智能情報分析中數據與算法風險識別模型構建研究
2022-08-31 15:35:42馬海群
情報學報 2022年8期
關鍵詞:智能
張 濤,馬海群
(1. 黑龍江大學信息管理學院,哈爾濱 150080;2. 黑龍江大學信息資源管理研究中心,哈爾濱 150080)
1 引 言
隨著大數據、人工智能等技術深入發展,想充分發揮新時代國家情報工作的“先導”“引領”“耳目、尖兵、參謀”作用,就要使情報工作適應當前社會整體環境。情報工作在黨和國家事業取得歷史性成就過程中發揮了重要作用,作為服務于國家安全與發展的情報工作有了新的歷史使命。在情報工作的眾多環節中,情報分析處于核心地位,它是決策的前提與基礎,高質量的情報分析是情報工作成果的體現,是衡量情報工作質量的重要標準。隨著海量多源異構數據急劇增加,人工智能憑借其強大的數據分析優勢,極大提升了數據收集、分析及生產新數據的能力,從而使情報分析上升到“高端智庫”模式的情報服務、戰略性服務層面,情報人員在復雜多變的決策環境中對海量、異構、多模的數據進行分析時,智能算法發揮了重要作用,它不但能大幅度提升情報分析的全面性與準確性,還能在短時間內為用戶提供高水平、有價值的分析結果。雖然它可以輔助用戶完成智能化的分析過程,提升情報分析效率,但數據與算法是一把雙刃劍,在為管理決策帶來便利的同時,會引發數據投毒、數據泄露、算法缺陷、算法操控等一系列安全風險,這也逐漸成為限制情報工作發展的主要因素之一[1]。黨的十九屆五中全會和六中全會公報中都對防范化解重大安全風險提出明確要求,可見國家對風險識別與防范的重視程度。當前數據與算法風險正是大數據與人工智能時代情報分析所特有的,我國在該領域研究相對薄弱。從制度層面看,并沒有形成風險識別機制,尤其是在情報工作領域,若不及時防范與化解數據與算法風險,不僅會導致情報分析失準,甚至還會給社會穩定乃至國家安全造成災難級影響。因此,進一步加強對情報分析中數據與算法風險前瞻識別、預防與治理的研究符合總體國家安全發展戰略目標。早在2018 年,中國首個人工智能深度學習算法標準《人工智能深度學習算法評估規范》在中國人工智能開源軟件發展聯盟成立大會上正式發布;2019 年,中國信息通信研究院安全研究所發布《人工智能數據安全白皮書(2019 年)》;2021 年9 月,國家互聯網信息辦公室、中央宣傳部等九部委印發《關于加強互聯網信息服務算法綜合治理的指導意見》;2021 年11 月,中共中央政治局召開會議審議《國家安全戰略(2021—2025 年)》時提出,統籌做好新型領域安全,加快提升網絡安全、數據安全、人工智能安全等領域的治理能力;2022 年3 月《互聯網信息服務算法推薦管理規定》正式實施,國家在強化數據與算法安全風險事件防范的同時,不斷通過法規制度完善數據與安全風險的頂層設計;2021 年12 月全國金融標準化技術委員會發布《金融數據安全數據安全評估規范(征求意見稿)》,該標準為第三方安全評估機構等單位開展金融數據安全檢查與評估工作提供了參考。由此可見各領域也逐漸開始建立完善具有領域特色的數據與算法安全風險防范措施。
國內外學者圍繞智能情報分析、數據與算法風險等主題展開了卓有成效的研究。第一,智能情報分析。智能情報理念源于1993 年錢學森先生提出的人機結合是智慧式情報的關鍵[2]。2015 年王飛躍[3]基于錢學森先生的智能情報理念提出平行智能情報,此后學界在人工智能與情報工作相結合方面形成了一系列理論層面及應用層面的研究成果。理論研究是智能情報分析的基礎,如計算情報研究[4-6]、數據智能情報研究[7-9]、智能情報分析系統[10-11]、智能與情報融合研究[12-14]等,這些研究奠定了智能情報分析的理論基礎。應用研究是智能情報分析的目標,近年來,很多學者將人工智能技術與不同領域情報工作相結合形成了一系列應用研究成果,如反恐情報[15]、金融情報[16]、軍事情報[17]、安全情報[18]、競爭情報[19]、應急情報[20],這些研究成果使智能情報分析項目得以推廣應用,并逐漸得到認可,其中中國科學院文獻情報中心成立智能情報重點實驗室是理論與應用研究相結合的重要支撐。第二,數據與算法風險。數據風險方面,國內學者從治理[21]、問題[22]、體系[23]、路徑[24]、機制[25]等視角對數據安全風險進行研究;國外學者從模型[26]、標準[27]、維度[28]、成熟度模型[29]等視角進行數據風險治理研究。算法風險方面,國內學者從算法治理[30]、法律規制[31]、法律問責[32]、算法權力[33-34]等視角對算法風險進行深入研究;國外學者從法律決策責任[35-36]、倫理責任[37]、協同治理[38]等視角對算法風險治理進行研究。
從已有研究成果可見,智能情報分析理論與應用已經得到了學界的廣泛關注,并且從責任、監管、治理等視角對數據與算法風險進行了較為充分的研究,但是針對智能情報分析領域風險識別的研究成果較少,尤其缺少對數據與算法風險識別模型構建與實證層面的研究。因此,本文以實現防范與化解情報分析中數據與算法帶來的安全風險為目標,重在討論智能情報分析領域數據與算法風險問題,基于風險社會理論[39]、監管沙盒理論[40]構建“數據-算法-流程”為一體的智能情報分析風險識別模型,通過實際智能情報分析項目驗證模型的有效性,最終形成凸顯情報特色、突出情報領域話語權、具有實踐推廣意義的創新性成果。
2 模型構建
技術不斷進步所引發的不確定性、沖突、對抗和分歧導致社會各領域發展與風險疊加共生,我國社會轉型呈現時空高度壓縮的跨越式特征,人工智能技術應用于情報分析項目中恰恰符合貝克風險社會理論中所提到的復雜交互性、突出人為性、不確定性等特征[39]。《ISO 31000: 2018 風險管理指南》將識別方法、識別模型作為風險識別的核心要素[41]。因此,本文將識別方法和識別模型作為主要研究對象,以有效識別智能情報分析中數據與算法所導致的失實風險、決策風險、偏見風險、隱私風險等[42]。
2.1 識別方法
沙盒測試是在監管沙盒理論基礎上形成的數據與算法風險識別方法,所謂的沙盒測試就是在項目上線前在內部環境下進行的測試,此時在正常線上環境是無法看到或查詢到該項目的,只有項目通過測試上傳到生產環境之后,用戶才能使用該功能[43]。人工智能視域下情報分析涉及領域較廣,不同于以往在某一空間范圍內進行試點的方式,沙盒測試突破空間范圍的限制,強調對智能情報分析項目的風險預警,測試機構通過參與智能情報分析項目的全過程,對數據與算法的風險點進行識別,并提出最優建議,同時,參與沙盒測試的項目在申請、測試、形成報告等方面都有詳細的規定,這有助于將智能情報分析項目中數據與算法風險控制在一定范圍內,并最大限度上保障情報分析的安全性。沙盒測試分為單向識別和雙向識別兩種模式:單項識別是基于數據描述與算法描述實現的,而雙向識別是基于流程的數據與算法風險識別的,尤其是數據與算法相融合后,通過對項目流程的測試形成雙向驅動,并相互識別存在的風險。
2.2 識別模型
智能情報分析中數據與算法是核心要素,對其風險識別是有效提升情報分析準確性的重要環節。常見的數據風險主要包括數據越界、數據質量、數據泄露、數據投毒、數據隱私等[44]。常見算法風險主要包括算法缺陷、算法偏見、算法歧視、算法操控、算法黑箱等[1]。正是基于以上對數據與算法風險的分析,本文將智能情報分析中數據與算法風險識別模型構建分為篩選審核—沙盒測試—輸出結果三個階段,如圖1 所示。
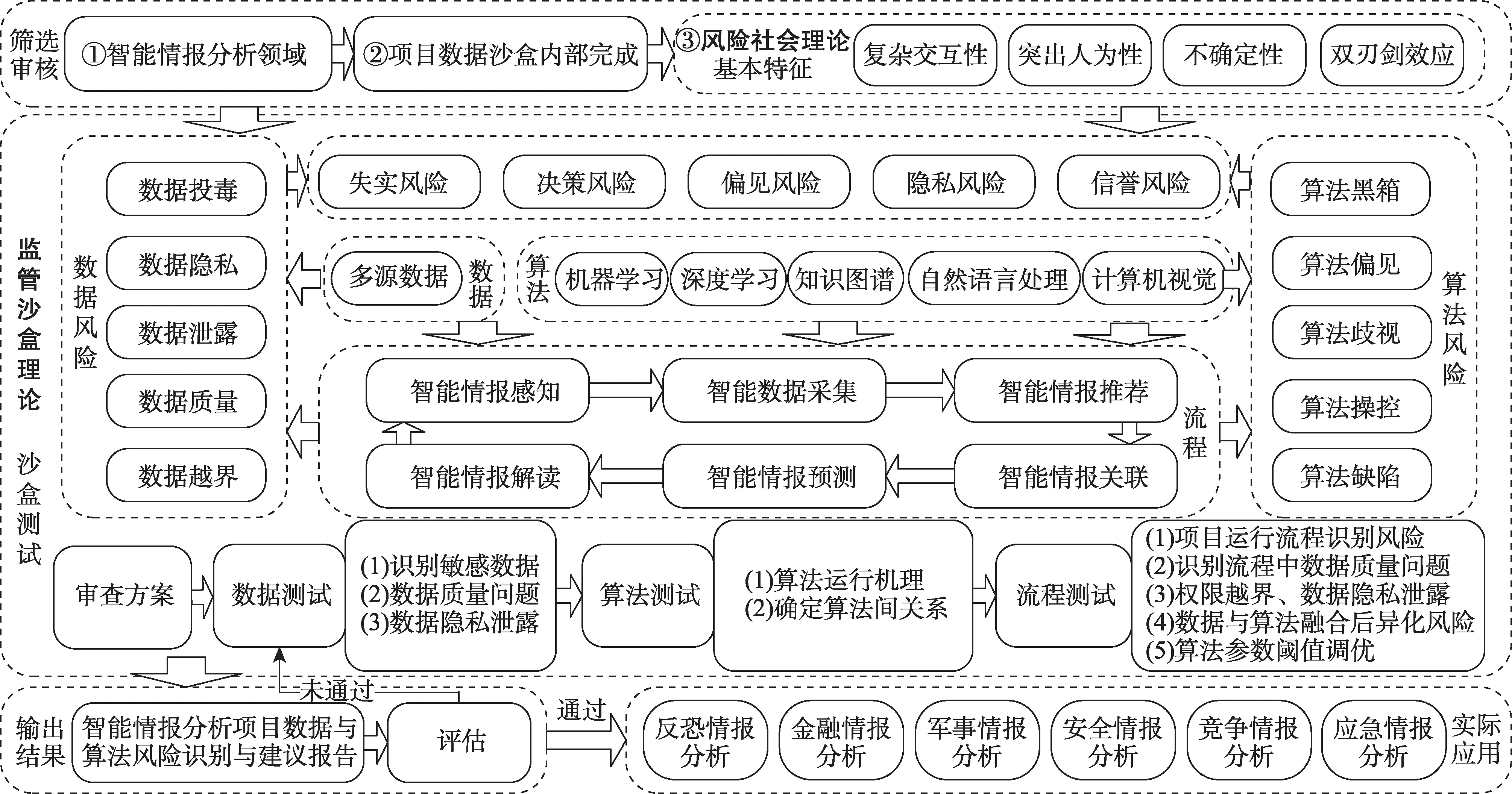
圖1 智能情報分析中數據與算法風險識別模型
1)篩選審核
本課題團隊向沙盒測試機構提出申請,在篩選審核過程中,應遵循以下基本原則:一是入盒項目歸屬于智能情報分析領域,所謂智能情報分析項目需要以大量的數據為基礎,融合大數據與人工智能技術,是支持復雜業務問題的自動識別、判斷并做出前瞻或實時決策的智能化項目[10,45];二是入盒項目所涉及的數據均應在沙盒內部完成,并不會對現實社會造成影響;三是入盒項目有數據與算法風險所具備的風險社會理論中復雜交互性、突出人為性、不確定性、雙刃劍效應等特征[42]。基于此篩選出項目是否符合入盒標準。
2)沙盒測試
項目通過篩選審核后,參考監管沙盒中沙盒測試流程[46]和軟件項目管理標準[47],入盒項目團隊要從“數據-算法-流程”三個維度提交五份報告,具體報告詳情如表1 所示。若審查所提供的相關報告準確無誤,則沙盒測試機構將基于實際項目和相關文檔對入盒項目進行全面測試。

表1 智能情報分析項目相關報告
(1) 數據描述。要對項目中數據進行全面描述,基于數據越界、數據質量、數據泄露、數據投毒、數據隱私等風險按照如下步驟進行:一是明確數據收集范圍,確定關鍵敏感字段;二是在實際測試過程中,重點觀測每個環節的數據質量;三是識別是否存在數據泄露、數據投毒等風險,識別是否存在觸犯《中華人民共和國網絡安全法》《中華人民共和國數據安全法》《中華人民共和國個人信息保護法》《中華人民共和國保守國家秘密法》(以下分別簡稱《網絡安全法》《數據安全法》《個人信息保護法》《保密法》)等法規的情況。
(2) 算法描述。要對項目中算法進行全面描述,基于算法黑箱、算法歧視、算法偏見、算法操控、算法缺陷等風險按照如下步驟進行:一是確定所使用的核心算法類型,明確使用算法運行機理;二是確定算法間使用關系,重點關注是否存在算法加權、算法改進后使算法運行機理發生變化的情況,尤其是深度學習算法的交叉使用,其評估標準可以參照2018 年中國電子技術標準化研究院等機構發布的《人工智能深度學習算法評估規范》。
(3)流程測試。沙盒測試以風險識別與防范為基本思路,流程測試重點參考數據描述和算法描述的內容。智能情報分析流程主要包括智能情報感知、智能數據采集、智能情報推薦、智能情報關聯、智能情報預測、智能情報解讀等[1],情報分析項目往往包括其中的一個或多個流程。流程測試是在數據測試和算法測試基礎上進行的,要基于數據與算法風險特征通過實際數據識別風險,具體步驟如下:一是從項目運行流程視角發現數據與算法的運行風險;二是基于項目流程測試識別由bug 導致的數據質量問題;三是識別項目中越界存取、數據隱私泄露的情況;四是對算法中參數、閾值進行反復調試直至最優;五是重點核查數據與算法相融合后的異化風險。
3)輸出結果
沙盒測試完成后,要基于沙盒測試結果最終形成智能情報分析數據與算法風險識別建議綜合報告,并由測試團隊對結果做出評估,綜合參考《人工智能深度學習算法評估規范》《人工智能數據安全白皮書》等,將數據與算法風險按照嚴重程度、可控性和影響范圍等因素[42]分為災難級(I)、嚴重級(II)、一般級(III)和輕微級(IV)四級,如表2 所示。其中情報分析項目內容和數據與算法風險點是評估等級的重要標準,將評估等級線劃定為輕微級(IV),若項目所有評估風險均低于輕微級(IV),則可將其投放市場;若高于輕微級(IV),則未通過評估,需要根據風險點進行整改,整改后重新入盒測試,直到通過評估。智能情報分析項目測試機構應持續跟蹤入盒項目測試狀況及產生的經驗數據,以此提升智能情報分析風險識別的準確性;對智能情報分析項目中數據與算法的風險識別能夠降低項目入市后的安全風險,以促使情報工作市場良性循環發展。

表2 數據與算法風險評估等級劃定表
3 實證研究
為更好地驗證風險識別模型的有效性,本文以本課題團隊中“領域熱點主題識別及演化分析項目”為例,基于風險識別模型識別該項目中數據與算法存在的風險。篩選審核作為風險識別初始環節,根據篩選原則,首先確定項目所采用的LDA(latent Dirichlet allocation) 主題聚類是人工智能領域無監督學習的重要算法之一,而對某領域熱點主題識別及演化研究是情報學研究的重點內容[48],因此該項目歸屬于智能情報分析領域;其次,該項目以智能算法領域為例[49],其測試過程與結果屬于全封閉狀態;最后,該項目中數據與算法風險具有典型的風險社會基本特征,尤其是符合突出人為性和雙刃劍效應。因此,判定該項目符合入盒測試條件,根據項目團隊提供的5 份報告(見表1)和風險識別模型(見圖1),對該智能情報分析項目中數據與算法風險進行識別。
3.1 核心數據描述
基于《智能情報分析項目需求分析報告》《智能情報分析項目數據設計報告》《智能情報分析項目測試報告》對項目中核心數據進行如下描述:①數據采集:該項目中核心數據選擇Web of Science(WoS)中以“智能算法”為關鍵詞的48734 條文本數據;②數據處理:提取篇名及摘要形成預處理語料,篩選無效數據、不完整數據,剩余47896 條數據;③構建數據詞典:提取關鍵詞形成該項目的領域詞典,共50565 條;④主題數據抽取:此部分分別對全局數據與階段數據進行LDA 主題聚類,全局數據進行主題抽取后共形成46 個主題,階段數據按照時間劃分為12 個階段,分別形成了每個階段的最優主題;⑤主題數據過濾:將全局主題與階段主題進行相似度計算,按照一定規則進行主題過濾,去除無效主題,有效主題數分別為(13,17,16,24,28,29,29,25,27,30,27,42);⑥熱點主題識別:依據新穎度和支持度對熱點主題進行識別[50],識別熱點主題82 個;⑦主題演化路徑:通過計算不同階段熱點主題相似度形成主題演化路徑[51];⑧輸出智能情報分析結果:基于實際數據輸出可視化的情報分析結果。
3.2 核心算法描述
基于《智能情報分析項目需求分析報告》《智能情報分析項目核心算法解釋性文檔》《智能情報分析項目測試報告》分析發現,該項目中核心算法為LDA 主題模型和余弦相似度。
(1)LDA 主題模型。LDA 主題模型的聯合概率具體表示[52]為
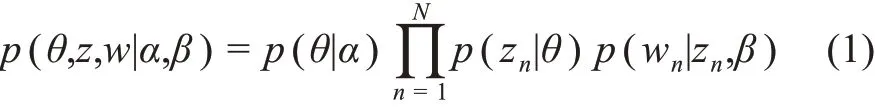
為了使算法描述得更為清晰,測試團隊用圖模型的表示方式來分解公式(1)。把公式(1)抽象為語料層、文本層、詞語層,利用圖模型的方式把LDA模型表示出來,如圖2 所示。①語料層:α和β是文本語料集的超參數,這兩個參數是模型訓練的關鍵,α是p(θ)分布的向量參數,用于生成主題分布θ;β是主題對應詞語的概率分布矩陣p(w|z)。②文本層:文本和主題分布θ是對應的,每個文本產生的主題z的概率是不同的。③詞語層:z是由主題分布θ生 成的,w是由z和β共 同生成 的,w和z是 相對應的;w為觀察變量,θ和z為隱藏變量,可以通過EM(expectation maximization)學習出α和β,由于后驗概率p(θ,z|w)無法直接計算,因此要用似然函數下界來近似推理出估計值,計算最大似然函數,得出α和β,不斷迭代直到收斂,最終完成主題聚類過程。在該項目中,通過perplexity 方法來確定LDA 模型最優主題數[53]。
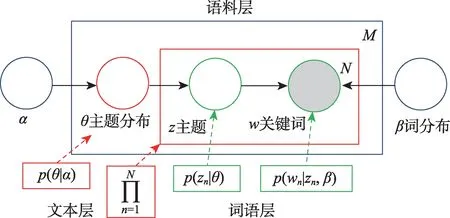
圖2 LDA生成過程圖模型
(2)余弦相似度。該項目采用余弦相似度計算的方法來衡量相鄰較近時間片的熱點主題關系,從而確定相關主題間的演化關系與演化路徑。對任意兩個主題z1和z2,利用余弦相似度計算主題相似性[54],即
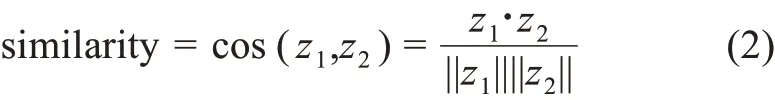
其夾角余弦值表示距離,通過計算兩個向量的余弦值來表示兩個主題相似度,其取值范圍從0 到1,數值越大則相似度越高。
3.3 基于流程的數據與算法風險識別
依據智能情報分析整體流程,基于《智能情報分析項目需求分析報告》《智能情報分析項目流程設計方案》《智能情報分析項目測試報告》,形成該項目的數據與算法風險識別圖,識別出10 個風險點,如圖3 所示。在沙盒測試后形成的《智能情報分析數據與算法風險識別及建議綜合報告》中將圍繞這些風險點提出綜合建議。
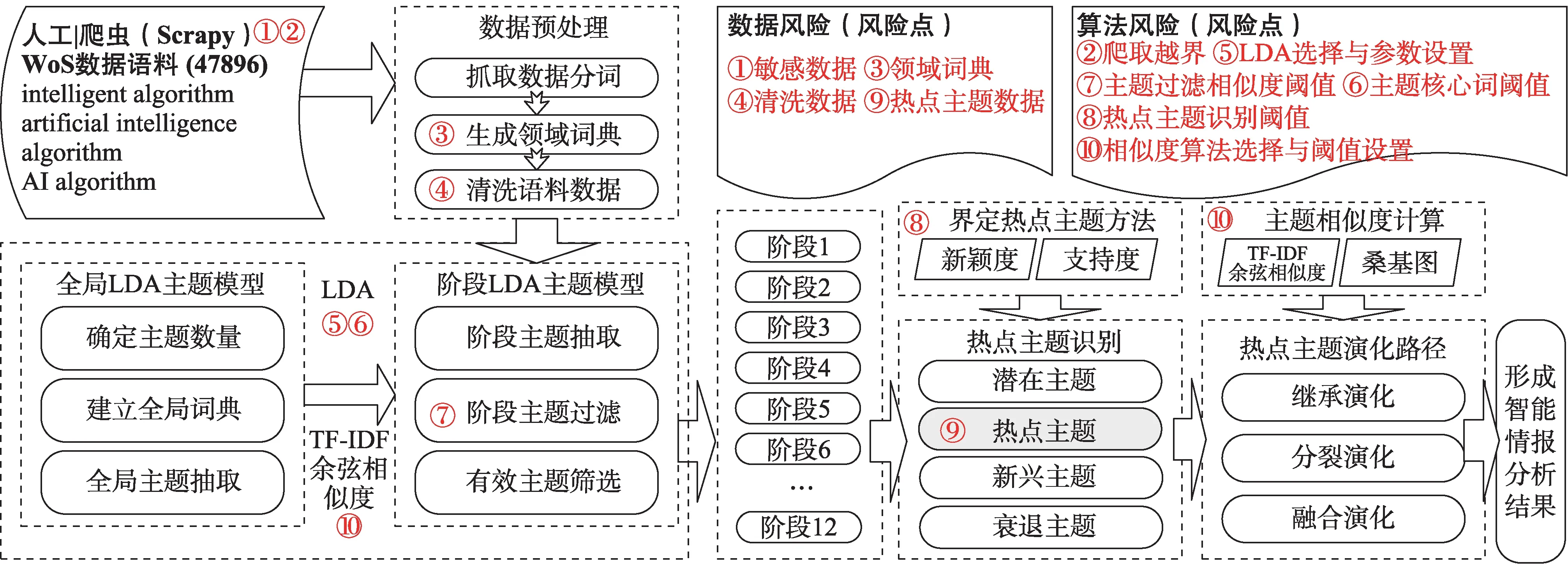
圖3 基于項目流程的數據與算法風險識別
1)數據采集
①敏感數據:包括保密數據、隱私數據等。在數據獲取或爬取過程中,按照《網絡安全法》《數據安全法》《個人信息保護法》《保密法》中對數據獲取的明確要求,嚴格審查數據獲取規則、數據獲取主題、數據獲取范圍,如果發現處于爭議的數據需要通過建立敏感數據字典的方式進行預警與過濾,采集敏感數據的數量會直接影響機器學習的深化程度及算法操控風險發生。在本項目中由于選擇主題為智能算法,獲取途徑為直接下載,因此該部分數據源并未涉及敏感數據。
②爬取越界:《數據安全法》第三十二條提出,任何組織、個人收集數據,應當采取合法、正當的方式,不得竊取或者以其他非法方式獲取數據;《數據安全管理辦法(征求意見稿)》第十六條和第十七條規定了爬蟲獲取數據的界限,尤其是對收集重要數據或敏感數據,應特別重視并嚴格審查,該環節極易造成數據隱私風險、數據泄露風險。該項目利用人工采集數據,因此并未涉及此類風險。
2)數據處理
③領域詞典:由于該項目需要引入領域詞典,因此該環節容易出現帶有污染、偏見與歧視性的數據詞典,需要詳細核查領域詞典數據獲取途徑,并對詞典內容進行反復檢驗。該項目是將WoS 文獻中的關鍵詞疊加去噪后作為領域詞典,因此該部分數據質量相對較好。
④清洗數據:該項目通過NLTK (natural lan‐guage toolkit)進行預處理,包括tokenize 分詞、詞性標注、歸一化等,隨后導入領域詞典,去除副詞、形容詞、助詞等無實際意義的詞(只保留名詞、動詞等)等操作,通過反復測試識別無效詞進而形成無效詞表并導入,直至實現數據最優。一旦無實際意義的數據充實到LDA 主題聚類中,就會造成數據污染,這將會對有價值的情報構成直接影響。
3)主題抽取
⑤LDA 選擇與參數設置:算法選擇與參數設置都會影響最終情報輸出的結果,基于3.2 節核心算法描述了解LDA 模型、運行機理及影響其穩定性的關鍵因素后,做如下風險分析。一是LDA 采用的是詞袋模型,語義分析層面較為欠缺,因此在數據集較小或數據內容欠規范的情況下會直接影響結果輸出的精準性。鑒于該項目數據集合較大,且數據內容相對規范,因此選擇該算法風險較低。二是參數設置對算法穩定性起到重要作用。對LDA 算法超參數、迭代次數、主題數量等進行合理推測,通過沙盒測試觀察實驗運行結果,反復調整最終確定合理數值為:(a)超參數:α=0.01,β=0.001。如果超參數設置越小,主題聚類后就越集中。由于最優主題數和詞典數較大,因此參數α和β要選擇較小的數值,這樣會使文檔—主題、主題—詞分布聚集到部分特征維度上。(b)迭代次數:迭代次數多容易導致消耗性能,迭代次數少會使模型不收斂,為了保證足夠的Gibbs 采樣次數,經反復測試后,數值為500 輸出數據較為合理。(c)主題數量:引入perplexity 困惑度方法對LDA 模型多次測試后,隨著迭代的進行,LDA 模型的perplexity 曲線會逐漸收斂,因此根據perplexity 曲線收斂性可驗證LDA 主題數據的準確性。
4)主題過濾
⑥主題核心詞閾值:此閾值比例設置較高時,會導致許多概率較低的詞參與到相似度計算;閾值比例較低時,會導致與主題相關的主題詞被過濾掉,使主題相似度計算數值出現虛高,這會對情報結果產生嚴重失實風險。在該項目中主題內容通過詞分布進行向量化,將每個主題視為向量,每個詞視為主題向量的一個屬性維度,其對主題的貢獻概率是向量在這個方向上的強度,將LDA 聚類后的全局主題和階段主題都視為向量,向量的維數理論上是全局詞典中詞的數量,因此計算主題向量之間的余弦值可以衡量主題之間的距離,這個距離反映了兩個主題內容的相關程度,該項目選取傳統的
TF-IDF (term frequency-inverse document frequency)生成詞向量,測試過程中建議選用word2vec 和BERT(bidirectional encoder representation from transformers)訓練詞向量模型。在計算兩個主題向量的內積時,每個向量都有156545 維,經過反復測試,選取概率小于1/156545 約為6.39×10-6(接近0)的數值,而該數值恰好約占總主題詞數量的5%,因此閾值按照5%選取,通過隨機抽樣方法觀測主題內容確定該閾值置信度較高,所帶來的情報失實風險較小。
⑦主題過濾相似度閾值:此部分閾值設置較高會導致有價值主題被排除,閾值設置較低會使部分無效主題進入。通常來說,只要算出階段主題對任意一個全局主題的余弦相似度大于閾值,就認為階段主題和全局主題關聯較大,這就實現了對有效主題的識別。此部分閾值計算公式為
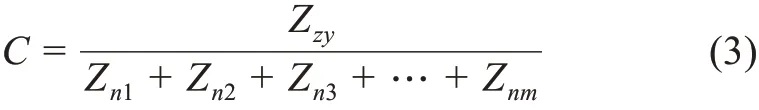
其中,Zzy為全局最優主題數;Znm為階段主題數。根據公式(3)計算閾值C為0.1009。在測試過程中出現了階段主題和全局主題之間所有主題詞的概率平均且很小,余弦相似度接近1 的情況,這是LDA 主題聚類時主題計算崩潰造成的,因此還要選取大于閾值C且小于95%的階段主題。通過數據與算法的雙向驅動識別風險,若此部分數據被識別為有效主題,則輸出的情報將會出現失實風險。
5)熱點主題識別
⑧熱點主題識別閾值:按照《智能情報分析項目核心算法解釋性文檔》中熱點主題識別所提出的新穎度和支持度計算方法[50],對熱點主題識別過程分析如下。
首先,計算不同階段中主題平均概率Rn,只要某一階段的某一文檔對主題分布的概率大于Rn,就認為該文檔對這個主題構成了支撐,Zxn為階段有效主題數量,計算公式為

其次,計算支撐度ZCn,定義文檔支撐數量為DZn,階段文檔總數為Dn,計算公式為

再次,計算平均支撐度ZCP,計算公式為
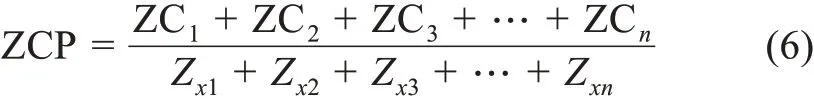
最后,進行熱點主題識別,在階段主題支撐度矩陣中篩選出大于文檔平均支撐度的主題作為熱點主題,Rn閾值設置直接影響熱點主題識別結果,經過反復測試證實當前閾值相對合理,熱點主題識別相對較為準確。
⑨熱點主題數據:基于以上方法確定第二象限數據為熱點主題區域,但實際測試發現,在新興主題區域中部分主題是熱點主題的延續,只要新興階段的主題和熱點階段的主題具有相似性,就說明它們是同一演化路徑熱點主題的延續,這類主題屬于持續熱點主題。最終得到熱點主題82 個,如圖4 所示,如果忽略新興主題區域圓圈部分數據,就會使有效數據缺失并直接導致出現情報分析結果失準或帶有偏差等風險。
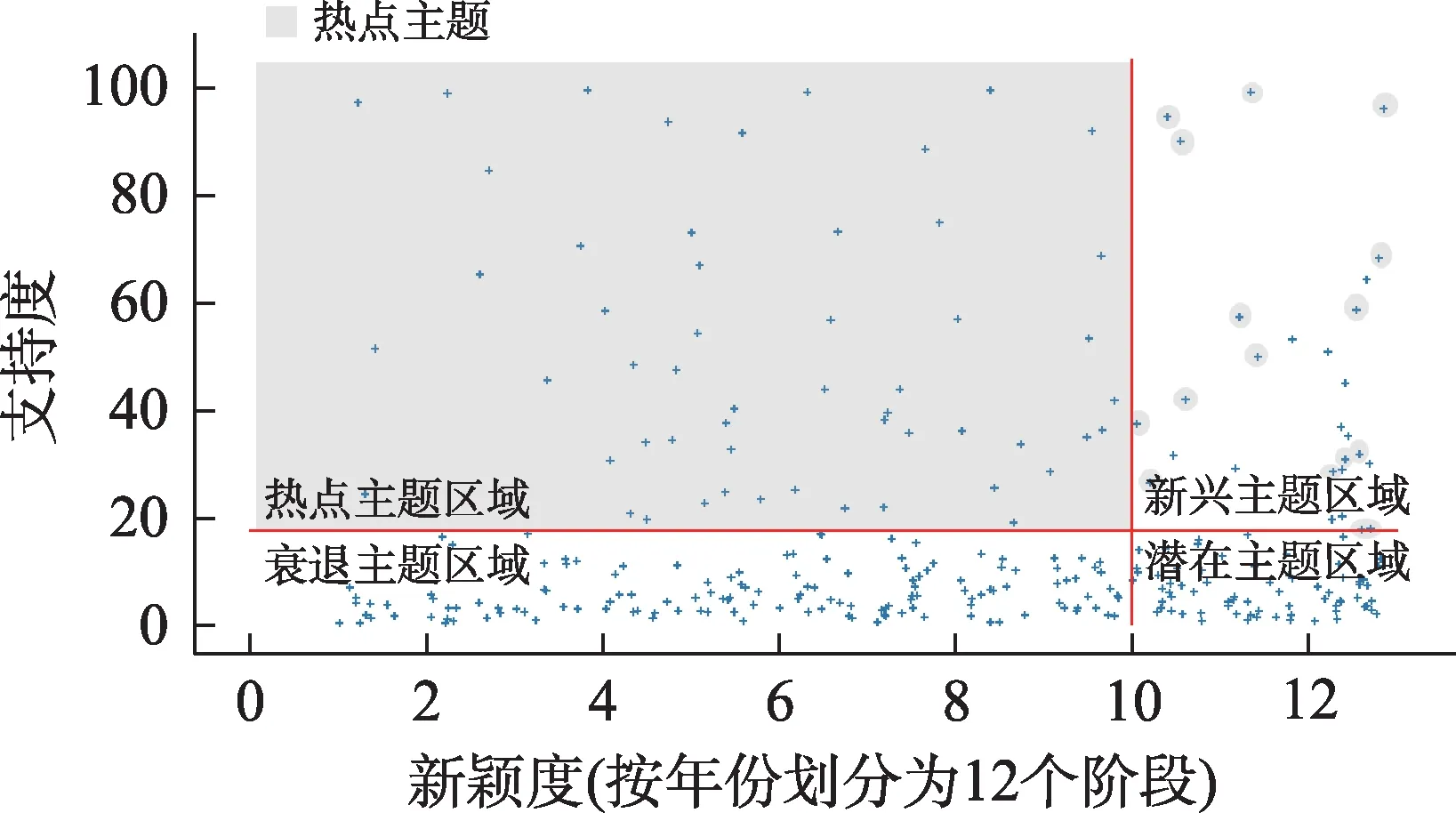
圖4 智能情報分析項目熱點主題分布散點圖
6)主題演化路徑
⑩相似度算法選擇與閾值設置:相似度計算是機器學習領域基礎而重要的算法,余弦相似度計算是常用相似度算法之一,其應用于眾多領域。在該項目中,主要利用此算法計算相鄰階段熱點主題之間的余弦相似度。在算法選擇層面,由于余弦相似度是基于詞語的方法,并未考慮語義層面的內容,因此應盡量考慮基于知識庫與語料庫的方法[55];該算法可能會過濾掉一些語義相似的數據,進而使情報結果準確度降低,在測試結果中建議選擇更多的相似度算法以提升情報分析的準確度,進而挖掘更精準的情報。在閾值設置層面,測試發現在相鄰熱點主題相似度矩陣中,大于20%的共有68 個相鄰主題,大于30%的共有26 個相鄰主題,為了將更多相關主題納入演化路徑中,因此測試選取20%作為閾值,最終形成如圖5 所示的熱點主題演化路徑。
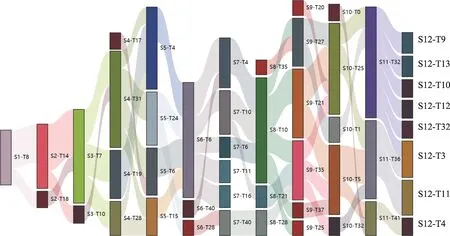
圖5 不同階段的主題演化路徑
7)形成情報分析結果
針對所形成的部分繼承演化、融合演化和分裂演化路徑做如下分析。其中S1~S12 代表了階段,T代表了某階段的主題。
(1) 繼承演化:選取從S6-T28 到S7-T40 再到S8-T28 所形成的繼承演化路徑,如圖6 所示。其中S6-T28 到S7-T40 相似度為0.211,再到S8-T28 相似度為0.347,從2008—2009 年genetic algorithms、con‐troller 的提出開始,演化到2010—2011 年的robot、controller,在智能機器人運動控制領域進行全局最優解搜索,再演化到2012—2013 年的robot、con‐troller、simulated annealing,在運動控制系統中逐漸使用模擬退火算法(simulated annealing)取代遺傳算法(genetic algorithms)。遺傳算法和模擬退火算法的作用都是多目標優化找到全局最優的近似解,解決傳統的窮舉法獲得全局最優解運算量大的問題,但遺傳算法存在局部搜索能力差、容易陷入過早收斂等缺陷,模擬退火算法的出現解決了當時存在的問題,因此從時間上符合演化規律。
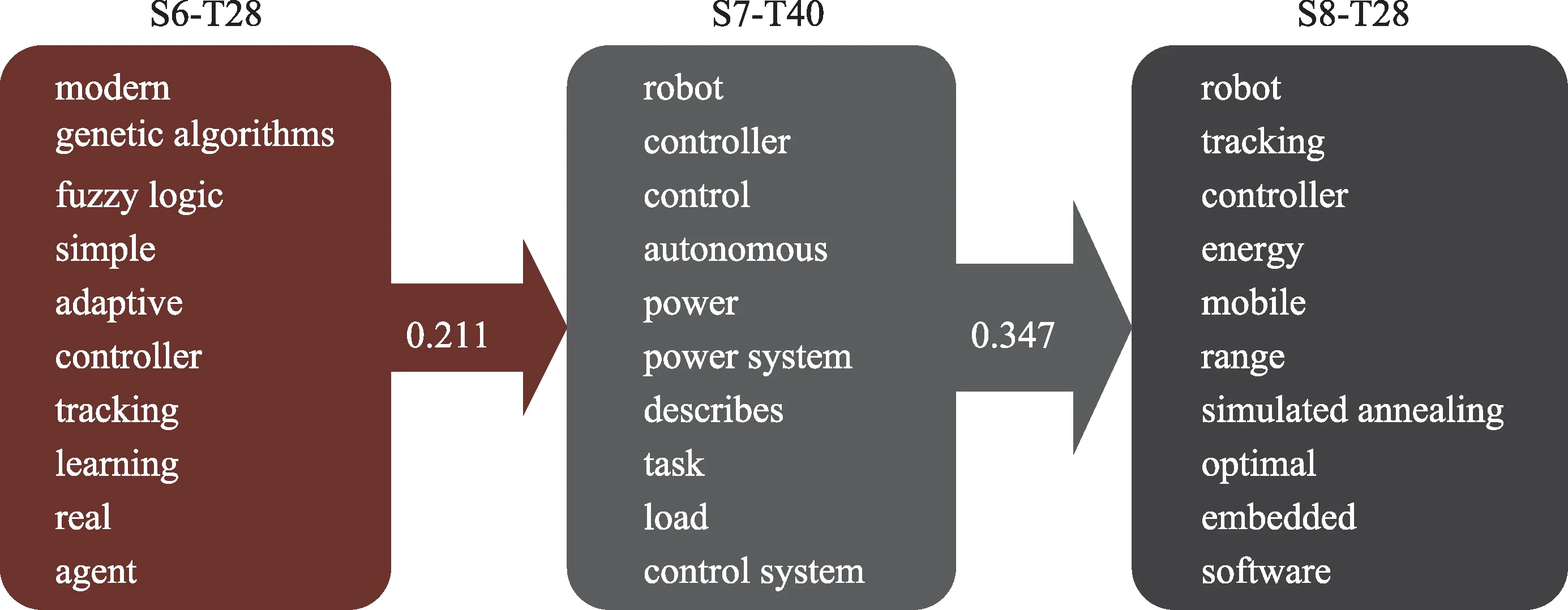
圖6 繼承演化路徑及主題詞(Top 10)
(2) 融合演化:選取從S9-T20、S9-T21、S9-T27、S9-T35 主題融合為S10-T25 的路徑,如圖7 所示。2014—2015 年在技術領域出現了learning、method、optimization、optimized、genetic algorithm、local、complexity 等,主要探討各種優化參數技巧訓練復雜的智能算法模型,在應用領域vehicle、mobile、wireless sensor network 也開始廣泛應用智能算法。2016—2017 年主題融合形成了model、recog‐nition、detection、support vector machine 等,在該階段文字識別、語音技術識別、圖像識別等領域不斷興起,并取得了不錯的結果,該階段多數研究從技術上支持向量機(support vector machine) 進行分類。事實上在以神經網絡為主的深度學習出現以前,支持向量機是一種非常有效的分類算法。
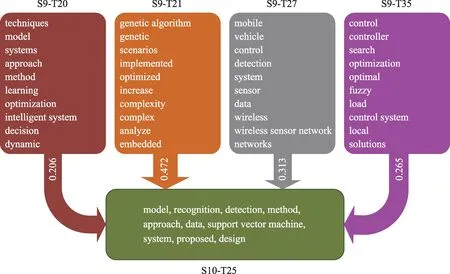
圖7 融合演化路徑及主題詞(Top 10)
(3)分裂演化:選取從S11-T32 主題分裂為S12-T3、 S12-T9、 S12-T10、 S12-T12、 S12-T13、 S12-T32 的路徑,如圖8 所示。該階段分裂主題數量最多,自2018—2019 年machine learning、neural net‐work、deep learning 的出現,到2020—2021 年主題分裂 為objective、detection、recognition、CNN (con‐volutional neural network)、 ANN (artificial neural network)、deep learning、congestion、city、machine learning、 decision tree、 prediction、 real-time、 big data 等。分裂主題為三類:(a)目標探測和識別:包括objective、detection、recognition 等,該階段語音識別、文字識別、圖像識別得到更廣泛的應用;(b)應用于不同領域:在the internet of things、de‐vices、congestion、city 等領域都發揮重要作用,如物聯網、智慧城市等;(c)算法更為細化:包括CNN、ANN、decision tree、real-time、big data 等,其中CNN、ANN 等深度學習算法在該階段得到了快速發展。
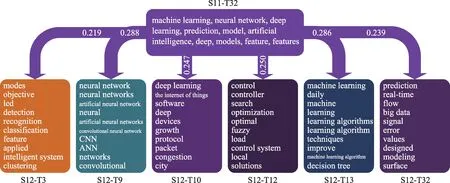
圖8 分裂演化路徑及主題詞(Top 10)
通過對以上演化路徑的分析完成了情報分析過程并得出了與實際相符的分析結果,但從主題詞上來看,確實存在一些無實際意義的詞語,因此需要進行反復測試才能使分析結果更準確。
3.4 測試結果
沙盒測試是對智能情報分析項目中數據與算法風險進行識別的主要方法,并從全流程視角識別風險。對該項目10 個風險點進行評估,根據表2 中的風險等級對數據與算法中每項風險進行風險描述、風險等級類別和等級劃分,如表3 所示,雖然該項目不存在較為嚴重的失實風險、決策風險、偏見風險、隱私風險等,但尚存在4 個輕微級(IV)和6個一般級(III)風險點,因此項目團隊要針對6 個一般級(III)風險點進行逐一確認并整改,提交整改說明報告,再次測試無誤后方可入市。本文所提出的風險識別模型不但能有效識別智能情報分析項目中數據與算法風險,還能最大限度降低項目入市后所帶來的安全隱患。
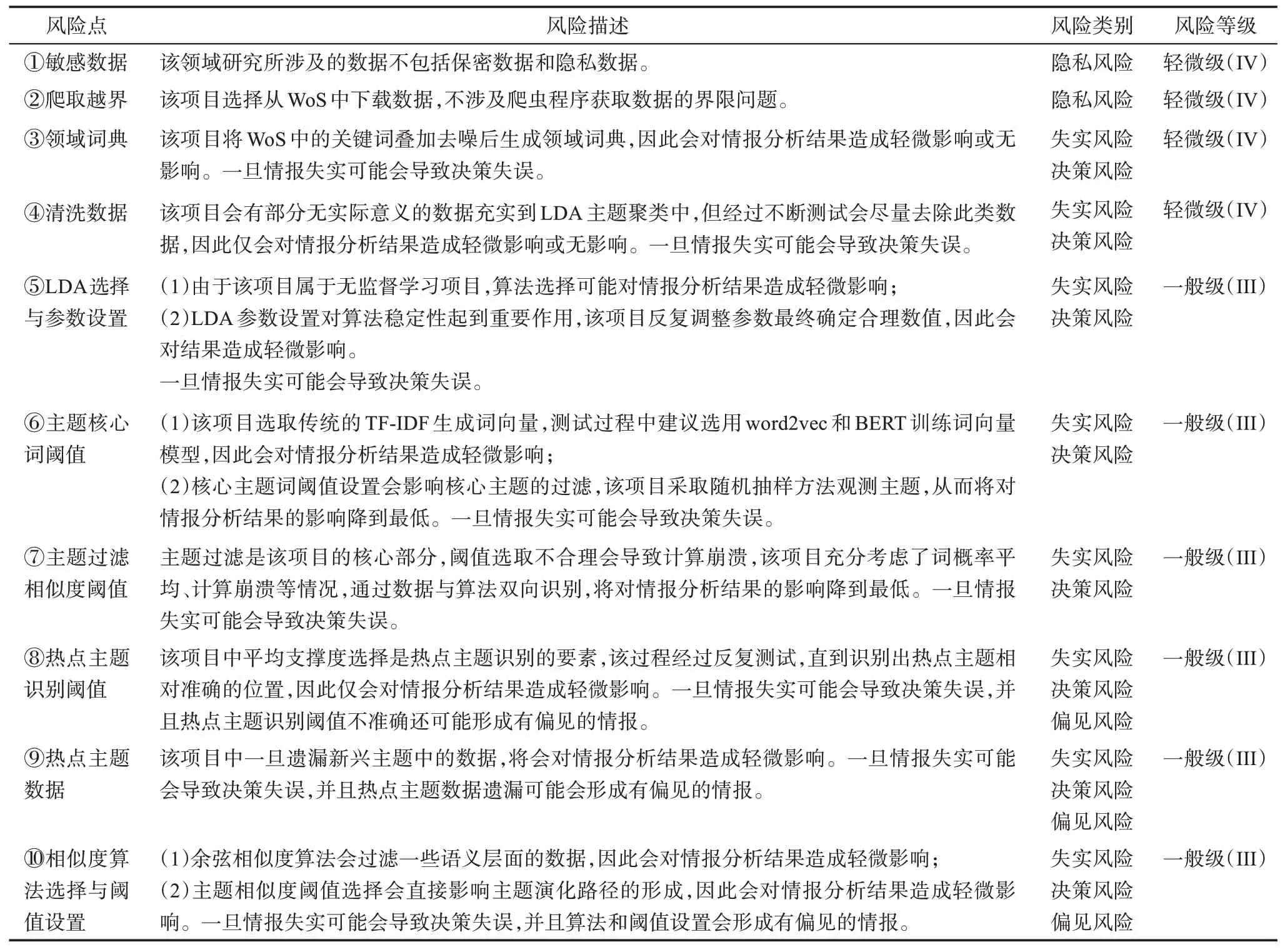
表3 智能情報分析項目中數據與算法風險定級
4 結論與建議
在新興技術推動社會進步的同時,越來越多的情報分析項目基于大數據與智能算法來實現,但它們在為人類社會提供便捷與高效的同時,也帶來了種種難以預測的風險,而且這些風險在金融情報、軍事情報、反恐情報、應急情報等領域更具危害性,影響范圍更大,甚至會危及社會穩定與國家安全。2021 年7 月“滴滴出行”等接受網絡安全審查,被發現其嚴重違法違規收集使用用戶隱私數據,給社會乃至國家安全帶來風險,該事件將數據與算法風險識別推上了前臺。實際上,《中華人民共和國國民經濟和社會發展第十四個五年規劃和2035 年遠景目標綱要》中明確提出了防范化解重大風險體制機制應不斷健全[56],因此該事件的及時處理也充分體現了國家對防范化解重大風險的決心。基于此,本文以風險社會理論、監管沙盒理論為依托,構建“數據-算法-流程”的智能情報分析安全風險識別模型,并以本課題團隊的“領域熱點主題識別及演化分析項目”為例,詳細分析了其數據與算法風險識別的過程,同時也驗證了風險識別模型的有效性。最后,通過模型構建與實證提出如下對策建議,期望形成凸顯情報學學科特色、突出情報領域話語權、具有實踐推廣意義的研究成果。
1)培養情報學領域人才的風險識別意識
基于以上實證研究發現,該項目中所存在的風險和當前社會“重創新、輕風險”的思想相吻合,而這正是風險識別意識淡薄所導致的;如果該思想在情報人才培養中蔓延,所帶來的潛在危害是無法估量的。因此要培養具有風險識別意識的耳目、尖兵、參謀、引領式情報人才[57],提出以下三點建議:一是在情報學科中增加最新信息技術課程,尤其要重點介紹技術運行原理及應用場景,如人工智能技術、大數據技術等課程;二是增加項目管理中風險識別相關課程,尤其是對技術算法與核心數據中的風險識別及風險預測等;三是增加智能情報分析應用實踐項目,增加情報人才的實踐能力,有意識培養情報學人才在應用實踐過程中的風險識別經驗。
2)情報工作機構中設立監管沙盒職能
在風險識別模型中,沙盒測試是基于監管沙盒理論形成的,監管沙盒是指由監管機構提供一個“安全空間”,創新企業在符合特定條件的前提下,可申請突破一定的規則限制在該空間內進行項目測試[58]。監管沙盒強調的是多元共治的監管理念,注重監管機構、被監管者以及消費者多元主體共同參與治理,通過多元共治,將事前預防與事中、事后監管相結合,有效改善了監管信息不對稱問題,由此實現對風險的識別及監管。目前越來越多的情報分析項目應用智能技術,而其帶來的風險問題容易被忽略,因此情報工作機構應擔負起智能情報分析項目中數據與算法風險識別的重任。建議以情報工作機構或行業協會牽頭,融合高校、企業的科研力量,在機構內部設立監管沙盒職能,實現對智能情報分析項目中數據與算法風險識別的理論與應用研究,以協助智能情報分析項目團隊對項目的完善與創新,降低項目運行的風險。
3)數智環境下實現國家情報工作制度創新
在情報工作機構中,構建風險識別模型需要完善的規則設計,而規則是制度的重要體現形式,因此我們將沙盒測試視作一項平衡科技創新與風險的制度設計,它一旦在情報工作機構內部運行,將是國家情報工作制度重要的創新點之一。當前數智環境下,數據與算法風險識別后急需通過制度建設進行治理,因此情報工作機構要從制度建設層面關注智能情報分析領域所應用到的數據與算法,從以下兩個方面提出建議:一是建立具有情報特色的算法監管和算法問責制度,例如,國家適時考慮制定《算法法》,國家情報機構針對已有法規制定適用于情報領域的《人工智能算法審查規范》《算法責任框架》等,在強化監管與問責法律效應的同時,對各領域情報工作起到指導作用。二是構建具有情報特色的數據監管制度。《數據安全法》第二十二條提出,“國家建立集中統一、高效權威的數據安全風險評估、報告、信息共享、監測預警機制。國家數據安全工作機制統籌協調有關部門加強數據安全風險信息的獲取、分析、研判、預警工作”。這主要說明國家會加強數據風險情報的共享機制,從制度層面實現智能情報分析中對數據的有效監管。
情報分析有別于其他數據分析項目,其知識性、保密性、價值性、時效性等特點均較為突出。由于“領域熱點主題識別及演化分析項目”屬于團隊內部測試項目,其本身并不會對國家安全及社會穩定造成嚴重影響,因此項目選擇上不具有高風險特征。本文所選取的LDA 主題聚類是無監督學習算法,在風險識別層面并不存在如隨機森林、神經網絡等算法帶來的黑箱風險問題,針對部分具有黑箱特征的風險識別不完全適用,但本文旨在嘗試開拓全新應用研究領域,通過構建智能情報分析項目數據與算法風險識別模型來為更多研究者提供參考與借鑒。未來,本團隊將繼續針對智能情報分析項目對有監督學習算法進行實證,尤其是對具有黑箱屬性的智能算法進行深入研究。
猜你喜歡
開放教育研究(2021年3期)2021-05-25 02:41:06
小學科學(學生版)(2020年12期)2021-01-08 09:28:04
裝備制造技術(2020年4期)2020-12-25 05:26:24
表面工程與再制造(2019年6期)2019-08-24 06:40:04
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
商周刊(2018年18期)2018-09-21 09:14:46
能源(2018年4期)2018-05-19 01:53:44
