基于手機的OCR測試集構建及自動化評估模型
2022-08-29 02:20:48曹慧靜
現代信息科技 2022年12期
曹慧靜
(傳音控股技術有限公司,上海 202106)
0 引 言
針對人工智能,訓練數據量的大小和豐富性決定了其準確性,因此數據集的構建對識別的準確性非常重要。針對印度市場用戶語言翻譯的問題,引入了選區翻譯功能(用戶在當下使用的界面上可以選擇需要翻譯區域進行翻譯)。根據用戶選中的內容圖像識別成文字,再把文字翻譯成需要的目標語言,用戶選中的區域內容根據用戶的使用場景和用戶的偏好而不一樣。選區翻譯相比競品有其優勢,能夠不中斷用戶當前使用頁面的閱讀體驗,而把需要翻譯的內容直接覆蓋在選中區域原文上,而不影響其他未選擇區域的閱讀,使得翻譯體驗更加便捷。
1 OCR 技術現狀研究
OCR(Optical Character Recognition)是指對文本資料的圖像文件進行分析識別處理,獲取文字及版面信息的過程。亦即將圖像中的文字進行識別,并以文本的形式返回。
OCR 識別應用很多場景,例如OCR 視頻文字識別、人臉識別、身份證件識別、票據識別、車牌碼識別、銀行卡識別等等,在業界也屬于比較成熟的應用;但是對于小語種OCR 識別能力應用于翻譯場景有待繼續提升和挖掘。OCR整體識別的流程如圖1所示。
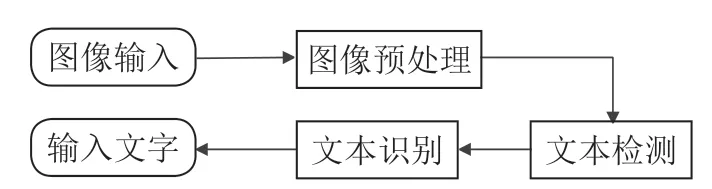
圖1 OCR 整體識別的流程
圖像預處理。通常是針對圖像的成像問題進行修正。由于深度學習的發展,現在普遍使用基于CNN 神經網絡的特征提取手段,得益于CNN 強大的學習能力,配合大量的數據可以增強特征提取的魯棒性。常見的預處理過程包括:幾何變換(透視、扭曲、旋轉等)、畸變校正、去除模糊、圖像增強和光線校正等。
文字檢測。即檢測文本的所在位置和范圍及其布局,框選出圖像中的文本區域,通常也包括版面分析和文字行檢測等。文字檢測主要解決的問題是哪里有文字,文字的范圍有多大。
文本識別。是在文本檢測的基礎上,對文本內容進行識別,將圖像中的文本信息轉化為文本信息。文字識別主要解決的問題是每個文字是什么,識別出的文本通常需要再次核對以保證其正確性,文本校正也被認為屬于這一環節。
文字識別包括以下幾個步驟:特征提取和降維—分類器設計—訓練—后處理;
2 針對手機終端上圖像測試構造方法
根據用戶在手機終端真實的使用場景,不同用戶在不同界面用戶翻譯的需求是不一樣的,翻譯的頁面元素類別不一樣,翻譯的選區大小也會有差距,需要貼合用戶的真實使用場景構造測試數據集。同時針對印度市場應用和用戶的使用習慣;印度市場語言人口使用排行榜如下:印度語—孟加拉語—古吉拉特語—奧里亞—阿薩姆語—克什米爾語。印度手機銷售市場,受教育程度低,每四個人中就有一個文盲,無法順利完成閱讀和書寫,因為基于手機目標銷售市場的小語種和用戶真實使用的場景來準備測試集至關重要,用戶場景基于以下幾個維度來分析:
圖像大小:根據選區翻譯的用戶使用場景,選區翻譯的大小需要覆蓋幾種典型的不同比例的大小,例如:選區翻譯界面是手機界面全屏、是手機界面1/4、是手機界面1/2、是手機界面3/4、是手機界面1/3、是手機界面2/3、是手機界面1/5 等。
圖像元素分析:在手機終端上,不同的用戶使用場景,界面包含的元素是不一樣的,和APP 設計和內容強相關。經過在不同用戶場景下分析手機終端上界面元素,大體上分類以下幾類:純文本型、圖片型、視頻型、圖片型文字、純文本和圖片組合、純文本型和視頻型組合、純文本和圖片型文字組合等幾種場景。
圖像上文本內容特征分析:經過分析手機不同用戶場景,不同場景的文本,其文本內容特征也有比較大差異。圖像上文本的內容特征也影響文本提取的準確性,因此測試集包含的文本內容特征越豐富,其準確性就越高。根據手機終端本文特征分析,測試集的文本特征應包含以下集中特征:不同的標點符號(: , .? ; / “”- & # ~ ...)、不同字體大小、字體加粗、項目符合、數字和文本的結合、金錢符號($)、不同語種混合(中英混合等)等等。
用戶場景APP 需求分析:根據用戶的選區翻譯需求,需要覆蓋不同的類型的應用場景,滿足不同的翻譯訴求。手機終端上的APP 大致可以分為幾大類:新聞閱讀類APP,社交類APP,電子讀書類APP、視頻類APP、游戲類APP、購物類APP、銀行類APP,其中購物類APP、游戲類APP、銀行類APP 偏工具類使用,對翻譯的訴求理論上不是特別大,因此需要重點覆蓋新聞閱讀類APP、社交類APP、電子讀書類APP 都是偏沉浸式閱讀體驗類APP,需要重點去覆蓋。
印度市場各類APP 基本與國內市場相同,除了金融投資領域,各行各業基本都有相應的互聯網服務,印度市場APP 有自己獨立的本土化的APP。
閱讀類APP:Daily hunt、谷歌News、FK、Inshorts、Prime Video、Netfix、Linkin 等。 交流場景:Whatsapp、Facebook、Outlook、Uber、Mail 等。觀影場景:YouTUbe、Prime Video、Zee5、Hotstar、OOT 等。
根據上述分析后,手機終端OCR 文本識別再翻譯的算法模型測試集構建方法如圖2所示。

圖2 印度手機終端OCR 測試集構建方法
3 針對手機終端界面OCR 識別評估模型
準對不同的OCR 使用場景,評估維度會有差別,大體上分為以下兩種:字符準確率、召回率和整行準確率、召回率。
字符準確率:即識別對的字符數占總識別出來字符數的比例,可以反映識別錯和多識別的情況,缺點是無法反應漏識別的情況。
字符識別召回率:即識別對的字符數占實際字符數的比例,可以反映識別錯和漏識別的情況,但是沒辦法反應多識別的情況,可以配套字符識別準確率一起使用。
文本行定位為的準確率和召回率:同字符識別的準確率和召回率。主要反應文本行定位的指標,是OCR 算法的重要指標;一個字段算一個整體,假如100 個字分為20 個字段,里面錯了5 個字,分布在4 個字段里,那么識別率是16/20=80%。
針對用戶場景的測試集構建之后,在手機終端閱讀類APP 上,為了更好體現OCR 文本識別后體可讀性,提出OCR 識別的句準率統計方法,同時除了計算句準率之外,為了更直觀看到OCR 句準確率、OCR 識別性能以及錯誤的情況。提出手機終端頁面OCR 識別評估模型如圖3所示。
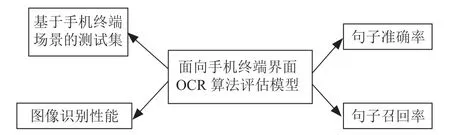
圖3 OCR 算法屏幕模型
其中圖像識別性能影響手機終端頁面翻譯體驗的時間,OCR 識別性能越好,基于OCR 應用的印度等小語種翻譯速度越快,體驗越好,因此圖像識別性能也是基于面向用戶手機終端OCR 模型質量的關鍵指標之一。
4 OCR 評估模型自動化實測試實現方法
根據上一章節提出的OCR 評估模型,無法高效的通過人手動統計方式來實現,為了提高統計的效率和準確性,需要開發一套OCR 評估模型的自動化實現方案,如圖4所示。
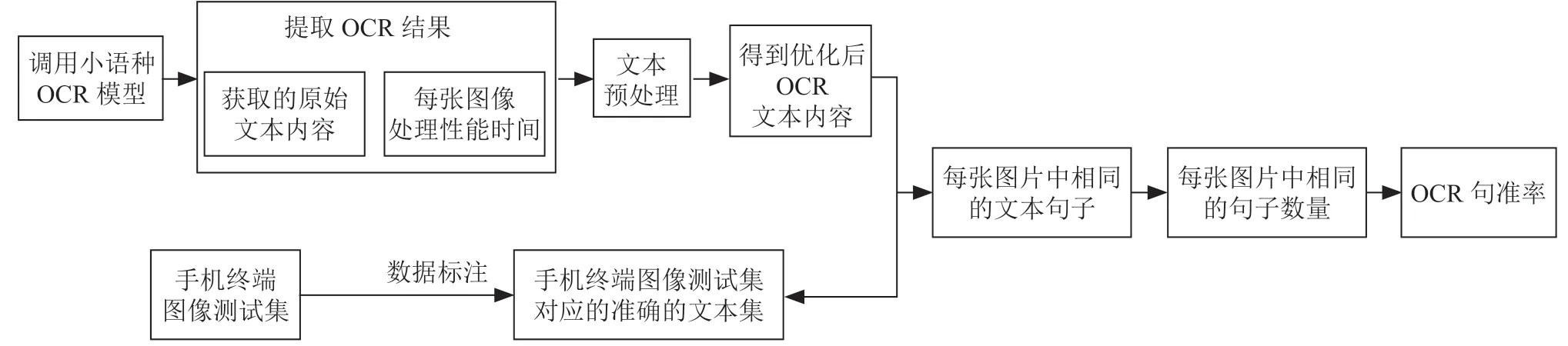
圖4 OCR 評估模型自動化實現方法
OCR 識別的關鍵指標中圖像識別性能的計算方法,調用小語種OCR 模型后,根據開始讀取每一張圖片的時候,記錄每一張圖片開始讀取的時間,以及圖像文本識別完之后的時間,通過計算兩者的時間差即為每張圖片的文本識別性能。在同一手機上,圖像識別的時間的大小和圖像大小以及和含有的文本內容數量強相關(圖像大小覆蓋在第3 章節介紹中有覆蓋到),圖像中包含的文本信息內容越多,OCR 識別的時間就越長,反之。不同的手機上,OCR 識別性能還和手機芯片平臺強相關,手機芯片性能越好,OCR 識別性能越好。
OCR 性能的關鍵性能指標中句準率/召回率體現文章中句子的準確性,句子是文本中相對較小的單位,句準率越高越能體現OCR 的模型和算法的優劣,為了自動化計算文本的句準率需要準備每一張圖像測試集對應的文本集,OCR識別到的文本后通過標點符號進行切分統計,通過逐一對比OCR 識別的文本和測試集對應的文本集對比是否匹配,通過句準率計算模型的平均準確率是在60%左右。
同時為了測試和研發方便查看,把以上相關的測試結果通過自動化寫到同一張Excel 表中統計顯示如圖5所示。
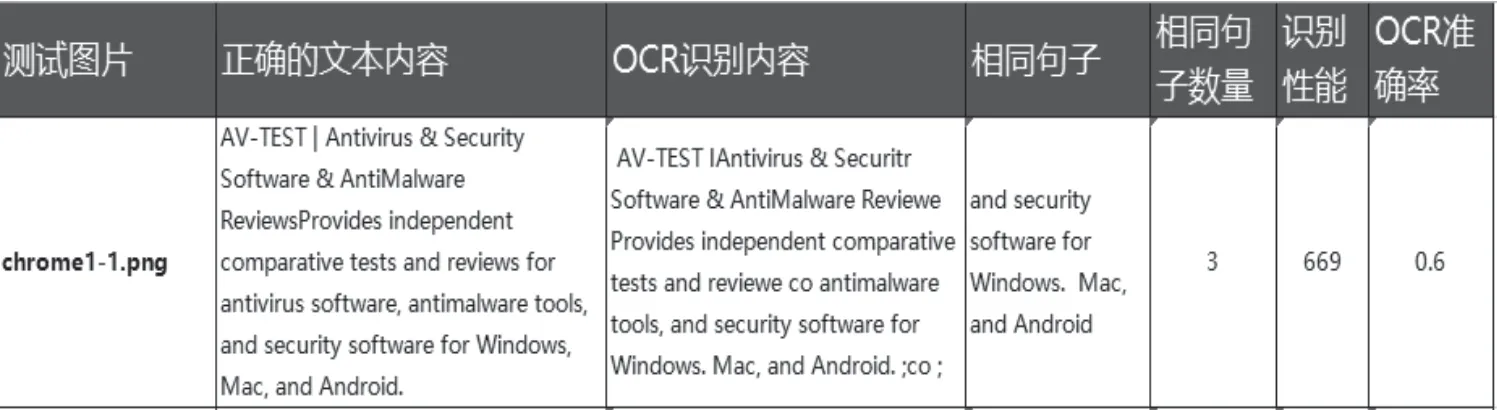
圖5 測試結果
對測試集中的每一個測試圖像中的句準率和性能數據有了很好的對比和參考;通過該自動化方法評估OCR 模型優劣。
5 結 論
根據用戶場景來構建測試集,對OCR 模型和算法的準確率至關重要。沒有符合目標用戶場景的測試數據,無法度量模型和算法的優劣,因此需要研究用戶場景中的用戶習慣和用戶的偏好,針對用戶場景的測試集才能更好地發現用戶場景的問題,提升用戶場景的體驗。因此提出了基于手機終端用戶場景OCR 測試集的構建的方法,如果是針對某單一用戶使用場景則需要去針對性地去根據用戶體驗或者人因分析后再構造該特定場景的測試集。基于該測試集提出了適合手機終端的OCR 識別的評估模型:基于用戶手機終端場景的測試集、更好體現句子可讀性的句準率/召回率來度量準確率、影響使用性能體驗的OCR 圖像識別性能以及該OCR 評估模型自動化實現。
猜你喜歡
當代陜西(2020年13期)2020-08-24 08:22:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
制造技術與機床(2017年5期)2018-01-19 02:49:17
商用汽車(2016年11期)2016-12-19 01:20:16
濰坊學院學報(2016年2期)2016-12-01 13:00:11
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
小學教學參考(2015年20期)2016-01-15 08:44:38
新聞傳播(2015年11期)2015-07-18 11:15:04
