基于多尺度優化感知網絡的口罩檢測方法*
2022-08-20 01:39:24趙緒言
計算機工程與科學 2022年8期
茍 淞,趙緒言,侯 松,李 威
(西南交通大學計算機與人工智能學院,四川 成都 611756)
1 引言
新冠肺炎(COVID-19)疫情給全世界人民的生活造成了嚴重的危害,在各國政府和醫療系統的共同努力下,新冠肺炎疫情正逐步得到控制。根據中華人民共和國國家衛生健康委員會疾病預防控制局發布的信息可知,口罩是預防呼吸道傳染病的重要防線,可以降低新型冠狀病毒感染風險。口罩不僅可以防止病人噴射飛沫,降低飛沫量和噴射速度,還可以阻擋含病毒的飛沫核,防止佩戴者吸入[1]。科學佩戴口罩,對于新冠肺炎、流感等呼吸道傳染病具有預防作用,既保護自己,又有益于公眾健康[2]。
因此,智能口罩檢測成為了一項重要的任務,可以督促人們在公共社交場合佩戴口罩,對于維護公眾健康有著重要的意義。然而,基于深度學習的口罩檢測是一項全新的任務,其核心主要是2個方面:一是獲取人臉目標在圖像中的位置信息;二是判斷該人臉是否佩戴口罩。目前口罩檢測的相關研究和方法十分有限。該任務面臨著以下巨大的挑戰:
(1)如圖1a所示,在口罩檢測的應用場景中,首先需要對人臉進行檢測,而人臉具有尺度多變、數量冗大、表情多樣、視角差異、局部遮擋和化妝偽裝等特征,這些特征通常會對檢測方法帶來較大的影響,導致誤檢或漏檢。
(2)如圖1b所示,口罩的外觀具有多樣性,如款式多樣、顏色各異、帶有花紋圖案,且側臉戴口罩特征不明顯等,給口罩檢測算法的設計帶來了困難。并且,當人戴上口罩后,部分面部被遮蓋,也會增加人臉檢測的難度。
(3)如圖1c所示,未正確佩戴口罩(口罩沒有遮住口鼻或置于其他位置等)和面部局部被遮擋,會對口罩檢測造成干擾,容易在戴口罩與未戴口罩兩類間造成混淆。
按照現有的通用深度學習目標檢測方法,口罩檢測任務可以由單階段目標檢測模型或兩階段目標檢測模型來完成。當前通用單階段目標檢測模型有CenterNet[3]、FCOS[4]和YOLOv1[5]等Anchor-Free檢測模型,也有基于Anchor 機制的SSD(Single Shot multibox Detector)[6]、YOLOv2[7]和YOLOv3[8]等檢測模型。通用2階段目標檢測模型中,R-CNN[9]系列模型的檢測效果較為出色,該類模型的推理過程分為2個階段,第1階段通過滑動窗口推測出目標可能的位置坐標,第2階段對預測框進行分類和評估。之后的Faster R-CNN[10]拋棄了傳統的滑動窗口和Selective Search生成檢測框的方法,直接使用RPN(Region Proposal Network)生成檢測框,提升了檢測框的生成速度。然而,上述通用深度學習目標檢測模型都缺乏針對口罩檢測特性的獨有設計,在多尺度感知方面仍有不足,造成檢測效果不夠理想。

Figure 1 Examples of difficulties in face mask detection圖1 口罩檢測困難示例
人臉檢測是口罩檢測的重要組成部分。張修寶等[11]提出的口罩檢測方法具有重要的意義,該方法先進行人臉檢測,再對檢測結果進行戴與未戴口罩分類。近年來,研究人員提出了一批專用的人臉檢測網絡,例如用于人臉檢測與對齊的三級聯CNN(Convolutional Neural Network)[12]網絡MTCNN(Multi-Task Convolutional Neural Network)[13]、單階段人臉檢測器PyramidBox[14]和RetinaFace[15]等。其中PyramidBox基于FPN(Feature Pyramid Network)[16]進行了優化,提出低層級特征金字塔網絡,充分結合高層級環境語義特征和低層級面部特征,能夠單步預測所有尺度的人臉。目前,能夠將高層級特征和低層級特征進行結合,在多尺度上進行感知,并作為專用口罩檢測的方法還非常少。
本文提出了一種多尺度優化感知的口罩檢測方法——PyramidMask。本方法采用ResNet50作為骨干網絡,保證深層的戴口罩人臉的特征能夠被有效地提取;在 FPN思想的基礎上,結合骨干網絡的特性,設計尺度感知網絡和高密度先驗框,增強檢測模型的多尺度感知能力,保證口罩檢測模型在處理不同尺度人臉、口罩時的性能;設計圖像拼接的數據增強方法,增強訓練集中目標的多尺度特征,同時在數量上擴充數據集。上述3個優化點的結合,能夠有效解決口罩檢測所面臨的3個挑戰。本文方法在公開的口罩檢測數據集[17]上進行了測試,相較于基準方法,在未戴口罩和戴口罩的檢測召回率上分別有12.5%和5.4%的提升,在未戴口罩和戴口罩的檢測精確率上分別有4.1%和6.0%的提升;在多尺度檢測實驗中,本文方法的檢測精度也領先于主流的單階段檢測模型YOLOv3和CenterNet,以及兩階段檢測模型Faster R-CNN R50 FPN;然后,通過對原訓練數據進行圖像拼接增強,使得本文方法的檢測精度又有進一步的提升。
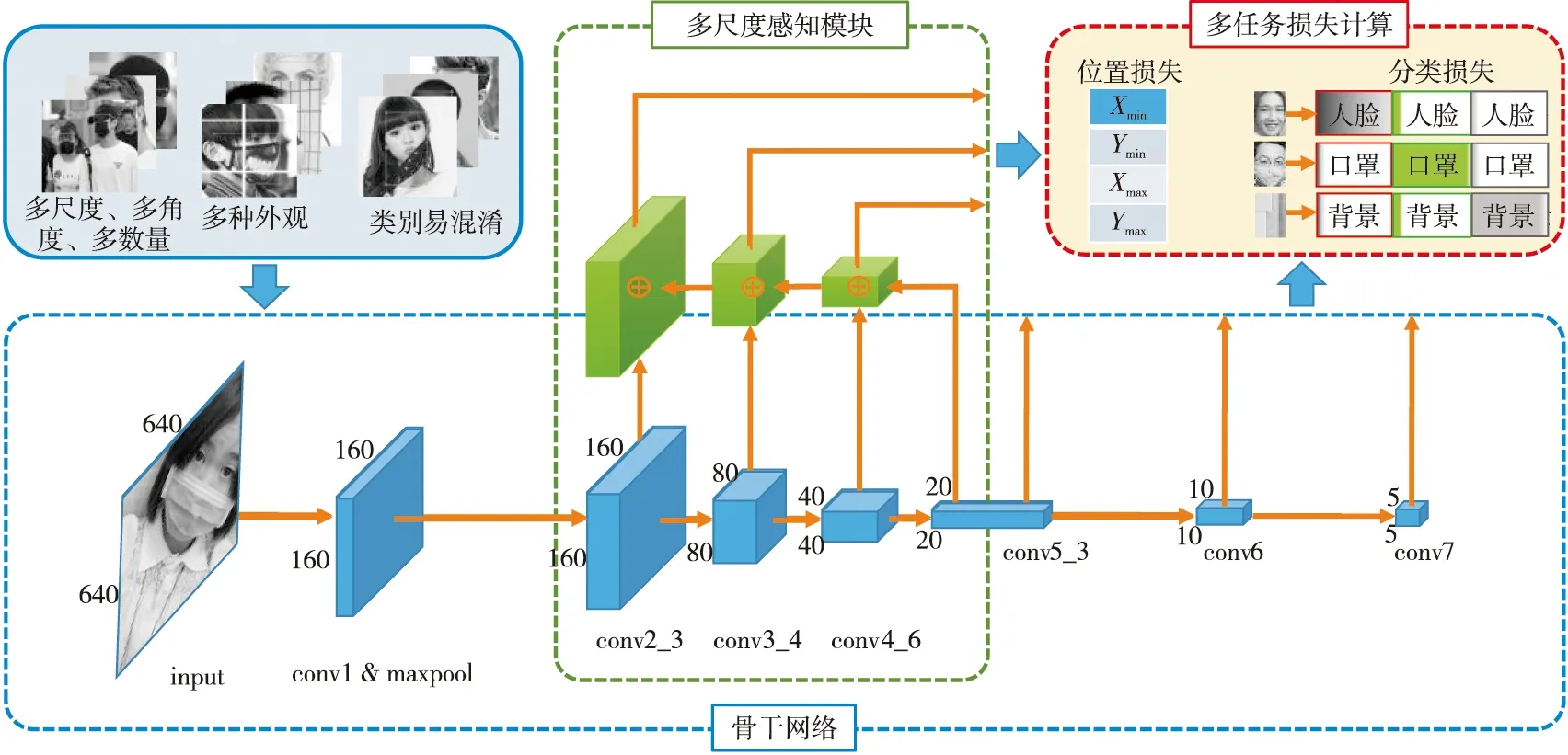
Figure 2 Network structure of PyramidMask 圖2 PyramidMask口罩檢測方法網絡結構
2 PyramidMask口罩檢測方法
如圖2所示,本文提出的PyramidMask口罩檢測方法為一個端到端的單階段檢測模型,由骨干網絡、多級尺度感知模塊和多任務損失計算3個部分組成。使用ResNet50作為骨干網絡,負責特征提取,生成特征圖,提高模型對未戴口罩人臉和戴口罩人臉特征的提取性能;設計多尺度感知優化的尺度感知網絡,提取足夠的淺層圖像信息和深層語義信息,減少特征未對準和細節丟失的影響;損失計算是多任務的,分為位置損失和分類損失2個部分,對尺度感知網絡的每一層輸出計算損失,計算L1范數得到位置損失,計算softmax和交叉熵得到分類損失。PyramidMask每進行一次推理,會輸出2部分信息:一是預測的目標框位置,二是對應目標框的分類置信度。
2.1 骨干網絡
卷積神經網絡CNN利用卷積核與原始圖像或特征映射進行卷積,提取更高層級的特征。但是,研究人員發現,當卷積神經網絡的深度超過19層時,隨著卷積層深度的繼續增加,網絡在訓練集和測試集上的性能卻降低了,這是因為較淺層和較深層的網絡在訓練時的優化難度不一樣,且難度的增長并不是線性的,越深的網絡越難以優化。
ResNet[18]通過引入如圖3所示的殘差塊(Bottleneck Design)在輸入和輸出之間建立了一條直接的關聯通道,從而使得強大的有參層能集中精力學習輸入和輸出之間的殘差。檢測、分割和識別等領域的很多方法都是在ResNet的基礎上完成的。
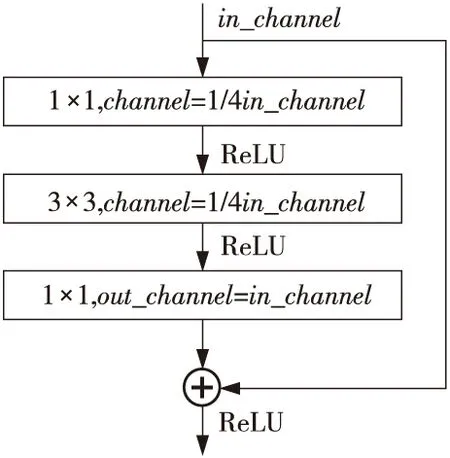
Figure 3 Bottleneck design for ResNet(50/101/152)圖3 ResNet(50/101/152)的殘差塊
本文所提出的口罩檢測方法PyramidMask,使用ResNet50作為骨干網絡,在面對外觀多樣、角度各異的口罩以及人臉時,相較于VGG(Visual Geometry Group)[19]網絡,有著更佳的深層特征提取性能[20],能為后續的尺度感知網絡提供更有效的、自上而下的和最初始的多尺度的語義信息和特征圖。
2.2 尺度感知網絡的設計
人臉、口罩這類尺度多變的目標,對檢測模型的多尺度檢測性能有很高的要求。尤其是針對圖像中像素較少的小尺度目標,在經過逐層卷積操作和下采樣后,在網絡末端,這些小尺度目標的特征會變得更小且更不明顯。骨干網絡對圖像中物體特征進行提取時,淺層網絡分辨率高,提取到的是目標的細節特征,深層網絡分辨率低,提取到的更多是目標的語義特征。例如,SSD、YOLO等模型在增加網絡深度的同時,卻沒有充分利用淺層特征,造成模型對口罩、人臉這類多尺度目標的檢測效果不理想。
針對這一問題,在 FPN思想的基礎上,本文設計尺度感知網絡的核心思路是:
(1)將骨干網絡的淺層細節信息和深層語義信息充分融合,避免細節丟失;
(2)通過高密集的先驗框(Anchor)采樣,保證小尺度的人臉、口罩目標也有高召回率。
設計的尺度感知網絡結構如圖4所示,左邊的網絡自底向上是骨干網絡ResNet50的正向傳播過程,特征圖經過卷積核計算,尺度會越來越小;右邊的網絡自上而下,對更抽象、語義更強的深層特征圖進行上采樣。在參考了FPN設計思想的基礎上,本文選擇ResNet50中4個殘差塊各自的最后一層作為特征圖提取層,即conv2_3、conv3_4、conv4_6和conv5_3,再將提取的特征圖與右邊的上采樣網絡橫向連接疊加(橫向連接的2層特征的空間尺寸相同),組成完整的尺度感知網絡,并在每層進行獨立預測。設計高密度先驗框,在網絡6個從上至下的特征層中分別設計了25 600,6 400,1 600,400,100和25,總計34 125個先驗框,相較于SSD的8 732個先驗框,在數量上有較多的增加,從而保證了對不同尺度目標檢測的高召回率。
至此,淺層特征得到了語義信息的增強,每一層預測所用的特征圖都融合了不同分辨率、不同強度的特征,配合高密度先驗框,可以增強對多尺度目標,尤其是小尺度目標的檢測性能。
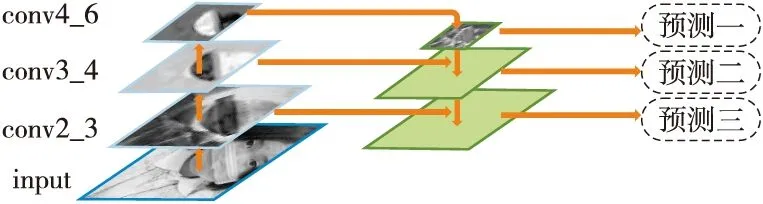
Figure 4 Structure of multi-scale awareness network圖4 尺度感知網絡結構
2.3 多任務損失函數的設計
多任務損失函數由2部分組成:一個是位置損失Lloc,另一個是分類損失Lconf。在訓練過程中,口罩檢測模型預測包括3類矩陣:先驗框坐標矩陣Ppro(Ppro∈Rm×4)、分類置信度矩陣Pconf(Pconf∈Rm×c)和預測框坐標矩陣Ploc(Ploc∈Rt×4,t∈[0,m])。訓練數據中標注的內容包括2類矩陣:目標真實框坐標矩陣Tloc(Tloc∈Rn×4)和目標真實框類別矩陣Tconf(Tconf∈Rn×1),表示目標真實框坐標集合和目標真實框類別集合。其中,m為先驗框個數,n為正樣本個數,t為預測框個數,c為目標類別個數,Rm×4為一個m行4列的矩陣。

(1)
其中,i為正樣本中的先驗框序號,j為預測框的序號。
(2)
其中,c為目標類別個數,本文中c=3,表示存在戴口罩類、未戴口罩類和背景類3個類別。
(3)
最后,總的損失函數如式(4)所示:
L=Lloc+Lconf
(4)
3 實驗及結果分析
3.1 數據集
本文實驗使用公開口罩檢測數據集[17],共計7 959幅RGB圖像(訓練集6 120幅,測試集1 839幅),標注框分為戴口罩和未戴口罩2個類別,其中戴口罩標注有3 970個,未戴口罩標注有9 586個。該數據集由WIDER FACE[21]人臉數據集和MAFA[22]人臉遮擋數據集中部分數據組成。WIDER FACE人臉數據集共計32 203幅RGB圖像(含已標注的訓練集12 880幅,驗證集3 226幅),訓練集中標注內容只包含159 420個人臉類(作為未戴口罩類)。MAFA人臉遮擋數據集共計30 811幅RGB圖像(訓練集25 876幅,驗證集4 938幅),其訓練集中只標注出了29 430個遮擋的人臉類(篩選出部分作戴口罩類)。
口罩檢測數據集中人臉和口罩的尺度多樣,角度豐富,口罩樣式較多,且包含有手部和其他非口罩物品對面部的遮蓋等,數據集示例如圖5所示。

Figure 5 Examples of public face mask detection dataset圖5 公開口罩檢測數據集示例
3.2 評估標準
參照公開口罩檢測數據集[16]的評估標準,本文采用精確率precision和召回率recall作為本文實驗的評估標準。評價方法的混淆矩陣如表1。

Table 1 Confusion matrix for evaluating method表1 評價方法的混淆矩陣
精確率precision和召回率recall的計算分別如式(5)和式(6)所示:
(5)
(6)
3.3 對照實驗
模型的訓練、推理均在Ubuntu16.04系統上完成,代碼使用PyTorch深度學習框架開發。硬件平臺為4塊NVIDIA GeForce GTX TITAN xp。輸入圖像尺寸大小為640×640,batchsize設置為16,訓練采用動態學習率,初始值為0.000 1,前8 400批次的訓練,每400個批次將學習率提升0.5倍,從第13 000批次的訓練開始,每6 000個批次將學習率降低一半。使用SGD(Stochastic Gradient Descent)優化器進行反向傳播和更新。
實驗在原始的公開口罩數據集上訓練本文的PyramidMask模型(單階段)、CenterNet模型(單階段)、YOLOv3模型(單階段)、Faster R-CNN R-50-FPN(兩階段)模型和基準方法的SSD模型(單階段),實驗結果如表2和表3所示。
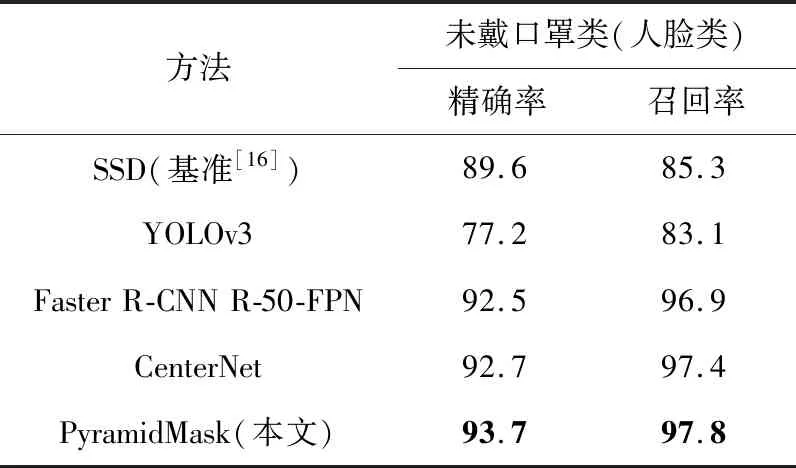
Table 2 Results of controlled experiment without masks表2 未戴口罩類對照實驗結果 %
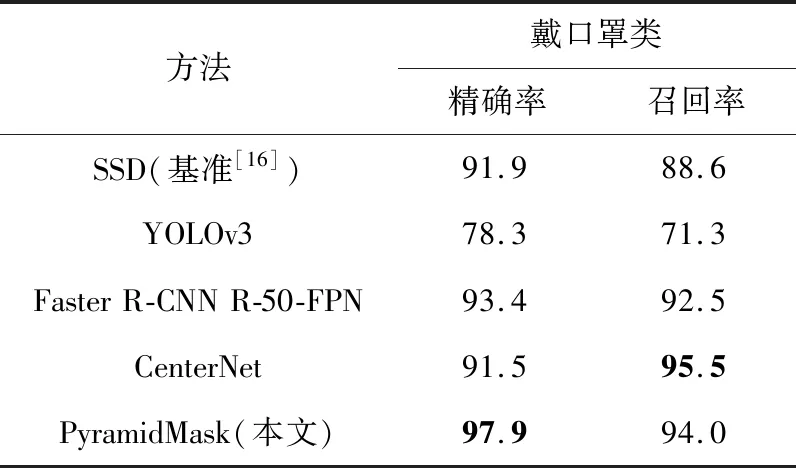
Table 3 Results of controlled experiment with masks表3 戴口罩類對照實驗結果 %
相較于基準方法[17],本文提出的PyramidMask在未戴口罩和戴口罩的召回率上分別有12.5%和5.4%的提升,在未戴口罩和戴口罩的檢測精確率上分別有4.1%和6.0%的提升。YOLOv3輕量的模型結構對小目標特征的提取能力不足。CenterNet和Faster R-CNN在經過下采樣后,因為CenterNet網絡底層特征圖分辨率比Faster R-CNN的更高,保持了更多的細節特征,所以對于本文實驗的小尺度數據,CenterNet召回率更高,為網絡后續的熱力點估計奠定了良好的基礎,進而有著更高的精確率。
3.4 多尺度檢測實驗
如圖6a所示,從左至右,將公開口罩檢測數據集[16]的測試集中的圖像調整為原始圖像、相較于原始圖像邊長的75%,50%和25%,生成多尺度的測試集,并使用3.3節中完成訓練的模型在不同尺度的圖像上進行測試,以獲取Faster R-CNN R-50-FPN、YOLOv3、CenterNet和PyramidMask模型在不同尺度目標上的檢測性能。
圖像在輸入到檢測模型時,模型會對圖像進行分辨率調整,這會造成上述多尺度圖像輸入到模型時并沒有嚴格按照所設計的尺度。針對這一問題,本文對輸入圖像進行填充處理,如圖6b所示,使調整尺度后的圖像在分辨率上與原始圖像一致,從而確保多尺度檢測實驗的嚴謹性。
實驗結果如表4和表5所示,PyramidMask模型在4個檢測尺度上都有較高的精確率和召回率。
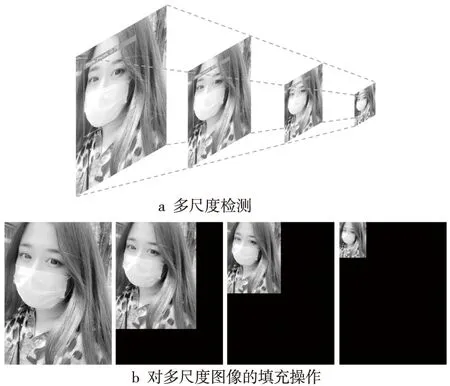
Figure 6 Multi-scale detection and padding operation on images圖6 多尺度檢測和圖像的填充操作
3.5 數據增強的方法
為了獲取更多尺度的目標數據,需要增加數據量。本文采用的方法為:對公開口罩檢測數據集中的圖像進行水平翻轉,再進行四合一圖像拼接處理,其對應的標注信息同時進行翻轉和拼接。進行圖像拼接處理具有以下優點:
(1)將4幅圖像尺度縮小后拼接,不僅獲得了多尺度的目標,也增加了單幅圖像中目標的數量。可以模擬人臉尺度多變、數量冗大的特征。
(2)增加了單幅圖像背景的復雜度。
(3)變相增加了訓練時的批處理數據量[23]。
數據增強后,訓練集擴充到了15 300幅圖像,四合一圖像拼接的數據示例如圖7所示,圖7a為原始圖像,圖7b為拼接后的圖像。
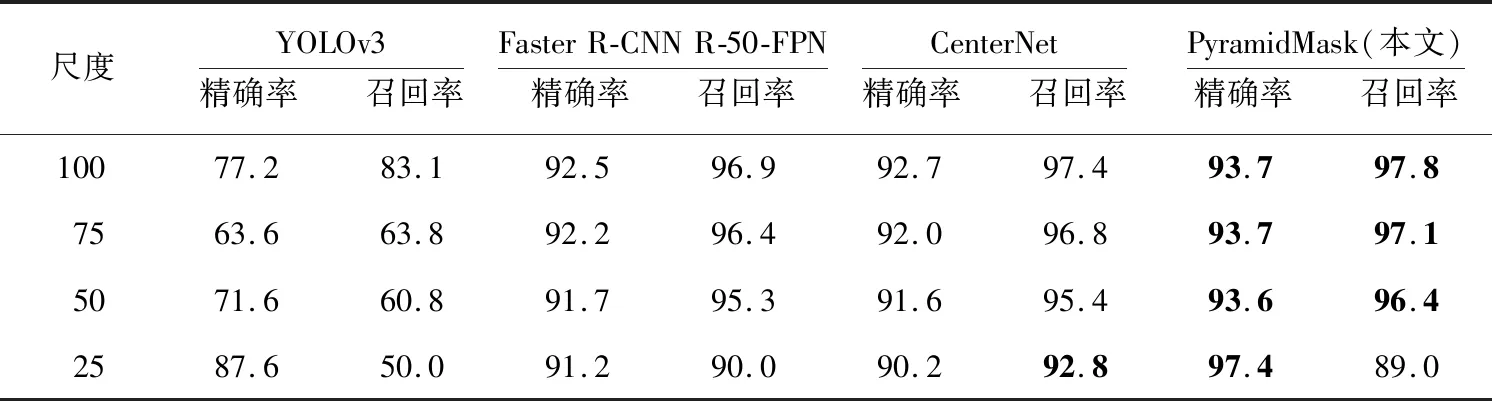
Table 4 Results of multi-scale detection experiment without masks表4 未戴口罩類多尺度檢測實驗結果 %
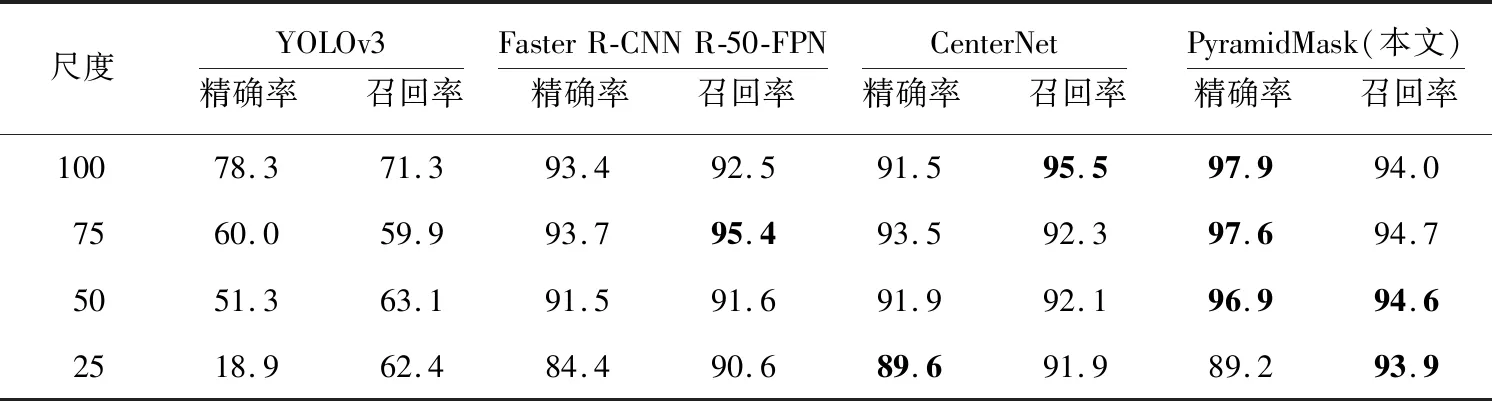
Table 5 Results of multi-scale detection experiment with masks表5 戴口罩類多尺度檢測實驗結果 %
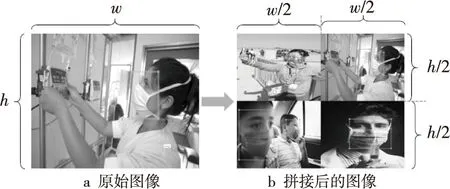
Figure 7 Example of image mosaic expansion of mask detection dataset圖7 口罩檢測數據圖像拼接擴充示例

Figure 8 Example of experiment on correct wearing of mask圖8 口罩正確性佩戴檢測實驗結果示例
3.6 數據增強實驗
3.5節提出了四合一圖像拼接的數據增強方法后,本節實驗使用的訓練數據為:數據增強后的口罩檢測數據再加上未增強的口罩檢測數據集,共計15 300幅圖像。其他實驗條件(包括測試集)與3.3節中的相同。實驗結果如表6和表7所示。

Table 6 Results of data expansion experiment without masks表6 未戴口罩類數據增強實驗結果
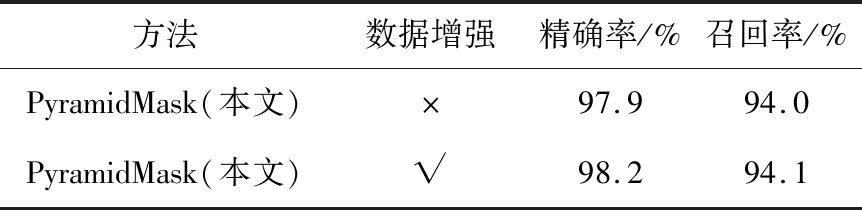
Table 7 Results of data expansion experiment with masks表7 戴口罩類數據增強實驗結果
數據增強后,PyramidMask方法的精確率和召回率均有一定的提升。未戴口罩類中,在保持精確率的情況下,召回率提升了0.2%;在戴口罩類中,在召回率提升0.1%的情況下,精確率提升了0.3%,表明使用拼接數據增強方法后的數據訓練模型,對提高檢測性能有一定的幫助。
3.7 口罩正確性佩戴檢測實驗
為檢驗本文模型對已戴口罩但佩戴不正確(沒有覆蓋到口鼻)現象的檢測能力,自建和網絡爬取了共計408幅未正確佩戴口罩類的圖像,并使用3.3節中訓練完成的各模型進行推理、對照驗證。評判標準:若模型檢測結果為未戴口罩類,則模型檢測正確;若模型檢測結果為戴口罩類,則模型檢測錯誤。統計各模型檢測正確的比例,比例越高,說明模型對未正確佩戴口罩檢測的性能越好。實驗結果如表8和圖8所示。PyramidMask檢測正確率高于其他3個對照組,有一定的正確佩戴口罩檢測能力,表明其網絡結構對數據特征有較優的提取和擬合能力。
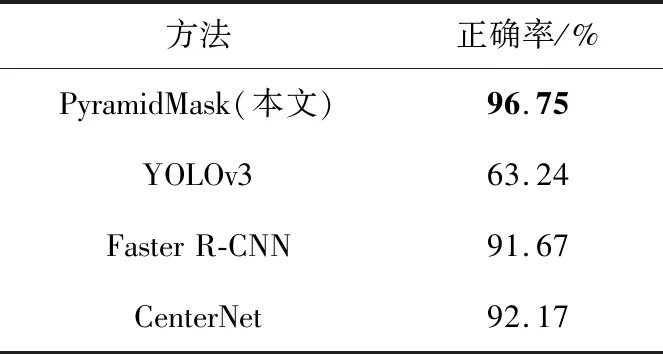
Table 8 Results of experiment on correct wearing of mask 表8 口罩正確性佩戴檢測實驗結果
3.8 檢測效果
本節在多尺度、多數量、多角度、多種外觀口罩和未遮住口鼻等圖像上,使用本文提出的PyramidMask口罩檢測方法進行測試,以檢驗PyramidMask方法的魯棒性。如圖9所示,PyramidMask在不同類型的圖像中,都能夠檢測出人臉和戴口罩的人臉,表現出了較好的檢測效果。

Figure 9 Results of mask detection with PyramidMask圖9 PyramidMask方法的口罩檢測效果
4 結束語
本文針對當前專用口罩檢測算法缺乏、通用目標檢測模型在面對多尺度、多數量、多角度和多外觀樣式口罩以及人臉檢測效果不佳的問題,提出了一種專用的、多尺度感知優化的、單階段口罩檢測方法——PyramidMask。通過設計結合ResNet骨干網絡特性的尺度感知網絡、高密度先驗框、目標尺度特征增強和數量擴充的方法,在包含大量困難檢測數據的公開口罩檢測數據集上,獲得了高于SSD基準、YOLOv3、Faster R-CNN和CenterNet檢測模型的檢測性能。在多尺度檢測實驗中,PyramidMask檢測模型在多尺度目標的感知能力上也領先于單階段檢測模型YOLOv3、CenterNet和兩階段檢測模型Faster R-CNN,表明了PyramidMask模型結構中尺度感知網絡的有效性。并且,在公開口罩檢測數據集的困難數據上,PyramidMask也表現出了較好的檢測效果,體現了本文方法的魯棒性。當前模型參數仍較為龐大,未來可以嘗試在保證檢測準確性的情況下,精簡模型結構,以確保模型在現實場景中使用的便利性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
