基于集成學習的電動汽車充電站超短期負荷預測
2022-08-25 08:52:24李恒杰朱江皓傅曉飛梁達明
上海交通大學學報 2022年8期
關鍵詞:模型
負荷預測對于智能電網的可靠性運維和有效管理至關重要.對充電負荷進行超短期精確預測是提高充電站安全經濟運行的重要措施,還能為智能電網的安全監測、成本控制、調控決策提供重要依據,同時也是充電基礎設施投資新建、充電站容量擴充與規劃決策的有力支撐.在電動汽車還未大規模并入電網時,對能源系統中的負荷進行預測已經有20多年的發展歷史,研究方法主要有兩類:一類是基于數學預測模型的傳統預測方法,包括趨向外推法、彈性系數法、時間序列法、線性回歸法等,主要基于線性關系構建,忽略了氣候、日期類型等因素對超短期充電負荷預測的影響,預測準確率較低;另一類是機器學習類算法,包括決策樹、神經網絡、集成學習、深度學習等.
在全生育期注意防治螟蟲、紋枯病等病蟲害。在抽穗期注意防治稻粒黑粉病和稻曲病。一般在破口期、見穂期和齊穂期用克黑凈或愛苗各防治1次。
近年來,基于機器學習的電力系統負荷預測方法因其越來越高的精度,已成為負荷預測領域的熱點.文獻[7]通過條件生成式對抗網絡(Conditional Generative Adversarial Network, CGAN)對抗學習復雜的非線性數據之間的聯系,減少了特征值的偏差,提高了預測精度,但訓練數據僅包含單一類型數據,缺少泛化能力.文獻[8]結合降噪自編碼器、奇異譜分析和長短期記憶神經網絡構建綜合電力預測模型,降低了噪聲干擾,提高了預測精度,但模型較為復雜,對平臺算力有較高要求.文獻[9]使用反向傳播網絡人工神經網絡(Back Propagation-Artificial Neural Network, BP-ANN)提取數據特征向量,卷積神經網絡(Convolutional Neural Networks, CNN)提取圖像特征,通過多層BP-ANN進行短期預測,但模型訓練時間過長,難以部署.文獻[10]將改進的隨機森林與密度聚類組合,通過疊加各分量預測值來獲取負荷預測值,但模型構建復雜,泛化能力較低.文獻[11]構建道路模型,通過Dijkstra路徑尋優算法在出行鏈上預測電動汽車(Electric Vehicle, EV)充電負荷概率密度函數,但時間尺度長,無法面對超短期的負荷預測.
近些年來我國的公路里程不斷創下歷史新高,公路建設規模不斷擴大,這就對公路工程建設提出了新的挑戰。面對日益復雜的公路工程建設環境,只有嚴格做好公路工程質量的管理工作,才能夠確保良好的工程質量。
考慮到超短期充電負荷預測問題數據的大體量、高時效、高計算資源要求等因素的影響,本文使用集成學習(Ensemble Learning, EL)進行超短期充電負荷預測.一般的回歸性預測方法只考慮到天氣、溫度、濕度等因素的影響,并未考慮到電動汽車基礎設施需求的特異性.電動汽車充電負荷需求具有時空不確定性、隨機性,且電動汽車配置參數存在個性化差異,為超短期充電站負荷的精確預測帶來了挑戰.為解決上述問題,使用占用資源極低的輕量級梯度提升框架(Light Gradient Boosting Machine, LightGBM)構建基礎充電負荷,預測基礎回歸器群;為進一步提升預測精度,使用提升集成方法對基礎回歸器群進行集成,在經過多次迭代和超參數調整后構成最終的充電負荷預測模型.
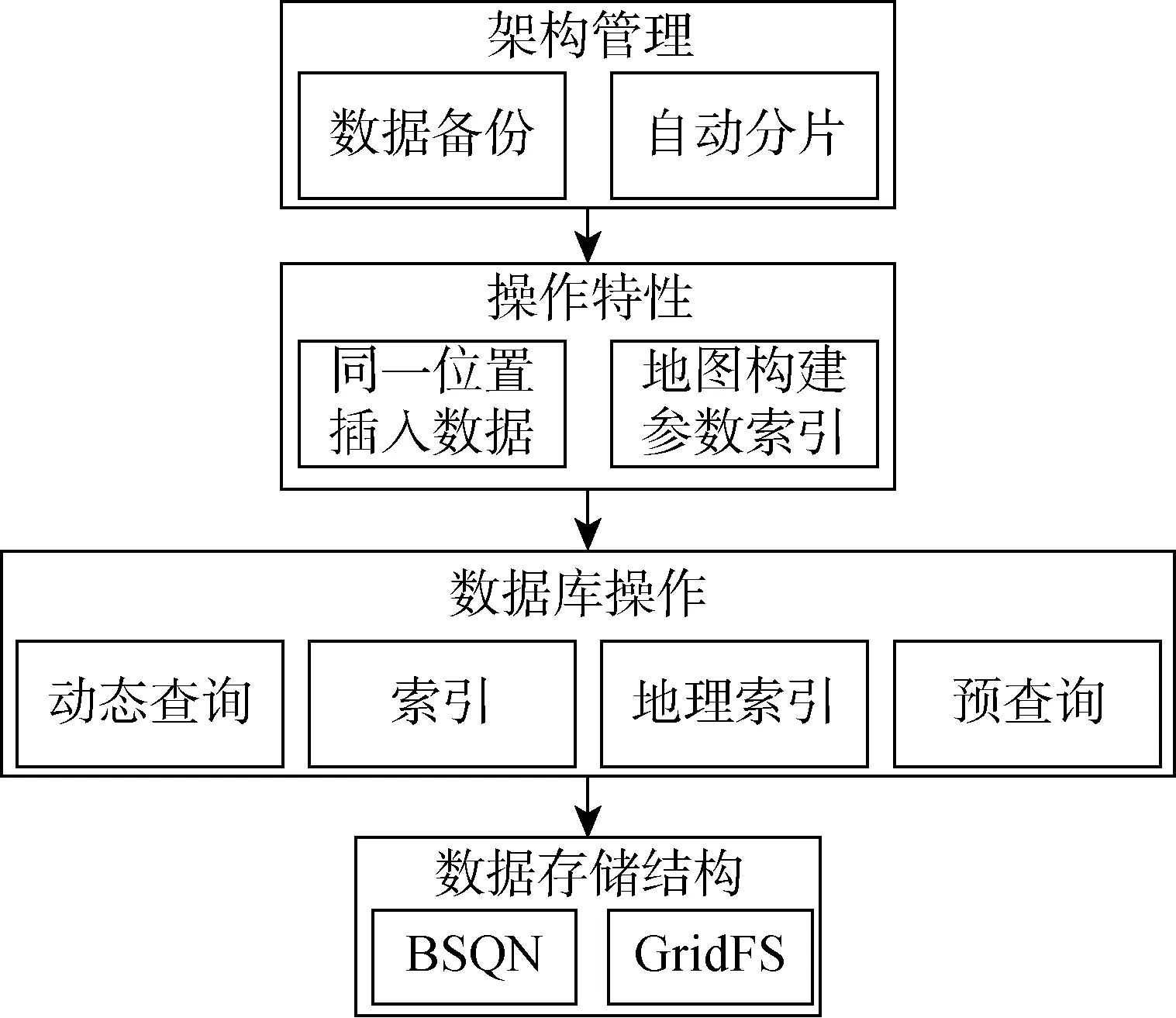
1 EEB-LGBM預測框架
能量集成輕量梯度提升框架(Energy Ensemble Boosting-Light Gradient Boosting Machine, EEB-LGBM)結構包括2層,即基礎回歸器群生成層和集成決策層.基礎回歸器群生成層的作用是學習構建后的數據集的特征,并生成數個具有差別的基礎回歸器構成基礎回歸器群.集成決策層的作用是對基礎回歸器群進行串行優化,在合并后輸出最終模型用于超短期充電負荷預測.EEB-LGBM預測框架的結構如圖1所示.結構中的各個參數及其意義如表1所示.
他注意到,隨著改革開放的深入,再加上醫生忙碌的客觀事實,關愛正在逐漸淡化。“我們希望鼓樓醫院的價值理念中多一點點關愛。而這種關愛不僅僅局限于父母親人,而是一種大愛,即關心服務的每位患者。”
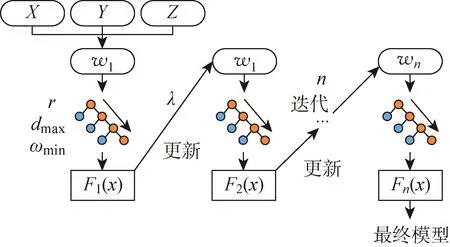

在EEB-LGBM預測框架中,初始的樣本劃分將影響因素、噪聲數據與真實充電負荷數據同步輸入進行訓練集劃分,并對每一輪生成的基礎回歸器的參數進行記錄,在下一輪時通過計算出的回歸權重不斷進行串行迭代并更新自身參數,以此不斷優化,最終集成為基于EEB-LGBM預測框架的超短期充電負荷預測模型.
在用該結構進行超短期充電負荷預測時,用實際充電負荷數據、影響充電負荷的相關因素和隨機噪聲數據構成原始數據集.將原始數據集進行權值劃分后用于訓練基礎回歸器,并搜索基礎回歸器的最優參數進行并行化優化,數個基礎回歸器構成基礎回歸器群進行多次迭代,最終集成為用于超短期充電負荷預測的最終模型,從而進行超短期充電負荷預測.
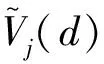
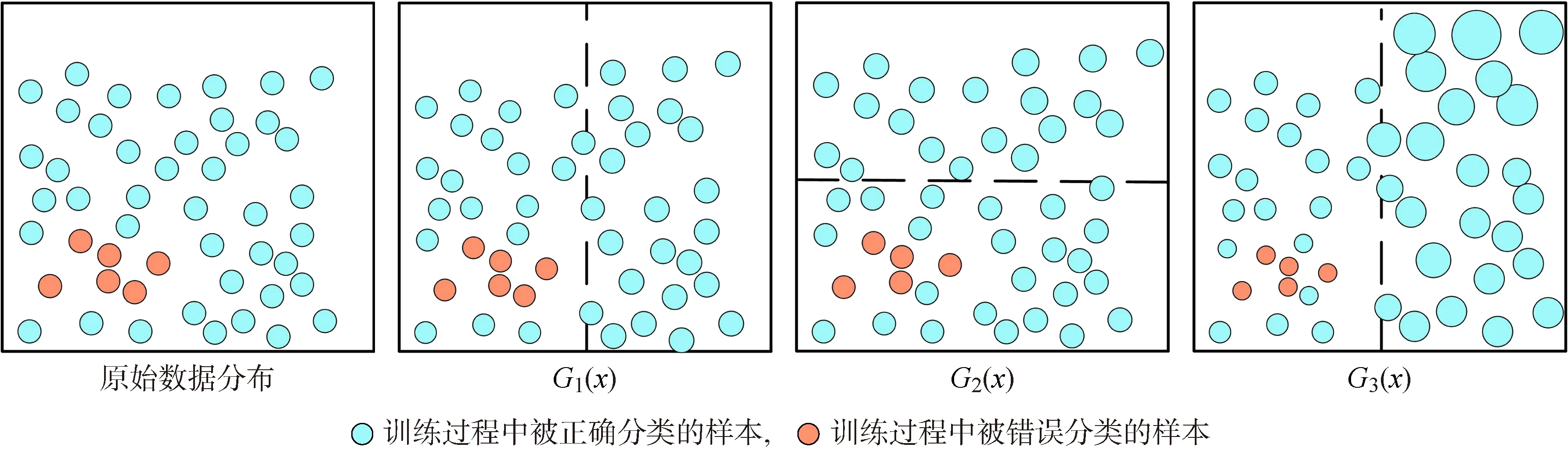
在整個集成過程中基本回歸器()錯誤回歸的樣本權值增大,而被正確分類樣本的權值減小,以此完成自我優化和糾錯,最終回歸模型的加權過程如圖2所示.


(1)

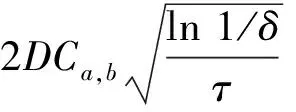
(2)
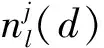
來自樣本和特征的擾動將增加基礎學習器的多樣性,有助于提高泛化性能,但同時也會導致訓練流程中誤差的疊加增大.為減小特征選擇時造成的誤差,同時避免重復特征和零特征構成的不必要計算,引入EFB特征選擇策略進行特征束的構建.通過向特征要素的原始值添加偏移來保證特征的排他性,使得駐留在不同的面元中的特征聚集,將具有排他性的特征捆綁到更少的密集特征上,以此構建特征束.
區內褶皺構造不甚發育,總體上表現為一向東偏南傾斜的單斜構造,由于應力作用的影響,局部可見到層間小揉皺構造及勾狀構造。
基礎回歸器群易受到偏差-方差權衡的影響,而使用自適應提升(Adaptive Boosting, Adaboost)方法進行集成,可以在維持模型方差和偏差平衡時增加模型的預測能力,避免因單一模型過于依賴訓練集,使得在測試集上測試與真實預測時產生回歸精度降低、結果失真等問題.在初始化構建完成數據集的權值分布后,對每一個基礎訓練樣本都賦予相同的權值:

利用數據挖掘技術分析HIF-1α在胃癌中的預后意義…………………………………孫美濤,自加吉,陳 瑩,嚴長寶,戴莉萍,余 敏,熊 偉(32)

(3)
=1, 2, …,
式中:為基礎回歸器的權重和;1為基礎回歸器的初始權值;為權值分布的數量.基礎回歸器框架對權值更新后的訓練數據集進行學習,得到原始回歸器為
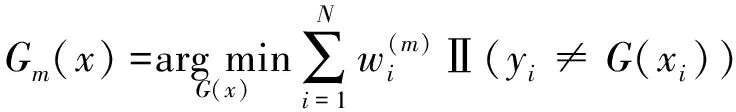
(4)
..影響充電負荷的條件因素 目前對于電力充電負荷預測研究大多考慮的氣象影響因素有溫度、濕度、降水、風向、風速等.但為了更加精細化和實時化地進行充電負荷預測,還需合并考慮連接時長、充電功率、車型配置、節假日等因素.本文使用 1~7代表星期一至星期日,節假日使用0和1進行二值化處理,車型分為純電、混動,同樣使用0和1進行二值化處理.
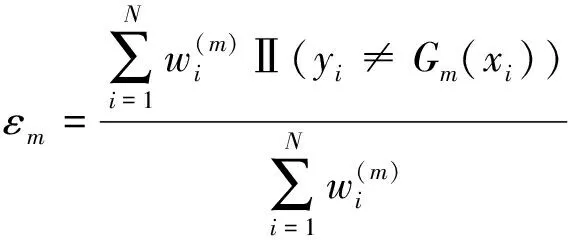
(5)
式中:為規范化因子.

(6)
根據回歸誤差率更改每個基礎回歸器的權重系數,預測表現更好的基礎回歸器具有更高的權重.之后更新訓練數據集的權值分布:
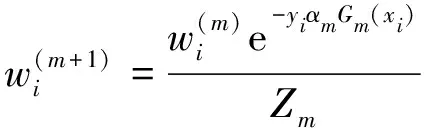
(7)

(8)
=1, 2, …,
每個基礎回歸器通過不同的權重系數集合為最終的回歸模型,()在最終回歸器中的權重系數為
在不斷更新迭代后,根據權值將1~的所有基礎回歸器集合為最終回歸器:

(9)
在推動水質不斷變好的同時,2004年,淳安出臺《關于加強千島湖生態漁業管理的若干意見》,加碼“保水漁業”的實施力度。
2 基于EEB-LGBM預測框架的超短期充電負荷預測模型
基于EEB-LGBM預測框架的超短期充電負荷預測模型主要包括數據集構建、回歸器集成和充電負荷預測結果輸出,其結構如圖3所示.
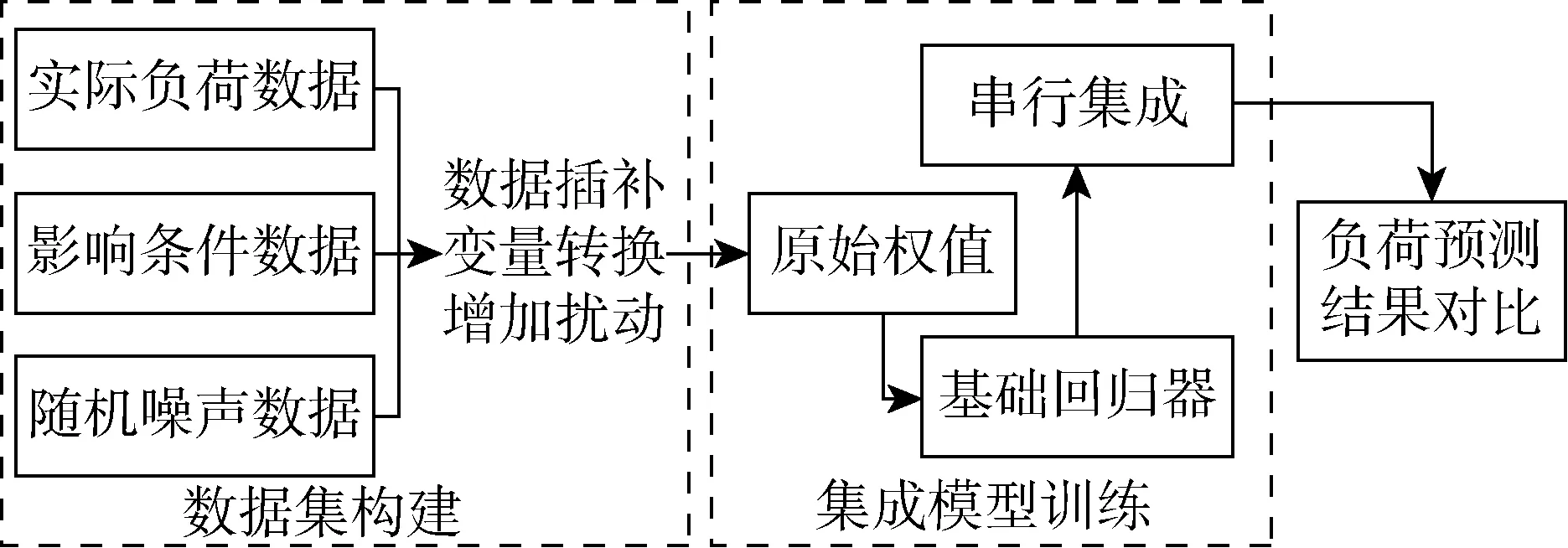
在構建數據集部分需要確定數據集的大小和特性,選用合適的方法進行數據清洗,為訓練部分劃分原始訓練數據.隨機噪聲數據為函數生成具有正態分布的變量,與原始訓練數據共同輸入后使得訓練后的模型具有更強的穩定性.充電負荷的影響條件包括氣候數據、日期類型數據、連接時長數據等.實際充電負荷數據為充電站監測得到的真實充電站充電負荷數據.在訓練超短期充電負荷預測模型的過程中,采用LightGBM結合提升結構生成最終模型,用于超短期充電負荷預測.首先,將實際充電負荷數據、影響條件數據、隨機噪聲數據同步進行數據清洗后輸入集成模型訓練部分劃分原始權值.其次,基于原始權值數據集生成數個基礎回歸器,以此構成基礎回歸器群后進行串行集成,在集成過程中不斷迭代優化,最終使得整個基于EEB-LGBM預測框架的充電負荷預測模型達到最優.
為了探究模型效果,使用訓練好的超短期充電負荷預測模型進行充電負荷預測,并與其他超短期充電負荷預測模型的預測結果進行對比.所有對比模型使用相同方法構建的初始數據集進行訓練,輸出1 d的預測曲線,并與真實值進行對比,觀察模型擬合度.進行對比實驗時,使用回歸決定系數()、平均絕對百分比誤差(Mean Absolute Percentage Error, MAPE)、均方根誤差(Root Mean Square Error, RMSE)、訓練時間(Time to Training, TT)作為評價指標,對比不同模型的性能.
2.1 數據分析與處理
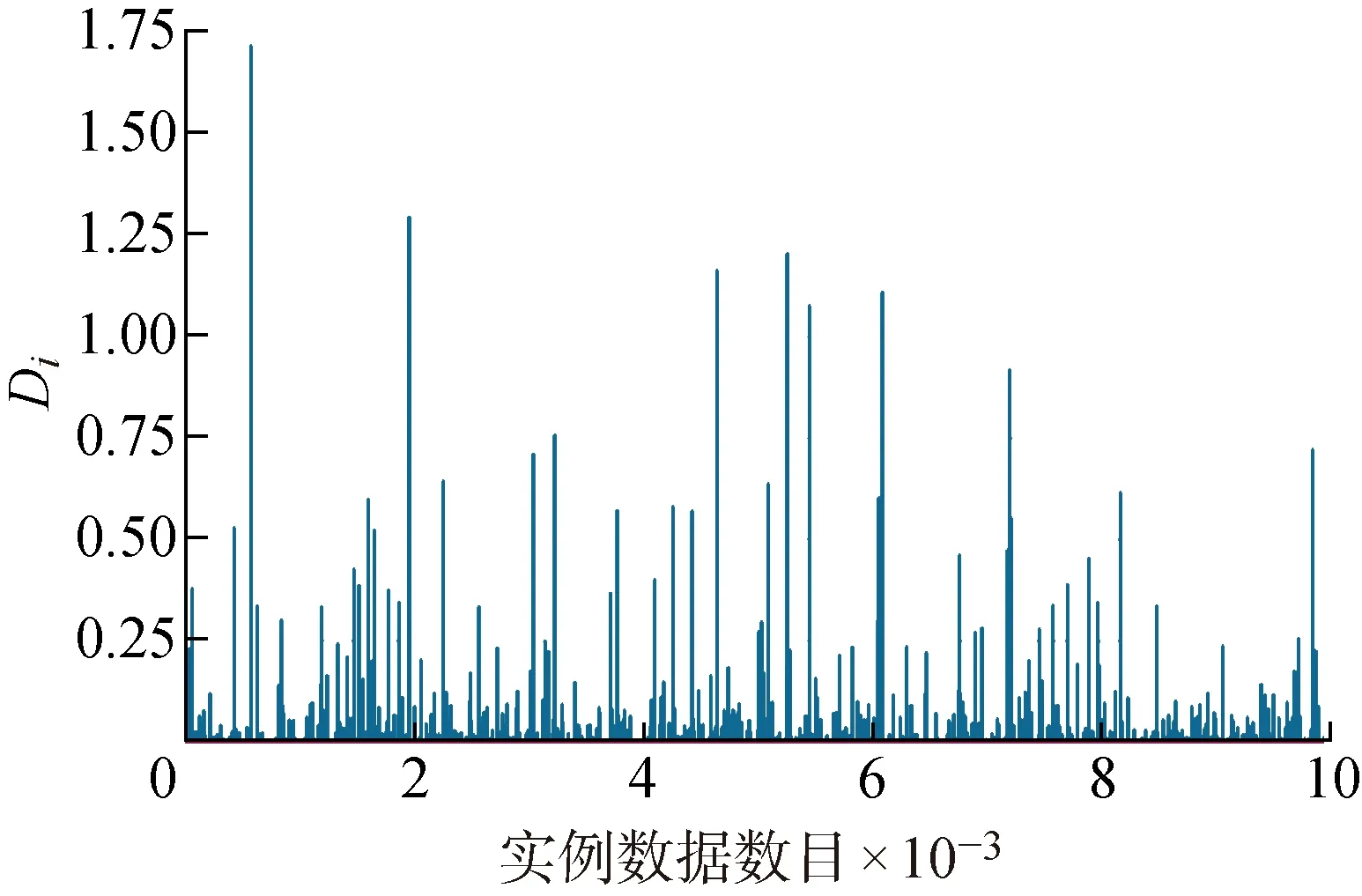
..實際充電負荷數據 實際充電負荷數據來源于充電站系統的實時采樣,單站10個采集點,超短期充電負荷預測輸出為未來24 h的充電負荷.為選擇合適的基礎回歸器群框架與集成方式,對數據進行庫克距離分析是有必要的.庫克距離分析常用在最小二乘回歸當中對數據點的影響進行評估,也可以用于檢查數據集當中不同數據點的影響力,其計算公式如下:

(10)
Previous papers have found that the prevalence of hospital undernutrition varies between 27% to more than 50% depending on the identification criteria, the medical or surgical setting and the age of the patients[6-10].
又寫作“牢絡”。《釋名·釋衣服》:“畱,牢也。幕,絡也。言牢絡在衣表也。”《釋名疏證補·釋衣服》:“先謙曰,留、牢雙聲。《淮南本經》注,除人讀牢為霤,霤從雨留聲。《士喪禮》注,牢讀為樓,樓、留聲近,皆其證也。絡、幕疊韻。”由此可知“牢絡”與“留幕”聲相近,義相通。高明《琵琶記·幾言諫父》:“名韁利鎖,牢絡在海角天涯。”《琵琶記·激怒當朝》:“羈縻鸞鳳青絲網,牢絡鴛鴦碧玉籠。”以上“牢絡”均有“覆蓋”之義。
回顧性分析2008年1月~2014年12月在本院接受手術治療的80例GustiloⅢA、B型脛骨開放性骨折患者的病歷資料。其中,27例接受非擴髓帶鎖髓內釘(unreamed tibial nail,UTN)固定,22例采用鎖定加壓鋼板(locking compression plate,LCP)固定,31例接受單側外固架(unilateral external fixator,UEF)固定。三組患者一般資料詳見表1,三組在年齡、性別、損傷機制等方面的差異均無統計學意義(P>0.05)。
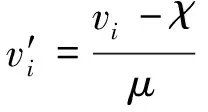
(11)

..數據預處理 在統一進行原始權值計算前,需要對數據集進行預處理,以便模型快速提取特征進行學習.對于缺失特征使用中位數估計函數插補,對于多級別特征根據輪廓系數標準使用均值聚類算法進行壓縮,對于插補完成的所有特征使用魯棒縮放將特征映射到[0, 1]區間上進行規范化,公式如下所示:
2.2 集成模型訓練與優化
基礎回歸器群框架的選擇對于最終模型的性能有較大影響,因此,對于所有適用于超短期充電負荷預測問題的共16種回歸模型,使用相同的經過預處理構建完成的數據集進行訓練,在相同的評價指標下進行對比.為適應超短期充電負荷預測問題,評價指標權重最大,生成時間次之,其他評價指標的權重依次減小.在所有框架中LightGBM框架在精確度上略微領先,但在訓練時間上表現出極大優勢,因此使用LightGBM框架學習數據集構建數個基礎回歸器.對于基礎回歸器群的單個基礎回歸器,以最優為目標進行多次迭代和參數優化,之后將優化好的基礎回歸器群輸入集成層.對于LightGBM框架選取生長最大深度、葉片節點個數、縮分實例、隨機部分特征、L1正則化、L2正則化等參數構建參數搜索空間.在超參數空間的參數搜索方法選擇樹狀結構帕仁估計(Tree-Structured Parzen Estimator, TPE)算法,首先根據損失函數對超參數進行排序,并使用分位數對全體超參數進行分組.分別對優化表現較好的超參數組和優化表現較差的超參數組進行核密度估計,給定較好組有更高的被選擇概率,較差組有更低的被選擇概率.最后,經過優化效果評估后繼續分組,不斷迭代,最終輸出經過最優表現超參數組合優化后的基礎回歸器群.為加快超參數搜索優化過程,對進行TPE算法搜索的超參數搜索空間使用MongoDB結構構建數據庫,轉為并行化搜索,進行超參數搜索過程優化,如圖5所示.
將經過優化的基礎回歸器群進行權重計算,以其中具有最大損失函數的回歸器為目標增大優化權重進行迭代,構建集成預測模型.同樣以最優為目標,以基礎回歸器群的最優數量、基礎回歸器的權重縮減系數、誤差函數計算方式為超參數,構建MongoDB結構的超參數存儲空間,使用TPE算法進行并行化搜索,進一步優化其預測精度構成最終的超短期充電負荷預測模型.
2.3 評價指標
回歸模型的評價指標決定系數比對稱平均絕對百分比誤(Symmetric Mean Absolute Percentage Error, SMAPE)、均方誤差(Mean Square Error, MSE)、RMSE、平均絕對誤差(Mean Absolute Error, MAE)和MAPE等更具信息量和真實性,并且沒有MSE、RMSE、MAE及MAPE對回歸模型進行性能評價時的可解釋性限制,甚至可以對比不同研究領域當中不同回歸模型的性能.因此在選擇基礎回歸器框架和集成框架時,給予更大的參考權重,在接近時同時參考MAPE、RMSE、TT等指標,各評價指標的計算公式如下:
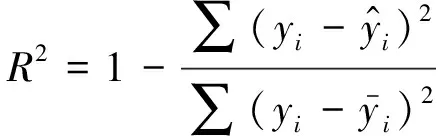
(12)
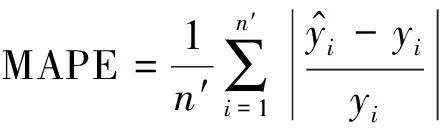
(13)

(14)
3 實驗結果及對比
3.1 實驗數據準備
使用Foundation E-Laad.nl(ElaadNL)在2019年實測某充電站的電動汽車充電負荷需求數據以及氣象、日期類型數據構建數據集.ElaadNL充電站包括充電樁、快速充電器、電池、充電燈和 IOTA 三相充電器,每相電流至少為16 A,充電功率為11 kW.充電站由不同的用戶群體共享,白天的用戶群體主要為辦公室工作人員,下午或晚上為游客,深夜主要為附近居民,同時還有一些特定的用戶群體,如出租車、共享汽車或市內物流.實測充電負荷數據集主要為連接類型、連接時長、充電功率、充電樁編號、總耗能,由充電站系統實時采集.溫度、濕度、氣壓等氣象數據采集頻率為1次/h,再合并隨機噪聲數據后構成原始數據集.其中70%為訓練集輸入模型進行訓練,剩余30%為測試集.對基礎回歸器群與集成方式都進行10折交叉驗證進行性能對比.
c)當C(px,y)==C(px-1,y)且C(px,y)==C(px,y-1)時, 表示塊px,y和上鄰域塊以及左鄰域塊之間均存在跨塊缺陷, 此時將上鄰域的標號賦值給塊px,y; 另外, 如果Label[x,y-1]≠Label[x-1,y]表明左鄰域和上鄰域的標號存在沖突, 需要將其記錄在等價標號關系表中。
3.2 模型構建實驗
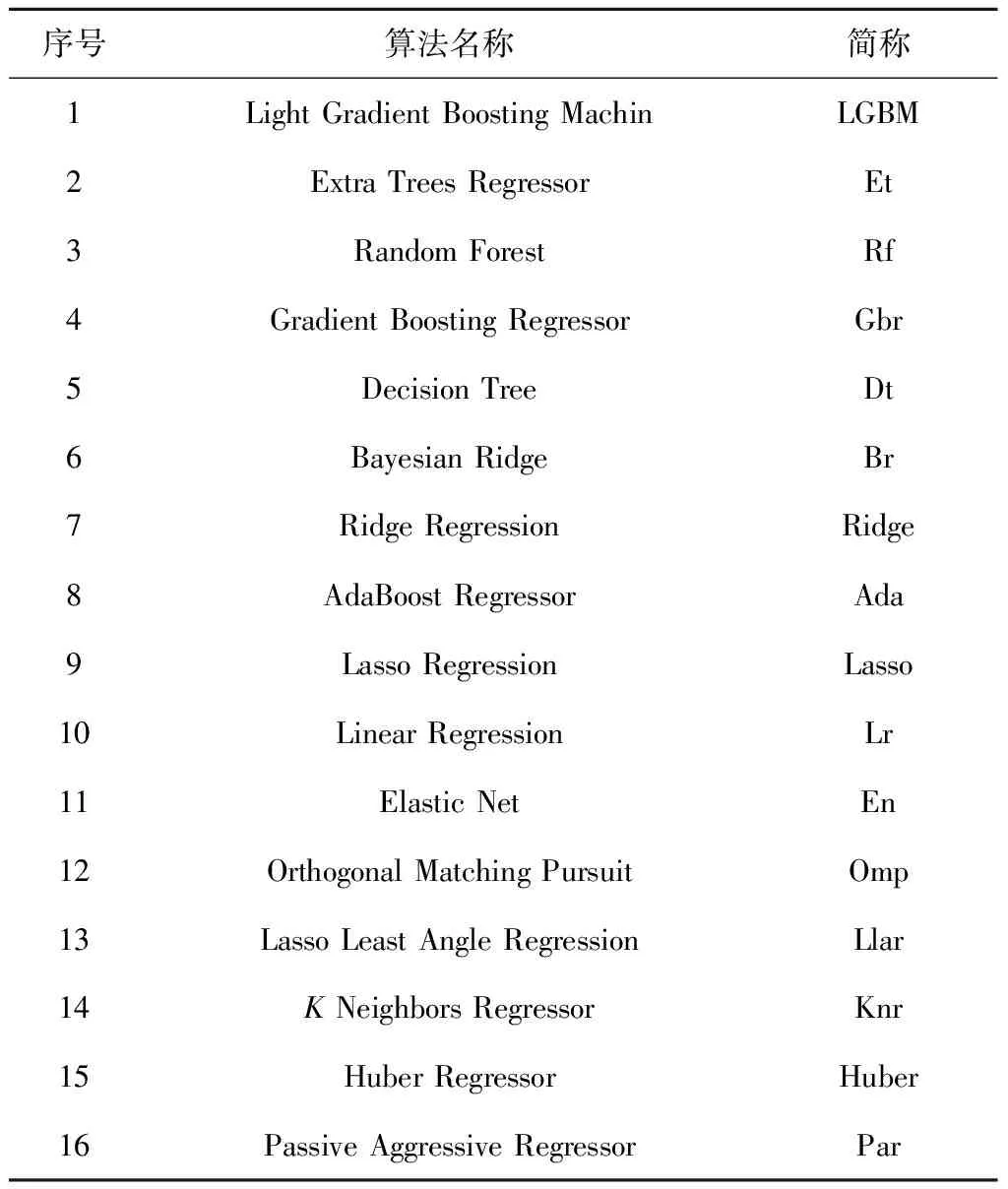
..基礎回歸器性能對比與選擇 在基礎回歸器群的構建過程中,針對充電站充電負荷的超短期回歸預測共選取了16種回歸算法構建基礎回歸器進行比較.這16種算法的全稱與對應簡稱如表2所示.選取的16種算法在構建后的相同數據集上進行訓練,使用10折交叉驗證在相同的測試集上驗證所有模型的性能,在相同指標下降序排列,其結果如表3所示.
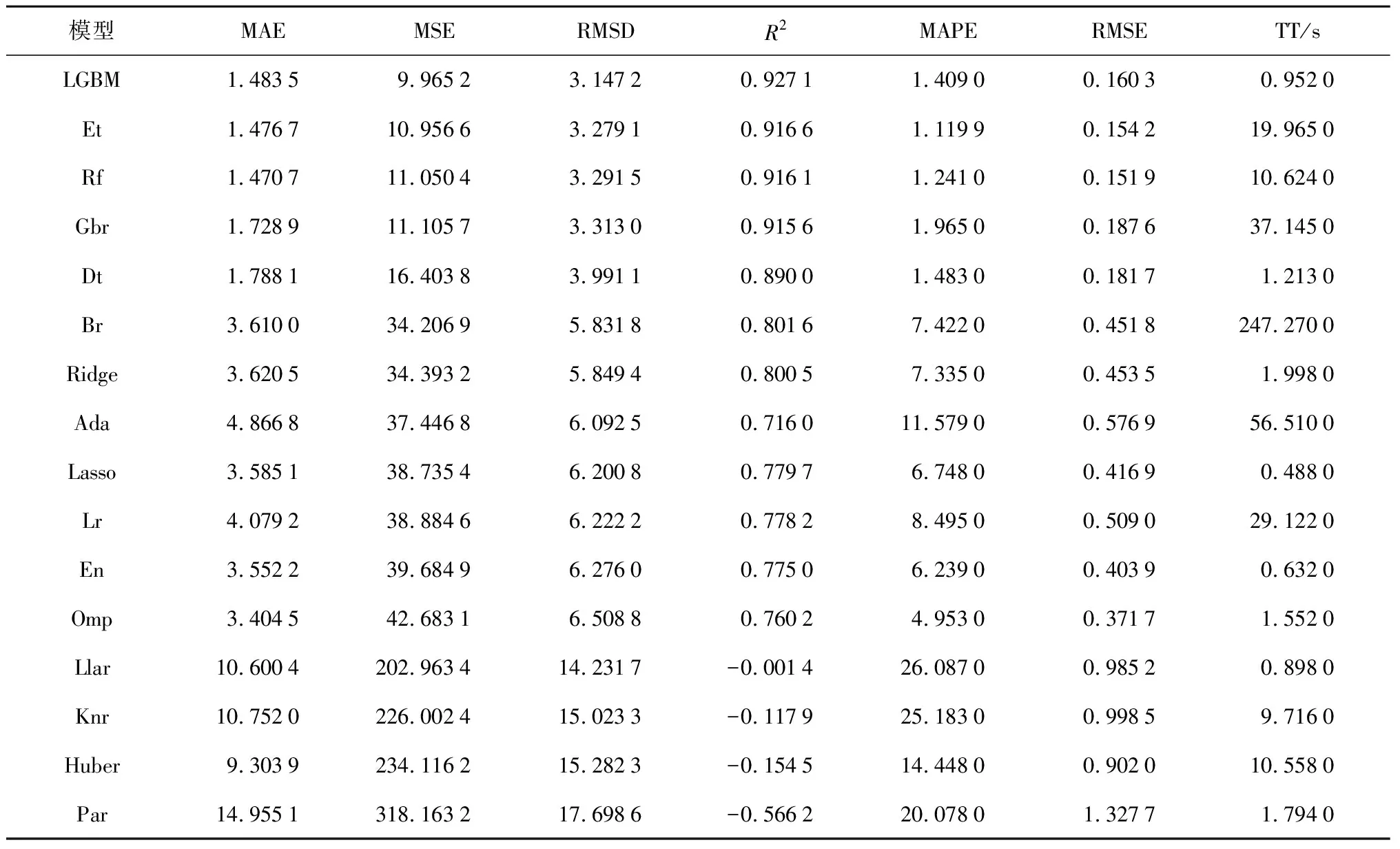
在充電站充電負荷超短期預測這一特定的應用場景上,LightGBM框架表現出極大優勢:在精確度領先的情況下,其訓練時間縮短為Et、Rf等算法的1/260~1/20,大幅增加了調控速度,更適合面對超短期尺度上的充電負荷預測問題;同時計算資源需求大幅度縮小,降低了充電站的構建、維護、檢修、擴容的成本.
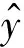
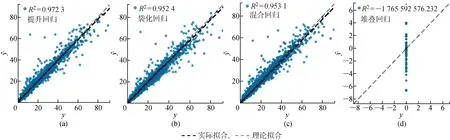
異構集成算法要結合3種不同的算法構建最終預測模型,因此在訓練時間上大大落后于同構集成算法,且充電負荷預測的正確率提升并不明顯.混合結構準確率提升至95.31%,堆疊結構產生了模型沖突,使得結果失真.在同構結構中,提升結構具有最高的準確率,達到97.23%.在袋化類結構中,采用多個基礎回歸器并行投票原則進行集成,因此當基礎回歸器對某個特征點不敏感時,會出現基礎回歸器群中的所有基礎回歸器在學習時都出現錯誤,導致最終回歸器同樣不能正確學習到該特征點的特征.但在提升類結構的串行集成過程中,后一個基礎回歸器會對前一個基礎回歸器不敏感的特征點加大訓練權值,因此避免了袋化方式在預測時不斷輸出同一錯誤點的缺陷,具有自我糾正能力.因此選擇提升方法對基礎回歸器群進行集成,構成最終的超短期充電負荷預測模型.
3.3 EEB-LGBM預測框架的性能分析
通過學習曲線和殘差分析可以觀察分析生成的模型對數據的利用效率與預測穩定性.學習曲線將模型在訓練集上的損失函數的最優值與在驗證數據集上評估的損失函數作對比,驗證數據集的參數是否與產生最優函數的參數相同,同時可以觀察到對數據的利用效率.計算基于EEB-LGBM預測框架的超短期充電負荷預測模型的學習曲線,可以觀察到該模型對訓練數據的需求量小,初始訓練時收斂速度快,隨著訓練數據的不斷增大,準確率穩步提升,在6000條數據時模型的整體準確率接近峰值,具有良好的泛化能力,其學習曲線如圖7所示.
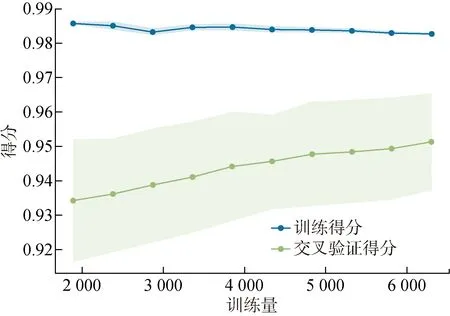
殘差計算可以驗證模型的殘差是否與隨機誤差存在一致性,體現回歸模型在面對真實隨機數據時預測能力的穩定性.殘差驗證結果的可視化如圖8所示.在對基于EEB-LGBM預測框架的模型進行殘差計算后可以觀察到,該模型在面對隨機分布的誤差時顯示出了極高的穩定性,在訓練集上預測精度達到了99.12%,在測試集上精度達到了97.23%.
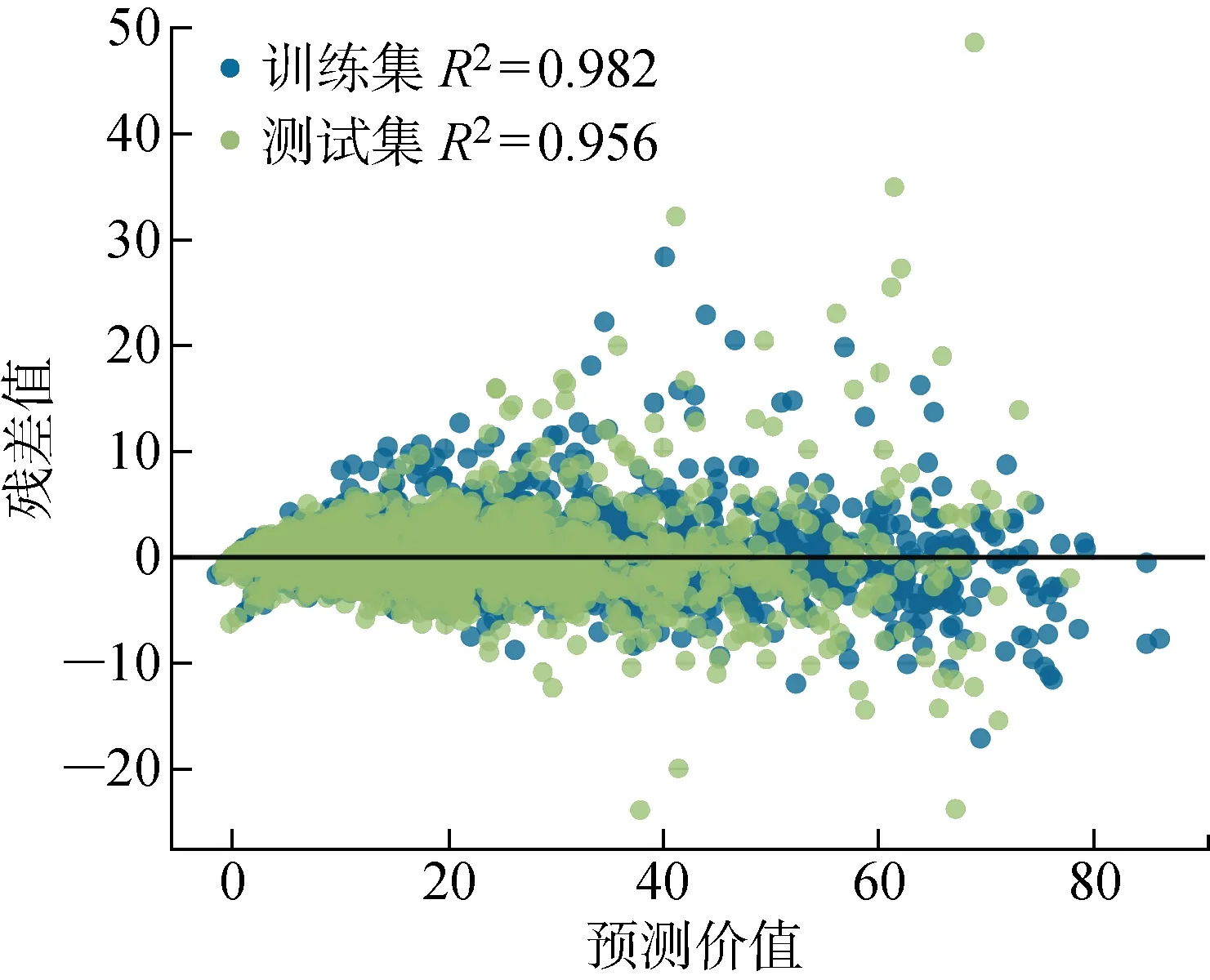
3.4 充電負荷預測模型對比
為對比EEB-LGBM的實際預測能力,將其與使用反向傳播神經網絡(Back Propagation Neural Network, BPNN)、卷積神經長短期記憶網絡(Convolutional Neural Networks-Long Short Term Memory, CNN-LSTM)、差分自回歸移動平均模型(Autoregressive Integrated Moving Average Model, ARIMA)構成的充電負荷預測模型進行性能對比.各模型均使用相同的充電負荷數據集以及相同的充電負荷條件影響因素數據集進行訓練,輸出某一天的預測值與實際充電負荷值進行對比,其結果如圖9所示.結果表明,雖然各預測方法都可以預測到充電負荷的變化趨勢,但本文所提出的基于EEB-LGBM預測框架的超短期充電負荷預測模型與實際充電負荷曲線具有最高的擬合率.各對比預測方法在測試集上的決定系數、MAPE以及TT如表4所示.
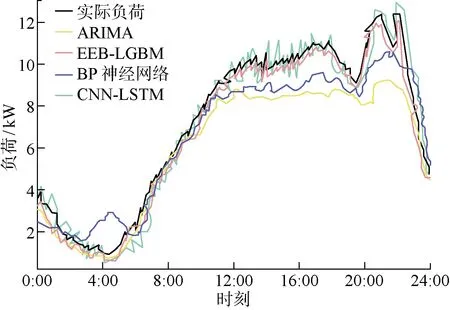
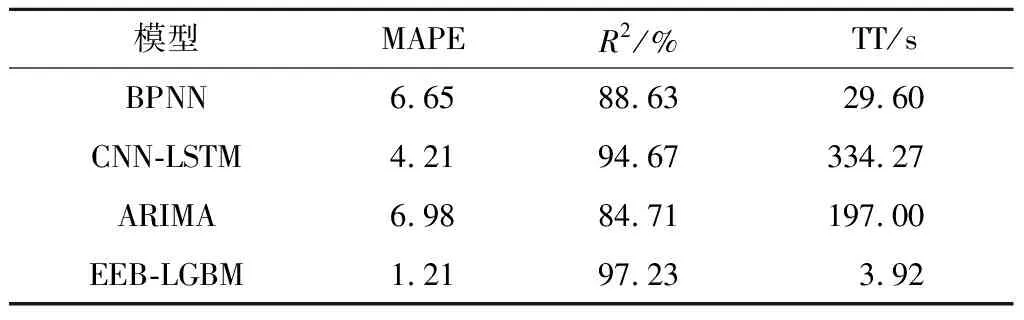
4 結語
目前的超短期負荷預測模型具有準確率欠缺、時間尺度過長、訓練時間長、計算資源需求大等缺點,同時未針對電動汽車充電站充電負荷的特點進行優化.本文提出的基于集成學習的雙層預測框架進行超短期充電負荷預測方法通過LightGBM構建高性能的基礎回歸器群,對充電負荷數據集進行學習,以提升類同構結構進一步提升預測精度,并使用MongoDB構建超參數空間,TPE算法進行并行化超參數搜索進行優化,最終構成超短期充電負荷預測模型.對比實驗證明,提出的基于EEB-LGBM預測框架的超短期充電站充電負荷預測模型,相比BPNN、CNN-LSTM、ARIMA預測模型不僅提高了預測精度,且顯著縮短了訓練時間,降低了計算資源需求,同時具有訓練數據需求小、收斂速度快、泛化能力強的優點,能夠滿足充電站超短期電力充電負荷預測的高效性、穩定性及經濟性等要求.
本文使用的提升類結構的串行集成方式在訓練時間上還具有進一步優化空間.為更好滿足超短期充電負荷預測對預測效率的高要求,后續工作將進行串行集成結構改善,以期進一步縮短模型的訓練時間,加快預測響應速度.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
