基于燃煤電站運(yùn)行數(shù)據(jù)的煙氣脫硫系統(tǒng)性能預(yù)測(cè)研究
2022-09-03 01:37:44李存文王在華陳濤馮前偉徐克濤張楊
發(fā)電技術(shù) 2022年4期
李存文,王在華,陳濤,馮前偉,徐克濤,張楊
(1.華電電力科學(xué)研究院有限公司,浙江省 杭州市310030;2.國(guó)網(wǎng)浙江省電力有限公司電力科學(xué)研究院,浙江省 杭州市310014;3.華電新疆發(fā)電有限公司,新疆維吾爾自治區(qū) 烏魯木齊市830063)
0 引言
為了進(jìn)一步響應(yīng)《煤電節(jié)能減排升級(jí)與改造行動(dòng)計(jì)劃(2014—2020年)》[1]的號(hào)召,燃煤電站仍在尋求管理和技術(shù)手段,以實(shí)現(xiàn)排放達(dá)標(biāo)的同時(shí)降低煙氣環(huán)保系統(tǒng)的運(yùn)行維護(hù)成本,即環(huán)保系統(tǒng)的精細(xì)化運(yùn)行控制顯得越發(fā)重要。而對(duì)煙氣環(huán)保系統(tǒng)性能的準(zhǔn)確認(rèn)識(shí)是其精細(xì)化控制的基礎(chǔ)。
獲取環(huán)保系統(tǒng)性能的途徑有性能試驗(yàn)、在線監(jiān)測(cè)等。性能試驗(yàn)依據(jù)于標(biāo)準(zhǔn)規(guī)范,指標(biāo)全面,但試驗(yàn)條件嚴(yán)苛,化驗(yàn)耗時(shí)長(zhǎng);在線監(jiān)測(cè)主要由現(xiàn)場(chǎng)表計(jì)完成,指標(biāo)的實(shí)時(shí)性、延續(xù)性好,但存在一些參數(shù)(如漿液品質(zhì)等)無(wú)法監(jiān)測(cè)的情況。如何準(zhǔn)確、快速、高效地獲取環(huán)保系統(tǒng)實(shí)時(shí)性能,仍是科研技術(shù)人員需要研究的重要課題[2]。
數(shù)據(jù)挖掘技術(shù)融合人工智能、數(shù)據(jù)庫(kù)、高性能計(jì)算等多學(xué)科的成果,是將大量數(shù)據(jù)轉(zhuǎn)換為信息和知識(shí)的強(qiáng)大工具[3-5]。運(yùn)用數(shù)據(jù)挖掘技術(shù),研究獲取環(huán)保系統(tǒng)性能的新方法,為環(huán)保系統(tǒng)精細(xì)化控制作技術(shù)支撐,實(shí)現(xiàn)生態(tài)環(huán)境治理能力現(xiàn)代化[6]。
1 環(huán)保系統(tǒng)數(shù)據(jù)挖掘算法
1.1 數(shù)據(jù)預(yù)處理
電站運(yùn)行參數(shù)來(lái)自運(yùn)行實(shí)際,其數(shù)據(jù)一致性和完整性往往無(wú)法達(dá)到數(shù)據(jù)挖掘的要求。因而,數(shù)據(jù)預(yù)處理必不可少,有必要進(jìn)一步研究并實(shí)現(xiàn)運(yùn)行數(shù)據(jù)預(yù)處理方法的標(biāo)準(zhǔn)化。此外,鑒于運(yùn)行數(shù)據(jù)在采集時(shí)已完成數(shù)量化,即自帶數(shù)值屬性,因此,數(shù)據(jù)預(yù)處理包括數(shù)據(jù)集成、數(shù)據(jù)清理和變換、統(tǒng)計(jì)分析及可視化,具體步驟如圖1所示。
數(shù)據(jù)集成將分散數(shù)據(jù)集成為數(shù)據(jù)集。
運(yùn)行數(shù)據(jù)不可避免地包含異常、缺省數(shù)據(jù)和噪聲,因而,為針對(duì)性地提高數(shù)據(jù)質(zhì)量,需進(jìn)行以下數(shù)據(jù)清理:一致性檢查并清理缺省值、空值和異常值;移動(dòng)平均濾波法光滑去噪;剔除違背工藝邏輯的工況數(shù)據(jù)。
為規(guī)避量綱對(duì)數(shù)據(jù)認(rèn)識(shí)的影響,同時(shí)為數(shù)據(jù)模型建模及迭代優(yōu)化考量,數(shù)據(jù)變換的主要內(nèi)容有:max-min 歸一化,穩(wěn)定梯度下降算法的求優(yōu)速度,以加快模型訓(xùn)練速度;對(duì)有類似開或關(guān)2種狀態(tài)的參數(shù)進(jìn)行二值化處理,壓縮模型變量數(shù)值域及量綱;引入新指標(biāo),如電耗量、還原劑耗量等,豐富對(duì)象性能指標(biāo)。
統(tǒng)計(jì)分析及可視化包括兩部分:識(shí)別研究對(duì)象的物理邊界、數(shù)據(jù)特征及規(guī)模;將信息從數(shù)據(jù)中提煉為可解釋的知識(shí),包括圖、表等。
1.2 環(huán)保系統(tǒng)關(guān)鍵因素分析
按所采集的測(cè)點(diǎn)參數(shù)計(jì),數(shù)據(jù)集的維度通常非常大,這無(wú)疑加大了數(shù)據(jù)建模的工作負(fù)擔(dān)。因此,須對(duì)數(shù)據(jù)集進(jìn)行降維,同時(shí)提取環(huán)保系統(tǒng)性能指標(biāo)的關(guān)鍵因素集,而主成分分析方法在這方面十分有效[7-11]。
算法步驟如下:
1)以采樣時(shí)刻劃分?jǐn)?shù)據(jù)元組,構(gòu)成數(shù)據(jù)集O;
2)元組集O的標(biāo)準(zhǔn)化成矩陣S;
3)求矩陣S的相關(guān)系數(shù)矩陣R;
4)求取矩陣R的特征根λi及其特征向量ηi;
5)將標(biāo)準(zhǔn)化后的指標(biāo)變量轉(zhuǎn)換為主成分ξj;
6)分析各主成分權(quán)重系數(shù),并締結(jié)結(jié)果集U;
7)設(shè)定遴選權(quán)重系數(shù)規(guī)則,將主成分劃入關(guān)鍵因素集。
1.3 環(huán)保系統(tǒng)性能數(shù)據(jù)模型
煙氣凈化處理包含復(fù)雜的物理、化學(xué)反應(yīng),且傳熱與傳質(zhì)耦合,參數(shù)間關(guān)系復(fù)雜,使得機(jī)理模型雖然能保證邏輯趨勢(shì)的正確性,但分析的精細(xì)度面臨瓶頸,而數(shù)據(jù)模型因強(qiáng)擬合而具備高精度[12-13]。另外,環(huán)保系統(tǒng)內(nèi)部傳質(zhì)存在磨損、漿液中有害物質(zhì)聚集等因素,致使系統(tǒng)性能隨運(yùn)行時(shí)間而衰減,因而,定期地對(duì)數(shù)據(jù)模型進(jìn)行訓(xùn)練更新,適應(yīng)環(huán)保系統(tǒng)特性變化,既可保證模型的正確性,還可規(guī)避復(fù)雜的機(jī)理建模過程。
回歸分析是構(gòu)建復(fù)雜對(duì)象特性模型的高效方法[14-18]。以關(guān)鍵因素集作為數(shù)據(jù)模型的輸入,融合多項(xiàng)式、Lasso、Ridge和神經(jīng)網(wǎng)絡(luò)算法[19-21],構(gòu)建環(huán)保系統(tǒng)數(shù)據(jù)模型,如圖2 所示。此外,為了均衡優(yōu)化速度,模型迭代優(yōu)化選用梯度下降算法進(jìn)行。
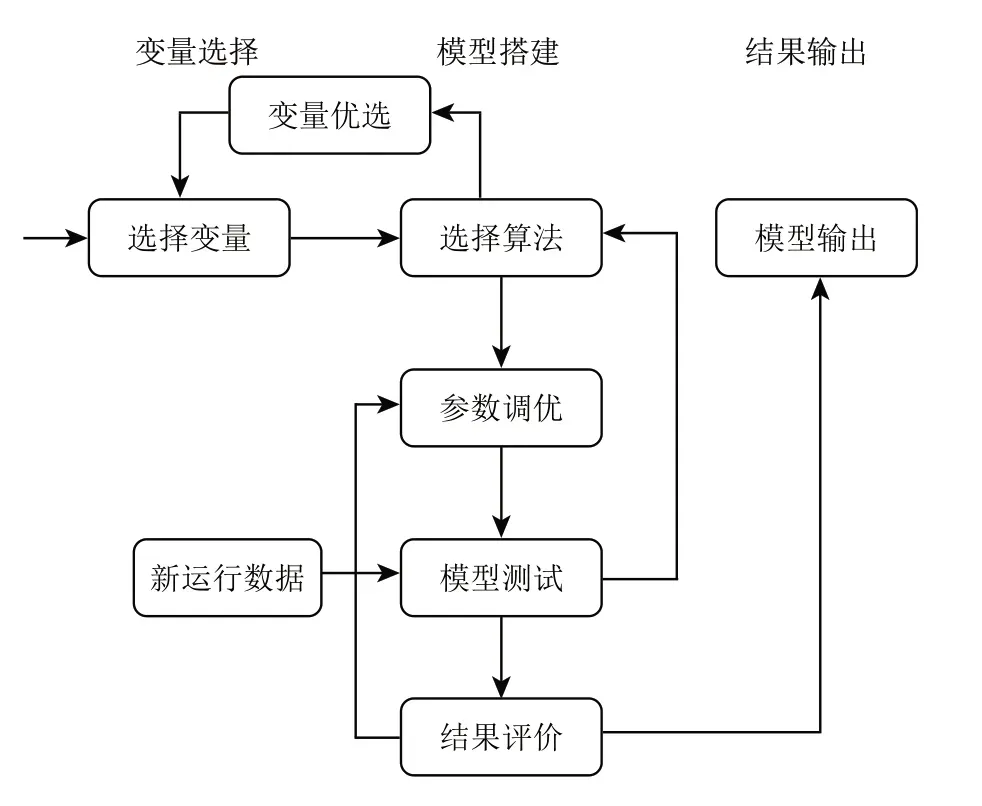
圖2 煙氣環(huán)保系統(tǒng)數(shù)據(jù)模型搭建方法Fig.2 Method of building data model of flue gas environmental protection system
數(shù)據(jù)模型的評(píng)價(jià)指標(biāo)較為豐富,結(jié)合實(shí)際并規(guī)避量綱及數(shù)值量級(jí)對(duì)模型精度的影響,綜合研究后選用均方根誤差γRMSE、決定系數(shù)γR2、平均絕對(duì)百分比誤差γMAPE這3 個(gè)指標(biāo)來(lái)評(píng)價(jià)數(shù)據(jù)模型的準(zhǔn)確性、有效性。
2 數(shù)據(jù)模型應(yīng)用案例分析
某燃煤電站660 MW機(jī)組煙氣脫硫系統(tǒng)采用石灰石-石膏濕法工藝,“1爐1塔”配置,噴淋空塔并設(shè)置5層噴淋層、1層托盤。借助于廠級(jí)實(shí)時(shí)監(jiān)控信息系統(tǒng)(supervisory information system, SIS),采集到2018年4—6月為期50天、包括107個(gè)參數(shù)的運(yùn)行數(shù)據(jù)。依托Matlab平臺(tái),將數(shù)據(jù)塊集成為數(shù)據(jù)矩陣,以采樣時(shí)刻為元組劃分原則,并去除重復(fù)數(shù)據(jù),得到共計(jì)13983條數(shù)據(jù)元組。根據(jù)運(yùn)行參數(shù)在時(shí)域上連續(xù)的特點(diǎn),采用前時(shí)刻值填充后時(shí)刻缺省值,并運(yùn)用移動(dòng)平均濾波的方法進(jìn)行去噪。
數(shù)據(jù)平滑濾波后,機(jī)組功率的瞬時(shí)波動(dòng)大大減弱、數(shù)據(jù)趨勢(shì)及均值不失真,也說(shuō)明數(shù)據(jù)去噪的必要性,如圖3所示。

圖3 數(shù)據(jù)平滑濾波前后結(jié)果Fig.3 Results before and after data smoothing filtering
剔除與物質(zhì)守恒及煙氣漏風(fēng)等客觀規(guī)律相違背的工況數(shù)據(jù),主要有:1)煙氣出口氧含量小于入口氧含量的數(shù)據(jù);2)煙道兩側(cè)煙氣氧含量絕對(duì)偏差超過3.0%的數(shù)據(jù);3)折算后出口污染物濃度大于入口的數(shù)據(jù);4)機(jī)組有功功率小于等于零的數(shù)據(jù)。數(shù)據(jù)清理后,得到數(shù)據(jù)質(zhì)量高的8616個(gè)元組數(shù)據(jù),即8616×111數(shù)據(jù)矩陣,占原數(shù)據(jù)集約61.62%,表明所采集運(yùn)行數(shù)據(jù)的有效性高。
數(shù)據(jù)變換主要在建模中完成,而電耗和物耗指標(biāo)為數(shù)據(jù)模型提供先驗(yàn)知識(shí)與信息。
最后,統(tǒng)計(jì)環(huán)保系統(tǒng)參數(shù)的最值和眾數(shù),得到該環(huán)保系統(tǒng)的物理邊界,見表1。
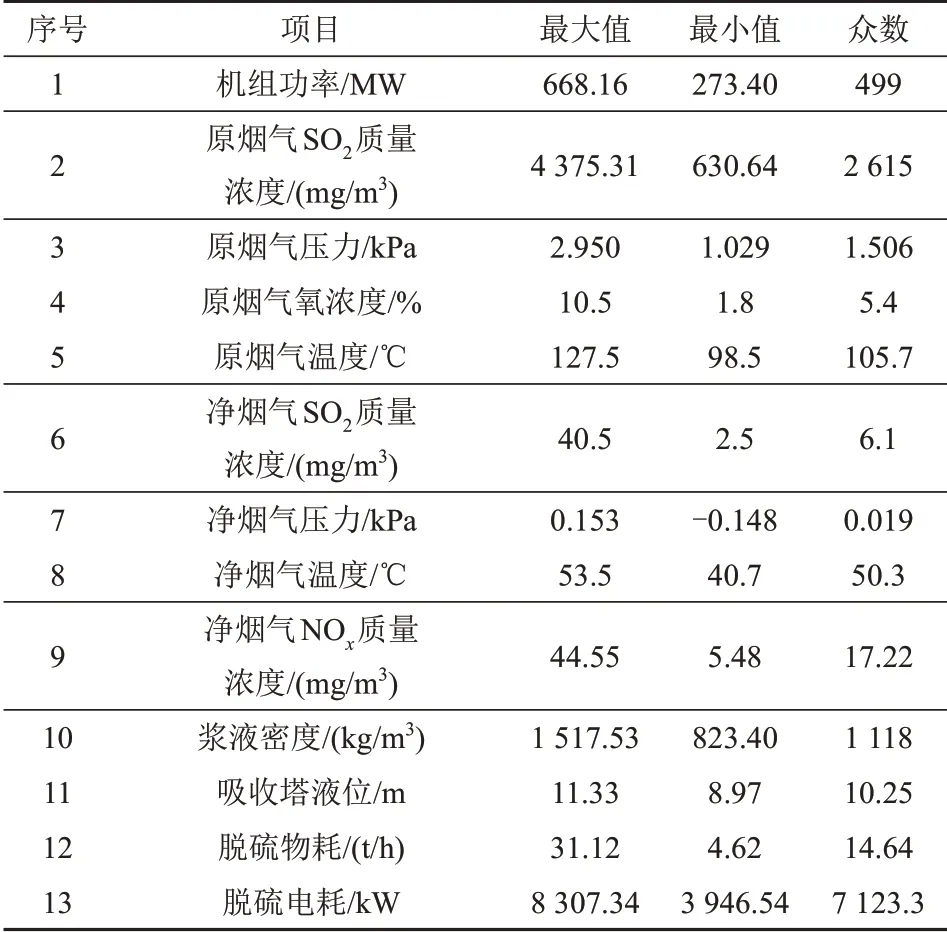
表1 運(yùn)行數(shù)據(jù)的統(tǒng)計(jì)分析Tab.1 Statistical analysis on operation data
脫硫效率是表征煙氣脫硫系統(tǒng)性能的關(guān)鍵指標(biāo)。借助于阿里云平臺(tái),分析各參數(shù)對(duì)脫硫效率的影響,構(gòu)成關(guān)鍵因素集。結(jié)果表明,影響脫硫效率的關(guān)鍵影響因素有原煙氣SO2濃度、循環(huán)泵電流、漿液pH 值、原煙氣煙塵濃度、漿液密度、煙氣量、原煙氣溫度等,如圖4 所示。該結(jié)果與機(jī)理定性分析結(jié)論一致,表明主成分分析方法具有較好的適用性和有效性,為后續(xù)脫硫系統(tǒng)的運(yùn)行優(yōu)化及調(diào)整提供定量的參考。
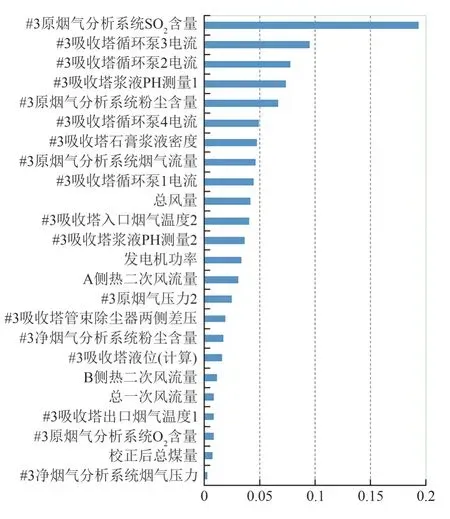
圖4 關(guān)鍵因素集Fig.4 Key factor set
梳理關(guān)鍵因素集的結(jié)果,作為煙氣脫硫系統(tǒng)性能數(shù)據(jù)模型的輸入,采用多算法融合的回歸分析技術(shù)構(gòu)建環(huán)保系統(tǒng)性能數(shù)據(jù)模型,最終通過預(yù)測(cè)凈煙氣SO2濃度、凈煙氣溫度、脫硫電耗、石灰石耗量,以達(dá)到預(yù)測(cè)煙氣脫硫系統(tǒng)性能的目的,同時(shí)完成算法調(diào)優(yōu)和模型訓(xùn)練,如圖5所示。

圖5 煙氣脫硫系統(tǒng)性能預(yù)測(cè)數(shù)據(jù)模型Fig.5 Data model for performance prediction of flue gas desulphurization system
數(shù)據(jù)模型的建立成功表明了方法的可行性,而模型的準(zhǔn)確性通過3個(gè)指標(biāo)來(lái)評(píng)價(jià)界定,見表2。
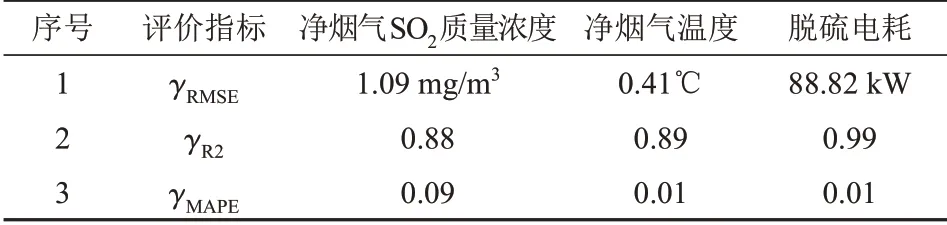
表2 數(shù)據(jù)模型的主要評(píng)價(jià)指標(biāo)與效果Tab.2 Main evaluation index and effect of the data model
γRMSE分別為1.09 mg/m3、0.41℃、88.82 kW,與其眾數(shù)和最大值相比,數(shù)值和量級(jí)均在工程允許范圍內(nèi);γR2均大于0.85,模型的效果較好,能高概率地保證模型趨勢(shì)的正確性;γMAPE均小于0.10,模型能高準(zhǔn)確度地模擬對(duì)象的輸入和輸出,間接表明算法和參數(shù)匹配較好。
為進(jìn)一步驗(yàn)證模型的有效性和準(zhǔn)確性,選取不同機(jī)組負(fù)荷下運(yùn)行數(shù)據(jù),對(duì)模型進(jìn)行測(cè)試,結(jié)果見表3和表4。
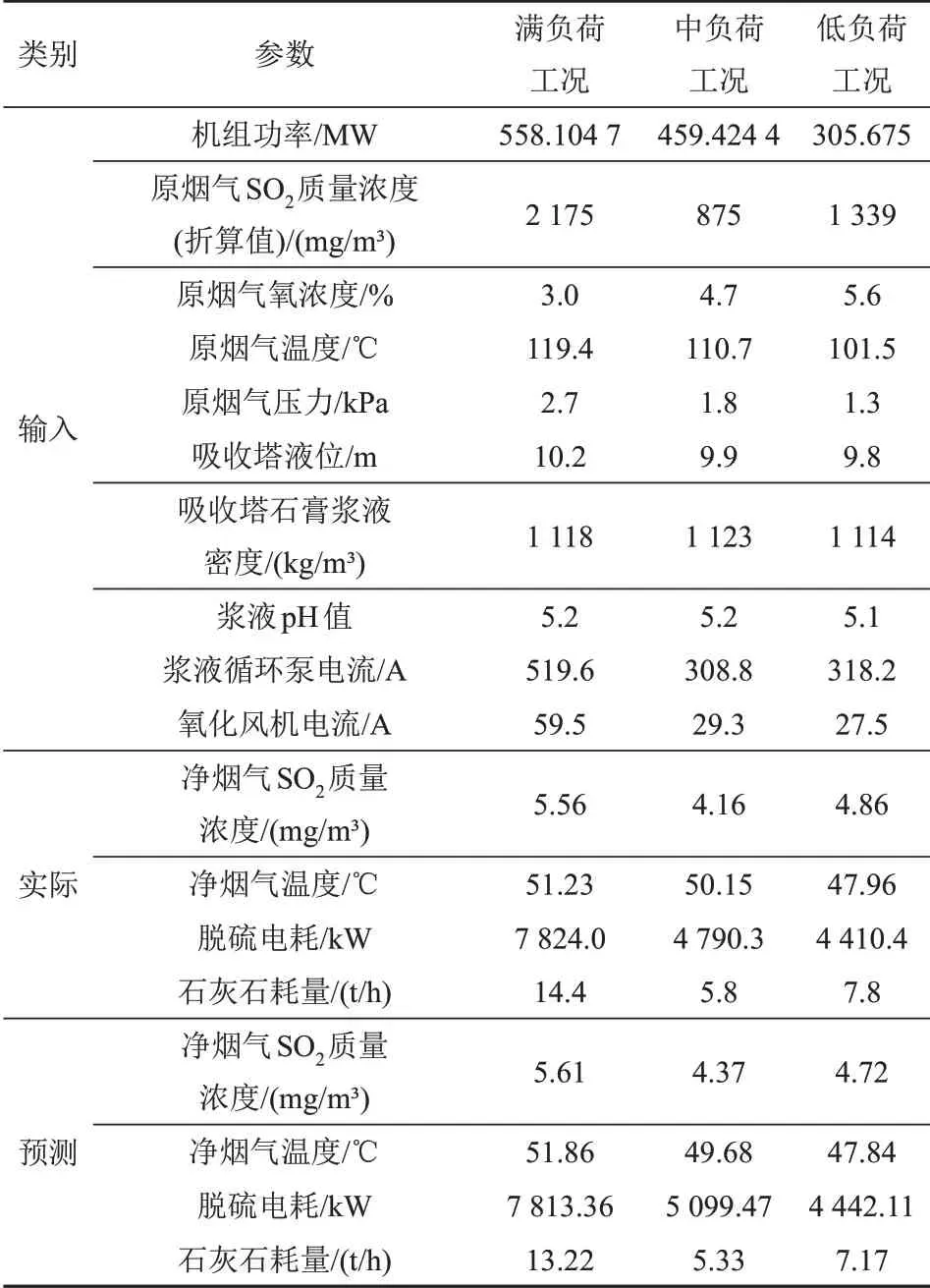
表3 煙氣脫硫系統(tǒng)性能預(yù)測(cè)數(shù)據(jù)模型測(cè)試案例Tab.3 Test case of performance prediction data model for flue gas desulfurization system
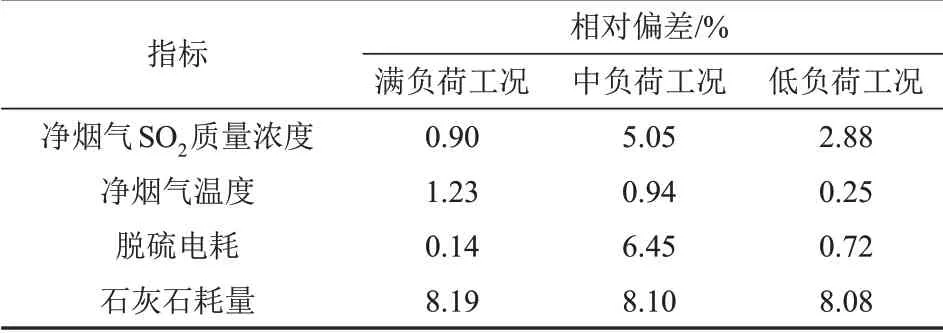
表4 數(shù)據(jù)模型測(cè)試結(jié)果Tab.4 Testing results of data model
石灰石制漿系統(tǒng)具有時(shí)滯延后特性,即石灰石耗量的精確確定不完全依托運(yùn)行數(shù)據(jù),因此石灰石耗量的準(zhǔn)確性對(duì)于模型效果評(píng)價(jià)的可靠性有待深入研究。剔除石灰石耗量后,各參數(shù)的相對(duì)偏差均小于6.50%,量級(jí)與模型的γMAPE相當(dāng),且數(shù)據(jù)模型能準(zhǔn)確復(fù)現(xiàn)負(fù)荷變化下環(huán)保系統(tǒng)狀態(tài)變化規(guī)律和趨勢(shì),具有較強(qiáng)的負(fù)荷適應(yīng)性,驗(yàn)證了性能預(yù)測(cè)數(shù)據(jù)模型的有效性和準(zhǔn)確性。
3 結(jié)論
突破傳統(tǒng)機(jī)理和試驗(yàn)研究的方式,以燃煤電站煙氣脫硫系統(tǒng)運(yùn)行數(shù)據(jù)作為切入點(diǎn),運(yùn)用大數(shù)據(jù)技術(shù)挖掘出影響脫硫系統(tǒng)性能的關(guān)鍵因素集,合理梳理關(guān)鍵因素并將其作為數(shù)據(jù)模型的輸入,融合回歸分析技術(shù)的多種算法,構(gòu)建了煙氣脫硫系統(tǒng)性能預(yù)測(cè)數(shù)據(jù)模型。實(shí)例證明,訓(xùn)練后的模型能高精度地復(fù)現(xiàn)不同負(fù)荷工況的脫硫系統(tǒng)性能,還具有較好的靈活性和可拓展性,為后續(xù)燃煤電站環(huán)保裝備的狀態(tài)監(jiān)測(cè)、趨勢(shì)分析、運(yùn)行優(yōu)化提供堅(jiān)實(shí)的基礎(chǔ)。相比于機(jī)理研究和試驗(yàn)方法,該研究方法更為高效靈活、簡(jiǎn)潔明了,豐富了燃煤電站環(huán)保研究思路,且具有啟示意義。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
化工管理(2022年13期)2022-12-02 09:21:52
工業(yè)設(shè)計(jì)(2022年8期)2022-09-09 07:43:20
軍民兩用技術(shù)與產(chǎn)品(2021年10期)2021-03-16 06:05:30
北京測(cè)繪(2020年12期)2020-12-29 01:33:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
測(cè)控技術(shù)(2018年2期)2018-12-09 09:00:52
家庭影院技術(shù)(2017年9期)2017-09-26 03:41:45
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
