面向Flink的負載均衡任務調度算法的研究與實現*
2022-08-11 08:41:02李文佳季航旭羅意彭
計算機工程與科學 2022年7期
李文佳,史 嵐,季航旭,羅意彭
(1.東北大學計算機科學與工程學院,遼寧 沈陽 110169;2.遼寧工業大學軟件學院,遼寧 錦州 121000)
1 引言
近年來,隨著數據經濟在全球的加速推進,以及5G、人工智能、物聯網等相關技術的快速發展,全球數據量迎來巨大規模的爆發,越來越多的政府機構和研究人員開始重視這種大量數據的收集、使用與處理。伴隨著數據的爆炸式增長與多種多樣需求的出現,一些傳統的大數據模型和分布式計算引擎已經很難滿足當前業務的需求,因此,許多新的分布式計算框架應運而生。大數據計算引擎的發展歷程主要分為4個階段。第一代大數據計算引擎是谷歌于2004年提出的基于MapReduce[1]的Hadoop[2]計算引擎。Hadoop主要依靠把任務拆分成map和reduce 2個階段去處理,這種模式由于難以支持迭代計算,因此產生了第二代基于有向無環圖DAG(Directed Acyclic Graph)[3]的以Tez[4]和Oozie為代表的計算引擎。雖然第二代計算引擎解決了MapReduce中不支持迭代計算的問題,但是由于這種計算引擎只能處理離線任務,在線任務處理需求增加的驅動下,產生了第三代基于彈性分布式數據集RDD(Resilient Distributed Dataset)[5]的Spark[6]計算引擎。Spark既可以處理離線計算也可以處理實時計算,它是在Tez的基礎上對Job作了更細粒度的拆分,但是其延遲較大,難以處理實時需求更高的連續流數據請求。因此,產生了現在主流的可以處理高實時性任務的第四代大數據計算引擎Flink[7]。Flink對事件時間的支持、精確一次(Exactly-Once)的狀態一致性以及內部檢查點機制等特性,決定了其在大數據計算引擎上占據主流地位。現如今越來越多的公司采用基于Flink的大數據計算引擎去實現多種場景,比如阿里巴巴雙十一實時大屏的投放、騰訊實時平臺的搭建以及美團、餓了么、愛奇藝等公司的數據處理流程都是基于Flink構建的。
在大數據計算引擎Flink中,大量的計算任務需要被調度到資源節點上,如何使整體任務用最少的完成時間,在很大程度上由它的調度算法決定,因此良好的任務調度算法是分布式計算的重要組成部分。有效的任務調度是分布式計算的一個關鍵問題,其目標是在滿足任務依賴關系的前提下,調整任務的執行順序,將任務分配給對應的資源,使整個系統的任務能在最短的時間內執行完成。
由于集群的異構性以及不同算子復雜度不同,大數據計算系統中不可避免地會出現負載不均的情況,本文提出了基于資源反饋的負載均衡任務調度算法RFTS(load balancing Task Scheduling algorithm based on Resource Feedback)。與傳統的負載均衡算法不同的是,RFTS算法綜合考慮了集群計算資源的實時負載情況以及處理任務的優先級和順序,更高效地完成任務與計算資源之間的分配,通過實時資源監控、區域劃分和基于人工螢火蟲優化GSO(Glowworm Swarm Optimization)的任務調度算法3個模塊,把負載過重的機器中處于等待隊列中的任務分配給負載較輕的機器,提高系統處理任務的執行效率和集群利用率。
本文的主要貢獻包括以下3個方面:
(1) 設計了一個Flink系統的實時監控系統Monitor,實時監控每個從節點(Slave)的CPU核數、CPU利用率、內存利用率和總內存大小等性能指標,從而獲取每個資源節點的負載大小。
(2) 提出基于資源反饋的負載均衡任務調度算法。該算法在集群出現負載不均時,重新分配每個資源節點的任務,以提高系統執行效率和整體資源利用率。該算法通過實現的實時監控系統Monitor來監控資源節點的負載情況,并根據區域劃分算法把集群劃分為過負載、輕負載、近飽和和差飽和4個區域,由于過負載區域的機器負載過重會影響整個集群的執行效率,因此用基于人工螢火蟲優化算法的調度策略,把過負載區域中資源節點位于等待隊列的任務調度給差飽和區域的資源節點。
(3) 通過編寫源碼,在大數據計算系統Flink中,實現了RFTS算法。
最后在TPC-C和TPC-H[8]數據集上對基于資源反饋的負載均衡任務調度算法進行了實驗,實驗結果表明,該算法在執行時間和吞吐量方面均有明顯的提升效果.
2 相關工作
任務調度是指系統將用戶提交的任務通過某種方式進行拆分、重組并分配到集群中對應的資源節點進行計算的過程。眾所周知,任務調度問題是NP-hard[9]。大數據計算模型是一種新型的分布式計算模型,專門用于處理海量數據的存儲、分析和計算,其優點在于能以使用較低的時間和空間成本來實現系統的高可擴性和可伸縮性。這些決定了大數據計算模型不僅可以應對數據日益增長的計算、存儲和分析需求,也可以很好地滿足并適應網絡環境中復雜多變的特點,保障基本的網絡性能請求。大數據計算中資源的服務質量好壞是衡量大數據計算效果的一個重要方面,但是大數據計算中云端存在諸多形態,且系統規模巨大,資源節點之間的結構差異性也較大,因此如何更好地實現任務調度就成為了大數據計算研究中的熱點和難點問題。
調度算法的目的是將任務調度到資源節點的同時使得任務的執行時間和吞吐量盡可能好。任務執行所需要的資源、網絡IO、耗費的時間和用戶需求等都由任務調度策略決定。因此,在分布式計算中任務調度很大程度上決定了分布式計算系統的系統性能。
分布式計算中常用的調度算法有經典調度算法和啟發式調度算法。經典調度算法主要有Max-Min算法[10]、Max-Max算法和Sufferage算法[11]、先到先服務、輪詢調度算法[12]以及公平調度算法[13]等,這些算法由于參數少、操作簡單、容易復現等優點被廣泛使用。但是,這類算法也存在著面對復雜場景和數據頻繁被調度的場景時任務分配效果較差、容易導致數據傾斜等缺點[14]。因此,研究人員提出了主要針對復雜場景的啟發式調度算法。Holland于1975年通過觀察生物界進化的規律,通過組合交叉、遺傳和變異的方式提出了遺傳算法[15];1991年意大利學者Dorigo通過模擬蟻群根據信息素的反饋信息不斷改變尋找食物的速度和方向的行為提出了蟻群算法[16];1995年Eberhart和Kenny博士通過觀察鳥群在遷移過程中根據其他鳥類的飛行軌跡來改變自身速度和位置的行為模式,提出了粒子群算法[17];還有現在被廣泛使用的模擬退火算法[18]、差分演化算法[19]等。啟發式調度算法雖然適合復雜場景并能夠快速展開全局搜索,但也存在隨機性過高、容易陷入局部最優解和參數難以控制等缺點。
Flink系統中默認的調度策略是輪詢調度算法,這種算法不考慮每個資源節點的異構性,容易導致集群負載不均,使性能強的資源節點和性能差的資源節點面對同樣多的任務,這時性能差的資源節點需要更多的時間,根據水桶效應,系統的執行效率是由性能最差的節點所決定的,因此集群負載不均會降低整個系統的執行效率。
基于上述分析可知,現有的調度算法不足以高效優化實時大數據計算系統Flink的執行速度,因此需要研究新的任務調度算法,使其在面對Flink系統復雜場景時能保證負載均衡且盡可能地提高系統執行效率。所以,本文提出了基于資源反饋的負載均衡任務調度算法RFTS。與傳統的負載均衡調度算法相比,RFTS算法根據集群中每臺機器當前的負載壓力和任務優先級來快速而高效地分配任務,可以在不降低任務處理實時性的前提下,提高系統處理任務的總體執行效率。
3 基于資源反饋的負載均衡任務調度算法RFTS
由于集群的異構性以及不同算子復雜度不同,分布式計算系統中不可避免地會出現負載不均的情況。針對該問題,本文提出了基于資源反饋的負載均衡任務調度算法。
在本節中,首先介紹RFTS算法的基本思想;接著,借助實例分別介紹RFTS算法包含的3個主要模塊。
3.1 定義與說明
首先對RFTS中用到的變量和公式進行定義與說明。令TM={TM1,TM2,…,TMm}為分布式系統中資源節點的集合,T={T1,T2,…,Tn}為需要執行的全部任務的集合。
定義1(任務整體完成時間) 任務整體完成時間是指從第一個任務執行開始到所有任務中最后一個任務完成所經歷的時間,記為TotalTime。負載均衡的目標是使得TotalTime盡可能小。
定義2(資源節點性能指標) 資源節點的性能指標如式(1)所示:
Metricj=C1*Core_Numj*ω1j+
C2*(1-ω2j)*ω3j,j=1,2,…,m
(1)
其中,C1、C2為常數,Core_Numj表示資源節點TMj的CPU核數,ω1j表示資源節點TMj的CPU利用率,ω2j表示資源節點TMj的內存利用率,ω3j表示資源節點TMj的總內存大小。因此,資源節點性能指標Metricj由CPU核數、CPU利用率和空閑內存大小決定,最后作歸一化處理。
定義3(資源節點負載值) 負載值代表該資源節點上任務負載量相對于該節點當前性能的承擔能力。負載值越小,表示該節點承受負載的能力越好,即可以承受更多的任務;反之,負載值越大,該節點承受負載的能力越差,需要減少該節點執行的任務。負載值的定義如式(2)所示:
(2)
其中,TaskNumj表示資源節點TMj的任務隊列中的任務數量;Metricj代表資源節點TMj的性能指標,Metricj越大,代表該資源節點性能越好,可以在單位時間內處理更多的任務;反之,則代表該資源節點的性能越差,在單位時間內能夠處理的任務越少。
集群負載平均值的定義如式(3)所示:
(3)
定義4(集群負載值) 集群負載值表示整個集群的負載均衡程度,如式(4)所示。如果集群負載值C_Load小于閾值β,則說明集群整體負載處于均衡狀態,算法結束;否則,集群負載值越大,說明集群負載不均的程度越高,此時需要將每個節點的負載值和集群負載值存入MongoDB數據庫中,為下一階段的區域劃分和任務重新調度做準備。
(4)
3.2 主要思想
由于Flink系統中任務以隨機順序調度,本文提出了一種基于資源反饋的負載均衡任務調度算法,算法構建了一個優化器,通過集群資源實時監控、集群區域劃分和任務重新分配去優化Flink系統中的調度策略,以避免負載不均的情況。
RFTS算法的總體框架如圖1所示,其基本思想是先通過實時監控集群的性能情況,得到每個資源節點的負載值和整個集群的負載值,并把這些信息實時存儲到MongoDB數據庫中,集群的負載越小,則說明整個集群的負載越均衡。因此,當負載均衡值小于閾值時,說明集群處于均衡狀態,算法結束;否則,利用區域劃分算法劃分整個集群,把集群分成過負載、輕負載、近飽和和差飽和4個區域,最后采用基于人工螢火蟲優化的任務調度算法結合任務的優先級把過負載區域的任務遷移到差飽和區域中的資源節點上,以降低整個集群的負載值。
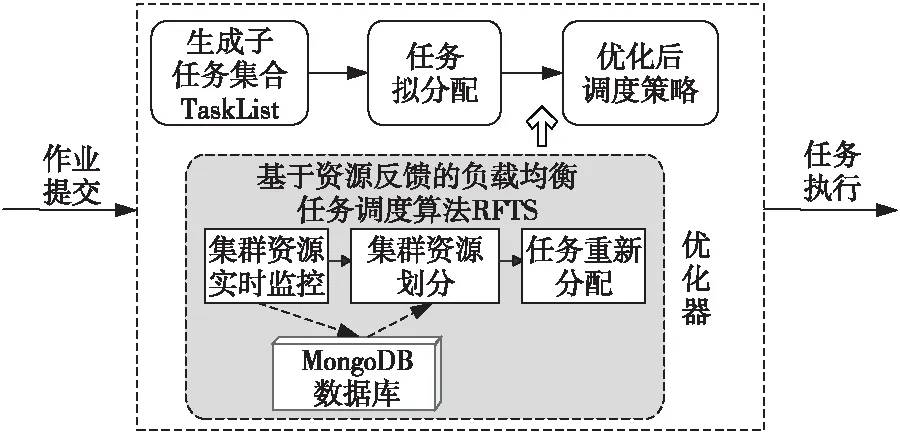
Figure 1 General framework of RFTS圖1 RFTS算法總體框架
本節進一步優化基于Flink本身的調度算法,針對已經完成初步調度策略的集群進行實時性能監控,當負載不均時根據各節點任務隊列中任務的數量和任務的優先級重新產生調度策略。
3.3 資源監控系統
資源監控系統為RFTS算法后期的區域劃分和基于人工螢火蟲優化的任務調度收集重要的系統實時信息。該系統每隔10 s對每個資源節點統計一次實時資源性能數據。在計算資源中最具代表性的資源性能數據包括CPU核數、 CPU 使用率、內存使用率和總內存大小,這4個指標反映了節點當前的負載能力。因此,本文用這4個指標構成的綜合值來代表該資源節點的實時性能,并通過計算得到每個資源節點的負載值,進而得到整個集群的負載值。
資源監控系統的具體流程如算法1所示,當集群負載值大于或等于β時(第1行),對于集群中的每個資源節點TMj,根據監控和管理Java虛擬機(JVM)管理接口的ManagementFactory管理工廠類中的getOperatingSystemMXBean方法去獲取資源節點底層的性能指標,計算節點TMj的CPU核數Core_Numj、CPU利用率ω1j和空閑內存量ω2j,根據式(1)和式(2)可以得出該資源節點TMj的性能指標Metricj和負載值Loadj(第2~5行);根據式(4)得出集群的負載值,并把每個節點的負載值和集群負載值放入數據庫MongoDB中(第6、7行),直到集群負載值小于閾值β,即集群實現整體的負載均衡。
算法1資源監控系統實現算法
輸入:資源節點集合TM、每個資源節點上的任務分配情況TaskNum。
輸出:數據庫MongoDB。
1.While集群負載值大于或等于閾值βdo
2.For集群中的每一個資源節點do
3. 計算資源節點TMj的CPU核數、CPU利用率和當前機器的空閑內存量;
4. 更新資源節點TMj的性能指標和負載值;
5.Endfor
6. 更新集群的整體負載值;
7. 把每個節點的負載值和集群負載值存入數據庫MongoDB中;
8. 輸出數據庫MongoDB;
9.Endwhile
下面通過一個實例來描述資源監控系統的執行過程,如圖2所示。對于整個集群而言,每隔10 s統計一次每個資源節點的CPU核數、CPU利用率、內存利用率和總內存大小,根據式(1)計算出每個節點的性能指標Metricj,根據每個節點上當前任務隊列中的任務數量和實時性能指標計算每個節點的負載值Loadj和集群負載值C_Load,并把這些信息實時存入MongoDB數據庫中,重復上述過程直到集群負載值C_Load小于β。
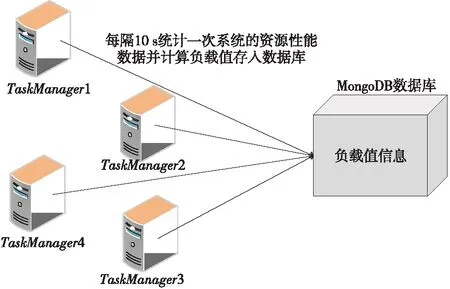
Figure 2 Execution of the resource monitoring system圖2 資源監控系統執行過程
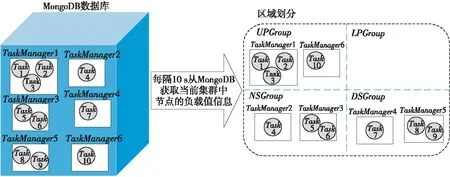
Figure 3 Execution of regional division圖3 區域劃分執行過程
3.4 區域劃分算法
本文將整個集群劃分為過負載、輕負載、近飽和和差飽和4個區域,依次記為UPGroup、LPGroup、NSGroup和DSGroup。
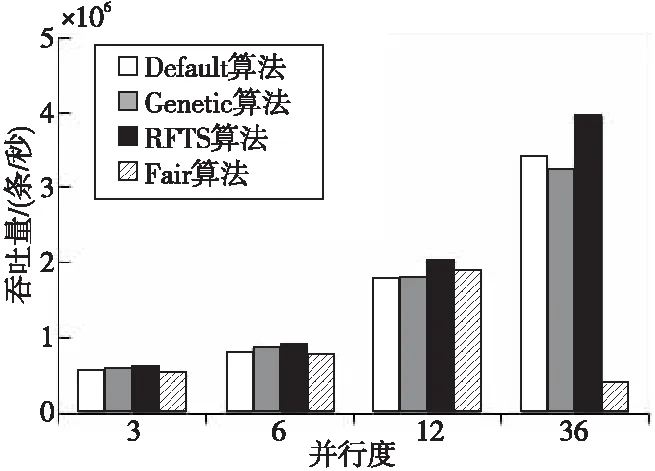
通過定義如式(5)所示的偏移量offset來劃分集群區域。h_threshold為啟發式集群高域值,且h_threshold≥0;l_threshold為低閾值,且l_threshold≤0。如果offsetj≥h_threshold,則節點TMj屬于過負載區域UPGroup;如果0≤offsetj offsetj=δj-β,j=1,2,…,m (5) 其中資源節點TMj負載偏差值δj如式(6)所示: (6) 區域劃分算法的偽代碼如算法2所示。當滿足過負載區域UPGroup不為空且差飽和區域DSGroup不為空,或者集群負載值C_Load<β這2個條件中的一條時(第1行)開始區域劃分算法,每隔10 s從MongoDB數據庫中提取當前資源中每個節點的負載值loadj,計算得出當前整個集群的平均負載,根據式(5)計算得到每個資源節點的當前偏移量offsetj(第3、4行),并結合啟發式集群高低閾值h_threshold和l_threshold計算出該節點的負載承受能力,根據該節點負載承受能力的高低把該節點分配到對應所屬區域(第5~16行)。如果區域劃分算法結束時C_Load小于β,則算法結束,否則,進入到基于人工螢火蟲優化的任務調度算法重新分配任務調度集合。 算法2區域劃分算法 輸入:數據庫MongoDB。 輸出:過負載區域UPGroup、輕負載區域LPGroup、近飽和區域NSGroup和差飽和區域DSGroup。 1.While(UPGroup≠?∧DSGroup≠?)∨(C_Load<β)do 2.ForMongoDB數據庫中的每一個資源節點 3. 計算每個資源節點TMj的負載偏差值δj; 4. 計算每個資源節點TMj的偏移量offsetj; 5.Casewhenoffsetj≥h_thresholdthen 6. 把資源節點TMj放入過負載區域UPGroup; 7.When0≤offsetj 8. 把資源節點TMj放入輕負載區域LPGroup; 9.Whenoffsetj 10. 把資源節點TMj放入差飽和區域DSGroup; 11.Whenl_threshold≤offsetj<0then 12. 把資源節點TMj放入近飽和區域NSGroup; 13.EndWhile 14.輸出劃分好的過負載區域UPGroup、輕負載區域LPGroup、近飽和區域NSGroup和差飽和區域DSGroup. 下面通過一個實例來描述區域劃分算法的具體執行過程,如圖3所示。假定當前集群由6個TaskManager組成,根據3.3節提出的資源監控系統,每個TaskManager的實時負載值都存儲在MongoDB數據庫中,每隔10 s從該數據庫中重新提取當前資源中每個節點的負載值Loadj和集群的負載值C_Load,并計算得到每個節點相對于集群負載平均值的偏移量。該實例中,TaskManager1~TaskManager6的偏移量分別是0.91,-0.09,-0.12,-0.58,-0.31和0.87,集群的高閾值為0.83,低閾值為-0.27,根據區域劃分算法,分配結果如圖3的右圖所示,TaskManager1和TaskManager6被分配到UPGroup,TaskManager2和TaskManager3被分配到NSGroup,TaskManager4和TaskManager5被分配到DSGroup。 人工螢火蟲優化GSO算法是2005年由印度學者Krishnanand和Ghose提出的一種新型的全局智能優化算法。該算法定義了螢火蟲的解空間,每個螢火蟲都有決策域,即自己的視線范圍。每只螢火蟲的亮度與其所在位置的目標函數值有關,螢火蟲位置的目標函數值越高,其亮度越大;相反,則亮度越小。根據螢火蟲的自然生活規律,它將在決策域中找到下一次運動方向。在決策域中,區域越亮,對螢火蟲的吸引力越強。螢火蟲的飛行方向會根據鄰域改變。另外,決策域的大小受鄰域中個體數目的影響,當鄰域密度減小時,螢火蟲決策域半徑增大,為了發現更多的鄰居,鄰域密度越大,其決策域半徑越小。最終,大部分螢火蟲會在一個區域內凝結,即達到極值點。 本節提出的基于人工螢火蟲優化的任務調度算法的原理是,基于3.4節的區域劃分算法把過負載區域UPGroup中的節點TMj上的任務Ti按照基于人工螢火蟲優化的任務調度策略調度到差飽和區域DSGroup中的節點TMp上,UPGroup中的節點按照負載值的大小降序排序,依次調度到DSGroup中,直到集群負載值C_Load小于閾值β。在該算法中任務Ti被定義為螢火蟲,DSGroup區域中的節點TMp被定義為螢火蟲的目標區域,任務的目標函數由UPGroup中節點TMj的任務數量、節點TMj中的任務Ti的優先級、目標節點TMp的負載值和目標節點TMp上高優先級任務的數量共同決定。下面先對本文提出的基于人工螢火蟲優化的任務調度算法進行基本定義與概念說明: 令N={n1,n2,…,nn}為螢火蟲集合,初始化每個螢火蟲的熒光素為l0,決策域為r0。螢火蟲ni在時刻t的熒光素值如式(7)所示: li(t)=(1-ρ)li(t-1)+γf(xi(t)), i=1,2,…,n (7) 其中,ρ代表螢火蟲中熒光素的消失率,γ代表熒光素的更新率,f(xi(t))表示螢火蟲ni在時刻t時位置xi(t)的目標函數值。 螢火蟲ni在t時刻的鄰居集合Gi(t)如式(8)所示: li(t) (8) 螢火蟲ni的速度方向v的定義如式(9)所示。 v=max(pi),pi={pi1,pi2,…,piGi(t)} (9) 其中, (10) 為螢火蟲ni向螢火蟲nj方向的轉移概率。 螢火蟲ni在時刻t時的位置定義如式(11)所示: (11) 其中,s為螢火蟲的步長。 φ(gt-1-|Gi(t-1)|)}} (12) 其中,rs表示螢火蟲的感知域范圍,φ表示決策域的更新率,gt-1表示螢火蟲在t-1時刻的鄰域閾值,Gi(t-1)表示螢火蟲ni在t-1時刻的鄰域。 基于人工螢火蟲算法的任務調度算法的流程如算法3所示,首先把UPGroup中的任務按照負載值高低進行排序,把UPGroup中的任務設定為螢火蟲,DSGroup區域設定為發光區域,在發光區域中尋找最優解并把任務調度到最優的資源節點上。 算法3基于人工螢火蟲優化的任務調度算法 輸入:螢火蟲集合N={n1,n2,…,nn}、迭代次數M、過負載區域UPGroup、輕負載區域LPGroup、近飽和區域NSGroup、差飽和區域DSGroup。 輸出:把UPGroup區域的任務調度給DSGroup中的節點DataNode。 1. 初始化算法中需要用到的參數; 2.ForniinN 3. 初始化熒光素、初始位置和初始決策域; 4.While當UPGroup區域和DSGroup區域都不空時,才有任務可以調度的空間do Figure 4 Execution process of task scheduling algorithm based on GSO algorithm圖4 基于人工螢火蟲算法的任務調度算法執行過程 5.ForniinN 7.For鄰域集合中的螢火蟲nj 8. 根據式(10)更新螢火蟲ni向螢火蟲nj方向的轉移概率; 9.If螢火蟲ni向螢火蟲nj方向的轉移概率大于此時最大值maxthen 10. 更新最大值為此時的轉移概率; 11.Endif 12.Endfor 13. 選出最大值作為螢火蟲ni的移動速度方向v; 14. 使螢火蟲ni向下一次迭代速度方向v移動并更新螢火蟲移動后的位置點; 15.Endfor 16. 更新螢火蟲在t+1時刻的決策域范圍并求出全局最優點pbest; 17.For過負載區域UPGroup中的任務Tj 18. 把任務Tj調度到差飽和區域DSGroup中選出的最優節點pbest; 19.Endfor 20.Endwhile 21.Endfor 22. 輸出更新過后的過負載區域UPGroup、輕負載區域LPGroup、近飽和區域NSGroup和差飽和區域DSGroup集合. 下面通過一個實例來描述基于人工螢火蟲優化的任務調度算法的具體執行過程,如圖4所示。 圖4a為原本的區域分配情況以及任務和資源節點的對應調度情況,當UPGroup和DSGroup都不為空時,把過負載區域UPGroup中的資源節點根據負載值由高到低進行排序,并把該資源節點中的任務按照優先級由高到低進行排序,對于UPGroup中的節點對應的分配任務模擬為螢火蟲,DSGroup定義為螢火蟲的區域移動范圍。 在本次實例中UPGroup中資源節點為TaskManager1和TaskManager6,它們的偏移量分別是0.91和0.87,TaskManager1中的任務Task1、Task2、Task3的優先級分別是低、低和高,TaskManager1中的任務Task3的優先級分高;對于DSGroup中的TaskManager4和TaskManager5的偏移量分別是-0.58和-0.31;NSGroup中資源節點為TaskManager2和TaskManager3,LPGroup區域為空。因為UPGroup中任務重新調度的順序為先按照資源節點中偏移量由高到低排序,對于同一資源節點中的任務再按照任務的優先級由高到低排序,因此UPGroup中第一個被調度的任務為TaskManager1中的Task3,由于DSGroup中TaskManager4的偏移量低于TaskManager5的偏移量,因此TaskManager1中的Task3任務被調度到TaskManager4中。 此時系統實時性能發生改變,從MongoDB數據庫中獲取實時的資源節點負載值信息,并根據節點當前的任務隊列數量進行重新分區。此時集群任務分配情況如圖4b所示,TaskManager1偏移量更新為0.64,處于LPGroup區域,下一個被調度的任務為UPGroup中的TaskManager6的Task10,此時DSGroup中的TaskManager4和TaskManager5的偏移量分別是-0.37和-0.28,因此Task10被調度到TaskManager4中,并且資源節點的性能發生變化;此時集群重新劃分后如圖4c所示,TaskManager4被劃分到LPGroup,TaskManager6被劃分到DSGroup區域,此時UPGroup為空,即最終的任務調度分配方案。 本文通過修改Flink 1.8.0的源碼,實現了基于資源反饋的負載均衡任務調度算法RFTS。本節設計并實施了一系列實驗,基于TPC-C和TPC-H數據集,從執行時間和吞吐量2個方面對Flink默認的調度算法、公平調度算法、遺傳算法和本文提出的RFTS算法進行對比實驗,測試了本文提出的面向Flink系統的任務調度優化算法的實用性。 實驗所用環境為4個節點組成的分布式集群,包括1個主節點(Master)和3個從節點(Slave),每臺服務器的配置信息如表1所示。 Table 1 Hardware configuration表1 硬件配置 搭建成由4臺服務器組成的Flink集群,其中的1臺Master為Flink集群中的JobManager節點,3臺Slave節點為Flink中的TaskManager節點,節點間通過千兆以太網連接,節點間的運行方式為Standalone模式。Flink集群的軟件及其版本如表2所示。 Table 2 Software configuration表2 軟件配置 本文實驗使用TPC-C和TPC-H數據集分別生成6個不同大小的數據集,測試程序將在這12個數據集上進行測試。數據集的來源和規模如表3所示。 Table 3 Dataset size表3 數據集規模 下面分別介紹這2個數據集的數據特征: TPC-C是聯機交易處理系統OLTP(On-Line Transaction Processing)的規范,TPC-C測試中使用的模型是一家大型商品批發銷售公司,在不同地區中設有多個倉庫,隨著業務的增長,公司需要添加新的倉庫,每個倉庫有10個銷售點,每個銷售點為3 000個客戶提供服務,每個銷售訂單對應10種產品,大約有1%的產品顯示缺貨時,需要從其他區域的倉庫中調運。整個TPC-C數據集由9張表組成,包括客戶表、區域、訂單表等等,產生的交易事務主要有5種,分別是新訂單、支付操作、發貨、訂單狀態查詢和庫存狀態查詢,該數據集可以通過命令指定生成數據集的大小。 TPC-H是商品零售業決策支持系統的測試基準,測試系統中復雜查詢的執行時間。它包含8個基本表,數據量可以設置為1 GB~3 TB不等,其基準測試包含22個查詢,查詢語句嚴格遵守SQL-92語法,并且不允許修改,主要指標為每個請求的響應時間,即提交任務后返回結果所花費的總時間。TPC-H中數據量的大小對查詢速度的影響很大,使用SF描述數據量,1SF對應1 GB單位,并且人工設定的數據量只是8個表中的總數據量并不包含索引和臨時表等空間占用情況,因此設定數據時需要預留更多的空間。對于同樣規模大小的數據集,TPC-H產生的數據類型比TPC-C產生的數據類型更多樣,關系更復雜。 本文分別在TPC-C和TPC-H不同規模的數據集上測試RFTS算法的處理時間,結果如表4所示,TPC-C代表簡單場景下的測試,TPC-H代表復雜場景下的測試。隨著數據集規模的增大,算法處理時間占任務整體執行時間的比例也增大了,這是因為處理任務的數據規模越大,出現負載不均的情況越多,需要遷移的任務急劇增多,因此調度算法所占整體執行時間的本身的比例也就越大。從表4可以看出,無論對于簡單數據還是復雜數據而言,調度算法所占整體執行時間的比例都小于1%。 其中,Dataset7~Dataset12對應的數據是基于TPC-H數據集的測試結果,Dataset1~Dataset6對應的數據是基于TPC-C數據集的測試結果。通過對比Dataset1&Dataset7,Dataset2&Dataset8,Dataset3&Dataset9,Dataset4&Dataset10,Dataset5&Dataset11,Dataset6&Dataset12,可以發現基于TPC-H數據集的實驗中任務整體執行時間和調度算法本身占用的時間都比基于TPC-C的要大,但是算法處理時間占任務整體執行時間的比例反而更小了。這是因為對于復雜數據場景,負載不均的情況更常見,RFTS算法的調度算法本身增加的時間對于優化的系統執行效率來說影響更小,即優化的效果更好。實驗結果表明,無論是TPC-C對應的簡單環境還是TPC-H對應的復雜場景,算法本身處理時間占任務整體執行時間的比例都很小。 Table 4 Proportion of processing time of the RFTS algorithm表4 RFTS算法的處理時間占比 執行時間是指從任務提交到完成所需要的總時間。執行時間越少,代表系統處理任務的計算能力越強。本節對RFTS算法、公平調度算法(Fair)、遺傳算法(Genetic)和Flink默認的輪詢調度算法(Default)在任務整體執行時間上進行對比實驗,分別基于TPC-C和TPC-H的6個數據集進行測試,作業并行度都設置為12,測試用例為WordCount。圖5和圖6分別為基于TPC-C和TPC-H數據集的執行時間對比圖。 Figure 5 Comparison of execution time based on TPC-C dataset圖5 基于TPC-C數據集的執行時間對比 Figure 6 Comparison of execution time based on TPC-H dataset圖6 基于TPC-H數據集的執行時間對比 從圖5和圖6可以看出,采用Fair調度算法與默認的輪詢調度算法的執行效率相差不大;采用遺傳算法Genetic的執行效率要優于采用Fair調度和默認的輪詢調度算法的,優化效果約為3.1%,在數據集為11 GB時優化效果最好;而采用本文提出的RFTS算法比采用Flink默認的輪詢調度算法、Fair調度算法和Genetic算法的執行時間都要短,且隨著數據集規模的增大,執行時間的優化效果越好,且在數據集規模大小相同的情況下,圖6對應的基于TPC-H數據集的執行時間優化效果優于圖5對應的基于TPC-C數據集的執行時間優化效果。原因同上,這說明RFTS算法對于復雜的、大規模場景執行時間優化效果更好。但是,無論是在TPC-C對應的簡單場景還是在TPC-H對應的復雜場景下,采用RFTS算法后的整體任務執行時間都要少于采用Flink默認的輪詢任務調度算法的。在多種數據集的測試下最終求出采用RFTS算法時整體任務執行時間的平均優化效率為6.3%。 吞吐量(throughput)是指系統單位時間內能夠處理的數據量大小,代表了系統的負載能力。圖7為RFTS算法、公平調度算法(Fair)、遺傳算法(Genetic)和 Flink默認的調度算法(Default)在不同并行度下的吞吐量對比分析圖。分析圖7可知,采用Fair算法時的吞吐量比采用Flink默認的輪詢算法的低;采用Genetic算法時的吞吐量優于采用Flink默認的輪詢算法和Fair算法的,在多種數據集測試下最終求出的采用Genetic算法的吞吐量平均優化效率為3.9%;而采用RFTS算法相比采用Flink默認的輪詢算法、Fair算法和Genetic算法的吞吐量更大,并且隨著并行度的增大,增加了同一時間內處理任務的機器數量,系統承受負載的能力增大,即系統單位時間內可以處理更多的數據。相比而言,使用RFTS算法吞吐量優化效果更好,這是因為使用RFTS算法會實時監控系統性能,并根據每個資源節點的負載承受能力,去調整任務隊列中的任務數量,時刻保證集群負載均衡,大大提升了資源利用率以及單位時間內可以處理的數據量。在多種數據集測試下最終求出的采用RFTS算法的吞吐量平均優化效率為11.7%。 Figure 7 Comparison of throughput at different degrees of parallelism圖7 不同并行度下吞吐量對比 Flink作為現在主流的大數據計算引擎,在實時數據處理和離線數據處理上都表現出了良好的效果,然而Flink計算引擎中的任務調度還有許多待優化的空間,因此本文提出了基于資源反饋的負載均衡任務調度算法RFTS。實驗結果表明,本文提出的RFTS算法能夠有效減少Flink計算引擎中任務的整體執行時間,增加吞吐量。 未來希望本文提出的RFTS算法可以應用于其它的大數據計算引擎中,并取得性能提升。3.5 基于人工螢火蟲優化的任務調度算法
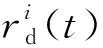
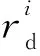
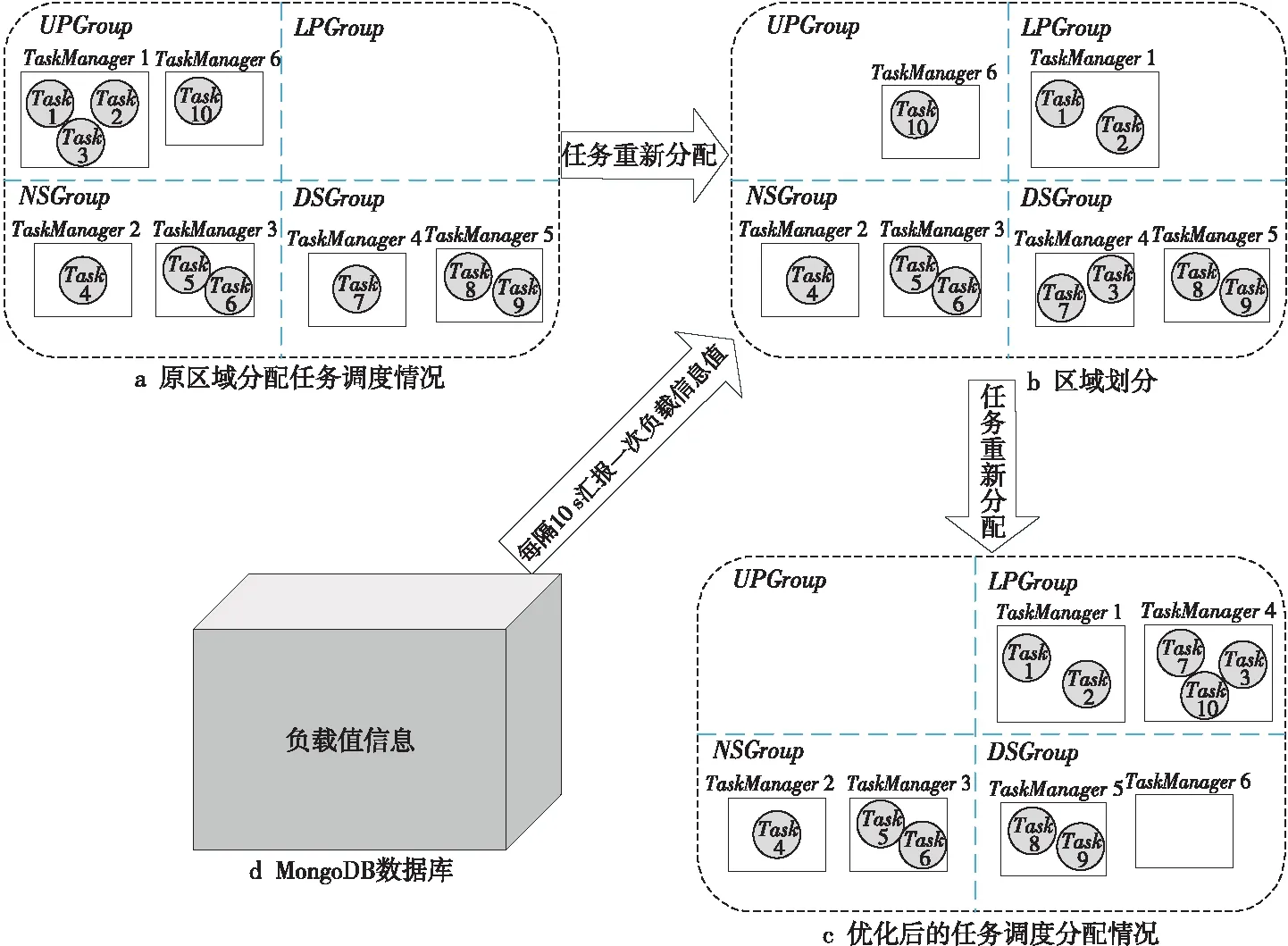
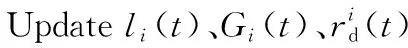
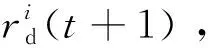
4 實驗與分析
4.1 實驗環境配置


4.2 數據集
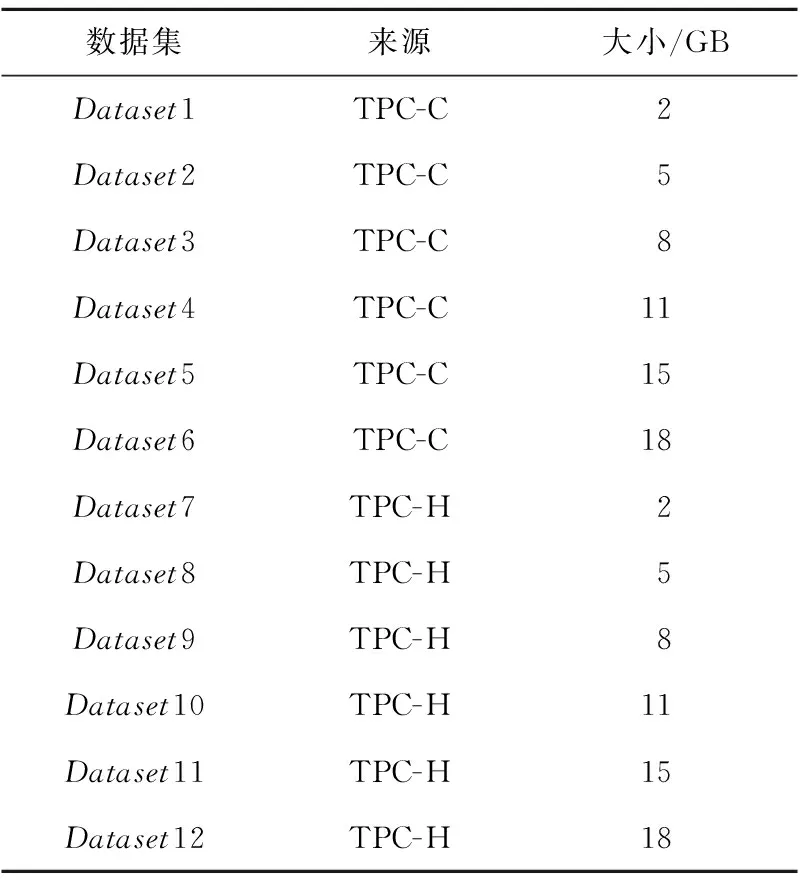
4.3 算法本身處理時間
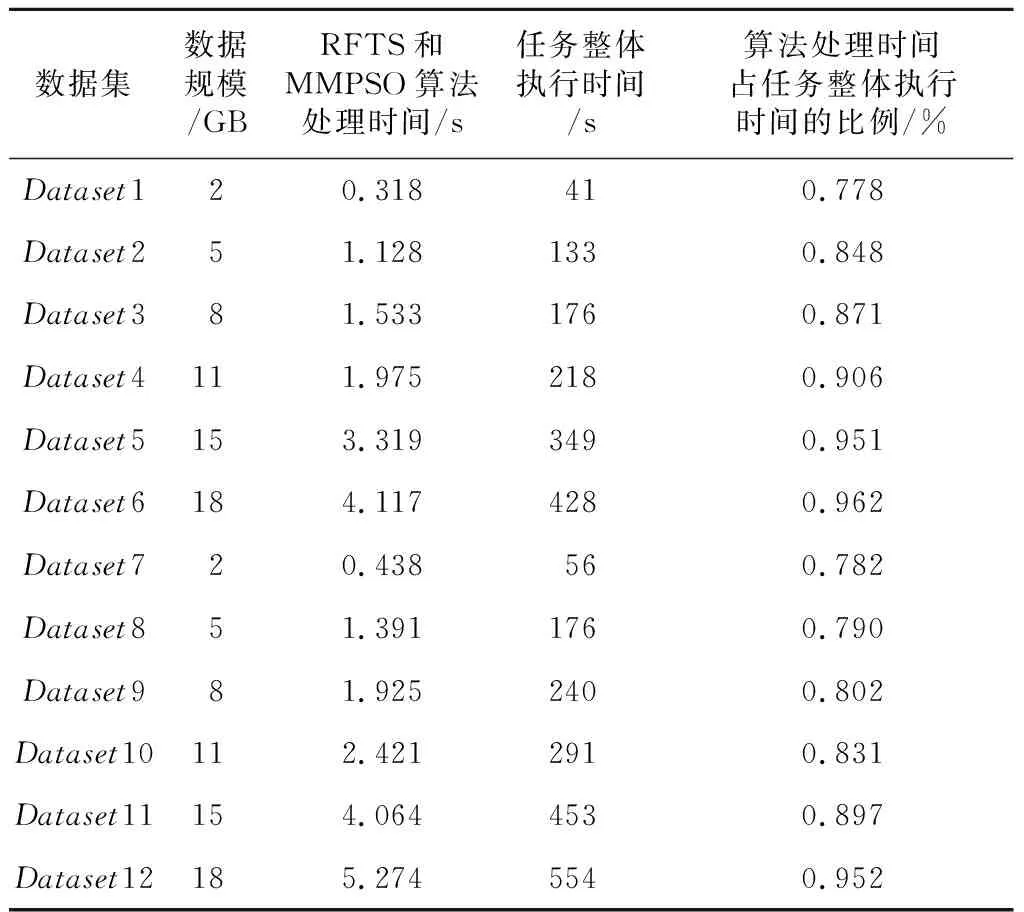
4.4 執行時間對比分析
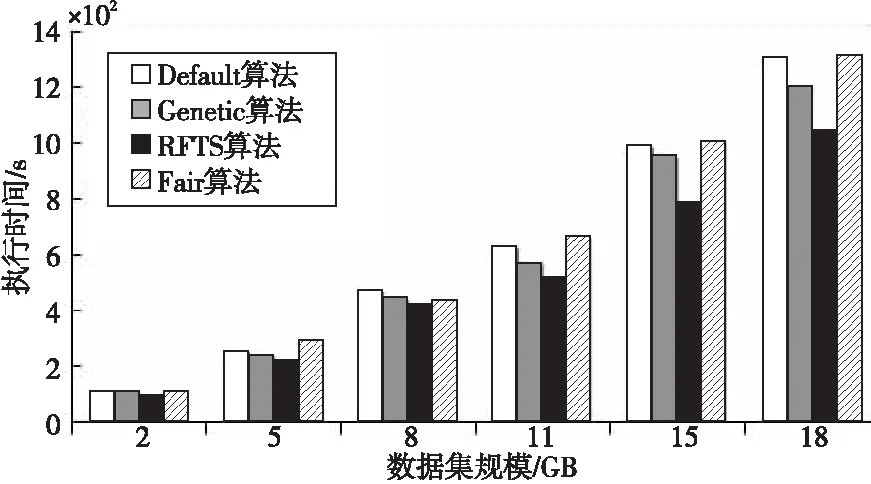
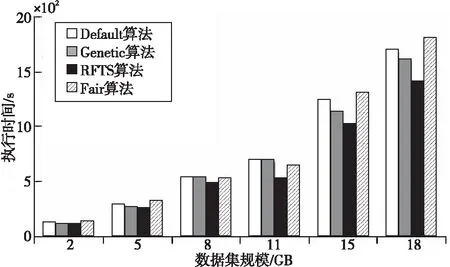
4.5 吞吐量對比分析
5 結束語
猜你喜歡
江蘇安全生產(2023年1期)2023-02-08 05:58:38吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48今日農業(2021年9期)2021-11-26 07:41:24發明與創新·小學生(2021年3期)2021-03-25 11:48:49作文成功之路·小學版(2020年5期)2020-06-11 12:48:26小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26資源再生(2017年3期)2017-06-01 12:20:59中國科技博覽(2016年2期)2016-04-25 20:32:39小學生導刊(2016年34期)2016-04-11 00:49:44電測與儀表(2015年5期)2015-04-09 11:30:52
