增強非線性特征提取的時間間隔感知序列推薦
2022-08-12 01:54:20寧昱霖
現代信息科技 2022年7期
寧昱霖
(安徽理工大學 計算機科學與工程學院,安徽 淮南 232001)
0 引 言
隨著互聯網技術的迅速發展,全球的數據總量呈井噴式增長。雖然大數據蘊含豐富的信息及巨大的商機,但信息過載造成的問題也隨之而來。如何有效的從海量的數據中提煉出有價值的信息成為當今信息檢索領域發展的一大難題。推薦系統作為緩解信息過載的技術之一,它已經成為電子商務、短視頻、新聞推送等各個互聯網領域的核心技術。
傳統的推薦模型,例如基于內容和基于用戶的協同過濾推薦,它們是以一種靜態的方式建模用戶和項目的交互且只可捕獲用戶廣義的喜好,而在現實生活中用戶的偏好是不斷改變的并且用戶前后的行為都存在極強的關聯性。序列推薦模型就是利用了用戶興趣的動態性,試圖將用戶過去的歷史行為記錄建模成一個項目序列,根據用戶最近交互的項目來預測他們的下一步行動。基于時間間隔的序列推薦模型是在傳統的序列推薦模型中顯式地融入用戶與項目交互時間的間隔。但由于數據集中涉及了復雜的時間間隔信息,單一的前饋神經網絡無法完全提取數據集中蘊含的信息,因此,本文準備使用三階段線性層代替前饋神經網絡以充分提取數據集中蘊含的信息。
1 模型與方法
本文提出的模型是基于基線模型TiSASRec進行改進的,在本節中,將詳細介紹改進后的TiSASRec 模型的各個組成部分,包括個性化時間間隔處理、嵌入層、時間感知自注意力模塊和預測層,模型流程如圖1所示。

圖1 模型流程圖
1.1 問題描述
定義和分別表示用戶字典和項目字典,給定每個用戶∈的歷史行為序列S={s,s,…},其中s∈,行為序列對應的時間序列可表示為T={t,t,…}。在時間步長時,模型會根據之前的項以及兩兩項目之間的時間間隔預測下一個項目。
1.2 項目序列及時間序列的處理

1.3 相對位置矩陣的計算
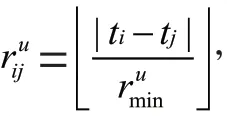
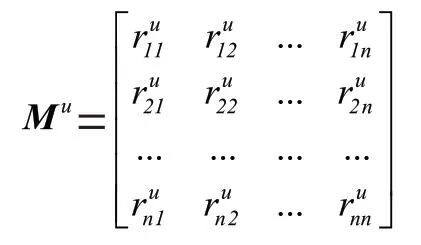
為了防止時間間隔過于稀疏,將時間間隔大于的時間間隔替換為,剪裁后的矩陣表示為M。
1.4 嵌入層
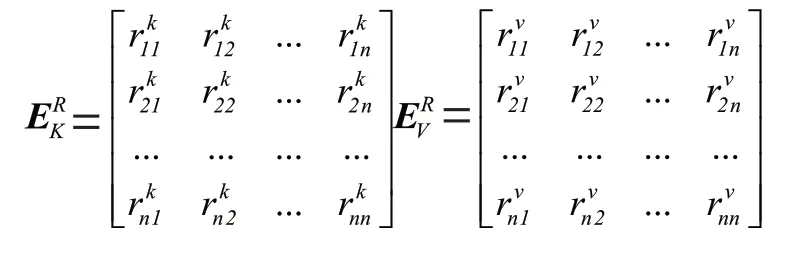
首先創建一個項目嵌入矩陣M∈,為嵌入維度。通過檢索用戶項目序列中的項目索引,從M中找到對應的嵌入表達,將其堆疊在一起,形成矩陣E,E∈R,可表示為E=[m,m,…,m]。然后,使用兩個不同的可學習的位置嵌入矩陣E,E∈R分別作為自注意力機制中key,value 矩陣的絕對位置編碼,表示為E=[p,p,…,p],E=[p,p,…,p]。對于相對位置嵌入矩陣的嵌入表示,同樣采用兩個版本E,E∈R,分別作為自注意力機制中key,value 矩陣的相對位置編碼,表示為:
1.5 時間感知自注意力模塊
1.5.1 時間感知自注意力機制
對于每個用戶∈的項目交互序列E=[m,m,…,m],計算新的序列=[,,…,z],對于每個z都是由項目交互序列的嵌入表達經過線性變化后再加權求和得到的。用公式可表達為:
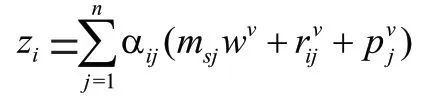
其中,w∈R為自注意力機制中將項目交互序列轉化為value 矩陣的線性層,α是softmax 函數對于權重系數的歸一化操作,可以表達為:
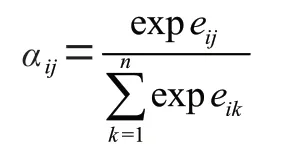
其中,e為結合交互序列中的項目信息,絕對位置信息以及相對位置信息的權重系數,可表示為:
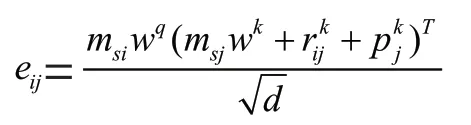
其中,w,w∈R分別為自注意力機制中將項目交互序列轉化為query,key 矩陣的線性層。為了防止模型未卜先知,需屏蔽所有q和k的連接(>)。
1.5.2 多層線性層
時間感知自注意力機制本質上仍然是一個線性模塊,沒有提取數據集非線性特征的能力,因此,需要在時間感知自注意力機制后面添加一個可以提取數據集中非線性特征的模塊。TiSASRec 模型采用一個前饋神經網絡提取數據集的非線性特征,但由于模型的輸入信息中包含復雜的時間信息,因此,本文選擇使用三層線性層替換前饋神經網絡進行非線性特征的提取,并且使用LeakyReLU 函數作為激活函數。其公式可表達為:
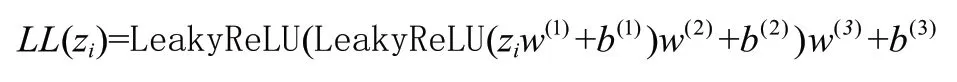
其中,∈R,∈,∈,∈,∈,∈R。
由于稠密數據集可能需要疊加多層注意力機制以及線性層,因此,會出現過擬合、梯度爆炸、訓練不穩定等問題。因此,采用傳統的層規范化、殘差連接以及dropout 來解決這些問題。

其中,⊙指的是元素的乘積,和是的均值和方差,和分別是比例因子和偏差項。
1.5.3 預測層
為了預測下一個項目,利用隱因子模型的思想計算用戶對項目的偏好分數,公式為:

1.6 損失函數及模型推理
由于模型的目標是提供一個排序后的項目列表,以驗證正樣本在項目列表的位置。因此,通過負采樣的方式來優化項目的排名。損失函數選擇binary cross entropy 函數:
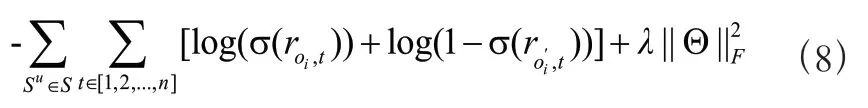

其中,o為期待的正輸出,’為o的負樣本,Θ={M,E,E,E,E},||?||是Frobenius 范數,是正則化參數,S是某個用戶的項目序列,是全部用戶的集合。
模型的任務是將給定的項目序列S={s,s,…,s}以及時間序列T={t,t,…,t}轉化為=[,,…,z],z可表示為:

2 實驗
2.1 數據集簡介
Movielens 1M:一個廣泛用于推薦系統的電影數據集,包含來自6 000 名用戶對4 000 部電影的100 萬條評分。
京東數據集:由京東公開,包含7 萬名用戶對2 萬個物品的455 萬條行為信息,為防止項目在項目序列中重復出現,本文只選取行為信息中的“瀏覽”部分作為樣本。
豆瓣影評數據集:采集于豆瓣電影,包含60 萬個用戶對7 萬部電影的400 萬條評分。
數據清洗后的數據集數據如表1所示。
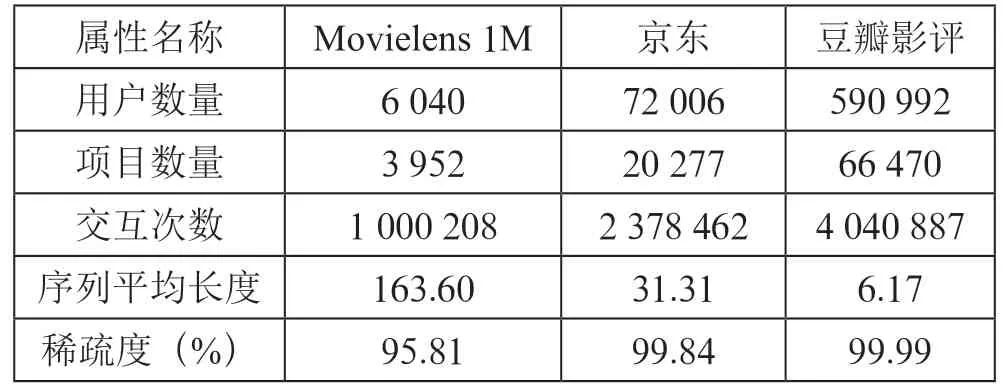
表1 數據集的數據
2.2 評估指標
由于模型最終會提供一個排序后的項目列表,因此,實驗選取了兩個常見的Top-評估指標HitRate@和NDCG@,以評估模型的性能。對于每個用戶,模型會隨機選取100 個負樣本,將正樣本與負樣本混合,對這101 個樣本進行排序,再通過HitRate@和NDCG@計算模型的性能。
HitRate@關注每個用戶的正樣本是否出現在101 個樣本排序后列表的前個項目中,其計算公式為:
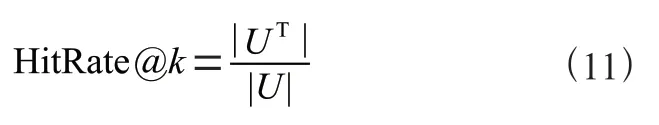
其中,||代表全體用戶的數量,||代表所有模型推薦成功的用戶數量。
NDCG@在HitRate@的基礎上更細粒度地關注了正樣本在101 個樣本中的位置,位置靠前得到的增益越大。其計算公式為:
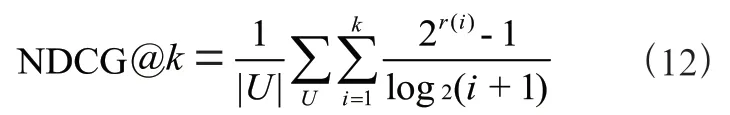
其中,()為指示函數,用于判定第個項目是否為正樣本。
2.3 實驗環境
操作系統及環境:Ubuntu18.04、Python3.8、CUDA11.0、PyTorch1.7.1。
GPU:NVIDIA GeForce RTX 2080 Ti。
CPU:Xeon E5-2678 v3。
2.4 實驗結果對比與分析
由于本文提出的模型是根據TiSASRec 模型進行改進的,因此在本節,將在三個數據集上進行對比。相關超參數設置如表2所示。

表2 默認超參數設置
實驗結果對比如表3所示。

表3 實驗結果對比
由表3可以看出,本文提出的方法在三個數據集上的性能皆優于TiSASRec 模型。這在一定程度上可以證明用三層線性層代替傳統的前饋神經網絡可以提高模型提取非線性特征的能力,尤其對于稀疏數據集豆瓣電影的提升最大,因為使用多層線性層更能捕獲數據集中的細粒度特征。
3 結 論
本文基于TiSASRec 模型改進的模型通過使用三層不同維度的線性層代替傳統的前饋神經網絡,提高了模型提取非線性特征的能力。經實驗驗證,評估指標在三個數據集上性能皆有提高。后續的工作將聚焦于改進融入相對時間間隔信息的策略,降低模型的復雜度,提高推理速度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
核科學與工程(2015年4期)2015-09-26 11:59:03
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
