基于改進Inception-ResNet_v2的低資源少數民族語音識別
2022-08-25 09:56:44賈嘉敏潘文林
軟件導刊 2022年8期
賈嘉敏,潘文林
(云南民族大學數學與計算機科學學院,云南昆明 650500)
0 引言
語言是人類相互間傳遞信息最原始、便捷的工具,更是文化傳承的重要載體[1]。漢語和少數民族語言作為中華民族文化的瑰寶,更是一個民族重要的象征。然而,在當今全球化發展的進程中,伴隨著各民族文化的融合,少數民族語言文化遺產的傳承與保護迫在眉睫。其中,對于跨中緬邊境的少數民族——佤族而言,為維護邊境穩定、增強國家認同,對其語言的傳承與保護顯得更加重要[2-3]。相比于語言資源豐富的漢語、壯語等語種,佤語因使用人數較少,較難收集到大量語料用于語音識別研究[4]。在當前參差不齊的語言環境下,很多少數民族語言正面臨消亡的危險境地。故對于低資源的少數民族語言開展相應的語音識別研究具有極為重要的文化保護價值。通過積極推動少數民族語言文化研究,能更好地對其進行保護與傳承,也是響應我國推動社會主義文化大發展、大繁榮的號召,推動語言及文化的多元發展。
現階段對于少數民族的語音識別研究主要是從基于語音信號[5]和語譜圖[6]兩個角度切入。針對基于語音信號的語音識別研究,李余芳等[7]分別利用特定發音人和非特定發音人所錄的語音進行隱馬爾可夫模型(Hidden Markov Model,HMM)訓練,對普米語孤立詞進行識別;趙爾平等[8]利用藏語語音學特征提出改進的藏語孤立詞語音識別方法,識別精度可達92.83%;胡文君等[9]利用kaldi 分別訓練5種不同的聲學模型,發現G-DNN 模型的普米語語音識別率明顯高于Monophone、Triphone1、Triphone2 及OSGMM 模型;穆凱代姆罕·伊敏江等[10]構建CNN-HMM 聲學模型和遞歸神經網絡(Recurrent Neural Network,RNN)語言模型,提升了維吾爾語語音識別精度;黃曉輝等[11]通過探究循環神經網絡模型對于藏語具有更好的識別性能,驗證了Bi-LSTM-CTC 模型應用于藏語語音聲學建模的可行性。針對基于語譜圖的語音識別研究,董華珍[12]引入基于卷積神經網絡的語譜圖模型,通過卷積神經網絡(Convolutional Neural Networks,CNN)對普米語孤立詞語譜圖分類進行探究,驗證其算法的可行性;侯俊龍等[13]將剪枝的卷積神經網絡AlexNet 模型用于普米語孤立詞識別,識別精度高達98.53%;楊建香[14]基于殘差網絡的佤語孤立詞語音識別精度可達96.3%,且連續語音語譜圖識別率為90.2%,驗證了其模型具有良好的魯棒性。
上述工作都獲得了相當不錯的成果,但是其中針對語譜圖的研究中,數據集設計存在不足之處,即同一個說話人說的詞會同時出現在訓練集和測試集中,在模型訓練過程中會產生過擬合的可能。因此,在低資源的少數民族語音識別中應更加合理地設計數據集劃分,以驗證模型的有效性。
同時,近年來隨著計算性能的不斷提升以及數據量的飛速增長,各種新型神經網絡模型不斷涌現,如Inception[15]、Resnet[16]、Transformer[17]、長短時記憶網絡(Long-Short Term Memory,LSTM)[18]等模型可從空間維度層面提升網絡性能,相關研究都取得了不錯的成果。然而,受限于佤語語料采集難度較大及研究基礎薄弱等問題,Inception 模型在語音識別上的應用研究未能進一步深入。因此,本文嘗試將Inception 模型應用于佤語的語音識別研究中,并在此基礎上結合擠壓—激勵模塊(Squeeze-and-Excitation Block,SE-Block)構建一種更優化的卷積神經網絡模型,以驗證該模型應用于少數民族語音識別的可行性。
1 模型介紹
1.1 Inception-ResNet_v2網絡
Inception-ResNet_v2 模型由Google 團隊于2016 年提出,其是在Inception 模型中引入Resnet 結構而生成的[19]。其中,Inception 結構是通過嵌入可提取多尺度信息的過濾器,并聚合來自不同感受野上的特征,從而實現性能的增益,同時采用1x1 卷積核進行降維處理以減少計算量。引入ResNet 結構可減少因層數增多而造成的過擬合及梯度消失現象,從而有效地加速收斂。Inception-ResNet_v2 模型結構如圖1所示。
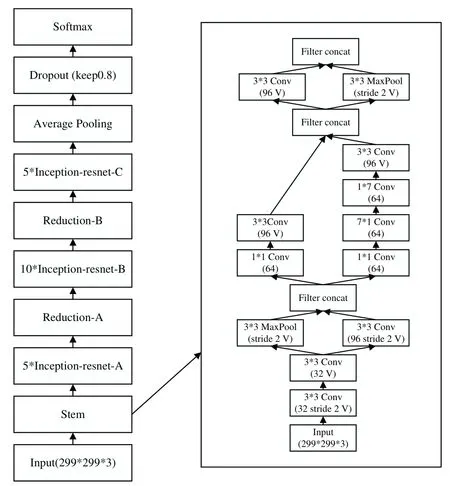
Fig.1 Inception-ResNet_v2 model structure圖1 Inception-ResNet_v2模型結構
該模型是基于原Inception 模型的進一步改進。對于輸入的299*299*3 語譜圖,先執行初始操作集Stem 模塊,以獲得更深的網絡結構。在進入Inception-Resnet 模塊時,Inception 模塊內的原池化操作被替換為殘差連接,即在Inception 中加入ResNet 思想,并在add 之前使用線性的1x1卷積對齊維度。Inception-Resnet A、B、C 3 組模塊結構相似,不同的是卷積核大小和尺度個數,其中Inception-ResNet 結構如圖2 所示。同時引入專門的Reduction 模塊用于改變特征圖大小,該模塊同樣采用多尺度信息提取的Inception 結構,以防止出現bottleneck 問題。
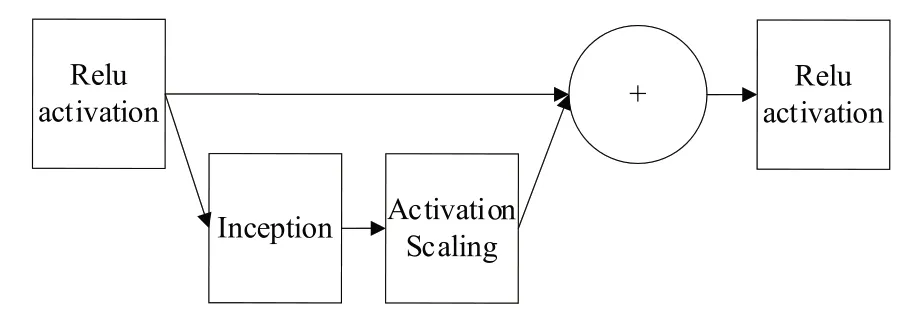
Fig.2 Inception-ResNet structure圖2 Inception-ResNet結構
1.2 SE-Block模塊
Squeeze-and-Excitation Block(簡稱SE-Block)是一種全新的特征重標定模塊。通過學習的方式自動獲取每個特征通道權重,然后依照其權重大小提高對當前任務有用的特征信息權重,并抑制對當前任務作用不大的特征信息權重,從而加快網絡訓練速度[20]。SE-Block 并不是一個完整的網絡結構,而是一個子結構,可嵌入到其他主流的分類、檢測模型中。將其引入到各種網絡模型中,可提高該網絡對特征維度的信息通道選擇能力,從而達到優化網絡性能的目的。故本文嘗試將SE-Block 插入Inception-ResNet_v2中并進行微調,訓練出優化后的模型。
SE-Block 示意圖如圖3 所示(彩圖掃OSID 碼可見,下同)。
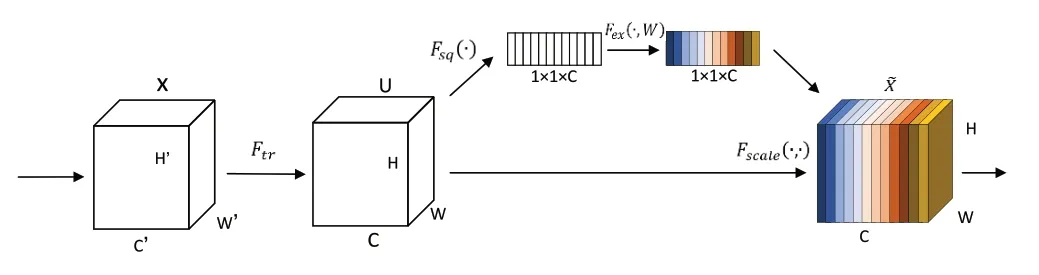
Fig.3 SE-Block diagram圖3 SE-Block示意圖
對于一個給定的特征圖,SE-Block 將通過如下步驟進行特征重標定:

Step2:通過Squeeze 操作進行特征壓縮,將每個二維平面的特征通道擠壓成一個實數,如式(2)所示。每個實數等價于具有全局的感受野,并且輸出的維度個數與輸入的特征通道數相對應。

Step3:為利用上一步操作中聚集的信息,通過Excitation操作進行自適應調整,如式(3)所示。

通過FC-ReLU-FC-Sigmoid 的過程得到一個維度為1 × 1 ×C的s,其作為特征通道的權重,以表征特征通道的重要程度。
Step4:最后進行Reweight 操作,將對應通道的每個元素與Excitation 的輸出權重分別相乘,如式(4)所示,從而實現了在通道維度上對原始特征的重標定。

SE-Block 的嵌入增加了網絡中的特征權重,即增大有效權重所占比重。
1.3 改進的Inception-ResNet_v2網絡
SE-Block 具有高效性與靈活性,目前已廣泛應用于圖像識別中。為提取到更精細的語譜圖特征,本文參考文獻[21]中的方法,嘗試將SE-Block 嵌入Inception-ResNet_v2模型中,探究SE-Block 對加強語譜圖信息提取的能力,并把激活函數由原本的ReLU 替換為Leaky ReLU,從而進一步提高語音識別精度。具體方法為在每個Inception-ResNet 模塊后加入SE-Block 進行特征重標定,以提升模型對channel特征的敏感性。
改進的Inception-ResNet_v2 網絡模型總體結構如圖4所示。
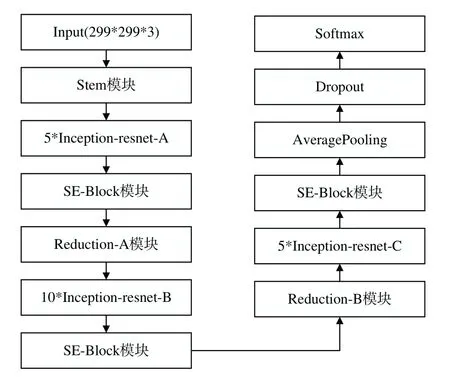
Fig.4 Overall structure of the model in this paper圖4 本文模型總體結構
2 實驗設計與結果分析
2.1 實驗環境及數據集
本文的實驗環境主要在Python 開發環境中,使用TensorFlow 深度學習框架進行搭建,操作系統為Win10.0。
實驗選用佤語作為研究對象,所用的佤語語料庫為300 個孤立詞,由2 男2 女分別重復讀5 遍生成,共得到6 000 條孤立詞語音。后期分別對語音語料進行歸類整理,生成300類帶標簽的佤語孤立詞語音語料庫。
為實現對語音信號的精確識別,實驗前期首先對語料庫中的原始語音信號進行傅里葉變換,生成對應語譜圖(見圖5),然后通過reshape 將每張語譜圖固定為同樣大小,即生成大小均為299×299×3 的6 000 張佤語孤立詞語譜圖,最終組成本次實驗所需的數據集。在圖5 中,如標記13_1_2是指由第一個人讀的第13個孤立詞的第2遍。

Fig.5 Phonological spectrogram of isolated words in Wa language圖5 佤語孤立詞語音語譜圖
2.2 實驗過程
少數民族孤立詞語音識別訓練流程如圖6 所示。首先通過對原始語音信號進行數據預處理,得到各條語音對應的語譜圖;然后將數據集中的所有數據劃分為訓練集、驗證集和測試集,再將其輸入到改進的Inception-ResNet_v2 模型中進行訓練,經Softmax 輸出分類結果;通過觀察驗證集精度是否達預期精度要求,不斷進行調參優化訓練,直至超過預期精度值;最后在測試集上進行測試,得到對應的模型識別結果。
對于數據集劃分作如下設計:對于佤語數據集,說話者共有4 人,選取其中3 位發音人的語音數據作為訓練集和驗證集(其中訓練集占比90%,驗證集占比10%),另外1位發音人的語音數據作為測試集進行實驗,得出相應的識別精度作為模型的識別精度值。

Fig.6 Training process of minority isolated word speech recognition圖6 少數民族孤立詞語音識別訓練流程
2.3 實驗結果分析
2.3.1 不同學習率訓練情況
為了觀察學習率對模型泛化性能的影響,分別對不同學習率進行對比實驗。同樣都訓練300 輪,在改進的Inception-ResNet_v2 模型中對佤語孤立詞語音分別進行訓練,并以驗證集精度和損失變化曲線作為衡量指標進行性能評估。圖7 為取不同學習率α(0.000 5、0.001 5、0.005、0.007 5),在佤語數據集上的訓練情況。可明顯看出,隨著學習率的不斷提高,模型收斂速度與精度都顯著提高。當學習率達到0.005 時,模型收斂速度明顯變快,精度也達到最高。但當學習率繼續提高至0.0075 時,模型精度則出現下降,實驗效果變差。
2.3.2 不同動量訓練情況
在模型訓練中,動量可加速SDG 在某一方向上的搜索以及減少震蕩現象。當前后梯度方向一致時,動量梯度下降可加速學習。而當前后梯度方向不一致時,動量梯度下降可抑制震蕩。因此,本次實驗在其他條件不變的情況下,選取學習率為0.005,訓練300 輪次,對比不同動量下梯度下降法的效果,如圖8所示。
實驗將參數β設為0.5、0.9、0.98,分別表示最大速度2倍、10 倍、50 倍于SGD 的算法。通過對不同超參數β的對比研究,發現當β為0.9 時,在訓練期間的震蕩明顯減弱,過程更加平穩,故此實驗取動量β=0.9。
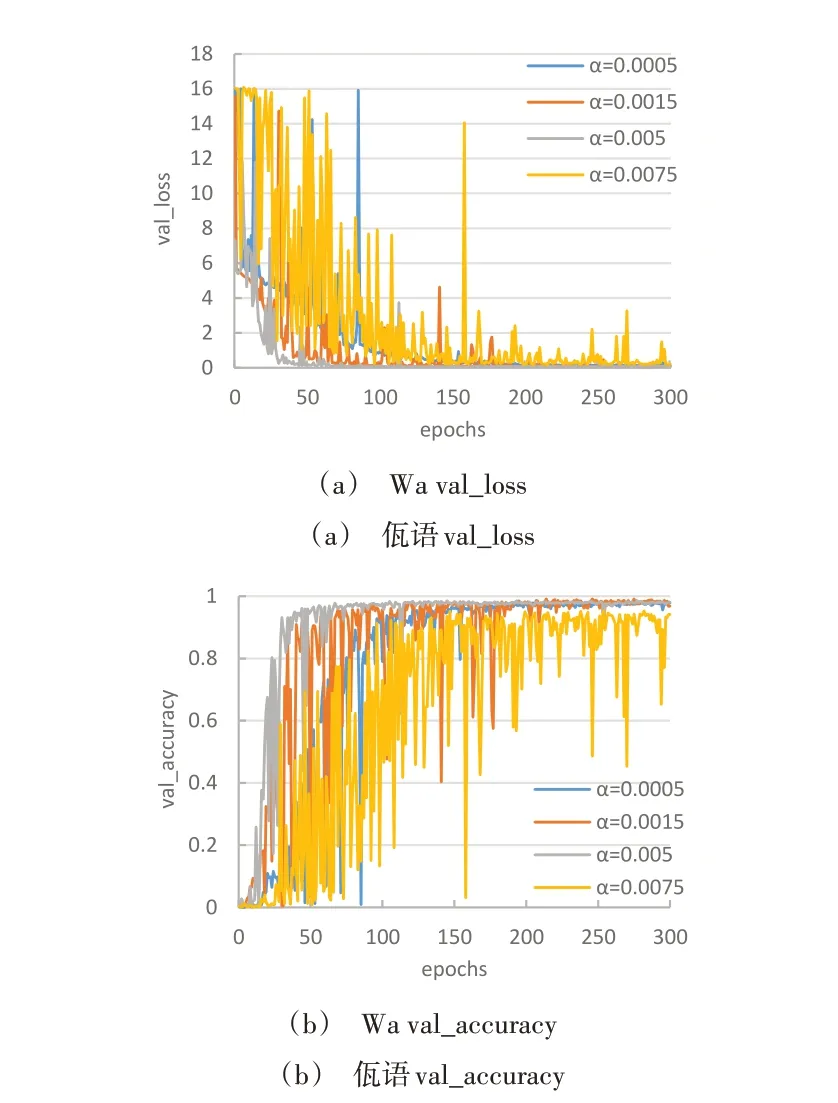
Fig.7 Training in Wa language dataset with different learning rates圖7 不同學習率下佤語數據集訓練情況
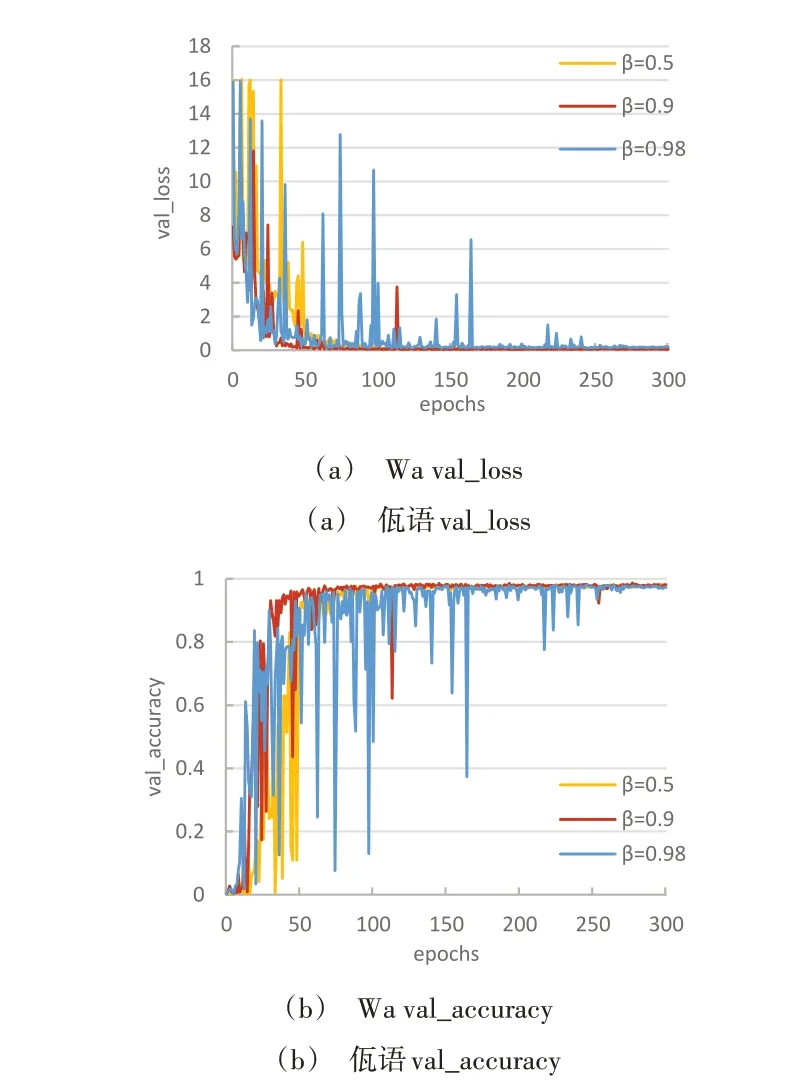
Fig.8 Training of Wa language dataset under different momentum圖8 不同動量下佤語數據集訓練情況
根據以上對比實驗與反復調試,最終確定模型超參數如下:學習率α為0.005,動量β為0.9,批大小為16。通過上述實驗訓練,實現了改進的Inception-ResNet_v2 模型對佤語孤立詞語音的識別。
2.3.3 不同模型下語音識別精度
為驗證本文方法的有效性,選擇Inception_v1、Inception_v4、Resnet_50 與Inception_resnet_v2 進行對比實驗。表1 為不同模型在佤語孤立詞語音識別中的精度比較,由表中數據可知,加入SE-Block 后的Inception_Resnet_v2 模型效果得到進一步提升,相較于其他主流模型,改進的Inception_Resnet_v2模型識別精度最高,達到80.02%。
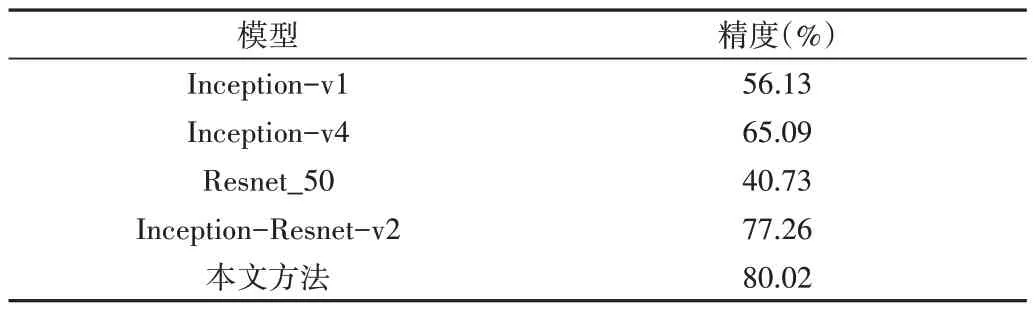
Table 1 Comparison of the accuracy of different models in Wa isolated word speech recognition表1 不同模型在佤語孤立詞語音識別中的精度比較
3 結語
本文提出基于改進Inception-Resnet_v2 的少數民族孤立詞語音識別方法,通過引入SE-Block 模塊,增強了模型的特征提取能力,在對非特定人的佤語孤立詞識別中取得了較好效果。實驗結果表明,該模型的識別性能最優,識別精度可達80.02%。證明本文方法可較好地應用于低資源少數民族語音識別中,為低資源少數民族語音識別提供了新思路。在接下來的工作中,可繼續擴充語料庫以解決說話人數較少的問題,在進一步提升模型識別精度的同時,為探究少數民族連續語音識別打下基礎。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
