一種基于改進SSD網絡的豬個體目標檢測方法研究
2022-08-05 02:41:10黃靜,張健
軟件工程 2022年8期
黃 靜,張 健
(浙江理工大學信息學院,浙江 杭州 310018)
syhj_sy@163.com;gxzj126@126.com
1 引言(Introduction)
隨著我國農業轉向高質量發展階段,畜牧養殖業也向著標準化、專精化、信息與智能化的發展方向轉變,出現了智能化養殖的新理念。畜禽的健康養殖要求養殖人員對其養殖的每一只畜禽要有及時和準確的了解,以實現智能化的管理。與此相關的自動化和智能化既是相關產業發展的迫切需求,也是相關科研人員研究的重點之一。生豬養殖業就是這種情況的典型代表,通過圖像進行豬個體的目標檢測,為后續實現豬養殖過程的精細化管理提供了技術支持。
對于豬個體目標檢測這樣的問題,近年來,深度學習技術應用于該領域的算法發展很快,各種優秀的網絡模型被提出來。基于神經網絡的目標檢測算法又可以分為兩種:Onestage目標檢測算法與Two-stage目標檢測算法。Onestage目標檢測算法事先預設候選框,因此其計算速度比較快,計算量相對較低,缺點是準確度相對較低。YOLO系列目標檢測算法是其代表,目前已經有YOLOv1、YOLOv2、YOLOv3、YOLOv4、YOLOv5。Two-stage目標檢測算法的過程則是在輸入后,第一步確定候選框,然后對這些候選框進行識別,以確定其類別。因此,這些算法得到的檢測結果往往比較精確,但是計算量較大,目標檢測的速度比較慢。其代表網絡算法則為RCNN系列,包括R-CNN、Fast R-CNN、Faster R-CNN及Mask R-CNN等。
目前,卷積神經網絡已經用于豬個體目標檢測問題。例如,PSOTA等和宋偉先都利用卷積神經網絡進行豬個體目標檢測;房俊龍等搭建了改進的CenterNet網絡;孫東來等搭建了改進的YOLOv3網絡等。
上述模型采集的數據圖像大多采集于大型養殖場,圖像質量較高,未能充分考慮復雜豬舍環境中光照較暗,豬易被遮擋導致的圖像區域面積較小、特征匱乏的問題。同時,實際豬個體目標檢測出現漏檢錯檢問題也大都與這兩個原因有關。
針對該問題,本文通過在原始SSD算法的基礎上引入FPN結構和CBAM注意力機制,并引入Focal Loss損失函數,在不顯著降低原始算法計算實時性的同時,提高算法的豬個體目標檢測精度和對豬遮擋及光線不足情況的適應性,更好地實現在實際豬舍環境下的豬個體目標檢測。
2 SSD算法模型(The model of SSD algorithm)
SSD算法是一種經典的目標檢測算法,也是目前目標檢測算法一種重要的檢測框架。原始的SSD算法性能相對平均,其與以精準度見長的Faster R-CNN算法相比檢測速度快,與以速度著稱的YOLO系列算法相比精準性更好。
2.1 SSD算法的網絡結構
SSD網絡的結構如圖1所示。
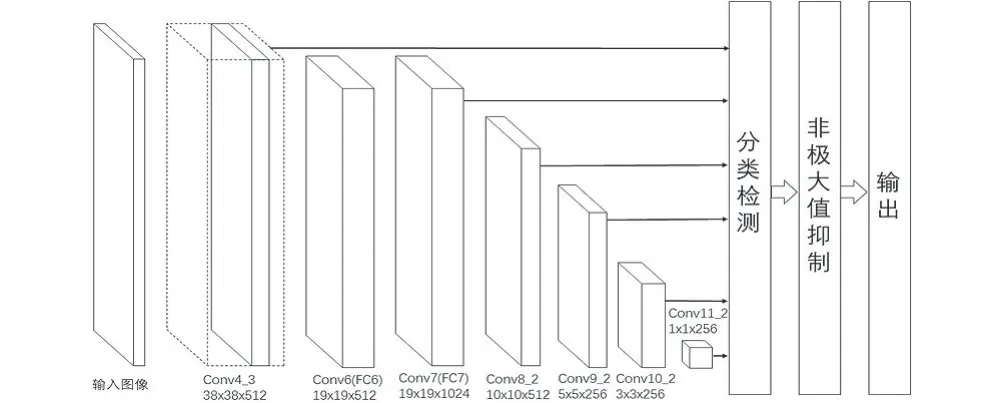
圖1 SSD網絡結構圖Fig.1 Diagram of SSD network structure
SSD的網絡模型使用VGG網絡作為主干網絡,與VGG16網絡一樣有16 層,包含五組卷積。其中,有兩組卷積都分別由兩個卷積層組成,剩下的三組卷積則分別由三個卷積層以及三個全連接層構成。但是和原始的VGG16網絡不同的是,起初為全連接層的FC6和FC7轉為卷積層,還一并擯棄了全部的Dropout層與FC8層。此外,在VGG16的特征提取層后又新增了Conv6、Conv7、Conv8、Conv9四個卷積層。
2.2 SSD算法的目標預測和分類過程
SSD算法使用六個卷積層對應的大小各異的特征圖作為預測部分的輸入,分別是第四卷積層中的最后一次卷積的特征圖、FC7中卷積的特征圖、第六和第七以及第八和第九卷積層中的中間的卷積對應的特征圖。SSD默認框從這六張特征圖中生成先驗框。先驗框由兩部分組成:先驗框中心位置信息和尺寸信息。先驗框中心能夠把特征圖劃分為許許多多尺寸固定的網格,其數量的多少與特征圖的大小成正相關,這就相當于將原始的輸入圖像根據特征圖的尺寸分別分割成網格。
SSD算法會在每個特征圖中生成四個或者六個先驗框,然后進入先驗框的微調和篩選過程。在一張特征圖中,SSD算法會先根據交并比選出和真實框重合度超過某個事先確定的閾值的先驗框,這些先驗框被稱為正樣本。而其他的先驗框則被稱為負樣本。在這種情況下,可能會產生正樣本的數量遠遠少于負樣本的問題。因此,SSD采用了和R-CNN網絡同樣的難例挖掘方法,也就是首先使用正樣本和負樣本的一個子集去訓練SSD網絡,然后立即用這個網絡模型進行預測并將那些被錯誤預測的負樣本(這些負樣本的正確的分類應該是正樣本)收集起來,形成難樣本集,最后再使用這個難樣本集去訓練網絡模型,如此反復。在整個過程中,保持正負樣本的數量比例接近1∶3。完成后,SSD算法使用非極大值抑制的方法進行先驗框的篩選,將不合適的先驗框去掉,留下的即為檢測結果。
2.3 SSD算法的損失函數
SSD算法的損失函數包含預測類別置信度損失和位置回歸損失兩部分。損失函數是通過這兩者的結合產生的,具體如式(1)所示:


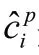
3 SSD算法的改進(Improvement of SSD algorithm)
由于豬圖像的光照條件差、豬個體被遮擋等造成檢測困難的直接原因是圖像中的目標區域較小,特征不夠明顯。為了解決這個問題,需要加強算法的特征提取能力,增強其對較小目標和困難目標的檢測能力。同時,通過改進損失函數,可以使網絡更加專注于這些難以檢測的目標,提高該類目標的檢測成功率。基于此,本文做了如下改進。
3.1 CBAM注意力機制
在算法中加入注意力機制可以使其無視無足輕重的特征信息,著重注意重要的特征信息,增強算法的表征能力,進而提高算法的目標檢測能力。
CBAM作為混合域注意力機制,將通道和空間這兩種因素結合在一起構建注意力模塊,使其更加全面,也更加高效。同時,作為一種輕量化模塊,加入CBAM模塊不會顯著增加卷積神經網絡的計算量,卻可以提高目標檢測的準確性。
CBAM模塊的流程是:首先在卷積神經網絡中選出特定的特征圖送入通道注意力模塊中,將通道注意力結果和初始的特征圖進行乘法操作;將所得到的中間結果送入空間注意力模塊中,然后將空間模塊的輸出結果與原來的中間結果相乘,即可得出最后的輸出結果。
3.2 特征金字塔結構
SSD目標檢測算法是一款經典的目標檢測算法,既擁有較快的計算速度,滿足大多數場景下實時性的需求,又可以擁有不錯的準確率,而且與Faster R-CNN相比,其訓練過程無須中間權重的存儲過程,降低了訓練成本。SSD網絡所采用的多特征圖檢測方式當時較為先進,但從當下看仍有較大的改進空間。
單從算法結構方面來說,SSD算法通過改進VGG16網絡,提取其中六個特征圖,分別對這些特征圖進行直接識別和分類,可能會出現多個特征圖識別到同一個語義信息的問題,造成重復和浪費。由于不同尺度的特征圖對不同目標的表征能力不同,而SSD算法又沒有當下已經應用很普遍的多特征融合,造成了其目標的檢測能力有較大進步空間。
特征金字塔網絡結構(FPN)是一種常常被用來解決目標多尺度檢測問題的重要手段,是多特征融合的主要結構之一。其在YOLOv3以來的YOLO系列算法中與PAN結構相結合的應用已經十分成熟。
FPN結構只需在已經成熟的網絡模型基礎上更改網絡層之間連接的方式,在盡量降低對算法計算量和實時性的影響的情況下,有效提高網絡模型對小目標的檢測能力。
特征金字塔結構將深層特征圖(包含豐富的語義特征信息)和淺層特征圖(包含豐富的紋理信息)通過三種連接方式(自上而下、自下而上和橫向連接)進行相互結合,使得各不同尺度特征圖都擁有豐富的特征信息,然后再在這些不同層級的特征圖上進行檢測。
將特征金字塔、CBAM模塊和原始的SSD算法進行有機結合,得到改進的SSD算法,其網絡結構如圖2所示。
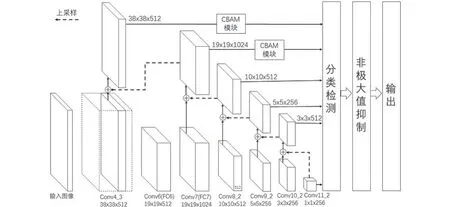
圖2 改進后的SSD網絡結構圖Fig.2 Diagram of improved SSD network structure
3.3 Focal Loss損失函數
對于因為光線條件較差,豬被遮擋導致的難以識別的豬個體,其檢測網絡模型應該進行重點關注。同時,豬個體目標檢測問題只需分辨豬個體和背景這兩種類別,目標數量較少,這樣就會造成正負樣本的數量不平衡。雖然SSD算法事先設定了正負樣本的比例,避免被過多的負樣本在訓練時浪費掉模型分辨樣本的能力,但還需要進一步改進。
為此,引入Focal Loss損失函數。該損失函數可以有針對性地解決這個問題。
Focal Loss損失函數如式(10)所示:
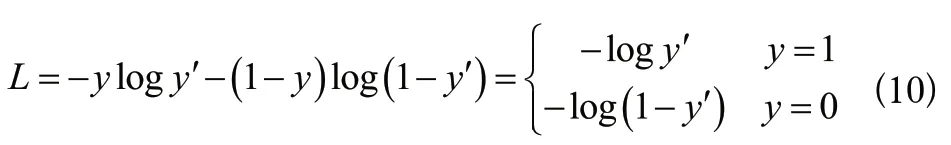
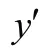
初步改進后的Focal Loss損失函數如式(11)所示:
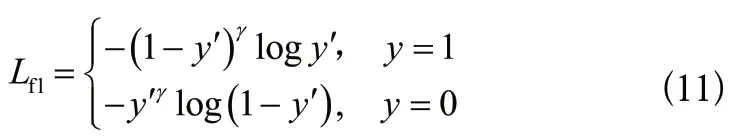
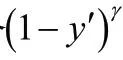
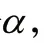
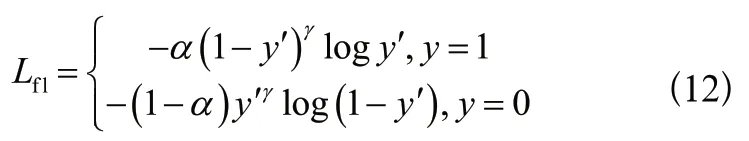
這樣就既能夠解決正負樣本數量不平衡問題,也能夠使得模型更加注重難分類的樣本。在本次實驗中,這些樣本就是因為光照、遮擋等問題造成的難以檢測到的樣本。
將Focal Loss損失函數置換原本的預測類別置信度損失函數,得到的改進SSD網絡結構的損失函數如式(13)所示:
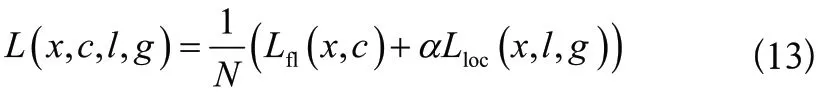
4 實驗分析(Experimental analysis)
4.1 數據集制作
本次實驗通過網絡爬蟲程序獲得網絡上公開的豬目標圖片,以及從互聯網公開視頻和自己實地拍攝的視頻中截取的豬目標圖片共5,122 張,其中特別加入含有豬被遮擋、光照條件差的圖片約1,000 張組成實驗數據集。每張圖片至少包含一個目標,可能包含多個目標。整個數據集按照Pascal VOC 2007數據集格式制作,在統一將圖片尺寸縮放為416×416后,利用Imglabel軟件對圖片中的目標進行標注,并將結果保存為XML文件。標注完成后,隨機按8∶1∶1將其劃分成訓練集、驗證集和測試集。
4.2 實驗平臺條件
本次實驗的軟硬件條件及其相關配置如表1所示。
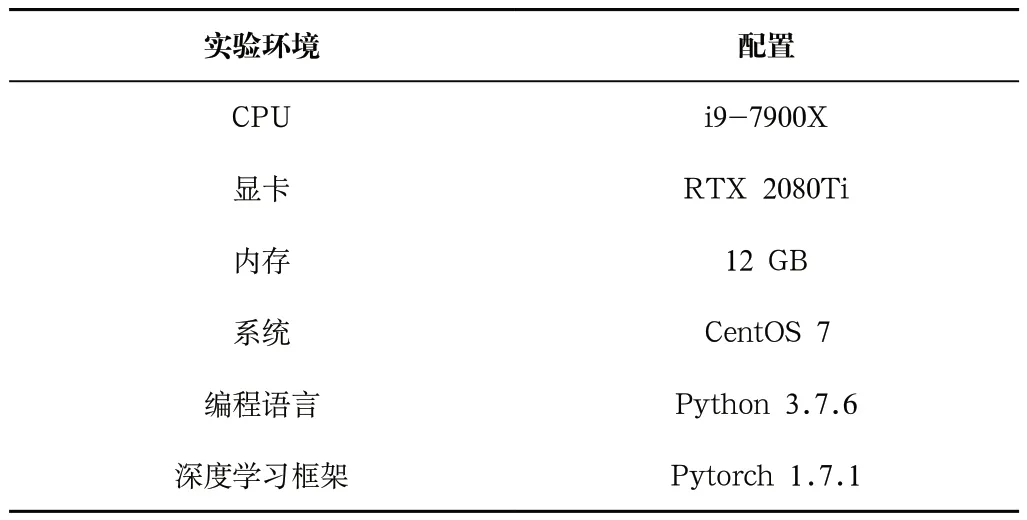
表1 實驗環境及配置Tab.1 Experimental environment and configuration
4.3 評價指標
結合本次實驗的實際情況,決定采用平均精度指標作為評價標準,其是精確率關于召回率的積分。兩者分別如式(14)和式(15)所示:
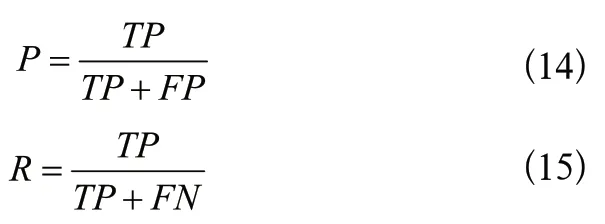
其中,表示正樣本被正確檢測的個數;表示正樣本被錯誤檢測成負樣本的個數;表示負樣本被錯誤檢測成正樣本的個數。精確率表示的是正確分類的樣本占所有樣本的比重;召回率則表示的是檢測正確的正樣本占所有正樣本的比重。
另外三個評價指標為檢測速度、誤檢率、漏檢率。檢測速度指其在數據集或者視頻流中每一秒檢測的圖像張數或者幀數。誤檢率為將不是目標的圖像檢測為目標的數目占總應檢出目標數目的比值。漏檢率為本應是目標的圖像檢測為不是目標的數目占總應檢出目標數目的比值。
4.4 實驗結果分析
分別對原始SSD算法和改進后的SSD算法進行訓練,待兩者的損失函數收斂后完成訓練。分別使用測試集對這兩個已經訓練好的模型進行對比驗證,得到的結果如表2所示。
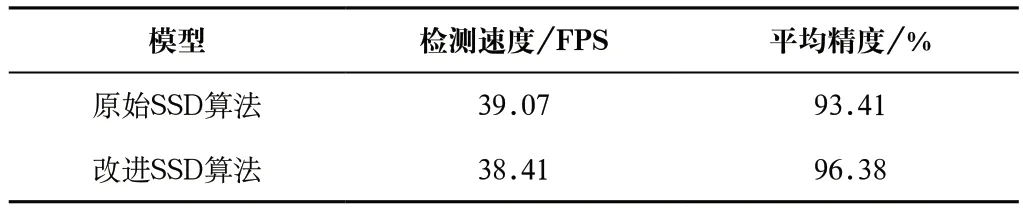
表2 SSD網絡模型改進前后性能指標對比表Tab.2 Comparison table of performance indicators before and after the improvement of SSD network model
為了驗證改進后的SSD算法模型的實際效果,取存在光照較差、豬被遮擋情況的豬舍視頻進行視頻檢測。檢測過程中,檢測平均速度為21.6 FPS,典型檢測結果截圖如圖3所示。

圖3 視頻檢測結果圖Fig.3 Diagram of video detection results
為了定量對改進后的SSD算法模型的檢測效果進行分析,將兩種算法模型對上述視頻的檢測結果隨機進行截取,獲得約800 張圖像。隨機選取其中292 張含有豬目標的圖像進行計數,計算出兩種算法對該視頻的誤檢率和漏檢率結果,如表3所示。
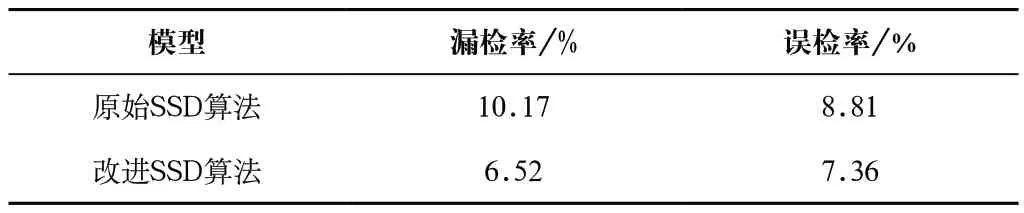
表3 SSD網絡模型改進前后實際視頻檢測結果對比表Tab.3 Comparison table of actual video detection results before and after the improvement of SSD network model
從表2和表3可以看出,改進的SSD算法有96.38%的平均精度,相較于原始SSD算法,其FPS指標降低了1.7%,但平均精度卻提高了2.97%。平均精度的提高得益于改進的SSD算法通過FPN結構與CBAM機制的聯合應用,提高了網絡對豬個體目標的特征提取能力。同時,漏檢率降低了3.65%,誤檢率降低了1.45%,兩者的降低不僅與上述網絡結構的改進有關,改進的損失函數使網絡模型更加關注這類目標也起了一定作用。整體改進后雖然算法的實時性略有降低,但在進行視頻檢測時仍能有21.6 FPS,基本可以滿足可能的視頻實時監測需求。同時,從圖3中可以發現,對于左側光線較暗且豬個體存在一定的相互遮擋的情況,以及右側豬大部分被遮擋的情況,改進后的SSD算法均可以對其進行有效識別,但部分豬目標的檢測框與實際個體之間的空隙稍大。綜上說明,改進后的SSD算法對于光線較暗和豬遮擋情況均有良好的適應性,對因此造成的豬目標難以檢測問題有一定的改善。
5 結論(Conclusion)
本文基于SSD目標檢測算法,對豬個體目標檢測問題進行探究。首先,通過廣泛收集數據,構建了較為全面的數據集,同時對訓練集、驗證集和測試集進行了劃分。然后,為了提高原始算法對豬個體目標的檢測能力,使用FPN結構和CBAM模塊對網絡進行改進,使用Focal Loss損失函數對原有損失函數進行改進。在對改進后的網絡完成訓練后,使用測試集數據和豬舍視頻進行了測試,最終的實驗結果表明,相較于原算法,改進后的SSD網絡模型在豬個體目標檢測問題上有96.38%的平均精度,檢測平均速度為21.6 FPS,并對光線變化和目標遮擋情況有更好的適應性。但同時也發現,部分檢測框與實際個體之間的空隙稍大,需要進一步探究和改進。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
