融合知識圖譜的多通道中醫辨證模型
2022-08-23 12:20:02葉青張素華程春雷鄒靜彭琳
科學技術與工程 2022年21期
葉青, 張素華, 程春雷, 鄒靜, 彭琳
(江西中醫藥大學計算機學院, 南昌 330004)
中醫辨證主要依賴臨床專家依靠感官收集四診信息,在中醫理論指導下,利用四診信息對證候歸屬進行判斷[1]。辨證是中醫認識疾病的基本原則,是中醫對疾病的一種特殊的研究和處理方法,也是中醫學區別于其他醫學的重要特征[2]。
縱觀整個中醫辨證發展脈絡,中醫辨證的研究方法可歸納為知識工程、數理統計法、傳統的機器學習方法和深度學習四大類[3]。知識工程主要是利用規則的方法進行辨證,但規則較多時則容易出現規則前后矛盾的現象[4]。知識圖譜是以圖的形式表現客觀世界中的實體、概念及其之間關系的知識庫。將知識圖譜應用于醫療決策是目前的研究熱點[5]。嚴冬等[6]收集了78例患者在北京中醫藥大學東直門醫院腦病科就診的病歷資料,對其進行主成分分析與聚類分析。王偉杰等[7]采用前瞻、多中心的橫斷面觀察性研究方法對302例類風濕關節炎患者病歷數據進行邏輯回歸分析。這類數理統計的方法在單一疾病的辨證效果尚好,但很難滿足真實臨床中多種疾病多個證候相兼的情況。許立輝等[8]采用基于關聯規則優化的FP-Growth算法,構建了中醫證候關聯分析模型。劉麗蓉等[9]提出了基于反向傳播(back propagation,BP)神經網絡和支持向量機方法,探討并構建了蕁麻疹證候分類模型,達到較好的效果。傳統的機器學習方法需要領域專家進行復雜的特征設計和提取,相對于其他研究領域,中醫領域數據類型繁雜、結構多樣并且缺乏統一的標準規范,如何保證數據集的質量面臨著巨大的挑戰。深度學習算法可從原始數據中自動提取特征,不需要研究者對領域知識有十分深入的了解[10]。張陽等[11]應用深度學習技術分析多囊卵巢綜合征患者不同的中醫辨證分型與生活方式,該研究數據量相對有限,結果可能有所偏差。許夢白等[12]收集關于不孕癥的中醫名醫病案300例,采用統計學注意力神經網絡模型構建不孕癥中醫辨證模型。然而,該研究所采用的數據僅為文獻病案數據,樣本量較小,模型在低質量數據中會產生偏移。
臨床上的中醫病歷文本數據在中醫四診(望診、聞診、問診、切診)的觀測角度不同,各方面的特征表達存在差異。例如,問診部分的“睡眠欠佳經年”與現代醫學語言相近;脈診部分的“略細弦澀,右寸略浮,尺沉稍有力,左關略軟”主要根據三部九候的方法對脈象要素進行描述;舌診部分的“舌質正紅,尖略紅,苔薄白”主要觀察舌質與舌苔的變化;望診部分的“形體偏瘦”多用于描述面色、皮膚、身材。模型通過對四診信息多通道的分開處理,訓練更為合理。
與此同時,中醫電子病歷缺乏高質量語料,模型訓練容易欠擬合。例如,脈診與舌診字段描述較全,但描述區分度較低;聞診字段則空缺信息較多等。此外,針對一個特定病案,雖然中醫病歷文本數據中四診觀測角度不同,但各觀測角度所得癥狀存在知識關聯。例如,某病案的問診部分的“睡眠欠佳經年”和望診部分的“形體偏瘦”具有關聯性。加入人工知識圖譜,可對模型訓練進行知識的增強。
通過上述分析,現提出融合知識圖譜的多通道中醫辨證模型。鑒于中醫辨證結果存在多種證候相兼的情況,對中醫電子病歷證候字段進行處理,構造中醫電子病歷多標簽分類數據集。人工構建小規模知識圖譜,訓練知識圖譜嵌入向量。對模型中標簽注意力部分改進為多通道結構,并將知識圖譜嵌入向量嵌入模型中,從而提高癥狀識別效果。
1 融合知識圖譜的多通道中醫辨證模型
臨床上的中醫病歷文本數據訓練和測試的樣本在脈診、舌診、望診、聞診和問診的觀測角度不同,各方面的特征表達有所差異。針對一個特定病案,雖然中醫病歷文本數據中觀測角度不同,但是各觀測角度所得癥狀存在關聯。中醫電子病歷缺乏高質量語料,模型訓練容易欠擬合。根據這些特點,提出融合知識圖譜的多通道中醫辨證模型。模型整體結構如圖1所示,該模型包括以下4個模塊。
(1)特征提取模塊。通過多個雙向長短期記憶網絡(bi-directional long short-term memory,BiLSTM)初步提取上下文信息和淺層語義特征,得到可以特征互補的癥狀句子向量。
(2)知識圖譜嵌入模塊。人工構建小規模知識圖譜,訓練中醫實體與關系的嵌入向量,得到更豐富的語義特征。
(3)模型融合與預測模塊。將特征提取模塊和知識圖譜嵌入模塊進行融合,進行算法的學習與預測。
(4)隨機加權平均模塊。使用隨機加權平均算法[13]進行模型的集成與優化,提高模型的泛化能力。
1.1 特征提取模塊
為了獲取文本的序列信息,選取基于反饋機制的BiLSTM提取特征信息,hi為雙向長短期記憶網絡i時刻的輸出向量,其表達式為
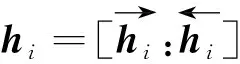
(1)
注意力權重αij的學習通過在原始的網絡結構中增加一個前饋網絡實現。這一前饋網絡的注意力權重的值αij是輸出隱藏向量hi和標簽隱藏向量wj的點積,其表示形式為
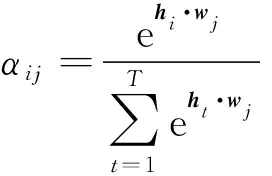
(2)
式(2)中:t為文本某個字符;T為文本長度。
標簽注意力模塊能夠自動地學習權重αij來捕捉癥狀字符和證候字符的相關性,學習所得的注意力權重將會被用來構建某一個特征向量。在j標簽時,注意力輸出向量kj的表達式為
(3)
基于多通道的方法借鑒集成學習思想,它訓練多個特征并整合,可獲得比單個特征更好的性能[14]。鑒于中醫電子病歷豐富的四診信息,文本將其應用于文本處理中,設置4個通道,對同樣的輸入
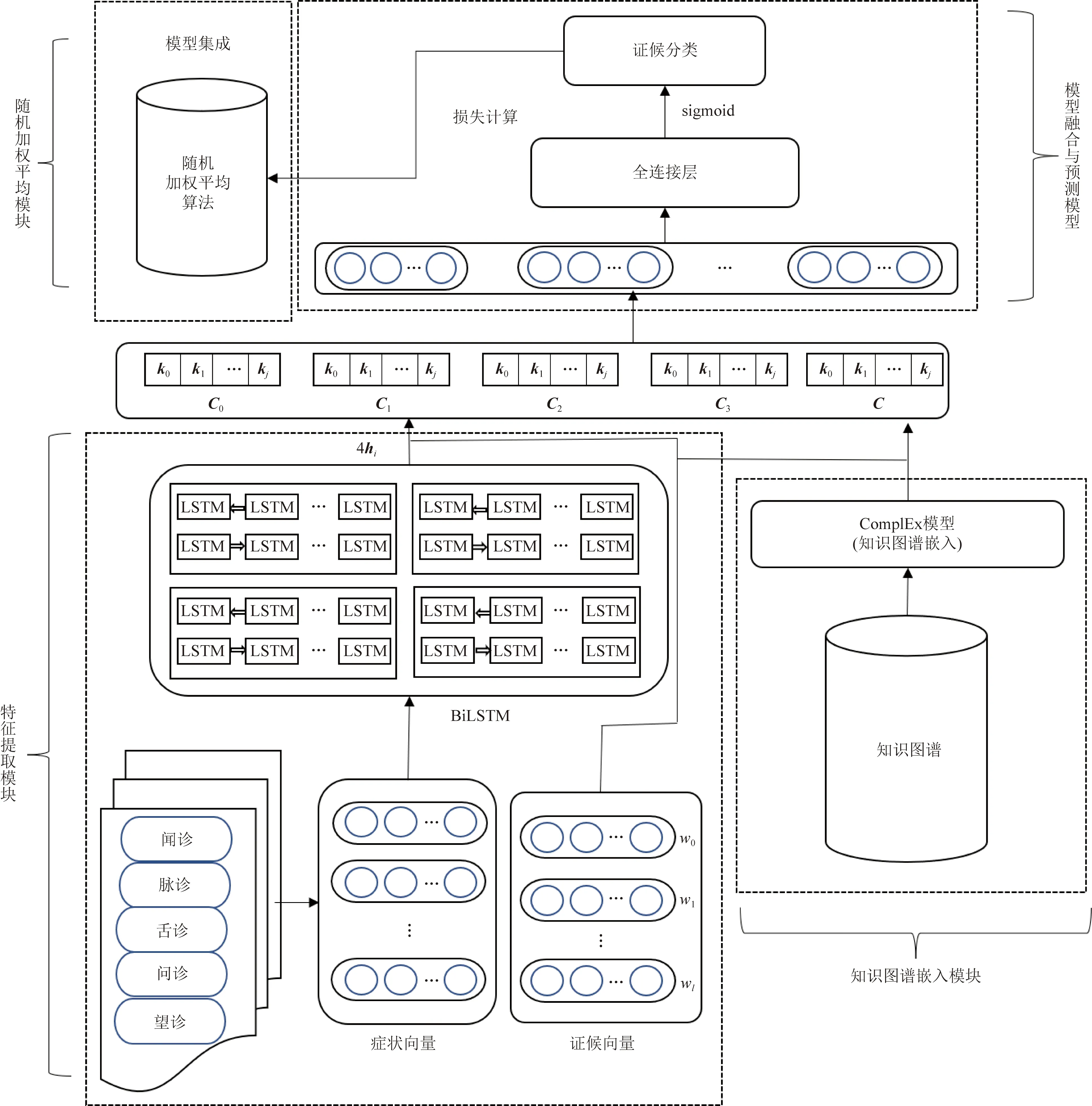
圖1 融合知識圖譜的多通道中醫辨證模型結構示意圖Fig.1 Structure diagram of multi-channel Chinese Medicine syndrome multi-label classification model based on knowledge graph
癥狀進行多種特征表示。如圖1所示,假設標簽數量為l,第i個通道中特征向量Ci表示為

(4)
式(4)中:k0為第0個標簽的注意力輸出向量;k1為第1個標簽的注意力輸出向量,以此類推。Ci∈Rl×m,i∈{0,1,2,3},m為標簽向量維度。
1.2 知識圖譜嵌入模塊
1.2.1 知識圖譜構建
為了學習癥狀之間的內在關聯,構造了基于中醫電子病歷的知識圖譜。實體抽取后得到八類實體:脈診、舌診、聞診、望診、查體、中醫診斷、護理宜忌和證候結論;十五類關系:脈診表現、舌診表現、聞診表現、望診表現、查體表現、證候結論表現、護理宜忌表現、中醫診斷表現、脈診-證候結論、舌診-證候結論、聞診-證候結論、望診-證候結論、查體-證候結論、證候結論-護理宜忌、證候結論-中醫診斷。
按中醫診斷的邏輯“辨證”,首先通過脈診表現、舌診表現、聞診表現、望診表現、查體表現、證候結論表現、護理宜忌表現、中醫診斷表現來對圖譜中8個類別的實體進行匯聚;然后在已有8類實體基礎上結合關系:脈診-證候結論、舌診-證候結論、聞診-證候結論、望診-證候結論、查體-證候結論、證候結論-護理宜忌、證候結論-中醫診斷,使用Neo4j構建圖譜,總計構建八類實體共202 619個,15類關系,總計1 499 457個三元組。部分知識圖譜展示如圖2所示。
1.2.2 知識圖譜嵌入
知識圖譜嵌入是將知識圖譜中的實體和關系進行向量表示,主要用于補全知識庫的知識,但也可用于知識問答、推薦、語義檢索、文本信息增強。
根據評分函數,嵌入技術大致分為兩類:平移距離模型和語義匹配模型。對于中醫領域,平移距離模型更關注中醫關系的多樣性。語義匹配模型更關注中醫實體和關系的深層次交互信息。在語義匹配模型中,RESCAL模型[15]將知識圖譜的三元組編碼為張量,通過點積形式的評分函數來衡量實體和關系的語義相關性。為解決隨著知識圖譜的擴增而導致RESCAL模型計算效率較低的問題,DistMult模型[16]將Mr限制為對角矩陣,通過雙線性對角模型學習實體和關系的向量表示。
用嵌入向量的點積作評分函數,可以處理關系的對稱性、自反性和非自反性,通過恰當的損失函數還可以實現其傳遞性。然而,實數向量之間的點積計算具有交換性,DistMult模型不適用于處理三元組反對稱的關系。ComplEx模型[17]在DistMult模型基礎上引入復數向量的方法捕捉反對稱關系,同時保留點積的效率優勢,即空間和時間復雜性的線性。
選用更關注實體和關系深層次交互信息的ComplEx雙線性模型。該模型中引入復數方法,可解決除對稱、非對稱外更復雜的對稱類型,更能表達中醫實體與關系的復雜性。定義事實的評分函數為
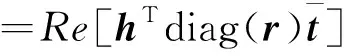

(5)
1.3 模型融合與預測模塊
將多通道特征向量和知識圖譜嵌入向量輸入一個完全連接層和一個輸出層中,利用sigmoid函數進行概率預測,標簽j的概率為
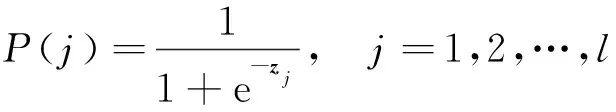
(6)
式(6)中:z為輸出向量;l為標簽數量。模型使用二進制交叉熵作為損失函數,該損失函數與sigmoid非線性激活函數匹配。損失函數的計算公式為
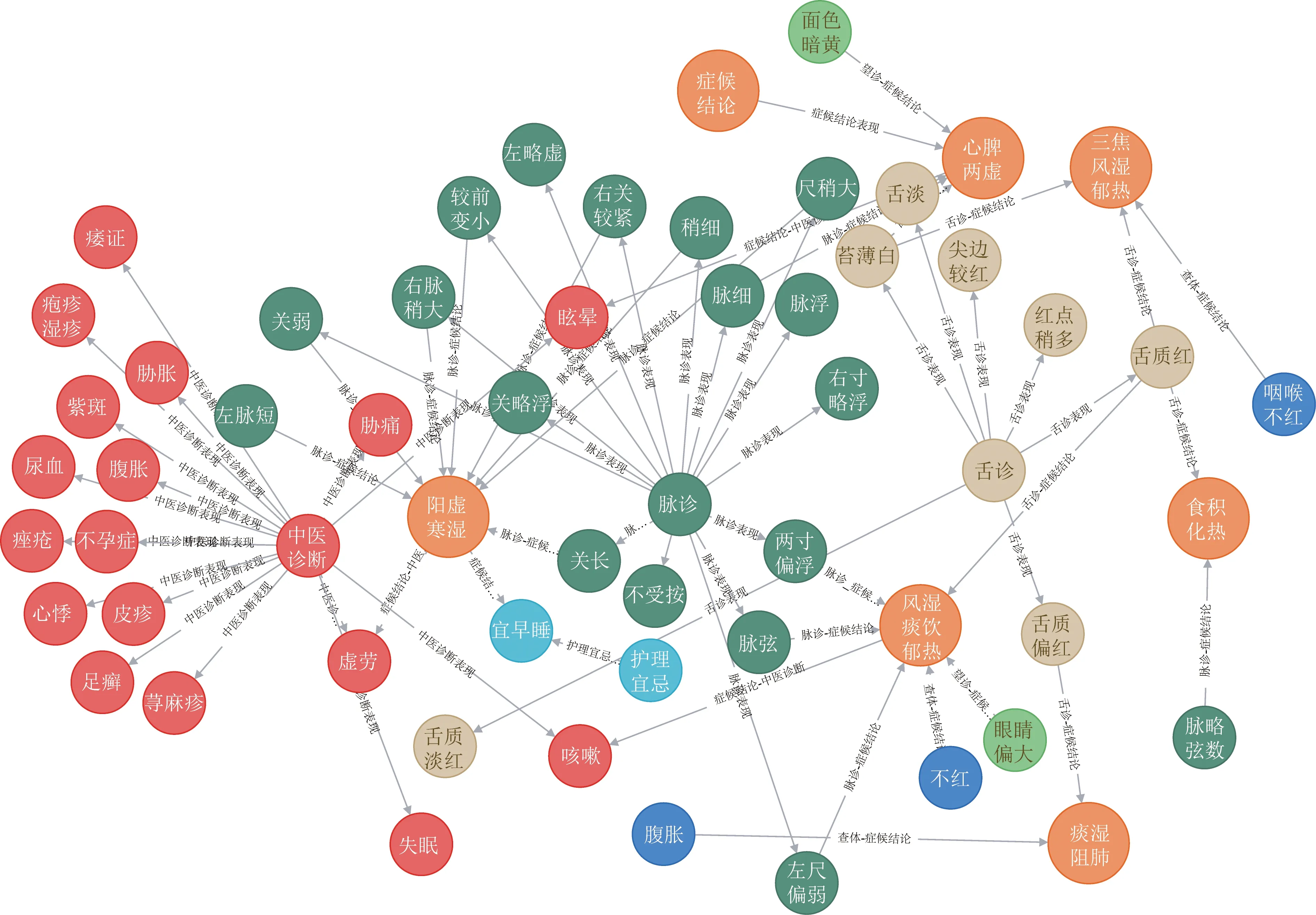
圖2 中醫電子病歷部分知識圖譜Fig.2 Part knowledge graph of Chinese Medicine electronic medical record
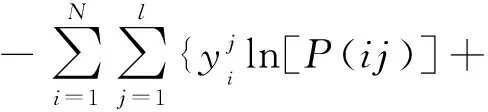
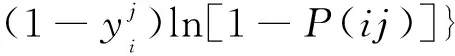
(7)

1.4 隨機加權平均模塊
隨機加權平均算法(stochastic weight averaging,SWA)與模型集成方法接近,但其計算損失更小。隨機加權平均算法的觀點來自經驗觀察,即每個學習速率周期結束時的局部最小值都傾向于在損失平面上損失值低的區域邊界處累積。通過平均化邊界點的損失值,可得到具有更低損失值、泛化性和通用性更好的全局最優解。模型平均權重參數更新方程為
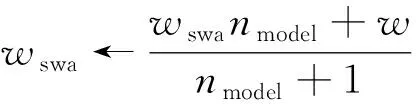
(8)
式(8)中:wswa為模型權重的平均值;w為模型初始化權重或模型經隨機梯度更新后的權重;nmodel為模型數量;←表示賦值更新。
2 實驗
2.1 實驗環境
實驗運行環境:算力為NVIDIA T4(6 核 CPU 30 GB 內存,50 GB 工作空間)、17.18 GB 顯存;編程語言為python 3;深度學習框架為pytorch。
2.2 實驗數據
實驗數據來自江西中醫藥大學岐黃國醫書院臨床中醫電子病歷,診斷時間為2009年12月—2019年5月,共有131 651條。該臨床中醫電子病歷字段包括:就診編號、病歷編號、診次、掛號流水號、脈診、舌診、一般情況、望診、聞診等共72個字段。經與專家探討與對電子病歷統計分析,選取脈診、舌診、望診、聞診、主訴(問診)等癥狀作為輸入特征字段,選取證候(癥候)結論作為標簽。部分病歷數據如圖3所示。
各字段存在缺失值,剔除證候結論字段空缺數據,剩余107 958條。證候標簽處理參考文獻[18],證候標簽處理例子如圖4所示。將證候結論部分的數據字段以標點符號分割開,形成多個證候標簽。若部分數據片段包含其他虛詞或無意義詞,用正則表達式的方法進行替換,處理過程主要依托python編程實現。最后,中醫電子病歷數據證候標簽總數為3 559類,每條病歷平均標簽數為5.06條。
2.3 評價指標
參考文獻[20],確定選用P@k(k處的精度,k=1,3,5)和N@k(k處的歸一化折損累計增益,k=1,3,5)兩個經典多標簽分類指標作為評估指標。P@k表達式為

(9)
式(9)中:rank(l)為第l個最高預測標簽的索引;yrank(l)為指示函數,判斷實際類別和預測類別是否一致;P@k為模型預測的前k個概率最大的結果里面含有正確標注的標簽的比例。N@k表達式如下。
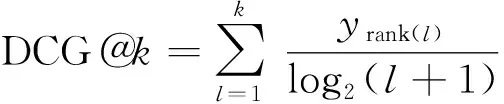
(10)
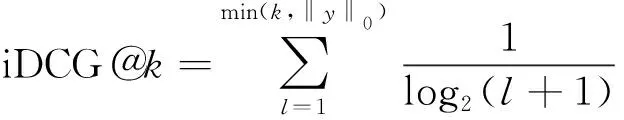
(11)
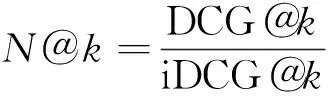
(12)
式中:log2(l+1)為對數衰減因子;‖y‖0為真實標簽中的數量;N@k為歸一化折損累計增益;DCG@k為折損累計增益,DCG@k令預測正確且排名靠后的證候比預測正確且排名靠前的證候取得更小的精度。N@k是用于排名的度量,N@k相比P@k考慮到位置的評價信息。
2.4 參數設置
實驗超參數設置如表1所示。

表1 實驗參數設置Table 1 Experimental parameter settings
2.5 實驗結果與分析
2.5.1 模型對比實驗
為了評估模型的性能,將本文模型與XML-CNN模型[19]、Attention XML模型[20](基線模型)、BERT模型[21]做對比實驗。其中XML-CNN模型屬于卷積神經網絡結構,Attention XML模型屬于循環神經網絡結構,BERT模型屬于Transformer結構。所有模型數據均以107 958條病歷數據進行實驗,訓練集與測試集按8∶2比例進行劃分,即數據量均分別為86 367條和21 591條,實驗結果見表2。
從表2實驗結果可以發現,XML-CNN模型由于較難捕捉到文本序列信息,對本文標簽數量大的電子病歷數據集表現不佳。Attention XML模型通過長
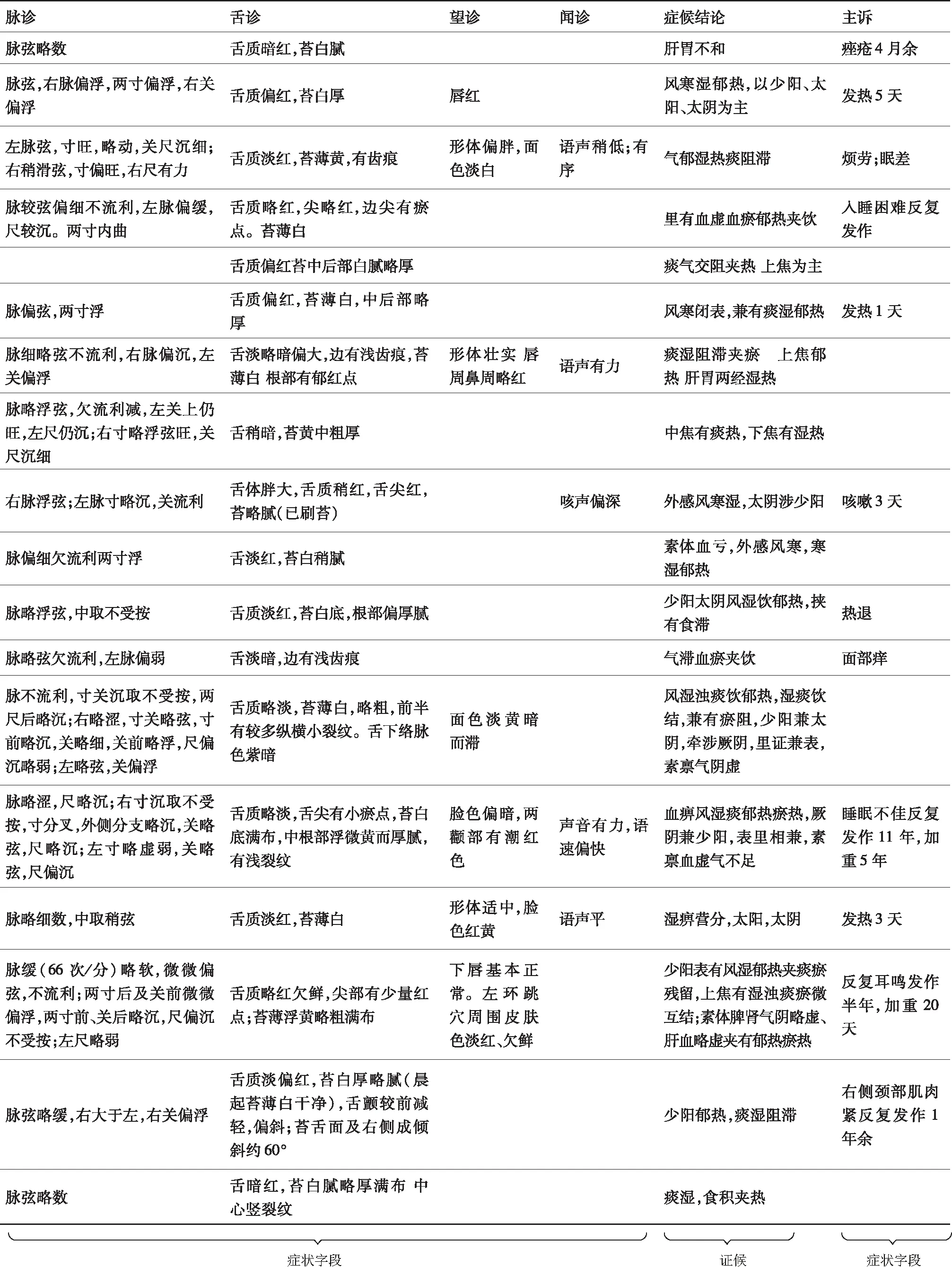
圖3 部分病歷數據Fig.3 Part of the medical record data
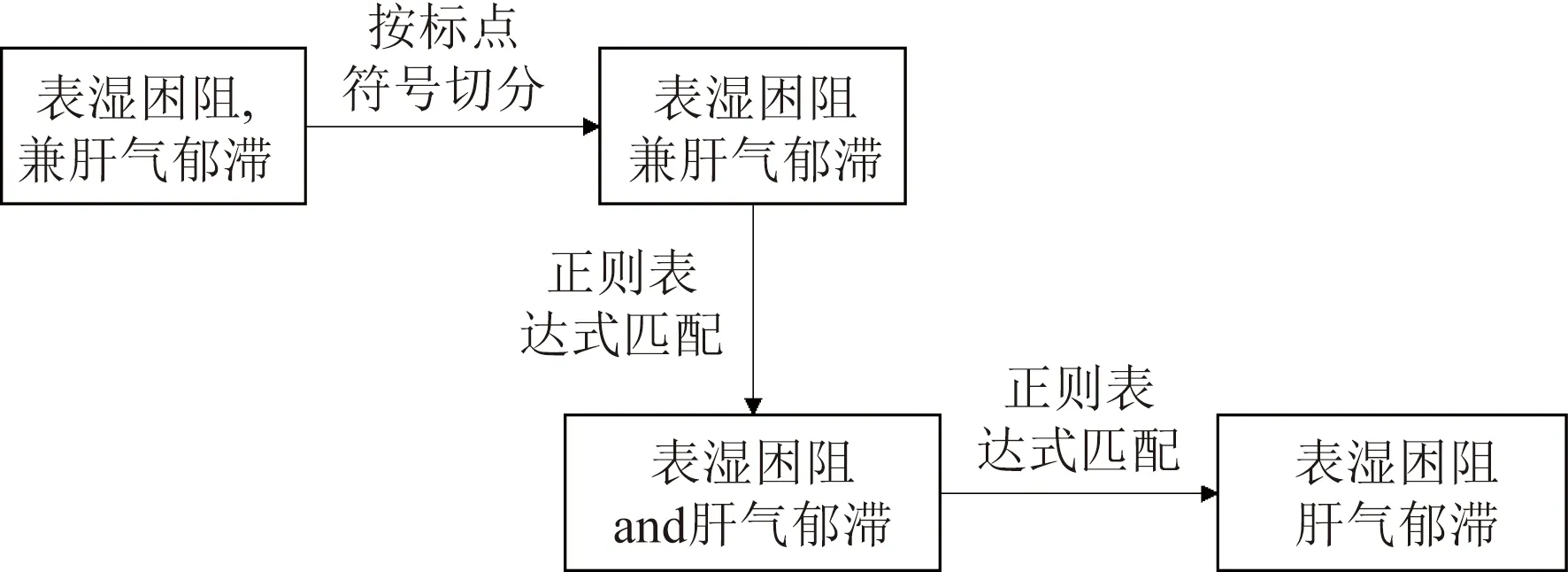
圖4 證候標簽處理過程示例Fig.4 Example of syndrome label processing process

表2 不同模型實驗對比結果Table 2 Comparison results of different model experiments
短期記憶網絡獲取文本序列信息,使用多標簽注意力機制融入標簽信息捕捉重要的癥狀特征,達到更好的多標簽分類效果,P@1指標相比XML-CNN模型提高11.04%。BERT模型相比XML-CNN模型有更好的實驗結果。但中醫電子病歷語料與通用語料存在一定差異,基于通用語料訓練的BERT模型預測結果精確度略差于Attention XML模型。針對病歷數據集中癥狀相互聯系和不同觀測角度的特征表達不同的問題,對模型中標簽注意力部分改進為多通道結構,并將知識圖譜嵌入向量嵌入模型中。本文模型在P@1指標上相比Attention XML模型提高3.51%,達到更好的實驗效果。
2.5.2 數據量差異實驗
為驗證數據量大小對模型的影響,將本文模型和Attention XML模型(基線模型)進行數據量差異對比實驗。實驗結果如表3所示。
可以看出,相比Attention XML模型,本文模型除5.8%數據的P@5略微降低,其他指標均有所提高,證明本文模型的模型效果更好。
相比Attention XML模型,本文模型在P@1指標上在百分比為5.8%、34.7%、58%、100%,電子病歷數據集上分別提高0.71%、1.06%、1.61%、3.51%。證實隨著電子病歷數據集百分比提高,本文模型提高的效果更顯著。
2.5.3 模型結構分析
為驗證模型結構的有效性,將本文模型拆解成4種結構模型:I(單通道模型);II(單通道及知識圖譜嵌入模型);III(多通道模型);IV(多通道及知識圖譜嵌入模型)。評估結果如圖5所示,可以得到以下結論。
(1)由I和III結果可知,多通道標簽注意力結構通過特征互補能更好地識別四診特征,使模型達到更好的效果。
(2)由I和II結果可知,知識圖譜嵌入結構可梳理癥狀間的關系,提高模型效果。
(3)由III和IV結果可知,知識圖譜嵌入結構在N@1提升效果較大,在N@3和N@5則持平或略有下降,說明知識圖譜嵌入結構使模型更趨向于預測出最優的結果。
2.5.4 通道可視化與辨證案例分析
將“口腔潰瘍反復多年。弦緩略滑舌偏胖嫩而暗,苔平”這條癥狀輸入預測模型中,并截取模型中多通道注意力層的癥狀字符權重,熱力圖如圖6所示。由圖6可知,第一個注意力通道更偏重于“苔平”,而第二、四個注意力通道更關注“口腔潰瘍”。由此可見,多通道標簽注意力可以獲取更多特征,能更好地實現特征互補。
抽取5個病歷特征描述輸入預測模型中,預測結果展示如表4所示,粗體為預測正確結果。在第1個例子中,模型完全預測正確,其“血糖高”字眼有更強的區分性。在第2個例子中,模型得到“略有風寒”這個與“風寒引動”證候含義相近的證候結論,原因是知識圖譜嵌入模型訓練中醫實體與關系,使得嵌入向量具有更豐富的語義特征,進而使預測模型得到含義相近的證候類型。在第3、4、5個例子中,預測結果均是部分預測正確,部分預測錯誤的預測結果,說明本文模型及其數據質量仍需要改進。總體而言,從標準證候與預測證候的結果對比可知,模型預測效果良好。
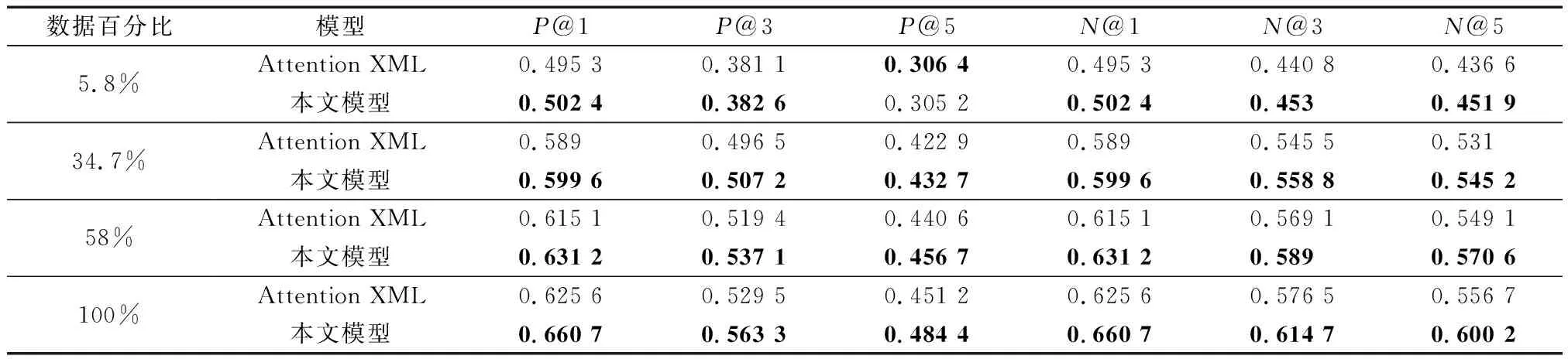
表3 數據量差異對比實驗Table 3 Data volume difference comparison experiment

圖5 結構評估結果對比Fig.5 Comparison of structural evaluation results

圖6 多通道標簽注意力結構的癥狀特征捕捉熱力圖Fig.6 Multi-channel tag attention structure symptom feature capture heat map

表4 辨證案例Table 4 Dialectical case
3 結論
針對中醫電子病歷高質量語料缺乏,以及病歷樣本在不同觀測角度的特征表達差異和同一病歷的癥狀存在關聯的特點,構建了融合知識圖譜的多通道中醫辨證模型。實驗顯示,基于中醫電子病歷數據集,本文模型在P@1指標、P@3指標、P@5指標上相比基線模型分別提高3.51%、3.38%、3.32%。模型表明,引入涵蓋專家經驗的知識圖譜既有知識對于中醫藥領域人工智能決策是一個不錯思路。
在未來工作中,中醫證候較難規范統一,導致任務處理標簽巨大。如何基于病歷病案現狀,提升模型決策效率,實現更為可行的輔助診斷,仍需進一步分析研究。總體來說,中醫辨證研究是中醫學科的核心問題之一,值得更多的探索。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
核科學與工程(2015年4期)2015-09-26 11:59:03
