人體肌電信號采集識別系統設計
2016-05-30 09:13:47李大鵬張百云史捷
科技創新導報 2016年14期
關鍵詞:數據采集
李大鵬 張百云 史捷
摘 要:表面肌電信號(Surface Electromyography, SEMG)是一種復雜的伴隨肌肉活動的電生理信號。設計采集系統對上臂肌肉的表面肌電信號進行多路采集,進行信號處理及計算分析,研究上臂運動動作與表面肌電信號特征之間的聯系。設計了肌電信號動作識別系統,在PC機上對信號進行顯示、處理、運算,在下位機顯示識別結果,控制電機做相應動作。實驗驗證可以識別上臂屈伸動作,并做出相應的電機控制動作。
關鍵詞:表面肌電信號 數據采集 識別系統
中圖分類號:TP212.1 文獻標識碼:A 文章編號:1674-098X(2016)05(b)-0068-02
表面肌電信號可以通過表面電極收集到,以避免創傷和感染。表面肌電信號是一種隨機信號,頻帶為10~1000 Hz,而能量主要集中在50~350 Hz,由于被測對象是有生命的系統,在測量方式上受到限制,因此對測量儀器提出了許多苛刻的要求。
研究簡單易用的表面肌電信號采集識別系統,對康復醫療、運動檢測、情感識別等應用具有幫助意義。
1 采集系統設計
1.1 電極
電極采用Ag-AgCl心電監護電極,屏蔽導聯線,是一種不可極化電極,可以將人體內的離子電流轉換為導線中電子電流。
1.2 前置放大器設計
生理前置放大電路的第一級基于INA128構成,兩個電極連接到放大器的差動輸入端,參考電極接地,增益可調。
1.3 濾波器設計
為消除干擾和噪聲的不利影響,需要根據肌電信號的頻率成分選擇適當的頻帶。文章濾波電路采用RC有源濾波器,包括帶通濾波器和雙T帶阻濾波器。高通濾波器的截止頻率為20 Hz,是為了減少由于皮膚和電極之間移動偽差(motion artifact)產生的低頻干擾;低通濾波器(LPF)的截止頻率為650 Hz。
1.4 數據采集卡及LabView界面的設計
選用基于采集卡與Labview及PC機構成的采集系統。在LabView中使用DAQ助手。設置通道1并采集模擬數據中的電壓值,采集用N采樣并采集10 000個數據,顯示相應波形。
1.5 下位機設計
下位機基于51單片機設計,包括與PC機的串口通訊,電機控制及LCD顯示。程序設計要注意顯示模塊耗時較長,步進電機模塊耗時較短,所以在主程序中不能把顯示模塊和步進電機模塊放在同一個循環中。
2 肌電信號的信號處理
肌電信號的時域分析如下。
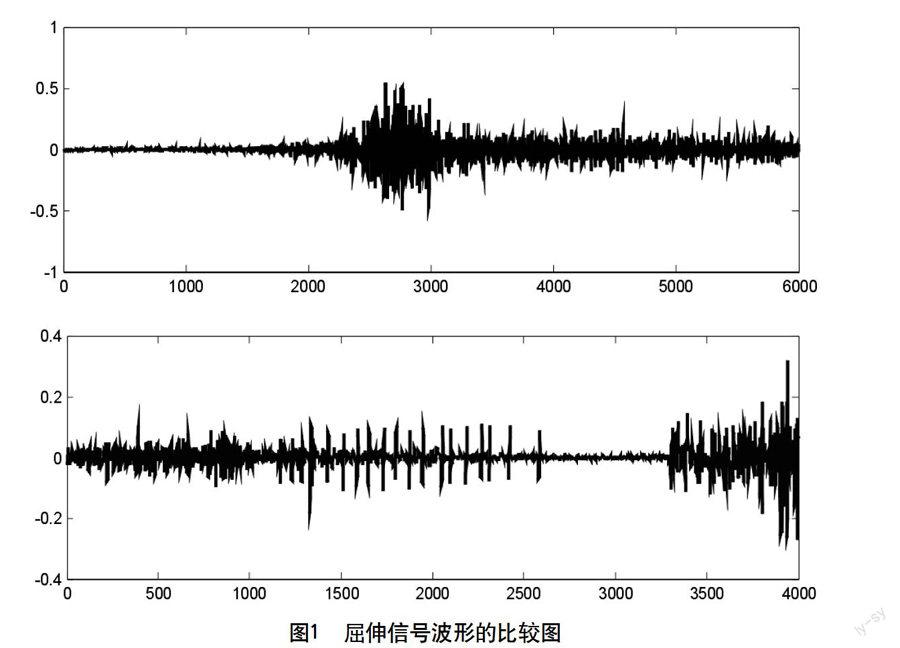
對原始數據采用Matlab對其進行了顯示來比較屈伸原始信號幅值的差別。屈伸信號波形幅值比較如圖1所示。從中可以看出對于屈伸不同動作,肌電信號幅值不同,變化規律也有所不同。
標準差:標準差是方差的算術平方根。標準差能反映一個數據集的離散程度。
積分肌電值IEMG:積分肌電值就是對所有信號取絕對值后積分,然后求均值,可用于提取肌電信號的特征。
均方根RMS:均方根就是一組數據的平方和除以數據的個數再開方,可以濾除信號中的噪聲,使濾波后的信號更平滑、更明顯。
經過比較研究者發現,屈伸信號的均值、標準差、方差均差別不大,但積分肌電值、均方根有效值有顯著差別。故選用了積分肌電值作為閾值的獲取標準。
3 采集識別實驗
為了驗證表面肌電信號采集電路的性能,文章設計了一組人體上肢表面肌電信號的采集識別實驗。
通過閾值比較在下位機上實現了屈伸動作的識別,通過上位機GUI實現了肌電信號的采集、儲存,并對肌電信號進行了時域和頻域的處理,通過比較幅相特性曲線、功率譜、倒譜等。得出屈伸動作下相應圖像差別不是太大,不能直觀地看出明顯的區別。
通過對肌電信號時域分析,得到了相關肌電信號的特征參數,經過比較得到在屈伸動作下積分肌電值的差別較大,適合作為閾值選取的標準。通過對不同人、屈伸時手臂的不同的地方進行多組采集,經過Matlab處理后,比較得到了合適的閾值。實驗中實現了屈伸動作識別并把識別結果顯示在LCD上、通過閾值比較來控制步進電機正反轉、蜂鳴器的報警等功能。
4 結語
文章設計的系統利用采集設備對上臂肌肉做特定動作的表面肌電信號進行多路采集,通過對微弱的肌電信號進行處理及計算分析,研究上臂運動動作與表面肌電信號特征之間的聯系。設計了肌電信號動作識別系統,在PC機上對信號進行顯示、處理、運算,用下位機顯示識別結果,控制電機作相應動作。實驗驗證可以識別上臂屈伸動作,并做出相應電機控制動作,該系統可以用在醫療診斷,康復醫學和假肢仿生控制中。
參考文獻
[1] 李大鵬.表面肌電信號用于假肢控制的研究[D].天津大學,2002.
[2] 李醒飛,李大鵬,張國雄,等.肌電信號控制仿生手的研究[J].中國機械工程,2005,17(5):488-492.
猜你喜歡
現代電子技術(2016年22期)2016-12-26 12:36:15
電子技術與軟件工程(2016年22期)2016-12-26 11:11:30
現代電子技術(2016年22期)2016-12-26 09:44:35
電子技術與軟件工程(2016年19期)2016-12-19 19:59:14
電腦知識與技術(2016年27期)2016-12-15 20:42:01
農業與技術(2016年15期)2016-11-09 17:43:03
科技視界(2016年18期)2016-11-03 22:51:40
中國科技博覽(2016年22期)2016-11-01 16:58:26
軟件工程(2016年8期)2016-10-25 15:54:18
軟件工程(2016年8期)2016-10-25 15:52:53
