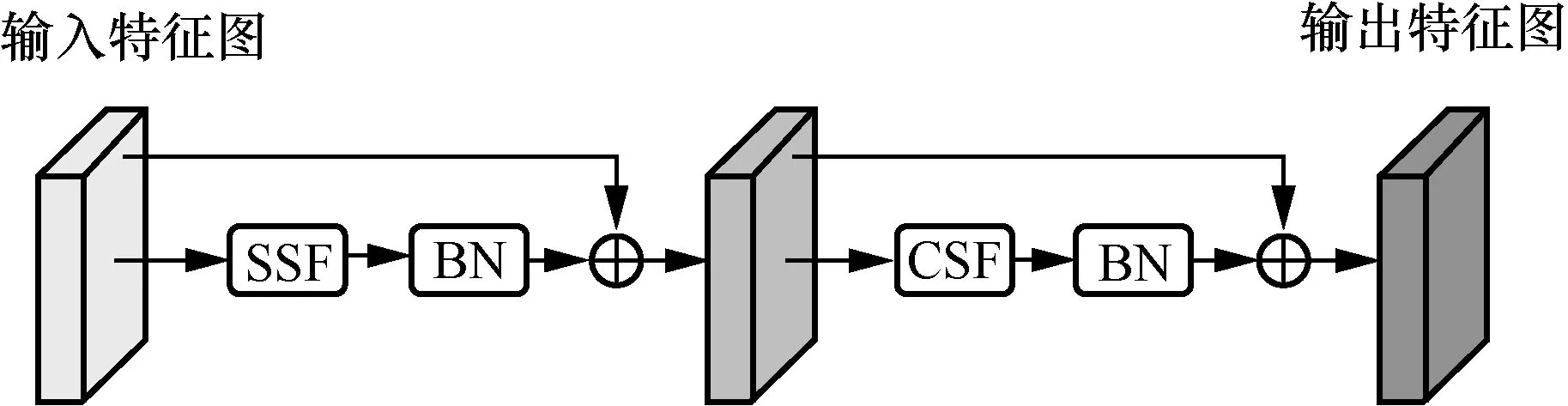
圖2 語義融合層的網絡結構
2.1.1 空間語義融合模塊
受限于卷積神經網絡的固定網絡結構,卷積層在固定位置對特征圖進行采樣,池化層以固定比例降低空間分辨率。由于特征圖感受野一般為矩形,導致感受野對行人不同姿態適應性較差。此外,固定大小的感受野對于不同尺寸的身體部位進行編碼是不合適的。為了解決這個問題,本文對中間特征圖進行空間語義融合,通過建模空間特征的相互依賴關系,自適應地確定每個特征的感受野,從而提高特征對身體姿勢和比例變化的穩健性。
空間語義融合模塊如圖3 所示。假設給定一個特征圖F∈RC×H×W,其中C、H和W分別表示通道數、特征圖高度和寬度。首先,將F重塑為F∈RC×M,其中M為空間特征的數量(M=H×W);然后,從特征圖的外觀關系和位置關系兩方面對空間特征進行依賴性建模,生成語義關系圖S;最后,融合特征圖F和語義關系圖S,生成新的融合特征圖。

圖3 空間語義融合模塊
對于外觀關系,通過測量輸入特征圖中任意兩位置之間的外觀相似性來生成外觀關系映射圖。Du等[21]提到在相鄰空間位置的局部特征具有重疊的感受野,所以它們之間有較高的相關性。因此涉及相鄰位置的感受野可以獲得更精細的外觀。假設fi,fj∈RC表示特征圖F中第i個和第j個空間位置的特征,分別選取i和j位置周圍大小為E×E的感受野,然后通過累加相應位置特征之間的點積,使用SoftMax 函數對F中的所有空間位置進行歸一化處理得到外觀相似性,計算式為
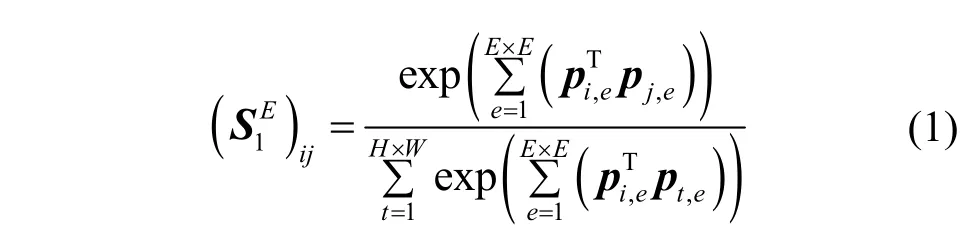
其中,pi,e和pj,e分別表示感受野大小為e的i和j位置上的特征,表示感受野大小為E對應的外觀關系圖。
根據式(2)融合不同尺寸E的感受野,得到對身體部位更穩健的關系圖。SoftMax 函數可以抑制不同部位較小的相似度,通過式(2)可以得到外觀關系圖S1。
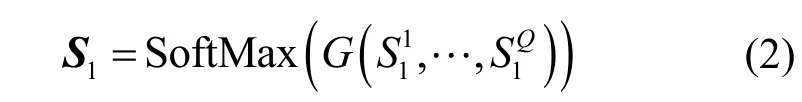
其中,G為具有元素乘積的融合函數,Q為不同尺度感受野的數量。
對于位置關系,行人圖像對應于相同的身體部位特征在空間上相近,通過二維高斯函數可以計算空間特征fi和fj之間的位置關系,即
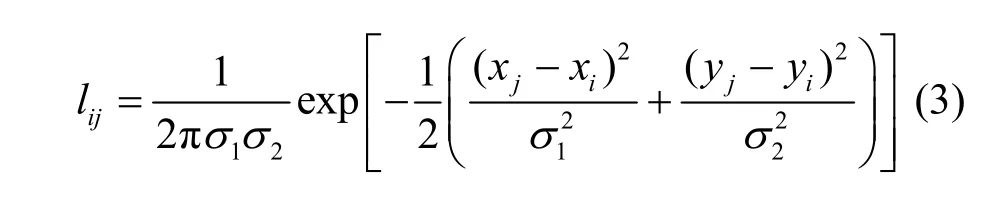
其中,(xi,yi)和(xj,yj)分別為fi和fj的位置坐標,(σ1,σ2)為二維高斯函數的標準差。通過式(4)規范化lij,使其關系值之和為1,記位置關系圖為S2。

最后,根據式(5)將外觀關系圖和位置關系圖進行融合,得到空間語義關系圖S。
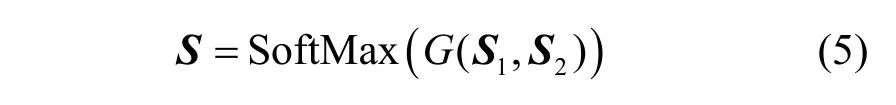
為了在原特征圖內融入空間特征,通過兩者相乘的方式得到融合特征圖Fs,計算式為
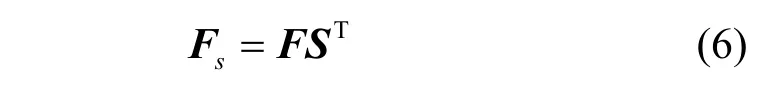
2.1.2 通道語義融合模塊
通常,卷積神經網絡經過下采樣處理后會丟失很多細節信息,然而這些細粒度信息對于行人的區分往往起到重要的作用,比如在困難樣本對中,通過利用衣服紋理或背包等細節信息,可以區分2 個不同的身份。根據Zhang 等[22]提到的大多數高級特征的通道圖對特定部分會表現出不同反應,融合不同通道中的相似特征,也可以增強行人獨有的特征。
通道語義融合模塊如圖4 所示。同空間語義融合一樣,重塑特征圖為F∈RC×M,將得到的F和自身轉置矩陣FT相乘,并將結果進行歸一化處理得到通道關系圖C∈RC×C,計算式為
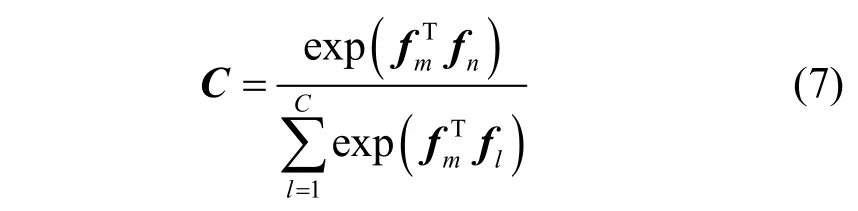
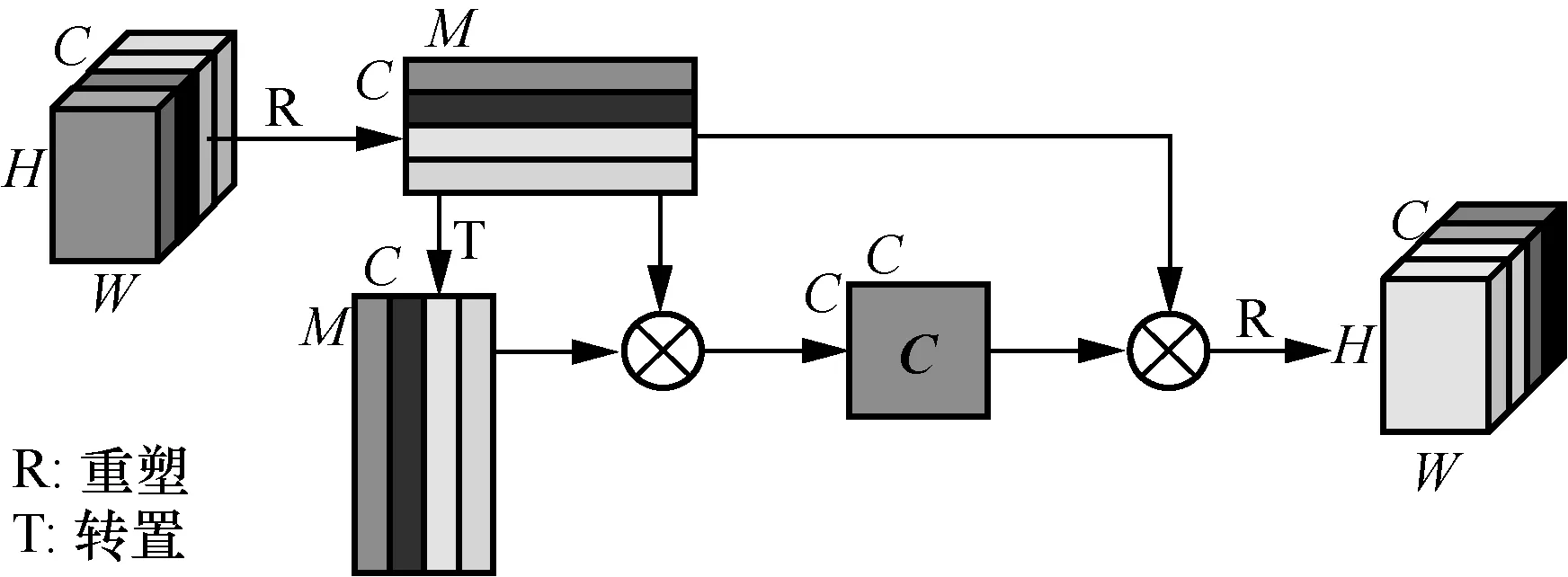
圖4 通道語義融合模塊
其中,fm和fn分別表示F的第m和第n通道中的特征。通過式(8)將通道關系圖和原特征圖進行融合得到新的融合特征圖Fc。

2.2 細粒度信息的密度聚類
受到Wang 等[23]提出的監督訓練分割方法的啟發,即從細粒度中可以提取出更多有用的信息。考慮到目標數據集中行人特征從全局到局部存在潛在的相似性,本文利用密度聚類方法[24]對全局和局部特征進行聚類,結合這兩部分信息能夠獲得更穩健和有辨識度的行人特征表示。網絡中語義融合層很大程度降低了可能因數據集產生的聚類噪音。

對于式(9)中的每組特征向量,利用密度聚類算法得到相應的偽標簽組,即每個身份根據它所屬的組分配一個偽標簽。經過主干網后,每張圖像xi對應3 個偽標簽,分別表示為因此,可以基于3 個特征向量分組結果組成一個有標簽的數據集X,如式(10)所示。此外,如圖1 所示,特征向量fi通過一個維度為2 048的全連接層,旨在獲取一個全局嵌入向量其偽標簽與特征向量fi共享。
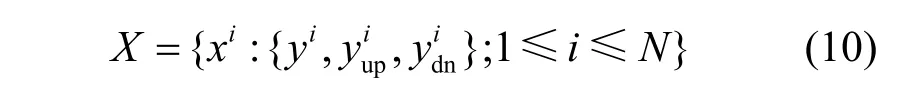
2.3 損失函數
為了學習到更具判別力的特征,本文在預訓練網絡損失函數上聯合使用難樣本挖掘的三元組損失和SoftMax 交叉熵損失。為每個小批量隨機采樣P個身份和K個實例,以滿足難樣本三元組損失的要求。三元組損失函數為

對于Baseline 網絡的訓練,利用SoftMax 交叉熵損失提高網絡判別學習能力,其計算式為
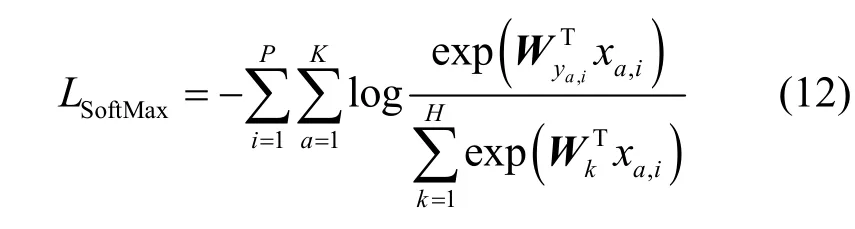
其中,ya,i為第i個身份的K張圖像中第a張圖像的真實標簽,H為身份的數量。通過式(13)將2 種損失函數進行組合,從而實現對預訓練網絡的更新。
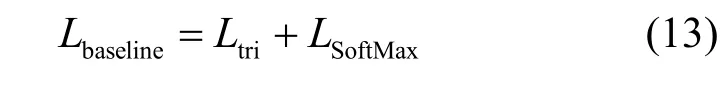
對于域遷移網絡的訓練,目標域圖片輸入網絡后,將聚類生成的偽標簽作為監督信息,使用三元組損失對預訓練模型進行跨域自適應微調。損失函數包含全局、上分塊、下分塊、全局嵌入4 個部分,計算式為

3 實驗及結果分析
3.1 實驗數據集
實驗主要在3 個行人數據集上對網絡進行評估,包括Market1501[25]、DukeMTMC-ReID[26]和MSMT17[27]。
Market1501[25]數據集圖像由6 臺相機捕捉,共包含身份1501 個,總圖像數量達到32 668 張。其中,訓練集身份有751 個,圖像有12 936 張;query 圖像共有3 368 張,身份有750 個;gallery 圖像共有15 913張;身份有751 個。
DukeMTMC-ReID[26]數據集是由8 臺相機捕捉的包含1 812 個不同行人的重識別公開數據集,其中有1 404 個身份同時出現在2 臺及以上的相機中,其余408 個身份用作干擾項。數據集包含訓練集圖像共有16 522 張,身份有702 個;query 圖像共有2 228 張,身份有702 個;gallery 圖像共有17 661 張,身份有1 110 個。
MSMT17[27]數據集是一個接近真實場景的大型數據集,由15 個相機捕捉圖像共有126 441 張,身份有4 101 個。其中訓練集圖像有30 248 張,身份有1 041 個;query 圖像有11 659 張,身份3 060 個;gallery 圖像共有82 161 張,身份有3 060 個。
3.2 實驗細節和評估指標
如第1 節所述,首先對Baseline 用源域數據集進行訓練,采用Zhong 等[32]使用的方法進行訓練。將輸入圖片的大小調整為256×128,采用隨機裁剪、翻轉和隨機擦除對數據進行增強;為滿足難樣本三元組損失的要求,將每個mini-batch 用隨機選擇的P=16個身份進行采樣,并從訓練集中為每個身份隨機采樣K=8張圖片,得到mini-batch 為128 張,將三元組損失的邊緣參數α設置為0.5。空間語義融合模塊中感受野的數量Q設置為3(如式(2))。由于ResNet[20]不同階段特征圖空間大小不同,因此本文采用不同的標準差(如式(3)),添加到layer2后的語義融合層σ1和σ2設置為10和20,添加到layer3后的語義融合層σ1和σ2設置為5和10。在訓練中使用權重衰減為0.000 5的Adam[33]優化器來優化70個epoch的參數。初始學習率設置為 6 × 10?5,在7個epoch 后將學習率調整為 1.8 × 10?5,再經過7 個epoch 學習率調整為 1.8 × 10?6,一直訓練到結束。
3.3 與先進算法的比較
在3 個公共數據集上,將本文算法與近年頂級會議文章所提出的算法進行比較。將行人重識別任務通用的累積匹配特性中的Rank 識別準確率(R-1、R-5、R-10)和均值平均精度(mAP,mean average precision)作為評價指標,評價模型在數據集上的性能。比較結果如表1和表2 所示,所有數據均不經過重排序處理。
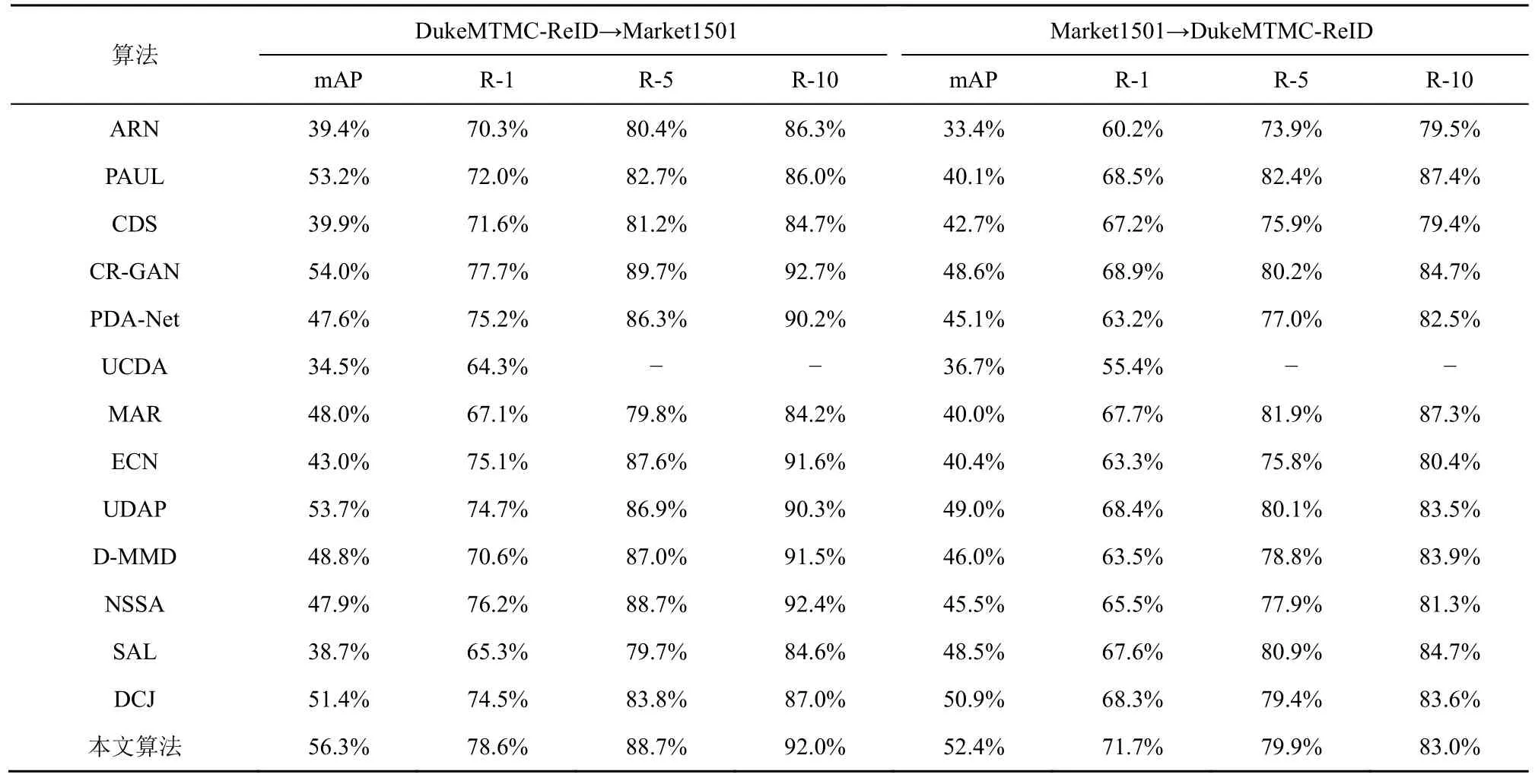
表1 不同算法在DukeMTMC-ReID和Market1501的實驗結果
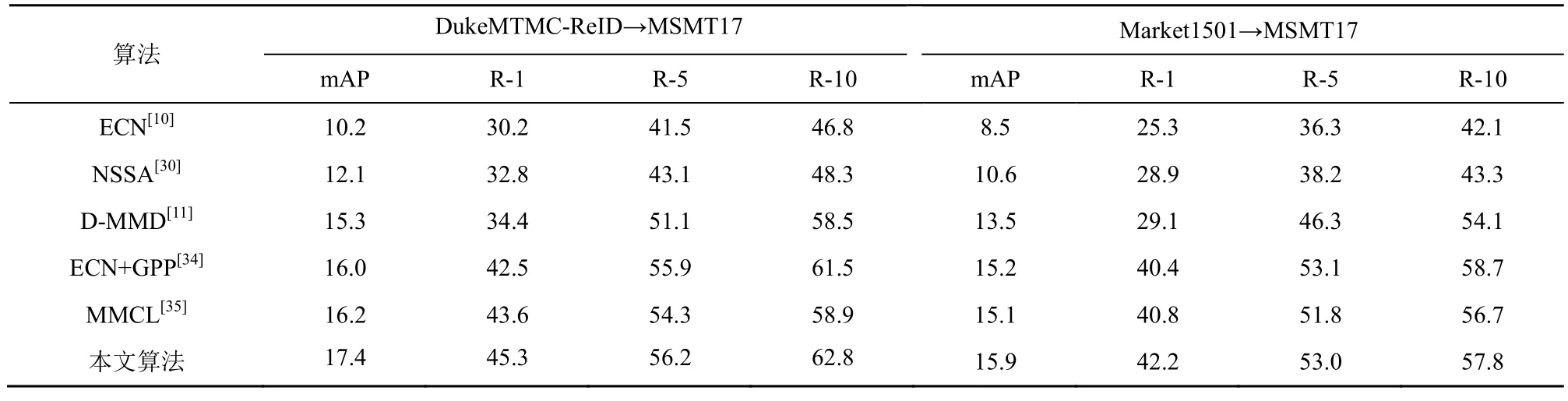
表2 不同算法在MSMT17的實驗結果
不同算法在MSMT17的實驗結果如表1 所示,包括8 種通過聚類形成偽標簽的算法UDAP[4]、MAR[13]、ECN[10]、CDS[29]、UCDA[5]、SAL[14]、DCJ[31]和NSSA[30];2 種通過域風格遷移的算法CR-GAN[6]和PDA-Net[7];3種特征對齊算法ARN[28]、D-MMD[11]和PAUL[12]。其中,CR-GAN[6]在DukeMTMC-ReID泛化到Market1501的mAP和R-1 表現最好,本文算法在網絡復雜度上遠低于CR-GAN[6],而且mAP提高2.3%,R-1 提高0.9%。在數據集Market1501泛化到DukeMTMC-ReID的結果中,本文算法表現更好,和上述算法中表現最好的DCJ[31]相比mAP 提高了1.5%,R-1 提高了3.4%。
表2為DukeMTMC-ReID和Market1501 分別泛化到MSMT17的實驗結果。MSMT17 數據集包含的身份更多且攝像頭視角更多,數據集包含較多存在身體錯位和遮擋等問題的圖片,更接近現實場景,難度較大。與表2 中性能最優的MMCL[35]算法相比,本文算法在DukeMTMC→MSMT17 上mAP提高 1.2%,R-1 提高 1.7%;在 Market1501→MSMT17 上mAP 提高0.8%,R-1 提高1.4%。
3.4 消融實驗
本節首先將模型在DukeMTMC-ReID 數據集上進行預訓練,然后在Market1501 數據集上進行消融研究,最后通過實驗分別驗證語義融合層中各部分和特征細粒度分塊的有效性。
在添加的語義融合層內,空間語義融合模塊中感受野尺寸E(如式(1))的選擇對識別準確率有較大影響。如表3 所示,不同尺寸E的感受野較Baseline 識別準確率均有所提高,但當E進一步增大到5 時,準確率開始下降。感受野的不斷增大會忽略一些關鍵身份信息。本文在式(2)中對不同感受野對應的關系圖進行融合時,選取感受野數量Q=3得到最優的實驗結果。
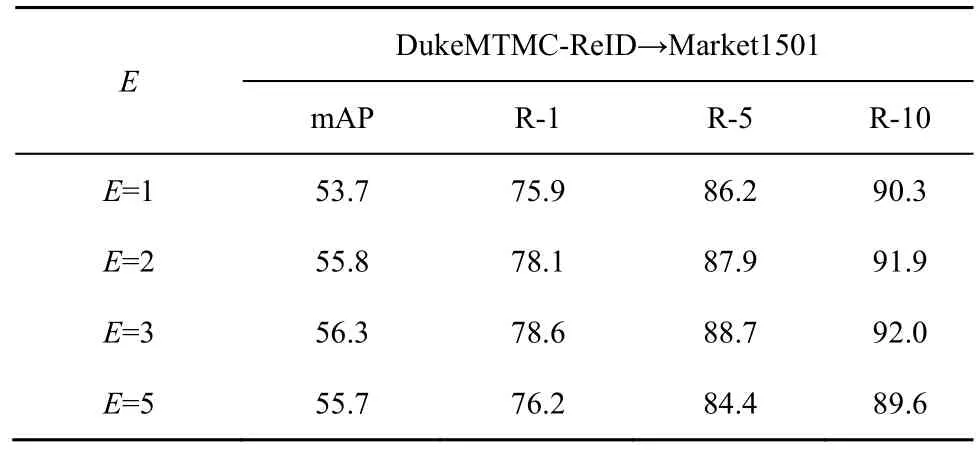
表3 不同感受野尺寸E的感受野對實驗結果的影響
對于融合函數G的選取,本文實驗將逐元素求最大值、累加以及相乘3 種函數作比較,實驗數據如表4 所示。在Q=3的情況下,融合函數對經過尺度分別為1、2、3的感受野所獲得的外觀相似圖進行融合,從表4 中可知,對應位置逐元素求最大值、累加和相乘的融合函數較Baseline 網絡的識別準確率均有所提升,其中逐元素相乘的融合函數對結果提升最為顯著。
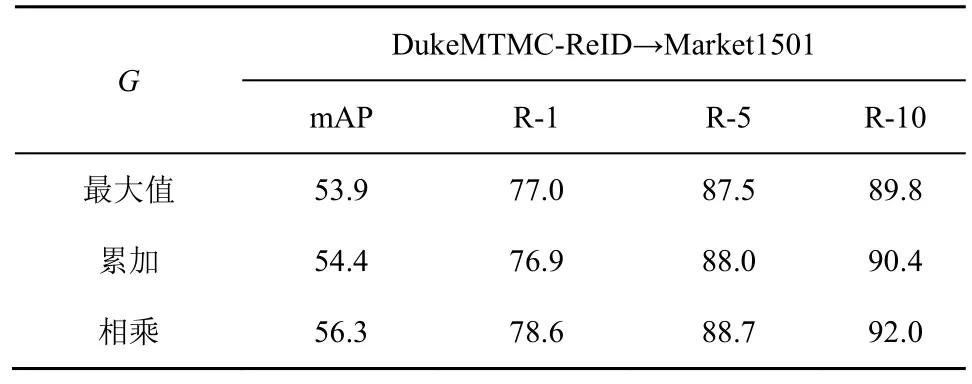
表4 融合函數G 對實驗結果的影響
對于網絡的整體結構,本節分別對語義融合層中空間語義融合和通道語義融合模塊進行消融實驗,實驗結果如表5 所示。通過分析,Baseline 網絡分別添加空間語義融合和通道語義融合模塊對識別準確率均有所提升。將二者按先空間后通道的方式串聯到一起,組合成語義融合層添加到Baseline 網絡中,對識別準確率的提升最大:mAP 提高4%,R-1 提高3.1%。由此可見,添加語義融合層可以獲取更多有效的行人特征信息,從而提高識別準確率。
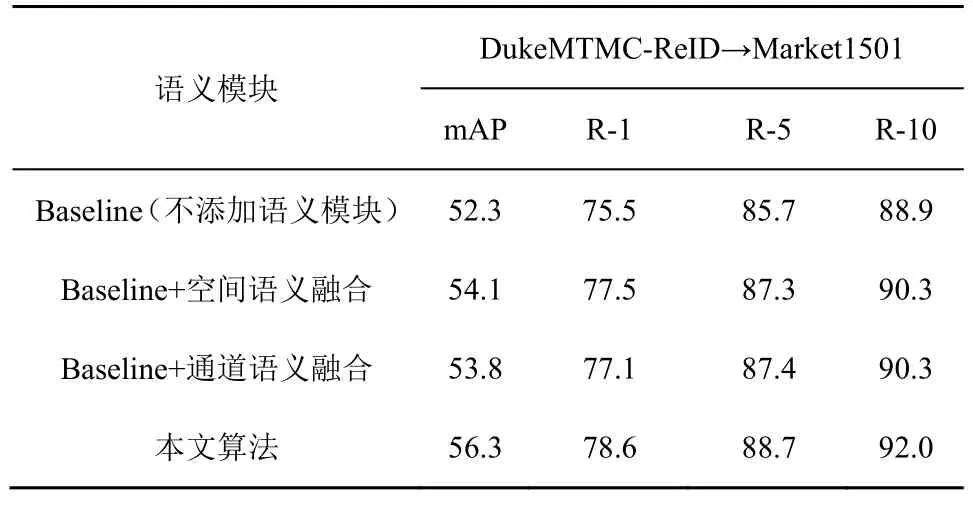
表5 不同語義模塊對實驗結果的影響
對于網絡輸出特征圖,本節在水平分塊的數目上進行了消融實驗。通過表6 可知,將網絡輸出特征圖分為上下兩部分能得到最佳識別準確率。通過分析可知,當不進行分塊時,特征圖丟失了有用的細粒度信息;當分塊較多時,由于數據集圖像內存在一些身體錯位和被遮擋的圖像,導致在經過密度聚類時會產生較多噪聲信息和較差的相似性挖掘以及匹配。因此,本文對網絡結構的設計時將分塊數確定為2。
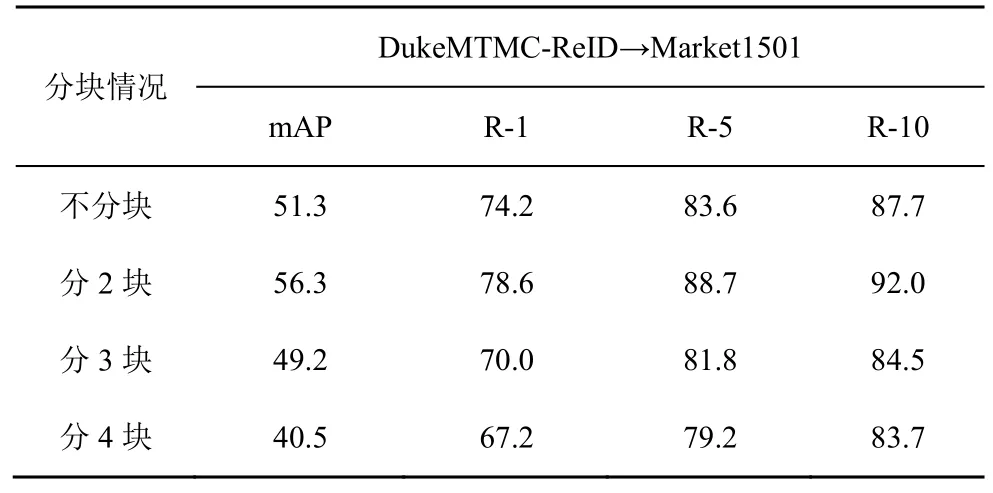
表6 不同分塊數對實驗結果的影響
3.5 可視化分析
為了更直觀地體現網絡在Baseline 上的改進,本節使用DukeMTMC-ReID 數據集進行預訓練,使用Market1501 數據集進行訓練和測試,使用熱圖[36]和檢索排序對實驗結果進行可視化分析。
熱圖共有4 組圖片,如圖5 所示。每組圖中,第一張圖像為Market1501 數據集行人圖片,第二張為經過Baseline 網絡的熱圖,第三張為經過本文網絡的熱圖。從圖5 中可以看出,Baseline 網絡由于固定感受野,所以只關注行人的局部信息,當圖像整體色調相近時(如圖5(a)所示),Baseline 網絡對行人的關注會被背景所干擾,本文方法將不同尺寸的感受野進行融合,實現了更關注行人主體的效果;當背景較為復雜時(如圖5(d)所示),Baseline網絡的關注完全偏離了人物,而本文的改進網絡表現依舊穩定。

圖5 熱圖
圖6 分別展示了Baseline 網絡和本文網絡在Market1501 數據集上識別實例的檢索排序結果。每張行人圖像上方的“√”和“×”分別表示查詢結果的正確與否。可以看到經過本文網絡的實驗結果在R-1、R-5 上的識別準確率都較高且穩定。其中,第二組行人的衣著相似難以辨認,Baseline 網絡在第二位置識別錯誤的行人圖像在本文網絡的識別結果排序中排第八位,且本文網絡未出現其他識別錯誤圖像。由此可見,在面對特征相似的行人圖像時,本文網絡依舊可以得到很好的識別效果。
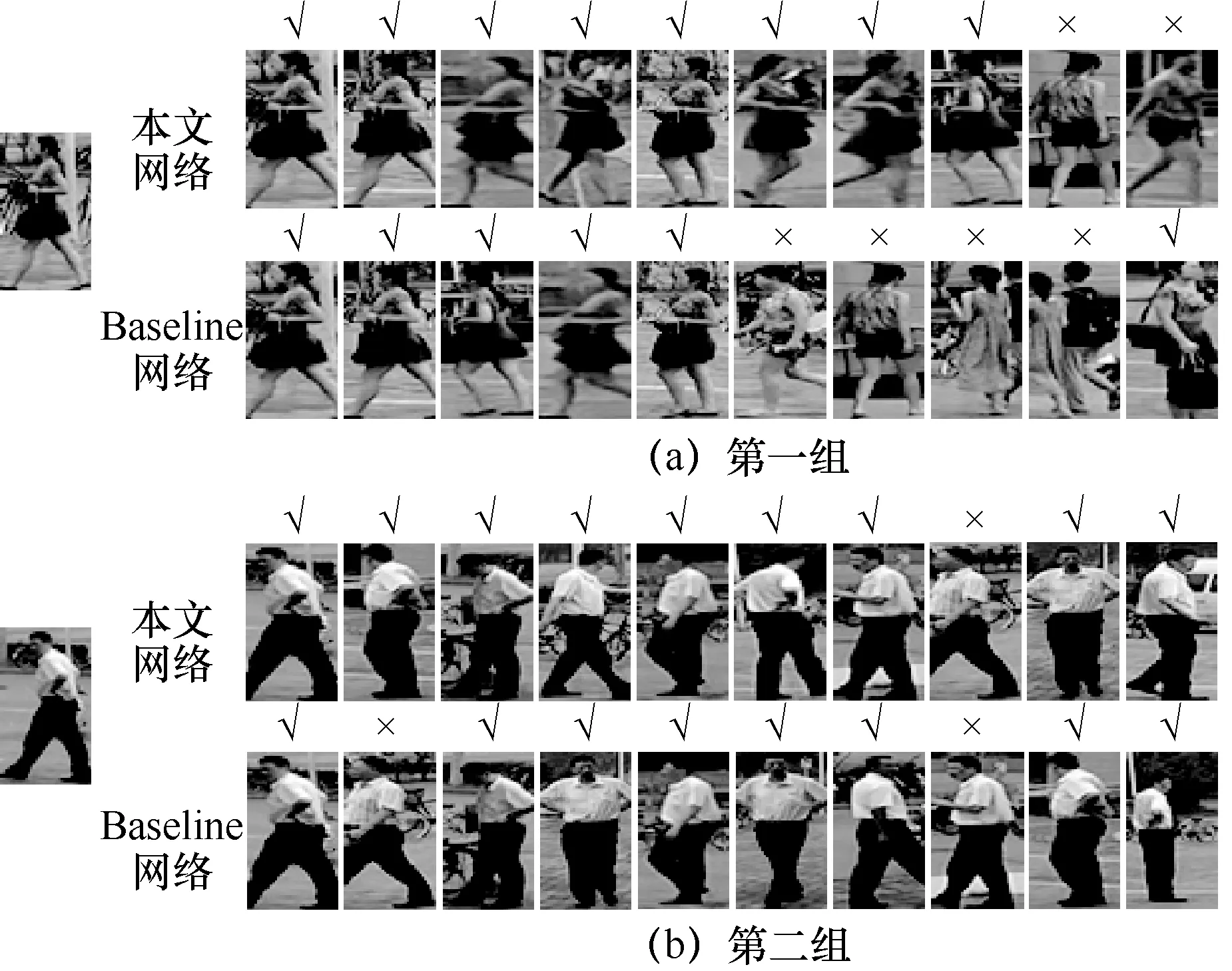
圖6 檢索排序結果
4 結束語
本文提出了一種基于語義融合的域內相似性分組網絡。語義融合層對于行人圖片自適應生成不同尺度的感受野,增強了空間特征之間的相互依賴關系,通過融合通道信息進一步提高了網絡的表示能力。實驗結果表明,相比于未添加語義融合層前的網絡,本文網絡的mAP 提高4.0%。此外,本文提出的網絡采用分塊的方式對目標域內細粒度相似性信息進行挖掘,得到更精確的行人分類信息。實驗數據表明,分塊聚類相比于未進行分塊處理的網絡mAP 提高5.0%。為了進一步增強網絡在現實環境中的泛化性,在后續的工作中本文將采用不同光照和塵霧環境的數據集對網絡進行訓練。對于行人被遮擋的情況,本文會為網絡添加行人遮擋模塊使網絡具備一定的抗遮擋能力。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
