基于注意力機制的多任務3D CNN-BLSTM 情感語音識別
2022-08-29 10:52:30陳志剛萬永菁
華東理工大學學報(自然科學版) 2022年4期
姜 特, 陳志剛, 萬永菁
(華東理工大學信息科學與工程學院,上海 200237)
語音交互是人與人之間最直接、高效的溝通方式之一。語音中包含著豐富的情感信息,而情感在語音交互中起著至關重要的作用。語音情感識別是指計算機對人類情感語音的感知和理解過程的模擬,即自動識別出語音信號的情感狀態[1]。語音情感識別在教育、醫療、服務產業、車載駕駛系統等各個領域已得到了廣泛的應用。
語音情感識別系統主要包括以下幾個要素:聲學特征參數、情感分類模型和情感語料庫。其中常用的聲學特征有梅爾倒譜系數(Mel-scale Frequency Cepstral Coefficients,MFCC )、振幅、過零率、基音頻率、共振峰、短時能量等[2]。此外,基于短時傅里葉方法的語音頻譜圖可以表征信號的時頻變化信息,已成為當前語音情感識別研究的一種趨勢。
傳統的機器學習方法,例如高斯混合模型、隱馬爾科夫模型和支持向量機,在之前的研究中被廣泛地用于對提取出的特征進行分類[3-5]。目前,深度神經網絡技術在語音情感識別方面也取得了一定的進展,例如卷積神經網絡(CNN)和遞歸神經網絡(RNN)[6-7]。2015 年, Lee 等[7]提出了一種具有雙向長短期記憶(BLSTM)模型的學習方法,考慮到遠距離上下文效應和情感標簽表達的不確定性,該系統對語音情感識別的準確率達到了63.89%。2017 年,Satt 等[8]提出了一種基于卷積神經網絡-長短期記憶網絡(CNN-LSTM)組合的高復雜度模型,直接應用于頻譜圖,獲得了較高的識別精度,同時也限制了延遲。2019 年,胡婷婷等[9]提出通過加入注意力機制來改進LSTM 模型,相比于單LSTM模型,準確率達到57%。2021 年,薛艷飛等[10]提出了一種基于多任務學習的語音情感識別方法,引入語言語種識別作為輔助任務,將在離散情感語料庫上的準確率提高到75.38%。目前,這些方法在語音情感識別中的準確率較低且參數提取時存在損失和失真的情況。
本文在前人研究的基礎上提出了一種基于注意力機制的多任務三維卷積神經網絡和雙向長短期記憶網絡相結合的情感語音識別方法(3D CNN-BLSTM)。該模型基于Mel 譜圖、SPC 聲紋圖和LPC 聲紋圖構建具有三維時空特征的多譜特征融合組圖作為輸入信號,將專注語音情感突出時段的注意力機制融入3D卷積網絡建模中,并采用集說話人情感識別與說話人性別于一體的多任務模式進行訓練,通過共享網絡參數學習共享特征,從而得到更高的分類準確率。
1 基于3D CNN-BLSTM 的語音情感識別模型
1.1 基于語音聲紋圖的譜特征提取
在語音情感識別領域的研究中,特征參數的提取尤為重要。Mel 譜圖可以有效地結合語音的時域和頻域特性,將語音信號在時域上頻譜的變化情況直觀地表現出來,并且符合人耳的聽覺特性,相對于傳統特征作為輸入的模型來說具有天然的優勢[11]。SPC 特征可以提取出語音中的譜包絡信息,使其不受基頻的影響[12]。LPC 特征可以通過過去若干個采樣點的線性組合來逼近原始或未來的語音波形,預測語音信號,能夠很好地表征出語音的共振峰頻率和帶寬信息[13]。為了更加有效地提取出語音中的情感信息,將以上3 種特征聲紋圖沿通道方向堆疊,豐富了語音信號中的特征,而且可以利用其對應位置之間的關系,提取其時空特性。本文使用Mel 譜圖、SPC 聲紋圖和LPC 聲紋圖構建具有三維時空特征的多譜特征融合組圖作為語音情感識別模型的輸入。
將語音的最大長度設置為3.5 s(所有語音的平均時長加上標準差),即將較長的語音在3.5 s 處剪切,較短的語音填充零。接下來,將長度為800 的漢寧窗應用于語音信號。采樣率設置為16 000 Hz。語音信號的時域波形圖和其Mel 譜圖、SPC 聲紋圖和LPC 聲紋圖如圖1 所示(圖中顏色尺寸(振幅)轉換為分貝,見右側數據條)。其中幀數fn=800 ,幀移inc=400 ,Mel 譜圖、SPC 和LPC 的大小分別為128×300 、 5 12×300 、 2 0×300 ,再通過重采樣的方式將大小統一為 1 28×300 ,組成三維聲紋圖。
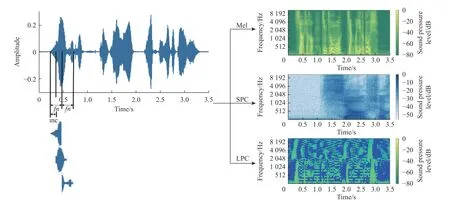
圖1 時域波形圖和Mel 譜圖、SPC 聲紋圖、LPC 聲紋圖對比Fig. 1 Comparison of time domain waveform with Mel spectrogram, SPC voice print and LPC voice print
將同一句語音“小時候聽祖母講過一個故事”分別用生氣(Anger)、害怕(Fear)、開心(Happy)、中性(Neutral)、悲傷(Sad)、驚訝(Surprise)6 種情緒的Mel 譜圖、SPC 聲紋圖和LPC 聲紋圖進行對比,結果如圖2 所示(圖中顏色尺寸(振幅)轉換為分貝,見下方數據條)。
由圖2 可以看出,由于Angry、Happy、Surprise屬于高亢情感,體現在Mel 譜圖上的變化比較明顯,所以聲紋比較清晰;Fear、Neutral、Sad 屬于低迷情感,語音波形平緩,起伏較低,體現在Mel 譜圖上聲紋比較模糊。LPC 聲紋圖可以很好地表征出語音的共振峰頻率和帶寬信息,不同情感語音發音的共振峰位置不同,相對于Fear、Neutral、Sad 這些低迷情感,Angry、Happy、Surprise 的共振峰頻率略微升高且動態范圍更大。SPC 聲紋圖可以提取出語音中的譜包絡信息,譜包絡能夠反映出語音的音質和發聲器官的各種相關參數從而表現出不同的情感,Happy、Fear、Sad 情感中譜包絡信息更明顯,而Angry、Neutral、Surprise 情感中譜包絡信息比較模糊。由于Mel 譜圖、LPC 聲紋圖和SPC 聲紋圖在這6 種情感中的表現不同,因此提取這3 種特征能夠更好地將語音中的情感信息提取出來。
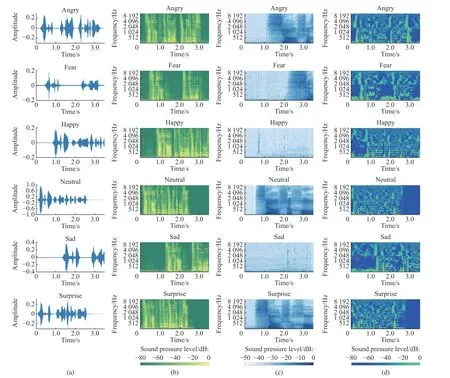
圖2 6 種情感的時域波形圖(a)、Mel 譜圖(b)、SPC 聲紋圖(c)和LPC 聲紋圖(d)對比Fig. 2 Comparison of time domain waveform (a), Mel (b), SPC voice print (c) and LPC voice print (d) of six emotions
1.2 自注意力3D CNN-BLSTM
將多譜特征融合組圖特征表示為X={x1,x2,···,xL} ,作為3D CNN 的輸入,其中xi∈Rf×c;L為時間(幀)長度;f為重采樣統一后的大小;c為通道數。為了有效地對輸入特征X進行訓練,使用基于注意力機制的多任務3D CNN-BLSTM 網絡。如圖3 所示,該網絡主要由四部分組成,包括兩層CNN 網絡(一層為3D CNN,一層為2D CNN 網絡)、兩層BLSTM 網絡、自注意力網絡和多任務層。
1.2.1 改進的三維卷積與二維卷積結合的神經網絡
為了更好地學習到多譜特征融合組圖中3 個通道對應位置之間的關系,將二維卷積拓展到三維卷積。卷積層包括64 個 3 ×5×2 的卷積核,步長為1,Dropout 層速率設置為0.5。
由于輸入的多譜特征融合組圖的通道數是3,經過一次三維卷積后沿通道方向的維度變成2,再經過一次最大池化操作,沿通道方向的維度變成1,然后將其輸出的 6 3×148×1 維的特征重塑為 6 3×148 維的特征輸入到二維卷積中,再進行最大池化操作,池化大小為2×2。
1.2.2 BLSTM 循環神經網絡(RNN)的自連接特性使其對序列數據上下文的依賴關系具有天然的描述能力[14],但傳統的RNN 在訓練時間跨度較長時會出現長期依賴問題,導致梯度消失。而LSTM 引入了細胞結構這一概念,對參數求偏導后的連乘操作改成連加的操作,通過遺忘門使梯度一直存在,克服了RNN 梯度消失的問題,在深層網絡的情況下也可以記住之前的信息,因此可以處理和預測較長一段時間的有用信息[15]。
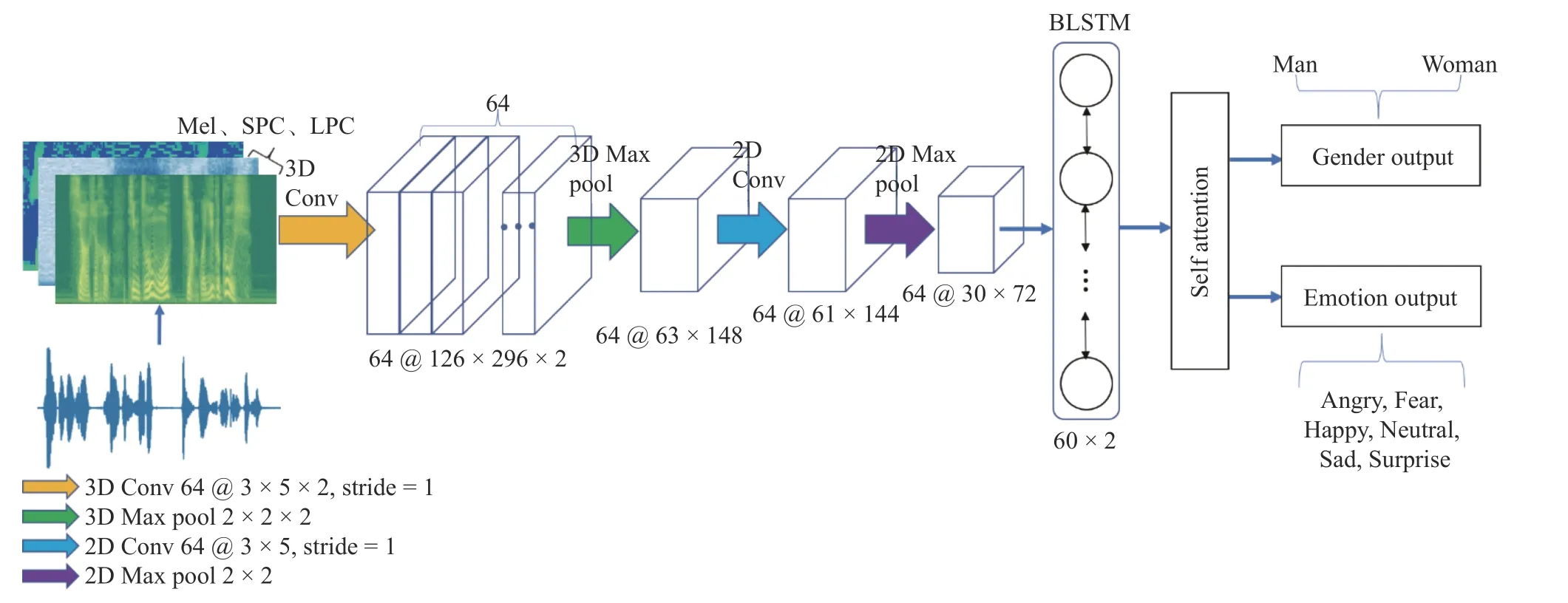
圖3 語音情感識別系統流程圖Fig. 3 Flowchart of speech emotion recognition system
在對語音情感識別問題的處理上,當前時刻的輸出不僅和之前時刻的狀態有關,還和未來的狀態有關。BLSTM 由兩個LSTM 上下疊加在一起組成,第1 層是從左邊作為序列的起始輸入,而第2 層是從右邊作為序列的起始輸入,輸出由這兩個LSTM 的狀態共同決定。BLSTM 中前向LSTM 和后向LSTM在時刻t的表示如下:

在三維的CNN 操作后,將序列特征輸入到雙向的LSTM 中,每個方向包含60 個節點,可以得到一個120 維的序列。
1.2.3 注意力機制 注意力機制是根據某一種事物不同部分的重要程度來計算的一種算法,即為事物的關鍵部分分配更多的注意力,通過注意力概率分布的計算,對某一關鍵部分分配更大的權重[16]。本文對從情感語音中提取的特征加入注意力機制,使模型對BLSTM 網絡輸出的特征給予不同的關注度。
將BLSTM 層輸出的隱藏層特征H={h1,h2,···,hL} 作為注意力層的輸入,其中H∈RL×d,d為BLSTM隱藏層的大小。注意力機制的具體實現如下:
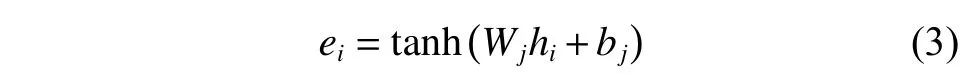

1.3 多任務學習
現實中的很多問題之間都存在著某些聯系,為了尋找其中很多問題之間的關聯信息,多任務學習的方法應運而生。多任務學習是遷移學習算法的一種,本質上是利用隱含在多個相關任務中的特定信息來提高泛化能力[17]。多任務學習通過結合共享層和屬性依賴層從輔助任務中學習,從而提高語音情感識別的準確率。文獻[18]已證明性別分類和情感分類具有音調和MFCC 等共同特征。本文通過多任務學習與情感分類任務共享有用信息,將性別分類作為輔助任務。考慮到男性和女性語音信號模式之間的差異,性別分類有助于識別其中的差異來提高語音情感識別的準確性。
考慮性別分類與情感分類之間的關系,將這兩個任務融合在一個模型中完成,并行學習,結果相互影響。兩個任務共享輸入層和隱層的全部參數,同時通過兩個輸出層分別生成情感和性別分類準確率,并通過以下目標函數對模型進行優化:
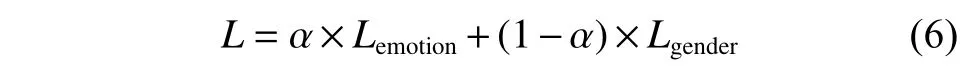
其中:Lemotion和Lgender分別是情感分類和性別分類的損失,直接將這兩個任務的損失相加,通過對兩個任務的損失配置不同的權重參數來調整每個任務的重要程度; α 為情感識別任務的權重。最后通過最小化目標函數來達到優化模型的目的。
2 實驗及結果分析
2.1 實驗環境
情感語音數據庫的質量直接關系到語音情感識別的準確率。本文選用中國科學院自動化研究所錄制的CASIA 漢語情感語料庫進行實驗。該語料庫是由4 名專業人員(兩男兩女)在純凈錄音環境下(信噪比約為35 dB)錄制而成,涵蓋了424 個漢語常用字音節,包括6 種情感,分別為生氣(Anger)、害怕(Fear)、開心(Happy)、中性(Neutral)、悲傷(Sad)、驚訝(Surprise)。每個說話人每種情感有300 條相同文本的語句,共7 200 條語句[19]。
實驗的硬件環境為Intel Core i7-7700K 的CPU和NVIDIA GeForce GTX 1 080 8G 的顯卡,開發語言為Python,深度學習框架為PyTorch。
2.2 參數設置
本實驗優化器采用Adam,學習率設置為0.001,batchsize 設置為100,epoch 設置為100,訓練集和測試集的比例為5∶1。
在特征提取階段,使用librosa[20]工具包對Mel譜圖、LPC 參數進行提取,梅爾濾波器的個數設置為128,LPC 階數選取20 階,使用自適應加權譜內插STRAIGHT 模型對SPC 進行提取。將從語音信號中提取的 1 28×300×3 的多譜特征融合組圖作為模型的輸入。
將卷積層得到的 6 4×30×72 維的輸出沿時間維度平鋪并轉置得到LSTM 網絡的輸入,維度為72×1 920,通過兩層隱藏層節點數為60 的雙向LSTM網絡,然后通過自注意力頭數為8 的注意力層和全連接層,最后得到情感和性別分類的準確率。
2.3 性能評估
為了驗證本文模型的有效性,采用準確率(Accuracy)、召回率(Recall)、精確率(Precision)和F1值作為評價指標,對不同模型的實驗效果進行評估。
2.3.1 數據準備 由于CASIA 漢語情感語料庫是在純凈錄音環境下進行錄制的,所以模型在有噪音的環境下的判斷結果并不準確。進行適當的數據增強,增加訓練的數據量和噪聲數據,提高模型的泛化能力和魯棒性。使用audiomentations 工具包對語音信號進行增強,有以下4 種方式:
(1)AddGaussianNoise:隨機添加高斯噪聲。
(2)TimeStretch:對時間維度調整,拉伸音頻信號而不改變音調。
(3)PitchShift:在不改變速度的情況下對音調進行調整。
(4)Shift:在時間軸的滾動,時移變換。
在數據增強階段,具體的參數設置如表1 所示。其中times 為倍數;semitones 為半音程。

表1 數據增強方法參數設置Table 1 Data augmentation method parameter setting
在相同條件下,使用本文模型通過不同的方式對語音進行數據增強,比較情感識別準確率的大小。共進行5 組對比實驗,其中實驗1 使用原始數據集在本文模型中進行訓練,實驗2~實驗5 分別采用AddGaussianNoise、 TimeStretch、 PitchShift、 Shift 對語音信號進行數據增強。實驗結果如表2 所示。
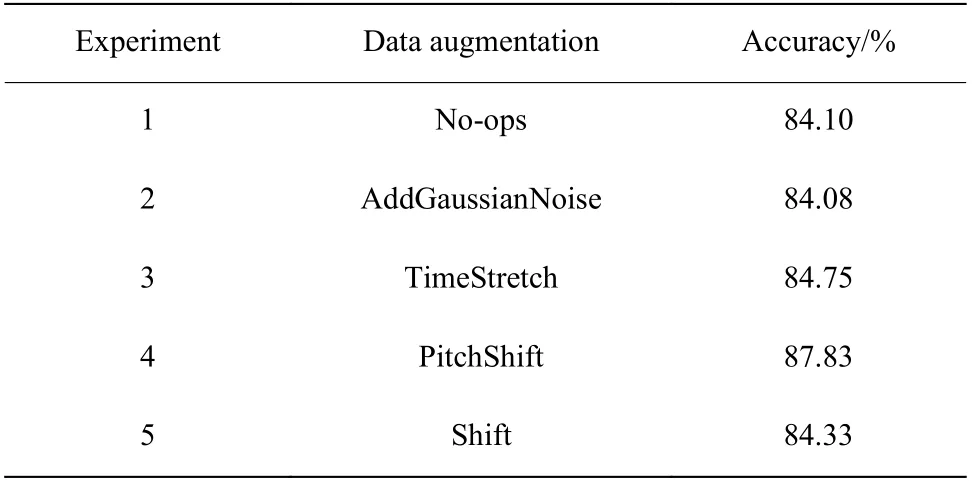
表2 數據增強對語音情感識別準確率的影響Table 2 Influence of the data augmentation on speech emotion recognition accuracy
由表2 可知,實驗1 采用不進行數據增強的方式訓練模型,識別準確率為84.10%;實驗2 使用添加高斯噪聲的方法與不進行數據增強的情感識別準確率相差不大,這是因為訓練集與測試集同時添加噪聲,只是提高了模型的泛化能力;實驗3~實驗5 所使用的數據增強的方法使得情感識別準確率有所提高,這是因為音頻變速、音頻變調和時間偏移的方法保持了語譜圖中時域與頻域的對應關系并且豐富了樣本的多樣性。
2.3.2 語音聲紋圖譜特征參數選擇 在相同條件下,使用本文模型,通過輸入不同的特征組合比較情感識別準確率的大小。將Mel 譜圖、LPC 聲紋圖和SPC 聲紋圖3 種特征中的每一種特征及兩兩組合的特征輸入到模型中,對比不同特征及組合特征對模型分類準確率產生的影響。其準確率、召回率、精確率和F1 值如表3 所示。
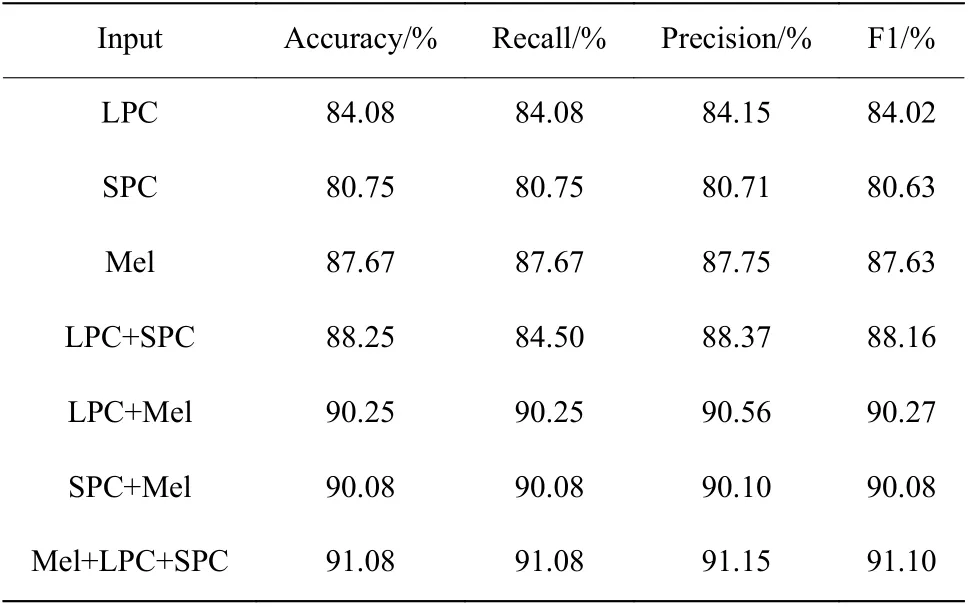
表3 輸入不同聲紋圖的對比結果Table 3 Comparison results of different voiceprints
由表3 可知,輸入3 種特征的組合能夠更優秀地提取出語音信號中的情感信息,提高了算法的有效性。
2.3.3 評估方法 本文中多任務學習的兩個任務分別為情感分類和性別分類,其目標函數如式(8)所示。通過嘗試設置不同的權重值,可以得到不同的準確率,其結果如表4 所示。
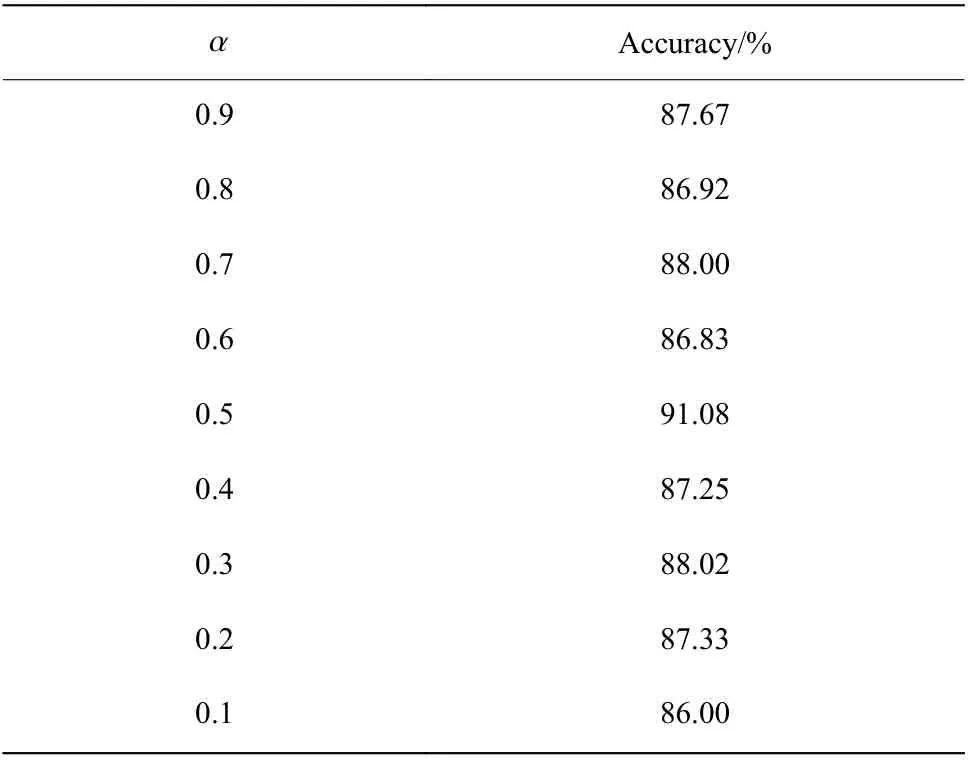
表4 不同α 值的情感分類準確率Table 4 Speech emotion recognition accuracy of different α values
由于本文的主要任務是對語音情感進行識別,因此對性別分類的準確率就不做贅述。表4 結果表明,當 α 設置過大時,性別分類對情感分類結果未起到輔助作用,情感分類準確率不是很高;當 α 設置過小時,模型更偏重于性別分類,因此語音情感識別準確率也不高;當 α 設置為0.5 時情感分類的準確性最高,這時語音情感分類和性別分類任務的權重比為1∶1。
2.3.4 實驗結果分析 將文獻[8]、文獻[21]、文獻[22]、文獻[23]模型在CASIA 漢語情感語料庫上的準確率進行對比,對比結果如表5 所示。
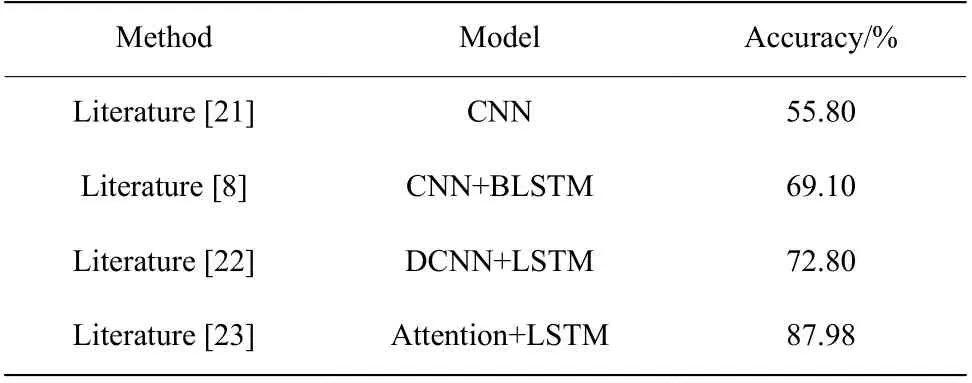
表5 在CASIA 漢語情感語料庫上不同模型方法的準確率對比Table 5 Accuracy comparison of different models in CASIA Chinese sentiment corpus
本文的基線模型采用文獻[8]提出的CNNBLSTM 模型,該模型是目前主流的語音情感模型。在該模型的基礎上,對卷積層層數和卷積核的大小進行調整,并添加不同的方法,設計出5 種不同的模型:
(1)改進CNN-BLSTM 模型。將CNN-BLSTM模型進行改進,CNN 的層數設置為兩層,卷積核的大小設置為 3 ×5 ,BLSTM 隱藏層節點數設置為60,并結合自注意力機制,對每幀情感特征給予不同的關注程度。
(2)3D CNN-BLSTM 模型。在CNN-BLSTM 模型的基礎上,使用Mel 譜圖、LPC 聲紋圖和SPC 聲紋圖特征,組成3 個通道的多譜特征融合組圖代替原輸入,并進行一次三維的卷積運算。
(3)CNN-BLSTM+multi-tasking 模型。在CNNBLSTM 模型的基礎上,加入多任務學習,將情感分類和性別分類相結合。將說話人的情感識別作為主任務,說話人性別分類作為輔助任務,兩個任務同時進行訓練,通過共享網絡參數學習共享特征。
(4)CNN-BLSTM+augmentaion 模型。在CNNBLSTM 模型的基礎上,進行適當的數據增強,增加語音數據的多樣性。
(5)3D CNN-BLSTM+ multi-tasking+ augmentaion模型。在CNN-BLSTM 模型的基礎上,將模型(2)、(3)、(4)中的方法相結合,即為本文提出的基于注意力機制的多任務3D CNN-BLSTM 語音情感識別模型。
采用5 種模型進行實驗的準確率、召回率、精確率和F1 值如表6 所示。5 種模型的混淆矩陣如圖4所示,其中右側數據條表示識別概率的大小,顏色越深識別概率越大。

圖4 不同模型的混淆矩陣比較Fig. 4 Confusion matrix comparison of different models

表6 5 種模型的對比結果Table 6 Comparison of five models
由圖4(e)的混淆矩陣可知,本文模型對各個情感的識別率都較高,其中識別率最高的是中性語音,達到95%,最低的是悲傷語音,為87%。由表6 中的數據可以看出,相比于CNN-BLSTM 模型,這5 種模型的實驗結果都要優于文獻[8]中的模型。3D CNNBLSTM 模型因為能夠學習到Mel 譜圖、LPC 特征和SPC 特征的3 個通道對應位置之間的關系,準確率提高了1.00%。CNN-BLSTM+multi-tasking 模型考慮了男性和女性語音信號模式之間的差異,性別分類有助于識別到其中的不同來提高語音情感識別的準確性,準確率提升了2.67%。CNN-BLSTM+augmentation模型考慮了本實驗數據庫是在純凈錄音環境下進行錄制的,所以模型在有噪音的環境下的判斷結果并不準確。進行適當的數據增強,增加數據的多樣性,提高模型的泛化能力和魯棒性,準確率提升了5.42%。最后由于上述實驗在語音情感識別上的準確率都較基線模型有一定的提高,因此結合了以上3 種方法,使用3D CNN-BLSTM+ multi-tasking+ augmentation 方法,得到的準確率為91.08%,比基線模型提升了8.58%,召回率、精確率和F1 值也得到了很大的提升。由此可見,本文提出的基于注意力機制的多任務3D CNN-BLSTM 情感識別方法具有更好的泛化能力。
3 結 論
本文提出了一種基于注意力機制的多任務3D CNN-BLSTM 情感語音識別方法,沿通道方向將Mel 譜圖、LPC 特征和SPC 特征堆疊,得到多譜特征融合組圖作為CNN 的輸入,提取更深的情感語音特征。連接雙向LSTM 網絡,充分提取了語音信號的上下文信息,將BLSTM 層的輸出作為自注意力層的輸入,計算權重后結合性別分類的多任務學習機制,兩個輸出層分別生成情感和性別分類準確率。實驗結果表明,在CASIA 漢語情感語料庫下,本文模型相比同類其他方法在語音情感識別上的效果更好,能夠有效地提升情感語音識別的準確率。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小太陽畫報(2019年10期)2019-11-04 02:57:59
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中國生殖健康(2018年5期)2018-11-06 07:15:40
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
