基于詞向量與CNN-BIGRU的情感分析研究
2022-08-25 09:56:38吳貴珍黃樹成
軟件導刊 2022年8期
吳貴珍,王 芳,黃樹成
(江蘇科技大學計算機學院,江蘇鎮江 212100)
0 引言
情感分析是指利用自然語言處理及計算機語言學等技術識別與提取原素材中的主觀信息,找出意見發表者在某些話題上的兩極觀點態度[1]。目前情感分析方法分為3種:基于情感詞典的方法、基于機器學習的方法、基于深度學習的方法。其中,基于深度學習的方法能從大量文本中自動學習到深層特征,情感分析效果好且模型適應性強[2]。因此,目前主流的情感分析方法是基于深度學習的方法。在深度學習領域又有多種情感分析模型,主要包括卷積神經網絡(CNN)模型和循環神經網絡(RNN)模型,但CNN 模型只能進行局部特征提取,RNN 模型存在短期記憶問題。為解決這一問題,長短期記憶模型(LSTM)和門控遞歸單元(GRU)等眾多變體被提出,并廣泛應用于情感分析領域[3-4]。然而,LSTM 和GRU 模型只具有前向信息記憶能力,而不能對后向序列進行記憶,故雙向RNN 結構隨之被提出。對比兩個雙向RNN 結構,即相比BILSTM 模型,BIGRU 模型的參數更少,網絡訓練速率也更快,在保持幾乎相同準確率的同時更節約網絡訓練時間,提高了效率[5-6]。
故本文選用CNN 與雙層BIGRU 相融合的方式進行情感分析,一方面利用CNN 局部感知的特點提取出語義特征,另一方面利用BIGRU 提取包含上下文信息的全文特征,對局部特征進行補充,以完善CNN 模型情感特征傾向信息。同時,為豐富特征信息并加強模型的特征學習能力、提高文本情感分析的準確性,提出疊加BIGRU 模型的雙層BIGRU 模型,即將第一層BIGRU 的輸出作為第二層BIGRU 的輸入,形成多層結構以增強特征。
1 相關研究
1.1 詞向量相關研究
在NLP(自然語言處理)中存在許多基于神經網絡的詞向量計算技術,如:神經網絡語言模型Word2vec 等。其中,Word2vec 是由MikolovT 等[7]在2013 年提出的,在詞向量計算中被廣泛應用。Word2vec 技術中包含兩種不同的詞向量計算模型:CBOW 模型與Skip-gram 模型[8-9]。由于CBOW 模型訓練時間短且具有較高計算精度,因此本文采用CBOW 模型。
CBOW 模型,中文譯為“連續詞袋模型”,其核心思想是:給定中心詞一定鄰域半徑內的單詞,預測輸出單詞為該中心詞的概率。該模型共分為3 層:輸入層、隱藏層(投影層)與輸出層。輸入層輸入中心詞一定鄰域半徑內的單詞詞向量,隱藏層將輸入層的詞向量按照規則進行計算,輸出層輸出獲得中心詞的概率。在CBOW 模型中,訓練目標為最大化對數似然函數L:
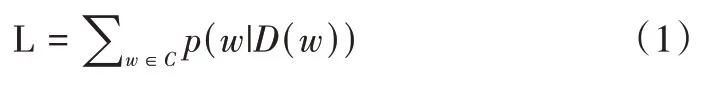
式中,D(w) 表示語句中除詞語w外的其他詞語,w為詞庫C 中的任意一個詞語。以對數似然函數為導向,計算出詞庫中詞語w在整個句子中出現的概率,實現對中心詞出現概率的預測。
1.2 情感分析相關研究
卷積神經網絡和遞歸神經網絡是文本情感分析領域兩種廣泛使用的深度學習模型。Bengio 等[10]最早使用神經網絡構建語言模型;Kalchbrenner 等[11]提出動態卷積神經網絡模型以處理長度不同的文本,將卷積神經網絡應用于NLP;Kim[12]對比了不同詞向量構造方法,利用提前訓練的詞向量作為輸入,通過CNN 實現句子級的文本分類,但這種方法也存在弊端,其忽視了待分類句子內部詞語之間的聯系;Mikolov 等[13]提出的RNN 模型可處理序列數據并學習長期依賴性,但RNN 存在短期記憶問題,無法處理一段很長的序列,且不具有對后向序列的記憶功能。為解決該問題,雙向RNN 結構變體被提出。如Graves 等[14]提出的雙向長短期記憶網絡(BILSTM),該模型在LSTM 上增加了反向層,使得LSTM 能夠同時考慮上下文信息,對雙向序列信息進行記憶,獲得雙向無損的文本信息;Chen等[15]利用多通道卷積神經網絡模型,從多方面的特征表示學習輸入句子的情感信息;Long 等[16]將雙向長短時記憶網絡與多頭注意力機制相結合對社交媒體文本進行情感分析,克服了傳統機器學習中的不足;Kai等[17]將卷積神經網絡與Bi-LSTM 融合起來,解決了現有情感分析方法特征提取不充分的問題,并分別通過實驗表明了該融合模型在實際應用中具有較大價值。同時,Wang 等[18]研究了樹形結構的區域CNN-BILSTM 模型,提供了更細粒度的情感分析,在不同語料庫上都取得了不錯的分類效果。
以上方法使用的都是傳統獲取詞向量模型的方式,并且未使用過CNN 與雙層BIGRU 融合進行情感分析,訓練準確性不夠高。本文通過對詞向量進行改進,加入Attention 機制提取重要的輸入向量,并融合CNN 與雙層BIGRU模型進行改進,以提高文本分析的準確性。
1.3 情感分析相關技術
1.3.1 CNN模型
常見的CNN 模型主要由輸入層、卷積層、池化層與全連接層構成。輸入層主要是得到一個二維矩陣,矩陣中的每一行對應不同的詞,不同的詞用不同向量表示。卷積層是卷積神經網絡的主要部分,卷積操作其實是卷積核矩陣與對應輸入層中一小塊矩陣的點積相乘,卷積核通過權重共享的方式,按照步幅上下左右地在輸入層滑動提取特征,以此將輸入層作特征映射,并作為輸出層。池化層一般采用最大池化法,將卷積層每個通道得到的向量進行最大池化,得到一個標量,最后將其拼接起來傳到全連接層或直接連接softmax 層進行分類[19]。全連接層連接一個softmax 層,將池化層獲得的一維向量輸入進去,其通常反映著最終類別上的概率分布,以此進行情感分類。
1.3.2 BIGRU模型
在單向的神經網絡結構中,狀態總是從前往后輸出,只能捕捉當前詞前面的相關信息。然而,在文本情感分類中,如果當前時刻的輸出能與前一時刻及后一時刻的狀態產生聯系,則能夠學習到該詞的上下文信息,有利于文本深層次特征提取,所以在GRU 基礎上選擇雙向循環控制單元(BiGRU)來建立這種聯系。BiGRU 是由兩個單向、方向相反、輸出由兩個GRU 狀態共同決定的神經網絡模型。
2 改進詞向量的CNN-雙層BIGRU 情感分析模型
情感分析的第一步是將計算機無法處理的文本信息轉換成計算機能夠識別的0-1 序列詞向量,并利用詞向量模型捕捉詞語之間的關系,得到序列化后的詞向量,然后將其送至深度學習模型中進行訓練,所以是否能獲得準確的詞向量對于情感分析非常重要。
在上文已介紹了傳統詞向量模型——CBOW 模型,該模型能夠通過上下文單詞預測中心單詞,得到序列化后的詞向量矩陣。但在實際的情感分析文本中,如大量商品評論或電影評論中,經常會出現商品屬性獨特的專有名詞或電影情節中的專業名詞、人名等,加上評論表達過于口語化以及停用詞使用存在不當,使得準確提取詞向量的難度加大,原有CBOW 模型效果不佳。因此,本文提出一種改進的詞向量模型,在原先的CBOW 模型基礎上加入Attention 機制對詞向量進行改進[20]。Attention 機制能夠快速獲得需要重點關注的目標區域,并抑制其它無用信息。
具體操作為:在CBOW 輸入層與隱藏層之間加入Attention 機制,關注關鍵詞提取并抑制其他干擾詞影響。加入Attention 機制后的CBOW 模型如圖1所示。

Fig.1 CBOW model after adding the attention mechanism圖1 加入Attention機制后的CBOW 模型
CBOW 模型的輸入是每個詞的one-hot 向量,設其為vj。改進后的CBOW 模型加入Attention 機制后,模型輸入為:


其中,第i 個詞通過softmax函數進行歸一化計算權重得分,得到可用權重。通過式(4)得到:

其中,Zi是Attention 機制中所需的訓練參數,Pi、Qi是由不同單詞之間的關系和權重所決定的。這一步是將Query與Key進行相似度計算得到權值的過程。
最后經過Attention 機制得到的輸入詞向量為:

在加入Attention 機制的CBOW 模型中,經Attention 機制得到的輸出向量作為CBOW 模型隱藏層輸入。在經過隱藏層和輸出層計算后,得到模型處理后第n 個單詞的詞向量如下:

之后,將改進后的詞向量模型得到的vnword送入深度學習模型中進行訓練。
在之前的情感分析深度模型中,通常將CNN 模型與LSTM 模型、GRU 模型或BILSTM 模型融合以獲取深度學習結果,速度與準確率都不太高,本文提出一種將CNN 與雙層BIGRU 模型相融合的方式進行情感分析,原因如下:①GRU 模型只有2 個門:重置門和更新門,相比有輸入門、遺忘門和輸出門3 個門的LSTM 模型,GRU 在達到相同效果的同時,具有更高的時間效率;②雙向GRU 模型能學習到該詞的上下文信息,有利于文本深層次特征的提取;③最后在BIGRU 模型基礎上疊加一層BIGRU,從而豐富了特征信息,并加強了模型的特征學習能力,提高了文本情感分析的準確性,該方式相比之前的深度學習模型,準確率和速率都更高。
其融合過程主要通過以下幾個步驟實現:
(1)將上文加入Attention 機制的CBOW 模型得到每個詞的詞向量vi∈Rn×d作為輸入層的輸入向量,其中n是詞數,d是向量維度,則初始輸入矩陣S 可表示為S=(v1,v2,…,vn)。
(2)利用CNN 提取局部信息特征。CNN 卷積層接收輸入層傳入的詞向量,在卷積層中通過設置3 種大小不同的濾波器提取h 個相鄰詞匯之間的靜態局部特征,公式如下:

其中,w 是卷積核,h是卷積核尺寸,vi:i+h-1是i到i+h-1 個詞組成的句子向量,b是偏移量。通過卷積層后得到特征矩陣c=[c1,c2,…,cn-h+1],對卷積層得到的句子局部特征矩陣c 進行下采樣,得到局部值的最優解Mi。這里采用最大池化技術,公式如下:

由于BiGRU 輸入必須是序列化結構,池化將中斷序列結構c,因此需要添加全連接層,將池化層后的向量Mi連接成特征矩陣U=[M1,M2,…,Mn]。
(3)將U 作為第一層BIGRU 的輸入。BIGRU 由正向GRU、反向GRU、正反向GRU 的輸出狀態連接層組成,BIGRU 網絡模型具體結構如圖2所示。
BIGRU 模型由輸入層、隱藏層、輸出層構成,其中隱藏層由兩個方向的G R U 構成。正反向GRU分別得到兩個對應隱藏層的輸出量其計算公式如下:
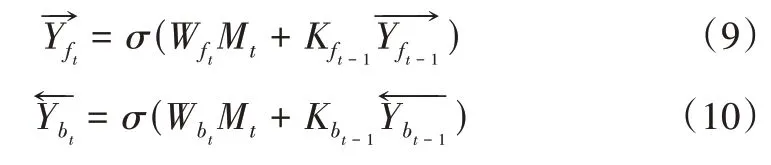

Fig.2 Specific structure of BIGRU model圖2 BIGRU模型具體結構
其中,σ表示sigmoid 激活函數,相當于門控信號;Mt表示在t 時刻整個模型的輸入值;分別表示t 時刻正向GRU和反向GRU的權重矩陣分別表示上一時刻正向GRU和反向GRU的權重矩陣分別表示t 時刻隱藏層的正向GRU和反向GRU輸出分別表示上一時刻正向和反向GRU 隱藏層輸出。
(4)將兩個輸出特征向量合并,得到BIGRU 輸出層向量Z′t:

(5)在單層BIGRU 模型上再堆疊一層BiGRU 單元,形成雙層結構以增強特征。將上一步得到BIGRU 模型的最終輸出Z′t作為第二層BIRGU 的輸入,在第二層BIGRU中,Z′t相當于第一層BIGRU的輸入Mt。分別計算第二層BIGRU正向和反向GRU在t時刻的輸出計算公式如下:

其中,Z′t表示在第二層BIGRU 中t 時刻的輸入分別表示t 時刻正向GRU 和反向GRU 的權重矩陣;分別表示第二層BIGRU 中上一時刻正向GRU和反向GRU的權重矩陣分別表示上一時刻正向和反向GRU 的隱藏層輸出。

在兩層之間需要添加一個大小為0.25 的dropout 層,以減少訓練過程的擬合。
(7)最后由情感分類層依靠其中的sigmoid 分類器完成情感分類。經過前面的步驟,已將蘊含實際含義的文本信息轉化成用詞向量組合而成的序列。本文的情感分析任務是對文本情感進行二分類,即將情感分為兩類:正向和負向。sigmoid 分類器在接收到含有語義信息的序列后,因其輸出范圍是0~1,會將結果轉換為概率進行分類。結果大于等于0.5 為正向情感,小于0.5 為負向情感,很適合二分類問題預測,從而最終完成情感極向預測。
3 實驗與分析
3.1 實驗環境
本次實驗基于Windows10 操作系統,處理器為Intel(R)Core(TM)i7-8550U,內存大小為8G,硬盤大小為1T。主要使用底層框架為Tensorflow 的Keras 深度學習API 訓練神經網絡模型,其版本號為2.3.1,用Python 語言進行實現。
3.2 實驗數據集
本文實驗數據集是從購物網站中爬取的10 個類別商品的共計6 萬條評論,其中正向情感與負向情感的評論各一半,均為3 萬條。數據集中每一條評論均被標記好情感類別:正向評價標注為1,負向評價標注為0。按照8:2 的比例劃分訓練集和測試集,即4.8 萬條評論用于訓練,1.2萬條評論用于測試。
3.3 實驗預處理與模型參數設置
首先,將數據集順序全部打亂,使正向與負向評論不會集中在一起,否則會影響模型分類的準確性;其次,對評論文本進行數據清洗,先去除停用詞,再使用jieba 分詞對文本進行分詞,并用詞向量訓練工具將單詞轉化為向量;之后,將分詞后的詞向量輸入到詞向量預訓練模型,即改進后的CBOW 模型中,設置句子最大長度120。若句子超過120 個詞,則超過的部分會被刪除;若句子不足120 個詞,則對其進行向右補0 操作。設置3 種大小的卷積核,分別為2、3、4,設置詞嵌入維度為100,步長為1。模型參數設置會影響分類效果,主要模型參數有:epoch、batchsize、optimizer、learning rate、activation。經過模型的多次迭代,配置最優參數,使得模型的分類效果最佳。詳細參數設置如表1所示。
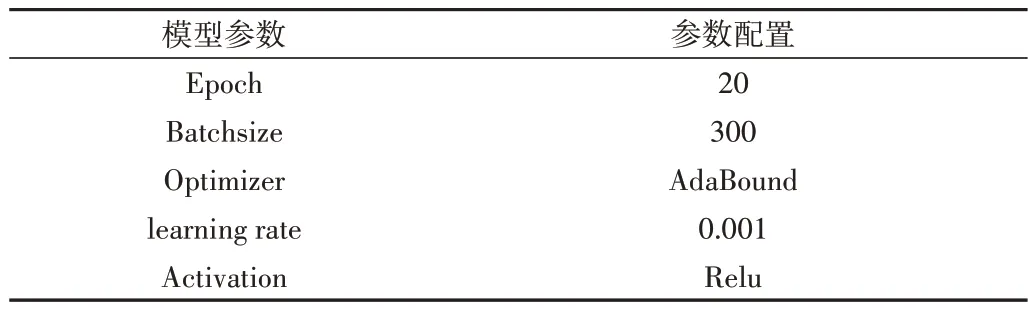
Table 1 Model parameter settings表1 模型參數設置
3.4 實驗評價標準
對于深度學習模型,一般有4 個評價指標對模型進行評價:①準確率(Accuracy)。所有預測正確(包括正向和負向)的樣本占總樣本的比重;②精確率(Precision)。正確預測為正向的樣本占全部預測為正向樣本的比例;③召回率(Recall)。正確預測為正向的樣本占全部實際正向樣本的比例;④F1值。精確值與召回率的調和均值。
3.5 實驗結果與分析
在10 個商品分類的評價數據集中,首先在詞向量不變的前提下,將本文提出的CNN-雙層BIGRU 模型與CNN、LSTM、GRU、CNN-LSTM、CNN-GRU、CNN-BILSTM、CNN-BIGRU 模型分別作比較,結果證明CNN-雙層BIGRU模型的效果優于其他模型。實驗結果如表2、圖3所示。

Table 2 Comparison of model results表2 模型結果比較

Fig.3 Experimental results of each model圖3 各模型實驗結果
其次,經過詞向量的改進,即在CBOW 模型中加入Attention 機制后,將本文提出的CNN-雙層BIGRU 模型在詞向量改進前后的準確率變化進行對比,如圖4所示。
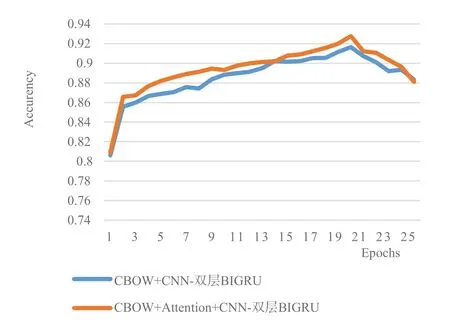
Fig.4 Changes in accuracy before and after word vector improvement圖4 詞向量改進前后準確率變化
最后,將所有模型的訓練時間進行比較,結果如表3所示。

Table 3 Comparison of model training time表3 模型訓練時間比較
從實驗結果可得出以下結論:
(1)根據圖3 和表2 可知,帶有雙向序列的融合模型CNN-BILSTM、CNN-BIGRU 比不帶雙向序列的融合模型CNN-LSTM、CNN-GRU 的準確率要高。如CNN-BIGRU 的準確率和精確率相比CNN-GRU 分別提高了0.33%和0.4%,說明雙向序列模型考慮了文本的先后關系,能更準確地提取文本上下文的信息特征,提高情感分析的準確率。且根據表3 可知,CNN-BILSTM 和CNN-BIGRU 同樣是雙向序列的融合模型,但在同樣的輪次訓練中,CNNBILSTM 的訓練時間為67s,準確率為91.19%,而CNN-BIGRU 的訓練時間為64s,準確率為91.38%。訓練時間減少了3s,準確率提高了0.19%,原因在于GRU 比LSTM 的模型結構更簡單。因此,無論從時間還是準確率上,CNN-BIGRU模型都更勝一籌。
(2)多疊加一層BIRGU 的CNN-雙層BIGRU 模型與CNN-BIGRU 模型相比,其準確率、精確率、召回率、F1值分別提高了0.27%、0.23%、0.15%和0.24%,說明疊加的一層BIGRU 結構能夠捕捉到更豐富的信息,提高了情感分析的準確性。
(3)由表3 和圖4 可知,在CNN-雙層BIGRU 模型中,采用改進后加入Attention 機制的CBOW 模型獲取詞向量,相比正常只采用CBOW 模型的CNN-雙層BIGRU 模型,整體上的情感分類準確率更高。當迭代次數為20 次時,二者均達到了各自準確率的峰值,且僅相差1.21%,說明能準確、快速提取到文本中的重要詞向量對于模型分類的重要性。以上實驗證實了本文提出的改進詞向量的CNN-雙層BIGRU 模型在情感分析中具有較好效果。
4 結語
本文主要通過兩方面對傳統情感分析方法進行改進:在詞向量方面,在對文本進行分析時,發現即使再優秀的模型,若對數據集文本中的每個詞不能準確地進行提取與定位,效果也會不佳,故加入Attention 機制進行改進;在模型方面,將能提取局部信息的CNN 與能加強特征信息以獲取上下文信息的雙層BIGRU 相融合,提高了模型準確率。雖然通過改進提高了模型準確率,但由于模型疊加層數多,導致時間效率不高,且隨著數據規模的增長,計算會更加復雜,訓練時間也會顯著變長,因此下一步將繼續尋找可兼顧準確率與時間效率的模型進行情感分析。
猜你喜歡
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:24
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
山東工業技術(2016年15期)2016-12-01 05:31:22
小學教學參考(2015年20期)2016-01-15 08:44:38
