基于CNN-BiLSTM與三支決策的入侵檢測方法
2022-08-25 09:56:36黃樹成王云沼
軟件導刊 2022年8期
沈 雪,王 遜,黃樹成,王云沼
(1.江蘇科技大學計算機學院,江蘇鎮江 212003;2.中國人民解放軍陸軍通信訓練基地,北京 100029)
0 引言
隨著互聯網和信息技術的飛速發展,網絡安全變得越來越重要,而入侵檢測技術已經成為保障網絡安全的一種重要手段[1],近年來備受國內外研究者的關注。
隨著機器學習算法的發展,很多研究人員將其應用到入侵檢測領域。機器學習能夠對特征進行學習并發現重要特征,將入侵檢測轉化為對網絡中正常行為和異常行為的分類問題。常見的傳統機器學習算法包括支持向量機(SVM)[2]、K 近鄰(KNN)[3]、決策樹(DT)[4]、隨機森林(RF)[5]等。上述方法在一定程度上提高了入侵檢測的性能,但基于傳統機器學習的算法不能自主地學習特征,需要人為提取特征。
隨著深度學習在語音識別、圖像識別和自然語言處理等領域的成功應用,許多國內外學者嘗試將深度學習技術應用于入侵檢測。常用的深度學習技術包括自動編碼器(AE)[6]、深度玻爾茲曼機(DBM)[7]、深度信念網絡(DBN)[8]、卷積神經網絡(CNN)[9]、循環神經網絡(RNN)[10]等。深度學習算法相比于傳統機器學習算法在檢測性能上有較大提升,但也存在一些不足。在特征提取上,卷積神經網絡(Convolution Neural Network,CNN)能夠提取到數據的局部特征,但缺乏學習序列相關性的能力,而長短期記憶(Long Short-term Memory,LSTM)只能讀取一個方向的序列數據,不能充分考慮之后屬性信息的影響。此外,對于入侵檢測研究,目前主要使用二分類方法,即將網絡行為歸屬到正常行為或者是入侵行為,這在實際檢測中,往往會因為信息不足盲目決策而造成誤分類。
針對上述問題,本文提出CNN-BiLSTM 與三支決策(Three-way Decision,TWD)理論相結合,建立CNN-BiLSTM 和三支決策入侵檢測模型。利用CNN-BiLSTM 進行特征提取,將提取后的特征進行三支決策,對信息不足的網絡行為進行延遲決策,直到獲取到足夠的信息再進行判斷,從而得到最終決策結果。最后,在NSL-KDD、CICIDS2017數據集上進行實驗,評價算法的綜合性能。
1 相關算法
1.1 卷積神經網絡
卷積神經網絡是深度學習的代表算法之一[11],它由3部分組成:輸入層、隱藏層和輸出層,其中隱藏層又包含卷積層、池化層、全連接層。其網絡結構如圖1所示。

Fig.1 CNN model structure圖1 卷積神經網絡模型結構
卷積層用來提取數據特征,公式如下:

池化層用于降低維數、減少計算量、加速網絡收斂,同時去除數據冗余特征,有效減輕網絡過擬合程度。為防止數據的時序特征被破壞,本文采用平均值池化對數據進行降維操作。
全連接層將前面提取到的所有局部特征進行組合。每個神經元都與上一層所有神經元連接,采用激活函數進行操作,將結果傳遞給輸出層。
激活函數用于計算各神經元的權重。常用的激活函數有Sigmoid 函數、Tanh 函數和ReLU 系列函數。

損失函數用來評估模型預測值和真實值的差別程度,損失函數的值越小,代表預測值越接近真實值。損失函數公式如下:

其中,yi代表樣本實際值,x[il]代表樣本預測值,n為樣本數據量。
CNN 的訓練過程包括前向傳播和反向傳播。通過前向傳播獲得預測值,利用損失函數計算出預測值與實際值的誤差,再通過反向傳播,根據計算出來的誤差損失和權重更新公式,并進行誤差的反向傳遞,進而更新網絡權重,經過大量迭代得到最終訓練模型。
權重和偏置的更新公式如下:

1.2 雙向長短期記憶
長短期記憶LSTM 是循環神經網絡RNN 的變形,它由3 個門控單元和一個記憶細胞組合而成[12]。LSTM 使用累加而不是累乘的方式計算細胞狀態,其導數也是累加方式,從而有效地解決了RNN 在訓練過程中出現的梯度消失和梯度爆炸問題。其網絡模型結構如圖2所示。

Fig.2 LSTM model structure圖2 LSTM模型結構
其中,ct-1、ht-1表示時間步t-1的記憶細胞和隱層狀態,xt是時間步t的輸入,ft、it、ot分別代表遺忘門、輸入門和輸出門;σ表示Sigmoid 激活函數是時間步t的候選記憶細胞,使用Tanh 激活函數;ct、ht、yt分別表示時間步t的記憶細胞、隱層狀態和輸出。特征提取步驟如下:
Step1:計算輸入門ft。通過讀取xt和ht-1,遺忘門ft對時間步t的細胞狀態進行篩選,決定丟棄什么信息。公式如下:
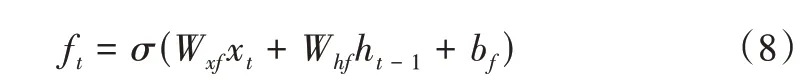
其中,Wxf和Whf是權重參數,bf是偏差參數。
Step2:計算輸入門it和候選記憶細胞,確定將哪些新信息存放進記憶細胞中。公式如下:
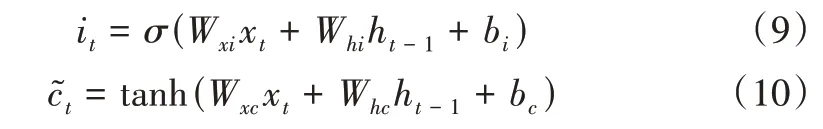
其中,Wxi、Whi、Wxc、Whc是權重參數,bi、bc是偏差參數。
Step3:計算更新的細胞狀態ct,得到最終更新的細胞狀態ct。公式如下:

Step4:計算輸出門ot和隱層狀態ht。公式如下:
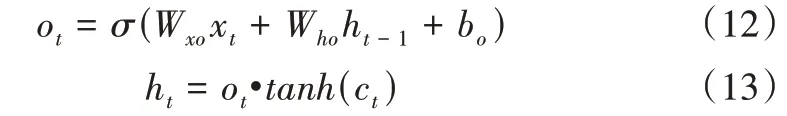
其中,Wxo和Who是權重參數,bo是偏差參數。
雙向長短期記憶BiLSTM 由一個正向LSTM 和一個反向LSTM 網絡組成,在LSTM 網絡單向數據流動的基礎上,增加了反向的數據流向,并且前向隱藏層和后向隱藏層之間沒有聯系,從而有效地解決了LSTM 只能提取單一方向的序列特征問題。其網絡結構如圖3所示。

Fig.3 BiLSTM model structure圖3 BiLSTM 模型結構
每一級隱藏層狀態ht的計算公式如下:

其中,LSTM代表式(8)—式(13)的運算過程,是前向隱藏層狀態是后向隱藏層狀態,Wfwd是前向隱藏層的權重參數,Wbwd是后向隱藏層的權重參數,bt是隱藏層的偏置參數。
1.3 三支決策理論
三支決策理論是Yao 等[13]基于概率粗糙集和決策粗糙集提出的新決策理論,是對二支決策理論的一種擴展。其核心思想是將整體區域(分類對象)劃分為3 個兩兩互不相交的區域,分別是正域(POS)、負域(NEG)和邊界域(BND),然后對不同的區域采取不同的策略。
將一個樣本x劃分到3 個不同的區域可能存在兩種不同的狀態,即x屬于該域(P)和x不屬于該域(N),并且對樣本x可以采取3 種不同的決策,即接受決策(Dp)、延遲決策(DB)和拒絕決策(DN)。由于將一個樣本劃分到正域、負域和邊界域的代價不同,因此可以得到6 種不同的分類代價,分別用λPP、λBP、λNP、λPN、λBN、λNN表示,其決策的代價損失函數如表1所示。

Table 1 Cost loss function表1 代價損失函數
根據貝葉斯最小風險原則,損失函數之間的大小關系滿足:0 ≤λPP≤λBP<λNP,0 ≤λNN≤λBN<λPN。
假設α、β為兩個決策閾值。根據文獻[14]的推導證明,可以得到其計算公式如下:

在入侵檢測中,正域表示該網絡行為屬于入侵行為,負域表示該網絡行為屬于正常行為,邊界域表示暫未進行決策的行為。假設X表示入侵概念的區域,x表示網絡行為樣本數據,P(X|[x])表示將一個網絡行為劃分到入侵區域的概率。
可以得到如下3條決策規則:①如果P(X|[x]) >α,則x∈POS(X)。將該網絡行為劃分到入侵行為區域中;②如果α≤P(X|[x]) ≤β,則x∈BND(X)。將該網絡行為劃分到邊界域中延遲決策,等待進一步處理;③如果P(X|[x]) <β,則x∈NEG(X)。將該網絡行為劃分到正常行為區域中。
2 基于CNN-BiLSTM 與三支決策的入侵檢測模型
2.1 入侵檢測算法整體流程
本文構建的基于CNN-BiLSTM 和三支決策的入侵檢測方法,其整體流程主要包括3 個部分:對數據進行預處理、通過CNN-BiLSTM 特征提取以及利用三支決策進行判斷。算法整體流程如圖4所示。
2.2 基于CNN-BiLSTM 的特征提取
在使用CNN-BiLSTM 進行特征提取時,具體提取步驟如下:
Step1:卷積層對預處理后的數據進行卷積操作,特征提取。
Step2:池化層對卷積層輸出的數據進行降維操作。

Fig.4 Algorithm overall flow圖4 算法整體流程
Step3:將CNN 提取到的特征送入BiLSTM 作為其輸入。
Step4:BiLSTM 對數據進行長距離依賴特征提取。
Step5:全連接層將前面提取到的局部特征進行整合。
Step6:根據損失函數計算出預計值與實際值的誤差。
Step7:采用梯度下降法進行反向傳播誤差,求出損失函數對每一個參數的梯度并更新網絡參數,多次迭代后得到最終訓練模型。
Step8:在訓練模型中輸出提取的數據特征,即數據的低維表示。
2.3 基于三支決策理論的網絡行為分類
在利用三支決策理論對網絡行為進行分類時,假設樣本集為X=(x1,x2,……,xn)。首先,求出樣本xi屬于正域的概率p(POS|xi),其中i=1,2,……,n。然后比較p(POS|xi)的值與決策閾值α、β的大小:如果p(POS|xi) >α,則將其劃分到正域中;如果p(POS|xi) <β,則將其劃分到負域中;如果α≤p(POS|xi) ≤β,則將其劃分到邊界域中。對于被劃分到邊界域中的網絡數據,將其重新輸入到CNN-BiLSTM 模型中進行特征提取,然后再次劃分。在邊界域內不再有樣本存在之前,該決策過程將一直持續下去[15]。具體算法步驟如下:
輸入:訓練集Tr,測試集Te
輸出:正域POS,負域NEG
1.初始化參數:CNN-BiLSTM 特征提取方式G;
決策閾值α,β;
三支分類器f;
正域(POS)=?;負域(NEG)=?;邊界域(BND)=?
2.while 測試集Te不為空:
Tr=G(Tr);Te=G(Te);
根據Tr訓練模型f;
由模型f得到Tr中的每個數據屬于正域的概率For eachp∈P,te∈Te:Ifp>α

3.輸出:正域POS,負域NEG
2.3 算法時間復雜度分析
本文提出的入侵檢測模型主要分為兩部分,分別是特征提取模塊和三支決策模塊。在特征提取模塊中,基于CNN-BiLSTM 的特征提取模型屬于深度學習模型,由于描述深度學習時間復雜度的變量太多,無法準確描述,通常并不計算深度學習模型的時間復雜度,假設這個模塊的時間復雜度為O(M)。在三支決策模塊中,假設算法的迭代次數是T,測試集中的數據個數為N,則第一次迭代時,數據集為測試集的全部數據,隨著迭代次數增加,測試集中的數據越來越少,當測試集中的數據為空時停止迭代,則此模塊的時間復雜度為O(T*N)。因此,可以得到本文入侵檢測模型時間復雜度為O(M)+O(T*N)。
3 實驗及結果分析
3.1 實驗數據集
3.1.1 NSL-KDD 數據集
NSL-KDD 數據集中的每條數據包含41 個特征和1 個類標簽。除正常行為外,各種類型的攻擊行為可以分為4類:DOS、R2L、U2R、PROBING[16]。NSL-KDD 數據集的行為類型分布如表2所示。

Table 2 NSL-KDD data set distribution表2 NSL-KDD數據集分布
3.1.2 CIC-IDS2017數據集
CIC-IDS2017 數據集包含良性和最新的常見攻擊[17],每條數據由79 個特征和1 個類標簽組成。其數據采集時間范圍為2017 年7 月3 日(星期一)9 時至2017 年7 月7 日(星期五)下午5 時,總共5 天。其中,星期一只采集到正常流量,周二到周五采集到攻擊,包括暴力FTP、暴力SSH、DoS、Heartbleed、Web 攻擊、滲透、僵尸網絡和DDoS。CICIDS2017數據集的行為類型分布如表3所示。

Table 3 CIC-IDS2017 data set distribution表3 CIC-IDS2017數據集分布
3.2 實驗數據處理
3.2.1 NSL-KDD 數據處理
(1)符號特征數值化。首先對非數值型的特征進行標簽編碼,再使用One-hot 編碼對標簽編碼后的數據進行處理。經過處理,可以使得原來擁有41 個特征屬性和1 個類標簽的數據集擴展成為具有119 個特征屬性和1 個類屬性的數據集。
(2)數字特征歸一化。由于CNN-BiLSTM 模型要求輸入的數據在0~1 之間,因而要對特征作歸一化處理,按照如下公式進行:

其中,x*是歸一化后的特征,x是待歸一化特征值,xmin是該特征的最小值,xmax是該特征的最大值。
3.2.2 CIC-IDS2017數據處理
(1)處理重復列。該數據集包含兩個重復的特征,即“Fwd Header Length”,刪除其中一列。
(2)處理缺失值。該數據集的缺失值均出現在“Flow Bytes/s”和“Flow Packets/s”特征中,由于缺省值的樣本非常少,因而直接刪除含有缺失值的樣本。
(3)處理數據不平衡問題。由于“Web Attack Brute Force”“Web Attack Sql Injection”和“Web Attack XSS”3 種入侵類型樣本數量較少,將其合并成一個類型并命名為“Web Attack”,并且將“Thursday-WorkingHours-Morning-WebAttacks.pcap_ISCX.csv”、“Tuesday-WorkingHours.pcap_ISCX.csv”和“Friday-WorkingHours-Morning.pcap_ISCX.csv”這3 個文件合并成一個文件,可在一定程度上解決數據不平衡問題。
(4)數據歸一化。處理方法同NSL-KDD 數據集。
3.3 評價指標
本文使用準確率(ACC)、誤報率(FPR)、檢出率(DR)、精確率(PR)、和F1 得分(F1)作為評估入侵檢測模型性能的指標。計算公式如下:

其中,TP表示入侵行為被正確歸類到入侵行為,TN表示正常行為被正確歸類到正常行為;FP表示正常行為被錯誤歸類到入侵行為,即誤報;FN表示攻擊行為被錯誤歸類到正常行為,即漏報。
3.4 樣本選取和參數設置
3.4.1 NSL-KDD 樣本選取
本文選取5 個不同的子樣本集進行實驗,并且將5 次實驗結果的平均值作為最終結果進行性能分析。選取的樣本數據子集的類型分布如表4所示。
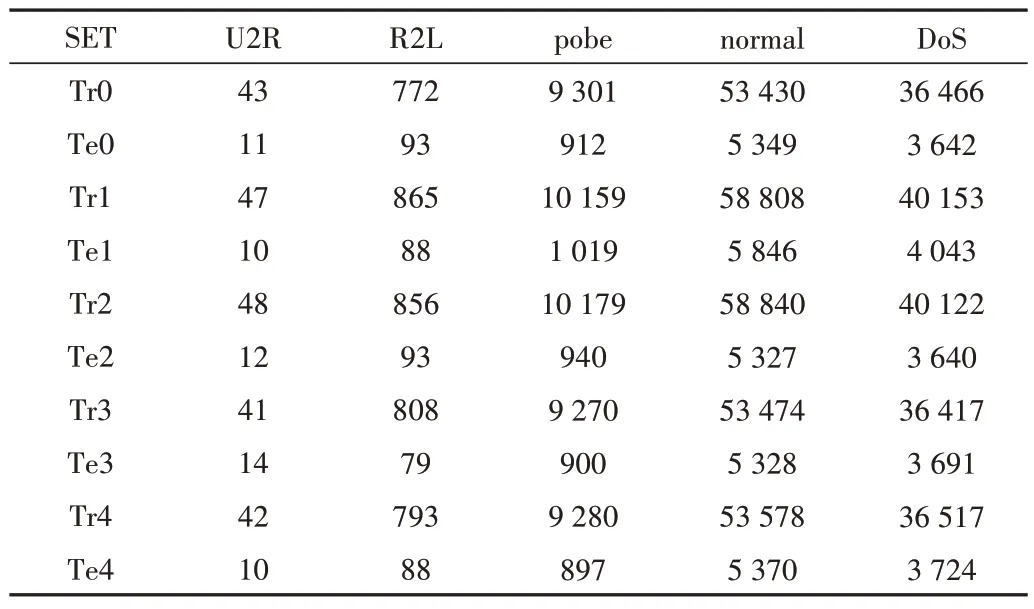
Table 4 Five data sample subset data distribution表4 5個數據樣本子集數據分布
3.4.2 CIC-IDS2017樣本選取
由于CIC-IDS2017 數據集較大,本文選取1/3 的數據集作為實驗數據,樣本類型分布如表5所示。

Table 5 Sample data set distribution表5 樣本數據集分布
3.4.3 參數設置
本文選用主成分分析(PCA)、奇異值分解(SVD)、因子分析(FA)和深度神經網絡(DNN)作為CNN-BiLSTM 的比較方法。
主成分分析PCA 的超參數設置為:最大數迭代次數1 000,最大允許誤差le-4,線性函數logcosh,成分數量為35。奇異值分解SVD 的超參數設置為:隨機SVD 求解器的迭代次數5,成分數量為35。因子分析的超參數設置為:最大數迭代次數1 000,最大允許誤差le-2,迭代次數3,成分數量為35。DNN 的超參數設置為:最大迭代次數2 000,學習率為le-3。CNN-BiLSTM 的超參數設置為:卷積核個數為2,大小為3,記憶模塊數為4,各模塊細胞數為2,最大數迭代次數1 000,最大允許誤差le-4。
3.5 實驗過程及結果分析
3.5.1 實驗1
為了比較CNN-BiLSTM 特征提取算法與其它特征提取方法的性能,在同樣使用三支決策分類器的條件下,分別使用主成分分析(PCA)、奇異值分解(SVD)因子分析(FA)和深度神經網絡(DNN)提取特征并作比較。在NSLKDD 數據集上進行實驗,結果如表6 所示,其中CNN-BiLSTM-TWD 簡寫為CBL-TWD。

Table 6 Experimental results of different feature extraction methods表6 不同特征提取方法的實驗結果比較
從實驗結果可以看出,CNN-BiLSTM-TWD 在準確率(ACC)、檢出率(DR)、精確率(PR)和F1 分數上優于其他幾種特征提取方法,整體性能較好。可以說明,本文所提的CNN-BiLSTM 方法具有更優的特征提取能力。
3.5.2 實驗2
為了比較三支決策算法和傳統二支分類算法檢測效果,在同樣使用CNN-BiLSTM 進行特征提取下,分別使用支持向量機(SVM)、K 近鄰(KNN)、隨機森林(RF)和貝葉斯模型(BYS)對網絡行為分類。在NSL-KDD 數據集上進行實驗,結果如表7所示。
從實驗結果可以看出,基于三支決策(TWD)的分類算法在準確率(ACC)、檢出率(DR)、精確率(PR)和F1 分數上優于其他幾種分類算法。這表明,使用基于三支決策理論的分類器,其入侵檢測性能優于傳統基于二支決策的分類算法。

Table 7 Comparison of experimental results of different classification models表7 不同分類模型的實驗結果比較
3.5.3 實驗3
為了將本文算法與其他入侵檢測算法進行比較,選取基于LDA 和極限學習機的入侵檢測模型(LDA-ELM)[18]、基于半監督學習的入侵檢測模型(SSL)[19]、基于層疊非對稱深度自編碼器的入侵檢測方法(SNADE)[20]和基于時空特征的分層入侵檢測系統(HAST-IDS)[21]。在NSL-KDD數據集上進行實驗,結果如表8所示。
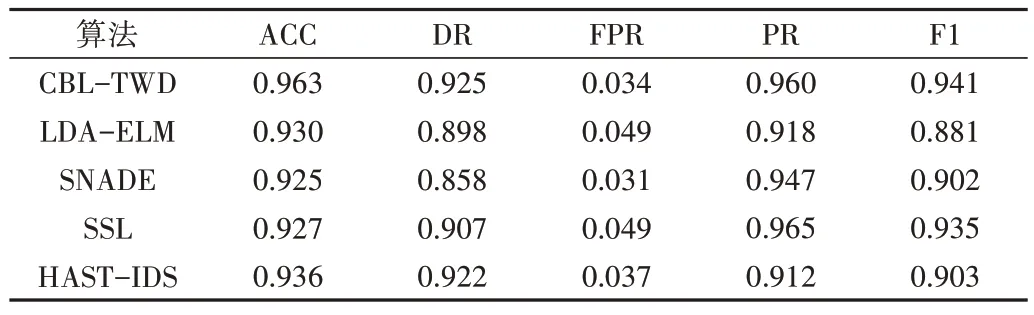
Table 8 Comparison 1 of experimental results of different algorithms表8 不同算法的實驗結果比較1
從實驗結果可以看出,本文所提的CNN-BiLSTMTWD 入侵檢測模型雖然在誤報率和精確率上表現稍顯不足,但在準確率(ACC)、檢出率(DR)和F1 分數上要優于其他檢測方法。綜上表明,本文提出的基于三支決策的分類算法在綜合性能上優于其他對比模型。
3.5.4 實驗4
實驗4 是在實驗3 的基礎上,保持其他實驗條件不變,將NSL-KDD 數據集替換成CIC-IDS2017 數據集。實驗結果如表9所示。

Table 9 Comparison 2 of experimental results of different algorithms表9 不同算法的實驗結果比較2
從實驗結果可以看出,基于CNN-BiLSTM-TWD 的入侵檢測模型在準確率(ACC)、檢出率(DR)、F1 分數上優于其他檢測方法。綜上表明,本文提出的入侵檢測模型優于其他對比模型。
實驗3 和實驗4 表明,本文所提方法在兩種數據集中都表現出了優越的入侵檢測性能,具有魯棒性。
4 結語
本文提出一種基于CNN-BiLSTM 和三支決策的入侵檢測方法,通過CNN-BiLSTM 模型從樣本中提取特征,再利用三支決策理論,根據決策閾值對網絡行為進行分類。對于劃分到邊界域中的數據,利用CNN-BiLSTM 重新提取特征后再進行分類,直到邊界域中不再有樣本為止。本文算法在特征提取和檢測分類上提高了入侵檢測性能,但是算法還有待改進。例如,未考慮到邊界域中數據的時間成本問題,當邊界域中存在的樣本數量很少時,仍會耗費大量時間進行決策,下一步將繼續深入研究邊界域的時間成本問題。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
