基于深度學習的景點圖像識別
2022-09-01 10:10:06單慧琳洪智毅張銀勝王興濤
實驗室研究與探索 2022年5期
單慧琳,洪智毅,張銀勝,王興濤
(1.無錫學院電子信息工程學院,江蘇無錫 214105;2.南京信息工程大學電子與信息工程學院,南京 210044)
0 引言
圖像識別是將圖像根據提取出的特征進行分類,進而將待識別的圖像與已有的圖像分類進行匹配。景點圖像識別屬于大規模圖像檢索的范疇,傳統的基于內容的圖像檢索方法由于圖像表達能力不強,處理數據又需要耗費大量的計算時間,不利于大規模圖像檢索。實現相關性更全面、速度更快、成本更低的景點圖像識別成為了圖像識別領域的熱門研究話題。基于哈希的圖像檢索方法將圖像的特征轉變為哈希碼,使用漢明距離來比較圖像的相似性,可以大大減少計算機的內存消耗和檢索響應時間,因此它能更好地適用于大規模圖像的檢索。
Ji等[1]通過一種特殊的位置詞匯編碼,將圖像中的視覺相關內容和地理特征進行整合,通過位置感知將地理特征進行區分,同時使描述符與區分后的地理特征進行迭代優化,生成精簡的地理特征描述符。同時,Ji等[2]還將圖標的其他信息添加進生成地理特征描述符的過程中,類似于將GPS 信息加入,使得最終的描述符更加精簡。在圖像特征檢索部分,Zhou 等[3]將圖像特征信息轉換成二進制編碼,進而實現快速檢索圖像。在通過二進制編碼描述被測圖像的基礎上,Min等[4]首先將圖像進行一次壓縮后,再轉化成哈希碼,使得哈希碼更短,實現更加快速的轉換。2017 年Zhu等[5]提出一種檢索方案,即通過改進規范視圖,實現離散多模態哈希算法上述這些圖像識別算法,都是人工或者半監督的方法實現圖像特征的提取,并不能實現端到端的學習提取特征。
隨著深度學習分析能力不斷提高,深度學習多層次的結構可以更好地發現復雜景點圖像數據之間的關聯性,因此,越來越多的研究者加入到深度學習的哈希檢索領域中,在CVPR 等人工智能和圖像識別的頂級會議中,相關論文不斷發表。2013 年迭代量化哈希[6](ITQ)被提出,這是一種通過降維然后找到量化誤差最小的哈希算法。離散圖哈希[7](DGH)指的是一種建立圖像對應的錨點圖直接離散約束求解的算法。譜哈希(SH)通過sign在0 點處將特征函數值實現二元量化[8]。Scalable Graph Hashing(SGH)和Restricted Boltzmann machine(RBM)等也相繼被提出[9-10]。2014年,Xia等[11]構建出一種相似度矩陣,這種用相似度矩陣來衡量兩個樣本之間的相似度關系的方法被叫做CNNH算法。2015 年,Zhao 等[12]通過對CNN 網絡中的一個具有凸上界的函數進行訓練,從而實現一種有序排列的深度哈希算法。這個有序排列的算法,可以有效地使圖像檢索系統最后返回的測試結果進行有效的優化。2015 年,Lin 等[13]在CNN 網絡的基礎上,增加了一個隱層,這個隱層采用Sigmoid 函數作為激活函數,這種通過添加隱層的方法可以使卷積神經網絡直接在調整結束后,對添加的隱層的特征值直接閾值化,并得到二進制編碼。2020 年,劉小安等[14]用CNN-BiLSTM-CRF的網絡模型對景點進行識別,同年,趙平等[15]將BERT+BiLSTM+CRF 用于景點識別,兩篇論文都是用于命名實體識別。
本文旨在設計一種新的圖像檢索方法,使用高層語義區分策略,綜合現有的深度學習和哈希檢索算法,應用到旅游景點圖像檢索中,使用新的卷積神經網絡和激活函數使神經網絡訓練更加快速。在提高圖像識別準確率的同時,降低檢索成本。
1 基于深度學習的哈希檢索方法
哈希映射主要指的是將被測圖像數據通過建立好的模型轉變為一種二進制編碼,使得被測圖像與二進制編碼之間存在映射關系。但由于傳統的哈希檢索算法,只能通過人為參與的方式設置算法對圖像特征的提取,這樣得到的二進制碼無法保證具有足夠的代表性。基于深度學習的哈希檢索方法可以使系統實現端到端的訓練,直接從訓練網絡中得到編碼。
在一般的哈希檢索算法中,普遍做法是將目標樣本表示為二進制碼,這樣的二進制碼具有固定的長度,以0/1 或者-1/ +1 來表示每一位二進制碼。這樣的轉化方式使得在最終的二進制編碼集中,可以通過計算被測圖像二進制碼與檢索圖像的距離來判斷是否相似(使用漢明距離來測量二進制代碼之間的相似性)。在哈希檢索算法的初級階段,研究者利用超平面劃分空間,進而通過被測圖樣的樣本點在空間的某個區域來確定取值。這樣的算法簡單粗暴會造成極大的編碼長度,隨著網絡圖像數據指數提升,這種方法需要驚人的存儲空間才能保證檢索的精確度。人們通過采取不同的優化方法或者構建不用的目標函數得到編碼長度更短的二進制編碼,使得哈希檢索的性能得到巨大提升。哈希檢索算法的主要目標是得到二進制碼,因此在優化的過程中會受到離散取值問題,通常采用一種放寬約束做法。下面主要介紹兩種較為先進的深度哈希算法:DLBHC(Deep Learning of Binary Hash Codes)算法和DNNH(Deep Neural Network Hashing)算法。
1.1 DLBHC算法
DLBHC算法相較于Semantic Hashing方法使用一種更加直接迅速的方法來學習二進制編碼。DLBHC算法的核心部分是插入一個全新的完全連接層,該完全連接層放置在倒數第二層和最終任務層之間。通過Sigmoid函數作為激活函數加入非線性因素,將代碼長度作為節點數,將語義信息通過端到端的微調添加到新加入的完全連接層的輸出中。在DLBHC 算法中,任務層最終輸出的二進制代碼包含了語義信息,但是最終的檢測結果依舊會產生一定偏差。這是由于采樣點的相對位置關系沒有在網絡訓練的過程中被考慮,因此,該網絡結構無法保證語義上相似的點包含所有漢明距離相近或者距離較短的點。該算法的網絡流程如圖1 所示。

圖1 DLBHC算法模型
1.2 DNNH算法
DNNH算法采用一種NIN的網絡結構。與同樣使用NIN網絡的CNNH算法相比,DNNH的核心做法是使用三元組的形式進行訓練。DNNH算法采用一種非交叉熵的損失函數,這種損失函數是建立在三元組基礎上的,采用這種基于三元組的損失函數使得不類似點的采樣在最終漢明空間之間的距離大于類似采樣的距離。同時,DNNH算法對NIN 網絡結構做出一些針對性的改變以適應哈希學習的任務,主要分為兩點:
(1)通過舍棄全連接層,使用部分鏈接層,使得每個不連接部分分別學習一部分,這樣可以有效地減少二進制碼在不同位上所產生的冗余(見圖2 左切片層)。
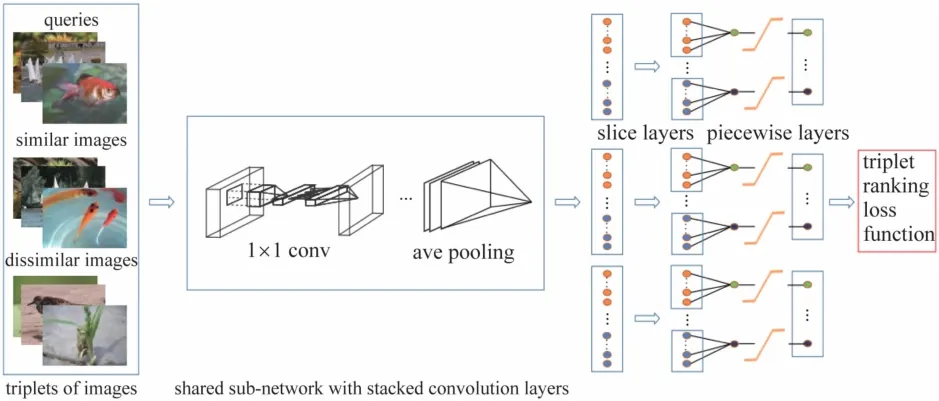
圖2 DNNH算法模型
(2)通過Sigmoid 函數作為激活函數,加入非線性因素,對于離散約束進行松弛。上面兩個核心部分已共同構成DNNH算法網絡圖中的分段和編碼模塊。DNNH算法可以實現端到端的訓練方式,將所學的圖像反作用于二值碼,因此,DNNH算法相較于同樣使用Network in Network網絡的CNNH算法,檢索效果有了足夠的提高。
1.3 改進的深度學習哈希檢索方法
本文提出一種改進的深度學習哈希檢索方法,對旅游景點進行圖像識別。使用該方法對已有的景點圖像數據進行訓練得到訓練集,該方法使用經典卷積神經網絡VGG16 來訓練提取圖像特征,采用5 ×5 的卷積核大小,使用交叉熵作為損失函數,將ReLU函數作為激活函數,在訓練好的網絡模型中,由哈希層以及哈希層中的編碼塊數確定k位的哈希編碼,并對得到的哈希編碼進行閾值化分得到二值碼,將待測的景點圖像數據通過同樣的網絡模型,以得到待測景點圖像的二值碼,通過對訓練集和待測圖像的二值碼進行多索引哈希近鄰檢索以實現最終的查找。
相較于傳統的DNNH 算法和DLBHC 算法,在深度學習部分,本文的方法使用一種更為仿生的特征提取策略,使識別首先發生在高語義層次。與DNNH 算法和DLBHC算法相比,本文采用ReLU函數作為神經網絡的激活函數,使得收斂速度更快,在哈希檢索部分,本文使用多索引近鄰檢索進行查找。
1.3.1 基于深度學習的特征提取策略
傳統的哈希算法基本通過手工設定的提取方法來提取特征,但這樣得到的特征表達能力都不太強。景點圖像識別首先依賴的是圖像的特征,而提取特征的策略將直接影響圖像檢索的準確率。
研究表明,景點圖像信息量最大的地方往往是圖像的高頻部分,這些高頻的部分一般表現為角點、凹凸點、斷點等地方。生物在區分這些圖像時,往往會集中區分這些高頻部分。通過對這些高頻部分的低層特征來構建相應的領域,然后利用其他與領域有關的低頻特征來歸納出對應的高頻特征,進而實現檢索。例如:當一個景點圖如黃山被輸入到計算機時,計算機往往通過提取這張圖像的所有特征,然后再遍歷搜索相對應的景點。這樣搜索計算量大,消耗時間較長。而人眼在收集到黃山的這張圖像信息時,人腦在第一時間會忽略掉其他無關的特征,從圖像中提取較大的信息量的低層特征,總結出高層特征,將“山”這一圖像信息輸入人腦,然后利用與山相關特征對圖像進行進一步的檢索,最終得出識別結果。
可以看出,人類對于圖像信號的理解往往發生在比較高的識別層次,而不是在低層次上進行遍歷搜索。這些高層次的特征是對相關領域的總結,例如當發現待識別的是一座山時,會立刻去尋找山的高度,山頂的形狀這些特征等,因此通過對于這些高層次特征的提取可以更快地實現圖像的檢索。
1.3.2 深度學習算法模型
基于像素和領域的特征可以設計一種分層次的算法模型,這種模型應具備從圖像中抽取基本高頻的像素特征,并對這些特征進行大致的領域劃分,然后在更高的語義層次上抽取圖像特征來最終識別對應的景點圖像。由于低層次抽取和高層次抽取具有矛盾性,因此不能使用單一的網絡學習結構來學習,需要一種深度學習的層次化結構來滿足在不同層次上抽取特征的需求。本文所提出的算法模型是在卷積網絡結構的基礎上進行改進的。VGG16 作為經典的卷積網絡,相較于其他網絡具有收斂快的優勢,因此本文使用卷積神經網絡VGG16 來訓練提取被測圖像的特征,卷積核大小可以選用3 ×3 和5 ×5,也可以采用2 個3 ×3 的卷積層堆疊。VGG 結構圖如圖3 所示。卷積過程如圖4 所示。

圖3 VGG16卷積網絡模型
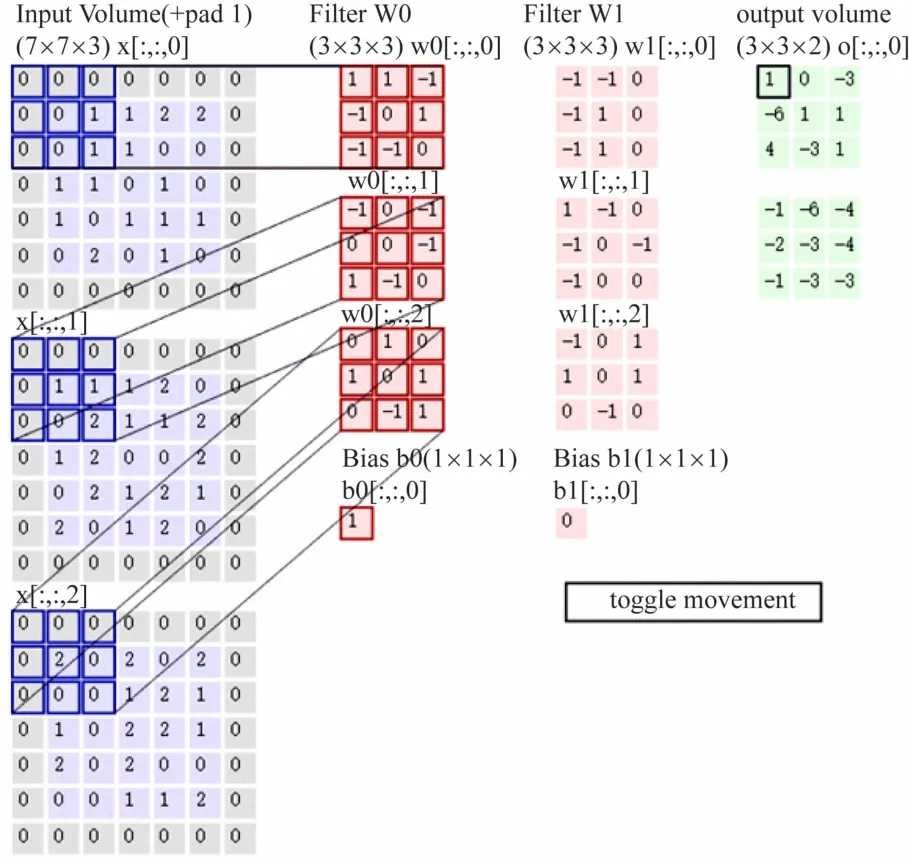
圖4 卷積過程
1.3.3 ReLU激活函數
DNNH算法和DLBHC 算法使用Sigmoid 函數作為激活函數來引入非線性因素。圖5 所示為Sigmoid函數圖像,Sigmoid單調遞增容易優化,但Sigmoid函數缺點十分明顯,Sigmoid 函數收斂緩慢,且會造成梯度消失,即Sigmoid 函數的導數在自變量x趨向于無窮時,會趨于0。函數公式:
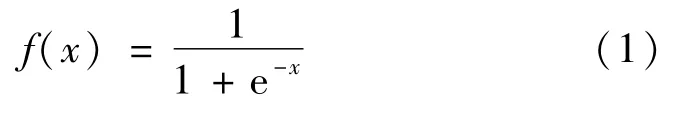
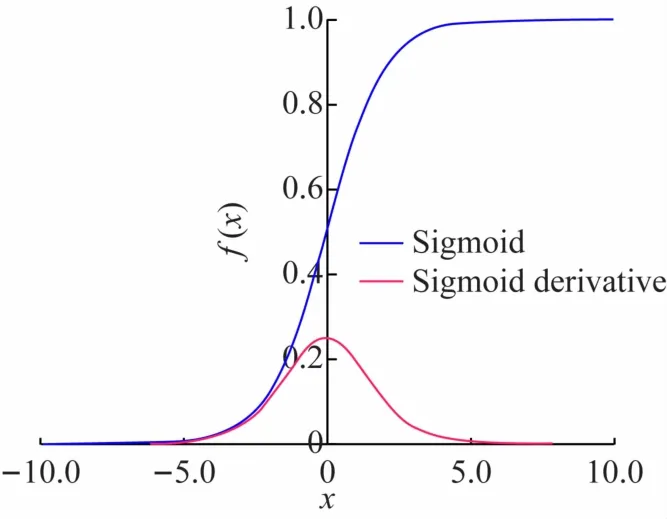
圖5 Sigmoid函數圖像
因此,本文采用ReLU 函數為激活函數。其函數定義為
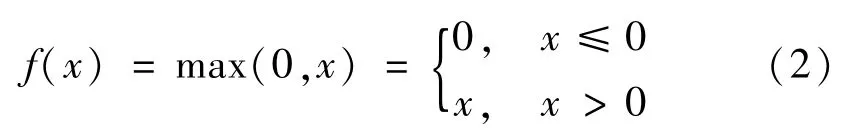
ReLU函數圖像如圖6 所示,ReLU 函數以0 點為中心,分為兩段函數。ReLU 函數與Sigmoid 函數相比,ReLU 函數的導數恒為1,從根本上解決了激活函數梯度消失的問題,同時ReLU 函數得到的隨機梯度下降的收斂速度要比Sigmoid 快很多。ReLU 函數也可以對神經網絡進行稀疏表達,對于無監督學習,也能獲得很好的效果。
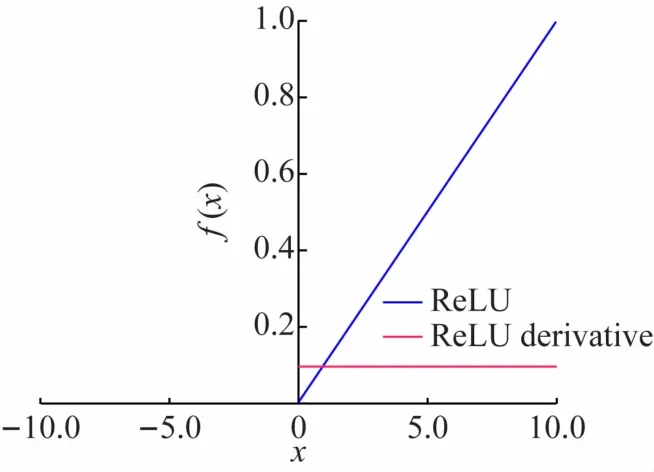
圖6 ReLU函數圖像
1.3.4 交叉熵損失函數
本文使用交叉熵作為損失函數來評價預測值和真實值的不相似程度,標準形式如下:
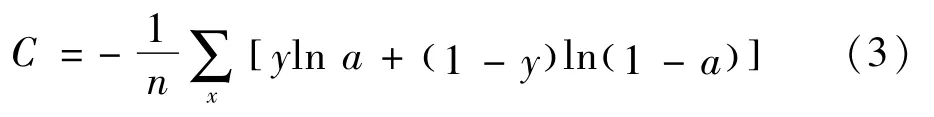
式中:x表示樣本;y表示實際的標簽;a表示預測的輸出;n表示樣本總數量。在深度學習訓練過程中,網絡會產生一定的誤差,這種誤差通過選擇的損失函數來進行彌補。因此,損失函數的性能將直接影響整個網絡系統的性能。
1.3.5 哈希碼生成
使用前面提到的卷積神經網絡以及交叉熵損失函數完成模型的構建,使用爬取到的圖片作為訓練集訓練,由哈希層以及哈希中的編碼塊數確定k位的哈希編碼。同時對松弛的哈希編碼使用一種閾值劃分,這種閾值劃分使得松弛的哈希編碼最終行成二進制編碼,閾值量化函數定義
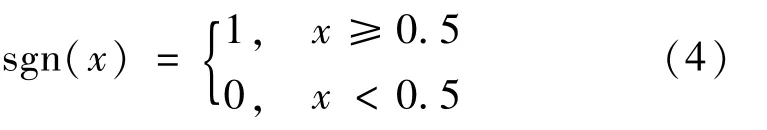
對于待測圖像A,可以通過訓練好的網絡模型,對待測圖像A進行哈希碼生成并經過閾值量化。最終得到二進制編碼為sgn(A)。
1.3.6 檢索策略
圖7 顯示了基于深度學習的哈希近鄰檢索的流程結構。哈希近鄰檢索是將圖像經過訓練好的模型網絡和閾值化過程,得到一個二進制編碼,將其放在索引表中去尋找候選的結果,計算查詢圖像的二進制碼與候選結果間的海明距離,將候選結果通過計算出的海明距離進行排序,排序后的結果序列即為得到的影像序列。本文使用多索引哈希近鄰算法,即在劃分索引時,將查詢圖像和候選結果同時分成多個連續不重復的子串,并分別建立對應的子串索引表,這種劃分子串的方式可以顯著提高查找的速度。
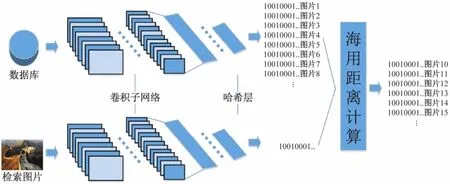
圖7 哈希近鄰檢索流程
2 實驗結果與分析
2.1 數據集
為了驗證構建的模型在旅游景點圖像檢索領域中的表現,從谷歌和百度提取1 萬余張熱門旅游景點圖片構建一個數據集,針對熱門景點中不同類型的景點,如建筑物、湖泊、樹木、山脈等分別進行抓取。數據集部分圖像如圖8 所示。將數據集中的圖片按9∶1的比例分為訓練集和測試集。

圖8 數據集部分圖像
2.2 評價指標
本文采用圖像識別常用評價指標,即查準率(也叫準確率,precision,P)、查全率(也叫召回率,recall,R)和F1測度值(F1-score)。
2.3 結果與分析
圖9~12 分別表示景點天壇和長城的部分測試樣本及測試結果。如圖9 所示,當被測樣本是天壇時,測試結果如圖10 所示。如圖11 所示,當被測樣本是長城時,測試結果如圖12 所示。

圖9 天壇測試集示例
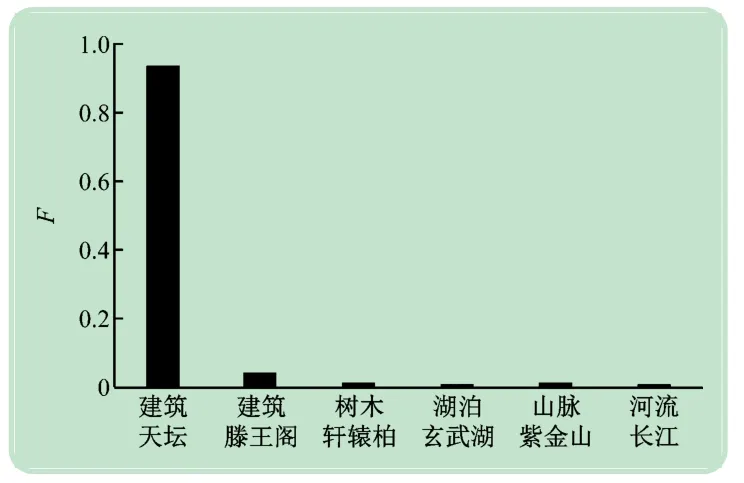
圖10 天壇測試結果

圖11 長城測試集示例

圖12 長城測試結果
為了進一步驗證本文模型的識別效果,設計了3組對比實驗,即分別使用DLBHC 算法、DNNH 算法和本文提出的方法進行對比,實驗結果對比如表1 所示。從表1 可以看出,本文方法的P、R和F1值都是3 種算法中最高的,分別為95.69%、93.36%、94.51%。3種算法的查全率曲線和P-R曲線如圖13、14 所示。由圖可見,本文提出的方法取得了最好的實驗效果,優于DLBHC算法和DNNH算法。
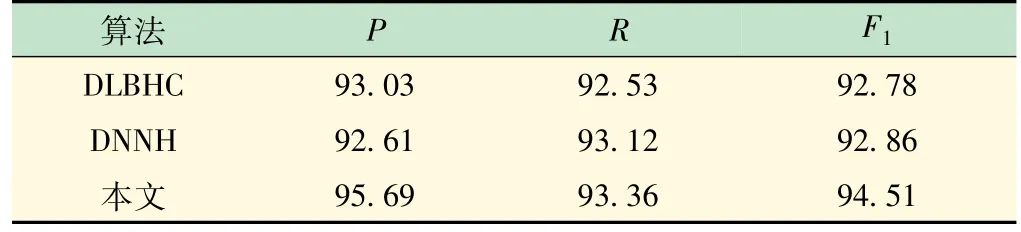
表1 實驗結果對比 %

圖13 3種算法的查全率曲線
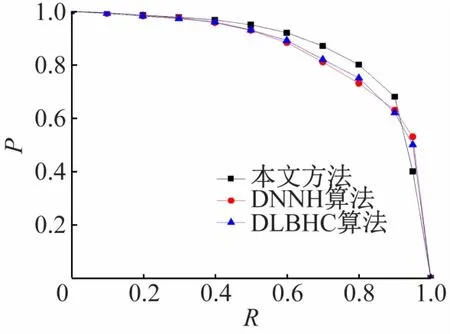
圖14 3種算法的P-R曲線
3 結語
本文分析了傳統深度哈希算法和傳統圖像檢索的優缺點,在對傳統深度哈希算法缺點加以改進的基礎上,提出一種新的特征提取策略的改進的深度學習哈希檢索方法,使得景點圖像數據集中更加快速地檢索。該方法使用了一種基于深度學習的多層次網絡模型,采用ReLU函數作為激活函數,引入非線性因素,通過網絡結構中使用VGG16 卷積網絡來提取具有良好表達能力和魯棒性的特征,并利用多索引哈希近鄰算法進行查找。
本文的方法很好地完成了預期目標,并通過創立一個影像數據集來驗證算法的有效性。驗證了本文提出的方法可以使得深度哈希網絡的訓練更加穩定和迅速。但該方法由于使用了VGG16 作為卷積神經網絡,造成算法占用內存較大,當待測圖像同時出現兩處景點時,存在一定的分辨誤差。本文后續將進一步研究。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
