基于深度學習的SAR目標識別DSP設計*
2022-08-20 01:39:20施慧莉李大亮
計算機工程與科學 2022年8期
何 濤,施慧莉,李大亮
(中國航空工業集團公司雷華電子技術研究所,江蘇 無錫 214063)
1 引言
傳統SAR(Synthetic Aperture Radar)目標識別需要人工憑借經驗進行特征提取與特征選擇,具有一定的主觀性和盲目性,難以保證識別的有效性,特別是現代作戰環境下機載SAR目標場景復雜多變,傳統目標識別算法在不同場景下的識別效率會受到干擾及目標特性的嚴重影響。近些年來,得益于大規模的帶標簽數據集PASCAL VOC、ImageNet和MS COCO的公開以及人工智能硬件平臺的發展,基于卷積神經網絡CNN(Convolutional Neural Network)的目標識別取得了重要突破,并成功擴展到了遙感圖像領域,為SAR目標識別提供了新的解決思路。
目前主流的CNN目標識別模型可以分為2大類:two-stage識別模型和one-stage識別模型。two-stage識別模型的典型代表是基于候選區域的R-CNN系算法,如R-CNN、Fast R-CNN和Faster R-CNN[1 - 3]等;經典的two-stage識別模型一般都比較耗時,這是由于在two-stage識別過程中,需要產生大量的候選區域,這些候選區域的處理占用了大量的處理時間。YOLO(You Only Look Once)[4]創造性地提出了one-stage方法,即直接利用深度CNN網絡得出目標的位置和所屬的類別。但是,YOLO模型存在物體識別精度低、對于小物體識別效果不好的缺陷。后續的YOLO-v2[5]模型和YOLOv3[6]模型通過加入批歸一化BN(Batch Normalization)層、提升輸入層分辨率、預測位置偏移值、殘差單元、多尺度識別等措施來提升小目標識別準確率和識別速度。卷積神經網絡在CPU和GPU平臺上已經有多種成熟的實現框架,例如Google開發的TensorFlow[7]框架,伯克利大學的C開源框架caffe[8],基于YOLO系列模型的C開源Darknet框架等。這些實現框架在GPU端的運行實現大都采用NVIDIA cudnn庫進行加速,在CPU的實現采用openmp方式進行多線程加速,因此深度學習CNN的主要加速運算平臺大多選用GPU或FPGA硬件平臺。基于DSP與GPU和FPGA在并行運算上的天然劣勢,傳統的深度學習框架(TensorFlow、caffe和keras等)不支持DSP平臺。
本文主要從基于深度學習的SAR目標識別在機載DSP平臺實時處理需求出發,通過構建CNN在多核DSP的運行生態,完成了多核DSP(C6678)平臺上的YOLOv3-TINY(YOLOv3網絡的輕量級模型)網絡的設計與實現,并進行了實測SAR數據驗證。雖然深度學習網絡在DSP的實時性上和GPU相比還有較明顯的差距,但其能夠滿足機載SAR的實時處理需求。
2 軟硬件簡介
2.1 TI C6678簡介
TMS320C6678[9]是TI公司基于KeyStone多核處理器架構的多核DSP,芯片集成了8個C66X DSP內核,內核頻率可達1.25 GHz,芯片處理能力強,外設功能豐富,可以廣泛地應用在通信、雷達、聲納、火控和電子對抗等領域。單C6678片內配置8個TMS320C66xTMDSP核,每個DSP單核內存配置512 KB核內高速緩存,8核共享4 MB SRAM高速內存;同時C6678提供了一個64位的DDR3外存接口,能以800 MB/s、1 033 MB/s、1 333 MB/s和1 600 MB/s的速率進行傳輸操作,數據率最高可至大約12.8 GB/s,可尋址空間為8 GB。
2.2 YOLOv3深度學習模型簡介
YOLOv3模型是YOLO系列網絡的第3個版本,是目前工程界首選的目標識別模型之一。相較于之前的版本,該版本增加了殘差單元、特征金字塔網絡和多尺度識別來進一步提升識別準確率,尤其是小目標的識別準確率。具體來說,YOLOv3主要有以下特點:(1)采用了Darknet53骨干網絡;(2)包含了多個殘差單元;(3)利用3個尺度的特征圖來共同進行最后的預測,提升了目標識別準確率。圖1給出了YOLOv3模型的網絡結構圖,其中CBL為YOLOv3模型中廣泛采用的卷積層,是卷積層+BN層+LeakyReLU激活函數的組合;殘差單元用Res_n*m表示,n表示第n個殘差單元,m為該殘差單元的重復利用次數,殘差單元的使用保證了網絡深度,提升了網絡的特征表達能力。
3 基于C6678的卷積神經網絡設計
常用的卷積神經網絡實現框架(TensorFlow、caffe和Darknet等)主要運行平臺為GPU和CPU,且不支持DSP,因此本文主要進行了多核DSP平臺上的可定制卷積神經網絡設計。鑒于復雜卷積神經網絡的訓練時間遠大于預測時間,可以通過高性能GPU服務器對目標數據訓練后,將訓練后的網絡權重輸入到DSP硬件平臺進行前向預測。因此,本文DSP平臺上的卷積神經網絡的卷積層設計不考慮反向預測,只進行卷積層的前向預測。
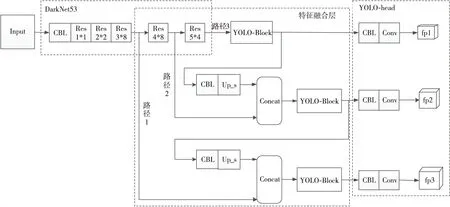
Figure 1 Network structure of YOLOv3 model圖1 YOLOv3模型網絡結構
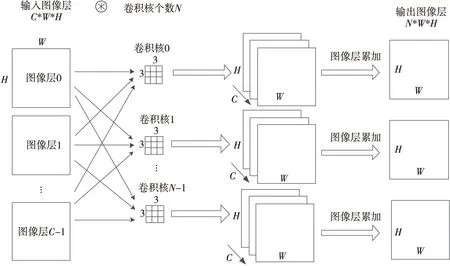
Figure 2 Schematic of convolutional layer processing圖2 卷積層處理原理
3.1 卷積層設計
3.1.1 并行計算策略
卷積層處理的主要原理如圖2所示,圖1中的示例為多通道圖像和不同的卷積核進行卷積,其中卷積層的輸入圖像尺寸為(C,W,H),C為圖像通道數,W為輸入圖像寬度,H為輸入圖像高度,N為卷積核個數。在實際卷積處理中,單個卷積核分別和每個圖像輸入進行卷積后還需進行多通道加和處理,等于單個卷積核和多通道輸入卷積處理后的圖像輸出尺寸為(W,H),N個卷積核的卷積層處理輸出為(N,W,H)。
根據卷積層處理特點及C6678的多核獨立計算特性,本文設計了如下2種卷積層并行計算策略:
(1)策略1:基于獨立卷積核計算的并行策略。
由卷積層的計算原理可知,不同卷積核和輸入圖像的卷積計算是完全獨立的,結合C6678的多核特性,該并行策略可以設計為:不同C6678核分配不同的卷積核來完成單個卷積層處理時的并行計算。
(2)策略2:基于圖像分塊的并行策略。
由卷積層的計算原理可知,每個卷積核需要遍歷每個圖像的不同區域位置進行卷積處理,同時多通道圖像經過一個卷積核處理后,還需要進行累加生成一幅圖像。從該處理過程可以看出,多通道圖像不同區域參與的卷積計算是完全獨立的。因此該并行策略設計為:將輸入多通道圖像劃分為不同的數據塊,每個C6678核獨立完成多通道不同圖像塊區域的卷積運算。
以上2種并行計算策略從并行計算的實現上都是完全可行的。但是,C6678的多核及存儲特性使每個核的獨立緩存上很難容納每個卷積層的輸入多通道圖像,只能存放于C6678的共享4 MB緩存中。策略1中每個獨立卷積核在計算時都需要讀取一次多通道圖像數據;而策略2因為是基于圖像塊進行的并行任務,每個C6678核讀取不同的圖像數據塊,讀取到的圖像數據塊可以參與N個卷積核計算。因此,策略1和策略2相比,雖然總的計算能力一致,但輸入圖像數據讀取時間增加了N倍。綜合考慮,本文采取策略2作為卷積處理的并行計算策略。
3.1.2 卷積束核心運算
在NVIDIA的深度學習庫cudnn、Darknet和caffe等實現框架中,卷積運算都是將卷積操作轉換為矩陣乘操作GEMM(GEneral Matrix Multiplication),由于GPU和CPU的高速內存在處理數據時沒有容量制約,所以矩陣乘操作是這些深度學習庫實現快速卷積的主要方式。但是,多核DSP高速緩存資源有限制,采用矩陣乘方式,無論是核內高速緩存還是多核共享緩存C6678都無法滿足計算存儲需求,參與計算的數據只能存放在DDR3上,導致計算效率急劇下降。因此,需要重新設計適配多核DSP的卷積運算。
考慮到多核DSP處理器有限的快速計算內存資源,本文針對性地提出了卷積束計算概念。卷積束可以理解為收集參與單個卷積核運算的多個圖像通道的數據作為單個卷積運算的輸入,卷積束運算可以簡化成卷積束與卷積核的乘累加。因此,在嵌入式平臺上,本文拋棄常用的深度學習框架中將卷積計算轉換為矩陣運算的思路,提出將單個卷積束運算作為多通道圖像卷積處理的一個基本計算核心。由此整個卷積層的計算抽象為遍歷多通道圖像依次得到不同的卷積束,每個卷積束依次和不同卷積核進行計算,不同的卷積核計算結果分別存儲于對應的輸出圖像層。單個卷積束運算如圖3所示,基于卷積束的卷積層處理控制流程如圖4所示。
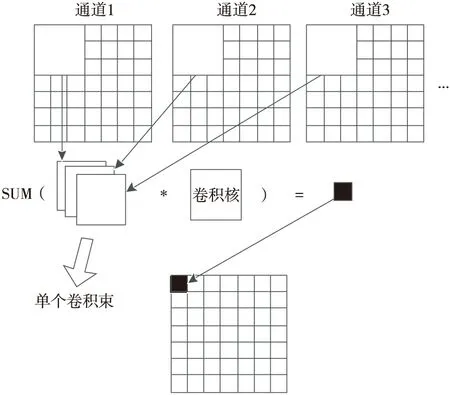
Figure 3 A single convolutional beam operation 圖3 單個卷積束運算

Figure 4 Flow chart of convolutional layer processing control based on convolutional beam圖4 基于卷積束的卷積層處理控制流程
3.2 DSP平臺上的深度學習框架
鑒于DSP平臺不支持常用深度學習框架,本文對多核DSP平臺上的深度學習框架進行簡易開發,使其可以支持常用的卷積神經網絡。多核DSP平臺上的開發框架主要包含以下主要內容:
(1)主要卷積神經網絡運行層支持,以組件方式進行配置運行。這些運行層包括卷積層、池化層、上采樣層、連接層、殘差層處理、YOLO檢測層處理。
(2)深度學習網絡配置分析處理:
- 結合嵌入式資源特性的網絡內存動態分配;
- 結合嵌入式資源特性的處理組件配置分析。
(3)訓練權重參數的加載及分析。
(4)前向預測推理。
本文目前的應用工作場景如下所示:
(1)服務器訓練。
通過桌面服務器進行深度學習網絡訓練,訓練完成后,保存訓練的權重參數。
(2)DSP預測推理。
將訓練后的權重導入到DSP外部存儲器,在DSP平臺上運行本文的處理框架進行前向預測推理。
通過以上工作,本文完成了深度學習網絡在多核DSP平臺上的基本生態建設,能夠使多核DSP按照桌面計算機的通用設置運行深度學習網絡。
3.3 調度設計
本文針對卷積神經網絡在C6678平臺上的運行設計了2個輸入接口:圖像數據輸入接口和目標識別類型接口。收到圖像數據后和目標檢測類型數據后,根據目標識別類型選擇不同的網絡架構并構建網絡,生成該架構下的網絡處理隊列,并同時進行權重數據文件分析,解析每個處理層需要的權重參數在外部存儲器內的偏移地址。同時,DSP主處理核啟動主處理進程,遍歷網絡組件處理隊列,并運行每個組件的前向預測函數;每個組件層在多核DSP平臺上的并行處理調度隱藏在每個組件層的前向預測函數中。網絡架構及調度流程如圖5所示。
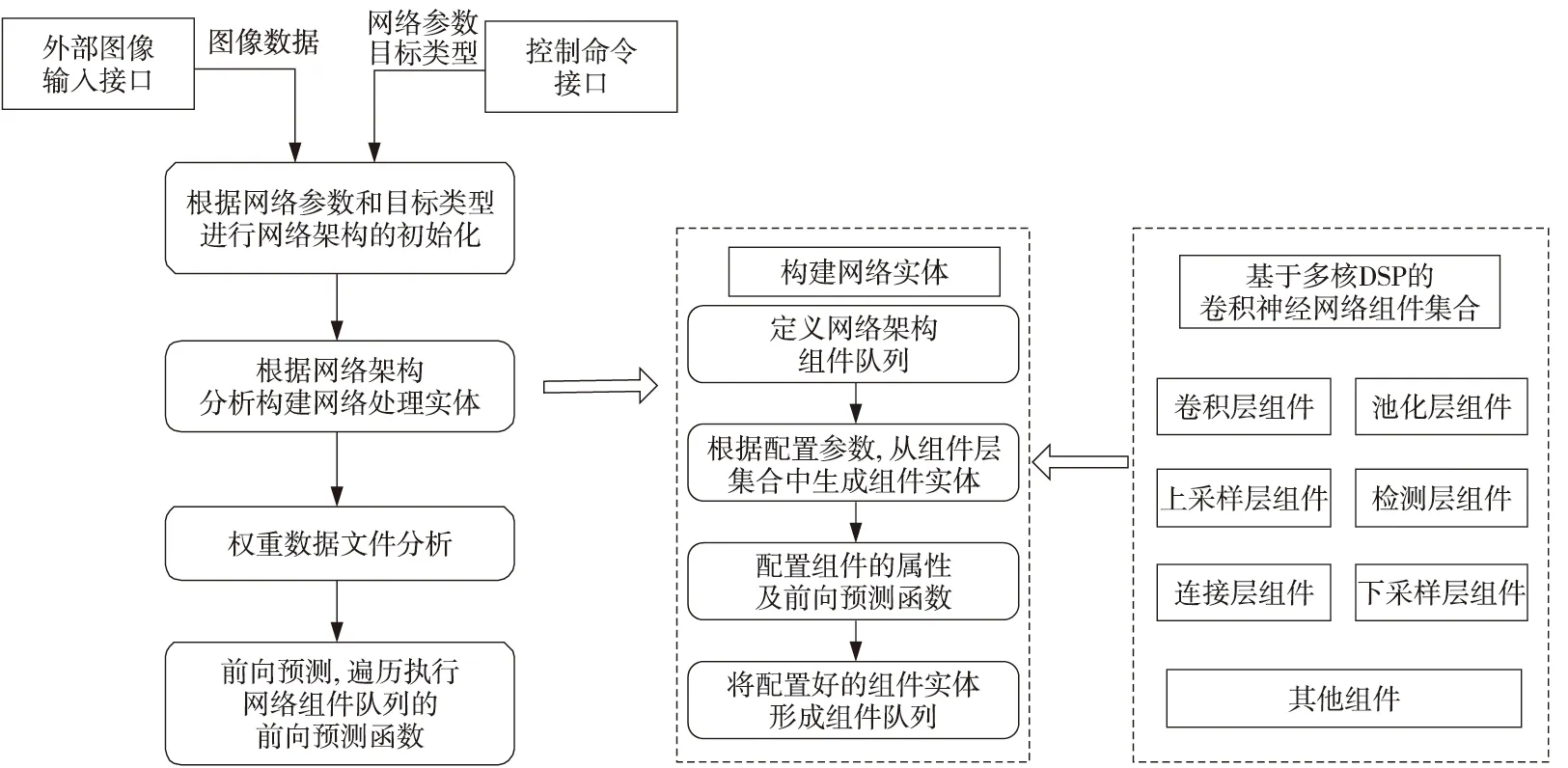
Figure 5 Scheduling flow chart of convolutional neural network for SAR target recognition based on C6678圖5 基于C6678的SAR目標識別卷積神經網絡調度流程圖
4 實驗驗證
4.1 運行平臺及運行時間統計
依據第3節所述的卷積神經網絡的設計內容,通過軟件優化設計與測試時,考慮YOLOv3網絡對多核DSP平臺資源的需求較高,其在C6678平臺上運行會受到較大限制,因此本文最終選擇YOLOv3-TINY網絡在C6678平臺上進行實時并行處理,硬件資源為單片C6678。
YOLOv3-TINY是YOLOv3的簡化版,相對YOLOv3模型,總網絡層數減少到了31層,但保留了殘差單元和多尺度識別,在網絡輕量化和識別性能上取得了較好的折衷,其中卷積層占16層,輸入為YOLOv3系列網絡的標準輸入尺寸416*416。在實際處理時大圖通過平滑抽取至(416,416)再輸入到深度學習網絡進行識別處理。網絡架構及運行時間如表1所示。通過多次統計,YOLOv3-TINY網絡在單片C6678上的識別處理時間平均為1 s左右。表1中class參數為識別目標類型數量,X為識別前總共預測的參數數量。
4.2 實驗結果分析
目前機載SAR圖像的典型目標相對光學圖像存在樣本量少的問題,坦克、飛機等戰術小目標圖像源很難獲取,因此在本文實驗中,SAR圖像樣本選擇獲取難度較低的機場目標樣本進行訓練。SAR機場數據集主要包含4種分辨率(0.3 m,0.5 m,1 m和3 m)共400幅圖像,其中無機場圖像占比10%,訓練集占比80%,驗證集占比20%。
訓練參數采用YOLOv3-TINY網絡標準模板參數,由于訓練樣本數較少,為了避免過擬合情況,訓練批次數在該樣本集上最大不超過30 000次。訓練平臺為地面GPU服務工作站,訓練完成后將YOLOv3-TINY網絡權重導入C6678 的DDR3存儲器。
由于數據集包含了多個機載平臺的實時SAR圖像,平臺的差異性(分辨率、輻射功率、作用距離和波形差異等)導致不同源的SAR圖像在質量、量化和對比度上有較大的區別,從而會影響目標識別對不同SAR圖像數據源的識別能力。本文通過實驗對驗證集進行測試,機場目標識別準確率為84%,實驗結果驗證了YOLOv3-TINY網絡對于少樣本訓練集及不同平臺SAR圖像的識別泛化能力,基本能夠滿足需求方對機載平臺的識別準確率要求。
圖6為8幅不同分辨率的SAR樣本圖像在C6678平臺的機場識別效果圖,這些樣本來源于不同機載雷達平臺,標注機場類的識別框尺寸在不同源圖像上會有較大的差別,這主要是因為對于機場類的大尺寸的目標識別而言,不同平臺的SAR圖像其目標標注范圍內會存在大量的其他形態信息,對卷積神經網絡的學習記憶會有一定程度的影響;訓練端對于機場類目標的位置信息標注主要是人工參與,其人工參與的機場標注范圍也會對測試結果產生一定程度的影響。
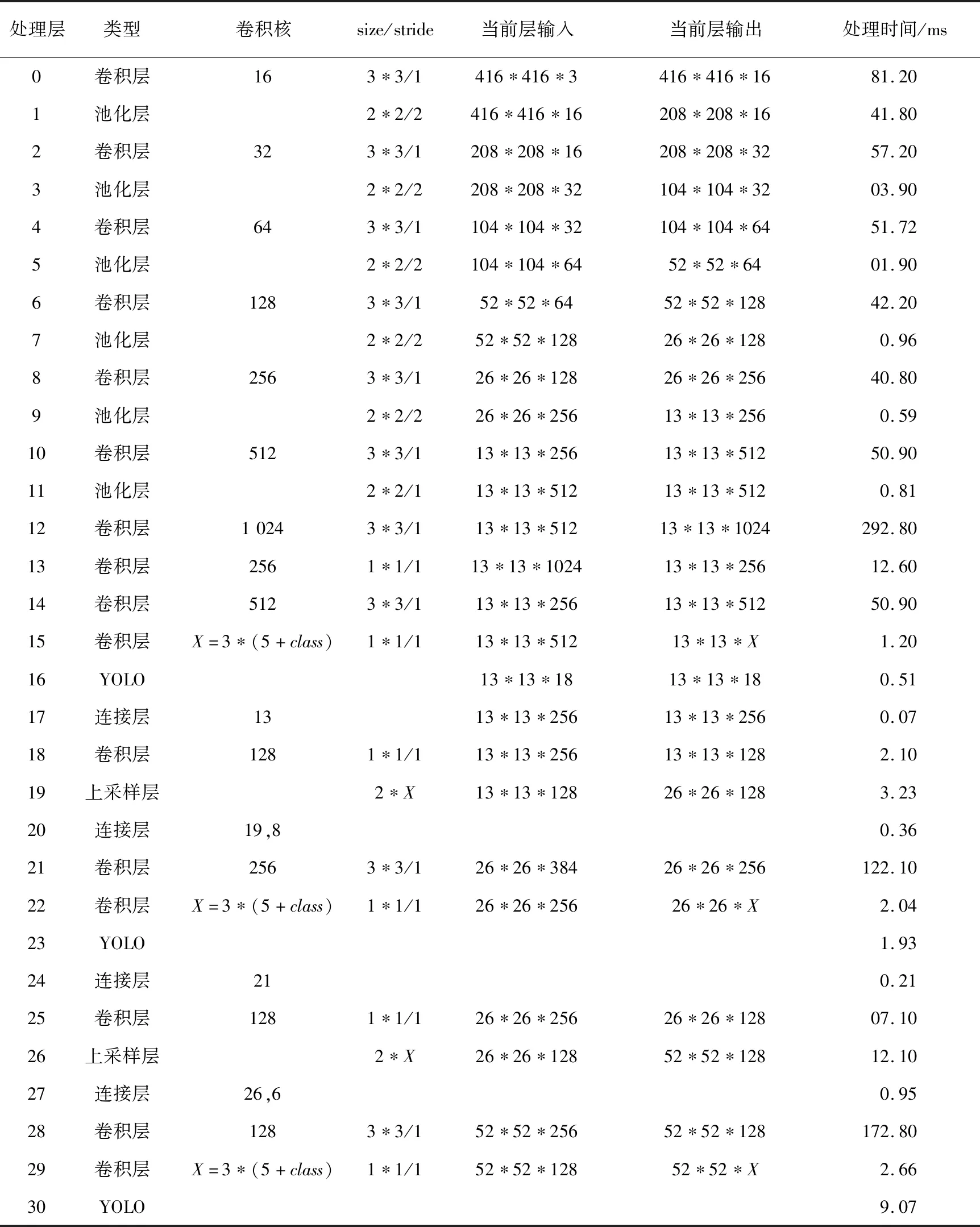
Table 1 Running time statistics of YOLOv3-TINY network architecture 表1 YOLOv3-TINY網絡架構運行時間統計

Figure 6 SAR airfield target recognition results圖6 SAR機場目標識別結果圖
YOLOv3-TINY網絡在DSP和GPU平臺上的檢測結果基本一致,但FPS值只有1,雖然和該模型在GPU的FPS值(大于100)相比,實時性能下降很多,但考慮到機載SAR的圖像周期為秒級,幀率大都小于1,所以在類C6678平臺上進行基于深度學習的機載SAR大型目標識別能夠滿足實時性需求。
5 結束語
本文結合C6678的多核DSP特性,通過設計卷積神經網絡在多核DSP上的運行架構及主要處理層,完成了YOLOv3-TINY網絡模型在C6678平臺上的實測運行。本文主要出發點是在DSP平臺沒有成熟的深度學習開發生態的條件下,驗證了多核DSP平臺上運行簡易深度學習網絡的可行性。本文設計的深度學習簡易框架在C6678多核DSP的運行性能能夠滿足目前機載SAR圖像目標識別的實時性需求,完成了基于C6678多核DSP的卷積神經網絡的設計實現。考慮到機載平臺的國產化需求較強,本文方法可以應用于未來類C6678的更高性能國產多核處理器上。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
