基于Simhash改進的文本去重算法
2022-08-23 07:16:40張亞男陳衛衛付印金
計算機技術與發展 2022年8期
關鍵詞:文本
張亞男,陳衛衛,付印金,徐 堃
(陸軍工程大學 指揮控制工程學院,江蘇 南京 210007)
0 引 言
進入大數據時代,數字化信息呈現爆炸式增長。伴隨著云計算、大數據、物聯網等信息技術的快速發展,數據量呈幾何級增長,據IDC最新發布的報告預測,全球數據總量將從2016年的16.1 ZB增長到2025年的175 ZB[1]。隨著全球生成和存儲的數據越來越多,對存儲容量的需求將繼續以穩定的速度增長。但是無論是云存儲系統,還是傳統的數據存儲系統,都存在大量的冗余數據,有的系統中數據重復率高達70%~90%[2]。越來越多的研究者開始關注解決數據冗余問題以縮減存儲空間,重復數據刪除技術應運而生。重復數據刪除技術的核心思想是,只存儲唯一的數據對象,對于其他重復數據則通過存儲指針代替,指針指向該唯一數據對象。
當前流行的相似文本檢測和去重算法主要有k-shingle[3]、Minhash[4]和Simhash[5]算法。Simhash是Google工程師Charikar等人提出的一種局部敏感哈希算法,用來解決億萬級別網頁去重問題。Simhash算法較其他算法的優勢是處理速度快,結果準確度高,被廣泛應用于相似文本檢測、冗余數據去重和數據異常檢測等領域[6]。該文主要對Simhash算法在文本去重上的應用進行研究和改進,以進一步提高其檢測重復文本的精確率。
1 相關研究
1.1 Simhash算法
傳統的哈希算法能夠對任意長度的輸入數據進行計算,輸出固定長度的哈希值。SHA-1、MD5等傳統哈希算法,對輸入數據非常敏感,只要有1 bit的差距都幾乎不可能產生相同的哈希值,因此無法衡量文本的相似度。重復數據刪除技術分為相同數據檢測技術和相似數據檢測技術兩大類,傳統的哈希算法對后者的效果并不理想[7]。Simhash的主要思想是降維,將高維的特征向量映射成低維的特征向量,通過這些向量的漢明距離(Hamming Distance)來判定文本的相似度。Simhash算法流程(如圖1所示)大致如下:
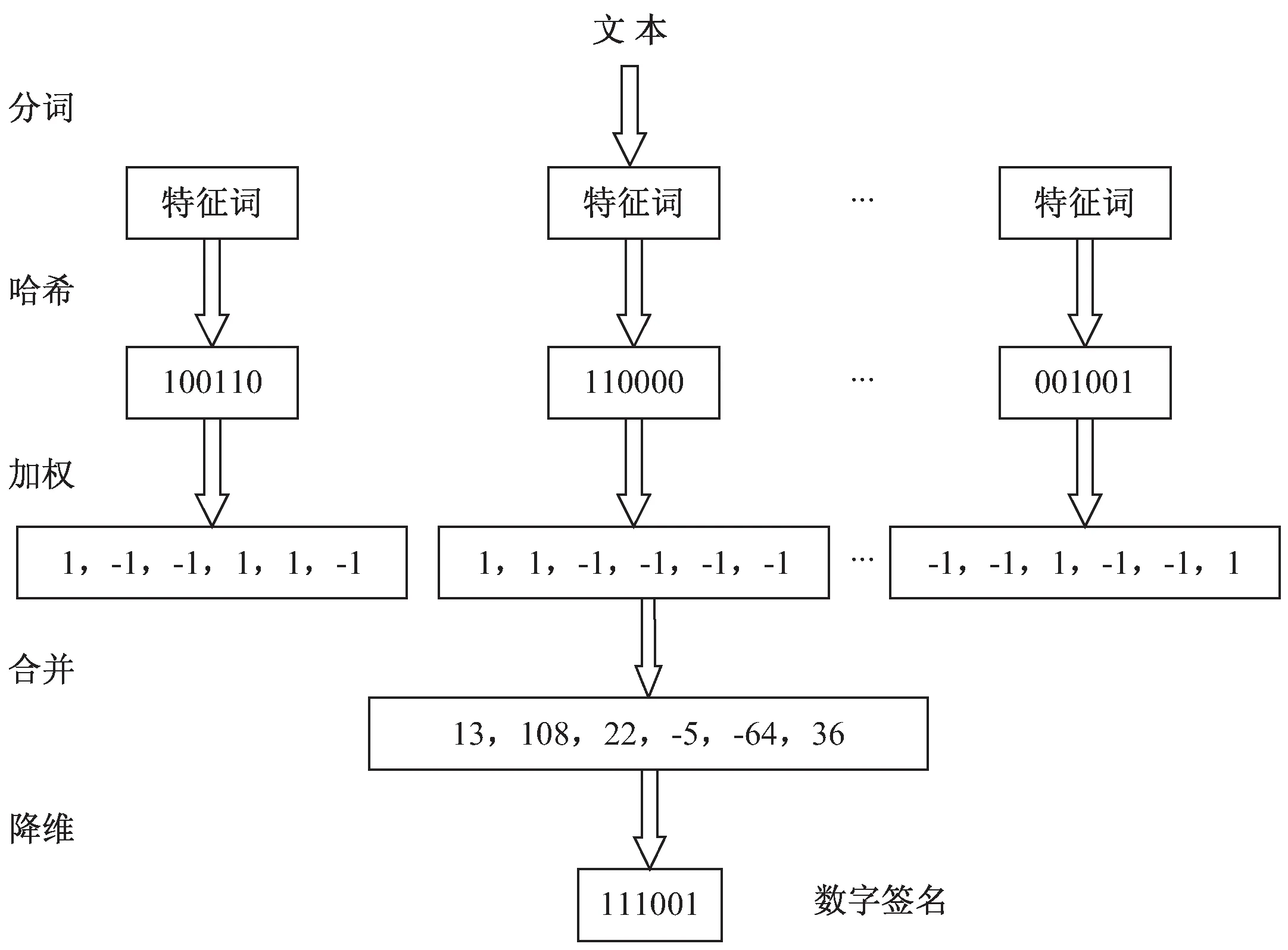
圖1 Simhash算法流程
(1)分詞。首先對文本進行分詞,將文本轉化為一組特征。然后,去除特殊符號、停用詞等無關字詞。
(2)哈希。使用同一哈希函數計算各個詞的哈希值,分別得到它們對應的f位簽名Sig。
(3)加權。為每個特征詞賦予權重,對每個詞的f位簽名進行加權計算。在計算每個比特位時,遇到1則加上其權重值,遇到0則減去其權重值,得到每個詞的加權特征值。
(4)合并。對文本內的每個加權特征值進行累加,得到一個f位向量V。
(5)降維。對向量V降維,對于每個比特位,如果大于0則將該比特位置為1,否則置為0。得到的結果作為文本的簽名,記為S。
在計算文本間距離階段,對不同文本的簽名進行異或操作,逐位比較其簽名值。如果該比特位上的值不同則記為1,否則為0,得到1的個數即為漢明距離的大小。漢明距離越大,代表兩個文本相似度越低,反之則相似度越高。
1.2 當前研究現狀
在大數據高性能存儲應用領域,傳統的Simhash算法已無法滿足其需求。首先,特征詞選取的精度不高,不能很好地體現文本特征。其次,對特征詞權重的計算比較片面,導致準確率下降。針對上述問題,國內外研究者進行了進一步的研究與改進。
文獻[8]針對特征詞權重影響因素考慮不足的問題,在Simhash權重計算階段,從詞性、詞長、標志詞以及文檔標題中是否含有特征詞等幾大方面對TF-IDF算法的權重計算進行改進,缺點是僅僅根據特征詞的詞性、長度和是否處于標題摘要等位置對權重進行優化,會導致部分權重過大。文獻[9]將Simhash算法和GAN(Generative Adversarial Networks)網絡進行結合用于惡意軟件檢測,通過轉化為灰度圖像提高惡意軟件識別率和性能。文獻[10]引入文檔標簽、摘要、關鍵詞和參考文獻等其他信息,從多個維度計算文本相似度,但是沒有考慮詞匯位置分布的影響因素。文獻[11]提出的E-Simhash算法采用詞頻和熵加權的方式優化特征詞權重計算,并針對Simhash算法無法體現特征詞位置信息的問題,在特征詞哈希時與其位置進行異或運算。但是在計算特征詞簽名時簡單地將其哈希與所在位置進行異或運算,容易造成文本簽名失真。例如在文本頭僅僅添加一個文字就可能會導致所有特征詞位置發生改變,造成文本簽名值的顯著改變。
以上對Simhash算法的改進主要存在兩個問題。第一個問題是,在對特征詞哈希加權時沒有考慮特征詞之間的關聯性,例如待去重文本中可能存在幾個大類,而屬于某一類文本中的特征詞具有很強的關聯性,可能會同時出現。如果這些詞同時占有較高權重,對于分類性能很好,但是卻為差異檢測帶來了干擾。第二個問題是,不能很好地體現特征詞位置分布信息。
2 改進的Simhash算法
針對以上提到的問題,對Simhash算法進行改進。傳統的Simhash算法基于詞袋模型,無法表征語序信息。但是僅考慮特征詞出現的頻率而不考慮語序特征,會影響結果的準確性。為了減少誤判,該文將特征詞的位置分布信息融入Simhash計算簽名。為提高運算效率,選取權重前m的詞語而非全部詞語作為特征詞。針對特征詞的共現現象,根據Jaccard相似度對權重進行優化,降低相關度較高的特征詞的權重,以提高檢測精度。改進BDR算法用于反映特征詞位置分布,使用隨機函數將特征詞所在位置映射到f維向量空間,對得到的特征向量累加得到均差向量,然后做降維處理作為位置特征值。取特征詞哈希與位置特征值加權求和作為其特征向量,與優化后的特征詞權重相乘,經合并降維后生成新的文本簽名。最后,通過計算文本間的漢明距離來判斷文本相似度,將A,B兩個文本之間的相似度定義為:
(1)
其中,Ham(A,B)表示A,B兩個文本的漢明距離,f表示文本簽名值的比特位數。兩個文本的距離越小,相似度越大。文獻[12]的實驗結果表明,對于64位的長文本簽名,可以將漢明距離不大于3的兩個文本判定為相似文本,同時保證較高的準確性。
2.1 特征詞權重的改進
現有的基于Simhash改進算法主要使用TF-IDF算法為特征詞賦權,在計算文本間相似性時沒有考慮特征詞之間的共現現象,而這與基于選擇的特征降維模型前提條件“特征項之間相互獨立”相矛盾[13]。文本集中的特征詞可以分為三類[14]:第1類特征詞在某一類文本中大量出現而在其他類文本里很少出現,第2類特征詞常常在幾個文本類別中出現而在其他類文本里很少出現,第3類特征詞卻在幾乎所有文本類別中都出現。使用TF-IDF算法會對第3類特征詞賦予極低的權重,對于前兩類特征詞通常會賦予較高權重。但是當前兩類特征詞出現共現現象時,由于都占據較高的權重,導致文本簽名模糊,反而不利于文本去重。例如有以下文本:
①李白是唐代詩人
簽名值:010011000101000100101101
②李白不是唐代詩人
簽名值:010011000101000100111101
其中,詞語“是”、“不是”就屬于第3類,在幾乎哪一類文本中都有出現,根據TF-IDF計算得到的權重很低。而“李白”、“唐代”、“詩人”這些詞屬于前兩類,根據TF-IDF算法計算得到的權重較高。如果取權重前3的詞語作為特征詞,通過傳統Simhash計算兩個文本簽名值距離為1,即使兩個文本內容和含義有很大差異也會被判定為重復。而“李白”、“唐代”、“詩人”共現頻率很高,由“李白”一詞幾乎可以代替其他詞語,這樣一來“是”、“不是”就成為影響文本簽名值的特征詞。
(1)TF-IDF算法。
在大數據高性能存儲中,文本數量巨大,將每個文本分詞后所得的詞語數量會大大增加,為降低計算機運行的時空間復雜度,需要對分詞結果進行篩選。TF-IDF算法是一種特征提取的方法,可以在盡量保證文本特征信息的同時縮減特征詞的數量,達到降維目的。其一般表達形式為:
ωdt=tfdt×idf(Nnt)
(2)
其中,ωdt表示特征詞t在文本d中的權重,tfdt表示特征詞t在文本d中出現的頻率,N表示文本集中文本的總數,idf(Nnt)表示逆文檔頻率,是對文本集中文本總數N和特征詞t出現的文本數目n的比值取對數,用于權衡特征詞重要性。在實際應用中,為減少文本長度影響,需要對特征詞權重進行歸一化處理。在改進的算法中,TFC[15]的應用最為廣泛,其表達式可寫作:
(3)
其中,mdt表示特征詞t在文本d中出現的次數,Md表示文本d中的特征詞總數,nt表示文本集中出現特征詞t的文本數。
(2)Jaccard相似度。
Jaccard系數是一種二元數據對象的相似性度量方法,常用于比較有限樣本集之間的相似性。其表達式為:
(4)
其中,J(x,y)表示二元對象x,y的相似度,f11表示x取1并且y取1的樣本個數,f01表示x取0并且y取1的樣本個數,f10表示x取1并且y取0的樣本個數。在上式中,x取1表示樣本中包含特征詞x,反之則不包含,y同理。在實際應用中,特征詞x,y即使同時出現在多個樣本中,它們出現的次數也會呈現隨機性。為了消除量綱的影響,對其做了以下改進:
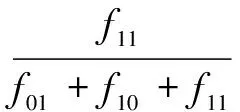
(5)
其中,n表示同時包含特征詞x,y的樣本總數,xk表示第k個樣本中特征詞x出現的次數,yk表示第k個樣本中特征詞y出現的次數。
(3)相似度加權算法。
在計算特征詞權重時,在TF-IDF基礎上,根據Jaccard相似度對權重進行優化。算法簡記為J-Tidf,由其計算得到的權重表達式為:
(6)
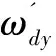
2.2 體現特征詞位置信息的哈希簽名
傳統的Simhash算法基于詞袋模型,無法表征特征詞在文本中出現的位置。例如有以下文本:
①太陽隊總決賽贏了雄鹿隊
簽名值:101110010101000100001100
②雄鹿隊總決賽贏了太陽隊
簽名值:101110010101000100001100
即使兩個文本的內容和含義大不相同,使用傳統的Simhash算法也會得到完全相同的簽名值。因此,該文針對文本詞匯位置信息設計一套簽名方案,以量化文本間的特征詞分布差異。
2.2.1 BDR算法
BDR(Binary Dimension Reduction)是Rameshwar等人提出的一種稀疏二進制向量降維算法[16],旨在通過維度壓縮降低存儲空間和提高計算效率,同時盡可能保留原始向量的特征。在詞袋模型中,大多數單詞很少出現在文本中。以Twitter為例,每條推文限制為140個字符,如果只考慮英文推文,由于英文詞匯量為171 476個,每條推文都可以表示為171 476維度的稀疏二進制向量,其中1表示存在單詞,0表示不存在。在BDR算法中,這種稀疏性是實現降維的前提[17]。BDR算法(如圖2所示)分為以下幾步:
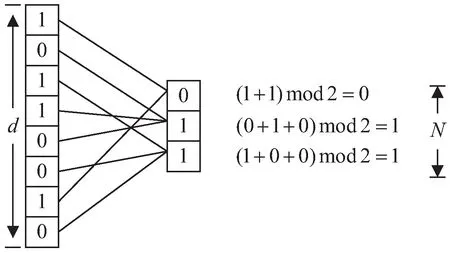
圖2 BDR算法示例
①映射。對于由01組成的d維二進制向量u和N維向量v,選擇一個隨機函數,將向量u中的每個比特位映射到向量v上的每個位置。
②奇偶校驗。對于映射到向量v上的每個比特位上的01求和,如果和是奇數則記為1,否則記為0。
壓縮維度N的邊界為ψ2log2n,與原始向量維度d無關。其中ψ表示數據稀疏性,即原始向量集合中出現1的數量最多的向量中1的個數,n表示待比較二進制向量個數。壓縮后的數據繼承了原始數據的內積,其漢明距離總是小于或等于原始數據的漢明距離,同時在Jaccard相似性計算上與Minhash保持幾乎相同的準確性。
2.2.2 改進BDR算法用于表示特征詞位置差異
BDR算法在保留數據對象內積的前提下有效實現了數據降維,但是隨著待比較向量數目n的增加,文本長度增加導致稀疏性系數ψ變大,這使得壓縮維度N不斷增大。該文對BDR算法進行了改進,將其應用到特征詞位置信息的降維表達上,在損失一定精度的情況下,可以大大降低壓縮維度。改進后的算法簡稱PBDR,流程(如圖3所示)如下:
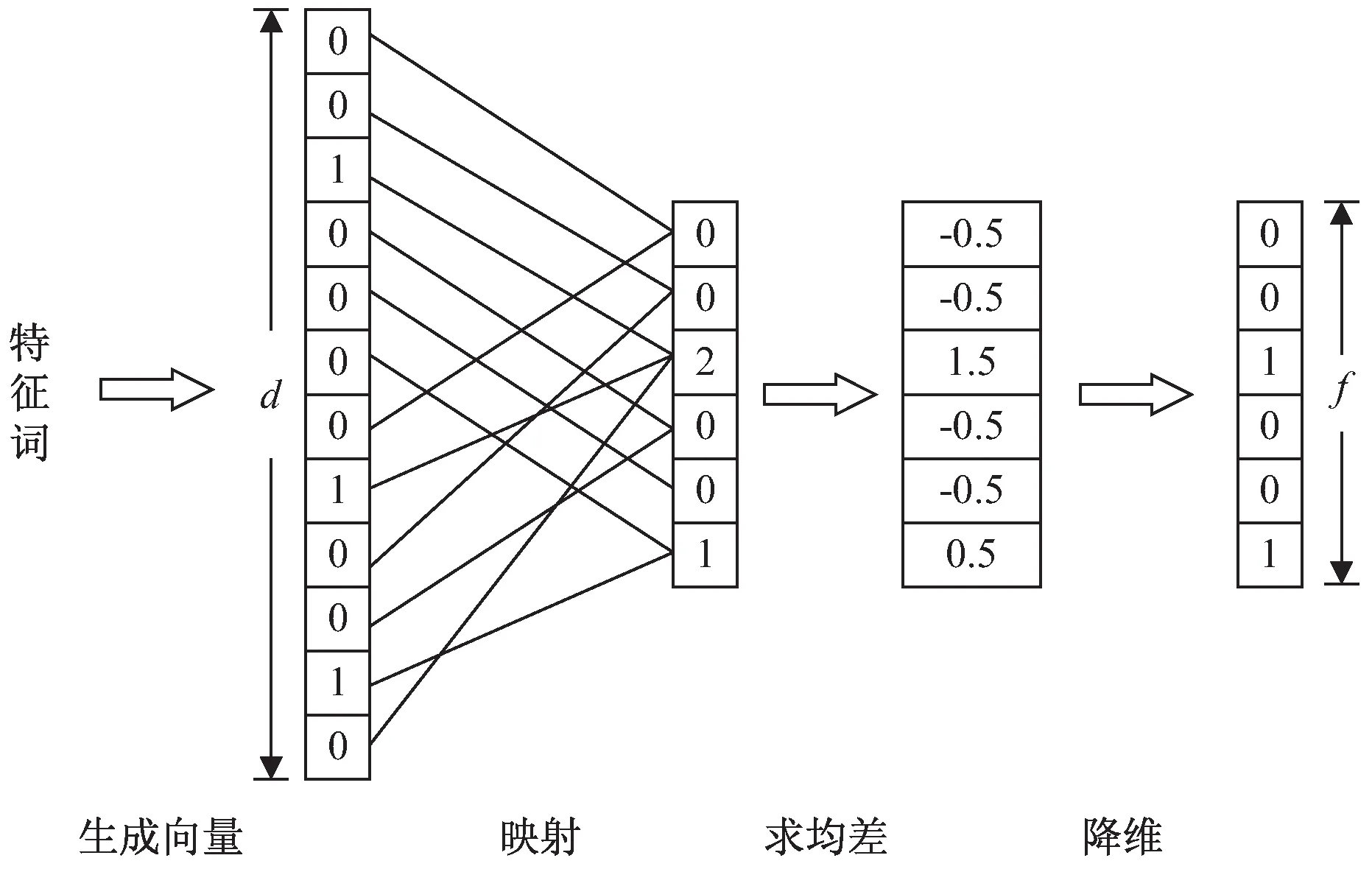
圖3 改進的BDR算法流程
①生成原始向量。對于每個特征詞,統計其在文本中的位置,生成對應的d維二進制向量u,d表示文本詞匯總數。對于每個比特位,如果該特征詞在文本第p個位置出現,則向量u的第p位置為1,否則置為0。
②映射。選擇一個隨機函數,將向量u中的每個比特位映射到f維向量v。在計算向量v的每個位置時,將映射到該位的01值進行求和。
③求均差。對向量v每個位置,先求所有位置上數值的均值,然后將每個位置上的數值減去均值,得到該特征詞的均差向量。
④降維。對特征詞的均差向量降維,對于每個比特位,如果大于0則將該比特位置為1,否則置為0。得到反映特征詞位置特征的簽名,記為Sig'。
2.3 融合特征詞詞匯和位置信息的Simhash算法
改進后的算法(P-Simhash算法)主要針對傳統Simhash算法為特征詞賦權不夠合理、沒有體現文本特征詞分布位置差異的缺點,在哈希、加權兩個過程中做出改進。算法流程(如圖4所示)如下:
(1)分詞。使用Jieba分詞工具對文本進行分詞,去除特殊符號、停用詞等無關字詞。
(2)哈希。計算權重并按照權重大小選取前m個分詞結果作為特征詞,使用同一哈希函數計算各個詞的哈希值,得到它們分別對應的f位簽名Sig。
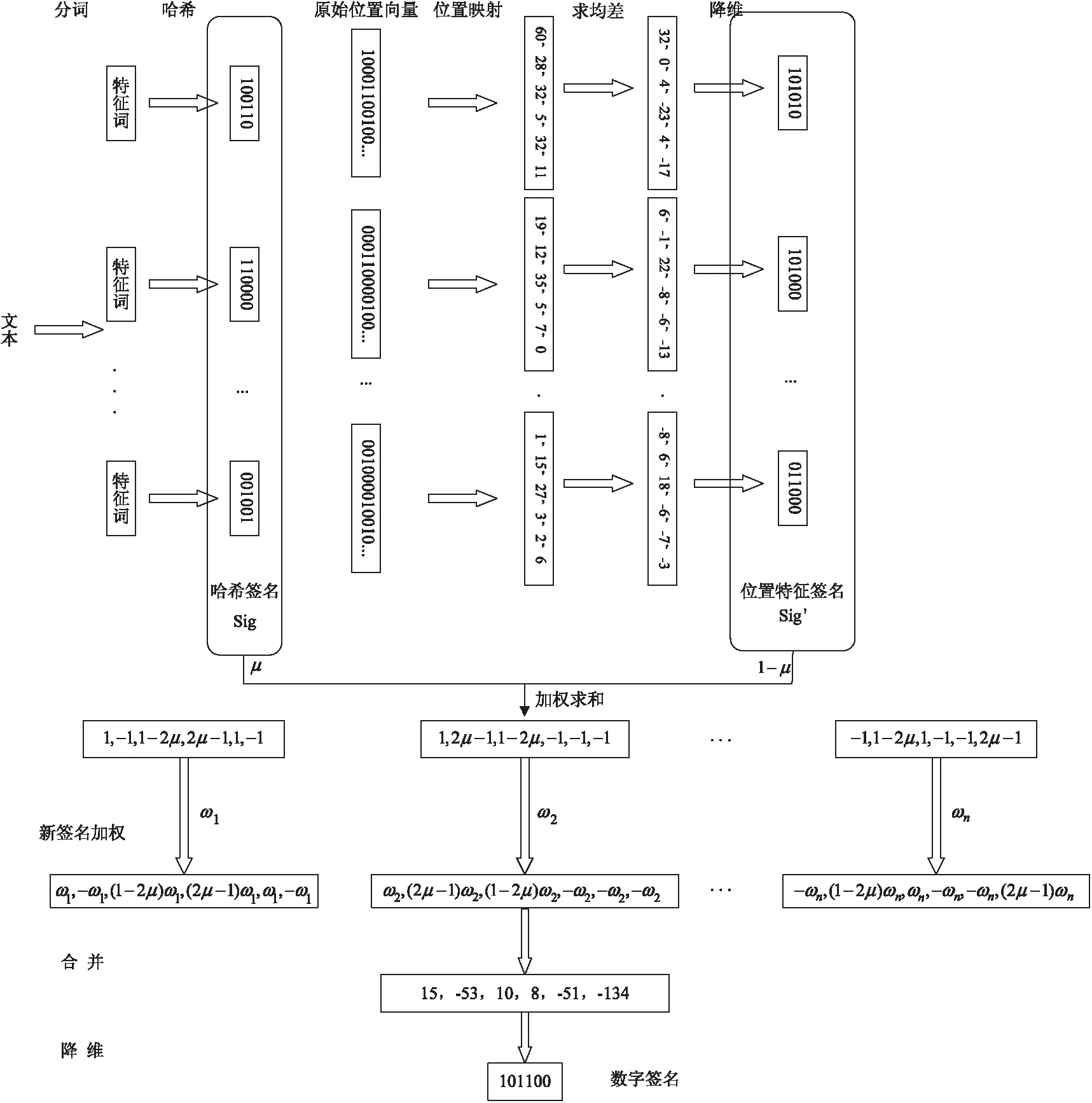
圖4 P-Simhash算法流程
(3)位置特征轉換。使用同一映射函數通過PBDR算法計算各個詞對應的f位位置特征簽名Sig'。
(4)簽名加權合并。對于上兩步得到的特征詞的兩種特征簽名加權求和,得到其對應的特征向量SigFnl,計算公式為SigFnl=μ×Sig+(1-μ)×Sig'。在計算每一位時,如果遇到0則先將其置為-1然后再進行運算。
(5)二次加權。使用J-Tidf算法計算詞的權重,對每個詞的特征向量SigFnl進行加權計算。將特征向量對應的每一位上的數值乘以權重值,得到每個詞的加權特征值。
(6)合并。對文本內的每個加權特征值進行累加,得到一個f位向量V。
(7)降維。對向量V降維,對于每個比特位,如果大于0則將該比特位置為1,否則置為0。得到的結果作為文本的簽名,記為S。
3 實驗及分析
為了檢驗提出的改進算法對重復文本的檢測性能,選擇搜狗新聞數據集作為實驗數據,對原Simhash算法和改進后的Simhash算法進行對比。主要評估去重率、精確率、召回率和F1值[18]等指標,各指標的表達式如下:
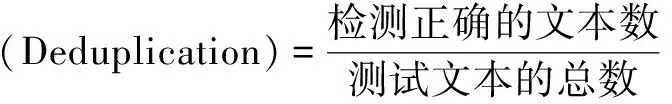
(7)
精確率(Precision)=
(8)

(9)
(10)
3.1 實驗環境
實驗代碼采用Python語言編寫,測試環境部署在Windows10操作系統上,硬件環境為Intel(R) Core(TM) i5-10200HCPU @2.40 GHz 處理器,8 GB內存容量,分詞工具采用 Jieba3.0。
3.2 實驗數據
數據集采用搜狗實驗室中的全網新聞數據2012版,收錄了來自若干新聞站點2012年6至7月期間國內、國際、體育、社會和娛樂等18個頻道的新聞數據,有近10萬條。首先剔除少于100個內容的新聞類別,然后再剔除其中字數小于800的新聞,隨機選取4 246篇新聞進行后續實驗。前文提及的E-Simhash算法在計算文本簽名時也融入了特征詞分布信息,因此該文也將重點與其進行實驗比較。隨機選取其中的2 831個樣本作為訓練集,用作計算特征詞之間的Jaccard相似度,以優化其權重。在E-Simhash算法對比實驗中,用作計算特征詞的左右信息熵。將剩余的1 515個樣本作為測試集,比較不同算法性能。
3.3 實驗結果與分析
使用64位二進制01向量作為文本簽名值,在計算簽名值時μ值的選取待實驗后給出。E-Simhash算法選取漢明距離為10并以此為基礎開展實驗,為了保證實驗的客觀性,漢明距離取10。
3.3.1μ的取值對去重率的影響
如2.3中所述,P-Simhash算法在第(4)步計算特征詞對應的向量時,采用加權合并的方法得到融合位置分布信息的特征向量。對于任意比特位,若Sig和Sig'在該位上相同時μ值大小對結果無任何影響;當Sig和Sig'在該比特位上不同時,經加權計算得到的值域為|2μ-1|,μ值表征了特征詞位置分布對簽名的影響程度。μ取值越大,特征詞位置分布不同帶來的影響就越大,但是對于自然文本來說,大多數時候特征詞位置的改變并不影響整個文本的語義。因此,當μ取值超過一定范圍后,算法的去重率反而會下降。圖5顯示了μ在不同取值情況下,運行P-Simhash算法得到對應的去重率。實驗結果表明,對于實驗選取的搜狗新聞數據集,當μ取值在1.4到1.9之間時,P-Simhash的去重率達到比較高的程度。因此,進行后續的算法性能比較實驗時,參數選擇μ=1.5。
3.3.2 不同算法性能比較
P-Simhash在計算文本簽名時融入了位置信息,計算的文本簽名能夠體現特征詞位置分布差異的影響;同時在特征詞哈希加權時降低了共現詞的權重,避免了關聯特征詞具有較高權重導致簽名模糊,因此相比其他算法擁有較高的精確率和召回率。如圖6所示,P-Simhash算法在精確率上以0.946:0.803:0.909分別高于傳統Simhash算法和E-Simhash算法,在召回率上以0.879:0.674:0.813分別高于傳統Simhash算法和E-Simhash算法。F1值是評價去重算法性能的重要指標,在該指標上P-Simhash算法以0.911:0.732:0.858優于傳統Simhash算法和E-Simhash算法。
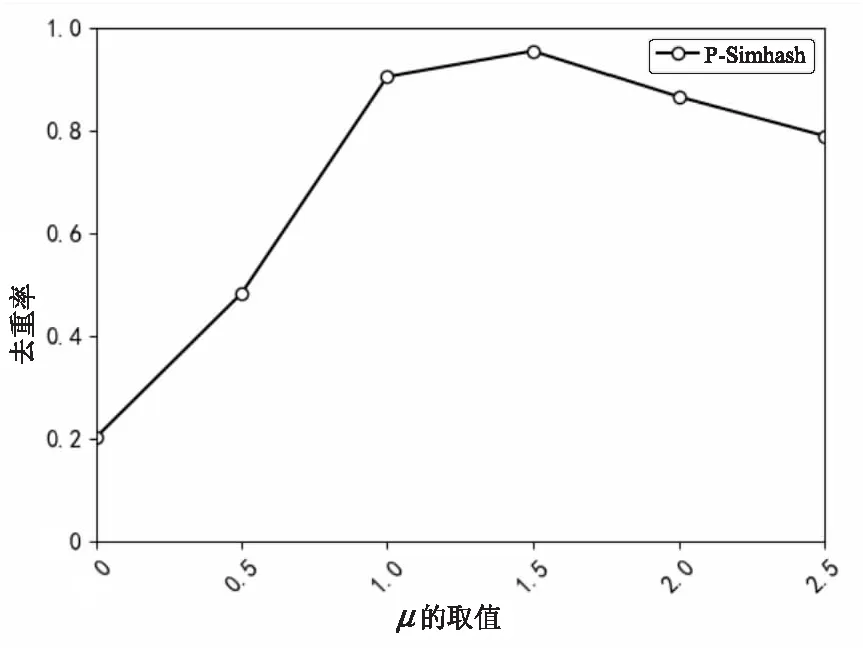
圖5 μ在不同取值下的去重率
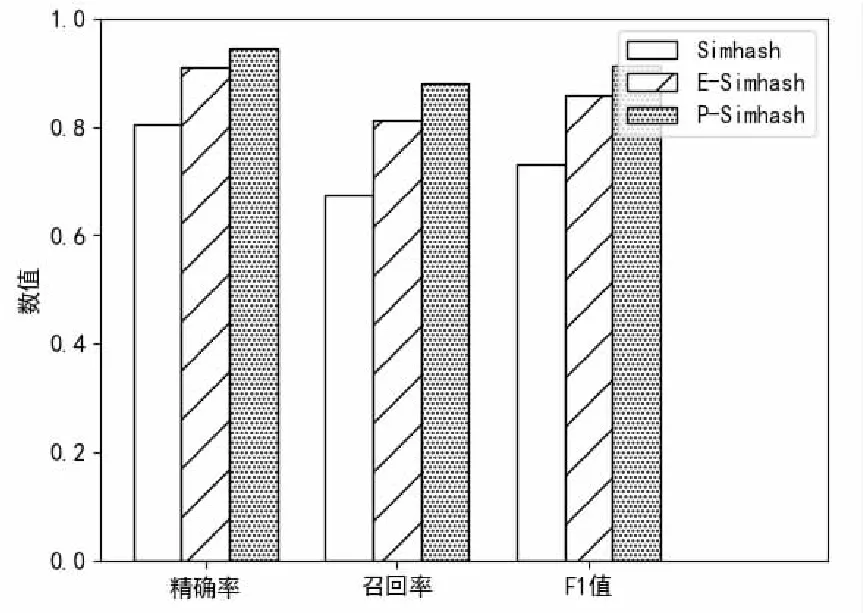
圖6 算法性能對比
3.3.3 算法執行時間比較
P-Simhash算法在生成文本簽名時加入了詞匯位置特征計算,帶來了一定的時間開銷。為解決這一問題,該文采用前m個特征詞而非全部特征詞計算文本簽名,因此可以節省大量的哈希運算時間。由圖7可以看出,特征詞權重幾乎呈指數下降,當m大于20時,特征詞的權重值很小,對生成簽名值的影響也有限。因此,選擇權重前20的特征詞計算文本簽名。
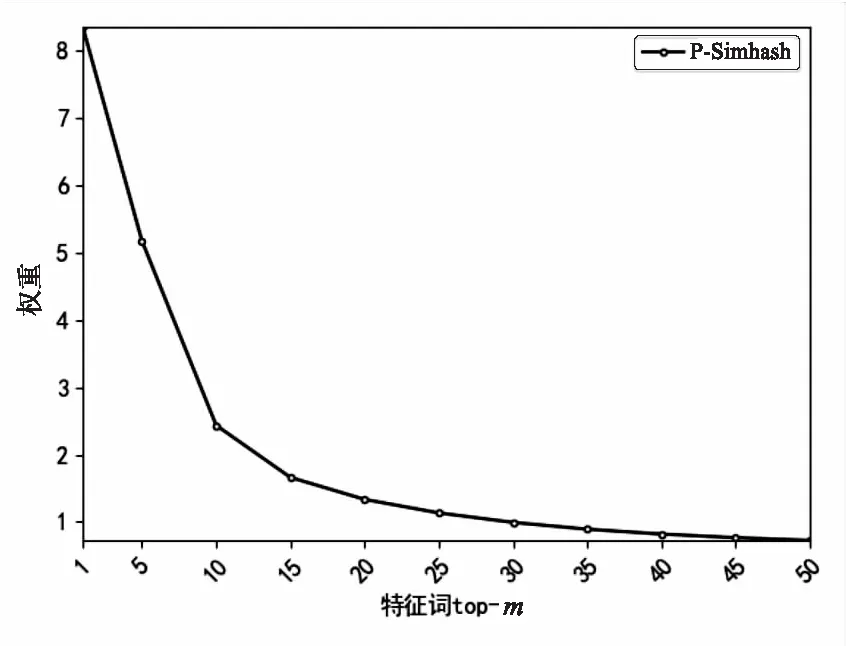
圖7 前m個特征詞的權重
為了比較不同算法的運行時間,將測試樣本集通過裁剪拼接,調整每條新聞樣本長度為1 000、2 000、3 000、4 000字,然后分別進行測試。實驗結果如圖8所示,隨著文本長度不斷增加,算法的執行時間也越來越長。P-Simhash算法由于在生成文本簽名時加入了詞匯位置特征計算,有一定的時間開銷,但由于僅使用前20個特征詞計算文本簽名,節省了特征詞哈希時間,因此P-Simhash算法執行時間與Simhash算法幾乎相同。同時,由于無論文本長度變化始終選取前20個特征詞計算文本簽名,因此算法穩定性更好。而E-Simhash算法將全部特征詞哈希與其每個位置分別進行異或操作,因此耗費時間更多。
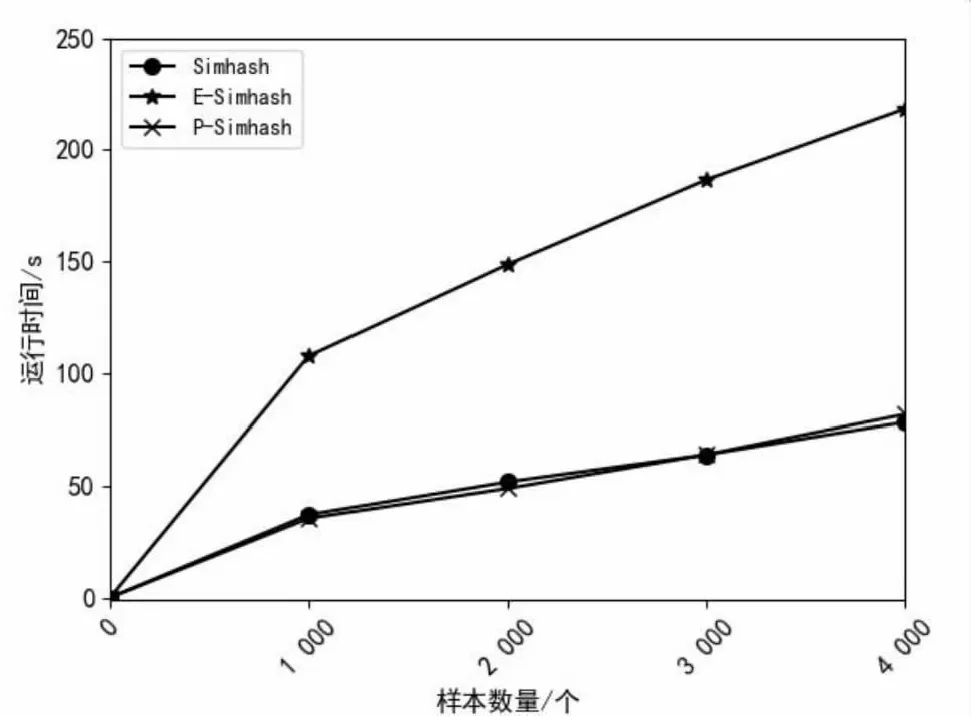
圖8 算法執行時間對比
總結以上實驗結果可以得出,P-Simhash以0.911:0.732將傳統Simhash的去重效果提高了24.4%,而算法執行時間幾乎相等。同時,在時間開銷和去重性能上均明顯優于E-Simhash算法。綜合去重性能和算法執行效率,提出的P-Simhash算法較其他算法性能更好。
4 結束語
針對傳統Simhash算法對重復文本檢測精確度不高的問題,采用改進的Jaccard相似度計算方法計算特征詞的關聯度,適當降低共現詞的權重,從而將注意力放在可能造成文本差異的部分。對于其無法體現特征詞在文中分布的缺點,引入了二進制維度縮減算法,并在此基礎上進行了改進,以便將特征詞在文本中的位置分布信息映射到低維向量空間。設計了新的特征詞簽名,將詞哈希與其位置信息結合在一起作為新的特征詞簽名。實驗結果表明,提出的P-Simhash算法的去重性能較傳統Simhash算法有明顯提高。基于Simhash改進的中文文本去重算法普遍依賴ICTCLAS、Jieba等分詞工具,如不能識別新詞、分詞不準確等會給相似度計算帶來較大影響,在算法的分詞階段還有較大的改進空間。此外,上述算法直接將特征詞進行哈希計算,缺乏衡量近似詞的手段,兩個同義詞的哈希值很可能完全不同,可能導致兩個相似文本相似度很低。下一步將針對詞義的相似程度設計一套獨特的詞簽名方案,以便更好地應用于相似文本檢測工程。
猜你喜歡
云南教育·小學教師(2022年4期)2022-05-17 14:46:24
新世紀智能(語文備考)(2020年4期)2020-07-25 02:28:52
新世紀智能(語文備考)(2020年4期)2020-07-25 02:28:52
甘肅教育(2020年8期)2020-06-11 06:10:02
藝術評論(2020年3期)2020-02-06 06:29:22
制造技術與機床(2019年10期)2019-10-26 02:48:08
新世紀智能(語文備考)(2018年11期)2018-12-29 12:30:58
電子制作(2018年18期)2018-11-14 01:48:06
小學教學參考(2015年20期)2016-01-15 08:44:38
語文知識(2015年11期)2015-02-28 22:01:59
