基于Kettle的數(shù)據(jù)轉(zhuǎn)換同步方法研究
2022-08-25 09:56:56韋亞軍張文文李冬青
軟件導(dǎo)刊 2022年8期
韋亞軍,張文文,李冬青
(南京國圖信息產(chǎn)業(yè)有限公司,江蘇南京 210000)
0 引言
隨著自然資源信息化體系的完善,各機(jī)構(gòu)改革逐步落實(shí)到位。如何更加高效、安全、靈活地實(shí)現(xiàn)各部門、各應(yīng)用系統(tǒng)之間的數(shù)據(jù)轉(zhuǎn)換、同步及遷移工作成為當(dāng)前自然資源信息化建設(shè)面臨的重要難題[1-3]。目前數(shù)據(jù)轉(zhuǎn)換、同步工作一般采用兩種方法[4-7]:一種是借助專業(yè)的抽取—轉(zhuǎn)換—加載(Extract-Transform-Load,ETL)工具實(shí)現(xiàn),如Oracle數(shù)據(jù)庫的OWB、SQL Server 2000 的DTS、達(dá)夢(mèng)數(shù)據(jù)庫DTS等,該方法通常要求目標(biāo)數(shù)據(jù)庫必須是指定類型,因此缺乏靈活性;另一種是通過SQL 編程的方式實(shí)現(xiàn),可有效提高ETL 運(yùn)行效率,但編碼復(fù)雜,難以快速構(gòu)建ETL 工作環(huán)境,具有一定的應(yīng)用局限性。
針對(duì)上述問題,結(jié)合自然資源信息化體系建設(shè)過程中數(shù)據(jù)多源、數(shù)據(jù)量大、結(jié)構(gòu)復(fù)雜等特點(diǎn),本文基于開源ETL工具Kettle 構(gòu)建源數(shù)據(jù)庫轉(zhuǎn)換同步環(huán)境,并提出一種新的數(shù)據(jù)轉(zhuǎn)換同步方法。該方法充分融合集成了傳統(tǒng)ETL 工具與SQL 編程二者的優(yōu)勢(shì),解決了ETL 工具目標(biāo)數(shù)據(jù)庫需指定類型的不足以及SQL 編程方法的局限性問題,提高了開發(fā)速度和工作效率,有效解決了自然資源信息化建設(shè)過程中多源數(shù)據(jù)到目標(biāo)數(shù)據(jù)的轉(zhuǎn)換與同步難題,同時(shí)也為企業(yè)的數(shù)據(jù)集成工作提供了更多思路。
1 Kettle簡介
Kettle 是一款強(qiáng)大、開源的ETL 工具,又名“水壺”,意為將各種數(shù)據(jù)放到一個(gè)壺中,然后以一種指定的格式流出。Kettle 支持可視化的圖形用戶界面(Graphics User Interface,GUI),以工作流的形式流轉(zhuǎn),無需安裝即可在Windows、Linux 及Unix 系統(tǒng)上運(yùn)行,數(shù)據(jù)抽取、轉(zhuǎn)換、同步、過濾功能高效穩(wěn)定[8-11]。
Kettle 的數(shù)據(jù)集成功能主要由轉(zhuǎn)換(Transformation)和作業(yè)(Job)兩個(gè)核心組件完成,其中轉(zhuǎn)換組件為進(jìn)行數(shù)據(jù)操作的容器,數(shù)據(jù)操作即數(shù)據(jù)從輸入到輸出的過程,每一個(gè)轉(zhuǎn)換表示對(duì)一個(gè)或多個(gè)數(shù)據(jù)流進(jìn)行特定的數(shù)據(jù)操作;作業(yè)組件負(fù)責(zé)將一個(gè)或多個(gè)轉(zhuǎn)換組織在一起,根據(jù)事先設(shè)定的工作流模式,協(xié)調(diào)數(shù)據(jù)源并執(zhí)行轉(zhuǎn)換活動(dòng),從而完成一項(xiàng)特定的數(shù)據(jù)處理任務(wù)。通常情況下,一項(xiàng)大型任務(wù)會(huì)被分解為多個(gè)邏輯上隔離的作業(yè),作業(yè)完成即代表該數(shù)據(jù)處理任務(wù)完成[12-15]。Kettle 的概念模型如圖1所示。
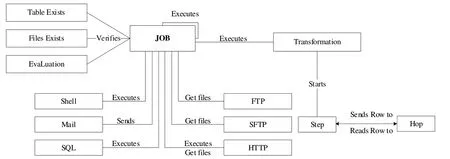
Fig.1 Kettle conceptual model diagram圖1 Kettle概念模型圖
2 應(yīng)用場景
根據(jù)操作系統(tǒng)網(wǎng)絡(luò)環(huán)境的不同,Kettle 的應(yīng)用場景可分為3 種[16],分別為表視圖、前置機(jī)和文件模式,具體如圖2 所示。其中,表視圖模式是數(shù)據(jù)集成處理中經(jīng)常遇到的場景,即在同一網(wǎng)絡(luò)環(huán)境下需要對(duì)多種數(shù)據(jù)源進(jìn)行抽取、篩選、轉(zhuǎn)換和加載等,如歷史數(shù)據(jù)同步、異構(gòu)系統(tǒng)數(shù)據(jù)交互、數(shù)據(jù)對(duì)稱發(fā)布或備份;前置機(jī)模式是一種典型的數(shù)據(jù)交換模式,數(shù)據(jù)交互雙方A 和B 在網(wǎng)絡(luò)不通的情況下可以通過前置機(jī)C 實(shí)現(xiàn)連接,此時(shí)雙方可以約定好前置機(jī)C 的數(shù)據(jù)庫結(jié)構(gòu)標(biāo)準(zhǔn),通過開發(fā)應(yīng)用接口將數(shù)據(jù)組織成標(biāo)準(zhǔn)結(jié)構(gòu)并推送至前置機(jī);文件模式是指當(dāng)數(shù)據(jù)交互雙方A 和B完全物理隔離時(shí),只能通過指定格式文件的方式實(shí)現(xiàn)數(shù)據(jù)交互,如XML 格式。該模式在應(yīng)用A 中開發(fā)應(yīng)用接口用于生成標(biāo)準(zhǔn)格式的文件,然后通過移動(dòng)硬盤等介質(zhì)在某一時(shí)間拷貝文件接入應(yīng)用B,應(yīng)用B 按照標(biāo)準(zhǔn)接口規(guī)范接收數(shù)據(jù)。以上3 種應(yīng)用場景若均從系統(tǒng)層面實(shí)現(xiàn)數(shù)據(jù)同步轉(zhuǎn)換,無疑工作量巨大,同時(shí)涉及到一些復(fù)雜的業(yè)務(wù)和邏輯,還會(huì)產(chǎn)生一定的程序錯(cuò)誤,增加了項(xiàng)目投入成本。而利用Kettle 完成數(shù)據(jù)同步轉(zhuǎn)換工作可有效減少研發(fā)工作量,提高工作效率。
3 數(shù)據(jù)同步方法
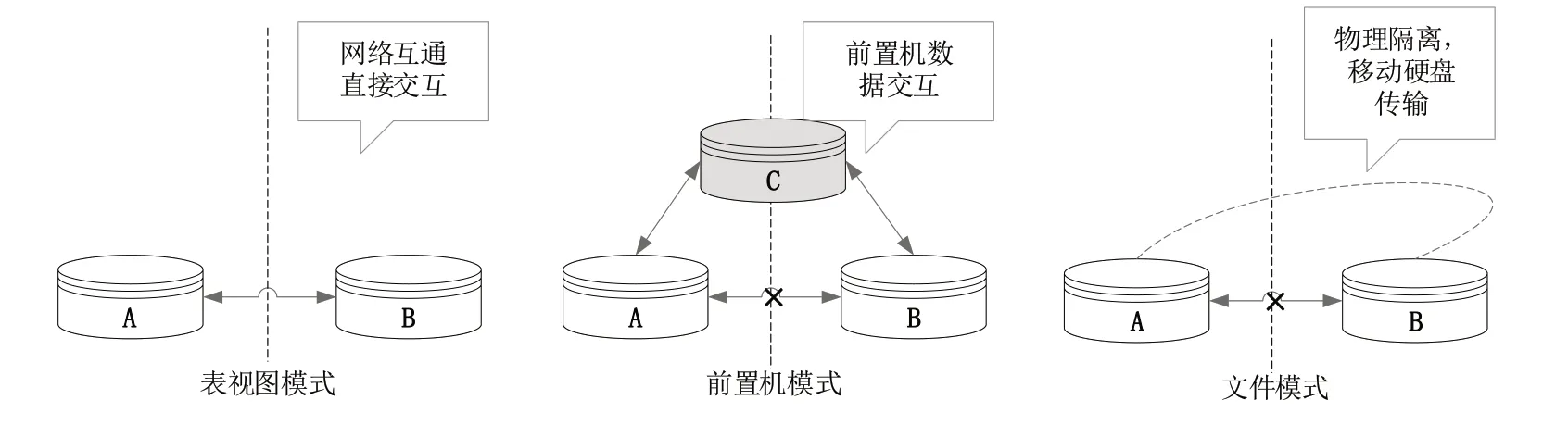
Fig.2 Kettle application scenario圖2 Kettle應(yīng)用場景
基于Kettle 的數(shù)據(jù)轉(zhuǎn)換同步方法是通過Kettle 制定數(shù)據(jù)抽取、篩選、轉(zhuǎn)換規(guī)則,并以工作流的形式執(zhí)行作業(yè)任務(wù),從而實(shí)現(xiàn)數(shù)據(jù)轉(zhuǎn)換、同步工作。主要步驟為首先在數(shù)據(jù)同步工作前對(duì)業(yè)務(wù)需求進(jìn)行分析,制定一套詳細(xì)且專業(yè)的數(shù)據(jù)同步流程和策略;然后將該同步流程和策略轉(zhuǎn)化為Kettle 可識(shí)別的轉(zhuǎn)換腳本和作業(yè)流程;最后形成基于Kettle的源數(shù)據(jù)庫轉(zhuǎn)換同步環(huán)境,實(shí)現(xiàn)源數(shù)據(jù)到目標(biāo)數(shù)據(jù)的高效持續(xù)更新機(jī)制[17]。
3.1 業(yè)務(wù)需求分析
某自然資源與規(guī)劃局的自然資源一體化業(yè)務(wù)審批系統(tǒng)(以下簡稱審批系統(tǒng))由我司研發(fā)并已上線運(yùn)行,檔案管理系統(tǒng)則由另一家公司研發(fā),兩個(gè)系統(tǒng)分布在不同的網(wǎng)絡(luò)環(huán)境中,無法直接進(jìn)行交互,但可以通過前置機(jī)完成連接。現(xiàn)局方要求我司協(xié)助完成業(yè)務(wù)審批數(shù)據(jù)歸檔工作,每天定時(shí)將審批系統(tǒng)已辦結(jié)的業(yè)務(wù)數(shù)據(jù)同步至前置機(jī)數(shù)據(jù)庫(以下簡稱目標(biāo)數(shù)據(jù)庫),該目標(biāo)數(shù)據(jù)庫由檔案管理系統(tǒng)研發(fā)公司設(shè)計(jì),檔案管理系統(tǒng)獲取目標(biāo)數(shù)據(jù)庫中的數(shù)據(jù)進(jìn)行歸檔操作。
上述業(yè)務(wù)場景為典型的前置機(jī)模式,要求歸檔的數(shù)據(jù)包括土地、礦產(chǎn)、林業(yè)、綜合事務(wù)等,涉及審批系統(tǒng)中的多個(gè)數(shù)據(jù)源(以下簡稱源數(shù)據(jù)庫)。由于系統(tǒng)已經(jīng)上線運(yùn)行,除需完成新的業(yè)務(wù)數(shù)據(jù)同步外,還需要實(shí)現(xiàn)歷史數(shù)據(jù)的歸檔工作。
3.2 同步流程
結(jié)合業(yè)務(wù)需求分析,本次數(shù)據(jù)同步除需完成日常增量數(shù)據(jù)同步外,還應(yīng)完成歷史數(shù)據(jù)全量同步。為防止重復(fù)全量同步操作,本文設(shè)計(jì)了增量和全量數(shù)據(jù)同步流程,在啟動(dòng)定時(shí)作業(yè)任務(wù)后,首先判斷目標(biāo)數(shù)據(jù)庫的記錄數(shù),確定是否已經(jīng)存在歷史業(yè)務(wù)數(shù)據(jù),若不存在,則可以先進(jìn)行全量數(shù)據(jù)同步,確保歷史數(shù)據(jù)同步到目標(biāo)數(shù)據(jù)庫,防止數(shù)據(jù)丟失[18-19]。數(shù)據(jù)同步流程如圖3所示。
3.3 同步策略
結(jié)合實(shí)際需求及數(shù)據(jù)同步流程,本文制定了數(shù)據(jù)結(jié)構(gòu)分析、數(shù)據(jù)篩選、數(shù)據(jù)組合、數(shù)據(jù)規(guī)范、數(shù)據(jù)清理和數(shù)據(jù)校驗(yàn)6個(gè)同步策略。
3.3.1 數(shù)據(jù)結(jié)構(gòu)分析
數(shù)據(jù)結(jié)構(gòu)分析策略主要針對(duì)源數(shù)據(jù)庫和目標(biāo)數(shù)據(jù)庫的表結(jié)構(gòu)、E-R 圖進(jìn)行分析,形成源數(shù)據(jù)庫和目標(biāo)數(shù)據(jù)庫表與表、字段與字段之間的對(duì)應(yīng)關(guān)系,利用Excel 表格、思維導(dǎo)圖等形式整理記錄各數(shù)據(jù)庫表、字段的對(duì)應(yīng)關(guān)系,具體示例如圖4所示。
3.3.2 數(shù)據(jù)篩選
根據(jù)實(shí)際業(yè)務(wù)需求,從源數(shù)據(jù)庫中篩選滿足要求的基礎(chǔ)數(shù)據(jù)信息,剔除目標(biāo)數(shù)據(jù)庫不需要的表和字段,獲得滿足實(shí)際要求的各類業(yè)務(wù)數(shù)據(jù)信息,解決無效數(shù)據(jù)同步到目標(biāo)數(shù)據(jù)庫的問題。利用Kettle 工具輸入組件完成源數(shù)據(jù)篩選,具體操作如圖5所示。
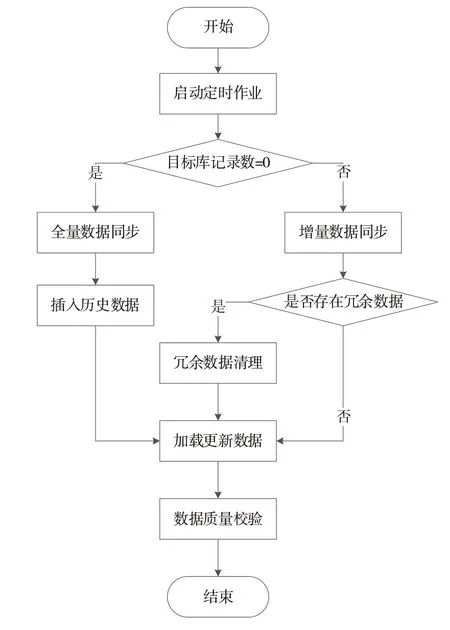
Fig.3 Data synchronization process圖3 數(shù)據(jù)同步流程
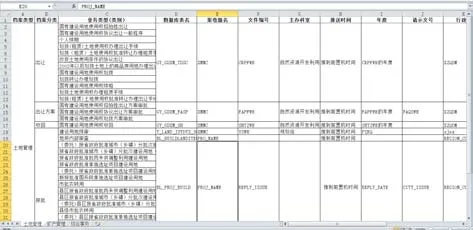
Fig.4 Data structure analysis example圖4 數(shù)據(jù)結(jié)構(gòu)分析示例

Fig.5 Data screening process圖5 數(shù)據(jù)篩選操作
3.3.3 數(shù)據(jù)組合
在源數(shù)據(jù)篩選過程中建立統(tǒng)一的業(yè)務(wù)主鍵,建立各表之間的組合關(guān)系,完成源數(shù)據(jù)基礎(chǔ)數(shù)據(jù)重組,解決數(shù)據(jù)同步過程中業(yè)務(wù)缺失、關(guān)鍵信息不全等問題。
3.3.4 數(shù)據(jù)規(guī)范
根據(jù)目標(biāo)數(shù)據(jù)庫標(biāo)準(zhǔn)要求,對(duì)篩選的基礎(chǔ)數(shù)據(jù)進(jìn)行規(guī)范化處理,建立同步數(shù)據(jù)標(biāo)準(zhǔn),解決數(shù)據(jù)規(guī)范不一致、格式不統(tǒng)一等問題。
3.3.5 數(shù)據(jù)清理
進(jìn)行增量數(shù)據(jù)同步前,檢查并清理目標(biāo)數(shù)據(jù)庫中已經(jīng)存在的冗余數(shù)據(jù),以保證目標(biāo)數(shù)據(jù)庫數(shù)據(jù)的實(shí)時(shí)性、準(zhǔn)確性。
3.3.6 數(shù)據(jù)校驗(yàn)
針對(duì)目標(biāo)數(shù)據(jù)庫的數(shù)據(jù)業(yè)務(wù)邏輯關(guān)系進(jìn)行校驗(yàn),剔除不符合校驗(yàn)規(guī)則的數(shù)據(jù),完成數(shù)據(jù)質(zhì)檢工作,解決數(shù)據(jù)質(zhì)量不符合要求的問題。
根據(jù)以上數(shù)據(jù)同步策略,結(jié)合實(shí)際需求分析,本文設(shè)計(jì)了如圖6 所示的數(shù)據(jù)同步架構(gòu),構(gòu)建了基于Kettle 的源數(shù)據(jù)庫轉(zhuǎn)換同步環(huán)境,形成了由源數(shù)據(jù)庫到目標(biāo)數(shù)據(jù)庫的自動(dòng)持續(xù)更新機(jī)制。
4 業(yè)務(wù)應(yīng)用
利用基于Kettle 的數(shù)據(jù)轉(zhuǎn)換同步方法,結(jié)合源數(shù)據(jù)庫轉(zhuǎn)換同步環(huán)境,設(shè)計(jì)了本次數(shù)據(jù)轉(zhuǎn)換同步的轉(zhuǎn)換腳本和作業(yè)任務(wù),使審批系統(tǒng)各項(xiàng)業(yè)務(wù)數(shù)據(jù)轉(zhuǎn)換為可供檔案管理系統(tǒng)使用、分析、決策的目標(biāo)數(shù)據(jù),并對(duì)其進(jìn)行校驗(yàn)。同時(shí),開發(fā)了定時(shí)觸發(fā)腳本文件,以完成對(duì)作業(yè)任務(wù)的定時(shí)調(diào)度,實(shí)現(xiàn)源數(shù)據(jù)到目標(biāo)數(shù)據(jù)的自動(dòng)持續(xù)更新。

Fig.6 Data synchronization architecture圖6 數(shù)據(jù)同步架構(gòu)
4.1 基于Kettle的作業(yè)任務(wù)
基于實(shí)際業(yè)務(wù)需求,對(duì)審批系統(tǒng)土地、礦產(chǎn)、林業(yè)、綜合事務(wù)等業(yè)務(wù)數(shù)據(jù)進(jìn)行篩選、拼接,并與附件材料數(shù)據(jù)關(guān)聯(lián)、合并,對(duì)其中的非標(biāo)準(zhǔn)數(shù)據(jù)進(jìn)行規(guī)范化處理,部分?jǐn)?shù)據(jù)處理示例如圖7 所示。應(yīng)用數(shù)據(jù)篩選、數(shù)據(jù)組合、數(shù)據(jù)規(guī)范及數(shù)據(jù)清理4 個(gè)同步策略構(gòu)建審批系統(tǒng)業(yè)務(wù)數(shù)據(jù)轉(zhuǎn)換流程,見圖8。同時(shí)建立作業(yè)任務(wù),集成所有轉(zhuǎn)換流程,實(shí)現(xiàn)對(duì)整個(gè)審批系統(tǒng)從源數(shù)據(jù)到目標(biāo)數(shù)據(jù)同步的集成控制,維護(hù)數(shù)據(jù)同步的流程秩序。

Fig.7 Data processing example圖7 數(shù)據(jù)處理示例
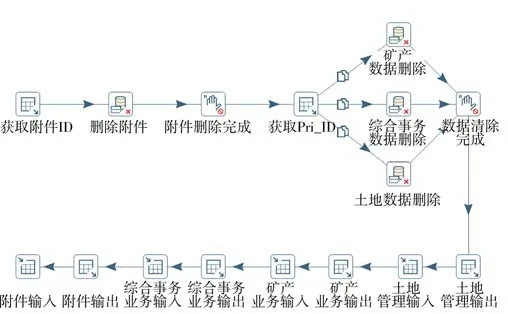
Fig.8 Data transformation flow圖8 數(shù)據(jù)轉(zhuǎn)換流程
數(shù)據(jù)轉(zhuǎn)換、同步工作完成后需對(duì)結(jié)果進(jìn)行數(shù)據(jù)校驗(yàn),校驗(yàn)內(nèi)容主要包括目標(biāo)數(shù)據(jù)庫表之間的邏輯關(guān)系是否符號(hào)要求,數(shù)據(jù)庫表總數(shù)、記錄總數(shù)是否與源數(shù)據(jù)一致等。對(duì)目標(biāo)數(shù)據(jù)庫部分表記錄總數(shù)進(jìn)行統(tǒng)計(jì)校驗(yàn),結(jié)果見圖9。校驗(yàn)結(jié)果表明,利用基于Kettle 的數(shù)據(jù)轉(zhuǎn)換同步方法可順利完成數(shù)據(jù)轉(zhuǎn)換、同步工作,數(shù)據(jù)轉(zhuǎn)換率、有效率、正確率均高達(dá)98%以上。
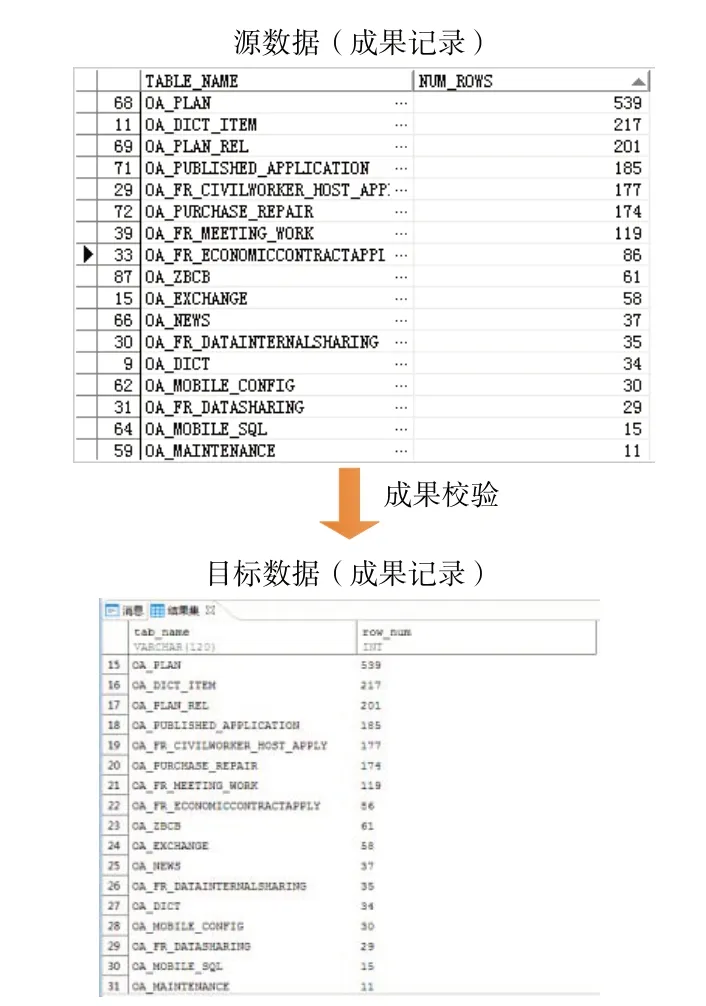
Fig.9 Data validation example圖9 數(shù)據(jù)校驗(yàn)示例
4.2 定時(shí)觸發(fā)任務(wù)
定時(shí)觸發(fā)任務(wù)主要利用Kitchen 命令行控制工具編寫.bat 腳本文件,并與Kettle 工具相結(jié)合,實(shí)現(xiàn)系統(tǒng)對(duì)作業(yè)任務(wù)的定時(shí)調(diào)度,完成源數(shù)據(jù)到目標(biāo)數(shù)據(jù)的持續(xù)更新工作。.bat腳本文件代碼為:


5 結(jié)語
本文針對(duì)實(shí)際業(yè)務(wù)需求,基于ETL 工具Kettle 制定了數(shù)據(jù)同步流程與策略,并在此基礎(chǔ)上構(gòu)建了基于Kettle 的源數(shù)據(jù)庫轉(zhuǎn)換同步環(huán)境,提出新的數(shù)據(jù)轉(zhuǎn)換同步方法,利用該方法可實(shí)現(xiàn)對(duì)審批系統(tǒng)土地、礦產(chǎn)、林業(yè)、綜合事務(wù)等數(shù)據(jù)的高效抽取、篩選、轉(zhuǎn)換和同步。校驗(yàn)結(jié)果表明,該方法數(shù)據(jù)轉(zhuǎn)換率、有效率、正確率均高達(dá)98%以上,滿足了檔案管理系統(tǒng)對(duì)目標(biāo)數(shù)據(jù)庫的查詢、分析和決策需求。同時(shí)制定了定時(shí)觸發(fā)任務(wù),解決了系統(tǒng)后臺(tái)對(duì)作業(yè)任務(wù)的定時(shí)調(diào)度問題,最終實(shí)現(xiàn)了源數(shù)據(jù)庫到目標(biāo)數(shù)據(jù)庫的高效自動(dòng)持續(xù)更新。未來將不斷完善數(shù)據(jù)規(guī)范和校驗(yàn)過程,提高數(shù)據(jù)質(zhì)量,優(yōu)化轉(zhuǎn)換作業(yè)流程,提升數(shù)據(jù)同步效率,為企業(yè)的數(shù)據(jù)轉(zhuǎn)換、同步及遷移工作提供更多思路。
猜你喜歡
工業(yè)設(shè)計(jì)(2022年8期)2022-09-09 07:43:20
軍民兩用技術(shù)與產(chǎn)品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
少年博覽·初中版(2020年6期)2020-06-12 11:42:23
家庭影院技術(shù)(2017年9期)2017-09-26 03:41:45
財(cái)經(jīng)(2017年2期)2017-03-10 14:35:35
故事大王(2016年7期)2016-09-22 17:30:08
財(cái)經(jīng)(2016年15期)2016-06-03 07:38:02
財(cái)經(jīng)(2016年3期)2016-03-07 07:44:46
財(cái)經(jīng)(2016年6期)2016-02-24 07:41:51
