基于數據分析的露天煤礦卡車運距計算
2022-08-17 01:02:26馮占科毛志浩劉志成萬博
采礦技術 2022年4期
關鍵詞:模型
馮占科,毛志浩,劉志成,萬博
(國家能源集團國能網信科技(北京)有限公司, 北京 100096)
0 引言
礦用卡車運輸是露天礦運輸系統中重要的運輸方式之一,對露天礦的生產成本具有較大影響,國內外露天礦研究表明,卡車運輸成本占總成本的25%~45%。國內專家學者對卡車運距進行了研究,周玉民通過建立數學模型以及實踐歸納出載重汽車的合理運距范圍,從而實現了長遠規劃的經濟效益最大化[1]。安太堡露天礦對原煤運輸系統進行了改造,縮短了其運輸距離,大大降低了生產成本[2]。伊敏露天礦通過建立數學模型和計算,總結出露天礦自卸汽車運輸的合理運距范圍,并通過對伊敏露天礦現有數據的計算、總結和分析,得出了載重能力較大的卡車具有較低的噸公里運輸成本和較高的運輸效率的結論[3]。王建光等提出了一種基于三角剖分原理的采剝加權平均運距計算方法,實踐應用表明,該方法能顯著提高運距計算的準確性,對露天礦山企業的生產成本控制具有重要意義[4]。柴森霖等分析了卡車調度優化準則及影響調度效果的因素,用計算機仿真事件步長法模擬了裝運環節[5]。白潤才研究了單斗—卡車工藝實時調度優化決策系統,并提出了一種設計思路,即露天礦分時段卡車實時調度系統,有助于對調度過程進行優化[6]。顧清華等基于各裝載、卸載點間的多條運輸路徑和生產任務,建立了綜合成本最小的低碳條件下卡車運輸優化模型,在實際應用中能有效減少運輸成本,減少耗能和碳排放[7]。柴森霖等建立了路徑優化模型,并用遺傳算法得到能耗較低的最優化路徑,克服露天礦以等效運距為權重進行路徑優化的不可行性[8]。
上述研究對露天礦運距的優化和智能運輸調度提供了思路,但是并未實現如何解決露天礦卡車運距計算不準確的問題。研究發現,露天煤礦采剝區域變化頻繁、道路復雜多變和網絡盲區等因素使露天礦卡車運距存在漂移和準確性較低的現象。現階段露天礦卡車運距不準無法為智能調度提供依據,也無法作為計算卡車司機工作量的依據,因此部分單位選擇按月對司機的運距進行手動統計并結合產量對司機進行考核,人工統計的工作量較大,也有部分單位僅僅通過產量對司機進行考核,忽視了運距的作用。
隨著露天礦智能化建設的推進,智能運輸調度系統實現了車鏟智能調度,其核心是在效率最優原則下實現最小的運距,準確的運距不僅僅為智能運輸調度提供依據,也可實現用運距和產量對卡車司機進行綜合考核,解決露天礦實際問題并最終促進露天礦管理模式的改變。
1 綜合運距
露天礦的生產流程包括剝離、采煤、地面生產 和輔助生產等環節,運距自動糾偏算法主要涉及剝離和采煤中的運輸過程。露天礦的典型生產工藝如圖1所示。
露天礦開采工藝主要為單斗—汽車工藝,即單斗電鏟采裝煤礦或剝離土方、礦用卡車運輸、破碎站和排土場進行物料卸載。礦用卡車是連接電鏟和卸載點之間的橋梁,形成了露天礦的生產運輸線。露天礦的生產能力主要指的是運輸能力,露天礦的運輸直接成本和間接成本占生產總成本的40%以上。露天礦運距可直接反應運輸成本,同時運距也可以衡量運輸效率,因此運距是露天礦的核心生產指標之一。
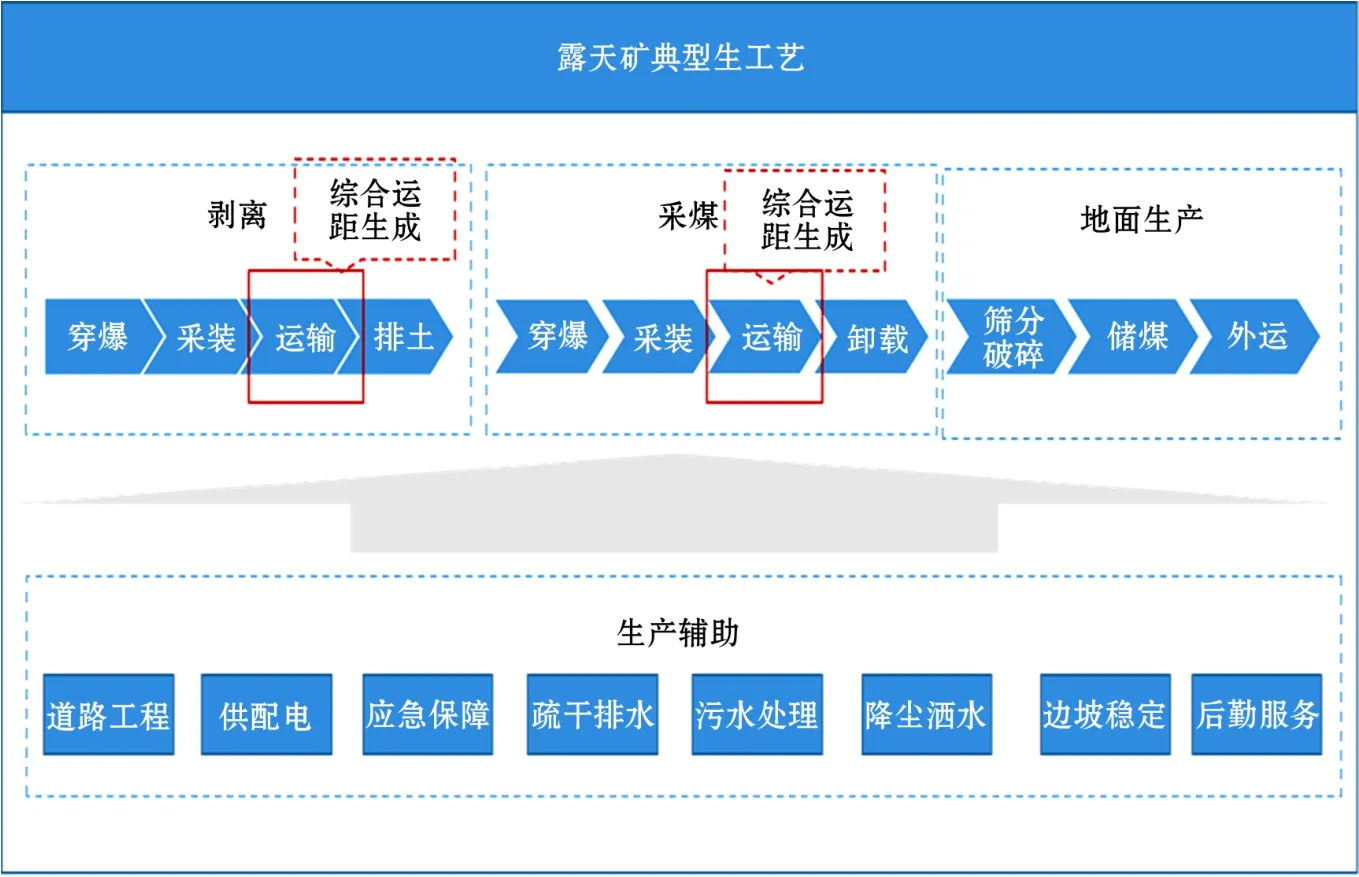
圖1 露天礦典型生產工藝
智能運輸調度系統中車載終端是一種安裝在露天礦運輸卡車上的專用計算機,由衛星定位系統、中央微處理機、顯示屏、觸摸屏、接口系統和電源幾部分組成。露天礦通過GPS信號實時計算單趟運距,即通過卡車裝完狀態下GPS信號的坐標和卡車卸完狀態下的GPS信號坐標,加載該時間段內中間全部的GPS信號,最終確定卡車的單趟運距,其單趟運距的詳情如圖2所示。
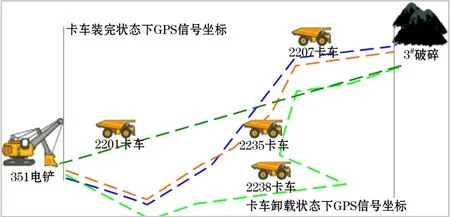
圖2 露天煤礦卡車單趟運距示意
由圖2可以得出,相同支路上卡車的綜合運距在理論上是一致的,由于礦用卡車的GPS信號會出現跳躍,導致不同的礦用車輛單趟運距相差較大。在實際生產過程中不同卡車在支路上的綜合運距相差比較大,因此需要將支路上的綜合運距進行動態的固定,即在某一時段時間內支路的運距是相同的,在不同時間段內運距是變化的。
本文將支路中不同卡車單趟運距輸入模型中,系統自動剔除異常值點和極端異常值點。將有效數據值擬合成正態分布得到期望值,并將期望值賦值給該支路的綜合運距值,即該支路上的不同卡車單趟運距均與綜合運距相同。某班次卡車的總運距如式(1)所示:
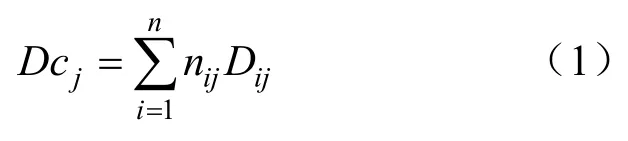
式中,Dcj為礦用卡車在j時間段的運距值;Dij為支路i在j時間段的綜合運距值;nij為在j時間段內支路i運行的次數。
2 綜合運距建模
2.1 數據來源
本文選擇1號和2號露天煤礦為研究對象,2號露天礦的卡車均安裝智能運輸調度車載終端,終端通過GPS信號計算卡車的重運和空運運距,通過卡調系統可記錄卡車的運距。1號礦和2號礦的智能運輸調度系統已平穩運行,經過長時間驗證后發現該方法會因為斷網、信號漂移等因素使部分數據失真,但是大部分的數據質量相對較高,因此項目中選用的模型數據和驗證數據來源于1號和2號露天礦。
2.2 模型選擇
智能運輸調度系統計算的運距存在漂移和缺失等不準確的情況,需要將數據進行清洗以提高數據的質量。目前在礦區采用手工清理的方式去掉異常數據,統計工作量十分巨大,因此需要通過系統自動去除異常數據以減少工作量,提高工作效率。目前清洗數據方法有箱線圖法、聚類分析、去重分析、降噪分析、回歸建模和正態分布的離群點檢測等方法。單趟運距值是離散型,異常值通常是離群點,因此初步確定使用箱線圖法和正態分布的離群點檢測法對數據進行篩選,達到清洗的效果。
2.2.1 箱線圖檢測法
箱線圖(Box-plot)又名箱形圖或盒須圖[9],是一種顯示數據分散情況的統計圖,其篩選方法實際上是利用數據的分位數來識別異常點。該方法主要用于反映原始數據的分布特征,也可以比較多組數據的分布特征。箱線圖的繪制方法是:首先在一組數據中找出其上邊緣、下邊緣、中位數和兩個四分位數;然后,連接兩個四分位數以繪制箱體;最后將上下邊緣與箱體連接,中位數在箱體的中間。其原理如圖3所示。
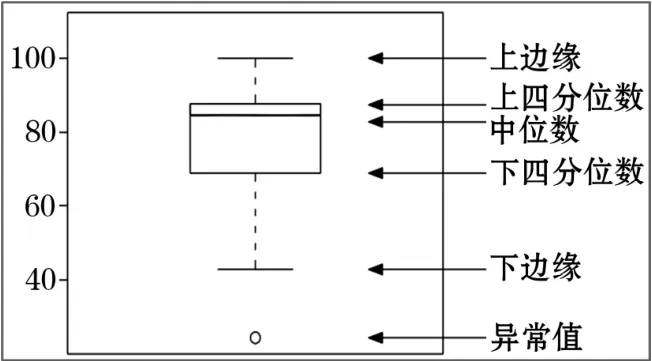
圖3 箱線圖法原理
圖3中的下四分位數是指數據的25%分位點的對應值(Q1);中位數為數據的50%分位點的對應值(Q2);上四分位數則為數據的75%分位點的對應值(Q3);上邊緣值的計算公式為Q3+1.5(Q3-Q1);下邊緣值的計算公式為Q1-1.5(Q3-Q1)。其中,Q3-Q1表示四分位差。采用箱線圖識別異常值的判斷標準是:當變量的數據值大于箱線圖的上邊緣值或小于箱線圖的下邊緣值時,就可以認為這樣的數據點為異常點。所以,基于箱線圖可以定義某個數值型變量的異常點和極端異常點,它們的判斷標準見表1。通過箱線圖法進行判斷后,可判斷出異常值的編號和異常值數據,實現數據清洗的目的。

表1 箱線圖法異常值判別標準
2.2.2 正態分布的離群點檢測法
由正態分布的定義可得,數據點落在距均值正負1倍標準差內的概率為68.27%;數據點落在距均值正負2倍標準差內的概率為95.45%;數據點落在距均值正負3倍標準差內的概率為99.73%,即3倍的標準差原則(可忽略3倍的標準差以外的數據值對整體的影響)。標準正態分布的概率密度如圖4所示。
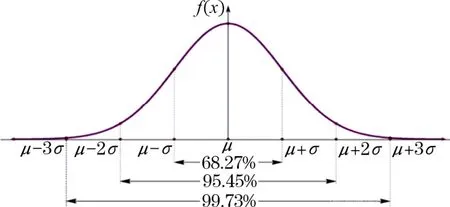
圖4 標準正態分布概率密度
數據點落在距均值正負2倍標準差之外的概率不足5%,屬于小概率事件,將這樣的數據點稱為異常點。同理,如果數據點落在距均值正負3倍標準差之外的概率更小,可將這些數據點稱為極端異常點。異常點的判別標準見表2。通過正態分布的離群點檢測法進行判斷后,可判斷出異常值的編號和異常值數據,實現數據清洗的目的。

表2 異常點的判別標準
上述兩種方法均可實現對運距數據進行清洗的目的,由于相同的支路內的單趟運距是互相獨立的,且理論上是無窮的。在實際上相同裝卸點之間的數據量相對較大,運距數據互相獨立,根據大數定律可確定運距的數據分布滿足正態分布,是自然界中最常見的數據分布,具有普適性[10],因此本項目中選用正態分布的離群點檢測法對數據進行清洗。
2.3 數據建模
根據上述分析選擇正態分布的離群點檢測法對數據進行清洗。支路ID是將電鏟ID和卸點ID進行組合形成的,選取不同支路之間的重運單趟運距作為輸入值訓練模型;待模型訓練成功后可得到不同支路上的異常值;將異常值點去除后進行正態分布得到的期望值,即為該支路上卡車的綜合運距值。將數據導入系統后,系統自動統計出不同支路的樣本數、異常值數、期望值和全部數據,并可查看異常值點的詳情數據。
系統根據不同支路的數據分布可得到數據分布的散點圖,并借助于兩條水平參考線識別異常值或極端異常值,如圖6所示。圖6中顯示散點值和偏離均值正負2倍標準差的參考線,橫軸是將數據按時間進行排序,縱軸是運距值,通過運距值的分布可直觀地查看到異常值點和數據的分布特征。經過分析后明確運距值符合標準正態分布。
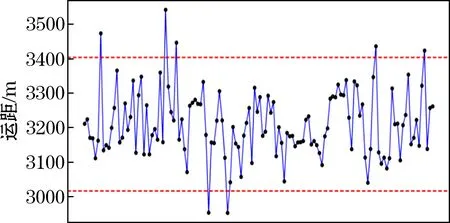
圖5 運距分布散點
由于異常值使運距不準,依據剔除異常值后的數據繪制正態分布直方圖,如圖6所示。圖6中所示的是支路上運距分布,該正態分布圖會根據數據的數量進行改變,數據量越大 正態分布越標準,當數據量為無窮時即為標準正態分布。
2.4 模型驗證
不同支路的運距是動態變化的,當班內支路的運距的變化是可忽略的,因此在驗證時數據的選擇不能跨度很大,通常以一天三班或兩天六班為一個數據周期。在調度作業系統中做生產月度計劃時會對運距進行計劃,因此選擇生產月度計劃后續兩天的數據來訓練和驗證模型。此次隨機選取1號礦和2號礦中6個班次的運距作為測試數據代入模型,通過對比得到的期望值與實際值進行驗證,驗證結果見表3。通過該模型得到的綜合運距與實際運距的誤差率絕對值在0.22%~5.91%之間,在合理的范圍內,可滿足露天礦的生產要求。
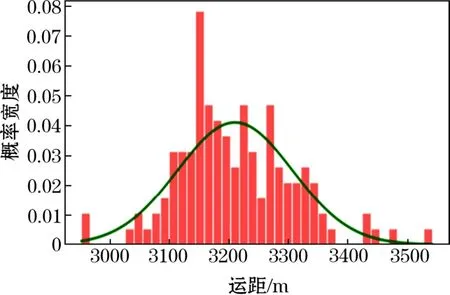
圖6 運距的正態分布直方圖
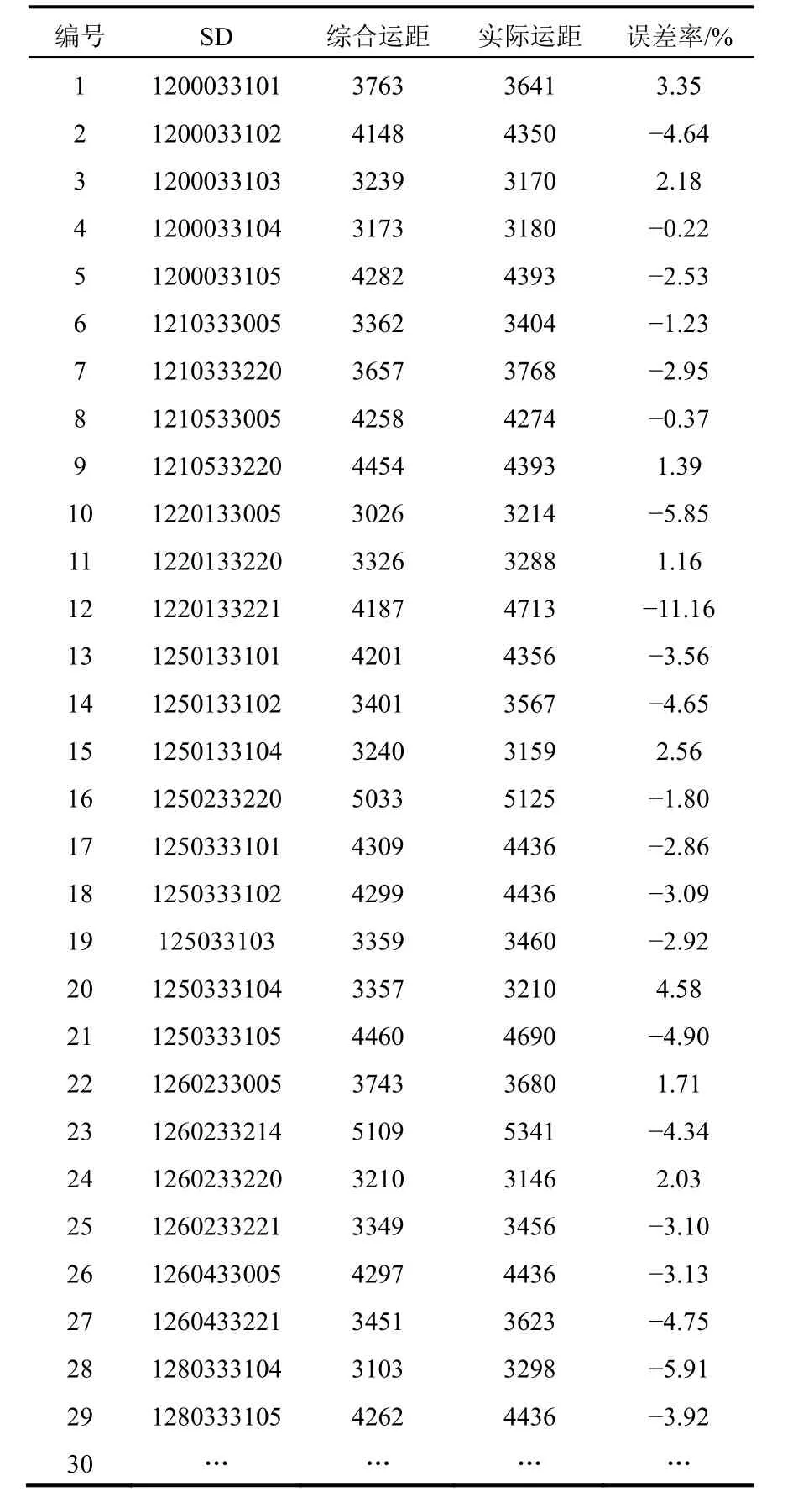
表3 綜合運距的驗證
3 實證研究
3.1 應用效果
將上述模型應用到某露天礦的智能運輸調度系統中對實時采集運距進行糾偏,將運輸卡車的運距數據自動采集到系統中,通過系統模型進行運算,得出綜合運距值。綜合運距值作為卡車調度中核心指標,對指導生產有重大意義,同時改變了露天礦中生產計量模式。
3.2 經濟效益
根據實際情況進行統計分析,該露天礦每月份所有卡車重運趟數為49 980車以上,傳統方式礦區需要對卡車重運趟數進行人工統計,剔除掉無效數據,統計時間比較長,每月的統計工作用時至少不低于7 d。通過系統自動生成綜合運距,可以大大減少卡車運距測量的誤差率,將按車次統計運輸卡車的重運趟數轉變為按里程統計運輸卡車的重運趟數,減少了人工統計的工作量,節約人力成本,產生一定的經濟效益。
露天礦的傳統方法是將卡車運輸的產量作為司機考核的核心依據,其原因是卡車運距的準確性不高,無法作為考核依據。系統自動糾偏運距后可改變傳統的考核方式,綜合運距和卡車運輸產量來考核司機的工作量和計算工資,同時精準的運距可與露天礦的燃油系統進行結合,得到精準的燃油單耗指標,為露天礦精細化管理提供依據。
4 結論
本文根據露天礦運距的實際情況進行研究,選取1號礦和2號礦不同裝卸點之間的運距來訓練模型,模型可自動識別出異常點和極端異常點,并將異常點剔除,將有效數據生成運距的正態分布直方圖,將期望值作為支路的綜合運距。選取與月度生產作業計劃同期的6個班次的運距值并代入訓練好的模型后,將得到的綜合運距與實際運距進行對比,驗證了模型的準確性,通過該模型得到的綜合運距與實際運距的誤差率絕對值在0.22%~5.91%之間,在合理的范圍內可滿足礦區的生產要求。
將此模型應用到某露天礦中,系統自動生成綜合運距,可以大大減少卡車運距測量的誤差率,減少人工統計的工作量,節約人力成本。同時將按車次對司機考核的傳統方式轉變為按運距和卡車連輸產量相結合的新方式,為露天礦精細化管理提供了支撐,符合礦區作業生產過程中的要求,并能為實際生產帶來一定經濟效益。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
