基于Hadoop平臺的網絡安全趨勢大數據挖掘算法
2022-08-22 01:31:46唐建海
工業加熱 2022年7期
唐建海
(重慶醫科大學附屬第一醫院,重慶 400016)
網絡安全趨勢數據挖掘過程中,經常出現大量空值或者缺失的情況,對其進行深度挖掘有助于揭示數據中包含的信息與關聯,獲取潛在信息[1-2]。在相關研究中,文獻[3]提出了快速頻繁項集挖掘算法。利用AHT-growth算法快速定位節點,實現頻繁項集挖掘。此方法有效縮短了執行時間,但算法所占內存問題仍需要進一步優化。文獻[4]提出了基于關聯規則的大數據挖掘方法。該方法適用于密集數據集,改進的E-SLMCM算法可以在遍歷數據庫較少次數下,轉變數據庫為垂直格式并記錄時間戳,從而節省了計算用時。但在并行處理大數據方面有待提高運算效率。文獻[5]針對稀疏空間數據進行上下文離群點挖掘,為減少計算節點共享與訪問數據帶來的I/O開銷,設計并行離群點挖掘計算框架,進行數據約簡、局部稀疏子空間構造和稀疏子空間驗證之間的并行計算,從而提高了運行效率。但該方法在多個數據節點挖掘數據時,容易發生數據傾斜從而導致系統負載不均衡的問題。
針對上述分析,為了進一步完善網絡安全趨勢大數據挖掘方法,利用Hadoop平臺篩選網絡安全趨勢大數據,重新確定聚類質心,引入改進K-均值大數據挖掘算法,以實現網絡安全趨勢大數據的深度挖掘。
1 網絡安全趨勢大數據深度挖掘算法
1.1 網絡安全趨勢大數據篩選
考慮網絡安全趨勢大數據信息缺失的情況,根據Hadoop平臺中的數據讀取機制(Hadoop Distributed File System,簡稱HDFS)。通過網絡安全趨勢大數據特征的篩選,排除了信息極端不完整數據和空值數據,便于重新確定數據聚類質心。
為了提高篩選數據的過濾性,提高后續網絡安全趨勢大數據深度挖掘的速度,需要評估網絡安全趨勢大數據覆蓋節點行為,以確定數據特征。假設服務器節點i的性能為Yi,則可利用下列函數描述服務器節點性能:
(1)
式中:參數a、b、c為各個指標對服務器性能的不同影響權重;Fi為CPU性能;Ni為內存性能;Pi為磁盤I/O性能。在Hadoop平臺中運行作業,根據計算結果評估網絡安全趨勢大數據覆蓋節點,校驗并修正。當平臺一次運行時,用R為運行任務總數,Ri為節點i完成的運行任務數量。考慮到Hadoop平臺處理的數據大小一致,因此Ri也表示一次運行時需要處理的數據量的大小。根據上述分析,驗證式(2)是否成立。
(2)
式中:j為與節點i相鄰的不同節點。當任意兩個不同節點的評估結果成立時,則表明節點性能對于Hadoop平臺是可以信賴的。
但由于無法精準得到方程中第一組公式等號兩邊的精準值,因此設置一個容忍度閾值λ,令λ=5%,將誤差范圍控制在5%以內。則式(2)在重新定義后的計算方程為
(3)
當節點評估結果滿足該條件時,排除數據為信息極端不完整數據和空值數據,選擇可用來重新計算聚類質心的網絡覆蓋節點[6]。設網絡中各個覆蓋節點數據大小的波動幅度為q,則需滿足式(4):
(4)
式中:n為網絡節點總數;P1,P2,…,Pn為每一節點的數據量大小;Y1,Y2,…,Yn為各個節點對應的性能評估結果;PR為Hadoop平臺可處理的數據大小。通過上述過程評估節點性能,修正節點誤差,并根據式(4)的計算所得,選擇精準性更高的網絡安全趨勢大數據覆蓋節點,完成了數據的篩選。
1.2 確定質心改進大數據挖掘算法
根據上述篩選數據結果,重新確定聚類質心,便于后續深度挖掘網絡安全趨勢大數據。這一過程通過K-均值算法實現[7],即利用全部網絡安全趨勢大數據的平均值,作為聚類結果中各個簇的質心點,圖1為該算法的質心確定示意圖。
根據圖1可知,網絡安全趨勢大數據覆蓋節點之間相互重疊、滲透、深入,而得到的質心卻存在較大的偏離量。因此根據重新選擇的網絡安全趨勢大數據覆蓋節點,重新確定聚類質心[8]。假設任意兩個節點用Ai和Aj表示,zs用于表示s個聚類簇區域,則任意節點之間的距離為
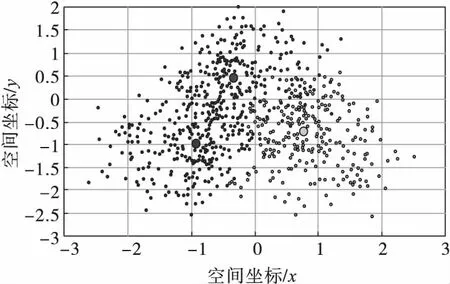
圖1 大數據挖掘算法質心聚類結果
(5)
式中:d為節點之間的距離;m為數據維度。則根據上述計算,確定質心的計算公式為
(6)
式中:Ei為生成的i個簇;ei為簇Ei的質心[9-10]。根據上述計算結果,重新獲取大數據挖掘算法的聚類質心,以此改進大數據挖掘中的K-均值算法,該改進過程為:
根據Hadoop平臺給定的網絡覆蓋節點數據,利用質心ei生成一個全新的Canopy集合,此時由于全部數據需要最少位于Canopy且數據點不歸附于同一個簇,因此只需要計算其與質心ei的間距,根據就近原則將數據歸入相應的Canopy集合中,令簇不堆疊。迭代產生的新簇,統計質心獲得的網絡覆蓋最遠趨勢數據,直至算法收斂。
1.3 網絡安全趨勢大數據并行化深度挖掘
將改進后的K-均值挖掘算法,與Hadoop環境并行化處理。以CSV的文件格式,將網絡安全趨勢大數據存儲于Hadoop分布式文件系統中,并初始化類[11]。根據改進后的K-均值大數據挖掘算法,確定聚類個數并初始化聚類中心,然后將待執行任務發送到選擇的網絡安全趨勢大數據覆蓋節點中;格式化分布式文件系統中的數據;逐行掃描覆蓋節點內的數據樣本,同時完成其與當前網絡中多個質心之間的計算,找到最近質心點,并標記為K。再重新構造鍵值對
Reduce=Hash(K)
(7)
式中:Reduce為大數據挖掘算法的分割結果;Hash為哈希函數。將該分割結果作為分配記錄,將數據分配到Hadoop平臺中指定的Reduce端,可以開始并行化處理。在所有Reduce端,構造、合并來自清洗階段的數據,其構造后的表現形式為
而網絡安全趨勢大數據的MapReduce階段,則根據上述數據挖掘流程,獲取網絡安全趨勢大數據覆蓋的效果圖。為每一個網絡覆蓋區域的數據分片,用S1,S2,…,Sn表示。已知Sn從數據塊中產生,數據分片Sn的個數決定數據覆蓋密度,而數據分片Sn的個數n的取值,依賴于數據塊的數量和大小[14]。已知一個數據塊可以分割為若干個數據分片,則可以利用式(8),計算數據分片個數。
(8)
式中:μ為數據塊大小;g為數據塊數目。根據該數量,獲取完整的數據覆蓋密度。MapReduce的數據處理端將輸出結果傳輸到Reduce端,該步驟參考式(7)[15]。至此實現基于Hadoop平臺的網絡安全趨勢大數據深度挖掘算法。
2 仿真實驗
通過仿真實驗,驗證算法挖掘網絡覆蓋數據時的可靠程度,并討論該算法與文獻[3]和文獻[4]兩種大數據挖掘算法挖掘時,選擇的網絡節點覆蓋率。為區分實驗測試結果,將此次研究的算法作為實驗組,將文獻[3]和文獻[4]算法作為對照A組和對照B組。測試過程中選擇網絡節點覆蓋率、查全率以及查準率作為測試指標,并設置三組不同的實驗測試環境。
2.1 實驗準備
此次實驗在Matlab R2018a中完成,具體參數設置如表1所示。
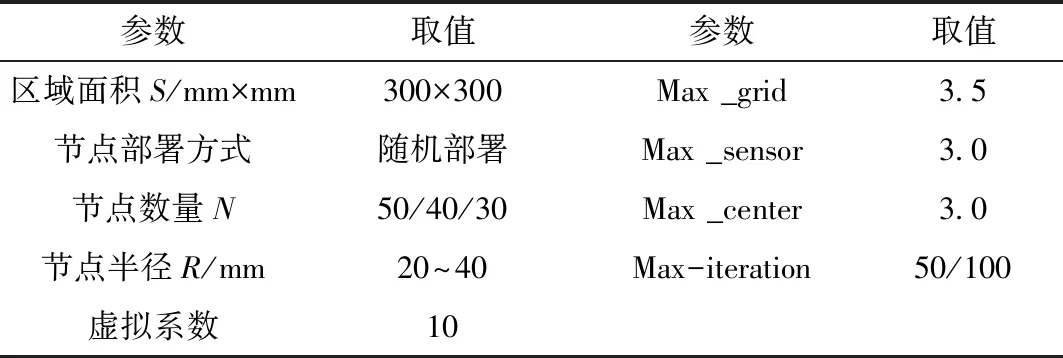
表1 仿真實驗測試參數
根據表1設置的實驗測試條件,分別利用三種不同的算法開始實驗。實驗共分為3組進行,第一組中,節點數量為0~50。已知仿真實驗測試下,三種算法均顯示了網絡覆蓋效果以及節點選擇結果。
2.2 網絡節點覆蓋率
當網絡覆蓋趨勢中的節點數量為50時,三種算法得到的網絡覆蓋趨勢節點挖掘結果,如圖2所示。
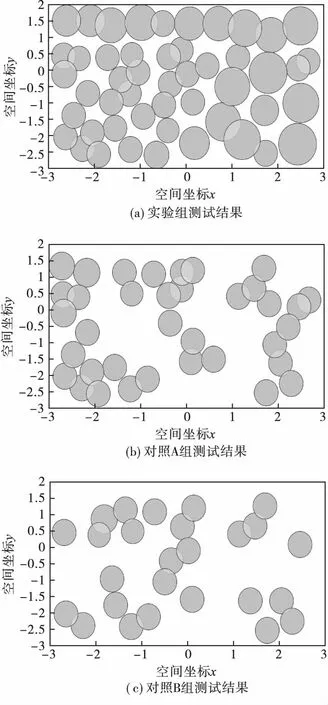
圖2 三種方法的網絡覆蓋趨勢節點挖掘結果(N=0~50)
根據上述實驗測試結果可知,面對相同數量的網絡覆蓋節點,實驗組中的大數據挖掘算法,均可以利用重新計算得到的質心,將這些預設節點挖掘出來,準確率達到98%,形成與網絡覆蓋趨勢高度相似的挖掘反饋結果。對照A組和對照B組中的兩組對比挖掘算法,通過多次挖掘,得到的網絡覆蓋節點大面積堆疊、交叉,其挖掘結果與網絡覆蓋趨勢的差異性極大,不能完全反饋網絡覆蓋趨勢的變化趨勢,只能體現局部網絡覆蓋特征。
為更好地顯示三組算法的結果差異,計算三種算法的節點覆蓋率,表2所示為覆蓋率統計結果。
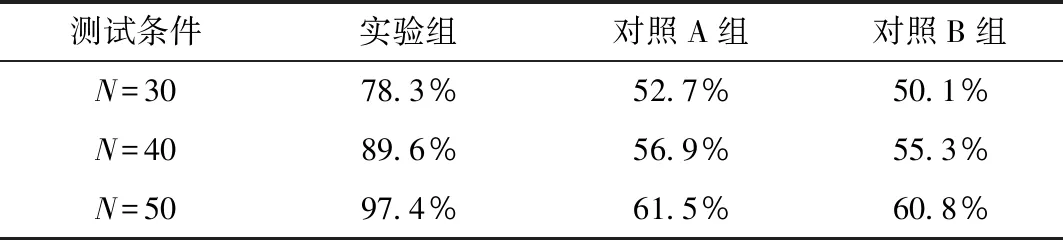
表2 算法覆蓋率統計結果
比較表2中的統計數據可知,在擴大覆蓋節點后,實驗組中的算法獲取超過95%的覆蓋節點;而對照組并沒有因為節點數量增加而大幅度提高挖掘節點覆蓋率,與實驗組相比,其節點最大覆蓋率低于70%。綜合上述實驗測試結果可知,此次研究的算法可以得到更大范圍的覆蓋節點,以此獲取網絡安全趨勢大數據。
2.3 查全率與查準率對比
為了進一步驗證此次設計的方法網絡安全趨勢大數據挖掘的效率,對比文獻[3]與文獻[4]方法的查全率與查準率。將實驗結果對比用直方圖表示,直觀對比三種方法的性能,具體如圖3和圖4所示。
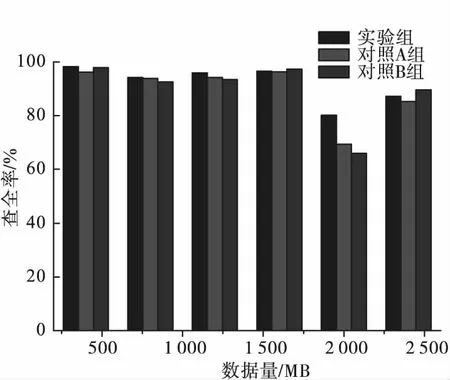
圖3 三種方法的查全率對比
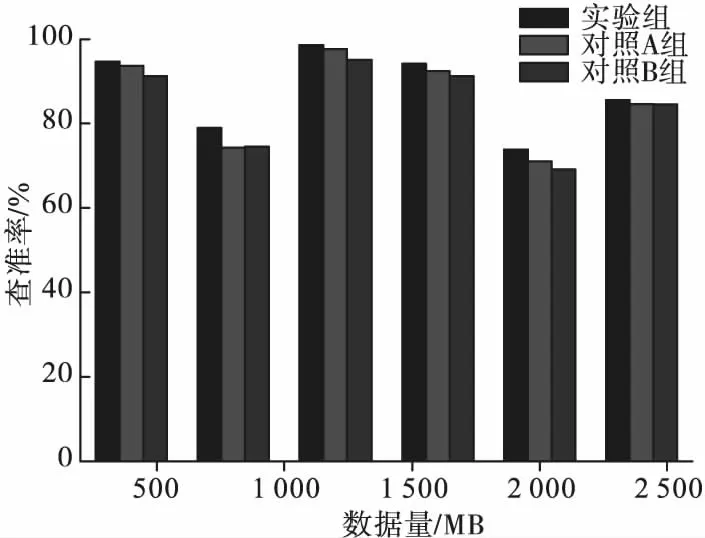
圖4 三種方法的查準率對比
對比圖3和圖4可得,在查全率方面,實驗組方法在數據量小于2 000 MB時,算法的性能優于對照組的兩組方法,當數據量為2 500 MB時,實驗組方法較實驗B組小2.39%。在查準率方面,實驗組方法的性能均高于其他兩種算法,查準率最高達到98.63%。
3 結 語
此次研究的網絡安全趨勢大數據挖掘算法,充分利用了Hadoop平臺的功能特征,根據更加精準的質心選擇網絡安全趨勢大數據覆蓋節點,挖掘其中的可靠信息。通過多組實驗測試可以看出,網絡覆蓋面積越大時,其中的覆蓋節點越多,查全率與查準率的性能也較高,此次研究的算法應用效果較理想。但該算法在查全率仍存在一定局限性,今后的研究應該將算法與其他類型的平臺相連接,實現全新的大數據挖掘。
猜你喜歡
第一財經(2021年6期)2021-06-10 13:19:08
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國生殖健康(2019年10期)2019-01-07 01:21:04
信息安全研究(2018年12期)2018-12-29 11:01:46
小學生必讀(中年級版)(2018年4期)2018-07-05 06:00:48
Coco薇(2017年9期)2017-09-07 21:23:49
電力與能源(2017年6期)2017-05-14 06:19:37
紡織服裝流行趨勢展望(2016年2期)2016-05-04 03:47:15
信息通信技術(2015年6期)2015-12-26 01:16:46
聲屏世界(2015年7期)2015-02-28 15:20:13
